


一、 引言与底层计算范式的物理重构
现代信息技术的基础长期建立在冯·诺依曼(von Neumann)架构之上,该架构的核心特征是计算单元与存储单元的物理分离。随着数据密集型应用和基于张量运算的超大规模人工智能(AI)模型的参数量呈指数级增长,处理器与内存之间频繁的数据搬运导致了严重的“冯·诺依曼瓶颈”。这种物理分离不仅限制了系统的有效带宽,更导致了极高的数据传输能耗。当前,数据中心支撑大规模机器学习训练的能耗正以惊人的速度攀升。据估计,目前全球数据中心每年消耗约200太瓦时(TWh)的电力,如果计算架构不发生根本性变革,到2030年,数据中心甚至将消耗全球约3%的电力资源。此外,受限于互补金属氧化物半导体(CMOS)物理极限的逼近,传统的摩尔定律扩展在热预算、量子隧穿效应和制造成本方面已遭遇难以逾越的物理壁垒,在未来十年内将不可避免地触及科学基本定律的限制。
在这一背景下,神经形态计算(Neuromorphic Computing)作为一种非冯·诺依曼计算范式,从生物神经系统的结构与运行机制中汲取灵感,通过底层硬件的重构来实现极低功耗、高并行度和超低延迟的信息处理。其核心原则在于实现计算与存储的原位融合(Compute-in-Memory),消除数据在不同层级存储器间的无效移动。与传统数字逻辑基于全局时钟的同步运算不同,类脑计算依赖于异步的、事件驱动(Event-driven)的脉冲通信机制。这种范式转变不仅是硬件结构的重塑,更是信息编码方式的根本性变更:信息不再仅仅表现为静态的布尔电平状态,而是被编码为脉冲(Spike)序列在时间轴上的相对分布特征。这种时空信息处理能力使神经形态系统在处理动态、稀疏的真实世界传感器数据时,展现出远超传统图形处理单元(GPU)和张量处理单元(TPU)的能效比。人类大脑能够以大约20瓦的极低功耗执行任何现有数据中心都无法企及的复杂认知计算,这为下一代高能效电子系统的设计提供了终极蓝图。
二、 神经动力学模型与脉冲时空编码机制
2.1 脉冲神经网络(SNN)与事件驱动计算
类脑计算的算法基础是脉冲神经网络(Spiking Neural Networks, SNNs)。作为第三代人工神经网络,SNN在结构上更贴近生物学的真实性。在SNN中,人工神经元通常采用泄漏积分-点火(Leaky Integrate-and-Fire, LIF)模型或其衍生变体。其核心动力学过程表现为:神经元的膜电位(Membrane voltage, 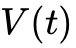 )随着突触前神经元输入脉冲(Spike,
)随着突触前神经元输入脉冲(Spike, 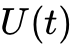 )的到达,随时间进行空间与时间上的积分累加;当膜电位未达到阈值时,电荷会以特定的时间常数逐渐耗散(泄漏);一旦膜电位超越预设的动态阈值(
)的到达,随时间进行空间与时间上的积分累加;当膜电位未达到阈值时,电荷会以特定的时间常数逐渐耗散(泄漏);一旦膜电位超越预设的动态阈值(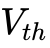 ),神经元即刻激发一个离散的动作电位(脉冲),并通过互连的突触网络将信息异步传递给下游神经元,随后自身膜电位重置为基态。
),神经元即刻激发一个离散的动作电位(脉冲),并通过互连的突触网络将信息异步传递给下游神经元,随后自身膜电位重置为基态。
SNN区别于传统人工神经网络(ANN)的关键在于时间维度的显式引入与绝对的事件驱动特性。由于脉冲信号是离散的二值事件,只有在状态发生显著变化时,网络才进行主动计算并消耗能量。如果电荷值未能超过阈值,它最终会消散。这种极度稀疏的激活模式极大降低了系统的静态和动态功耗。理论上,SNN的异步性质使得每一个神经元都可以作为独立的计算节点并发运行,无需等待全局时钟同步。因此,类脑硬件具备极高的大规模并行处理能力,使得其实际执行的任务数量在给定时间内理论上可以等于网络中神经元的数量。
2.2 突触可塑性与局部学习规则的数学表征
在学习机制方面,传统深度学习(Deep Learning)高度依赖于全局误差的反向传播(Backpropagation, BP)算法。然而,脉冲的离散二进制特性和不可微性,对直接在SNN中应用梯度下降优化构成了严峻的数学挑战。因此,类脑计算系统广泛采用受生物学启发的局部学习规则,其中最核心的是脉冲时间依赖可塑性(Spike-Timing-Dependent Plasticity, STDP)。STDP通过严格评估突触前与突触后脉冲的相对发放时间差来动态调整突触权重:若突触前脉冲在突触后脉冲之前极短的时间内到达,则判定存在因果关系,从而增强该突触连接(长时程增强,LTP);反之则减弱该连接(长时程抑制,LTD)。
