



执行摘要
本报告是AI数据中心基础设施全链路研究的总结,在前置9篇零部件报告(GPU/ASIC/存储/铜缆/CPO/交换机/液冷/电源/PCB)的基础上,首次从整机系统集成的视角,将分散的零部件整合为可运转的AI服务器系统。
核心结论一:整机集成能力决定最终性能天花板。同样8卡H100配置,不同厂商整机MLPerf训练性能差距3-5%,但分布式集群线性扩展率差距可达30%以上,相当于35%的硬件投入被浪费。核心差异不在零部件参数,而在系统协同设计——信号完整性、散热-供电联动、网络拓扑优化、软件通信库调优。
核心结论二:AI服务器TCO结构与传统服务器截然不同。由于高端GPU极其昂贵(单台8卡机型超25万美元),3年周期内硬件CapEx占比高达75-85%,电费及制冷OpEx占10-15%。液冷的核心价值不是省电费,而是提升机架功率密度(10kW/柜→100kW/柜),减少机房租赁面积和跨机柜网络光缆开销。风冷vs液冷TCO对比:以单柜8卡H100为例,单机柜风冷方案PUE约1.4,液冷方案PUE可低至1.15;万卡级集群综合PUE约1.25。液冷初期投入高20-30%;在万卡集群尺度下,液冷节省的机房面积和光缆成本可在2-3年内抵消初期投入溢价,3年TCO反而低10-15%。
核心结论三:国产替代的关键瓶颈从硬件(L2)跃迁至AI生态(L3-L4)。算力芯片成功≠集群成功。异构通信库(类似NCCL)、编译器(算子融合)、底层调优工具链的缺失,导致纸面算力极高但实际训练吞吐量极低。L3→L4是国产替代的"死亡之谷"。
核心结论四:整机架构正从"单机逻辑"转向"集群逻辑"。NVIDIA从DGX(单机)到GB200 NVL72(整机柜),云厂商从采购标准服务器到自研ASIC+定制整机,ODM从代工向设计服务延伸。能交付Cluster(集群)的厂商才有议价权。
本报告面向投资者、从业者及行业研究者,力求在零部件深度拆解与整机系统认知之间架起桥梁,揭示AI服务器从"堆料"到"系统工程"的核心逻辑。
第一章:为什么需要整机视角?
1.1 零部件报告已经覆盖了什么
在前置的9篇报告中,我们已系统拆解了AI服务器的核心零部件:计算(GPU/ASIC)、存储(HBM/DRAM/SSD)、互连(铜缆/光模块/交换机)、散热(液冷)、供电(电源)、载体(PCB)。每篇报告独立成篇,数据详实、逻辑闭环,为理解单个零部件提供了深度认知。
1.2 行业核心认知误区:堆料≠高性能AI服务器
在零部件报告完成后,一个核心问题浮现:如果零部件都选最好的,整机性能是否一定最好?答案是否定的。
误区一:只看GPU单卡算力,忽略系统算力释放。H100单卡FP16 Tensor Core峰值算力989 TFLOPS,但在实际训练集群中,由于互连带宽不足、CPU预处理瓶颈、散热降频等因素,系统算力利用率通常仅50-70%。
误区二:只看零部件参数,忽略匹配度。8卡H100仅配单路32核CPU(双路合计32核),在数据预处理密集型场景(如计算机视觉、多模态大模型)中,CPU核数不足直接导致GPU算力闲置。行业共识是8卡高阶系统标配双路56-64核处理器。
误区三:只看静态BOM成本,忽略全生命周期TCO。AI服务器3年TCO中,硬件采购占比75-85%,电费仅占10-15%。液冷的价值不在省电费,而在提升机架密度、减少机房面积。
实测数据印证了这一判断:同样8卡H100配置,不同厂商整机MLPerf训练性能差距约3-5%,但在分布式集群线性扩展率上,差距可达30%以上。NVIDIA DGX SuperPOD本质上卖的是一套经过极限调优的"集群操作系统",而不仅仅是金属盒子。
【行业踩坑案例】
案例一:国内某白牌厂商8卡H100整机因PCIe拓扑设计错误,GPU跨NUMA节点通信延迟增加3倍,实际训练性能仅为DGX H100的60%。(详细拆解见3.2节NVLink Switch与PCIe拓扑设计)
案例二:某云厂商万卡集群因NCCL拓扑感知调优不足,线性扩展率仅65%,相当于3500张GPU的算力被闲置。(详细拆解见5.1.1节PCIe拓扑与P2P通信设计)——网络硬件层面部署了Fat-Tree拓扑,但NCCL未针对实际拓扑选择最优的all-reduce算法,导致大量通信流量经过非最优路径,核心交换机拥塞严重。
1.3 缺的是什么:系统集成视角
整机视角回答的是零部件报告无法覆盖的问题:选型匹配(8卡H100配多少HBM?互连带宽够不够?散热能不能压住?)、成本优化(BOM表中GPU占65%+,其他部件怎么降本?)、性能瓶颈(weakest link在哪?GPU算力≠系统算力)、部署差异(训练型、推理型、边缘型服务器的架构分野及选型逻辑)。
1.4 整机报告的核心价值
给投资者:看清"零部件故事"如何转化为"整机产品",区分"真整机厂商"和"硬件组装厂"。核心投资逻辑有三:其一,"整机即集群"——AI服务器不再是单机逻辑,能交付集群(Cluster)的厂商才有议价权,毛利率正从"钣金组装"向"网络拓扑设计+热管理系统集成"转移;其二,"从风冷到液冷的价值转移"——TDP失控使液冷从"选修"变为"必修",关注掌握冷板、CDU及流体分配微通道核心专利的部件/整机协同厂商;其三,"国产替代的生态破局者"——纯看芯片算力意义减弱,投资应聚焦那些能通过ASIC定制化网络芯片或在通信库层面重写底层协议,从而"用多张中低阶卡组合出等效高阶卡体验"的系统级厂商。
