



AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
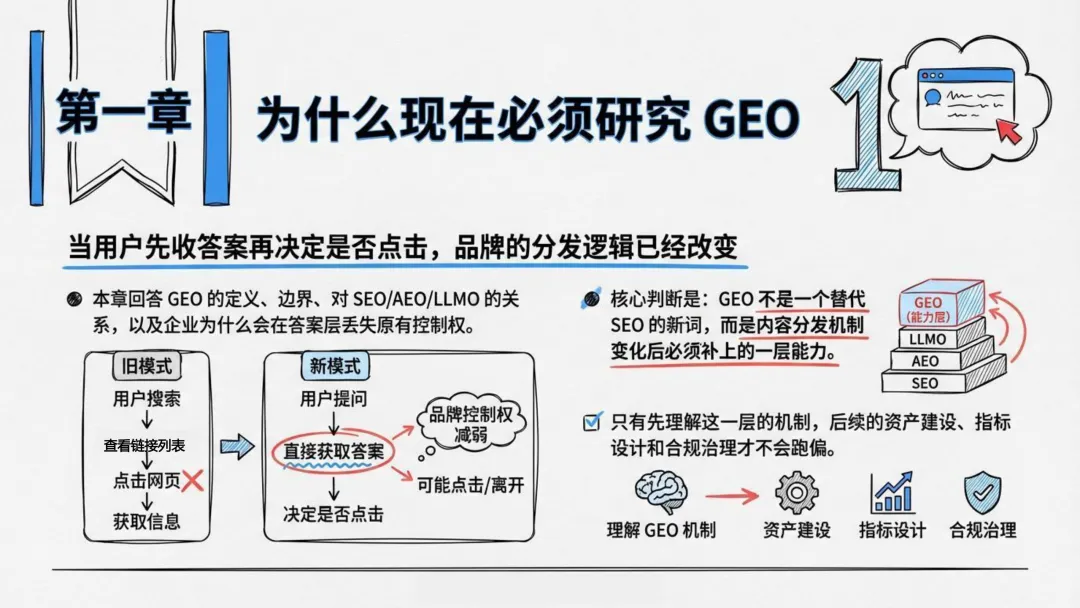
过去二十年,企业的数字营销只有一个执念:排在前面。只要在搜索结果页占据前三,流量、线索、交易似乎就水到渠成。
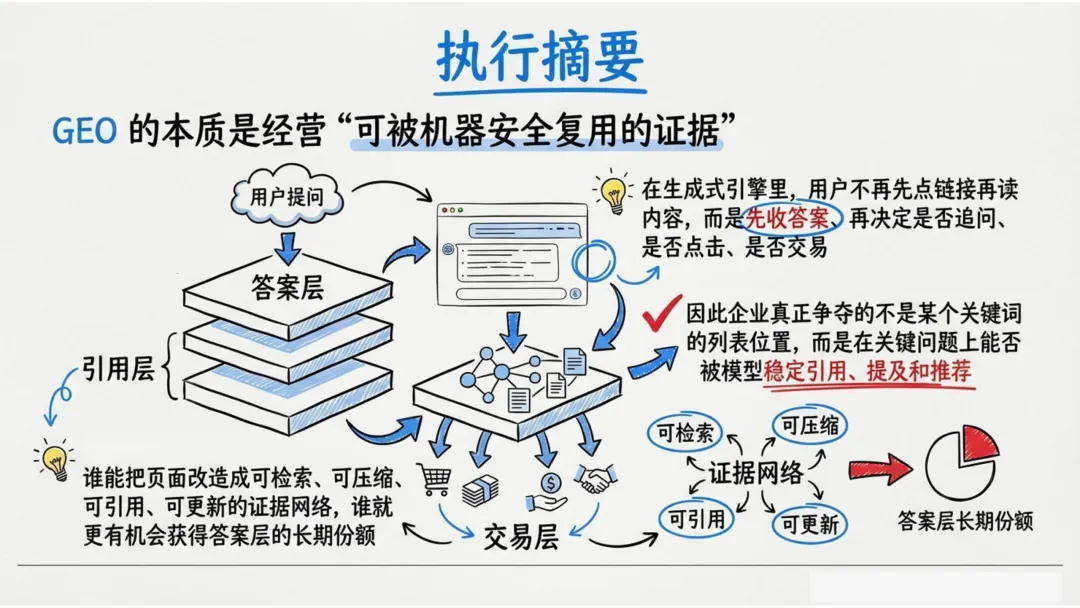
但今天,用户的行为变了。越来越多的人不再逐条点击蓝色链接,而是直接看生成式AI给出的那一段答案——一个完整的句子、一段总结、一个对比表格,甚至一句“推荐你选X”。
