



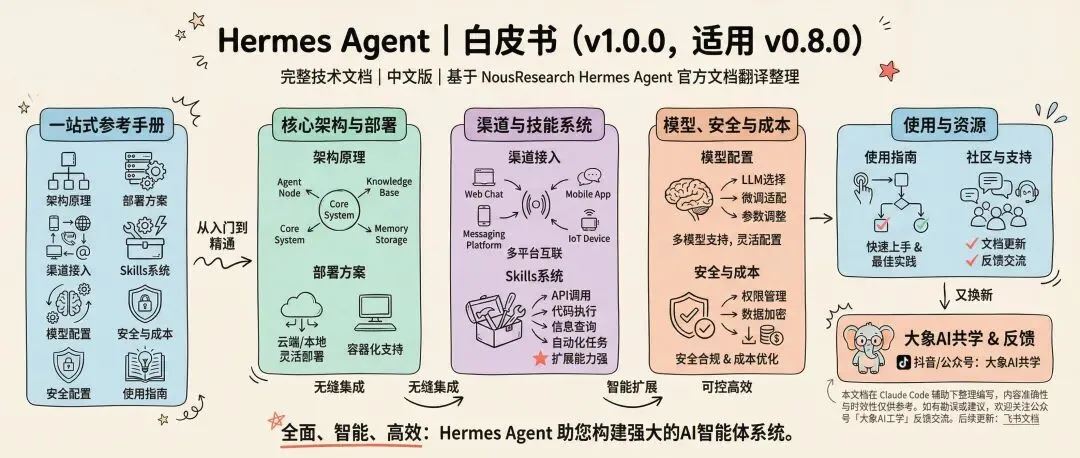
从入门到精通,涵盖架构原理、部署方案、渠道接入、Skills系统、模型配置、安全与成本、使用指南的一站式参考手册。
文档版本:v1.0.0
适用版本:v0.8.0
完整技术文档 | 中文版
基于 NousResearch Hermes Agent 官方文档翻译整理
大象
抖音/公众号:大象AI共学
本文档在 Claude Code 辅助下整理编写,内容的准确性与时效性仅供参考。如有勘误或建议,欢迎关注公众号「大象AI工学」反馈交流。
后续更新:https://wcnoxi4wqsvx.feishu.cn/docx/F8djdHVIAoPCEHxuQ37ch9EjnEb?from=from_copylink
目录
第一部分:入门指南
1. Hermes Agent 概述 2. 学习路径 3. 安装指南 4. 快速开始 5. 更新与卸载 6. Android/Termux 安装 7. Nix & NixOS 设置
第二部分:用户指南
1. CLI 界面 2. 配置 3. 会话管理 4. 安全
第三部分:消息平台
1. 消息网关概述 2. Telegram 设置 3. Discord 设置 4. 语音模式
第四部分:核心功能
1. 工具与工具集 2. 技能系统 3. 持久化内存 4. 上下文文件 5. MCP (Model Context Protocol) 6. 定时任务 (Cron) 7. 子代理委托 8. 代码执行 9. 事件钩子 10. 批处理 11. 浏览器自动化 12. 强化学习训练 13. 提供商路由
第五部分:开发指南
1. 架构 2. 添加工具 3. 创建技能 4. 贡献指南
第六部分:实用指南
1. 技巧与最佳实践 2. 每日简报机器人教程 3. 团队 Telegram 助手教程 4. 作为 Python 库使用 5. 使用语音模式
Hermes Agent 可以作为机器人与 Discord 集成,让您可以通过私信或服务器频道与您的 AI 助手聊天。机器人接收您的消息,通过 Hermes Agent 管道处理(包括工具使用、记忆和推理),并实时响应。它支持文本、语音消息、文件附件和斜杠命令。
在设置之前,大多数人想知道的是:Hermes 进入您的服务器后的行为方式。
Hermes 的行为表现
| 场景 | 行为 |
| 私信(DMs) | Hermes 会回复每一条消息,不需要 |
| 服务器频道 | 默认情况下,只有当您 |
| 自由响应频道 | 您可以使用 |
| 帖子(Threads) | Hermes 会在同一个帖子中回复。除非该帖子或其父频道被配置为自由响应,否则提及规则仍然适用。帖子与会话历史的父频道是隔离的。 |
| 多用户共享频道 | 默认情况下,为了安全和清晰,Hermes 会在频道内为每个用户隔离会话历史。除非您明确禁用,否则两个在同一频道中交谈的人不会共享同一个对话记录。 |
| 提及其他用户的消息 | 当 |
? 大象提示:如果您想要一个普通的机器人帮助频道,人们可以在其中与 Hermes 交谈而无需每次都标记它,请将该频道添加到 DISCORD_FREE_RESPONSE_CHANNELS 中。
Discord 网关模型
Discord 上的 Hermes 不是无状态回复的 Webhook。它通过完整的消息网关运行,这意味着每个传入消息都会经过:
1. 授权(DISCORD_ALLOWED_USERS) 2. 提及/自由响应检查 3. 会话查找 4 会话记录加载 5. 正常的 Hermes 代理执行,包括工具、记忆和斜杠命令 6. 响应交付回 Discord
这很重要,因为繁忙服务器中的行为取决于 Discord 路由和 Hermes 会话策略。
Discord 中的会话模型
默认情况下:
- 每个私信都有自己的会话
- 每个服务器帖子都有自己的会话命名空间
- 共享频道中的每个用户在该频道内都有自己的会话
因此,如果 Alice 和 Bob 都在 #research 频道与 Hermes 交谈,默认情况下 Hermes 会将这些视为单独的对话,即使他们使用的是同一个可见的 Discord 频道。
这由 config.yaml 控制:
group_sessions_per_user:true只有当您明确希望整个房间共享一个对话时,才将其设置为 false:
group_sessions_per_user:false共享会话对于协作室很有用,但它们也意味着:
- 用户共享上下文增长和令牌成本
- 一个人的长期工具繁重任务可能会使其他人的上下文膨胀
- 一个人的正在运行的任务可能会打断同一房间中另一个人的后续请求
中断和并发
Hermes 按会话密钥跟踪正在运行的代理。
使用默认的 group_sessions_per_user: true:
- Alice 中断自己正在进行的请求只会影响该频道中 Alice 的会话
- Bob 可以在同一频道中继续交谈,而不会继承 Alice 的历史记录或中断 Alice 的运行
使用 group_sessions_per_user: false:
- 整个房间为该频道/帖子共享一个正在运行的代理槽
- 来自不同人的后续消息可能会互相打断或排队
本指南将引导您完成完整的设置过程 - 从在 Discord 开发者门户创建机器人到发送第一条消息。
步骤1:创建 Discord 应用程序
1. 前往 https://discord.com/developers/applications 并使用您的 Discord 帐户登录。 2. 点击右上角的 New Application。 3. 为您的应用程序输入名称(例如 "Hermes Agent")并接受开发者服务条款。 undefined. 点击 Create。
4eneral Information 页面。记下 Application ID - 稍后您将需要它来构建邀请 URL。
步骤2:创建机器人
1. 在左侧边栏中,点击 Bot。 2. Discord 会自动为您的应用程序创建一个机器人用户。您会看到机器人的用户名,您可以自定义它。 3. 在 Authorization Flow 下: - 将 Public Bot 设置为 ON - 使用 Discord 提供的邀请链接需要此设置(推荐)。这允许安装选项卡生成默认授权 URL。
- 保持 Require OAuth2 Code Grant 设置为 OFF。
? 大象提示您可以在此页面为您的机器人设置自定义头像和横幅。这是用户在 Discord 中看到的内容。
私有机器人替代方案
如果您希望保持机器人私有(Public Bot = OFF),您必须在步骤5中使用手动 URL 方法,而不是安装选项卡。Discord 提供的链接需要启用 Public Bot。
步骤3:启用特权网关意图
这是整个设置中最关键的一步。如果未启用正确的意图,您的机器人将连接到 Discord 但无法读取消息内容。
在 Bot 页面上,向下滚动到 Privileged Gateway Intents。您会看到三个开关:
| 意图 | 用途 | 是否必需? |
| Presence Intent | 查看用户在线/离线状态 | 可选 |
| Server Members Intent | 访问成员列表,解析用户名 | 必需 |
| Message Content Intent | 读取消息的文本内容 | 必需 |
通过将开关切换为 ON,启用Server Members Intent和Message Content Intent。
- 如果没有 Message Content Intent,您的机器人会收到消息事件,但消息文本为空 - 机器人实际上看不到您输入的内容。
- 如果没有 Server Members Intent,机器人无法解析允许用户列表的用户名,可能无法识别是谁在向它发送消息。
⚠️ 这是 Discord 机器人不工作的首要原因如果您的机器人在线但从不回复消息,几乎可以肯定是 Message Content Intent 被禁用了。返回 https://discord.com/developers/applications,选择您的应用程序 → 机器人 → 特权网关意图,确保 Message Content Intent 已切换为 ON。点击 Save Changes。
关于服务器数量:
- 如果您的机器人在少于100个服务器中,您可以自由地打开和关闭意图。
- 如果您的机器人在100个或更多服务器中,Discord 要求您提交验证申请才能使用特权意图。对于个人使用,这不是问题。
点击页面底部的 Save Changes。
步骤4:获取机器人令牌
机器人令牌是 Hermes Agent 用作您的机器人登录的凭证。仍在 Bot 页面上:
1. 在 Token 部分下,点击 Reset Token。 2. 如果您的 Discord 帐户启用了双因素身份验证,请输入您的 2FA 代码。 3. Discord 将显示您的新令牌。立即复制它。
⚠️ 令牌仅显示一次令牌仅显示一次。如果您丢失了它,您需要重置它并生成一个新的。切勿公开分享您的令牌或将其提交到 Git - 任何拥有此令牌的人都可以完全控制您的机器人。
将令牌存储在安全的地方(例如密码管理器)。步骤8中您将需要它。
步骤5:生成邀请 URL
您需要一个 OAuth2 URL 来邀请机器人到您的服务器。有两种方法可以做到这一点:
选项A:使用安装选项卡(推荐)
需要公开机器人
此方法需要在步骤2中将 Public Bot 设置为 ON。如果您将 Public Bot 设置为 OFF,请改用下面的手动 URL 方法。
1. 在左侧边栏中,点击 Installation。 2. 在 Installation Contexts 下,启用 Guild Install。 3. 对于 Install Link,选择 Discord Provided Link。 4. 在 Guild Install 的 Default Install Settings 下: - Scopes:选择 bot 和 applications.commands
- Permissions:选择下面列出的权限。
选项B:手动 URL
您可以使用以下格式直接构建邀请 URL:
https://discord.com/oauth2/authorize?client_id=YOUR_APP_ID&scope=bot+applications.commands&permissions=274878286912将 YOUR_APP_ID 替换为步骤1中的 Application ID。
所需权限
这些是您的机器人需要的最低权限:
- View Channels - 查看它有权访问的频道
- Send Messages - 回复您的消息
- Embed Links - 格式化丰富的响应
- Attach Files - 发送图像、音频和文件输出
- Read Message History - 维护对话上下文
推荐的额外权限
- Send Messages in Threads - 在帖子对话中回复
- Add Reactions - 对消息做出反应以进行确认
权限整数
| 级别 | 权限整数 | 包含内容 |
| 最低 | 117760 | 查看频道、发送消息、读取消息历史、附加文件 |
| 推荐 | 274878286912 | 以上所有内容加上嵌入链接、在帖子中发送消息、添加反应 |
步骤6:邀请到您的服务器
1. 在浏览器中打开邀请 URL(来自安装选项卡或您构建的手动 URL)。 2. 在 Add to Server 下拉菜单中,选择您的服务器。 3. 点击 Continue,然后点击 Authorize。 4. 如果提示,请完成 CAPTCHA。
ℹ️ 信息您需要在 Discord 服务器上拥有 Manage Server 权限才能邀请机器人。如果您在下拉菜单中没有看到您的服务器,请让服务器管理员改用邀请链接。
授权后,机器人将出现在您服务器的成员列表中(在您启动 Hermes 网关之前,它会显示为离线)。
步骤7:查找您的 Discord 用户 ID
Hermes Agent 使用您的 Discord 用户 ID 来控制谁可以与机器人交互。要找到它:
1. 打开 Discord(桌面或 Web 应用程序)。 2. 前往 Settings → Advanced → 将 Developer Mode 切换为 ON。 3. 关闭设置。 4. 右键单击您自己的用户名(在消息、成员列表或您的个人资料中)→ Copy User ID。
您的用户 ID 是一个长数字,例如 284102345871466496。
? 大象提示开发者模式还允许您以相同的方式复制 频道 ID 和 服务器 ID - 右键单击频道或服务器名称并选择复制 ID。如果您想手动设置主频道,您将需要频道 ID。
步骤8:配置 Hermes Agent
选项A:交互式设置(推荐)
运行引导式设置命令:
hermes gateway setup出现提示时选择 Discord,然后在询问时粘贴您的机器人令牌和用户 ID。
选项B:手动配置
将以下内容添加到您的 ~/.hermes/.env 文件中:
# 必需DISCORD_BOT_TOKEN=your-bot-tokenDISCORD_ALLOWED_USERS=284102345871466496# 多个允许的用户(逗号分隔)# DISCORD_ALLOWED_USERS=284102345871466496,198765432109876543然后启动网关:
hermes gateway机器人应该会在几秒钟内在 Discord 上线。向它发送消息 - 可以是私信或在它可以看到的频道中 - 进行测试。
? 大象提示您可以在后台运行 hermes gateway 或将其作为 systemd 服务以实现持久运行。有关详细信息,请参阅部署文档。
配置参考
Discord 行为通过两个文件控制:~/.hermes/.env 用于凭证和环境级开关,~/.hermes/config.yaml 用于结构化设置。当两者都设置时,环境变量始终优先于 config.yaml 值。
环境变量(.env)
| 变量 | 必需 | 默认值 | 描述 |
| DISCORD_BOT_TOKEN | 是 | — | 来自 |
| DISCORD_ALLOWED_USERS | 是 | — | 允许与机器人交互的 Discord 用户 ID,逗号分隔。没有这个,网关默认拒绝所有用户。 |
| DISCORD_HOME_CHANNEL | 否 | — | 机器人发送主动消息(cron 输出、提醒、通知)的频道 ID。 |
| DISCORD_HOME_CHANNEL_NAME | 否 | "Home" | 日志和状态输出中主频道的显示名称。 |
| DISCORD_REQUIRE_MENTION | 否 | true | 当为 |
| DISCORD_FREE_RESPONSE_CHANNELS | 否 | — | 频道 ID,逗号分隔,即使 |
| DISCORD_IGNORE_NO_MENTION | 否 | true | 当为 |
| DISCORD_AUTO_THREAD | 否 | true | 当为 |
| DISCORD_ALLOW_BOTS | 否 | "none" | 控制机器人如何处理来自其他 Discord 机器人的消息。 |
| DISCORD_REACTIONS | 否 | true | 当为 |
| DISCORD_IGNORED_CHANNELS | 否 | — | 频道 ID,逗号分隔,即使被 |
| DISCORD_NO_THREAD_CHANNELS | 否 | — | 频道 ID,逗号分隔,机器人在这些频道中直接响应而不是创建帖子。仅当 |
| DISCORD_REPLY_TO_MODE | 否 | "first" | 控制回复引用行为: |
配置文件(config.yaml)
~/.hermes/config.yaml 中的 discord 部分镜像了上面的环境变量。Config.yaml 设置作为默认值应用 - 如果等效的环境变量已经设置,则环境变量优先。
# Discord 特定设置discord:require_mention:true# 在服务器频道中需要 @提及free_response_channels:""# 逗号分隔的频道 ID(或 YAML 列表)auto_thread:true# 在 @提及时自动创建帖子reactions:true# 在处理过程中添加表情符号反应ignored_channels: [] # 机器人永远不会响应的频道 IDno_thread_channels: [] # 机器人响应而不创建线程的频道 ID# 会话隔离(适用于所有网关平台,不仅仅是 Discord)group_sessions_per_user:true# 在共享频道中按用户隔离会话discord.require_mention
类型: 布尔值 — 默认值:true启用后,机器人仅在服务器频道中被直接 @提及 时才响应。无论此设置如何,私信始终会得到响应。
discord.free_response_channels
类型: 字符串或列表 — 默认值:""机器人在这些频道中响应所有消息而不需要 @提及。接受逗号分隔的字符串或 YAML 列表:
# 字符串格式discord:free_response_channels:"1234567890,9876543210"# 列表格式discord:free_response_channels:-1234567890-9876543210如果帖子的父频道在此列表中,则该帖子也变为无需提及即可响应。
discord.auto_thread