目前的研究致力于将STDP的局部高效性与反向传播的全局寻优能力相融合。例如,SSTDP(Surrogate Spike-Time-Dependent Plasticity)算法通过引入替代梯度(Surrogate Gradients),在避免BP过程中非可微求导的同时,利用STDP的局部特征提取属性。该方法有效降低了BP训练中脉冲消失的可能性,并显著减少了网络延迟所需的时间步长。实证数据显示,利用SSTDP训练的SNN在标准视觉数据集上实现了卓越的分类精度(Caltech 101达到99.3%,MNIST达到98.1%,CIFAR-10达到91.3%),同时其推理阶段的能耗比直接训练的SNN低25至32倍。
此外,更为复杂的三因子(Three-factor)学习规则,如奖励调制STDP(Reward-Modulated STDP),正在被直接引入硬件层和系统软件栈中。以开源架构为例,基础的基于脉冲对的STDP权重更新规则可被精确定义为:
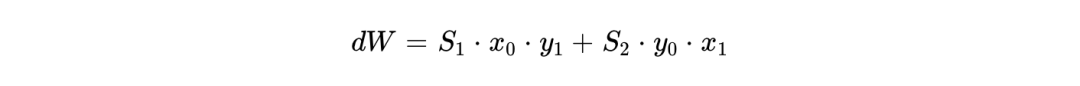
其中 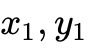 分别代表突触前与突触后的脉冲迹(Spike traces),
分别代表突触前与突触后的脉冲迹(Spike traces),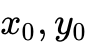 代表脉冲发生时刻的二值状态。而在奖励调制机制下,更新方程被扩展为包含第三个代表多巴胺浓度或环境奖励的变量 (Tag):
代表脉冲发生时刻的二值状态。而在奖励调制机制下,更新方程被扩展为包含第三个代表多巴胺浓度或环境奖励的变量 (Tag):
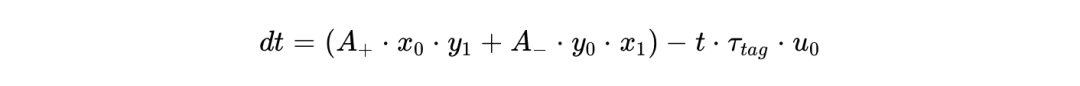
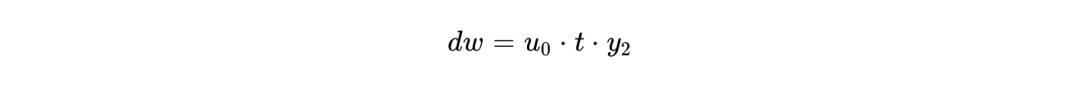
这种高级学习规则不仅使得网络具备在线的微调能力,更极大降低了对大规模离线预训练和人工调整的依赖,支撑了片上连续学习(Continual Learning)和实时强化学习的工程部署。
三、 神经形态底层硬件体系结构与核心系统标杆
神经形态硬件的底层实现路径根据信号处理域的不同,主要划分为三大阵营:纯数字设计、纯模拟/亚阈值设计以及数模混合信号集成架构。
纯模拟系统(如斯坦福大学的Neurogrid)利用CMOS晶体管在亚阈值区(Subthreshold region)的工作特性,直接在物理层面上模拟生物神经元离子通道的常微分方程。电容积分和脉冲触发复位机制被用于真实模拟膜动力学。Neurogrid的能源效率极为惊人,模拟一百万个神经元(分布在16×16的神经核心阵列上)的总功耗仅为5瓦。然而,模拟电路在先进制程节点上面临严重的器件不匹配(Device mismatch)、晶圆内差异、噪声敏感性,且其静态连接性缺乏突触可塑性机制,这使其更适合实时的脑神经科学仿真,而非可编程的自适应人工智能应用。
为了追求更高的可靠性、软件可编程性以及与摩尔定律先进制程节点的兼容性,学术界与工业界目前更倾向于纯数字架构或混合架构。纯数字系统通过数字硬件或微码软件求解低级神经动力学方程,保证了行为的高度一致性和可重复性。混合架构(如BrainScaleS和ROLLS)则试图结合两者的优势:在模拟域进行高速的神经动力学积分(BrainScaleS通过晶圆级技术实现比生物实时快一万倍的加速物理模拟),而在数字域处理异步脉冲路由和动态连接配置。
3.1 全球标杆神经形态芯片微架构对标分析
通过对当前主流类脑芯片的制程节点、网络规模、功耗指标及底层机制进行系统性的基准测试比较,可以清晰洞察类脑处理器的技术分化与应用定位:
处理器架构 | 开发机构 | 制程工艺 | 核心架构特征与网络规模 | 神经元模型、通信与学习机制 | 功耗与性能基准 |
Loihi 2 | Intel | Intel 4 (EUV) | 纯数字异步架构;单芯片支持模拟13.1万个神经元和1.3亿个突触。模块化互连架构支持大规模扩展(如Hala Point系统达11.5亿神经元)。 | 支持可编程动态神经元、微码可配置STDP规则。内存全部本地化于核心SRAM。采用异步事件驱动通信。 | 片上推理总功耗极低(约26W)。在传感器融合任务中达161 GOp/s吞吐量,仅耗1.5W(较CPU能效提升>100倍)。 |
TrueNorth | IBM | 28nm CMOS | 纯数字;100万个神经元与2.56亿个可编程突触,分布于4096个神经常规核心(Neurosynaptic cores)。 | 基于LIF模型。通信采用二维网格片上网络(2D mesh NoC)和维度排序路由(Dimension-ordered routing)。 | 极高能效,每百万神经元仅耗电65mW。不具备原生的片上学习(On-chip learning)能力,仅支持推理。 |