这意味着什么?如果你的品牌没有出现在那段答案的正文里,用户可能根本不知道你的存在。
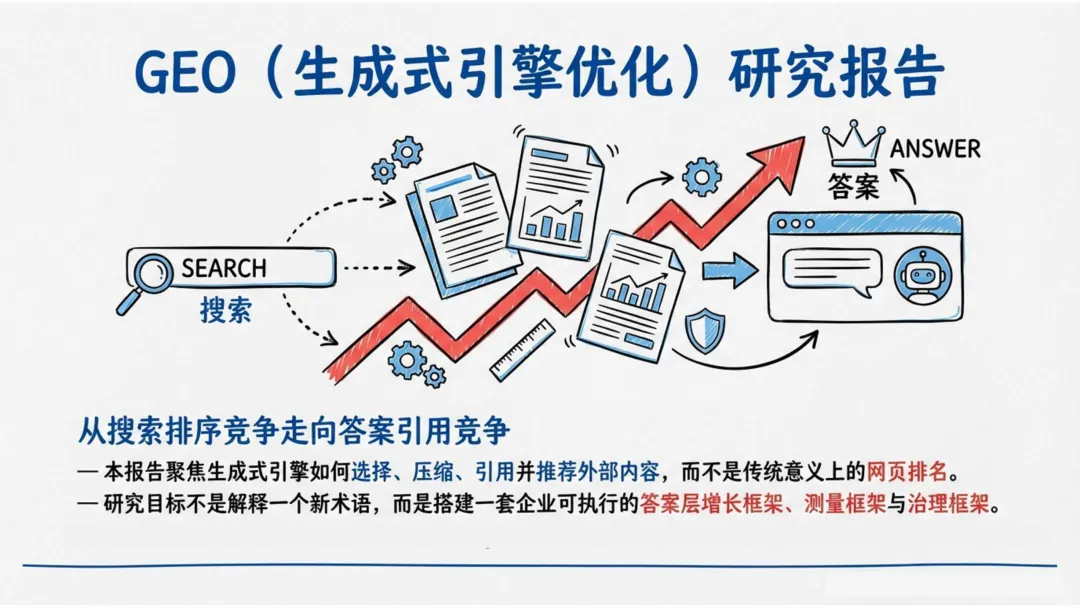
这正是清华大学团队联合智灵动力发布的《生成式引擎优化研究报告》要回答的核心命题:在生成式AI主导的分发时代,企业的竞争不再是“链接排名”,而是“答案存在”。
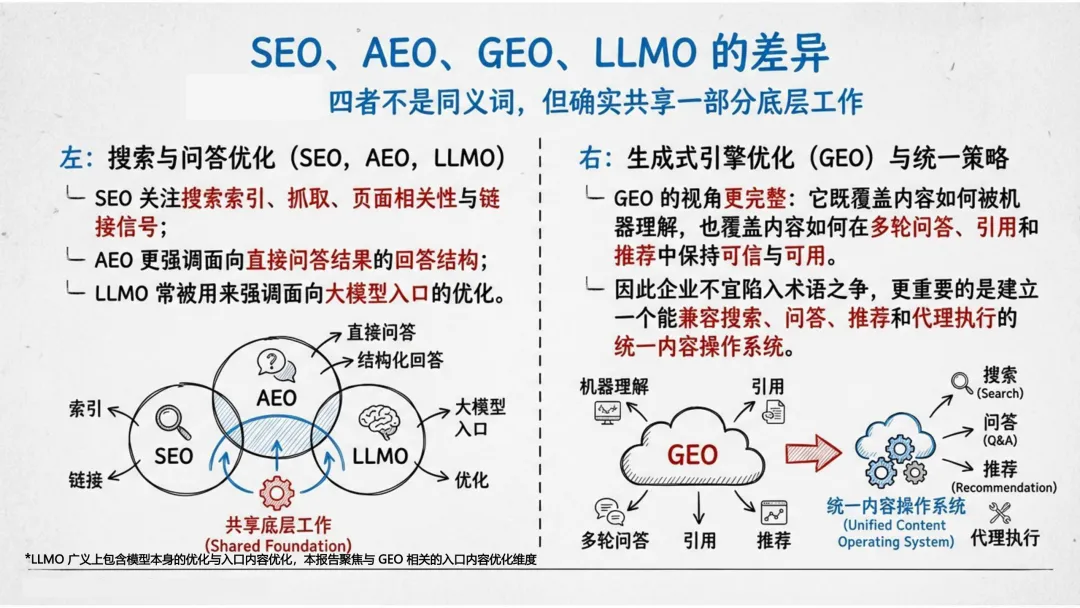
一、从“被搜索”到“被引用”:胜负手已经位移
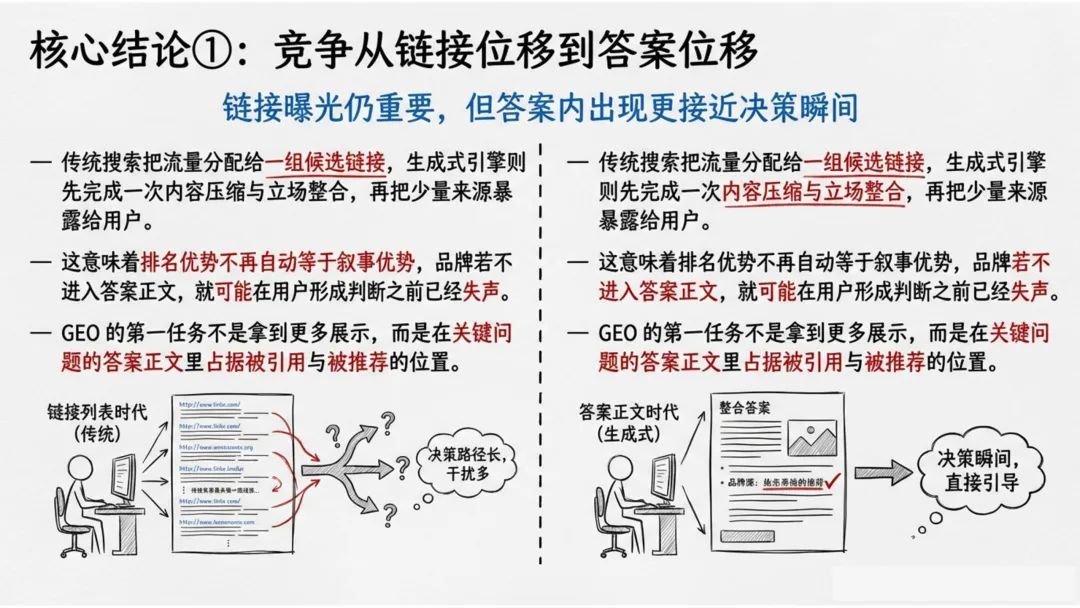
报告提出了一个极具冲击力的判断:排名优势不再自动等于叙事优势。
传统SEO解决的是“能不能被找到”,而GEO解决的是“能不能被模型选中、压缩、并写进答案里”。生成式引擎的工作方式不是展示一组链接,而是先完成一次内容压缩与立场整合,再把少量来源暴露给用户。
如果你只是排在搜索结果前列,但你的内容没有被模型抽出来放进答案正文,那用户很可能根本不会点开你。
GEO的第一任务,不是拿到更多展示,而是在关键问题的答案正文里占据被引用、被提及、被推荐的位置。
报告用三个层次区分了商业价值:
被引用:你的页面承担事实证据角色
被提及:品牌进入模型的叙事
被推荐:模型替你做了筛选和背书
这三者不会自然重合。企业需要针对不同的问题类型,设计不同层次的证据结构。
二、为什么现在是GEO的窗口期?