类型: 布尔值 — 默认值:true启用后,普通文本频道中的每个 @提及 都会自动为对话创建一个新帖子。这使主频道保持干净,并为每个对话提供自己的隔离会话历史。创建帖子后,该帖子中的后续消息不需要 @提及 - 机器人知道它已经在参与。
在现有帖子或私信中发送的消息不受此设置的影响。
discord.reactions
类型: 布尔值 — 默认值:true控制机器人是否向消息添加表情符号反应作为视觉反馈:
- ? 当机器人开始处理您的消息时添加
- ✅ 当响应成功交付时添加
- ❌ 如果处理过程中发生错误时添加
如果您觉得反应分散注意力,或者机器人的角色没有 Add Reactions 权限,请禁用此功能。
discord.ignored_channels
类型: 字符串或列表 — 默认值:[]即使被直接 @提及,机器人也永远不会在这些频道中响应。这具有最高优先级 - 如果频道在此列表中,机器人会默默地忽略那里的所有消息,无论 require_mention、free_response_channels 或任何其他设置如何。
# 字符串格式discord:ignored_channels:"1234567890,9876543210"# 列表格式discord:ignored_channels:-1234567890-9876543210如果帖子的父频道在此列表中,则该帖子中的消息也会被忽略。
discord.no_thread_channels
类型: 字符串或列表 — 默认值:[]机器人在这些频道中直接在频道中响应,而不是自动创建帖子。仅当 auto_thread 为 true(默认)时才生效。在这些频道中,机器人像普通消息一样内联响应,而不是生成新帖子。
discord:no_thread_channels:-1234567890# 机器人在这里内联响应适用于专门用于机器人交互的频道,在这些频道中帖子会增加不必要的噪音。
group_sessions_per_user
类型: 布尔值 — 默认值:true这是一个全局网关设置(不是 Discord 特定的),控制同一频道中的用户是否获得隔离的会话历史。
当为 true 时:Alice 和 Bob 在 #research 中交谈时,每个人都有自己与 Hermes 的独立对话。当为 false 时:整个频道共享一个对话记录和一个正在运行的代理槽。
group_sessions_per_user:true有关每种模式的完整含义,请参阅上面的 会话模型 部分。
display.tool_progress
类型: 字符串 — 默认值:"all" — 取值:off, new, all, verbose控制机器人在处理时是否在聊天中发送进度消息(例如 "正在读取文件...","正在运行终端命令...")。这是一个全局网关设置,适用于所有平台。
display:tool_progress:"all"# off | new | all | verbose- off - 无进度消息
- new - 每个轮次仅显示第一个工具调用
- all - 显示所有工具调用(在网关消息中截断为40个字符)
- verbose - 显示完整的工具调用详细信息(可能产生长消息)
display.tool_progress_command
类型: 布尔值 — 默认值:false启用后,网关中会提供 /verbose 斜杠命令,让您无需编辑 config.yaml 即可在工具进度模式之间循环(off → new → all → verbose → off)。
display:tool_progress_command:true交互式模型选择器
在 Discord 频道中发送不带参数的 /model 以打开基于下拉菜单的模型选择器:
undefined. 提供商选择 - 显示可用提供商的选择下拉菜单(最多25个)。 undefined. 模型选择 - 第二个下拉菜单,包含所选提供商的模型(最多25个)。
选择器会在120秒后超时。只有授权用户(在 DISCORD_ALLOWED_USERS 中的用户)才能与之交互。如果您知道模型名称,可以直接键入 /model <name>。
技能的原生斜杠命令
Hermes 会自动将已安装的技能注册为原生 Discord 应用程序命令。这意味着技能会出现在 Discord 的自动完成 / 菜单中,与内置命令并列。
- 每个技能都成为一个 Discord 斜杠命令(例如 /code-review、/ascii-art)
- 技能接受可选的 args 字符串参数
- Discord 对每个机器人有100个应用程序命令的限制 - 如果您的技能多于可用插槽,额外的技能会被跳过,并在日志中发出警告
- 技能在机器人启动期间与 /model、/reset 和 /background 等内置命令一起注册
无需额外配置 - 通过 hermes skills install 安装的任何技能都会在下次网关重启时自动注册为 Discord 斜杠命令。
主频道
您可以指定一个"主频道",机器人在那里发送主动消息(例如 cron 作业输出、提醒和通知)。有两种设置方法:
使用斜杠命令
在机器人所在的任何 Discord 频道中键入 /sethome。该频道将成为主频道。
手动配置
将这些添加到您的 ~/.hermes/.env:
DISCORD_HOME_CHANNEL=123456789012345678DISCORD_HOME_CHANNEL_NAME="#bot-updates"将 ID 替换为实际的频道 ID(右键单击 → 开启开发者模式下复制频道 ID)。
语音消息
Hermes Agent 支持 Discord 语音消息:
- 传入语音消息 使用配置的 STT 提供商自动转录:本地 faster-whisper(无需密钥)、Groq Whisper(GROQ_API_KEY)或 OpenAI Whisper(VOICE_TOOLS_OPENAI_KEY)。
- 文本转语音:使用 /voice tts 让机器人在文本回复旁边发送语音音频响应。
- Discord 语音频道:Hermes 还可以加入语音频道,收听用户讲话,并在频道中回话。
有关完整设置和操作指南,请参阅:
- https://hermes-agent.nousresearch.com/docs/user-guide/features/voice-mode
- https://hermes-agent.nousresearch.com/docs/guides/use-voice-mode-with-hermes
故障排除
机器人在线但不回复消息
原因: 消息内容意图被禁用。解决方法: 前往 https://discord.com/developers/applications → 您的应用 → 机器人 → 特权网关意图 → 启用 Message Content Intent → 保存更改。重启网关。
启动时出现 "Disallowed Intents" 错误
原因: 您的代码请求了开发者门户中未启用的意图。解决方法: 在机器人设置中启用所有三个特权网关意图(Presence、Server Members、Message Content),然后重启。
机器人无法看到特定频道中的消息
原因: 机器人的角色没有查看该频道的权限。解决方法: 在 Discord 中,前往频道设置 → 权限 → 添加机器人角色,并启用 View Channel 和 Read Message History。
403 Forbidden 错误
原因: 机器人缺少所需权限。解决方法: 使用步骤5中的 URL 以正确的权限重新邀请机器人,或在服务器设置 → 角色中手动调整机器人的角色权限。
机器人离线
原因: Hermes 网关未运行,或者令牌不正确。解决方法: 检查 hermes gateway 是否正在运行。验证 .env 文件中的 DISCORD_BOT_TOKEN。如果您最近重置了令牌,请更新它。
"用户不允许" / 机器人忽略您
原因: 您的用户 ID 不在 DISCORD_ALLOWED_USERS 中。解决方法: 将您的用户 ID 添加到 ~/.hermes/.env 中的 DISCORD_ALLOWED_USERS 并重启网关。
同一频道中的人意外共享上下文
原因:group_sessions_per_user 被禁用,或者平台无法为该上下文中的消息提供用户 ID。解决方法: 在 ~/.hermes/config.yaml 中设置此项并重启网关:
group_sessions_per_user:true如果您有意想要共享房间对话,请保持关闭 - 只需预期共享的对话历史和共享的中断行为。
安全
⚠️ 警告始终设置 DISCORD_ALLOWED_USERS 来限制谁可以与机器人交互。没有它,作为安全措施,网关默认拒绝所有用户。仅添加您信任的人的用户 ID - 授权用户可以完全访问代理的功能,包括工具使用和系统访问。
有关保护 Hermes Agent 部署的更多信息,请参阅 https://hermes-agent.nousresearch.com/docs/user-guide/security。
第15章 语音模式
Hermes Agent 在 CLI 和消息平台上支持完整的语音交互。您可以使用麦克风与代理交谈,听到语音回复,还可以在 Discord 语音频道中进行实时语音对话。
如果您想要包含推荐配置和实际使用模式的实用设置指南,请参阅 https://hermes-agent.nousresearch.com/docs/guides/use-voice-mode-with-hermes。
先决条件
在使用语音功能之前,请确保您已经:
1. 安装了 Hermes Agent —— pip install hermes-agent(参阅 https://hermes-agent.nousresearch.com/docs/getting-started/installation) 2. 配置了 LLM 提供商 —— 运行 hermes model 或在 ~/.hermes/.env 中设置您偏好的提供商凭证 3. 基础设置正常工作 —— 运行 hermes 验证代理可以响应文本,然后再启用语音功能
大象提示第一次运行 hermes 时会自动创建 ~/.hermes/ 目录和默认 config.yaml。您只需要手动创建 ~/.hermes/.env 来存放 API 密钥。
功能概述
| 功能 | 平台 | 描述 |
| 交互式语音 | CLI | 按 Ctrl+B 录音,代理自动检测静音并回复 |
| 自动语音回复 | Telegram、Discord | 代理在文本回复的同时发送语音音频 |
| 语音频道 | Discord | 机器人加入语音频道,监听用户讲话并语音回复 |
依赖要求
Python 包
# CLI 语音模式(麦克风 + 音频播放)pip install "hermes-agent[voice]"# Discord + Telegram 消息(包含 discord.py[voice] 用于 VC 支持)pip install "hermes-agent[messaging]"# 高级 TTS(ElevenLabs)pip install "hermes-agent[tts-premium]"# 本地 TTS(NeuTTS,可选)python -m pip install -U neutts[all]# 一次性安装所有功能pip install "hermes-agent[all]"| 额外包 | 包含的包 | 用途 |
| voice | sounddevice | CLI 语音模式 |
| messaging | discord.py[voice] | Discord 和 Telegram 机器人 |
| tts-premium | elevenlabs | ElevenLabs TTS 提供商 |
可选本地 TTS 提供商:单独安装 neutts,使用命令 python -m pip install -U neutts[all]。首次使用时会自动下载模型。
信息discord.py[voice] 会自动安装 PyNaCl(用于语音加密)和 opus 绑定。这是 Discord 语音频道支持的必需依赖。
系统依赖
# macOSbrew install portaudio ffmpeg opusbrew install espeak-ng # 用于 NeuTTS# Ubuntu/Debiansudo apt install portaudio19-dev ffmpeg libopus0sudo apt install espeak-ng # 用于 NeuTTS| 依赖 | 用途 | 适用场景 |
| PortAudio | 麦克风输入和音频播放 | CLI 语音模式 |
| ffmpeg | 音频格式转换(MP3 → Opus,PCM → WAV) | 所有平台 |
| Opus | Discord 语音编解码器 | Discord 语音频道 |
| espeak-ng | 音素化后端 | 本地 NeuTTS 提供商 |
API 密钥
添加到 ~/.hermes/.env:
# 语音转文本 —— 本地提供商完全不需要密钥# pip install faster-whisper # 免费、本地运行,推荐GROQ_API_KEY=your-key # Groq Whisper —— 快速、免费层级(云端)VOICE_TOOLS_OPENAI_KEY=your-key # OpenAI Whisper —— 付费(云端)# 文本转语音(可选 —— Edge TTS 和 NeuTTS 无需任何密钥即可工作)ELEVENLABS_API_KEY=*** # ElevenLabs —— 高级音质# 上面的 VOICE_TOOLS_OPENAI_KEY 也会启用 OpenAI TTS大象提示如果安装了 faster-whisper,语音模式的 STT 功能可以零 API 密钥运行。首次使用时会自动下载模型(base 型号约 150 MB)。
CLI 语音模式
快速开始
启动 CLI 并启用语音模式:
hermes # 启动交互式 CLI然后在 CLI 内使用这些命令:
/voice 切换语音模式开启/关闭/voice on 启用语音模式/voice off 禁用语音模式/voice tts 切换 TTS 输出/voice status 显示当前状态工作原理
1. 使用 hermes 启动 CLI,并用 /voice on 启用语音模式 2. 按 Ctrl+B —— 播放提示音(880Hz),开始录音 3. 讲话 —— 实时音频电平条显示输入:● [▁▂▃▅▇▇▅▂] ❯ 4. 停止讲话 —— 静音 3 秒后,录音自动停止 5. 播放两声提示音(660Hz),确认录音结束 6. 音频通过 Whisper 转写并发送给代理 7. 如果启用了 TTS,代理的回复会被朗读出来 8. 录音自动重新开始 —— 无需按任何键即可再次讲话
这个循环会持续到您在录音过程中按 Ctrl+B(退出连续模式),或连续 3 次录音未检测到语音为止。
大象提示录音快捷键可以通过 ~/.hermes/config.yaml 中的 voice.record_key 配置(默认:ctrl+b)。
静音检测
采用两阶段算法检测您是否结束讲话:
1. 语音确认 —— 等待音频高于 RMS 阈值(200)至少 0.3 秒,容忍音节间的短暂停顿 2. 结束检测 —— 确认有语音后,连续静音 3.0 秒后触发停止
如果 15 秒内完全没有检测到语音,录音会自动停止。
silence_threshold 和 silence_duration 都可以在 config.yaml 中配置。
流式 TTS
启用 TTS 时,代理会在生成文本时逐句朗读回复——您无需等待完整响应生成:
1. 将文本增量缓冲为完整句子(最少 20 个字符) 2. 去除 markdown 格式和 <think> 块 3 实时为每个句子生成并播放音频
幻觉过滤
Whisper 有时会从静音或背景噪音中生成幻听文本(例如"谢谢观看"、"订阅"等)。代理会使用包含 26 种语言的已知幻觉短语集,加上捕获重复变体的正则表达式模式来过滤这些内容。
网关语音回复(Telegram 和 Discord)
如果您还没有设置消息机器人,请参阅平台特定指南:
- https://hermes-agent.nousresearch.com/docs/user-guide/messaging/telegram
- https://hermes-agent.nousresearch.com/docs/user-guide/messaging/discord
启动网关连接到消息平台:
hermes gateway # 启动网关(连接到已配置的平台)hermes gateway setup # 首次配置的交互式设置向导Discord:频道 vs DM
机器人在 Discord 上支持两种交互模式:
| 模式 | 使用方式 | 需要提及 | 设置 |
| 直接消息(DM) | 打开机器人资料 → "发送消息" | 否 | 立即可用 |
| 服务器频道 | 在机器人所在的文本频道中输入 | 是( | 机器人必须被邀请到服务器 |
DM(推荐个人使用): 只需打开与机器人的 DM 并输入消息——无需 @ 提及。语音回复和所有命令的工作方式与频道中相同。
服务器频道: 只有当您 @ 提及机器人时才会响应(例如 @hermesbyt4 hello)。确保从提及弹出窗口中选择机器人用户,而不是同名的角色。
大象提示要在服务器频道中禁用提及要求,添加到 ~/.hermes/.env:
或者将特定频道设置为自由响应(无需提及)
命令
这些命令在 Telegram 和 Discord 中都可以使用(DM 和文本频道):