Tianjic (天机) | 清华大学 | 28nm CMOS | 异构数字众核架构;单芯片模拟约4万个脉冲神经元与1000万个非脉冲(ANN)神经元。 | 融合计算模型:无缝支持SNN与非脉冲深度学习模型。神经元被设计为可配置有限状态机。SRAM作为查找表存储权重。 | 功耗中等,具有极高的灵活性,解决了生物合理性与深度学习预测精度之间的混合映射问题。 |
SpiNNaker 2 | 曼彻斯特大学 / 德累斯顿大学 | - | 纯数字;采用153个ARM内核,配备19MB片上SRAM和2GB外挂DRAM。 | 软件定义的神经元模型,高度依赖ARM核的指令级计算,支持STDP等复杂突触可塑性。 | 专注于极大规模的计算神经科学仿真和事件路由。 |
Akida | BrainChip | 多节点兼容 | 纯数字,专为边缘AI优化;支持CNN到SNN的工具链转换。 | 事件驱动计算;内置基于单次/小样本的持续学习功能,完全独立的片上学习能力。 | 亚毫瓦级极低静态功耗;较传统边缘AI处理器能耗降低百倍。 |
Neurogrid | 斯坦福大学 | 180nm CMOS | 纯模拟亚阈值架构;104.8万神经元与数十亿突触;16×16核心阵列。 | LIF模型;层次化地址事件表示(AER)协议;时间分割多路复用(TDM)用于突触寻址。 | 极端高能效(总功耗5W);缺乏突触可塑性,网络拓扑静态,无法自适应学习。 |
BrainScaleS | 海德堡大学 | 65nm CMOS (晶圆级) | 晶圆级数模混合架构;极大网络规模。 | 加速模拟神经动力学,数字通信基础设施;原生支持STDP。 | 极速物理模拟能力;但晶圆级集成导致整体功耗较高且制造复杂度大。 |
DYNAP | SynSense | 180nm CMOS | 纯数字架构;具有可编程路由表的运行时可重配置突触连接。 | 支持STDP和动态网络重构;低延迟事件处理。 | 神经元密度中等;相较于纯模拟设计,其单个神经元能耗较高。 |
ROLLS | 瑞士苏黎世联邦理工 | 180nm CMOS | 混合设计:亚阈值模拟神经元电路与数字可编程突触。网络规模严重受限。 | 在极小的硅面积内实现多种可塑性机制;用于可塑性机制的机理探索。 | 具有超低的每神经元功耗,但不适于大规模工业应用部署。 |
从数据结构和架构演进的视角可以看出:TrueNorth通过摒弃片上学习引擎和全局时钟,将SRAM与逻辑紧密耦合,实现了推理阶段极致的静态能效,但彻底牺牲了自适应性。Intel的Loihi系列代表了当前数字神经形态架构在可编程性和片上可塑性(On-chip plasticity)方面的工业界最高水准,其微代码可编程引擎使得SNN能够根据环境变化动态调整网络连接权重,彻底摆脱了云端训练的依赖。清华大学的天机(Tianjic)芯片则反映了一种极其务实的折中主义路线,通过架构级异构设计,使处理器既能执行计算密度的张量运算,又能运行生物启发的高稀疏性脉冲模型,极大降低了产业化部署和算法迁移的门槛。
3.2 众核通信与片上网络(NoC)的拥塞管理
神经形态计算在硬件架构上的扩展高度依赖于芯片内部的路由拓扑。对于数字类脑系统而言,绝大多数系统采用二维网格网络(2D Mesh NoC)处理基于地址事件表示(Address-Event Representation, AER)协议的脉冲包互连。然而,为了进一步降低通信瓶颈和拥塞,研究人员正在探索基于三元组架构(Triplet-Based Architecture, TriBA)的递归层级互连方案。
在 TriBA-cNoC 架构中,网络被结构化为一个层级图(Hierarchical graph),其中每个节点的度数恒定为3,极大简化了路由器的设计复杂度。相较于标准5端口的2D Mesh路由器,4端口的TriBA-cNoC路由器功耗降低了21%,芯片面积占用减少了53%。其核心的路由机制引入了“焦点路由图”(Focus Routing Graph, FRG)和“最显著子图”(Most Significant Subgraphs, MSG)的数学隔离理论。为了抑制数据包在热点节点(Hot nodes)的拥塞并避免死锁,该架构采用了一种两阶段的半自适应路由算法。通过专属的顶端缓冲区占用(Apex Buffer Occupancy, ABO)单元,路由器能够实时监测下游顶端节点的拥塞状态并将其广播给MSG内的所有节点,存储于本地查找表(LUT)中。这种全局感知机制在保持微小功耗开销(约3.94%)的前提下,将合成流量模式下的通信延迟降低了31.71%,在实际工作负载下的延迟更是降低了45.86%,大幅提升了底层硬件吞吐量。
四、 忆阻器物理学、CMOS异构集成与工艺边界