给从业者:系统集成的关键决策点与常见陷阱,从踩坑案例中汲取经验。
给读者:从芯片到机柜的完整认知地图,理解AI服务器作为系统工程的本质。
第二章:AI服务器架构全景
2.1 系统架构分层模型
AI服务器可抽象为六个层级:计算层(GPU/ASIC)、存储层(HBM/DRAM/SSD)、互连层(NIC/交换机/外部网络)、散热层(液冷/风冷)、供电层(PSU/PDU/外部电网)、控制层(Host CPU/BMC)。
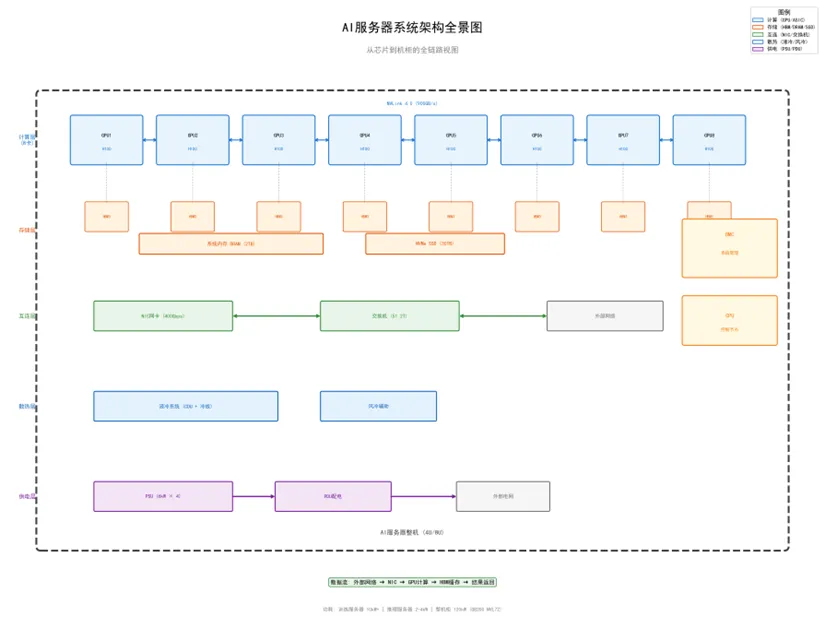
图1:AI服务器系统架构全景图(从芯片到机柜的六层模型)
2.2 整机架构的两大核心设计范式
范式一:全栈紧耦合一体化架构(NVIDIA主导)代表产品为DGX系列和GB200 NVL72。NVIDIA从芯片、互联、散热到软件全栈自研优化,追求极致性能。优势是性能天花板高;劣势是兼容性弱、成本高、供应商锁定。
范式二:开放解耦化架构(OCP/云厂商主导)代表为Meta、微软、阿里云的自研整机。基于OCP标准,模块化、白牌化、软硬件解耦。优势是灵活度高、成本优化空间大;劣势是性能调优难度大、碎片化。
国内厂商两条路线并行:华为走紧耦合,浪潮/曙光走开放解耦。
2.3 数据流全景
大模型预训练端到端数据流:数据集预处理(CPU)→ 载入系统内存(DRAM)→ GPU Direct Storage直接写入HBM → 前向计算(GPU Tensor Core)→ 反向传播 → 梯度同步(all-reduce)→ 参数更新 → checkpoint周期性写入SSD → 故障时从checkpoint恢复。
2.4 训练型 vs 推理型 vs 边缘型服务器架构分野
注:Intel Gaudi2 Server参数——8×Gaudi2芯片,~19.2 PFLOPS FP16,768GB显存,RoCE v2互联,风冷/液冷散热,~8kW功耗,开放解耦路线,SynapseAI软件生态,正常供货。
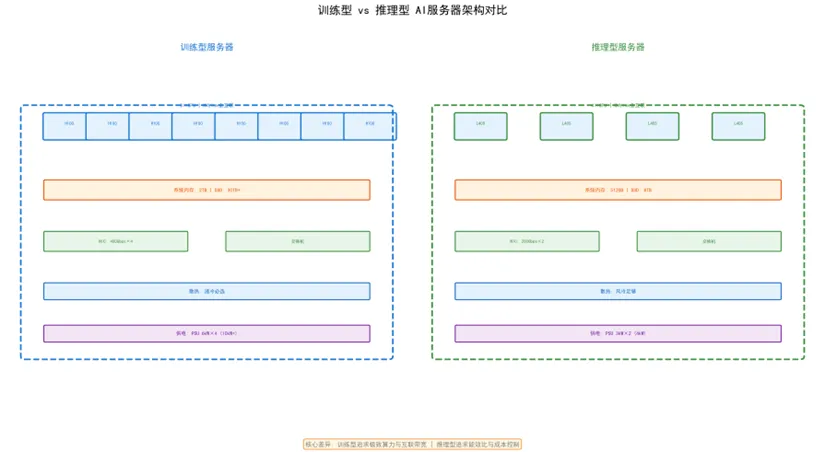
图2:训练型 vs 推理型服务器架构对比
第三章:计算子系统设计
3.1 GPU选型与配置逻辑
GPU是AI服务器的核心,但"选最好的GPU"不等于"选最合适的GPU"。配置逻辑需从模型规模、任务类型、成本约束三个维度综合决策。
数量决策:模型规模 → 显存需求 → GPU数量
以Llama-3 70B模型FP16训练为例:模型参数量70B,FP16精度下参数显存占用140GB。训练显存需求 = 模型参数(2B/参数) + 梯度(2B/参数) + 优化器状态(8字节/参数, Adam FP32存储) + 激活值(可变, 取决于batch size和序列长度) ≈ 12B+/参数。以70B模型计算,基础显存需求约840GB+。
若采用显存优化技术(8-bit Adam、ZeRO、梯度检查点等),可将需求压缩至500-600GB范围。此时8卡H100(总显存640GB)可完整容纳Llama-3 70B FP16训练,无需强制模型并行。若采用标准FP32 Adam,8卡H100显存不足,必须借助模型并行(张量并行+流水线并行)。H200(141GB×8=1128GB)配合8-bit Adam、ZeRO等显存优化技术,可支持140B模型FP16精度单节点训练。
GPT-4级别(1.8T参数)则需要数百卡集群。
型号决策:H100 vs H200 vs B200
H100是目前训练市场主流,80GB HBM3显存。H200升级至141GB HBM3e显存,适合大模型训练场景。B200(Blackwell架构)支持FP4稀疏精度,显存192GB HBM3e,单卡稀疏算力较H100大幅提升,但功耗也升至1000W+。
互联方式:NVLink vs PCIe
NVLink 4.0提供900GB/s带宽,是机柜内GPU互联的必选项。PCIe 5.0仅128GB/s,成本低但带宽瓶颈明显。用PCIe替代NVLink后,张量并行的通信开销变得不可接受,必须在软件层重构模型切分策略。
3.2 GPU互联拓扑与NVLink Switch设计陷阱
国内厂商在NVLink Switch环节存在严重踩坑点。带宽利用率不足50%的现象属实,但这通常不是协议层面的缺陷,而是信号完整性(Signal Integrity, SI)的物理灾难。
112G/224G PAM4信号对阻抗极度敏感。国内部分白牌厂商在PCB板材选型(如未采用超低损耗的Megtron 7级别材料)、过孔(Via)背钻工艺精度不够、或者铜缆/连接器压接应力控制不当时,会导致误码率(BER)飙升。112G/224G PAM4信号的SI问题会导致误码率飙升,NVLink链路层的FEC前向纠错能力耗尽后,会触发高阶链路重传;大量重传会直接占用有效带宽,最终表象就是"堆了硬件但有效带宽减半"。
业内进行IBERT眼图测试时,若眼高/眼宽闭合余量不足,跑NCCL All-Reduce测试时的总线带宽会直接从理论的900GB/s断崖式下跌至400GB/s以下。
除信号完整性问题外,NVLink Switch的散热设计缺陷也会导致带宽利用率下降:Switch芯片工作温度超过85℃时,会自动降频,导致NVLink总线带宽下降20-30%。