/voice 切换语音模式开启/关闭/voice on 仅在您发送语音消息时回复语音/voice tts 对所有消息都回复语音/voice off 禁用语音回复/voice status 显示当前设置模式
| 模式 | 命令 | 行为 |
| off | /voice off | 仅文本(默认) |
| voice_only | /voice on | 仅在您发送语音消息时回复语音 |
| all | /voice tts | 对每条消息都回复语音 |
语音模式设置在网关重启后仍然有效。
平台交付
| 平台 | 格式 | 说明 |
| Telegram | 语音气泡(Opus/OGG) | 在聊天中内联播放。如果需要,ffmpeg 会将 MP3 转换为 Opus |
| Discord | 原生语音气泡(Opus/OGG) | 像用户语音消息一样内联播放。如果语音气泡 API 失败,会回退到文件附件 |
Discord 语音频道
最沉浸式的语音功能:机器人加入 Discord 语音频道,监听用户讲话,转写语音内容,通过代理处理,并在语音频道中朗读回复。
设置
1. Discord 机器人权限
如果您已经为文本设置了 Discord 机器人(参阅 https://hermes-agent.nousresearch.com/docs/user-guide/messaging/discord),您需要添加语音权限。
前往 https://discord.com/developers/applications → 您的应用 → Installation → Default Install Settings → Guild Install:
在现有文本权限基础上添加这些权限:
| 权限 | 用途 | 是否必需 |
| Connect | 加入语音频道 | 是 |
| Speak | 在语音频道中播放 TTS 音频 | 是 |
| Use Voice Activity | 检测用户何时在讲话 | 推荐 |
更新后的权限整数:
| 级别 | 整数 | 包含内容 |
| 仅文本 | 274878286912 | 查看频道、发送消息、读取历史、嵌入、附件、线程、反应 |
| 文本 + 语音 | 274881432640 | 以上所有 + 连接、讲话 |
使用更新后的权限 URL 重新邀请机器人:
https://discord.com/oauth2/authorize?client_id=YOUR_APP_ID&scope=bot+applications.commands&permissions=274881432640将 YOUR_APP_ID 替换为开发者门户中的应用 ID。
警告重新邀请已经在服务器中的机器人会更新其权限,不会移除它。您不会丢失任何数据或配置。
2. 特权网关意图
在 https://discord.com/developers/applications → 您的应用 → Bot → Privileged Gateway Intents,启用所有三个:
| 意图 | 用途 |
| Presence Intent | 检测用户在线/离线状态 |
| Server Members Intent | 将语音 SSRC 标识符映射到 Discord 用户 ID |
| Message Content Intent | 读取频道中的文本消息内容 |
这三个都是完整语音频道功能所必需的。Server Members Intent 尤其重要——没有它,机器人无法识别谁在语音频道中讲话。
3. Opus 编解码器
运行网关的机器上必须安装 Opus 编解码器库:
# macOS (Homebrew)brew install opus# Ubuntu/Debiansudo apt install libopus0机器人会从以下位置自动加载编解码器:
- macOS:/opt/homebrew/lib/libopus.dylib
- Linux:libopus.so.0
4. 环境变量
# ~/.hermes/.env# Discord 机器人(已为文本配置)DISCORD_BOT_TOKEN=your-bot-tokenDISCORD_ALLOWED_USERS=your-user-id# STT —— 本地提供商无需密钥(pip install faster-whisper)# GROQ_API_KEY=your-key # 替代方案:云端、快速、免费层级# TTS —— 可选。Edge TTS 和 NeuTTS 无需密钥。# ELEVENLABS_API_KEY=*** # 高级音质# VOICE_TOOLS_OPENAI_KEY=*** # OpenAI TTS / Whisper启动网关
hermes gateway # 使用现有配置启动机器人应该在几秒钟内上线 Discord。
命令
在机器人所在的 Discord 文本频道中使用这些命令:
/voice join 机器人加入您当前的语音频道/voice channel /voice join 的别名/voice leave 机器人断开语音频道连接/voice status 显示语音模式和连接的频道信息运行 /voice join 之前您必须先在语音频道中。机器人会加入您所在的同一个语音频道。
工作原理
机器人加入语音频道后,会:
1. 独立监听每个用户的音频流 2. 检测静音 —— 至少 0.5 秒语音后出现 1.5 秒静音会触发处理 3. 转写音频通过 Whisper STT(本地、Groq 或 OpenAI) 4. 处理通过完整的代理管道(会话、工具、内存) 5. 朗读回复通过 TTS 发送到语音频道
文本频道集成
当机器人在语音频道中时:
- 转写内容会出现在文本频道中:[语音] @user: 您说的内容
- 代理响应会以文本形式发送到频道 并 在语音频道中朗读
- 文本频道是发出 /voice join 命令的频道
回声防止
机器人在播放 TTS 回复时会自动暂停音频监听器,防止听到并重新处理自己的输出。
访问控制
只有 DISCORD_ALLOWED_USERS 中列出的用户才能通过语音交互。其他用户的音频会被静默忽略。
# ~/.hermes/.envDISCORD_ALLOWED_USERS=284102345871466496配置参考
config.yaml
# 语音录制(CLI)voice: record_key: "ctrl+b" # 开始/停止录音的按键 max_recording_seconds: 120 # 最大录音长度 auto_tts: false # 语音模式启动时自动启用 TTS silence_threshold: 200 # 低于此 RMS 级别(0-32767)视为静音 silence_duration: 3.0 # 自动停止前的静音秒数# 语音转文本stt: provider: "local" # "local"(免费) | "groq" | "openai" local: model: "base" # tiny, base, small, medium, large-v3 # model: "whisper-1" # 旧版:未设置 provider 时使用# 文本转语音tts: provider: "edge" # "edge"(免费) | "elevenlabs" | "openai" | "neutts" | "minimax" edge: voice: "en-US-AriaNeural" # 322 种语音,74 种语言 elevenlabs: voice_id: "pNInz6obpgDQGcFmaJgB" # Adam model_id: "eleven_multilingual_v2" openai: model: "gpt-4o-mini-tts" voice: "alloy" # alloy, echo, fable, onyx, nova, shimmer base_url: "https://api.openai.com/v1" # 可选:覆盖自托管或兼容 OpenAI 的端点 neutts: ref_audio: '' ref_text: '' model: neuphonic/neutts-air-q4-gguf device: cpu环境变量
# 语音转文本提供商(本地无需密钥)# pip install faster-whisper # 免费本地 STT —— 无需 API 密钥GROQ_API_KEY=... # Groq Whisper(快速、免费层级)VOICE_TOOLS_OPENAI_KEY=... # OpenAI Whisper(付费)# STT 高级覆盖(可选)STT_GROQ_MODEL=whisper-large-v3-turbo # 覆盖默认 Groq STT 模型STT_OPENAI_MODEL=whisper-1 # 覆盖默认 OpenAI STT 模型GROQ_BASE_URL=https://api.groq.com/openai/v1 # 自定义 Groq 端点STT_OPENAI_BASE_URL=https://api.openai.com/v1 # 自定义 OpenAI STT 端点# 文本转语音提供商(Edge TTS 和 NeuTTS 无需密钥)ELEVENLABS_API_KEY=*** # ElevenLabs(高级音质)# 上面的 VOICE_TOOLS_OPENAI_KEY 也会启用 OpenAI TTS# Discord 语音频道DISCORD_BOT_TOKEN=...DISCORD_ALLOWED_USERS=...STT 提供商对比
| 提供商 | 模型 | 速度 | 质量 | 成本 | API 密钥 |
| 本地 | base | 快(取决于 CPU/GPU) | 好 | 免费 | 否 |
| 本地 | small | 中等 | 更好 | 免费 | 否 |
| 本地 | large-v3 | 慢 | 最好 | 免费 | 否 |
| Groq | whisper-large-v3-turbo | 非常快(~0.5秒) | 好 | 免费层级 | 是 |
| Groq | whisper-large-v3 | 快(~1秒) | 更好 | 免费层级 | 是 |
| OpenAI | whisper-1 | 快(~1秒) | 好 | 付费 | 是 |
| OpenAI | gpt-4o-transcribe | 中等(~2秒) | 最好 | 付费 | 是 |
提供商优先级(自动回退):本地 > groq > openai
TTS 提供商对比
| 提供商 | 质量 | 成本 | 延迟 | 需要密钥 |
| Edge TTS | 好 | 免费 | ~1秒 | 否 |
| ElevenLabs | 优秀 | 付费 | ~2秒 | 是 |
| OpenAI TTS | 好 | 付费 | ~1.5秒 | 是 |
| NeuTTS | 好 | 免费 | 取决于 CPU/GPU | 否 |
NeuTTS 使用上面的 tts.neutts 配置块。
故障排除
"未找到音频设备"(CLI)
PortAudio 未安装:
brew install portaudio # macOSsudo apt install portaudio19-dev # Ubuntu机器人在 Discord 服务器频道中不响应
机器人在服务器频道中默认需要 @ 提及。请确保:
1. 输入 @ 并选择机器人用户(带 #discriminator),而不是同名的角色 2. 或者使用 DM——无需提及 3. 或者在 ~/.hermes/.env 中设置 DISCORD_REQUIRE_MENTION=false
机器人加入 VC 但听不到我说话
- 检查您的 Discord 用户 ID 是否在 DISCORD_ALLOWED_USERS 中
- 确保您在 Discord 中没有静音
- 机器人需要来自 Discord 的 SPEAKING 事件才能映射您的音频——加入后几秒内开始讲话
机器人能听到我但不回复
- 验证 STT 可用:安装 faster-whisper(无需密钥)或设置 GROQ_API_KEY / VOICE_TOOLS_OPENAI_KEY
- 检查 LLM 模型已配置且可访问
- 查看网关日志:tail -f ~/.hermes/logs/gateway.log
机器人有文本回复但不在语音频道中说话
- TTS 提供商可能失败——检查 API 密钥和配额
- Edge TTS(免费、无密钥)是默认回退方案
- 检查日志中的 TTS 错误
Whisper 返回垃圾文本
幻觉过滤器会自动捕获大多数情况。如果仍然出现幻听转录:
- 使用更安静的环境
- 调整配置中的 silence_threshold(更高 = 更不敏感)
- 尝试不同的 STT 模型
第16章 工具与工具集
工具是扩展代理能力的函数。它们被组织成逻辑化的工具集,可以按平台启用或禁用。
可用工具
Hermes 附带了广泛的内置工具注册表,涵盖网页搜索、浏览器自动化、终端执行、文件编辑、内存、委托、RL 训练、消息传递、Home Assistant 等功能。
注意Honcho 跨会话内存作为内存提供商插件(plugins/memory/honcho/)提供,而不是内置工具集。请参阅 https://hermes-agent.nousresearch.com/docs/user-guide/features/plugins 进行安装。
高级类别:
| 类别 | 示例 | 描述 |
| 网页 | web_search | 搜索网页并提取页面内容。 |
| 终端与文件 | terminal | 执行命令和操作文件。 |
| 浏览器 | browser_navigate | 交互式浏览器自动化,支持文本和视觉。 |
| 媒体 | vision_analyze | 多模态分析和生成。 |
| 代理编排 | todo | 规划、澄清、代码执行和子代理委托。 |
| 内存与回忆 | memory | 持久化内存和会话搜索。 |
| 自动化与交付 | cronjob | 支持创建/列出/更新/暂停/恢复/运行/删除操作的定时任务,以及出站消息传递。 |
| 集成 | ha_* | Home Assistant、MCP、RL 训练和其他集成。 |
有关权威的代码派生注册表,请参阅 https://hermes-agent.nousresearch.com/docs/reference/tools-reference 和 https://hermes-agent.nousresearch.com/docs/reference/toolsets-reference。
使用工具集
# 使用特定工具集hermes chat --toolsets "web,terminal"# 查看所有可用工具hermes tools# 按平台配置工具(交互式)hermes tools常见工具集包括 web、terminal、file、browser、vision、image_gen、moa、skills、tts、todo、memory、session_search、cronjob、code_execution、delegation、clarify、homeassistant 和 rl。
完整集合请参阅 https://hermes-agent.nousresearch.com/docs/reference/toolsets-reference,包括平台预设如 hermes-cli、hermes-telegram,以及动态 MCP 工具集如 mcp-<server>。
终端后端
终端工具可以在不同环境中执行命令:
| 后端 | 描述 | 适用场景 |
| local | 在您的机器上运行(默认) | 开发、可信任务 |
| docker | 隔离容器 | 安全、可重复性 |
| ssh | 远程服务器 | 沙箱化,使代理远离自己的代码 |
| singularity | HPC 容器 | 集群计算、无 root 权限 |
| modal | 云执行 | 无服务器、扩展 |
| daytona | 云沙箱工作区 | 持久化远程开发环境 |
配置
# 在 ~/.hermes/config.yaml 中terminal: backend: local # 或 docker、ssh、singularity、modal、daytona cwd: "." # 工作目录 timeout: 180 # 命令超时时间(秒)Docker 后端
terminal: backend: docker docker_image: python:3.11-slimSSH 后端
推荐用于安全——代理无法修改自己的代码:
terminal: backend: ssh# 在 ~/.hermes/.env 中设置凭证TERMINAL_SSH_HOST=my-server.example.comTERMINAL_SSH_USER=myuserTERMINAL_SSH_KEY=~/.ssh/id_rsaSingularity/Apptainer
# 为并行工作者预构建 SIFapptainer build ~/python.sif docker://python:3.11-slim# 配置hermes config set terminal.backend singularityhermes config set terminal.singularity_image ~/python.sifModal(无服务器云)
uv pip install modalmodal setuphermes config set terminal.backend modal容器资源
为所有容器后端配置 CPU、内存、磁盘和持久化:
terminal: backend: docker # 或 singularity、modal、daytona container_cpu: 1 # CPU 核心数(默认:1) container_memory: 5120 # 内存(MB,默认:5GB) container_disk: 51200 # 磁盘(MB,默认:50GB) container_persistent: true # 跨会话持久化文件系统(默认:true)当 container_persistent: true 时,已安装的包、文件和配置会在会话之间保留。
容器安全
所有容器后端都运行有安全加固:
- 只读根文件系统(Docker)
- 删除所有 Linux capabilities
- 无权限提升
- PID 限制(256 个进程)
- 完整命名空间隔离
- 通过卷而非可写根层提供持久化工作区
Docker 可以通过 terminal.docker_forward_env 可选地接收显式环境允许列表,但转发的变量对容器内的命令可见,应视为暴露给该会话。
后台进程管理
启动和管理后台进程:
terminal(command="pytest -v tests/", background=true)# 返回:{"session_id": "proc_abc123", "pid": 12345}# 然后使用 process 工具管理:process(action="list") # 显示所有运行中的进程process(action="poll", session_id="proc_abc123") # 检查状态process(action="wait", session_id="proc_abc123") # 阻塞直到完成process(action="log", session_id="proc_abc123") # 完整输出process(action="kill", session_id="proc_abc123") # 终止process(action="write", session_id="proc_abc123", data="y") # 发送输入PTY 模式(pty=true)启用交互式 CLI 工具,如 Codex 和 Claude Code。
Sudo 支持
如果命令需要 sudo,系统会提示您输入密码(会话中缓存)。或者在 ~/.hermes/.env 中设置 SUDO_PASSWORD。
警告在消息平台上,如果 sudo 失败,输出会包含提示,建议将 SUDO_PASSWORD 添加到 ~/.hermes/.env。
第17章 技能系统
技能是代理可以按需加载的知识文档,遵循渐进式披露模式以最小化令牌使用,并且兼容https://agentskills.io/specification开放标准。
所有技能都存储在 ~/.hermes/skills/ 目录下——这是主目录和唯一可信来源。全新安装时,捆绑的技能会从代码库中复制到此处。从技能中心安装的技能和代理自行创建的技能也会保存在这里,代理可以修改或删除任何技能。
您也可以让 Hermes 指向外部技能目录——这些额外的文件夹会和本地目录一起被扫描。请参阅下文的外部技能目录部分。
相关参考:
- https://hermes-agent.nousresearch.com/docs/reference/skills-catalog
- https://hermes-agent.nousresearch.com/docs/reference/optional-skills-catalog
使用技能
每个已安装的技能都会自动作为斜杠命令可用:
# 在CLI或任何消息平台中:/gif-search funny cats/axolotl help me fine-tune Llama 3 on my dataset/github-pr-workflow create a PR for the auth refactor/plan design a rollout for migrating our auth provider# 仅输入技能名称会加载该技能并让代理询问您的需求:/excalidraw捆绑的plan技能是基于技能的斜杠命令自定义行为的很好示例。运行/plan [请求]会让 Hermes 在需要时检查上下文,编写 Markdown 格式的实现计划而不是直接执行任务,并将结果保存在当前工作区/后端工作目录下的.hermes/plans/目录中。
您也可以通过自然对话与技能交互:
hermes chat --toolsets skills -q "What skills do you have?"hermes chat --toolsets skills -q "Show me the axolotl skill"渐进式披露
技能使用令牌高效的加载模式:
Level 0: skills_list() → [{name, description, category}, ...] (~3k tokens)Level 1: skill_view(name) → Full content + metadata (varies)Level 2: skill_view(name, path) → Specific reference file (varies)代理只有在实际需要时才会加载完整的技能内容。
SKILL.md 格式
---name: my-skilldescription: Brief description of what this skill doesversion: 1.0.0platforms: [macos, linux] # 可选 — 限制仅在特定操作系统平台可用metadata: hermes: tags: [python, automation] category: devops fallback_for_toolsets: [web] # 可选 — 条件激活(见下文) requires_toolsets: [terminal] # 可选 — 条件激活(见下文) config: # 可选 — config.yaml 设置 - key: my.setting description: "What this controls" default: "value" prompt: "Prompt for setup"---# 技能标题## 适用场景该技能的触发条件。## 操作步骤1. 第一步2. 第二步## 注意事项- 已知的失败模式和修复方案## 验证方法如何确认操作成功。平台特定技能
技能可以使用platforms字段限制仅在特定操作系统上可用:
| 值 | 匹配系统 |
| macos | macOS (Darwin) |
| linux | Linux |
| windows | Windows |
platforms: [macos] # 仅支持macOS(例如iMessage、Apple Reminders、FindMy相关技能)platforms: [macos, linux] # 支持macOS和Linux设置该字段后,在不兼容的平台上,该技能会自动从系统提示、skills_list()返回结果和斜杠命令中隐藏。如果省略该字段,技能会在所有平台上加载。
条件激活(回退技能)
技能可以根据当前会话中可用的工具自动显示或隐藏。这对于回退技能尤其有用——当高级工具不可用时,免费或本地的替代方案会自动出现。
metadata: hermes: fallback_for_toolsets: [web] # 仅当这些工具集不可用时显示 requires_toolsets: [terminal] # 仅当这些工具集可用时显示 fallback_for_tools: [web_search] # 仅当这些特定工具不可用时显示 requires_tools: [terminal] # 仅当这些特定工具可用时显示| 字段 | 行为 |
| fallback_for_toolsets | 当列出的工具集可用时,技能 |
| fallback_for_tools | 同上,但检查单个工具而不是工具集。 |
| requires_toolsets | 当列出的工具集不可用时,技能 |
| requires_tools | 同上,但检查单个工具。 |
示例: 内置的duckduckgo-search技能使用fallback_for_toolsets: [web]。当您设置了FIRECRAWL_API_KEY时,web工具集可用,代理会使用web_search——DuckDuckGo技能保持隐藏。如果缺少API密钥,web工具集不可用,DuckDuckGo技能会自动作为回退选项出现。
没有任何条件字段的技能行为和之前完全一致——始终显示。
加载时的安全设置
技能可以声明所需的环境变量,而不会从发现列表中消失:
required_environment_variables: - name: TENOR_API_KEY prompt: Tenor API key help: Get a key from https://developers.google.com/tenor required_for: full functionality当遇到缺失的值时,Hermes只会在本地CLI中实际加载技能时安全地询问您。您可以跳过设置并继续使用该技能。消息平台永远不会在聊天中询问密钥——它们会提示您在本地使用hermes setup或编辑~/.hermes/.env进行配置。
设置完成后,声明的环境变量会自动传递到execute_code和terminal沙箱中——技能的脚本可以直接使用$TENOR_API_KEY。对于非技能环境变量,请使用terminal.env_passthrough配置选项。
详情请参阅https://hermes-agent.nousresearch.com/docs/user-guide/security#environment-variable-passthrough。
技能配置设置
技能还可以声明存储在config.yaml中的非机密配置设置(路径、偏好设置):
metadata: hermes: config: - key: wiki.path description: Path to the wiki directory default: "~/wiki" prompt: Wiki directory path设置存储在config.yaml的skills.config下。hermes config migrate会提示配置未设置的选项,hermes config show会显示这些设置。当技能加载时,其解析后的配置值会注入到上下文中,因此代理会自动知道配置的值。
详情请参阅https://hermes-agent.nousresearch.com/docs/user-guide/configuration#skill-settings和https://hermes-agent.nousresearch.com/docs/developer-guide/creating-skills#config-settings-configyaml。
技能目录结构
~/.hermes/skills/ # 唯一可信来源├── mlops/ # 分类目录│ ├── axolotl/│ │ ├── SKILL.md # 主说明文件(必需)│ │ ├── references/ # 额外文档│ │ ├── templates/ # 输出格式模板│ │ ├── scripts/ # 可从技能调用的辅助脚本│ │ └── assets/ # 补充文件│ └── vllm/│ └── SKILL.md├── devops/│ └── deploy-k8s/ # 代理创建的技能│ ├── SKILL.md│ └── references/├── .hub/ # 技能中心状态│ ├── lock.json│ ├── quarantine/│ └── audit.log└── .bundled_manifest # 跟踪已安装的捆绑技能外部技能目录
如果您在Hermes之外维护技能——例如,多个AI工具共享的~/.agents/skills/目录——您可以让Hermes也扫描这些目录。
在~/.hermes/config.yaml的skills部分添加external_dirs:
skills: external_dirs: - ~/.agents/skills - /home/shared/team-skills - ${SKILLS_REPO}/skills路径支持~展开和${VAR}环境变量替换。
工作原理
- 只读:外部目录仅用于技能发现扫描。当代理创建或编辑技能时,始终写入~/.hermes/skills/目录。
- 本地优先:如果本地目录和外部目录中存在同名技能,本地版本优先。
- 完全集成:外部技能会出现在系统提示索引、skills_list、skill_view返回结果中,并且可以作为/skill-name斜杠命令使用——和本地技能没有区别。
- 不存在的路径会被静默跳过:如果配置的目录不存在,Hermes会忽略它而不会报错。这对于可能不在每台机器上都存在的可选共享目录非常有用。
示例
~/.hermes/skills/ # 本地(主目录,读写)├── devops/deploy-k8s/│ └── SKILL.md└── mlops/axolotl/ └── SKILL.md~/.agents/skills/ # 外部(只读,共享)├── my-custom-workflow/│ └── SKILL.md└── team-conventions/ └── SKILL.md所有四个技能都会出现在您的技能索引中。如果您在本地创建一个名为my-custom-workflow的新技能,它会覆盖外部版本。
代理管理的技能(skill_manage工具)
代理可以通过skill_manage工具创建、更新和删除自己的技能。这是代理的程序记忆——当它找出一个复杂的工作流程时,会将该方法保存为技能供未来复用。
代理创建技能的时机
- 成功完成复杂任务(5+次工具调用)后
- 遇到错误或死胡同并找到可行路径时
- 用户纠正其方法时
- 发现非平凡的工作流程时
操作
| 操作 | 用途 | 关键参数 |
| create | 从零创建新技能 | name |
| patch | 定向修复(首选) | name |
| edit | 重大结构重写 | name |
| delete | 完全删除技能 | name |
| write_file | 添加/更新支持文件 | name |
| remove_file | 删除支持文件 | name |
大象提示patch操作是更新的首选——它比edit更节省令牌,因为工具调用中仅包含变更的文本。
技能中心
可以从在线注册中心、skills.sh、直接well-known技能端点和官方可选技能中浏览、搜索、安装和管理技能。
常用命令
hermes skills browse # 浏览所有中心技能(官方优先)hermes skills browse --source official # 仅浏览官方可选技能hermes skills search kubernetes # 搜索所有来源hermes skills search react --source skills-sh # 搜索skills.sh目录hermes skills search https://mintlify.com/docs --source well-knownhermes skills inspect openai/skills/k8s # 安装前预览hermes skills install openai/skills/k8s # 带安全扫描安装hermes skills install official/security/1passwordhermes skills install skills-sh/vercel-labs/json-render/json-render-react --forcehermes skills install well-known:https://mintlify.com/docs/.well-known/skills/mintlifyhermes skills list --source hub # 列出从中心安装的技能hermes skills check # 检查已安装的中心技能是否有上游更新hermes skills update # 重新安装有上游变更的中心技能hermes skills audit # 重新扫描所有中心技能的安全性hermes skills uninstall k8s # 移除中心技能hermes skills publish skills/my-skill --to github --repo owner/repohermes skills snapshot export setup.json # 导出技能配置hermes skills tap add myorg/skills-repo # 添加自定义GitHub源支持的中心来源
| 来源 | 示例 | 说明 |
| official | official/security/1password | 随Hermes发布的可选技能。 |
| skills-sh | skills-sh/vercel-labs/agent-skills/vercel-react-best-practices | 可通过 |
| well-known | well-known:https://mintlify.com/docs/.well-known/skills/mintlify | 直接从网站的 |
| github | openai/skills/k8s | 直接GitHub代码库/路径安装和自定义tap。 |
