


2026
4/21
TextIn.com
TextIn
—— 专注智能文字识别19年 ——
1. 引言:为什么选择TextIn与Coze搭建财报机器人?
面对季度、年度财报堆叠如山的PDF文档,技术团队如何快速、准确地将其中复杂的表格数据转化为结构化信息?本文将介绍一种高效实践方案:利用TextIn的智能文档解析能力,结合Coze的自动化工作流编排,快速构建一个能够处理多格式财报、抽取关键表格的自动化流程。
1.1 财报文档的典型难点
财报处理长期存在几大核心难点:
1. 表格结构复杂: 资产负债表、利润表等核心表格常存在跨页、续表情况,且合并报表与母公司报表两套体系并存,单元格合并频繁,对程序的结构化识别构成首要挑战。
2. 文档格式多样: 资料库中通常是电子PDF与扫描件图像混合共存,要求解决方案同时具备强大的文本解析与OCR版面分析能力。
3. 手工处理成本高昂: 三大表及附注的手动复制、粘贴、核对工作极其耗时,且容易出错,难以满足及时性、准确性要求。
1.2 TextIn+Coze方案的核心价值
本方案采用清晰的分工架构,将复杂问题模块化:
TextIn xParse引擎负责“读懂”文档: 其强大的版面分析与表格识别技术,能统一处理电子PDF与扫描件,将混乱的原始文档转换为包含完整表格结构、段落标题的清晰JSON数据,为下游提取提供高质量的结构化输入。
Coze工作流负责“串联”自动化流程: 可自动化编排“文件上传→调用TextIn解析→定位并抽取目标表格→输出至数据库/Excel”的完整管道。
Coze Bot 提供交互层: 可构建一个对话机器人,不仅支持触发自动化流程,更能基于抽取出的数据,提供报表摘要、关键指标对比、甚至问答解释,让数据结果可直接被业务人员使用。
这种组合将专业的文档解析、灵活的业务逻辑编排与友好的交互界面相结合,使开发者能聚焦于核心的抽取规则,快速搭建从原始文档到业务可用数据的端到端流水线。
2. 方案应用速览
财报机器人使用演示:
工作流: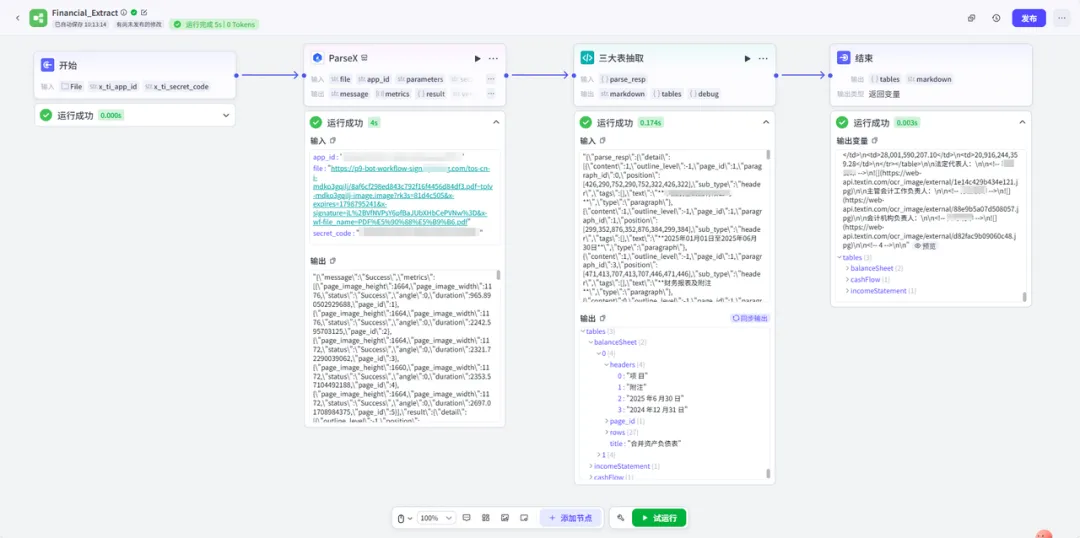
输出结果:
3. 架构设计
3.1 总体链路
用户上传财报 → Coze触发工作流 → xParse → 代码节点抽取 → 输出结构化tables
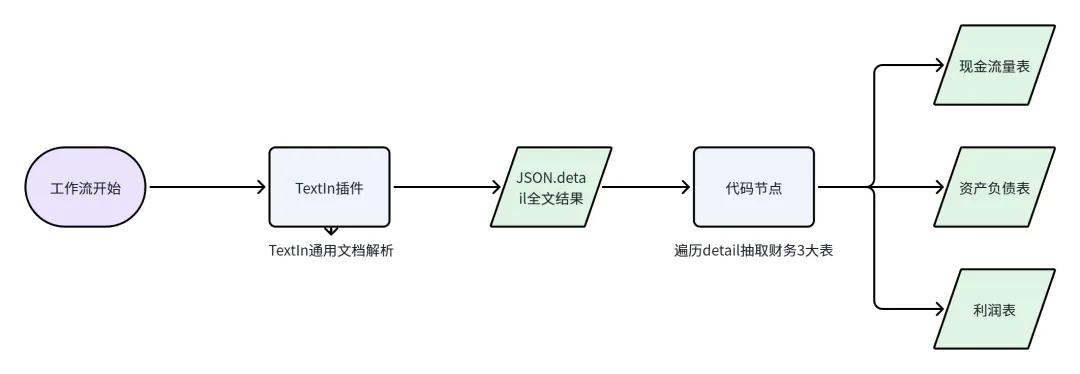