3.3 CPU与GPU的配比逻辑
Host CPU是AI服务器中容易被忽视但至关重要的组件。CPU不负责AI计算,但承担任务调度、数据预处理、系统管理、网络通信控制、GPU协同初始化与监控等关键职能。
对于8卡H100训练场景:最低配置双路32核(如Intel Xeon Silver)在纯大模型推理或简单训练中勉强够用;推荐配置双路56-64核(AMD EPYC Genoa/Turin更受青睐);预处理密集场景(计算机视觉、多模态大模型)需64核以上,否则GPU利用率大幅下降。
AMD EPYC在AI整机中更受青睐,原因在于PCIe通道数量(单路可达128条PCIe 5.0,更易实现无Switch或少Switch拓扑)以及更高的核心密度。
国产替代方面,海光C86兼容x86指令集,适配难度较低;鲲鹏ARM架构需软件重新编译,生态建设任重道远。
3.4 ASIC替代场景与异构协同
GPU是通用计算平台,ASIC是专用加速器。选ASIC的场景:推理为主、模型固定、批量部署(如Google TPU处理搜索推荐)。选GPU的场景:训练为主、模型迭代快、灵活性要求高。混合架构:训练用GPU,推理用ASIC(Google、AWS、微软的实践)。
在整机层面,异构计算需要解决系统级协同问题:任务调度硬件通道、内存池共享、中断处理机制。Google TPU Pod通过自研的ICI实现TPU间高速通信,华为Atlas通过HCCS实现昇腾芯片互联,均为紧耦合架构的典型代表。
第四章:存储子系统匹配
4.1 三级存储架构
AI服务器的存储系统呈金字塔结构:L1 HBM(GPU片上,容量80-192GB,带宽3-8TB/s)、L2 DRAM(系统内存,容量256GB-2TB,带宽200-400GB/s)、L3 SSD(持久存储,容量8-30TB,带宽5-50GB/s)。数据在三级存储之间流转的效率直接决定系统性能。
4.2 HBM容量规划
核心公式:显存需求 = 模型参数 × 精度字节数 × 冗余系数。FP16精度2字节/参数,FP8精度1字节/参数。训练需额外存储优化器状态(Adam:约4倍模型参数,FP32存储)。
并行策略对HBM需求影响巨大:张量并行(TP)单卡HBM需求高;流水线并行(PP)单卡HBM需求低。同样70B模型,不同并行策略下单卡HBM需求差异可达2倍以上。
以Llama-3 70B FP16训练为例(标准FP32 Adam):模型参数量70B,FP16精度下参数显存占用140GB,梯度140GB,优化器状态560GB,激活值等约100-200GB,合计约940-1040GB。8卡H100(每卡80GB)总显存640GB,不足以容纳,必须采用模型并行。若升级至H200(141GB显存),8卡总显存1128GB,可完整容纳模型。若采用8-bit Adam等优化技术,显存需求可压缩至500-600GB,8卡H100即可容纳。
4.3 GPU Direct Storage(GDS)系统级适配
GDS实现SSD数据直接写入GPU HBM,绕过CPU/DRAM。传统架构下,NVMe SSD读取数据至CPU DRAM再拷贝至显存,带宽通常卡在CPU内存总线(约10-15GB/s)。采用GDS配合PCIe 5.0 Switch,单节点存储吞吐量可跃升至50GB/s以上,延迟降低约40%。
但GDS对整机设计要求极其严苛:SSD必须与GPU挂载在同一个PCIe Switch拓扑域内。如果跨越了CPU的NUMA节点或UPI/XGMI总线,GDS性能会下降50%以上,几乎失去零拷贝优势。
4.4 系统内存与SSD配比
训练场景:DRAM 2TB+(数据集缓存),SSD 30TB+(checkpoint存储)。推理场景:DRAM 256GB(足够),SSD 8TB(模型权重+日志)。
4.5 Checkpoint存储的整机级设计
大模型训练中,checkpoint周期性保存模型状态,是核心IO瓶颈。以GPT-4级别模型为例,单次checkpoint大小可达数TB。整机层面的优化包括:RAID策略(提升写入带宽)、IO路径优化(绕过CPU直接写入)、缓存联动设计(DRAM作为写入缓存)。
4.6 存储瓶颈分析
HBM带宽 vs GPU算力:H100的3.35TB/s HBM带宽是否匹配989 TFLOPS算力?Byte-to-FLOP比例为3.35TB/s ÷ 989 TFLOPS ≈ 3.4 bytes/FLOP,行业理想值为4 bytes/FLOP,因此HBM带宽仍是GPU算力释放的核心瓶颈。
数据加载:CPU预处理速度 vs GPU消耗速度。若CPU预处理不足,GPU处于"饥饿"状态。
第五章:互连子系统选型
5.1 机柜内互连:铜缆 vs 光模块 vs CPO
机柜内互连的选择取决于距离和信号速率:<3米用无源DAC铜缆(成本低、功耗低);3-10米用AOC有源光缆;>10米用光模块+单模光纤。信号速率从112Gbps/PAM4向224Gbps演进,对信号完整性要求愈发严苛。
CPO技术的整机架构适配不是简单的光模块替换,而是需要重构整机PCB、供电、散热、拓扑设计。CPO将光引擎与交换机芯片封装在一起,减少电信号传输距离,降低功耗。但CPO的核心缺点是可维护性差:光引擎与交换机芯片封装在一起,单个光口故障需更换整个交换机,而非单独更换光模块。
