



原文:Post-Earnings-Announcement Drift Prediction: Leveraging Post-event Investor Responses with Multi-task Learning 出版:ISR 机构:特拉华大学(美国)、亚利桑那州立大学(美国)
1 引言
每隔三个月,上市公司都要向公众公布自己赚了多少钱,这就是"季度财报"。按理说,这个消息一出,股价应该立刻反应完毕才对——但现实中,股价往往会在财报发布后的数天甚至数月内,持续地朝着同一个方向缓慢移动,好消息对应慢慢涨,坏消息对应慢慢跌。这个现象被金融学家称为"盈余公告后漂移"(Post-Earnings-Announcement Drift,简称PEAD)。能提前预测出哪些股票会漂移、漂移多大,就意味着潜在的真实收益,因此吸引了大量研究者和投资机构的关注。然而,如何准确预测PEAD,至今仍是一个未被完全解决的难题。
想象一下这个场景:2024年10月,某科技公司公布季报,实际利润比市场预期高出了15%,这个超出预期的部分叫做"盈余惊喜"(Earnings Surprise)。消息一出,股价当天跳涨了3%。但接下来一个月里,股价又悄悄涨了7%——这段"慢动作"的上涨,就是PEAD。传统的预测方法会用"盈余惊喜有多大"来预测这个漂移,但问题来了:这个指标太有名了,所有人都在用它,市场已经把它的信息消化得差不多了,预测效果越来越差。后来,研究者开始利用财报电话会议(earnings call)的文字记录来寻找更多线索——这是CEO和CFO向分析师解读财报的一小时通话,包含大量管理层对未来的看法。然而,即便加入了这些文字信息,现有模型仍然忽略了一个关键环节:财报发布之后,各类投资者是怎么反应的?分析师有没有上调盈利预测?基金有没有加仓?散户有没有疯狂买入?这些"投资者的反应"才是推动股价慢慢漂移的真实力量,但因为这些数据要在财报发布后数天乃至数月才能收集到,传统的单任务预测模型根本无法利用它们。
综合而言,本文面临的挑战主要体现在以下几个方面:
"盈余惊喜"这个老信号正在失效:由于被过度使用,市场已提前消化了这个信息,单靠它预测PEAD的能力越来越弱 关键的"中间环节"被忽视:投资者在财报后的反应(分析师调整预测、机构买卖、散户动向)是连接"财报消息"和"最终股价变动"的桥梁,但现有方法完全无法利用这些数据 时间悖论困住了传统模型:这些投资者反应数据需要等待数天乃至数月才能收集完整,而预测必须在财报发布当天就给出结论,二者在时间上存在根本矛盾 长文本处理与结构化数据融合困难:财报电话会议平均有7000多个单词,如何让AI既读懂这些长文本,又充分利用财务比率等结构化数字特征,是一个技术难题
针对这些挑战,本文提出了一种将投资者反应纳入多任务学习框架的"FinAux + GradPerp + MQT"方法:
这篇论文的核心创意在于:换一个角度使用"投资者反应"数据。传统模型把这些数据当"输入"——但因为时间来不及,根本用不上。本文则把它们当"训练时的额外作业"——模型在学习预测股价漂移(主任务)的同时,也被要求同时预测"分析师会不会上调盈利预测"、"机构投资者会不会净买入"、"散户会不会大量跟进"等辅助任务(辅助任务,auxiliary tasks,统称FinAux)。这就像一个学生在备考主科的同时练习相关副科,副科的训练让他理解得更深,主科成绩反而更好。