开始节点: 接收用户上传的财报文件(File)。
TextIn插件节点: 将财报解析为结构化JSON,核心使用
result.detail(包含paragraph/table/image等元素)以及result.markdown。代码节点: 仅遍历
detail,通过“表标题 → 后续表格”方式抽取三大表,并统一输出为tables{balanceSheet,incomeStatement,cashFlow}。结束节点: 将
tables / debug / markdown输出给Bot,用于展示与后续问答分析。
3.2 数据结构约定
TextIn xParse - 插件节点的输出(result.detail / result.markdown等,详情见TextIn xParse API文档:https://docs.textin.com/xparse/parse-getjson)
Response├─ code # 接口状态码├─ message # 状态信息└─ result ├─ markdown # 文档级 Markdown └─ detail[] # 元素明细数组(只处理 type=table) └─ (仅当 item.type == "table" 时关注) ├─ type# 固定为 "table"(表格块) ├─ sub_type # "bordered"(有线) / "borderless"(无线) ├─ page_id # 表格所在页(续表拼接用) ├─ paragraph_id # 表格元素ID(续表拼接用) ├─ rows # 表格行数 ├─ cols # 表格列数 ├─ text # 表格整体文本(md/html;展示用,抽字段优先 cells) ├─ continue? # 是否跨页/跨段续表(可选字段) └─ cells[] # 单元格数组(抽取字段核心) ├─ row # 行号(从0开始) ├─ col # 列号(从0开始) ├─ row_span? # 行合并跨度(默认1) ├─ col_span? # 列合并跨度(默认1) └─ text # 单元格文本(字段值通常从这里拿)?TextIn的返回结果中对表格块(type=table)的两种常见数据形态(务必兼容)