2026年为1.6T CPO商用元年,3.2T CPO预计2028年量产。据产业链调研,中际旭创1.6T CPO光引擎良率已稳定在92%以上,2026年Q2开始批量交付;据厂商公开信息,英伟达已与Lumentum、Coherent各签订20亿美元CPO长单,锁定2026-2028年核心产能。
5.2 机柜间互连:交换机拓扑
胖树(Fat-Tree):经典数据中心拓扑,扩展性好,但核心交换机成本高。Dragonfly+:HPC场景优化,减少核心层交换机数量。全连接(Full Mesh):小规模集群(<128节点),延迟最低但成本高。
5.3 网络协议选择
InfiniBand:低延迟(~600ns)、高吞吐,训练场景首选。NVIDIA收购Mellanox后,IB生态与CUDA深度绑定。RoCEv2:以太网兼容,成本更低,但延迟和稳定性略逊于IB。TCP/IP:仅用于管理网络。
5.4 互连带宽规划与算力-带宽匹配黄金准则
基于Amdahl定律的演进,AI训练集群中通信耗时占比需控制在20%以内为行业及格线,控制在10%以内为优秀水平(工程经验阈值)。单卡H100(989 TFLOPS FP16)需配备至少1个400G或800G网络端口(50-100GB/s单向吞吐),才能避免通信瓶颈。
不同并行策略的通信需求差异巨大:张量并行(TP)极度依赖机内NVLink,对带宽最敏感;流水线并行(PP)对带宽容忍度稍高,但需平衡流水线气泡;数据并行(DP)依赖机间网络,all-reduce通信量大。并行策略的通信需求优先级:张量并行(TP)> 数据并行(DP)> 流水线并行(PP)。因此,张量并行域应尽可能限制在单个NVLink Switch内,避免跨交换机通信。
5.5 网络拥塞的系统级解决方案
整机层面的网络优化包括:ECN(Explicit Congestion Notification)标记、PFC(Priority Flow Control)死锁避免、GPUDirect RDMA协同设计。NVIDIA DGX SuperPOD的核心壁垒不仅是硬件,更是NCCL的拓扑感知优化。NCCL根据实际网络拓扑自动选择最优通信算法,这是第三方厂商难以复制的软实力。
第六章:散热与供电设计
6.1 功耗测算方法论
整机功耗测算需考虑所有部件:GPU(TDP × 数量)、CPU(通常200-300W)、NIC/SSD/风扇等辅助部件(约500W-1kW)、PSU转换损耗(通常5-20%)。整机功耗 =(GPU功耗 + CPU功耗 + 辅助功耗)/ 电源效率。
6.2 训练型服务器功耗案例
DGX H100:10.2kW(8×H100 700W + CPU/辅助/损耗)。GB200 NVL72:120kW(整机柜,18计算节点,每节点4×B200)。功耗密度趋势:从H100的700W → B200的1000W+ → 据厂商公开信息,NVIDIA Rubin预计2026下半年发布、2027上半年量产的1200W+,单机柜功耗突破100kW。
6.3 Power Excursion与动态功耗管理
GPU存在"Power Excursion"(功耗偏移)现象:标称TDP 700W的GPU,在微秒级瞬间可能飙升至1000W以上,持续时间通常为10-100微秒。这种瞬时功耗波动会同时触发供电负载波动和散热流量动态调整。
若供电系统响应速度不足,会导致电压跌落超过5%,触发GPU复位或计算错误。整机动态功耗管理(DPM)系统通过BMC实现CPLD/FPGA级的三方联动:检测到电流激增 → 拉升风扇转速/水泵流量;触及供电红线 → 强制GPU时钟节流(Throttling);持续监控 → 动态调整功耗分配策略。
6.4 散热方案决策树
散热方案的选择取决于单机功耗和部署规模:单机功耗<3kW风冷足够;3-8kW风冷+液冷混合;>8kW必须液冷;整机柜>50kW全液冷(集中CDU供冷)。
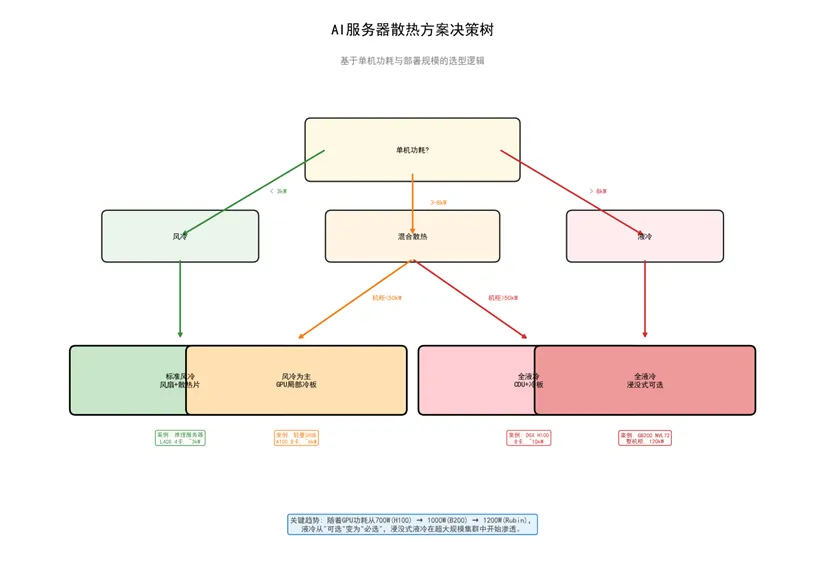
图3:AI服务器散热方案决策树
6.5 液冷系统设计要点
冷板设计:GPU、CPU全覆盖,微通道设计提升换热效率。CDU(Coolant Distribution Unit):流量分配、温度控制、冗余设计。冷却液:去离子水(成本低,需防腐蚀)、氟化液(3M Novec系列浸没式氟化液部分型号停产,冷板式液冷主流的去离子水方案不受影响;浸没式氟化液已有科慕Vertrel、霍尼韦尔Solstice等成熟替代方案,但采购成本较停产前有所上升)。
液冷整机可靠性:漏液检测与断电联动、防腐蚀设计、冗余回路、BMC故障预警。国内头部(浪潮、曙光)在冷板式液冷上已非常成熟,差距主要在底层CDU的精细化流体控制算法上。
6.6 浸没式液冷的整机层面挑战
浸没式液冷将整机浸入冷却液中,散热效率极高,但面临信号完整性挑战。冷却液的介电常数大于空气,会改变高速信号(224G SerDes)的阻抗匹配,导致高频信号衰减。NVIDIA GB200等最新架构官方主推高密度冷板方案,浸没式液冷仅在特定定制化场景有合作落地,未成为行业主流路线。
6.7 供电冗余设计与TCO视角能效优化
N+1冗余:4个PSU坏1个仍能运行。双路供电:市电A/B路切换。UPS:断电保护(15分钟缓冲)。高压直流(HVDC):减少AC-DC转换损耗,整机柜应用前景广阔。PSU负载率与转换效率:通常50-80%负载率效率最高。