更聪明的是,论文还设计了一套叫做GradPerp的"权重分配器":它会实时计算每个辅助任务给模型带来了多少"新鲜信息"(用数学上的梯度正交分量来衡量),对带来新视角的任务给更高权重,对和其他任务高度重复的任务降低权重,从而让模型的学习过程更高效。最后,整个系统搭载在一个叫做多查询Transformer(MQT)的神经网络上,可以为每个任务生成专属的"注意力探针",从同一份财报文本中提取出不同任务关心的不同信息。实验覆盖2010年至2022年的6万多次季报电话,结果表明该方法的预测精度和实际投资回报(日超额收益alpha)均显著优于现有方法,每日风险调整后的超额收益是传统盈余惊喜策略的两到三倍。
2 研究方法
2.1 问题定义与任务建模
在正式介绍模型之前,论文先明确了这个预测任务到底要"输入什么、输出什么"。
输入方面,模型有两类数据来源。第一类是非结构化输入,也就是财报电话会议的文字记录(Earnings Call Transcript)。每家公司每个季度都会开一次电话会,论文把这段文字记为 ,其中 是管理层讨论环节(Management Discussion)的文本, 是问答环节(Questions & Answers)的文本。之所以要把这两段文字分开处理,是因为研究发现两个环节在语言风格和信息含量上有明显差异——管理层讨论通常是提前准备好的,而问答环节更能反映管理层对突发问题的即时反应。第二类是结构化输入,包含16个人工提取的财务指标,比如盈余惊喜(earnings surprise)、管理层情绪得分等,这些都是金融文献中已经验证过对PEAD有预测力的特征。
输出方面,模型同时预测多个目标,这正是"多任务学习"的核心。主任务是 ,也就是从财报电话会议当天起算21个交易日内的累计异常收益(详见2.3节)。此外,模型还同时预测 个辅助任务(),这些辅助任务代表不同市场参与者的事后反应(详见2.4节)。
整个训练过程的目标函数是:
直觉上,这个公式的意思就是:模型要同时把主任务和所有辅助任务都尽量预测准,但不同任务的"重要程度"由权重 来控制。其中 是主任务的权重, 是第 个辅助任务的权重,所有权重加起来等于1,且这些权重本身也是模型在训练过程中自动学习调整的(具体方法见2.5节的GradPerp)。需要特别注意的是:虽然训练时要同时优化所有任务,但测试和评估只看主任务的预测效果——辅助任务的作用是在训练阶段帮主任务学得更好。
这个多任务框架对比传统的单任务学习(只预测PEAD)有什么好处?图2清晰地回答了这个问题:传统方法忽视了盈余新闻和股价运动之间的"中间桥梁"——投资者的事后反应。而MTL框架可以把这些事后反应变成辅助任务,在训练阶段"偷听"这些信号,却不需要在预测时等待这些数据的收集,从而实现了即时预测和利用后验信息的两全其美。
2.2 多层次多查询Transformer架构
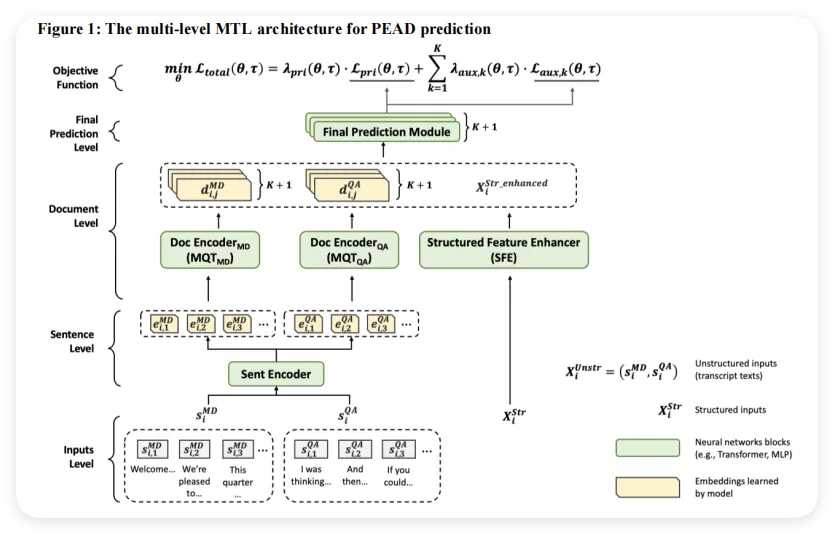
确定了任务框架之后,接下来要设计一个能处理长篇财报文本并融合结构化特征的神经网络。论文提出的架构(如图1所示)分为四个层次,数据从底部逐层向上流动。
第一层:输入层(Input Level):在最底层,非结构化文本 被拆分成MD和QA两段,每段再进一步切割成一个个独立的句子。举个例子,MD部分第一句可能是"Welcome, we're pleased to report...",第二句是"This quarter we achieved...",以此类推,形成句子序列 ,其中 。结构化特征 暂时不进入句子编码阶段,留到后面再处理。