在超越纯数字逻辑框架的探索中,以忆阻器(Memristors / Two-terminal Synaptic Materials, TSMs)为代表的新型非易失性存储器件(NVMs)被视为构建下一代超高密度神经形态系统的终极物理载体。忆阻器具有随历史流经电荷量改变自身阻值的非线性动态特性,其物理机制(如氧空位迁移、导电细丝的形成与断裂、相变或自旋力矩转移)与生物突触的离子通道动态演变过程表现出高度的同构性。
4.1 潜行电流(Sneak Path Current)的解析建模与架构约束
在无源交叉阵列(Passive Crossbar Arrays)结构中,将忆阻器映射为突触矩阵进行模拟域的乘加运算(MAC)面临一个致命的基尔霍夫定律拓扑缺陷——潜行电流效应。当系统对某一特定目标单元施加读取或写入电压时,电流不仅会流经目标器件,还会通过周围处于低阻态(LRS)的相邻器件网络形成不可控的并联泄漏路径。
潜行电流会呈指数级降低信号的读取裕度(Noise Margin),产生严重的电学串扰,进而使得能够可靠寻址的阵列最大物理规模受到严格限制。最新的封闭形式解析分析框架基于IMEC 14nm技术节点的物理参数进行建模,揭示了潜行电流与阵列尺寸、互连线电阻、器件开关比(ON/OFF Ratio)、读取电压模式(如全一数据模式与FRC连接策略)之间的高度非线性耦合关系。
为抑制潜行电流,硬件架构设计中通常强制引入高度非线性的选通器件(Selector devices,如二极管或晶体管),构成1T1R(单晶体管单电阻)或1S1R(单选择器单电阻)的交叉阵列布局。选通器件在阈值电压以下能够提供极高的截止阻抗,有效阻断寄生路径。然而,选通器的引入不仅降低了存储密度,而且其自身的工艺偏差会与忆阻器的可变性相叠加,对整体阵列的一致性产生难以预估的二次干扰。
4.2 CMOS-忆阻器混合集成的制程挑战与热预算
将忆阻器阵列通过后道工序(BEOL)单片集成(Monolithic integration)到先进制程的CMOS逻辑平台上,是实现超高面积效率(GOPS/mm²)和能量效率(GOPS/W)的关键路径。据评估,CMOS集成忆阻器驱动的系统架构较传统冯·诺依曼GPU在能效上通常能提升约一个数量级(10倍)。然而,在微纳制造过程中,工艺的材料兼容性与热预算(Thermal Budget)构成了严峻的挑战。忆阻器氧化层或相变材料的沉积与退火温度必须严格控制,一旦超过CMOS底层的热容忍极限,将直接导致底层互连线和晶体管性能退化,甚至造成介电层熔断失效。由于物理隔离的缺失,芯片在高速运行中产生的巨大瞬态热场也会引发忆阻器件导电细丝状态的漂移,加速器件老化。
在具体的物理流片实践中,例如在2.5mm × 2mm微缩CMOS裸片上集成忆阻器,必须克服极小表面积上的多步光刻挑战。研究人员提出了一种详尽的制造工艺流:首先通过溅射(Sputtering)一层SiO2来降低芯片表面的高粗糙度;由于芯片尺寸极小,需将其使用PVC胶带贴合在载片晶圆上,并放置四个伪芯片(Dummy chips)辅助光刻对准;随后使用氮气吹扫确保芯片平整贴附;在此基础上以极高转速旋涂正性光刻胶,以最大限度消除边缘胶珠(Edge bead)的形成。底电极通过电子束蒸发(E-beam evaporation)沉积,而器件功能层通过溅射完成。为了解决剥离(Lift-off)工艺中常见的“兔耳”(Rabbit ear)残留物难题,必须引入专用的剥离光刻胶层。最后,为了暴露出底层焊盘,采用湿法刻蚀代替干法刻蚀,从而避免了光刻胶硬化导致难以去除的工艺死结。
4.3 器件可变性、耐久度限制与架构级补偿
当前的氧化还原基(Redox-based)阻变存储器(ReRAM)在开关周期中面临低耐久度(Endurance,即在器件特性显著退化前能够承受的翻转次数)、高周期间变异性(Cycle-to-cycle variation)以及大规模生产成品率低的问题。由于不可控的缺陷密度和离子迁移的随机性,器件在多阻态调节过程中往往表现出电导状态漂移和热噪声敏感性。
为应对上述物理极限,材料科学层面的突破是基础(如探索基于拓扑微结构的Bi/Al-Cu忆阻器或新型铁电器件)。此外,极端尺寸缩放(Extreme scaling)被证实可通过在空间上限制导电细丝的成核区域来有效降低器件变异性。在架构电路设计层面,研究者提出了使用复合冗余机制——将多个具有高方差和不稳定性的单忆阻器单元并联,构筑为一个具有高鲁棒性的“宏突触单元”(Multi-memristor cell)。这种策略牺牲了部分的系统集成密度,换取了网络权重的稳定性和计算状态的确定性,为深度学习任务中的高精度推理提供了硬件保障。针对热管理,温度传感电阻式随机存取存储器(TSRRAM)的集成被证明能够主动监控芯片的热分布特征(平均绝对传感器误差控制在2.14 K内),为动态热管理(DTM)算法提供了可靠的被动感测数据。
五、 神经形态软件生态、算法抽象与中间件演进