形态 A:HTML/Markdown 表格(最常见于工作流插件输出) item.type == "table"item.text内包含<table>...</table>(或Markdown table)抽取方式: 解析 text→ 转二维矩阵(headers/rows)形态 B:单元格数组cells(部分接口/参数下提供) item.cells[]存在,包含row/col/text等抽取方式:优先用 cells拼matrix(更结构化),不存在再回退到解析text
财务三大表抽取 - 代码节点的输出示例(tables)
tables.balanceSheet / incomeStatement / cashFlow均为数组,设计理由如下:
同一份财报可能包含“合并 + 母公司”两套表; 或者出现“(续)”导致一张表被拆成多段; 因此用数组承载多张/多段表更稳妥,业务侧可按 title/page_id再做合并与筛选。
tables
{"balanceSheet": [ {"headers": ["项 目","附注","2025 年6 月30 日","2024 年12 月31 日" ],"page_id": [ 2 ],"rows": [ ["流动资产:","","-","-" ], ],"title": "合并资产负债表" }, ],"incomeStatement": [ {"headers": ["项 目","附注","2025 年1-6 月","2024 年1-6 月" ],"page_id": [ 4 ],"rows": [ ["一、营业总收入","","88,095,798,091.41","85,336,441,428.97" ], ],"title": "母公司利润表" } ],"cashFlow": [ {"headers": ["项 目","附注","2025 年1-6 月","2024 年1-6 月" ],"page_id": [ 5 ],"rows": [ ["一、经营活动产生的现金流量;","","-","-" ], ],"title": "母公司现金流量表" } ]}Debug
"debug": {"detailLen": 823,"titleCandidates": 6,"hitTitles": [ {"idx": 120, "page_id": 2, "title": "合并资产负债表"}, {"idx": 260, "page_id": 4, "title": "母公司利润表"} ],"picked": [ {"titleIdx": 120, "tableIdx": 125, "tableType": "balanceSheet"}, {"titleIdx": 260, "tableIdx": 268, "tableType": "incomeStatement"} ],"tableBlocks": 12}3.3 关键设计点(财报专属)
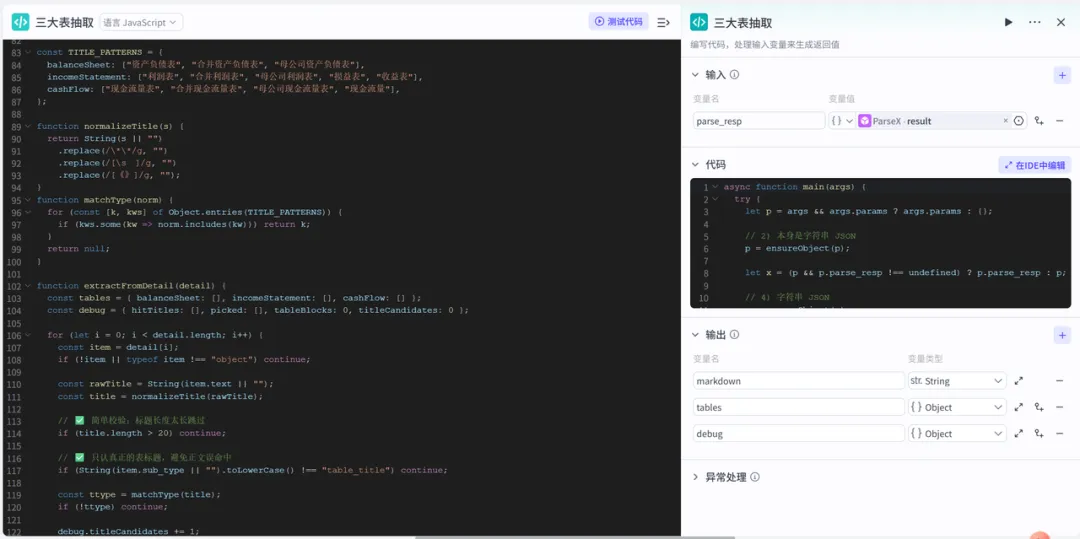
标题命中策略(table_title + 关键词)
标题长度阈值(>20 跳过): 避免长文档中出现“包含关键词的长句”被误判为表标题,从而误抽无关表格。 只认 sub_type=table_title:优先使用版面分析识别到的“表格标题”元素,减少正文段落(header/text)误命中概率。
const TITLE_PATTERNS = { balanceSheet: ["资产负债表", "合并资产负债表", "母公司资产负债表"], incomeStatement: ["利润表", "合并利润表", "母公司利润表", "损益表", "收益表"], cashFlow: ["现金流量表", "合并现金流量表", "母公司现金流量表", "现金流量"],};function normalizeTitle(s) {return String(s || "") .replace(/\*\*/g, "") .replace(/[\s ]/g, "") .replace(/[《》]/g, "");}function matchType(norm) {for (const [k, kws] of Object.entries(TITLE_PATTERNS)) {if (kws.some(kw => norm.includes(kw))) return k; }return null;}function extractFromDetail(detail) { const tables = { balanceSheet: [], incomeStatement: [], cashFlow: [] }; const debug = { hitTitles: [], picked: [], tableBlocks: 0, titleCandidates: 0 };for (let i = 0; i < detail.length; i++) { const item = detail[i];if (!item || typeof item !