第二层:句子层(Sentence Level):一个共享的句子编码器(Sentence Encoder)负责把每一句话变成一个向量。论文采用的是MPNet,这是一种预训练好的句子级Transformer模型,能把任意一句话映射为一个768维的数字向量(句子嵌入)。
具体来说,对于MD和QA各自的句子序列,编码器输出:
这里有一个细节:每句话是独立编码的,编码句子A时不会"看"句子B。这样设计主要是为了计算效率,句子之间的语义关系交给下一层来学。
第三层:文档层(Document Level):这是整个架构的核心,也是引入多任务学习的关键之处。MD和QA各有一个文档编码器(Doc Encoder),两者都采用多查询Transformer(MQT)。
MQT的巧妙之处在于:它为每一个任务(主任务+K个辅助任务)各准备一个独立的"查询向量"(Query Vector,长度256维),用来代表该任务的关注侧重点。这些查询向量通过注意力机制相互交互——直觉上,这就像是"预测股价漂移"和"预测分析师预测修正"这两个任务在互相"交流",互相借鉴对方关注的信息,从而让各任务的表示更加丰富。
每个文档编码器最终输出 个文档级嵌入向量(对应主任务和K个辅助任务):
结构化特征增强器(SFE):结构化特征只有16个数字,而文本嵌入有 个维度,如果直接拼接,16个数字很容易被"淹没"。为此,论文设计了结构化特征增强器:先用一个线性层把16维结构化特征升维到256维,再经过ReLU激活,得到增强后的特征 :
最终,每个任务 对应的特征是MD文本嵌入、QA文本嵌入和增强结构化特征的拼接,总维度为 :
第四层:预测层(Prediction Level):最顶层有 个独立的线性投影层,每个任务一个,各自将1792维特征映射为一个标量预测值。主任务输出的就是预测的 ,各辅助任务分别输出对应的市场反应指标预测值。
2.3 PEAD的度量方式
PEAD(盈余公告后漂移)的本质是:一家公司发布财报后,股价并不会立刻完全反映新信息,而是在接下来数天乃至数月内持续朝某个方向"漂移"。要捕捉这个漂移,需要一个能跨越不同股票和市场环境进行公平比较的指标。
论文采用累计异常收益(Cumulative Abnormal Return,CAR)作为PEAD的度量:
这里有几个关键概念:
是股票在第 个交易日的实际收益率( 是财报电话会议当天); 是预期收益率,即如果这次财报事件没发生,这只股票按照其风险特征应该获得的收益; 是异常收益,代表股价变动中专门由财报事件引起的那部分; 把21个交易日(约一个自然月)的异常收益加总,就得到 。
举个例子:假设某只股票在财报发布后的一个月里实际上涨了5%,但根据其风险特征,这只股票在这段时间里本来就应该上涨3%(预期收益),那么异常收益就只有2%,这才是真正由财报信息带来的价值。这样的设计能确保我们比较的是"财报信息本身的影响",而不是"市场整体上涨"的混淆效应。
论文使用"五特征模型(C5 model)"来估算预期收益,该模型考虑了公司规模、账面价值比、盈利能力、投资水平和价格动量五个风险维度,被证明在各类公司事件研究中表现优秀。选择21个交易日而非更长时间窗口,是在"足够捕捉PEAD效应"与"预测难度不过高"之间找到的平衡点。
2.4 辅助任务选择(FinAux)

这是论文最重要的创新之一。理解这部分,首先要弄清楚一个核心问题:为什么PEAD不能被立刻完全反映在股价里?