报告用多组数据证明:这不是一个遥远的概念,而是一个正在打开的市场窗口。
第一,数字基础设施已经足够普及。美国家庭电脑拥有率达95.5%,宽带订阅率91.0%。这意味着问答式决策不是少数人的习惯,而是主流行为。
第二,企业级AI使用率仍然很低。2023年的数据表明,绝大多数企业还没有系统性地利用AI。这意味着竞争格局尚未固化,先入场者有机会建立优势。
第三,反垄断正在打破传统分发垄断。美国司法部在2025年的搜索案与数字广告案中,明确指向Google对开放网络的垄断。搜索、广告、答案之间的利益平衡正在重构。
结论很直接:分发结构正在重置,品牌现在不占位,以后就没有位子可占。
三、模型怎么选内容?四层因果链决定你的去留
报告把生成式引擎使用外部内容的过程拆成了四层,每一层都是一道过滤器。
第一层:检索内容必须可被抓取、结构清晰、实体明确。如果连候选集都进不去,后面一切免谈。GEO并不否定基础SEO,而是把它升级为“让证据页稳定进入候选集”的前置工程。
第二层:合成模型不会搬运整页内容,而是抽取高密度、低歧义、可直接复述的语义块。报告提出了一个关键概念——语义压缩率:模型压缩后还能保留多少核心结论。高压缩率的页面,即使被缩写也不会失真;低压缩率的页面,剩下一堆空话。
第三层:引用模型更偏好出处清晰、事实闭环的材料。被引用不是运气,而是你的内容在安全性和可核查性上的综合结果。
第四层:交互在多轮问答中,模型会持续调用同一信源的证据。所以,只写“我们很好”是不够的,你需要覆盖“是什么—为什么—怎么选—不适合谁—替代方案”的完整证据链。
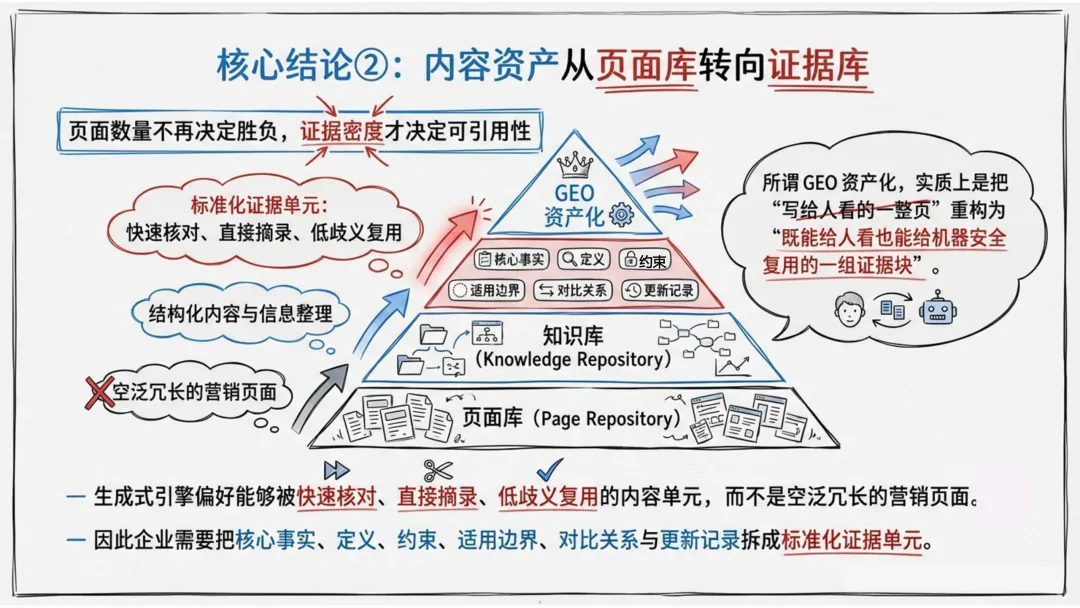
四、企业该做什么?从“展示册”转向“证据库”