底层硬件材料和架构的繁荣若缺乏软件生态的支撑,将不可避免地陷入孤岛效应。过去,SNN的开发高度依赖于具体硬件芯片的底层专属指令,严重限制了算法模型的迭代速度,并形成了陡峭的学习曲线。目前,类脑计算正处于类似于传统计算机发展史中从汇编语言向高级通用编译器跨越的转折期。
5.1 Lava软件框架:软硬协同与对象抽象
以Intel主导的开源软件框架Lava为例,其核心理念是通过对象导向的“进程(Processes)”与事件基元来封装神经动力学行为。Lava框架允许开发者基于通用CPU/GPU进行网络构建与仿真,并能将其无缝映射到异构后端硬件(如Loihi 2数字芯片)。
在Lava生态中,突触权重的在线可塑性更新以显式的代数形式实现,框架内部原生支持自定义的局部学习规则。例如,开发者可以直接调用基于Loihi学习引擎的 STDPLoihi 类进行两因子STDP算法部署。此外,Lava的 PyLearningDenseModel 等进程模型允许开发者在浮点精度(Float)、位近似(Bit-approximate)以及完全位精确(Bit-accurate)之间灵活切换,从而在软件仿真阶段准确评估网络在目标硬件定点数计算环境下的量化损失。这种软件抽象层级赋予了算法研究人员直接探索组合优化(如QUBO二次无约束二值优化)和大规模持续学习网络的能力,彻底改变了以往“算法代码需硬编码迁就芯片总线走线”的被动局面。
5.2 神经形态中间表示(NIR):软件栈底层的彻底解耦
为了打破跨硬件平台的隔离墙,学术界积极推进了“神经形态中间表示”(Neuromorphic Intermediate Representation, NIR)的标准化建设。NIR提供了一种基于有向计算图的标准指令集抽象,专门用于描述SNN的结构特征化与时序动态特性。它将上层的高级神经科学模型(由PyNN、NeuroML等定义)或深度学习工具箱(如snnTorch、Norse、Nengo、Sinabs)编写的算法,无损地转化成一种序列化、跨平台的数据格式。
NIR的设计机制确保了神经网络模型动力学(如膜电位整合与泄漏率、发放阈值计算)在不同的数字类脑硬件(如Intel Loihi 2, SynSense Speck, SpiNNaker 2)上能够实现确定性的复现。严密的验证实验表明,在面对不同的离散化积分方案和不同的时间编码(Temporal encoding)方案下,经过NIR转换部署的SNN在各异构平台上的输出脉冲发放率(Output firing rate)和绝对的脉冲时间戳保持了高度的数学等效性。中间层IR的出现表明类脑计算正走向通用范式,使得硬件制造商只需专注于优化后端的微码执行编译器和晶体管效率,而算法开发者可以完全依赖统一的基于计算图的前端生态模型。
5.3 传统GPU上的SNN仿真基准与局限
尽管专用神经形态硬件是部署SNN的终极载体,但在大规模原型设计阶段,研究人员仍高度依赖冯·诺依曼架构下的高性能计算(HPC)集群。软件代码生成器(如GeNN、BindsNET、Brian2等)通过针对NVIDIA GPU(如Tesla V100)的并行张量加速进行优化,显著弥合了SNN时空稀疏运算与GPU密集矩阵引擎之间的计算鸿沟。
仿真基准测试显示,在单核CPU上运行常规前馈和稀疏SNN时,BindsNET提供了最佳的速度与可扩展性;而在利用GPU多核加速的大规模计算(如遗传算法或皮层微电路模拟)中,Brian2GeNN展现出最强的多节点扩展性。一项在NVIDIA V100上的模拟实验表明,全尺寸新皮层微电路模型可以以接近0.5倍实时(Real-time)的速度运行,其仿真能量成本较早期CPU集群甚至较SpiNNaker系统低14倍。然而,随着模型规模逼近真实的传感器融合与片上自主学习系统,冯·诺依曼架构的内存带宽与总线功耗将最终限制这些仿真的能效极限。
六、 技术标准化体系架构规划(IEEE体系)
随着神经形态技术的商业化渗透与边界扩张,全球标准化机构(特别是IEEE)正深度介入,旨在从协议层面规范这一新兴范式。缺乏统一的架构标准、硬件接口定义与基准测试数据集,一度是制约产业界进行规模化系统集成的主要障碍。
在2025年至2026年间,IEEE系统地启动了一系列至关重要的标准制定项目(Project Authorization Requests, PARs)。其中最核心的标志性工程是处于草案制定阶段的 IEEE P3762 异构混合推理系统技术要求标准(Standard for Technical Requirements for Heterogeneous Hybrid Inference Systems)。该标准的制定明确了传统的深度学习加速器、常规CPU与新型类脑处理器节点之间的通信握手协议、数据格式互操作性原则以及混合算力的调度边界,为类脑芯片无缝接入主流云计算和数据中心基础设施扫清了工程定义盲区。
此外,IEEE体系围绕类脑AI生态延展出多个强相关的细分标准:
IEEE P3753:针对支持在线反馈与动态学习的人工智能强化学习系统架构和要求进行标准化,直接支撑类脑芯片在具身智能中的学习模型。
IEEE P3704 与 P3709:针对具身智能(Embodied Intelligence)的能力评估框架与代理人工智能(Agentic AI)进行规范,定义了自主机器人在未知环境下的智能边界。
IEEE P3723:定义电力领域智能边缘设备的数据处理框架,响应类脑传感器在工业物联网领域的低功耗接入需求。
IEEE P3225.02:建立基于区块链技术的可信AI数据共享框架,确保分布式的脉冲神经数据在边缘网络中流转时的网络安全(Cybersecurity)与隐私溯源。
这些系统级标准(期限通常设定至2029年)的密集出台,意味着类脑计算正快速脱离实验室的“自由探索”状态,跨入具备高度商业约束力与全球兼容性的工业落地阶段。
七、 跨域应用实测基准与极端场景效能验证
通过详尽的定量实测数据与应用案例(Case Studies),可以精准剥离技术浮夸,明确界定类脑系统在边缘智能、极低功耗控制与超低延迟信息提取方面的绝对优势区间。
7.1 流式大语言模型(LLM)与边缘端音频识别
在大型生成式模型(Generative AI)的边缘端部署方面,由于DRAM读写功耗和内存墙的限制,传统GPU面临着极高的功率墙。Loihi 2芯片利用无矩阵乘法(MatMul-free)量化架构、三进制累加器(Ternary accumulators)以及脉冲事件率编码(Event-rate encoding),在流式状态空间模型(Streaming State-Space Modeling, 典型如S4D算法)的运行评估中,展示出了颠覆性的能效跃升。
物理对标测试显示,在执行序列处理与词元(Token)生成任务时,Loihi 2芯片能够实现高达 41.5 tokens/sec 的系统吞吐量;而在生成模式(Generation mode)下,每个Token消耗的绝对能量仅为405毫焦耳(mJ)。与之形成强烈对比的是,基于传统冯·诺依曼架构的先进边缘计算板卡 NVIDIA Jetson Orin Nano 在执行完全对等的推理任务时,吞吐量仅为 13.4 tokens/sec,且每个Token的能耗飙升至 719-1200毫焦耳。这表明,在词元级流式序列生成任务中,Loihi 2的能源效率较传统嵌入式GPU提高了高达145倍,并将单次计算延迟大幅缩减了7倍;在预填充(Prefill)阶段,Loihi更以3.7 mJ/token的微小能耗彻底击穿了GPU的功耗底线,同时在INT8/FP16精度量化下保持了等同的基准准确率。
在高度依赖时间维度的实时唤醒词检测(Keyword Spotting, KWS)任务中,基于代理梯度直接训练的SNN在Loihi 2硬件上运行,展现出极端的时空稀疏优势。文献记录的综合能量延迟积(Energy-Delay Product)较 Jetson Orin Nano 基线实现了约250倍的能耗缩减与18倍的绝对延迟提速,响应时间控制在3毫秒(ms)以内。
7.2 自主微型无人机(MAV)神经形态控制与极端视觉SLAM
在自主机器人控制领域,特别是对载荷、电池容量与计算时延有着严苛约束的微型飞行器(MAVs),类脑计算展示了成为“杀手级”基础技术的潜力。传统的视觉里程计(Visual Odometry)和同步定位与建图(SLAM)算法依赖于全局快门相机(Frame-based cameras),其固定高频(如30-60 fps)的全帧像素刷新与后端密集的稠密矩阵处理流水线,在高速动态或光照剧变的环境下面临严重的运动模糊和高能耗。
将动态视觉传感器(Dynamic Vision Sensors, DVS,即事件相机)与神经形态处理器进行闭环集成提供了全新的工程范式。DVS仅以异步方式记录由于场景光强发生对数级变化而引发的局部像素阈值越界事件,具备微秒级的超高时间分辨率(无运动模糊)和极高的宽动态范围(HDR)。在极低照度(小于10勒克斯,信噪比恶化至-2 dB的极端弱光条件)下,传统视频系统面临完全黑屏与像素失效,而基于脉冲的神经视觉系统依旧能够通过捕捉极其稀疏的光子变化,重构目标轮廓并在稀疏学习架构下精准规避动态障碍物。