答案在于投资者的异质性与反应的时滞性。如图2所示,财报公布( 时刻)之后,不同类型的投资者——分析师、机构投资者、散户——需要各自消化信息、做出判断、采取行动,这个过程需要时间。正是这些陆续到来的市场反应,一点一点地把股价推向新的均衡水平,形成了持续数周乃至数月的"漂移"。
直觉上,如果我们能让模型"提前知道"这些投资者反应会是什么,模型就能更准确地预测股价最终漂移到哪里。但问题是:这些反应数据在财报发布当天( 时刻)还不存在,要等几天甚至几个月才能收集到,所以不能直接作为模型输入。
MTL框架的妙处在于:把这些数据作为辅助任务的预测目标(输出),而非模型的输入。这样,在训练阶段,模型通过同时学习"预测股价漂移"和"预测投资者反应",会被迫从财报文本中提取更深层的信息。而在实际预测时,模型只需要财报当天的数据,不需要等待任何事后数据,完全避免了"前瞻性偏差(look-ahead bias)"。
论文将这套辅助任务命名为FinAux,共包含以下六个指标(见表3):
第一类:股票分析师的预测修正(Revision)
股票分析师是专业的市场信息处理者,他们的职业声誉取决于预测准确性,因此在财报发布后会迅速更新自己对公司全年盈利的预测。这个"预测修正"被广泛视为市场观点变化的信号,定义为:
具体来说, 是分析师 在第 季度财报发布后一个月内对公司年末盈利预测的修正幅度,取所有分析师修正的中位数,再除以财报发布前一天的股价 进行标准化。举个例子:如果某公司股价是100元,而大多数分析师在财报后把全年盈利预测上调了等值于0.5元的幅度,那么Revision就是0.5%。这个正向修正往往预示着股价将继续上涨。
第二类:机构投资者的净资金流入(InstInflow 和 FundInflow)
机构投资者持有美国股市约70%-80%的市值,他们的买卖行为对股价影响极大。论文用两个数据源来捕捉机构投资者的反应:
来自Thomson/Refinitiv 13F数据库的机构整体净资金流入:
其中 是机构 在第 季度财报后三个月内对股票 的持仓美元价值变化量,所有机构加总即得净流入。正值说明机构整体在买入(看好该股),负值说明整体在卖出。
来自CRSP共同基金数据库的共同基金净资金流入(FundInflow)定义类似,专门聚焦于共同基金这一重要机构群体(截至2021年总资产超过21.3万亿美元)。
第三类:散户投资者的净资金流入(RetailInflow)
散户虽然持股比例不及机构,但对股价波动性有显著影响。散户净流入定义为:
即财报后三天内(注意这里窗口更短,只有三天,而非机构的三个月)散户买入订单与卖出订单的美元差值。窗口之所以更短,是因为散户的交易行为持续性较弱,且识别是否为散户订单本身存在估算误差,时间窗口越长误差累积越大。
第四类:不同时间窗口的累计异常收益(CAR(0,0) 和 CAR(0,3))
除了上述三类市场参与者的反应,论文还纳入了两个更短期的CAR作为辅助任务:财报当天的异常收益 和财报后三天的累计异常收益 。这是基于同质任务(Homogeneous Tasks)的思路——更短期的CAR相对更容易预测,可以给主任务提供"快捷通道"式的学习信号。实验表明 和 对整体性能提升贡献最大。
在选取这些辅助任务时,论文还遵循了"多样性原则":注意到 和 两者相关系数高达0.87,而 与其他任务的相关性几乎为零(-0.01至-0.03)。这种多样性正是GradPerp所鼓励的——不同类型的辅助任务为模型提供了来自不同维度的训练信号。
2.5 自适应任务权重方法(GradPerp)
有了合适的辅助任务,接下来的问题是:如何决定在训练中给每个任务分配多少"注意力"(权重)?
这个问题比看起来复杂得多。如果所有任务权重相同,高度相似的辅助任务会重复强化同一方向,而真正独特的辅助任务反而被稀释。如果像一些现有方法那样,把"梯度与主任务最相似"的辅助任务赋予最大权重,会加快收敛但可能损害泛化能力——毕竟,让模型学得更快不等于让模型学得更好。
论文的核心洞察是:**一个辅助任务的价值,不在于它和主任务有多像,而在于它能提供多少其他任务都没有提供过的"新信息"**。这就是GradPerp(Gradient Perpendicular,梯度垂直分量法)的设计哲学。
梯度是什么?