| clawhub | 来源特定标识符 | 社区或市场集成。 |
集成的中心和注册中心
Hermes目前集成了以下技能生态系统和发现来源:
1. 官方可选技能(official)
这些技能在Hermes代码库中维护,安装时内置信任。
- 目录:https://hermes-agent.nousresearch.com/docs/reference/optional-skills-catalog
- 代码库中的位置:optional-skills/
- 示例:
hermes skills browse --source officialhermes skills install official/security/1password2. skills.sh(skills-sh)
这是Vercel的公共技能目录。Hermes可以直接搜索它、查看技能详情页面、解析别名样式的slug,并从底层源仓库安装。
- 目录:https://skills.sh/
- CLI/工具仓库:https://github.com/vercel-labs/skills
- Vercel官方技能仓库:https://github.com/vercel-labs/agent-skills
- 示例:
hermes skills search react --source skills-shhermes skills inspect skills-sh/vercel-labs/json-render/json-render-reacthermes skills install skills-sh/vercel-labs/json-render/json-render-react --force3. Well-known技能端点(well-known)
这是基于URL的发现机制,从发布了/.well-known/skills/index.json的站点获取技能。它不是单一的集中中心,而是一种Web发现约定。
- 示例活动端点:https://mintlify.com/docs/.well-known/skills/index.json
- 参考服务器实现:https://github.com/vercel-labs/skills-handler
- 示例:
hermes skills search https://mintlify.com/docs --source well-knownhermes skills inspect well-known:https://mintlify.com/docs/.well-known/skills/mintlifyhermes skills install well-known:https://mintlify.com/docs/.well-known/skills/mintlify4. 直接GitHub技能(github)
Hermes可以直接从GitHub仓库和基于GitHub的tap安装。当您已经知道仓库/路径或者想要添加自己的自定义源仓库时,这非常有用。
默认tap(无需任何设置即可浏览):
- https://github.com/openai/skills
- https://github.com/anthropics/skills
- https://github.com/VoltAgent/awesome-agent-skills
- https://github.com/garrytan/gstack
- 示例:
hermes skills install openai/skills/k8shermes skills tap add myorg/skills-repo5. ClawHub(clawhub)
第三方技能市场,作为社区来源集成。
- 网站:https://clawhub.ai/
- Hermes来源ID:clawhub
6. Claude市场风格仓库(claude-marketplace)
Hermes支持发布Claude兼容插件/市场清单的市场仓库。已知集成来源包括:
- https://github.com/anthropics/skills
- https://github.com/aiskillstore/marketplaceHermes来源ID:claude-marketplace
7. LobeHub(lobehub)
Hermes可以搜索LobeHub公共目录中的代理条目,并将其转换为可安装的Hermes技能。
- 网站:https://lobehub.com/
- 公共代理索引:https://chat-agents.lobehub.com/
- 底层仓库:https://github.com/lobehub/lobe-chat-agents
- Hermes来源ID:lobehub
安全扫描和--force
所有从中心安装的技能都会经过安全扫描器检查,查找数据泄露、提示注入、破坏性命令、供应链信号和其他威胁。
hermes skills inspect ...现在还会在可用时显示上游元数据:
- 仓库URL
- skills.sh详情页面URL
- 安装命令
- 周安装量
- 上游安全审计状态
- well-known索引/端点URL
当您已审核第三方技能并希望覆盖非危险策略阻止时,使用--force:
hermes skills install skills-sh/anthropics/skills/pdf --force重要行为:
- --force可以覆盖谨慎/警告类发现的策略阻止。
- --force不能覆盖dangerous扫描结论。
- 官方可选技能(official/...)被视为内置信任,不会显示第三方警告面板。
信任级别
| 级别 | 来源 | 策略 |
| builtin | 随Hermes发布 | 始终信任 |
| official | 代码库中的 | 内置信任,无第三方警告 |
| trusted | 可信注册中心/仓库,例如 | 比社区来源更宽松的策略 |
| community | 所有其他来源( | 非危险发现可以使用 |
更新生命周期
中心现在跟踪足够的来源信息,可以重新检查已安装技能的上游副本:
hermes skills check # 报告哪些已安装的中心技能在上游有变更hermes skills update # 仅重新安装有可用更新的技能hermes skills update react # 更新一个特定的已安装中心技能这使用存储的来源标识符加上当前上游包内容哈希来检测变更。
斜杠命令(聊天内)
所有相同的命令都可以通过/skills使用:
/skills browse/skills search react --source skills-sh/skills search https://mintlify.com/docs --source well-known/skills inspect skills-sh/vercel-labs/json-render/json-render-react/skills install openai/skills/skill-creator --force/skills check/skills update/skills list官方可选技能仍然使用类似official/security/1password和official/migration/openclaw-migration的标识符。
第18章 持久化内存
Hermes Agent 拥有边界清晰、经过整理的内存,可以跨会话持久化存储。这让它能够记住您的偏好、项目信息、环境配置以及学到的知识。
工作原理
代理的内存由两个文件组成:
| 文件 | 用途 | 字符限制 |
| MEMORY.md | 代理的个人笔记——环境信息、约定规则、学到的知识 | 2,200 字符(约800令牌) |
| USER.md | 用户配置文件——您的偏好、沟通风格、期望要求 | 1,375 字符(约500令牌) |
这两个文件都存储在~/.hermes/memories/目录下,会话启动时会作为静态快照注入到系统提示中。代理通过memory工具管理自己的内存——可以添加、替换或删除条目。
信息字符限制让内存保持聚焦。当内存已满时,代理会合并或替换条目,为新信息腾出空间。
内存在系统提示中的呈现方式
每个会话开始时,内存条目会从磁盘加载,并作为静态块渲染到系统提示中:
══════════════════════════════════════════════MEMORY (your personal notes) [67% — 1,474/2,200 chars]══════════════════════════════════════════════User's project is a Rust web service at ~/code/myapi using Axum + SQLx§This machine runs Ubuntu 22.04, has Docker and Podman installed§User prefers concise responses, dislikes verbose explanations格式包含:
- 头部说明存储类型(MEMORY或USER PROFILE)
- 使用百分比和字符计数,让代理知道容量情况
- 各个条目用§(章节符号)分隔
- 条目可以是多行的
静态快照模式: 系统提示注入在会话开始时捕获一次,会话期间不会更改。这是有意设计的——它保留了LLM的前缀缓存以提升性能。当代理在会话期间添加/删除内存条目时,更改会立即持久化到磁盘,但直到下一次会话启动才会出现在系统提示中。工具响应始终显示实时状态。
内存工具操作
代理使用memory工具执行以下操作:
- add — 添加新的内存条目
- replace — 用更新的内容替换现有条目(通过old_text进行子串匹配)
- remove — 删除不再相关的条目(通过old_text进行子串匹配)
没有read操作——内存内容会在会话开始时自动注入到系统提示中。代理将其内存视为对话上下文的一部分。
子串匹配
replace和remove操作使用简短的唯一子串匹配——您不需要完整的条目文本。old_text参数只需要是能够唯一标识一个条目的子串即可:
# 如果内存包含"User prefers dark mode in all editors"memory(action="replace", target="memory", old_text="dark mode", content="User prefers light mode in VS Code, dark mode in terminal")如果子串匹配多个条目,会返回错误,要求提供更具体的匹配内容。
两个目标存储说明
memory — 代理的个人笔记
用于存储代理需要记住的环境、工作流和经验教训相关信息:
- 环境信息(操作系统、工具、项目结构)
- 项目约定和配置
- 发现的工具特性和 workaround
- 已完成任务的日志条目
- 有效的技能和技术
user — 用户配置文件
用于存储用户身份、偏好和沟通风格相关信息:
- 姓名、角色、时区
- 沟通偏好(简洁 vs 详细、格式偏好)
- 忌讳和需要避免的内容
- 工作流习惯
- 技术技能水平
应该保存和跳过的内容
主动保存这些内容
代理会自动保存,您不需要主动要求。当它学到以下内容时会保存:
- 用户偏好: "我更喜欢TypeScript而不是JavaScript" → 保存到user
- 环境信息: "这台服务器运行Debian 12,安装了PostgreSQL 16" → 保存到memory
- 纠正信息: "Docker命令不要用sudo,用户已经在docker组里" → 保存到memory
- 约定规则: "项目使用制表符缩进,行宽120字符,Google风格文档字符串" → 保存到memory
- 已完成工作: "2026-01-15完成了数据库从MySQL到PostgreSQL的迁移" → 保存到memory
- 明确要求: "记住我的API密钥每月轮换一次" → 保存到memory
跳过这些内容
- 琐碎/明显的信息: "用户询问了Python相关问题" — 太模糊,没有用处
- 容易重新获取的信息: "Python 3.12支持f-string嵌套" — 可以通过网页搜索获取
- 原始数据转储: 大的代码块、日志文件、数据表 — 内存放不下
- 特定会话的临时信息: 临时文件路径、一次性调试上下文
- 已经在上下文文件中的信息: SOUL.md和AGENTS.md的内容
容量管理
内存有严格的字符限制,以保持系统提示的边界:
| 存储 | 限制 | 典型条目数量 |
| memory | 2,200 字符 | 8-15条 |
| user | 1,375 字符 | 5-10条 |
内存已满时的处理
当您尝试添加的条目会超出限制时,工具会返回错误:
{ "success": false, "error": "Memory at 2,100/2,200 chars. Adding this entry (250 chars) would exceed the limit. Replace or remove existing entries first.", "current_entries": ["..."], "usage": "2,100/2,200"}代理此时应该:
1. 读取当前条目(显示在错误响应中) 2. 识别可以删除或合并的条目 3. 使用replace将相关条目合并为更短的版本 4. 然后add新条目
最佳实践: 当内存使用率超过80%(在系统提示头部可见)时,在添加新条目之前先合并现有条目。例如,将三个独立的"项目使用X"条目合并为一个全面的项目描述条目。
优秀内存条目示例
紧凑、信息密度高的条目效果最好:
# 好:包含多个相关事实User runs macOS 14 Sonoma, uses Homebrew, has Docker Desktop and Podman. Shell: zsh with oh-my-zsh. Editor: VS Code with Vim keybindings.# 好:具体、可操作的约定Project ~/code/api uses Go 1.22, sqlc for DB queries, chi router. Run tests with 'make test'. CI via GitHub Actions.# 好:带上下文的经验教训The staging server (10.0.1.50) needs SSH port 2222, not 22. Key is at ~/.ssh/staging_ed25519.# 不好:太模糊User has a project.# 不好:太冗长On January 5th, 2026, the user asked me to look at their project which islocated at ~/code/api. I discovered it uses Go version 1.22 and...重复条目预防
内存系统会自动拒绝完全重复的条目。如果您尝试添加已存在的内容,会返回成功并提示"未添加重复条目"。
安全扫描
内存条目在被接受前会经过注入和泄露模式扫描,因为它们会被注入到系统提示中。匹配威胁模式(提示注入、凭证泄露、SSH后门)或包含不可见Unicode字符的内容会被阻止。
会话搜索
除了MEMORY.md和USER.md之外,代理还可以使用session_search工具搜索过去的对话:
- 所有CLI和消息平台会话都存储在SQLite数据库(~/.hermes/state.db)中,支持FTS5全文搜索
- 搜索查询返回相关的历史对话,并使用Gemini Flash进行摘要
- 代理可以找到几周前讨论的内容,即使这些内容不在活动内存中
hermes sessions list # 浏览历史会话session_search 与 内存的对比
| 特性 | 持久化内存 | 会话搜索 |
| 容量 | 总计约1,300令牌 | 无限制(所有会话) |
| 速度 | 即时(在系统提示中) | 需要搜索 + LLM摘要 |
| 使用场景 | 始终需要在上下文中的关键事实 | 查找特定的历史对话 |
| 管理方式 | 由代理手动整理 | 自动存储所有会话 |
| 令牌成本 | 每个会话固定(约1,300令牌) | 按需消耗(仅在需要搜索时) |
内存用于存储始终需要在上下文中的关键事实。会话搜索用于"我们上周有没有讨论过X?"这类查询,代理需要回忆历史对话的具体内容。
配置
# 在 ~/.hermes/config.yaml 中memory: memory_enabled: true user_profile_enabled: true memory_char_limit: 2200 # 约800令牌 user_char_limit: 1375 # 约500令牌外部内存提供商
对于超出MEMORY.md和USER.md能力的深度持久化内存需求,Hermes自带8个外部内存提供商插件——包括Honcho、OpenViking、Mem0、Hindsight、Holographic、RetainDB、ByteRover和Supermemory。
外部提供商与内置内存并行运行(永远不会替代它),并添加知识图谱、语义搜索、自动事实提取和跨会话用户建模等能力。
hermes memory setup # 选择并配置提供商hermes memory status # 检查活跃的内存提供商请参阅https://hermes-agent.nousresearch.com/docs/user-guide/features/memory-providers指南,了解每个提供商的完整详情、设置说明和对比。