== "object") continue; const rawTitle = String(item.text || ""); const title = normalizeTitle(rawTitle); // ✅ 简单校验:标题长度太长跳过if (title.length > 20) continue; // ✅ 查询TextIn接口返回数据中的表格标题,避免正文误命中if (String(item.sub_type || "").toLowerCase() !== "table_title") continue; const ttype = matchType(title);if (!ttype) continue;4. 准备工作
TextIn 开发者信息(x-ti-app-id / secret_code)
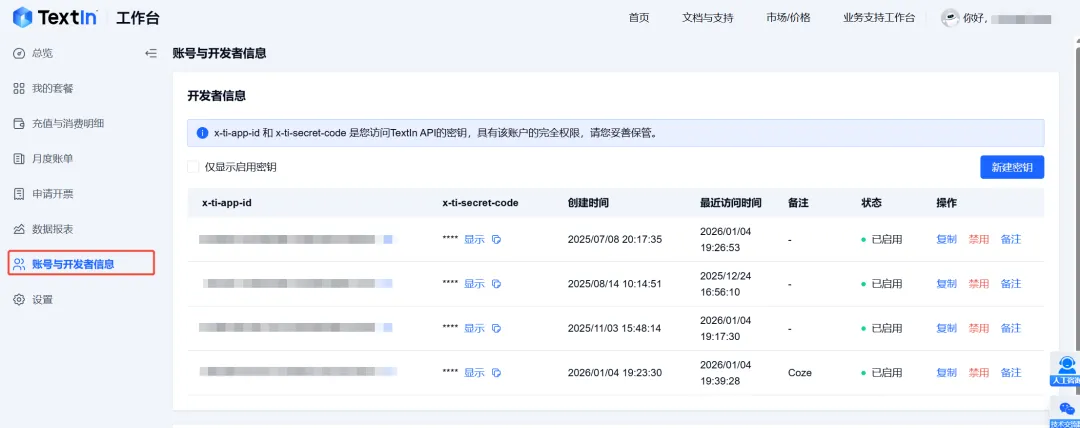
在TextIn控制台(https://www.textin.com/)「开发者信息」中获取 x-ti-app-id与x-ti-secret-code(下文统称 app_id/secret_code)。建议在Coze工作流里把鉴权参数作为开始节点输入传入(便于不同环境切换),或在团队内部用变量/密钥管理统一配置。
5. 工作流搭建
5.1 创建工作流
工作流命名、描述、版本说明 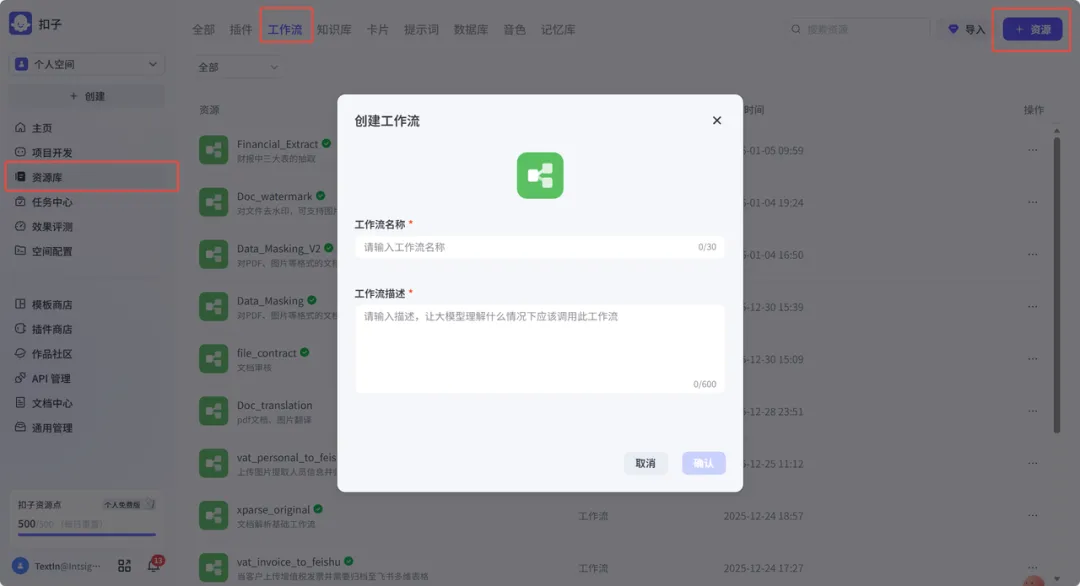
5.2 开始节点配置
Input类型:File(接收上传文件)
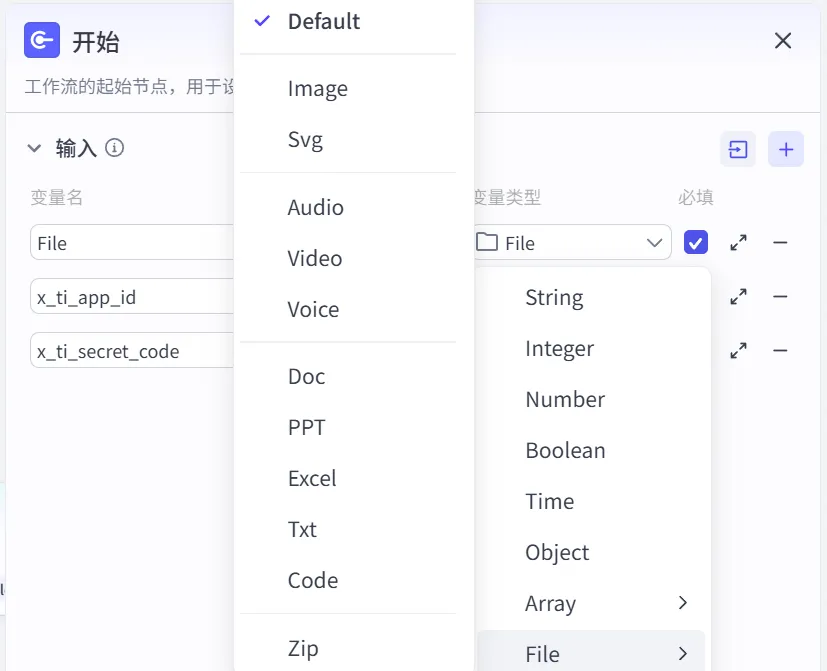
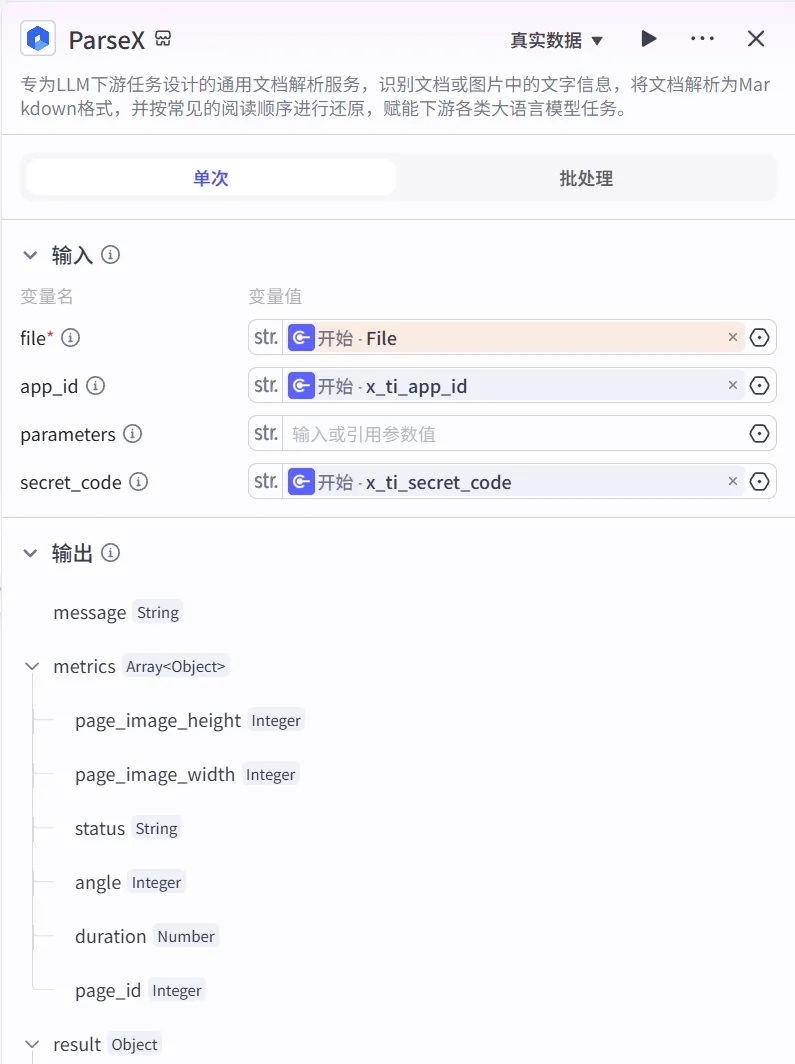
5.3 添加 xParse插件节点
输入映射:file → Input.file 鉴权配置:x_ti_app_id / x_ti_secret_code 输出字段说明:result.detail / result.markdown 等,输出重点使用: ParseX.result(作为代码节点输入),其中result.detail是抽表主数据源。