报告批评了一个普遍现象:很多企业把官网当成展示册,堆满结论性口号,却缺少定义、边界、对比、案例与可核查的数据。而模型偏偏需要的是后者。
GEO的资产单位,不再是“一篇文章”,而是一组可被检索、拼接、引用和更新的证据组件。
具体来说,企业应优先建设以下几类资产:
事实表:把核心数据做成结构化数据卡,让模型能直接调用,而不是在长文里翻找。
对比页:讲清你和替代方案的适用场景、成本、风险,而不是只喊“我们最好”。
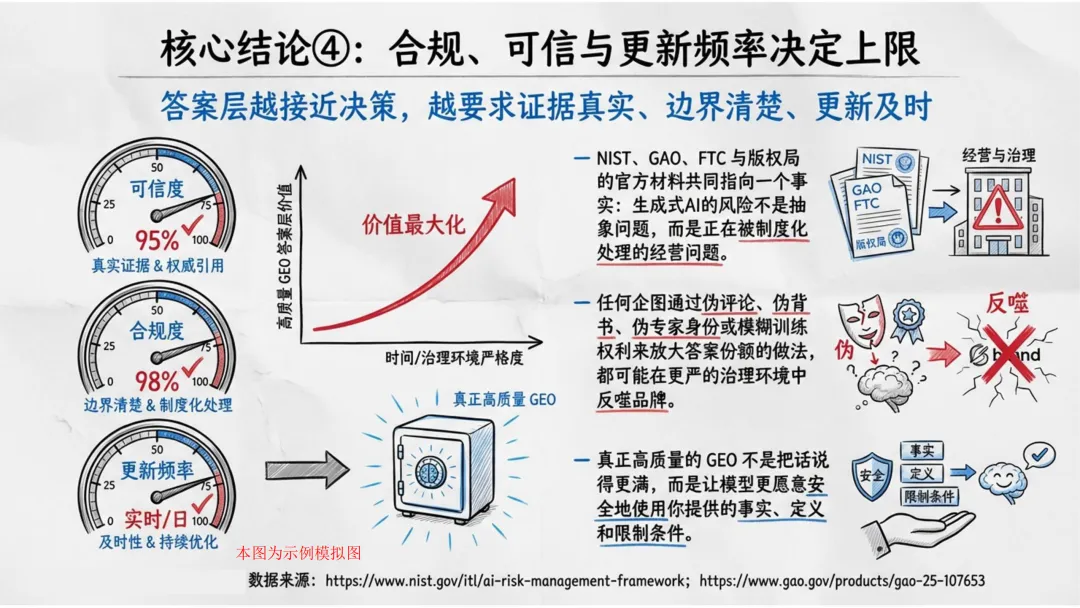
约束与边界页:敢于写清楚“不适合谁、什么条件下不能用”。报告指出,越敢写清不适用情形,越可能在高风险问题中赢得模型信任。
更新机制:价格、政策、功能会变,没有更新机制的页面会从资产变成风险源。
报告用一句话总结了这场转变:GEO的写作对象不是算法,而是模型在压缩答案时最愿意安全复用的语义单元。
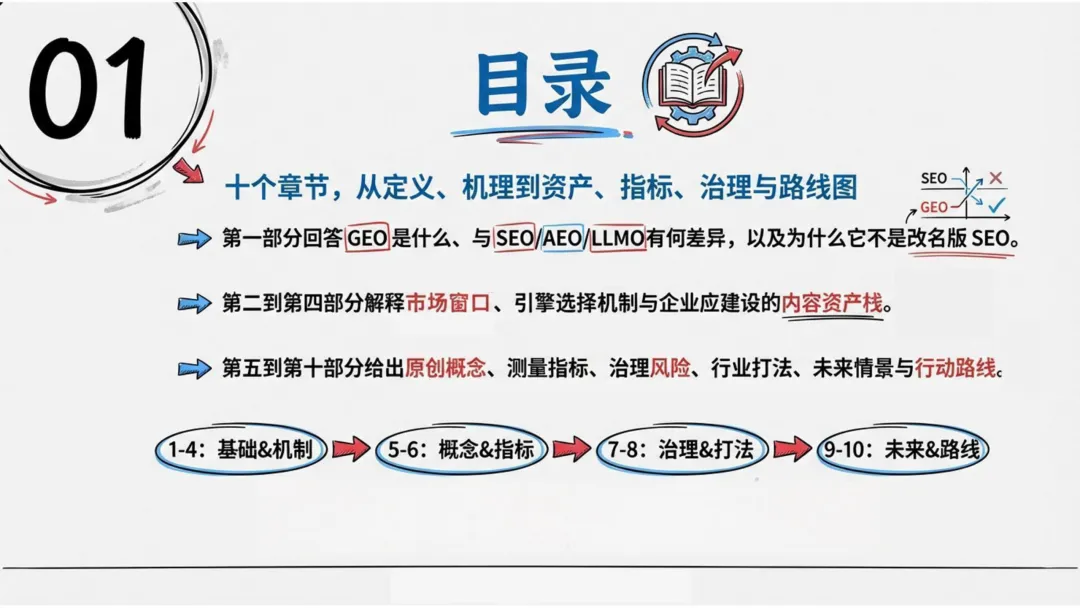
五、五个概念,让GEO从动作升级为战略
为了让企业团队有统一的语言,报告提出了五个原创概念:
答案份额:品牌在关键问题答案正文中占据的叙事空间,不只是“有没有出现”,还包括“扮演什么角色”。
引用可得性:模型在高风险问题里敢不敢引用你的内容,取决于证据清晰度、出处完整度和风险可控度。
语义压缩率:内容被压缩后还能保留多少关键信息。
事实回补成本:模型和用户为核对你的一条说法要付出多少额外努力。成本越低,越容易被采用。
品牌锚点密度:模型能稳定记住的“品牌—事实—场景”关系数量。锚点越多,叙事漂移越小。
这五个概念把GEO从零散的动作,变成了一套可测量、可管理、可优化的战略框架。
六、国内落地:适配本土模型与合规红线