第19章 上下文文件
Hermes Agent 会自动发现并加载上下文文件,这些文件决定了代理的行为方式。其中一部分是项目本地文件,从工作目录中发现。SOUL.md现在是Hermes实例的全局文件,仅从HERMES_HOME目录加载。
支持的上下文文件
| 文件 | 用途 | 发现方式 |
| .hermes.md | 项目说明(最高优先级) | 向上遍历到git根目录 |
| AGENTS.md | 项目说明、约定、架构 | 启动时的当前工作目录 + 逐步发现子目录 |
| CLAUDE.md | Claude Code上下文文件(也会被检测) | 启动时的当前工作目录 + 逐步发现子目录 |
| SOUL.md | Hermes实例的全局个性和语气定制 | 仅从 |
| .cursorrules | Cursor IDE编码约定 | 仅当前工作目录 |
| .cursor/rules/*.mdc | Cursor IDE规则模块 | 仅当前工作目录 |
优先级系统
每个会话仅加载一个项目上下文类型(第一个匹配的获胜):.hermes.md → AGENTS.md → CLAUDE.md → .cursorrules。SOUL.md始终作为代理身份(插槽#1)独立加载。
AGENTS.md
AGENTS.md是主要的项目上下文文件。它告诉代理项目的结构、需要遵循的约定以及任何特殊说明。
渐进式子目录发现
会话启动时,Hermes会将工作目录中的AGENTS.md加载到系统提示中。当代理在会话期间导航到子目录时(通过read_file、terminal、search_files等操作),它会逐步发现这些目录中的上下文文件,并在相关时注入到对话中。
my-project/├── AGENTS.md ← 启动时加载(系统提示)├── frontend/│ └── AGENTS.md ← 当代理读取frontend/目录下的文件时发现├── backend/│ └── AGENTS.md ← 当代理读取backend/目录下的文件时发现└── shared/ └── AGENTS.md ← 当代理读取shared/目录下的文件时发现这种方法相比启动时加载所有内容有两个优势:
- 不会导致系统提示臃肿 —— 子目录提示仅在需要时出现
- 保留提示缓存 —— 系统提示在多轮对话中保持稳定
每个子目录每个会话最多检查一次。发现过程也会向上遍历父目录,因此读取backend/src/main.py时会发现backend/AGENTS.md,即使backend/src/没有自己的上下文文件。
信息子目录上下文文件会经过与启动上下文文件相同的安全扫描。恶意文件会被阻止。
AGENTS.md示例
# 项目上下文这是一个Next.js 14 Web应用,后端使用Python FastAPI。## 架构- 前端:Next.js 14,使用App Router,位于`/frontend`目录- 后端:FastAPI,位于`/backend`目录,使用SQLAlchemy ORM- 数据库:PostgreSQL 16- 部署:Hetzner VPS上的Docker Compose## 约定- 所有前端代码使用TypeScript严格模式- Python代码遵循PEP 8规范,所有地方使用类型提示- 所有API端点返回JSON格式为`{data, error, meta}`- 测试文件放在`__tests__/`目录(前端)或`tests/`目录(后端)## 重要注意事项- 不要直接修改迁移文件 —— 使用Alembic命令- `.env.local`文件包含真实API密钥,不要提交到代码库- 前端端口3000,后端端口8000,数据库端口5432SOUL.md
SOUL.md控制代理的个性、语气和沟通风格。完整详情请参阅https://hermes-agent.nousresearch.com/docs/user-guide/features/personality页面。
位置:
- ~/.hermes/SOUL.md
- 如果使用自定义主目录运行Hermes,则为$HERMES_HOME/SOUL.md
重要说明:
- 如果SOUL.md不存在,Hermes会自动生成一个默认版本
- Hermes仅从HERMES_HOME加载SOUL.md
- Hermes不会在工作目录中查找SOUL.md
- 如果文件为空,不会向提示中添加任何SOUL.md内容
- 如果文件有内容,经过扫描和截断后会原样注入到提示中
.cursorrules
Hermes兼容Cursor IDE的.cursorrules文件和.cursor/rules/*.mdc规则模块。如果这些文件存在于项目根目录,且没有找到更高优先级的上下文文件(.hermes.md、AGENTS.md或CLAUDE.md),它们会被加载为项目上下文。
这意味着使用Hermes时,您现有的Cursor约定会自动生效。
上下文文件的加载方式
启动时(系统提示)
上下文文件由agent/prompt_builder.py中的build_context_files_prompt()函数加载:
1. 扫描工作目录 —— 检查.hermes.md → AGENTS.md → CLAUDE.md → .cursorrules(第一个匹配的获胜) 2. 读取内容 —— 每个文件以UTF-8文本格式读取 3. 安全扫描 —— 检查内容是否存在提示注入模式 4. 截断 —— 超过20,000字符的文件会进行首尾截断(70%头部,20%尾部,中间有标记) 5. 组装 —— 所有部分组合在# Project Context标题下 6. 注入 —— 组装后的内容添加到系统提示中
会话期间(渐进式发现)
agent/subdirectory_hints.py中的SubdirectoryHintTracker会监视工具调用参数中的文件路径:
1. 路径提取 —— 每次工具调用后,从参数(path、workdir、shell命令)中提取文件路径 2. 祖先目录遍历 —— 检查该目录和最多5级父目录(在已经访问过的目录处停止) 3. 加载提示 —— 如果发现AGENTS.md、CLAUDE.md或.cursorrules则加载(每个目录第一个匹配的获胜) 4. 安全扫描 —— 与启动文件相同的提示注入扫描 5. 截断 —— 每个文件最多8,000字符 6. 注入 —— 追加到工具结果中,让模型自然地在上下文中看到它
最终的提示部分大致如下:
# 项目上下文已加载以下项目上下文文件,请遵守:## AGENTS.md[您的AGENTS.md内容在这里]## .cursorrules[您的.cursorrules内容在这里][您的SOUL.md内容在这里]请注意,SOUL内容是直接插入的,没有额外的包装文本。
安全:提示注入防护
所有上下文文件在被包含前都会经过潜在提示注入扫描。扫描器会检查:
- 指令覆盖尝试:"ignore previous instructions"、"disregard your rules"
- 欺骗模式:"do not tell the user"
- 系统提示覆盖:"system prompt override"
- 隐藏HTML注释:<!-- ignore instructions -->
- 隐藏div元素:<div style="display:none">
- 凭证泄露:curl ... $API_KEY
- 机密文件访问:cat .env、cat credentials
- 不可见字符:零宽空格、双向覆盖、词连接符
如果检测到任何威胁模式,文件会被阻止:
[已阻止:AGENTS.md包含潜在提示注入(prompt_injection)。内容未加载。]警告该扫描器可以防范常见的注入模式,但不能替代对共享仓库中上下文文件的审查。对于非您自己编写的项目,始终要验证AGENTS.md的内容。
大小限制
| 限制 | 值 |
| 每个文件最大字符数 | 20,000(约7,000令牌) |
| 头部截断比例 | 70% |
| 尾部截断比例 | 20% |
| 截断标记 | 10%(显示字符计数并建议使用文件工具读取完整文件) |
当文件超过20,000字符时,截断消息如下:
[...已截断AGENTS.md:保留25000字符中的14000+4000字符。使用文件工具读取完整文件。]有效使用上下文文件的技巧
AGENTS.md最佳实践
1. 保持简洁 —— 远低于20K字符;代理每轮对话都会读取它 2. 使用标题结构化 —— 用##小节划分架构、约定、重要注意事项 3. 包含具体示例 —— 展示首选的代码模式、API结构、命名约定 4 说明禁止事项 —— "永远不要直接修改迁移文件" 5. 列出关键路径和端口 —— 代理会在终端命令中使用这些信息 6. 随项目演进更新 —— 过时的上下文比没有上下文更糟糕
子目录上下文
对于 monorepo,在嵌套的AGENTS.md文件中放入子目录特定的说明:
# 前端上下文- 使用`pnpm`而非`npm`进行包管理- 组件放在`src/components/`,页面放在`src/app/`- 使用Tailwind CSS,不要使用内联样式- 运行测试用`pnpm test`# 后端上下文- 使用`poetry`进行依赖管理- 运行开发服务器用`poetry run uvicorn main:app --reload`- 所有端点需要OpenAPI文档字符串- 数据库模型在`models/`目录,模式在`schemas/`目录第20章 MCP(模型上下文协议)
MCP让Hermes Agent能够连接到外部工具服务器,这样代理就可以使用Hermes本身之外的工具——GitHub、数据库、文件系统、浏览器栈、内部API等等。
如果您希望Hermes使用已经存在于其他地方的工具,MCP通常是最简洁的实现方式。
MCP的优势
- 无需先编写原生Hermes工具即可访问外部工具生态系统
- 同一个配置中同时支持本地stdio服务器和远程HTTP MCP服务器
- 启动时自动发现和注册工具
- 当服务器支持时,提供MCP资源和提示的实用包装器
- 支持按服务器过滤,这样您可以只向Hermes公开实际需要的MCP工具
快速开始
1. 安装MCP支持(如果您使用标准安装脚本,已经包含该功能):
cd ~/.hermes/hermes-agentuv pip install -e ".[mcp]"2. 在~/.hermes/config.yaml中添加MCP服务器:
mcp_servers: filesystem: command: "npx" args: ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/projects"]3. 启动Hermes:
hermes chat4 让Hermes使用MCP支持的功能。例如:
列出/home/user/projects中的文件并总结代码库结构。Hermes会发现MCP服务器的工具,并像使用其他工具一样使用它们。
两种MCP服务器
Stdio服务器
Stdio服务器作为本地子进程运行,通过stdin/stdout进行通信。
mcp_servers: github: command: "npx" args: ["-y", "@modelcontextprotocol/server-github"] env: GITHUB_PERSONAL_ACCESS_TOKEN: "***"适合以下场景使用stdio服务器:
- 服务器安装在本地
- 您需要低延迟访问本地资源
- 您遵循的MCP服务器文档展示了command、args和env配置
HTTP服务器
HTTP MCP服务器是Hermes直接连接的远程端点。
mcp_servers: remote_api: url: "https://mcp.example.com/mcp" headers: Authorization: "Bearer ***"适合以下场景使用HTTP服务器:
- MCP服务器托管在其他地方
- 您的组织公开了内部MCP端点
- 您不希望Hermes为该集成生成本地子进程
基础配置参考
Hermes从~/.hermes/config.yaml的mcp_servers部分读取MCP配置。
通用配置项
| 配置项 | 类型 | 含义 |
| command | 字符串 | stdio MCP服务器的可执行文件 |
| args | 列表 | stdio服务器的参数 |
| env | 映射 | 传递给stdio服务器的环境变量 |
| url | 字符串 | HTTP MCP端点 |
| headers | 映射 | 远程服务器的HTTP头 |
| timeout | 数字 | 工具调用超时时间 |
| connect_timeout | 数字 | 初始连接超时时间 |
| enabled | 布尔值 | 如果为 |
| tools | 映射 | 按服务器的工具过滤和实用策略 |
最小stdio示例
mcp_servers: filesystem: command: "npx" args: ["-y", "@modelcontextprotocol/server-filesystem", "/tmp"]最小HTTP示例
mcp_servers: company_api: url: "https://mcp.internal.example.com" headers: Authorization: "Bearer ***"Hermes如何注册MCP工具
Hermes会为MCP工具添加前缀,避免与内置工具名称冲突:
mcp__ 示例:
| 服务器 | MCP工具 | 注册名称 |
| filesystem | read_file | mcp_filesystem_read_file |
| github | create-issue | mcp_github_create_issue |
| my-api | query.data | mcp_my_api_query_data |
实际上,您通常不需要手动调用带前缀的名称——Hermes会在正常推理过程中发现并选择该工具。
MCP实用工具
当支持时,Hermes还会围绕MCP资源和提示注册实用工具:
- list_resources
- read_resource
- list_prompts
- get_prompt
这些工具按照相同的前缀模式按服务器注册,例如:
- mcp_github_list_resources
- mcp_github_get_prompt
重要说明
这些实用工具现在支持能力感知:
- 只有当MCP会话实际支持资源操作时,Hermes才会注册资源实用工具
- 只有当MCP会话实际支持提示操作时,Hermes才会注册提示实用工具
因此,一个仅公开可调用工具但不提供资源/提示的服务器不会获得这些额外的包装器。
按服务器过滤
您可以控制每个MCP服务器向Hermes提供哪些工具,实现对工具命名空间的精细管理。
完全禁用某个服务器
mcp_servers: legacy: url: "https://mcp.legacy.internal" enabled: false如果enabled: false,Hermes会完全跳过该服务器,甚至不会尝试连接。
白名单服务器工具
mcp_servers: github: command: "npx" args: ["-y", "@modelcontextprotocol/server-github"] env: GITHUB_PERSONAL_ACCESS_TOKEN: "***" tools: include: [create_issue, list_issues]只有这些MCP服务器工具会被注册。
黑名单服务器工具
mcp_servers: stripe: url: "https://mcp.stripe.com" tools: exclude: [delete_customer]除了被排除的工具外,所有服务器工具都会被注册。
优先级规则
如果同时存在白名单和黑名单:
tools: include: [create_issue] exclude: [create_issue, delete_issue]include优先级更高。
过滤实用工具
您也可以单独禁用Hermes添加的实用包装器:
mcp_servers: docs: url: "https://mcp.docs.example.com" tools: prompts: false resources: false这意味着:
- tools.resources: false会禁用list_resources和read_resource
- tools.prompts: false会禁用list_prompts和get_prompt
完整示例
mcp_servers: github: command: "npx" args: ["-y", "@modelcontextprotocol/server-github"] env: GITHUB_PERSONAL_ACCESS_TOKEN: "***" tools: include: [create_issue, list_issues, search_code] prompts: false stripe: url: "https://mcp.stripe.com" headers: Authorization: "Bearer ***" tools: exclude: [delete_customer] resources: false legacy: url: "https://mcp.legacy.internal" enabled: false如果所有工具都被过滤掉会发生什么?
