


摘要
2024年至2025年,全球软件工程领域经历了一场静水流深的范式革命。随着大语言模型(LLM)从实验性的技术展示转向企业级的核心基础设施,AI编程助手(AI Coding Assistants)已不再仅仅是提升个人效率的工具,而是正在重塑企业研发的全生命周期(SDLC)。本报告基于对全球金融、医疗、制造及科技行业头部企业的深度调研,结合中国市场的独特生态,旨在揭示这一变革背后的真实逻辑、实施路径及潜在风险。
研究显示,全球企业AI的采用率已达到78%,特别是在软件开发领域,AI正逐渐从“副驾驶”(Copilot)演进为具备自主规划能力的“智能代理”(Agent)。然而,宏观数据的繁荣掩盖了微观层面的复杂性。实证研究表明,尽管腾讯、谷歌等科技巨头报告了高达50%的代码生成率,但在特定场景下,尤其是对于资深开发者而言,AI的引入可能导致任务完成时间增加19%,这一“生产力悖论”揭示了认知负荷转移与流程适配滞后的深层矛盾。
与此同时,中国市场在数据主权、供应链安全及信创战略的驱动下,走出了与全球市场截然不同的发展路径。以腾讯、蚂蚁集团、华为为代表的企业,通过私有化部署、全栈自主及深度业务融合,构建了一套具有中国特色的智能研发体系。
本报告长达15,000字,将分六个章节详细剖析上述议题,为技术决策者提供一份详尽的实证参考。
一起来看这场“编程进化史”大片。
01
宏观背景:
智能研发(AI4SE)的全球经济技术图谱
► 1.1 从炒作到部署:2025年的全球AI格局
进入2025年,人工智能的发展已跨越了Gartner技术成熟度曲线的“期望膨胀期”,进入了实质性的“稳步爬升复苏期”。根据斯坦福大学HAI发布的《2025年AI指数报告》,企业对AI的投资呈现出显著的务实趋势。2024年,美国私人AI投资额达到1091亿美元,是中国的近12倍,但这并未阻碍中国在应用层面的快速跟进与差异化创新。
在软件工程领域,IDC的数据预测,到2028年,全球AI平台软件收入将达到1530亿美元,年复合增长率(CAGR)高达40.6%7。这一爆发性增长的背后,是企业对“软件吞噬世界”这一命题的再升级——如今,是“AI编写软件来吞噬世界”。
高盛的研究指出,生成式AI有望通过自动化约40%的编码工作,推动全球GDP增长7-10%。对于企业而言,这意味着研发成本结构的根本性重塑:人力成本占比可能下降,但算力与数据治理的成本将显著上升。
► 1.2 技术演进:语境感知与代理化趋势
2025年的AI编程工具已与2023年的初代产品有着天壤之别。早期的工具主要基于“中间填空”(Fill-in-the-middle)技术,解决的是单行或函数级的代码补全问题。而当前的行业前沿已向以下三个方向演进:
超长上下文(Infinite Context):随着Gemini 3.5 Pro、Claude 4.6等模型支持百万级Token的上下文窗口,AI助手不再局限于当前文件,而是能够读取整个代码仓库(Repository-level understanding)。这意味着AI可以理解复杂的跨文件依赖、架构规范及隐式约束,从而大幅降低了生成的“幻觉”率。
检索增强生成(RAG)的标准化:为了解决通用模型对企业私有知识(如内部框架、业务逻辑)的无知,RAG已成为企业级部署的标配。高盛和摩根大通的案例均表明,只有经过私有文档库微调或RAG增强的模型,才能在高度专业化的金融软件开发中发挥作用。
从Copilot向Agent的跃迁:新一代工具开始具备“代理”属性。它们不仅能写代码,还能自主运行终端命令、解析报错信息、生成单元测试并修复Bug。这种“闭环解决问题”的能力,标志着AI开始分担开发者的认知负荷,而非仅仅是打字负荷。
► 1.3 软件开发生命周期的重构
传统软件开发生命周期(SDLC)通常遵循“需求-设计-编码-测试-部署”的线性流程。AI的介入正在将这一流程重构为“意图-生成-验证”的循环。贝恩公司(Bain & Co.)的报告指出,虽然编码环节仅占SDLC的25-35%,但AI在需求分析(将模糊需求转化为规格说明书)、自动化测试(生成边缘案例)及遗留代码解释上的应用,正在产生比单纯编码更大的价值。这种全流程的渗透,要求企业必须重新设计研发管理流程,将“提示词工程”和“AI输出审查”纳入标准作业程序(SOP)。