在深度学习中,每个任务在每次训练迭代时都会产生一个"梯度"——它是任务损失函数对模型参数的导数,代表"朝哪个方向调整参数能让这个任务预测得更准"。直觉上,梯度就是每个任务给模型发出的"更新指令",指令的方向代表调整方向,指令的大小代表调整幅度。
在第 步训练中,所有任务的梯度排成一个矩阵:
QR分解的核心思想
GradPerp对这个梯度矩阵进行QR矩阵分解:
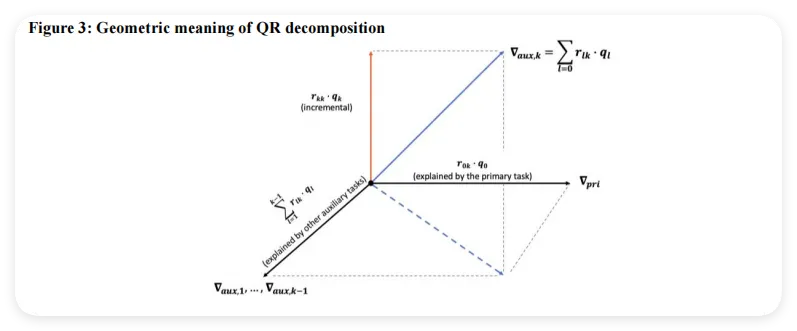
如图3所示,对于第 个辅助任务的梯度 ,QR分解会把它拆成两部分:
可被解释的部分(蓝色虚线):能被主任务梯度和前 个辅助任务梯度线性表达的分量——这部分信息是"重复"的,模型已经从其他任务中学过了; 垂直分量(红色线段 ):完全无法被其他任务梯度解释的"增量"部分——这才是第 个辅助任务独一无二贡献的新信息,其大小 就被用来作为该辅助任务的权重。
这就好比一个团队开会讨论方案:如果A已经提出了"要省成本、要提速度",而B补充了A完全没提过的"要保证质量",那么B的发言价值更高,应该给予更多关注;但如果C只是重复了A说过的"要省成本",那C的权重就应该低一点。
权重的计算公式
辅助任务的权重由 矩阵对角线元素决定:
主任务的权重为:
其中 是一个超参数,控制主任务相对于辅助任务的整体重要程度。 越大,模型越聚焦于主任务; 越小,辅助任务的正则化作用越强。论文发现 在大多数情况下效果良好,且模型对 的取值并不非常敏感。
与已有方法的对比
现有方法(如GradCos和OlAux)把"与主任务梯度余弦相似度越高"的辅助任务赋予越大权重,对应图3中蓝色虚线(投影分量)。GradPerp恰恰相反,它重视的是红色实线(垂直分量)——那些在方向上与其他任务最"不同"的辅助任务。这种"奖励多样性"的策略,类似于正则化技术(如LASSO、SVM),虽然可能减慢收敛速度,但能提高模型在未见数据上的泛化能力。
实现细节
为了避免随机梯度下降带来的噪声,GradPerp使用指数移动平均(EMA)来平滑权重更新:
论文中 ,意味着权重更新非常平滑,不会因为某次批次数据的随机性而大幅波动。此外,计算梯度时只针对MQT的最后一个解码块,而非所有模型参数,这大大降低了计算量,而实验表明这种近似几乎不影响GradPerp的效果。
在任务排序上,论文按辅助任务与主任务的相关系数从高到低排列(即 、、 等排在前面),实验发现这样略微优于其他排列方式。
实验结果证明,GradPerp在PEAD预测中表现最佳,不仅超过了其他六种自适应权重方法(包括GradCos、OlAux、Uncert等),甚至比固定等权重(FixedEqualWeights)高出约13%的预测性能(EV从8.02%提升至9.06%),且额外计算开销极小(训练时间仅为等权重基准的1.5倍)。
3 实验
3.1 实验设置
数据集: 研究使用了2008年至2022年间来自S&P Capital IQ数据库的财报电话会议记录,筛选条件包括:在Russell 3000指数中连续挂牌超过12个月、在数据库中有超过4条财报记录,且股价与财务数据完整。最终数据集包含2,728只股票、共61,223条季度财报记录。平均每条财报记录约7,209个单词(368个句子),其中管理层讨论(MD)部分约2,895个单词,问答(QA)部分约4,327个单词。
基准模型: 选取了来自金融、信息系统和计算机科学领域的五类基准:标准预期外盈余(SUE)单变量回归模型、包含多个财务比率的OLS多元回归、基于词袋模型的PEAD.txt、分层双向LSTM,以及分层Transformer。
评估指标: 主要使用解释方差(Explained Variance,EV)作为预测性能指标,EV越高代表模型预测越准确。经济意义层面则采用风险调整后的超额收益Alpha(通过Carhart六因子模型回归的截距项),正且显著的Alpha代表模型具备实际投资价值。
实验细节: 采用滚动窗口方式:以连续两年数据训练,随后一个季度作为测试集,窗口每次向前移动一个季度,共生成52个窗口,覆盖2010年第一季度至2022年第四季度。模型使用AdamW优化器,学习率为1e-4,批次大小32,在Nvidia RTX 6000 Ada GPU(48GB显存)上训练,并使用早停策略(连续3个epoch验证集EV无提升则停止)。