5.4 添加代码节点(核心)
输入变量配置 (选择
ParseX.result)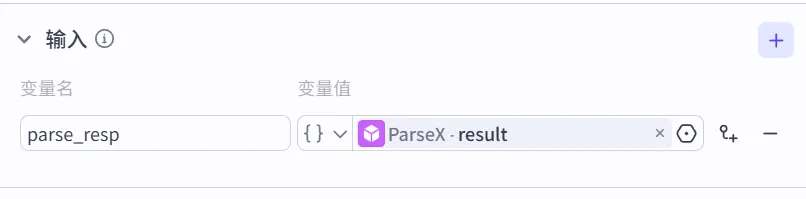
代码职责:遍历detail→找table_title→找后续table→HTML转二维矩阵→输出 tables(代码节点源码附在文章最末尾)
输出结构:
tables{balanceSheet,incomeStatement,cashFlow}+debug
5.5 结束节点输出
输出给Agent:tables / markdown / debug
6. 不止于抽取:更多自动化扩展方向
财报抽取机器人是一个高效的起点,接下来,基于TextIn提供的精准结构化数据与Coze灵活的工作流,还可以轻松延伸出更多智能化的数据处理能力:
续表自动合并: 财报中经常存在大型表格跨页,可在工作流中添加逻辑节点,按 title相同且表头一致合并 rows,并合并page_id,彻底解决数据割裂问题。表内锚点词校验: 为确保抽取表格的完整性与正确性,可设计自动校验规则。例如,检查资产负债表中是否同时存在“流动资产”/“资产总计”科目;验证利润表是否包含“营业收入”/“净利润”;确认现金流量表是否包含“经营活动”。这一步能有效拦截因解析页面错误或文档版本差异导致的重大数据缺失。 结构化导出至Excel: 将最终整理的 tables列表,通过添加代码节点或Coze插件,转换为更通用的CSV或XLSX格式文件。这能让财务、业务部门的同事无缝接手,直接在Excel环境中进行后续分析与可视化。实现智能多期对比: 将工作流升级为可接收两份财报,分别提取后,系统能根据标准化的会计科目名称自动对齐数据,计算关键项目的同比、环比变化,并可由集成的LLM输出差异分析简报。
通过TextIn与Coze的组合,我们完成了从杂乱文档到结构化数据,再到可交互、可扩展的业务工具的完整路径,构建了一个可靠、可重复、且持续进化的数据流水线。无论是应对合规检查,还是满足定期的经营分析,这个财报机器人都能成为你技术工具箱中一个反应迅速、值得信赖的数字化助手。
现在,是时候告别手动处理的繁琐与不确定,让你的数据工作流真正“智能”起来。
7. 附:代码节点源码
下载链接:https://dllf.textin.com/download/2026/CustomService/财报提取-coze代码节点源码.js