从TCO视角,供电能效优化的核心不仅是降低电费,更是确保供电稳定性以避免训练任务中断导致的巨额损失。一次万卡集群训练中断,重启和恢复成本可达数十万美元。
6.8 散热与供电的整机级协同
GPU峰值功耗同时触发供电瞬时负载波动与散热流量动态调整。整机DPM系统需实现供电、散热、GPU算力三方联动,这是系统集成的核心,也是前置散热/电源报告不会覆盖的内容。
第七章:整机集成与测试
7.1 ODM厂商角色
ODM(Original Design Manufacturer)在AI服务器产业链中扮演关键角色:设计(广达、纬创、工业富联根据客户规格书进行整机设计)、制造(SMT贴片、组装、线缆连接、系统烧录)、验证(功能测试、性能基准、可靠性验证)。ODM的核心竞争力正在从"代工制造"向"设计服务"延伸。
7.2 系统集成关键挑战
信号完整性(SI):高速信号(112Gbps/224Gbps PAM4)对PCB走线设计、板材选型、过孔工艺、连接器质量要求极高。SI问题会导致误码率飙升、有效带宽下降,是整机性能不达标的首要原因。
热管理:热点识别、风道/液冷回路优化、动态功耗管理。GPU峰值功耗的瞬态波动要求散热系统具备快速响应能力。
机械结构:GPU重量支撑(单卡约2kg,8卡16kg)、插拔力设计、振动防护、运输可靠性。
7.3 测试验证流程与AI专属测试体系
通用测试流程:ICT(在线测试)电路板短路/开路检测;FCT(功能测试)各部件功能验证;Burn-in(老化测试)高温高负载运行168小时(7天)+,筛选早期失效。高端AI服务器GPU/HBM早期失效概率高,行业通用168小时老化测试,核心节点要求336小时。
AI专属测试体系(整机厂商核心壁垒):性能测试(大模型端到端吞吐量、推理延迟稳定性、分布式集群线性扩展率);可靠性测试(长期高负载下显存错误率、NVLink误码率、故障容错——单卡故障时集群是否能继续运行);调优体系(BIOS参数、NVLink配置、网络协议、通信库的整机级调优)。
测试成本极高:AI整机Burn-in需数天至数周,占用大量设备和人力。测试体系本身的know-how是极高的护城河。
7.4 BMC与AI服务器专属运维
BMC(Baseboard Management Controller)是独立于主系统的带外管理单元。AI服务器的BMC需具备专属功能:GPU实时监控(温度、功耗、显存使用率、计算利用率);显存错误预警(ECC错误计数、软错误率趋势分析);NVLink状态管理(链路健康度、带宽利用率、误码率);液冷系统联动(流量、温度、压力监控,漏液预警);训练任务故障定位(自动识别故障GPU、触发任务迁移、生成诊断报告)。
国产整机与NVIDIA DGX在BMC功能上存在明显差距,主要体现在:无法实现GPU显存错误的提前预警和自动隔离,也不能与NCCL通信库联动进行故障规避。故障诊断的智能化程度和与上层调度系统的联动能力也有显著差距。
第八章:成本拆解与案例分析
8.1 BOM成本拆解(以DGX H100为例)
以下为DGX H100的BOM成本估算(2026年4月批量采购价),实际因配置、批量、时间波动:
核心发现:GPU占BOM成本的72%,仍是绝对的成本中心,但互连成本(含NIC、NVLink Switch、光模块及高速铜缆)已跃升至13-15%,成为第二大成本项。其他所有部件合计约占28%,整机性能高度依赖这些"配角"的协同设计。
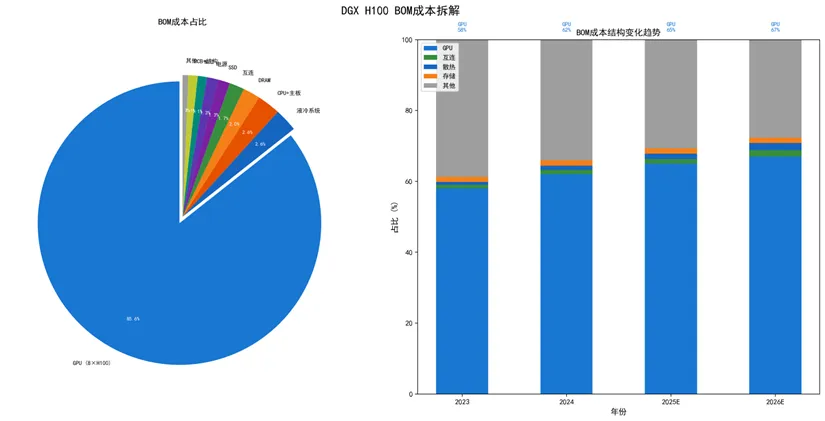
图4:DGX H100 BOM成本拆解与趋势
注:上述BOM结构中,GPU占比约72%,低于早期市场粗略估算的80%+。这并非GPU降价所致,而是互连与散热部件随算力升级价值量快速提升的结果。以互连为例,DGX H100不仅内含4颗NVLink Switch及大量机内高速铜缆,外部集群互联还需标配8个800G光模块,互连相关成本合计占比已达13-15%,从"配角"跃升为第二大成本中心。此外,DGX H100标配2TB系统内存(32×64GB DDR5),以满足大模型数据预处理的高带宽需求。
8.2 从BOM成本到全生命周期TCO
AI服务器的TCO结构与传统通用服务器截然不同:TCO = CapEx_Hardware + OpEx_Power + OpEx_Maintenance + OpEx_Software。硬件CapEx占75-85%(GPU极其昂贵),电费及制冷OpEx占10-15%(绝对值大但占比不高),运维OpEx占5-10%。
液冷的核心经济账不仅是降PUE省电费,更重要的是允许提升机架功率密度(从10kW/柜提升至100kW/柜),从而减少机房租赁面积和跨机柜网络光缆的昂贵开销。以万卡集群为例,机架密度提升10倍意味着机房面积减少90%,这在一线城市数据中心是巨额成本节约。
8.3 不同部署规模的成本优化策略
万卡级超大规模集群:网络拓扑优化(减少核心层交换机)、液冷集中供冷(共享CDU)、批量采购议价(GPU直采)。千卡级中型集群:平衡性能与成本,混合散热方案(关键节点液冷、辅助节点风冷),标准化配置降低运维复杂度。百卡级小型集群:标准化配置,降低运维复杂度,优先考虑交付周期和售后服务。
8.4 整机产品对比
8.5 成本趋势(2023-2026)