3.2 实验结果
实验一、核心预测性能对比实验
目的:全面验证本文提出的FinAux+GradPerp+MQT模型在PEAD预测精度上是否优于来自金融学、信息系统和计算机科学领域的五类基准模型,并检验多任务学习(MTL)框架是否带来显著性能提升。 涉及图表:表6(此表汇总了所有基准模型和本文模型的描述);表7(此表展示了所有模型在Russell 3000、Russell 2000和S&P 500三个股票样本上以EV衡量的预测性能,并报告了52个滚动窗口的均值和标准差) 实验细节概述:这是本文最核心的实验,旨在系统地验证所提出方法的有效性。实验精心选取了来自三个不同领域的基准模型:金融领域包括SUE(仅用"实际盈利与预期盈利之差"预测股价漂移的单变量回归)、OLS(使用包括盈利意外在内的多个财务比率的多元回归)和PEAD.txt(用词袋模型表示财报文本的机器学习模型);神经网络领域则包括分层双向LSTM和分层Transformer,分别代表了自然语言处理任务中最主流的两类深度学习架构。本文提出的模型FinAux+GradPerp+MQT,以及其配套变体FinAux+GradPerp+Transformer,均归属MTL类别,与上述不使用多任务学习的单任务模型(STL)形成明确对照。实验采用上文描述的滚动窗口方式,在52个窗口上分别训练和测试,最终报告EV的平均值与标准差。为进一步验证统计显著性,研究者对全部基准模型和本文模型进行了单尾t检验,零假设为基准模型优于本文模型。结果显示,本文模型FinAux+GradPerp+MQT在Russell 3000全样本上的EV达到9.06%,在所有模型中最高,远超同为神经网络的单任务Transformer(7.38%)和LSTM(5.31%),更大幅领先传统金融方法SUE(0.86%)和OLS(3.70%)。两个MTL模型均以0.001的显著性水平统计性地超越全部非MTL基准。此外,实验还发现,不论是哪类基准,小盘股(Russell 2000)的预测EV均高于大盘股(S&P 500),这与金融文献中"大盘股受到更严密的分析师和投资者关注、因此更难预测"的结论一致。 结果:FinAux+GradPerp+MQT以9.06%的EV成为性能最优的模型,在统计上显著超越所有基准(p<0.001)。多任务学习框架整体优于单任务框架,MQT架构优于普通Transformer,小盘股的预测表现整体优于大盘股。
实验二、设计组件消融分析实验
目的:逐步移除模型中的各个设计创新(SFE、GradPerp、FinAux),量化每个模块对整体预测性能的独立贡献,从而验证各设计选择的必要性。 涉及图表:表8(此表展示了分别去除SFE、GradPerp(替换为固定等权重)、FinAux和GradPerp(退化为STL模型)后,模型在S&P 500、Russell 2000和Russell 3000上EV的变化情况) 实验细节概述:采用标准的消融实验设计,每次仅去除一个设计组件,保持其余组件不变,观察EV的下降幅度。 结果:在Russell 3000上,去掉SFE后EV从9.06%降至6.47%(降幅28.5%),去掉GradPerp(改用固定等权重)后EV降至8.02%(降幅11.5%),完全去掉FinAux和GradPerp(退化为STL)后EV降至7.38%(降幅18.6%)。三个组件均对最终性能有显著贡献。
实验三、实现PEAD的可视化实验
目的:通过直观的曲线图展示各模型预测的股票组合在财报发布后长达一年的累计异常回报走势,从视觉层面验证模型的经济可行性。 涉及图表:图4(此图展示了各模型按预测PEAD将股票分为五分位后,最高与最低五分位组合差值的CAR曲线,横轴为财报发布后的交易日数(0至250天),纵轴为累计PEAD百分比) 实验细节概述:将每个季度的股票按模型预测的PEAD分为五个等级(五分位),绘制最高与最低五分位的差值曲线,模拟一种多空策略的累计收益轨迹。 结果:FinAux+GradPerp+MQT在一个月、一个季度和一年后分别实现了1.99%、4.19%和6.14%的实现PEAD,位居所有模型之首。传统的SUE策略曲线几乎持平,印证了"仅靠盈利意外预测PEAD的能力正在减弱"这一文献结论。股价漂移在一个月预测期结束后仍持续,说明PEAD具有较强的持续性。
实验四、辅助任务有效性分析实验
