



“人工智能行业专题(16):Agent驱动全球模型厂MaaS收入爆发,国产模型各有优势”由国信证券发布。
本报告共计:60页。完整版PDF电子版报告下载方式见文末。
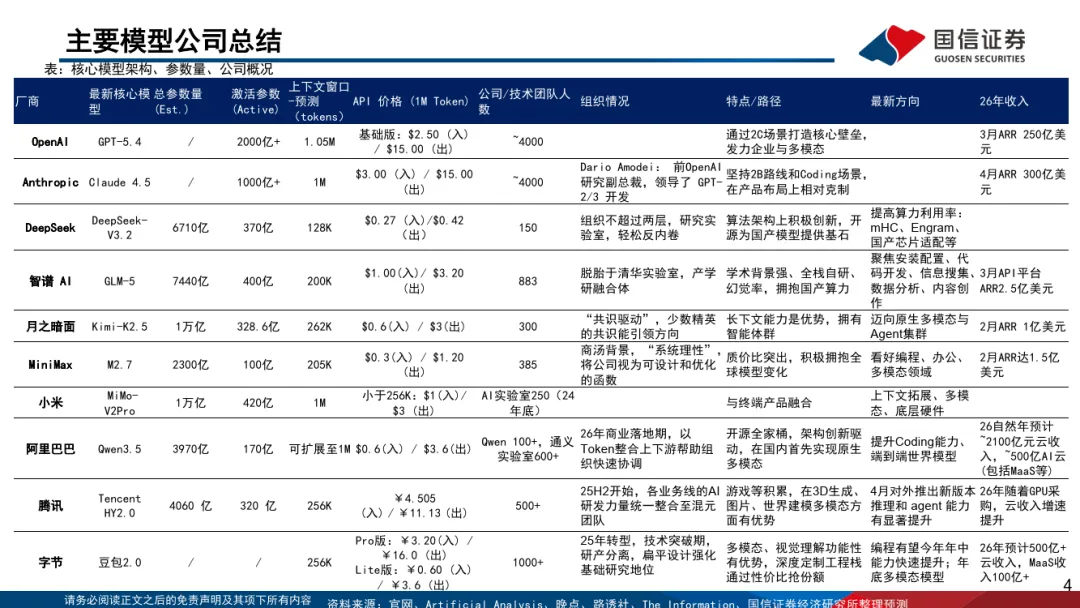
国产模型与全球模型厂商比较,主要在性价比领域优势明显。在国内Deepeek开源基础上,国产模型着重提升工程化、数据 能力,来弥补算力限制。国产模型性价比高主要系:①架构层面算力利用效率领先。以Deepseek为代表的国内厂商针对 MoE、注意力机制做了原创性轻量化优化。除此以外,国内厂商(如 Kimi、MiniMax)创始初期(23年左右),锚定长上下 文路线,针对超长文本场景做了成本全链路优化。②极致定价,中国厂商愿意以接近成本价来换市场份额。

国产模型劣势:算力限制下推理深度较国外弱,数据集质量较低
国产模型弱于国外方面:①在算力约束下,国产多采用思维链(CoT),线性单向推导的逻辑结构,推理深度和强度弱 于海外思维数(ToT)。②数据集规模与基础质量较低,并且数据开源生态弱。

国产模型质价比来源:极致工程优化、AI Infra等有优势
技术层面的“降本增效”。国外通过激活更多的参数来确保模型的“智力上限”。即便推理成本高,但只要模型表现出 绝对统治力,就能通过商业订阅覆盖成本。国产模型通过更少参数量以及工程化设计让单次推理消耗的显存和算力更低。
国内厂商针对MoE、注意力机制做了原创性轻量化优化。如DeepSeek 独创 DeepSeekMoE 架构,总参数仅激活 5.5%,算力动态分配效率远超海外同规模 MoE 模型;配套 MLA 多头潜在注意力技术,将 KV Cache 显存占用降至 传统架构的 1/10。
长上下文长期探索和链路优化。国内厂商(如Kimi、MiniMax)创始初期(23年左右),原生锚定长上下文路线, 针对超长文本场景做了全链路成本优化。
算力平替与调度:国产厂商擅长将碎片化的算力资源(如国产芯片、老款芯片)通过集群调度发挥最大效能。
AI Infra:国内电、人工成本更低,算力中心建设周期短,无过多电力限制等。
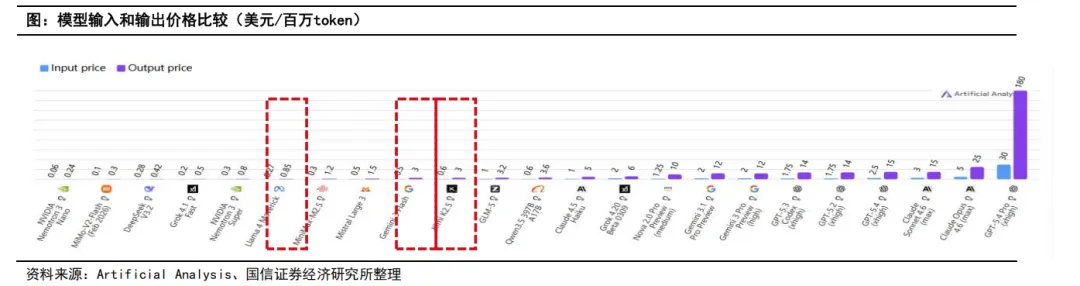
通过比较国内初创模型企业和大厂的模型布局,我们认为不同团队之间呈现差异化竞争,比如出身清华人工智能实验室的智谱,更加聚焦模型智能上届的突破,适配国产算力;Minimax从发展第一天起着眼于布局全球市场,成为最早出海并实现 可观收入的国产模型厂商之一;Deepseek背靠幻方,商业化压力小,引领国产模型架构创新;Kimi着重构建长上下文能力 和侧重Agent智能体集群协同能力。
幻影视界整理分享报告原文节选如下:






 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。