互连成本占比加速跃升:随着1.6T光模块、224G高速铜缆以及单机网络端口数量的翻倍(如GB200 NVL72庞大的铜缆背板),集群视角的互连成本(含网卡、Switch、光模块及线缆)占比已从10%向15%甚至更高区间攀升。结构件与供电/散热的基础设施级溢价突显:随着单机柜功耗从10kW飙升至GB200时代的100kW+,配套的液冷CDU(冷量分配单元)、高压直流电源(HVDC)组件、以及为应对Power Excursion(功耗偏移)的瞬态稳压电容,导致整机结构件及机电设备在总BOM中的绝对金额出现数倍增长。高阶DDR5(6400MT/s及以上)的先进制程DRAM产能,被HBM3/HBM4大幅挤占,短期内不存在降价空间;CPU、SSD等标准化部件的绝对金额并未下降,但因GPU与互连成本增速更快,其相对占比被动压缩。
8.6 国产整机进展
华为Atlas 900:昇腾910B集群,端到端训练性能约为同级别H100的40%-45%,集群线性扩展率75%,软件生态(CANN vs CUDA)是最大瓶颈。华为昇腾910B集群实测线性扩展率已达75%,CANN 7.0版本算子覆盖率提升至92%。
浪潮NF5688M7:H100集成方案,受美国出口管制影响,供货不稳定。海光+寒武纪方案:CPU+AI芯片组合,适配挑战大,生态建设初期。信创场景:党政/金融行业对国产化有硬性要求,但性能与稳定性仍需市场验证。
区分"真整机厂商"和"硬件组装厂"的核心指标:是否拥有自主的系统级调优能力和完整的AI专属测试体系。能交付万卡级集群的厂商才有议价权,单机厂商只能赚取5-10%的代工毛利。未来3年,具备整机柜交付能力的ODM厂商将获得更高的市场份额和毛利率。
第九章:国产替代与供应链安全
9.1 整机层面国产替代难点
GPU:昇腾910B vs H100,算力差距+生态差距(CUDA vs CANN)。互连:华为自研HCCS vs NVLink/InfiniBand,生态封闭。软件:从底层通信库到上层框架的全栈替代,迁移成本极高。
9.2 国产替代全栈适配成熟度分级模型
我们将国产替代成熟度分为5个等级,量化行业进度:
华为在CANN上的投入已持续数年,算子覆盖率已提升至92%,但仍与CUDA生态存在显著差距。
9.3 供应链风险地图
9.4 出口管制下的整机架构重构
美国对华AI芯片出口管制持续升级,国内厂商需在整机层面进行架构重构。NVLink受限:用PCIe 5.0替代(128GB/s vs 900GB/s,带宽缩水85%),必须在软件层重构模型切分策略,减小张量并行域,增加流水线并行切分。InfiniBand受限:用RoCEv2替代,延迟和稳定性略有下降,但成本更低。推动开放标准:OAM/UBB等开放互联标准,利用国产自研ASIC互连芯片进行Scale-up补偿。
9.5 整机厂商应对策略
华为路线:CANN软硬协同,闭源全栈(紧耦合)。优势是垂直整合度高、优化深度大;劣势是生态封闭、第三方适配困难。
开放路线:OAM标准下多家ASIC芯片异构组网(浪潮、曙光等)。优势是灵活度高、避免供应商锁定;劣势是碎片化严重、调优难度大。
双轨制设计:同一整机平台同时适配NVIDIA GPU与国产GPU,软件层做统一适配。这是当前国内头部厂商的核心布局,应对供应链波动。
第十章:趋势与展望
10.1 技术趋势
超大规模集群:从8卡→72卡(GB200 NVL72)→万卡集群。液冷普及:从可选→必选。GPU功耗从700W(H100)→1000W+(B200)→1200W+(NVIDIA Rubin),风冷已触及物理极限。
CPO渗透:2026年为1.6T CPO商用元年,3.2T CPO预计2028年量产。光模块向共封装光学演进。
存算一体:HBM带宽瓶颈催生新架构。AI算力资源池化与解耦:计算/存储/网络资源的池化重构,是云厂商未来3-5年的核心布局。整机柜交付:从单机交付到整机柜交付,产业链全面重构。
10.2 绿色AI对整机架构的硬性要求
双碳政策下,数据中心PUE限制趋严。中国新建大型数据中心PUE需低于1.3,这要求整机架构在能效优化上持续突破。液冷余热回收、AI驱动的动态功耗管理、高压直流供电等技术将成为准入门槛。
10.3 市场趋势
训练市场:增速放缓,但单集群规模增大。头部大模型厂商的训练需求趋于饱和,新增需求来自中型模型和垂直领域。推理市场:爆发增长,边缘部署兴起。随着大模型应用落地,推理算力需求呈指数级增长。国产替代:政策驱动+市场验证并行。
10.4 整机厂商格局演变
NVIDIA:从卖芯片到卖系统(DGX→GB200),从单机到整机柜,毛利率持续提升。云厂商:自研ASIC+定制服务器(Google TPU、AWS Trainium、微软Maia),降低对NVIDIA的依赖。ODM:从代工向设计服务延伸,具备系统级设计能力的ODM获得高附加值订单。国产厂商:华为(全栈自研,紧耦合)vs 浪潮/曙光(开放解耦,多厂商适配)两条路线并行。
第十一章:风险提示
11.1 技术风险
功耗墙:单芯片功耗逼近物理极限(B200 1000W+,NVIDIA Rubin 1200W+),散热和供电面临根本性挑战。散热极限:液冷也面临CDU容量和冷却液供应限制。3M部分Novec型号停产后,替代方案的可靠性仍需验证,冷却液成本上升风险。特定ASIC芯片流片失败风险:自研ASIC投入巨大,流片失败可能导致数亿美元损失。