目的:一是验证各辅助任务是否比主任务更易预测("窃听效应"假设),二是通过逐一剔除辅助任务评估各类投资者响应数据对主任务的实际贡献。 涉及图表:表9(此表展示了单独预测每个辅助任务与主任务CAR(0,21)时各自的EV,用于比较预测难度);表10(此表展示了依次去除RetailInflow、InstInflow+FundInflow、Revision、CAR(0,0)+CAR(0,3)后模型EV的变化) 实验细节概述:用与本文架构相同的模型和输入,但去掉多任务组件,单独预测每个辅助任务,通过EV对比衡量难度。 结果:除RetailInflow(EV 1.78%)和InstInflow(EV 4.83%)外,其余辅助任务的EV均高于主任务(7.38%),其中Revision的EV高达25.87%,证实辅助任务整体上比主任务更易预测。消融分析显示,CAR(0,0)和CAR(0,3)贡献最大,其次是Revision,所有辅助任务均带来正向提升。
实验五、GradPerp与其他加权方法对比实验
目的:验证GradPerp相对于六种已有自适应加权方法(以及固定等权重方法)的优越性,同时评估其额外计算开销是否可接受。 涉及图表:表11(此表展示了GradPerp与OlAux、GradCos、Uncert、AdaMT、DWA、GradNorm及FixedEqualWeights在EV和每轮训练时间(以FixedEqualWeights为基准归一化)上的全面对比)\ 实验细节概述:在保持FinAux和MQT架构不变的前提下,分别替换不同的加权策略,并报告52个窗口上的平均EV。 结果:GradPerp在Russell 3000上取得最高EV(9.06%),超越第二名GradCos(8.07%)和固定等权重(8.02%)。偏向主任务的方法整体优于无偏好方法,GradPerp的训练时间(相对值1.5)与其他梯度类方法相当,计算开销合理。
实验六、经济意义评估实验
目的:通过构建真实的"只买多"和"多空"两类投资组合,以风险调整后的超额收益Alpha评估各模型的实际投资价值,检验预测性能的提升能否转化为可观的经济回报。\ 涉及图表:表12(此表展示了所有模型在Russell 3000、Russell 2000、S&P 500样本上,只买多策略和多空策略的日均Alpha及其统计显著性);图5(此图展示了2010至2022年间FinAux+GradPerp+MQT模型的时变Alpha动态走势,以及同期市场指数变化) 实验细节概述:只买多策略选取每季度预测PEAD位于最高五分位的股票,于财报发布次日买入,持有21个交易日(约一个月);多空策略在此基础上额外做空最低五分位股票。Alpha由Carhart六因子模型回归截距项计算,正且显著表示模型创造了超越风险预期的收益。 结果:FinAux+GradPerp+MQT在Russell 3000上实现日均Alpha 0.064%(只买多,p<0.001)和0.090%(多空,p<0.001),均为所有模型中最高或并列最高。多任务模型对小盘股(Russell 2000)的Alpha提升尤为明显(多空Alpha达0.125%),对大盘股(S&P 500)的优势相对较小。时变Alpha图显示,Alpha在大部分时间段保持正值,但在2020年和2022年初市场剧烈波动期间出现明显下降,表明策略在极端市场环境下承受一定压力。
4 总结后记
本论文针对盈余公告后股价漂移(PEAD)预测这一经典金融问题,指出传统单任务学习(STL)框架忽略了"投资者事后响应"这一关键中间环节。为此,作者提出了一套多任务学习(MTL)框架,核心创新有三:一是设计了 FinAux 辅助任务集,纳入分析师预测修正、机构/零售资金流入等事后投资者反应指标;二是提出 GradPerp 自适应任务加权方法,通过 QR 分解让"提供更多样化训练信号"的辅助任务获得更大权重;三是基于多查询 Transformer(MQT)架构,配合结构化特征增强模块(SFE),同时处理 MD/QA 两段文本与结构化财务特征。
本文内容如有不对烦请留言指正
END
AI智能体(智能体架构师) | "分布式系统"视角看AI Agent(如何设计好的AI Agent) AI审稿 | ReviewEval:用AI给学术论文写同行评审,还能自我打分? |
欢迎关注「码农的科研笔记」公众号