报告专门讨论了国内市场。豆包、文心一言、通义千问均采用RAG(检索增强生成) 架构,底层逻辑一致:优先保障真实性、合规性、权威性。
国内GEO的核心要点:
完成ICP备案与搜索引擎站点认证,这是信源优先级的前提
从展示册思维转向证据库思维
坚守内容真实准确,严禁虚假、夸大、无来源的承诺
覆盖用户决策全链路,提升多轮追问留存率
跨模型适配,而不是绑定单一平台
合规是红线。报告明确指出:虚假内容、伪证据、诱导操纵模型的行为,会被直接过滤,严重者封禁站点抓取。
七、0-180天行动路线图
报告给出了一个非常务实的起步路径:
0-30天:梳理10-20个最高价值问题,建立答案日志,盘点现有资产缺口。目标不是立刻出结果,而是建立可观察的基线。
31-90天:围绕高价值问题,把内容从页面库改造成证据库——补事实表、对比页、边界页,建立更新机制,运行多引擎并跑实验。
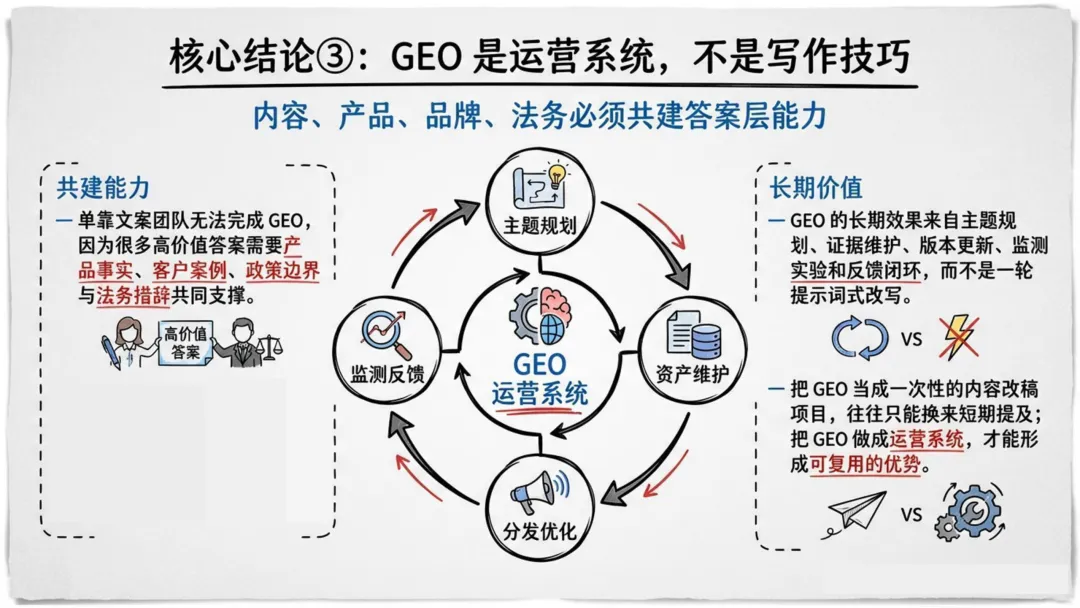
90-180天:把GEO接入内容规划、产品发布、品牌传播、法务审核,让它成为常规流程的一部分,而不是一个独立项目。
结语:经营答案,而不是优化页面
GEO的终局不是流量技巧,而是可信知识的经营能力。
当用户越来越习惯先向模型提问,企业真正需要管理的就不再是网页,而是品牌在问题求解过程中的答案位置与证据角色。
长期胜负,不在于谁更会迎合模型,而在于谁能更稳定地提供清楚、真实、可复用、可更新的知识资产。
最值得投入的,不是追逐一时的算法细节,而是建设一套穿越入口变化的答案经营系统。
本文基于清华大学《GEO(生成式引擎优化)研究报告》撰写,更多详细内容请查阅原文。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群


AI科普馆:打开AI世界之窗