当这种异步信号流不经由传统数字图像处理器转换,直接输入专门配置的SNN执行无人机的低级姿态估计与PID闭环控制时,产生了令人瞩目的硬件级效率。一项实飞测试实验将通过模仿学习(Imitation learning)和时间平移数据增强训练所得的SNN模型直接烧录部署在一架名为Crazyflie的超微型无人机上。实测结果表明,这个端到端(Perception-to-control)的神经形态闭环网络可以以高达500Hz的频率向旋翼电调发出无抖动的电机控制指令。执行同样的飞行控制模型,基于Intel Loihi神经形态芯片的总功耗维持在1.007瓦特(其中静态开启待机功耗为1瓦,实际运行脉冲神经网络的动态功耗仅为惊人的7毫瓦,单次推理耗能低至27微焦耳)。作为对比,若将同样的网络映射到嵌入式GPU控制模块上,系统总功耗高达3瓦特,且由于内存I/O和线程同步的巨大开销,其运行帧率仅能维持在每秒25次左右。这种高达10至64倍的运行速度提升,叠加极低的稳态误差(如在相关触觉反馈任务中误差控制在3.41毫米),从根本上解除了制约微型空中机器人向仿生级(如昆虫般敏捷)飞行进化的实时算力极限。
值得注意的是,在不同复杂度的视觉任务评估中,基于商用Akida AKD1000处理器的测试表明,在执行简单的MNIST量化分类网络时,其推理耗时较NVIDIA GTX 1080 GPU缩短了76.7%,能量消耗降低了99.5%。然而,当处理复杂的YOLOv2目标检测模型时,由于网络拓扑复杂度急剧上升,Akida的推理时间反而比GPU长出118.1%,尽管其整体能量消耗依然保持了96.0%的缩减。这一数据客观表明,当前的神经形态处理器在低功耗边缘感知的特定应用边界内具备统治力,但在面对高度并行化的大规模稠密张量计算时,其可扩展性与GPU相比仍存在物理限制。
八、 3D封装演进、芯片架构与全球商业化市场预测
8.1 3D IC先进封装:打破硅面积限制的关键推手
神经形态芯片设计的核心在于实现极高密度的神经互连(即超大规模突触矩阵的物理布线),这在传统的二维(2D)单片硅平面工艺中不可避免地面临金属走线拥堵、信号RC延迟恶化与芯片面积膨胀的问题。进入2026年以后,先进封装(Advanced Packaging)尤其是三维集成电路(3D IC)及异构集成技术(Heterogeneous Integration),正成为支撑甚至主导类脑计算规模横向扩展的根本动力。
系统设计的宏观路线图正在从单纯的晶圆级大芯片制造转向高度解耦的芯粒(Chiplets)三维纵向堆叠。通过业界最前沿的混合键合(Hybrid Bonding)技术,不同工艺节点下的硅层通孔(TSVs)与微凸块间距被不断压缩至1微米(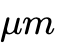 )甚至更低的物理尺寸。这使得系统设计者能够将海量的局部存储单元(如大容量SRAM模块或基于忆阻器的非易失性存储芯粒阵列)以极其微小的寄生电容和超低信号延迟直接三维压合于神经计算逻辑层的垂直正上方。这一物理维度的革新彻底拉近了计算器与内存的距离,完美匹配了类脑架构对超大规模、分布并行和局部短距离互联拓扑的严苛要求。
)甚至更低的物理尺寸。这使得系统设计者能够将海量的局部存储单元(如大容量SRAM模块或基于忆阻器的非易失性存储芯粒阵列)以极其微小的寄生电容和超低信号延迟直接三维压合于神经计算逻辑层的垂直正上方。这一物理维度的革新彻底拉近了计算器与内存的距离,完美匹配了类脑架构对超大规模、分布并行和局部短距离互联拓扑的严苛要求。
与此同时,为了应对由高带宽、高频脉冲并发激活所产生的极端热密度聚集现象(热场梯度不仅会导致底层CMOS晶体管阈值电压的漂移与信噪比劣化,更会直接影响光学互连的波长稳定性并诱发封装层面的热应力断裂),针对3D芯片的微流控芯片内冷却技术(Microfluidics inside the package)及复杂的多物理场热力学协同分析软件已从实验室走向投片量产。此外,共封装光学(Co-Packaged Optics, CPO)和光子集成电路(PICs)亦开始在服务器级类脑系统的数据通信网络中实现大规模的商用落地,用光子替代传统的铜线传输脉冲数据包,从根本上压制了长距离传输的焦耳热损耗。
8.2 市场规模的指数爆发与核心商业公司版图(2026-2030)
在技术突破与产业政策的双重刺激下,全球神经形态计算正迅速跨越学术界的概念验证(PoC)阶段,步入规模化商业部署的红利期。市场研究机构的多维数据一致印证了该领域的爆发性增长趋势:2023至2024年间,全球神经形态计算市场估值在52.7亿美元至75.2亿美元之间。受边缘人工智能(Edge AI)节点部署激增、物联网(IoT)安全监控及无人驾驶架构演进的强大驱动,预计到2030年至2033年,该市场的总规模将达到202.7亿美元至589.2亿美元的惊人体量,整个预测期内的年复合增长率(CAGR)高达19.9%至25.7%。其中,硬件终端组件(Neuromorphic Processors & Sensors)占据绝对的营收主导,图像处理和机器人传感器融合则是最主要的应用场景,而亚太地区被公认为增速最为迅猛的增量市场。
这一巨大的蓝海市场催生了异常活跃的商业公司与初创企业阵列,它们正在快速填补传统硅谷巨头留下的生态位:
BrainChip Holdings (ASX: BRN):作为数字类脑计算商业化的风向标,BrainChip推出了全面拥抱边缘计算的Akida全系列神经元处理器。2025年,其针对工业级边缘算力的AKD1500模块正式发布,并在年底成功获得了2500万美元(主要来源于LDA Capital的股权期权认购协议)的战略注资,用于推动Akida第二代架构以及在设备上原生运行的大型语言模型(Akida GenAI)的落地。其商业版图已拓展至与防务承包商(如Raytheon自主载具平台)、航天科研机构(AFRL、Frontgrade Gaisler)以及医疗穿戴设备的深度技术许可合作。
Innatera:作为欧洲初创势力的代表,推出了主打极低功耗脉冲模拟计算的T1 SNP处理器阵列(CES 2025),集成了RISC-V内核,专攻始终在线(Always-on)的音频与雷达传感器前端处理。
SynSense (时识科技):发布了Speck 2.0芯片阵列,将DVS事件视觉传感器与异步SNN处理逻辑直接进行了高度一体化的单片系统级封装,大幅占领了智能安防与消费级手势识别市场。
Aspinity 与 Prophesee:分别通过全模拟机器学习核心(AML100)和事件驱动型工业视觉Metavision传感器及SDK矩阵,从最底层传感器前端重构了数据采集范式,彻底消灭了冗余数据的数字化转换开销。
8.3 硅基新秩序:地缘政治与非传统架构的技术博弈
宏观地缘技术层面的封锁与脱钩约束正在倒逼全球半导体技术路线向非线性的多维架构演化(即所谓的“架构多元化”与“Sideways Innovation”)。
在面临先进制程光刻机(如EUV)及高端张量加速芯片出口禁令的区域(特别是中国),由于无法在传统微缩路线上直接对抗西方的密度优势,学术界与产业资本的巨额投入正战略性地全面转向基于忆阻器的存算一体(CIM)模拟类脑阵列、光电混合芯片技术以及基于先进芯粒互连的3D芯片堆叠技术(即采用类似“华为式”的多层空间堆叠来弥补单片性能的缺失)。这种在底层材料与非冯架构层面的被迫突围,正在构建以国家级电网安防、智慧城市海量物联网传感及机器人集群控制为主导的全新算力壁垒,甚至在特定基于推理的低精度端侧算力部署上逐步侵蚀传统GPU的市场份额。
与此同时,美国虽依然把持着底层EDA软件、顶级通用算力研发设施以及前沿框架生态(如拥有11.5亿个神经元的全球最大规模Hala Point系统的落成部署),但面临着由于AI泡沫降温导致的风险投资放缓、能源基础设施配套严重滞后以及关键类脑硬件研发人才向欧洲及亚洲外流的现实压力。欧洲则凭借着德国和瑞士等国在精密模拟电路设计、新材料制备以及极深厚的基础神经科学理论积淀,在全球类脑芯片的基础研发端保持着领导地位。在这个“新硅基秩序”的时代,掌控着先进特种半导体材料(如光刻胶与下一代存储材料)的日本,以及承接海量边缘AI硬件设计的印度,均作为不可或缺的底层支撑节点深刻影响着这一脑启发技术的最终落地方向。
九、 结论与发展启示
综合上述基于严密底层物理学拆解与详尽定量基准测试的数据分析,可以得出明确结论:神经形态计算体系已经彻底超越了单纯基于神经科学基础研究的仿生学物理模拟阶段,演变成为应对后摩尔时代算力危机与全球化能源瓶颈的实用型、战略级工业工程范式。
这一架构革命的核心逻辑在于其彻底摒弃了冯·诺依曼范式对时间(同步时钟)与数据(分离存储)的机械切割,创造性地将时间编码(稀疏的时序脉冲)与空间定位(高密度的分布式可塑性突触结构)无缝统一于底层物理介质的本征非线性动态属性之中。这种极其深刻的系统级重构,在解决边缘智能终端能源极度受限的复杂时序处理任务(诸如微型无人机群的自主敏捷导航、低照度极端视觉条件下的SLAM、高速流式状态空间与语言模型的端侧处理,以及始终在线的实时唤醒词监控)时,已经确凿无误地展示出相较于传统微处理器和GPU长达两个甚至三个数量级(百倍至千倍)的能效及响应延迟代差。
然而,要实现神经形态底层硬件在未来主流数据中心与大规模云端训练计算矩阵中对传统张量加速器主导地位的更替,整个行业领域必须在未来五年内强行跨越多个维度的交叉学科工程阻碍。
在器件底层与材料科学层面,必须通过引入具有高级拓扑微结构的新型铁电或多晶相变材料,以从根本的原子级层面平抑忆阻器等非易失性二端存储元件固有的电导状态漂移、不可控的周期间变异性以及限制互连密度的潜行电流效应。在先进制程与封装制造维度,系统集成商必须通过异构3D混合键合与高精度的微流控液冷热管理系统,彻底解决硅通孔极高互连密度下的良率损耗与热应力危机。在软件工具栈与工业标准层,全面加速以 IEEE P3762 异构混合推理标准为代表的一系列国际化协议的落实验证,并广泛推行 NIR 中间件和 Lava 等软硬件解耦生态的标准化适配。
神经形态计算技术与先进3D异构封装、新型量子/材料科学的深度融合演进,不仅正在重塑微纳电子工程的性能边界,更将在2026至2030年的关键窗口期内,决定全球泛在智能系统演进的话语权与大国半导体算力竞争的地缘版图。