如果您的配置过滤了所有可调用工具,并且禁用或省略了所有支持的实用工具,Hermes不会为该服务器创建空的运行时MCP工具集。这样可以保持工具列表整洁。
运行时行为
发现时机
Hermes在启动时发现MCP服务器,并将它们的工具注册到常规工具注册表中。
动态工具发现
MCP服务器可以在运行时通过发送notifications/tools/list_changed通知,告知Hermes其可用工具发生了变化。当Hermes收到此通知时,会自动重新获取服务器的工具列表并更新注册表——无需手动执行/reload-mcp。
这对于工具能力会动态变化的MCP服务器非常有用(例如,加载新的数据库模式时添加工具,或者服务离线时移除工具的服务器)。
刷新操作有锁保护,因此来自同一服务器的快速连续通知不会导致重叠刷新。提示和资源变更通知(prompts/list_changed、resources/list_changed)会被接收但尚未处理。
重新加载
如果您修改了MCP配置,使用:
/reload-mcp这会从配置重新加载MCP服务器并刷新可用工具列表。对于服务器主动推送的运行时工具变更,请参阅上文的动态工具发现。
工具集
每个配置的MCP服务器在提供至少一个注册工具时,也会创建一个运行时工具集:
mcp-这使得在工具集层面管理MCP服务器更加容易。
安全模型
Stdio环境变量过滤
对于stdio服务器,Hermes不会盲目传递您的完整shell环境。只有显式配置的env加上安全的基础环境变量会被传递。这减少了意外的密钥泄露。
配置级暴露控制
新的过滤支持也是一种安全控制手段:
- 禁用您不希望模型看到的危险工具
- 仅为敏感服务器暴露最小白名单
- 当您不希望暴露相关功能时,禁用资源/提示包装器
示例用例
仅暴露最小issue管理功能的GitHub服务器
mcp_servers: github: command: "npx" args: ["-y", "@modelcontextprotocol/server-github"] env: GITHUB_PERSONAL_ACCESS_TOKEN: "***" tools: include: [list_issues, create_issue, update_issue] prompts: false resources: false使用方式:
显示标记为bug的未解决issue,然后为不稳定的MCP重连行为起草一个新issue。移除危险操作的Stripe服务器
mcp_servers: stripe: url: "https://mcp.stripe.com" headers: Authorization: "Bearer ***" tools: exclude: [delete_customer, refund_payment]使用方式:
查找最近10笔失败的支付,并总结常见失败原因。仅服务单个项目根目录的文件系统服务器
mcp_servers: project_fs: command: "npx" args: ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/my-project"]使用方式:
检查项目根目录并说明目录结构。故障排除
MCP服务器连接失败
检查:
# 验证MCP依赖已安装(标准安装中已包含)cd ~/.hermes/hermes-agent && uv pip install -e ".[mcp]"node --versionnpx --version然后验证您的配置并重启Hermes。
工具没有出现
可能的原因:
- 服务器连接失败
- 发现过程失败
- 您的过滤配置排除了这些工具
- 该服务器上不存在对应的实用功能
- 服务器通过enabled: false被禁用
如果您是故意过滤的,这属于预期行为。
为什么资源或提示实用工具没有出现?
因为Hermes现在只有在同时满足以下两个条件时才会注册这些包装器:
1. 您的配置允许它们 2. 服务器会话实际支持该功能
这是有意设计的,可以保持工具列表的真实性。
MCP采样支持
MCP服务器可以通过sampling/createMessage协议向Hermes请求LLM推理。这允许MCP服务器要求Hermes代表其生成文本——对于需要LLM能力但没有自己模型访问权限的服务器非常有用。
采样功能默认对所有MCP服务器启用(当MCP SDK支持时)。可以在sampling键下按服务器配置:
mcp_servers: my_server: command: "my-mcp-server" sampling: enabled: true # 启用采样(默认:true) model: "openai/gpt-4o" # 覆盖采样请求使用的模型(可选) max_tokens_cap: 4096 # 每个采样响应的最大令牌数(默认:4096) timeout: 30 # 每个请求的超时秒数(默认:30) max_rpm: 10 # 速率限制:每分钟最大请求数(默认:10) max_tool_rounds: 5 # 采样循环中工具使用的最大轮数(默认:5) allowed_models: [] # 服务器可以请求的模型名称白名单(空=任何模型) log_level: "info" # 审计日志级别:debug、info或warning(默认:info)采样处理器包含滑动窗口速率限制器、按请求超时和工具循环深度限制,以防止滥用。每个服务器实例都会跟踪指标(请求数、错误数、使用的令牌数)。
要禁用特定服务器的采样功能:
mcp_servers: untrusted_server: url: "https://mcp.example.com" sampling: enabled: false将Hermes作为MCP服务器运行
除了连接到MCP服务器之外,Hermes也可以作为MCP服务器运行。这让其他支持MCP的代理(Claude Code、Cursor、Codex或任何MCP客户端)可以使用Hermes的消息能力——列出会话、读取消息历史,以及在所有已连接平台上发送消息。
使用场景
- 您希望Claude Code、Cursor或其他编码代理通过Hermes发送和读取Telegram/Discord/Slack消息
- 您需要一个单一的MCP服务器,同时桥接Hermes连接的所有消息平台
- 您已经有运行中的Hermes网关,且已连接到各个平台
快速开始
hermes mcp serve这会启动一个stdio MCP服务器。MCP客户端(而不是您)管理进程生命周期。
MCP客户端配置
将Hermes添加到您的MCP客户端配置中。例如,在Claude Code的~/.claude/claude_desktop_config.json中:
{ "mcpServers": { "hermes": { "command": "hermes", "args": ["mcp", "serve"] } }}如果您将Hermes安装在特定位置:
{ "mcpServers": { "hermes": { "command": "/home/user/.hermes/hermes-agent/venv/bin/hermes", "args": ["mcp", "serve"] } }}可用工具
MCP服务器暴露10个工具,匹配OpenClaw的通道桥接功能,加上Hermes特有的通道浏览器:
| 工具 | 描述 |
| conversations_list | 列出活跃的消息会话。可按平台过滤或按名称搜索。 |
| conversation_get | 按会话键获取单个会话的详细信息。 |
| messages_read | 读取某个会话的最近消息历史。 |
| attachments_fetch | 从特定消息中提取非文本附件(图像、媒体)。 |
| events_poll | 轮询自某个游标位置以来的新会话事件。 |
| events_wait | 长轮询/阻塞直到下一个事件到达(近实时)。 |
| messages_send | 通过平台发送消息(例如 |
| channels_list | 列出所有平台上可用的消息目标。 |
| permissions_list_open | 列出此桥接会话期间观察到的待处理审批请求。 |
| permissions_respond | 批准或拒绝待处理的审批请求。 |
事件系统
MCP服务器包含一个实时事件桥接器,会轮询Hermes的会话数据库以获取新消息。这让MCP客户端能够近实时地感知传入的会话:
# 轮询新事件(非阻塞)events_poll(after_cursor=0)# 等待下一个事件(最多阻塞到超时)events_wait(after_cursor=42, timeout_ms=30000)事件类型:message、approval_requested、approval_resolved
事件队列位于内存中,在桥接连接时启动。更早的消息可以通过messages_read获取。
选项
hermes mcp serve # 普通模式hermes mcp serve --verbose # 在stderr输出调试日志工作原理
MCP服务器直接从Hermes的会话存储(~/.hermes/sessions/sessions.json和SQLite数据库)读取会话数据。后台线程会轮询数据库以获取新消息,并维护内存中的事件队列。发送消息时,它使用与Hermes代理本身相同的send_message基础设施。
读操作(列会话、读历史、轮询事件)不需要网关运行。发送操作需要网关运行,因为平台适配器需要活动连接。
当前限制
- 仅支持stdio传输(暂不支持HTTP MCP传输)
- 通过mtime优化的数据库轮询,轮询间隔约200ms(文件未更改时跳过工作)
- 暂不支持claude/channel推送通知协议
- 仅支持文本发送(messages_send暂不支持媒体/附件发送)
第21章 定时任务(Cron)
使用自然语言或cron表达式调度任务自动运行。Hermes通过单个cronjob工具提供cron管理功能,采用操作式接口,而非独立的schedule/list/remove工具。
Cron目前支持的功能
Cron任务可以:
- 调度一次性或重复性任务
- 暂停、恢复、编辑、触发和移除任务
- 为任务附加零个、一个或多个技能
- 将结果返回给原始聊天、本地文件或配置的平台目标
- 在新的代理会话中运行,使用标准的静态工具列表
警告Cron运行的会话不能递归创建更多cron任务。Hermes在cron执行过程中禁用了cron管理工具,以防止失控的调度循环。
创建定时任务
在聊天中使用/cron
/cron add 30m "Remind me to check the build"/cron add "every 2h" "Check server status"/cron add "every 1h" "Summarize new feed items" --skill blogwatcher/cron add "every 1h" "Use both skills and combine the result" --skill blogwatcher --skill find-nearby从独立CLI创建
hermes cron create "every 2h" "Check server status"hermes cron create "every 1h" "Summarize new feed items" --skill blogwatcherhermes cron create "every 1h" "Use both skills and combine the result" \ --skill blogwatcher \ --skill find-nearby \ --name "Skill combo"通过自然对话创建
正常向Hermes提出要求即可:
每天早上9点,检查Hacker News上的AI新闻,并通过Telegram给我发送摘要。Hermes会在内部使用统一的cronjob工具处理。
基于技能的Cron任务
Cron任务可以在运行提示之前加载一个或多个技能。
单个技能
cronjob( action="create", skill="blogwatcher", prompt="Check the configured feeds and summarize anything new.", schedule="0 9 * * *", name="Morning feeds",)多个技能
技能按顺序加载。提示成为叠加在这些技能之上的任务指令。
cronjob( action="create", skills=["blogwatcher", "find-nearby"], prompt="Look for new local events and interesting nearby places, then combine them into one short brief.", schedule="every 6h", name="Local brief",)当您希望定时代理继承可复用的工作流,而无需将完整的技能文本塞进cron提示中时,这非常有用。
编辑任务
您不需要删除并重新创建任务来修改它们。
聊天中
/cron edit--schedule "every 4h"/cron edit--prompt "Use the revised task"/cron edit--skill blogwatcher --skill find-nearby/cron edit--remove-skill blogwatcher/cron edit--clear-skills 独立CLI
hermes cron edit--schedule "every 4h"hermes cron edit--prompt "Use the revised task"hermes cron edit--skill blogwatcher --skill find-nearbyhermes cron edit--add-skill find-nearbyhermes cron edit--remove-skill blogwatcherhermes cron edit--clear-skills 说明:
- 重复使用--skill会替换任务附加的技能列表
- --add-skill会追加到现有列表,而不会替换它
- --remove-skill会移除特定的附加技能
- --clear-skills会移除所有附加技能
生命周期操作
Cron任务现在拥有比仅创建/删除更完整的生命周期。
聊天中
/cron list/cron pause/cron resume/cron run/cron remove 独立CLI
hermes cron listhermes cron pausehermes cron resumehermes cron runhermes cron removehermes cron statushermes cron tick 各操作的作用:
- pause —— 保留任务但停止调度
- resume —— 重新启用任务并计算下一次未来运行时间
- run —— 在下一个调度器节拍触发任务
- remove —— 完全删除任务
工作原理
Cron执行由网关守护进程处理。 网关每60秒触发一次调度器,在隔离的代理会话中运行所有到期的任务。
hermes gateway install # 安装为用户服务sudo hermes gateway install --system # Linux:服务器开机启动的系统服务hermes gateway # 或在前台运行hermes cron listhermes cron status网关调度器行为
每个节拍时,Hermes会:
1. 从~/.hermes/cron/jobs.json加载任务 2. 检查next_run_at与当前时间的关系 3. 为每个到期的任务启动一个新的AIAgent会话 4. 可选地将一个或多个附加技能注入到新会话中 5. 运行提示直到完成 6. 交付最终响应 7. 更新运行元数据和下一次调度时间
~/.hermes/cron/.tick.lock处的文件锁可以防止重叠的调度器节拍重复运行同一批任务。
交付选项
调度任务时,您可以指定输出的去向:
| 选项 | 描述 | 示例 |
| "origin" | 返回任务创建的位置 | 消息平台上的默认值 |
| "local" | 仅保存到本地文件( | CLI上的默认值 |
| "telegram" | Telegram主频道 | 使用 |
| "telegram:123456" | 按ID指定的Telegram聊天 | 直接交付 |
| "telegram:-100123:17585" | 特定Telegram主题 | chat_id:thread_id |