11.2 供应链风险
地缘政治:美国出口管制持续升级,H20等阉割版芯片也可能受限。产能瓶颈:台积电CoWoS先进封装产能紧张,HBM供应受SK海力士/三星/美光垄断。关键材料:冷却液(部分型号停产,成本上升)、高纯铜、高端PCB板材等存在断供风险。海外底层技术专利诉讼风险:NVIDIA在GPU架构、互联技术、软件生态上拥有大量专利。
11.3 市场风险
大模型训练需求增速不及预期、头部厂商训练集群利用率不足:大模型训练投资是否过度?头部厂商的训练集群利用率是否充足?推理价格战:云厂商推理服务降价压缩硬件利润。技术路线突变:量子计算、神经形态芯片、光子计算等颠覆性技术可能改变AI算力格局。
11.4 政策与合规风险
国内信创政策、数据安全法对国产化的硬性要求,可能影响采购决策和供应链布局。海外出口管制、AI监管政策(如欧盟AI法案)对算力需求与供应链的影响。
附录
附录A:术语表 PAM4:四电平脉冲幅度调制,高速信号编码技术。CoWoS:Chip on Wafer on Substrate,台积电2.5D封装技术。TSV:Through-Silicon Via,硅通孔技术。NUMA:Non-Uniform Memory Access,非统一内存访问。UPI/XGMI:Intel Ultra Path Interconnect / AMD Infinity Fabric,CPU互连总线。OSFP:Octal Small Form-factor Pluggable,800G光模块封装。TP/PP/DP:Tensor Parallelism / Pipeline Parallelism / Data Parallelism,大模型分布式训练并行策略。RoCEv2:RDMA over Converged Ethernet version 2,基于以太网的远程直接内存访问。InfiniBand:高性能计算网络协议。ECC:Error-Correcting Code,显存纠错码。BER:Bit Error Rate,误码率。BOM:Bill of Materials,物料清单。
DGX:NVIDIA推出的AI服务器整机品牌。GB200:NVIDIA Blackwell架构的GPU集群版本。NVL72:NVIDIA GB200的整机柜配置,72颗GPU。BMC:Baseboard Management Controller,带外管理控制器。CDU:Coolant Distribution Unit,液冷系统的冷量分配单元。PSU:Power Supply Unit,电源供应单元。PDU:Power Distribution Unit,电源分配单元。GDS:GPU Direct Storage,GPU直接存储技术。OAM:OCP Accelerator Module,开放计算项目加速器模块标准。UBB:Universal Baseboard,通用基板标准。NCCL:NVIDIA Collective Communications Library,集合通信库。PUE:Power Usage Effectiveness,数据中心能源效率指标。SI:Signal Integrity,信号完整性。BER:Bit Error Rate,误码率。TDP:Thermal Design Power,热设计功耗。
附录B:参考标准
MLPerf Training/Inference:AI训练/推理性能基准测试。SPEC CPU/GPU:通用计算性能基准测试。OCP(Open Compute Project):开放计算项目规范。PCIe 5.0/6.0:外围组件互连标准。NVLink 4.0/5.0:NVIDIA GPU互联标准。
附录C:数据来源
各零部件报告的数据来源汇总(GPU/ASIC/存储/铜缆/CPO/交换机/液冷/电源/PCB)。NVIDIA官方规格书(DGX H100/B200/GB200 NVL72)。华为Atlas技术白皮书。浪潮、曙光产品规格书。行业研究机构:IDC、Gartner、TrendForce、Yole Développement。学术论文:MLPerf基准测试论文、SIGCOMM/ISCA会议论文。
附录D:AI服务器整机选型决策Checklist
【配置匹配】GPU数量/型号是否匹配模型规模和任务类型?显存容量是否满足模型参数+优化器状态需求?CPU核数是否充足(预处理密集型场景需64核+)?系统内存容量是否匹配数据集大小?SSD容量是否满足checkpoint存储需求?互连带宽是否匹配GPU算力(训练迭代中通信耗时占比<20%及格,<10%为优秀)?散热方案是否匹配整机功耗(>8kW需液冷)?供电冗余是否满足可靠性要求(N+1)?
【性能测试】MLPerf训练吞吐量是否达到预期?推理延迟稳定性是否满足SLA(99th percentile)?分布式集群线性扩展率是否>80%(行业及格线),优秀水平>85%,NVIDIA DGX SuperPOD可达90%以上?单卡故障时集群是否能继续运行?
【可靠性验证】Burn-in测试时长是否>168小时?显存错误率(ECC)是否在可接受范围?NVLink无纠错前(Pre-FEC)误码率(BER)是否<1e-15?液冷系统漏液检测是否可靠?BMC远程运维功能是否完善?