| "discord" | Discord主频道 | 使用 |
| "discord:#engineering" | 特定Discord频道 | 按频道名称 |
| "slack" | Slack主频道 | |
| "whatsapp" | WhatsApp主账号 | |
| "signal" | Signal | |
| "matrix" | Matrix主房间 | |
| "mattermost" | Mattermost主频道 | |
| "email" | 邮件 | |
| "sms" | 通过Twilio发送短信 | |
| "homeassistant" | Home Assistant | |
| "dingtalk" | 钉钉 | |
| "feishu" | 飞书/Lark | |
| "wecom" | 企业微信 |
代理的最终响应会自动交付。您不需要在cron提示中调用send_message。
响应包装
默认情况下,交付的cron输出会带有头部和尾部包装,以便收件人知道它来自定时任务:
Cronjob Response: Morning feeds-------------<代理输出在这里>Note: The agent cannot see this message, and therefore cannot respond to it.要交付不带包装的原始代理输出,请将cron.wrap_response设置为false:
# ~/.hermes/config.yamlcron: wrap_response: false静默抑制
如果代理的最终响应以[SILENT]开头,交付会被完全抑制。输出仍然会保存在本地以供审计(在~/.hermes/cron/output/中),但不会向交付目标发送任何消息。
这对于只应该在出现问题时报告的监控任务非常有用:
检查nginx是否正在运行。如果一切正常,仅响应[SILENT]。否则,报告问题。失败的任务无论是否有[SILENT]标记都会交付——只有成功运行的任务可以被静默。
调度格式
代理的最终响应会自动交付——您不需要在cron提示中为同一目标包含send_message。如果cron运行调用send_message到调度器已经要交付的目标,Hermes会跳过重复发送,并告诉模型将面向用户的内容放在最终响应中。仅在需要发送到额外或不同目标时使用send_message。
相对延迟(一次性)
30m → 30分钟后运行一次2h → 2小时后运行一次1d → 1天后运行一次间隔(重复性)
every 30m → 每30分钟every 2h → 每2小时every 1d → 每天Cron表达式
0 9 * * * → 每天上午9:000 9 * * 1-5 → 工作日上午9:000 */6 * * * → 每6小时30 8 1 * * → 每月第一天上午8:300 0 * * 0 → 每周日午夜ISO时间戳
2026-03-15T09:00:00 → 2026年3月15日上午9:00运行一次重复行为
| 调度类型 | 默认重复次数 | 行为 |
| 一次性( | 1 | 运行一次 |
| 间隔( | 永久 | 运行直到被移除 |
| Cron表达式 | 永久 | 运行直到被移除 |
您可以覆盖默认设置:
cronjob( action="create", prompt="...", schedule="every 2h", repeat=5,)编程方式管理任务
面向代理的API是一个统一的工具:
cronjob(action="create", ...)cronjob(action="list")cronjob(action="update", job_id="...")cronjob(action="pause", job_id="...")cronjob(action="resume", job_id="...")cronjob(action="run", job_id="...")cronjob(action="remove", job_id="...")对于update操作,传递skills=[]可以移除所有附加技能。
任务存储
任务存储在~/.hermes/cron/jobs.json中。任务运行的输出保存到~/.hermes/cron/output/{job_id}/{timestamp}.md。
存储使用原子文件写入,因此中断的写入不会留下部分写入的任务文件。
自包含提示仍然很重要
重要Cron任务在完全全新的代理会话中运行。提示必须包含代理需要的所有信息,附加技能提供的内容除外。
不好的示例:"Check on that server issue"
好的示例:"SSH into server 192.168.1.100 as user 'deploy', check if nginx is running with 'systemctl status nginx', and verify https://example.com returns HTTP 200."
安全性
定时任务提示在创建和更新时会经过提示注入和凭证泄露模式扫描。包含不可见Unicode技巧、SSH后门尝试或明显的秘密泄露 payload 的提示会被阻止。
第22章 子代理委托
delegate_task工具可以生成子AIAgent实例,这些实例拥有隔离的上下文、受限的工具集和自己的终端会话。每个子代理都有全新的对话,独立工作——只有它的最终总结会进入父代理的上下文。
单个任务
delegate_task( goal="Debug why tests fail", context="Error: assertion in test_foo.py line 42", toolsets=["terminal", "file"])并行批处理
最多支持3个并发子代理:
delegate_task(tasks=[ {"goal": "Research topic A", "toolsets": ["web"]}, {"goal": "Research topic B", "toolsets": ["web"]}, {"goal": "Fix the build", "toolsets": ["terminal", "file"]}])子代理上下文工作原理
关键:子代理一无所知子代理以完全全新的对话启动。它们对父代理的对话历史、之前的工具调用或委托前讨论的任何内容都一无所知。子代理的唯一上下文来自您提供的goal和context字段。
这意味着您必须传递子代理需要的所有信息:
# 不好的示例 - 子代理不知道"the error"是什么delegate_task(goal="Fix the error")# 好的示例 - 子代理拥有需要的所有上下文delegate_task( goal="Fix the TypeError in api/handlers.py", context="""The file api/handlers.py has a TypeError on line 47: 'NoneType' object has no attribute 'get'. The function process_request() receives a dict from parse_body(), but parse_body() returns None when Content-Type is missing. The project is at /home/user/myproject and uses Python 3.11.""")子代理会收到根据您的目标和上下文构建的聚焦系统提示,指示它完成任务,并提供结构化总结,说明它做了什么、发现了什么、修改了哪些文件以及遇到了什么问题。
实际示例
并行研究
同时研究多个主题并收集总结:
delegate_task(tasks=[ { "goal": "Research the current state of WebAssembly in 2025", "context": "Focus on: browser support, non-browser runtimes, language support", "toolsets": ["web"] }, { "goal": "Research the current state of RISC-V adoption in 2025", "context": "Focus on: server chips, embedded systems, software ecosystem", "toolsets": ["web"] }, { "goal": "Research quantum computing progress in 2025", "context": "Focus on: error correction breakthroughs, practical applications, key players", "toolsets": ["web"] }])代码审查 + 修复
将审查和修复工作流委托给全新的上下文:
delegate_task( goal="Review the authentication module for security issues and fix any found", context="""Project at /home/user/webapp. Auth module files: src/auth/login.py, src/auth/jwt.py, src/auth/middleware.py. The project uses Flask, PyJWT, and bcrypt. Focus on: SQL injection, JWT validation, password handling, session management. Fix any issues found and run the test suite (pytest tests/auth/).""", toolsets=["terminal", "file"])多文件重构
委托可能会淹没父代理上下文的大型重构任务:
delegate_task( goal="Refactor all Python files in src/ to replace print() with proper logging", context="""Project at /home/user/myproject. Use the 'logging' module with logger = logging.getLogger(__name__). Replace print() calls with appropriate log levels: - print(f"Error: ...") -> logger.error(...) - print(f"Warning: ...") -> logger.warning(...) - print(f"Debug: ...") -> logger.debug(...) - Other prints -> logger.info(...) Don't change print() in test files or CLI output. Run pytest after to verify nothing broke.""", toolsets=["terminal", "file"])批处理模式详情
当您提供tasks数组时,子代理使用线程池并行运行:
- 最大并发数: 3个任务(如果tasks数组更长,会被截断为3个)
- 线程池: 使用ThreadPoolExecutor,包含MAX_CONCURRENT_CHILDREN = 3个工作线程
- 进度显示: 在CLI模式下,树状视图会实时显示每个子代理的工具调用,并附带每个任务的完成行。在网关模式下,进度会被批量处理并转发到父代理的进度回调
- 结果排序: 结果按任务索引排序,与输入顺序匹配,与完成顺序无关
- 中断传播: 中断父代理(例如发送新消息)会中断所有活动的子代理
单任务委托直接运行,没有线程池开销。
模型覆盖
您可以通过config.yaml为子代理配置不同的模型——适合将简单任务委托给更便宜/更快的模型:
# 在 ~/.hermes/config.yaml 中delegation: model: "google/gemini-flash-2.0" # 子代理使用更便宜的模型 provider: "openrouter" # 可选:将子代理路由到不同的提供商如果省略,子代理使用与父代理相同的模型。
工具集选择技巧
toolsets参数控制子代理可以访问的工具。根据任务选择:
| 工具集模式 | 使用场景 |
| ["terminal", "file"] | 代码工作、调试、文件编辑、构建 |
| ["web"] | 研究、事实核查、文档查找 |
| ["terminal", "file", "web"] | 全栈任务(默认) |
| ["file"] | 只读分析、无需执行的代码审查 |
| ["terminal"] | 系统管理、进程管理 |
无论您指定什么,某些工具集对子代理始终是被阻止的:
- delegation —— 禁止递归委托(防止无限生成子代理)
- clarify —— 子代理不能与用户交互
- memory —— 禁止写入共享持久化内存
- code_execution —— 子代理应该逐步推理
- send_message —— 禁止跨平台副作用(例如发送Telegram消息)
最大迭代次数
每个子代理都有迭代限制(默认:50),控制它可以进行多少轮工具调用:
delegate_task( goal="Quick file check", context="Check if /etc/nginx/nginx.conf exists and print its first 10 lines", max_iterations=10 # 简单任务,不需要太多轮次)深度限制
委托的深度限制为2——父代理(深度0)可以生成子代理(深度1),但子代理不能进一步委托。这可以防止失控的递归委托链。
关键特性
- 每个子代理都有自己的终端会话(与父代理分离)
- 禁止嵌套委托——子代理不能进一步委托(不能生成孙代理)
- 子代理不能调用:delegate_task、clarify、memory、send_message、execute_code
- 中断传播——中断父代理会中断所有活动的子代理
- 只有最终总结会进入父代理的上下文,保持令牌使用高效
- 子代理继承父代理的API密钥、提供商配置和凭证池(支持速率限制时的密钥轮换)
委托 vs execute_code
| 因素 | delegate_task | execute_code |
| 推理能力 | 完整的LLM推理循环 | 仅执行Python代码 |
| 上下文 | 全新的隔离对话 | 没有对话,只有脚本 |
| 工具访问 | 所有非被阻止的工具,支持推理 | 通过RPC访问7个工具,没有推理 |
| 并行性 | 最多3个并发子代理 | 单个脚本 |
| 最适合 | 需要判断的复杂任务 | 机械的多步骤流水线 |
| 令牌成本 | 更高(完整LLM循环) | 更低(仅返回标准输出) |
| 用户交互 | 无(子代理不能澄清问题) | 无 |
经验法则: 当子任务需要推理、判断或多步问题解决时,使用delegate_task。当您需要机械数据处理或脚本化工作流时,使用execute_code。
配置
# 在 ~/.hermes/config.yaml 中delegation: max_iterations: 50 # 每个子代理的最大轮次(默认:50) default_toolsets: ["terminal", "file", "web"] # 默认工具集 model: "google/gemini-3-flash-preview" # 可选的提供商/模型覆盖 provider: "openrouter" # 可选的内置提供商# 或者使用直接自定义端点代替提供商:delegation: model: "qwen2.5-coder" base_url: "http://localhost:1234/v1" api_key: "local-key"大象提示代理会根据任务复杂度自动处理委托。您不需要明确要求它委托——当合理时它会自动这么做。

本文档在 Claude Code 辅助下整理编写,基于 Hermes Agent 官方文档、GitHub 仓库及社区资料。
内容的准确性与时效性仅供参考,如有勘误或建议,欢迎关注公众号「大象AI共学」反馈交流。
来源:https://hermes-agent.nousresearch.com/ · Created by 大象 · 2026 年 4 月
后续章节请移步:⬇️ 如需完整版请联系作者:大象