【成本核算】BOM成本中GPU占比是否合理(60-85%)?3年TCO是否包含电费、运维、软件授权?液冷系统的TCO优势是否充分考虑(密度提升)?国产替代方案的全栈适配成本是否评估?
5.1.1 PCIe拓扑与P2P通信设计
机内GPU通信的核心底层设计是PCIe拓扑与P2P(Peer-to-Peer)通信架构,工程实践中有三大核心准则:
准则一:同PCIe Switch域内的GPU P2P通信延迟<1μs,带宽可跑满PCIe 5.0线速;跨CPU NUMA(Non-Uniform Memory Access,非统一内存访问)节点的GPU P2P通信,需经过UPI/XGMI总线,延迟飙升至10μs以上,带宽下降60%以上。
准则二:无NVLink配置的8卡GPU整机,最优PCIe拓扑为「双PCIe Switch全互联架构」,每4卡GPU挂载至一个PCIe Switch,双Switch通过x16 PCIe 5.0链路互联,同时分别挂载至双路CPU的NUMA节点,实现跨节点通信带宽最大化。
准则三:PCIe Switch的DMA(Direct Memory Access,直接内存访问)引擎配置、ATS/PRI(Address Translation Service/Page Request Interface,地址翻译服务/页面请求接口)地址翻译服务,直接决定GPUDirect RDMA与GDS的性能发挥,配置不当会导致零拷贝优势完全丧失。
基于BSP(Bulk Synchronous Parallel,批量同步并行)模型,AI训练集群的并行效率计算公式为:
并行效率 = (单卡迭代耗时 / 多卡迭代耗时)/ 卡数 × 100%(即加速比/卡数,MLPerf通用标准)
其中,通信耗时由all-reduce数据量、网络带宽、并行策略共同决定。以8卡H100集群为例,若单卡迭代时间100ms,通信耗时40ms,则并行效率为71.4%;若通过拓扑优化将通信耗时降至10ms,并行效率可提升至90.9%,这就是整机系统设计对集群性能的核心影响。
5.5.1 GPUDirect RDMA系统级设计要求
GPUDirect RDMA(Remote Direct Memory Access,远程直接内存访问)实现了GPU显存与远端NIC(Network Interface Card,网络接口卡)的直接数据读写,绕过CPU/DRAM,可将机间通信延迟降低40%以上,带宽利用率提升30%以上。
其对整机设计的核心要求为:
要求一:NIC必须与GPU挂载在同一个PCIe Switch域内,避免跨NUMA节点传输。
要求二:主板必须支持PCIe ATS/PRI地址翻译服务,实现虚拟地址的直接映射。
要求三:系统固件(BIOS/UEFI)必须开启IOMMU(Input-Output Memory Management Unit,输入输出内存管理单元)虚拟化功能,同时在操作系统内配置对应的内存锁定权限,否则会导致RDMA功能无法启用。
7.2.1 RAS特性设计
RAS(Reliability, Availability, Serviceability,可靠性、可用性、可服务性)是AI服务器整机设计的核心准入门槛,也是区分消费级硬件与数据中心级整机的核心标志。
可靠性:GPU显存ECC(Error-Correcting Code,纠错码)纠错、PCIe链路CRC(Cyclic Redundancy Check,循环冗余校验)重试、NVLink/IB链路误码率实时监控与故障隔离、内存故障预警与离线修复。
可用性:整机部件热插拔(SSD/PSU/NIC)、GPU故障隔离与训练任务无感迁移、双路冗余设计的故障切换时间<1ms。
可服务性:BMC带外全链路故障诊断、部件FRU(Field Replaceable Unit,现场可更换单元)信息可追溯、远程固件升级与配置批量下发。
国产整机与NVIDIA DGX的核心差距之一,就是RAS特性的工程化落地能力不足,导致大规模集群的年平均可用性低于99.99%,无法满足超大规模训练的SLA(Service Level Agreement,服务等级协议)要求。
8.1.1 白牌整机vs品牌整机BOM对标
国内8卡H100白牌整机BOM成本拆解(2026年4月批量采购价):
核心差异:白牌整机无品牌与软件溢价,整机售价约28-30万美元,较DGX H100低10%以上,但无原厂NCCL调优与软硬件协同支持,实测性能较DGX低5-15%。
8.2.1 万卡级集群3年TCO量化测算模型(注:按1美元=7.2人民币汇率测算)
以一线城市数据中心、10240卡H100集群、3年运营周期为例,基于以下假设的全生命周期TCO量化测算:
假设条件:GPU型号为H100(批量采购价$25K/卡),网络为400G InfiniBand,数据中心PUE 1.25(一线城市核心地段万卡集群综合值),电价0.65元/度,年运行时长8760小时,液冷整机柜功率密度100kW/柜。注:若为偏远地区数据中心,机房租赁成本显著下降,液冷TCO回本周期可能拉长至4年以上。
核心测算结论:液冷方案带来的机房租赁成本节约,3年周期内远超其额外的硬件投入,这是液冷技术规模化普及的核心商业逻辑。
9.2.1 国产整机性能量化对标
据行业第三方测试数据,国产整机与NVIDIA DGX的性能量化对比如下(实测场景为Llama-3 70B模型FP16训练):
注:数据为2026年Q1行业第三方测试结果,华为昇腾910B已公开参与MLPerf Training官方跑分,端到端训练性能约为同级别H100的40%。
10.1.1 整机柜交付的行业标准与产业格局
整机柜交付的三大主流行业标准,决定了未来产业格局:
OCP OpenRack V3标准:北美云厂商(Meta/微软/谷歌)主导,开放解耦架构,液冷整机柜的主流国际标准。
ODCC天蝎4.0标准:国内三大运营商、阿里云/腾讯云主导,国内液冷整机柜的核心行业规范。
NVIDIA NVLink机柜标准:闭源紧耦合架构,仅适配NVIDIA GB200/Rubin平台,锁定客户生态。
产业趋势:具备开放标准整机柜设计能力的ODM厂商,将获得云厂商的核心订单,而仅能做单机集成的厂商,市场份额将持续萎缩。