► 1.4 关键洞察与行动建议
差异化部署策略:美国企业依托公有云 SaaS 便捷使用最新模型,而中国企业需在合规框架下探索混合云和本地化部署,构建私有模型池与安全运行环境。
成本和ROI考量:海外生态通过订阅付费降低了中小团队门槛,中国企业因大模型调用成本和信创要求,需对算力和许可投入进行精细化评估,选择合适的模型和工具以确保投资回报率。
人才与组织准备:跨国企业更注重研发流程的重构和 AIOps 流水线,国内组织应加速培养懂 DevOps 与 AI 的系统架构师,推动规范与指标体系建设。
02
全球企业实证案例深读:
效能与合规的平衡术
全球企业,特别是受到严格监管的金融与医疗巨头,在AI编程的落地实践中积累了大量关于治理、合规与ROI测算的实证经验。
► 2.1 金融服务业:华尔街的算法军备竞赛
金融行业因其高薪酬成本和高风险属性,成为AI编程工具ROI最高的落地场景之一。
2.1.1 高盛(Goldman Sachs):将AI内化为核心竞争力
战略背景:
高盛长期以来标榜自己为“科技公司”,其拥有数亿行专有代码,涵盖复杂的衍生品定价、高频交易及风险管理系统。面对技术债务和日益增长的维护成本,高盛在2023年启动了生成式AI的战略部署。
实证落地细节:
高盛并未直接向员工开放ChatGPT,而是选择了一条更为稳健的路径——将生成式AI深度集成到其内部开发者平台(Internal Developer Platform)中。
私有化微调与RAG:高盛利用银行内部的代码库和项目文档对模型进行了微调(Fine-tuning)。这使得AI助手不仅懂Python,更懂“高盛风味的Python”——即符合高盛内部SecDB数据库接口规范和合规要求的代码。
规模化应用:截至2025年,该工具已覆盖超过10,000名员工。
量化成效:根据高盛CIO Marco Argenti的披露,AI工具在日常任务(包括代码编写、文档分析、邮件摘要)中节省了员工约25%至40%的时间。在纯粹的代码生成环节,生产力提升约为20%。
深层洞察:
高盛案例的核心价值在于其对“知识管理”的重新定义。在传统模式下,新员工需要数月时间阅读文档和请教前辈才能理解遗留系统。而现在,AI充当了“全知全能的导师”,通过自然语言问答,大幅缩短了新员工的Onboarding时间。这种从“隐性知识”向“显性交互”的转变,是高盛数字化转型的关键一环。
2.1.2 摩根大通(JPMorgan Chase):构建生态级的AI基础设施
战略背景:
与高盛类似,摩根大通(JPMC)也面临着巨大的遗留系统挑战。作为美国最大的银行,JPMC拥有超过20万名员工和海量的COBOL、Java代码。
实证落地细节:
LLM Suite平台:JPMC并没有依赖单一工具,而是开发了名为“LLM Suite”的内部平台,作为连接底层大模型(如GPT-4)与上层业务应用的中间件。这个平台屏蔽了模型的复杂性,统一处理数据脱敏、合规审查和费用管理。
业务实效:
1) 财富管理:在资产与财富管理部门,AI工具帮助开发团队快速构建数据分析仪表盘,使得顾问能更专注于高价值客户服务。实证数据显示,该部门2024年的总销售额同比增长了20%,部分归功于AI带来的运营效率提升。
2) 代码现代化:JPMC利用AI加速了从COBOL到Java的迁移工作。AI工具不仅负责代码翻译,还负责生成解释文档和单元测试用例,这在人工操作中通常是成本最高、最易出错的环节。
采用规模:已有超过20万名员工(包括非技术人员)访问了该平台,其中超过一半的人每天多次使用。这表明AI编程能力正在溢出,赋能非专业开发者(Citizen Developers)解决简单的技术问题。
► 2.2 医疗健康业:在精准与伦理的边缘试探
医疗行业的特殊性在于,代码的错误可能直接导致患者生命安全的威胁或巨额的合规罚款。
2.2.1 梅奥诊所(Mayo Clinic):双重Coding的自动化
在医疗语境下,“Coding”既指软件编程,也指医疗分类编码(Medical Coding,即将病历转化为ICD-10/CPT计费代码)。梅奥诊所的AI实践横跨了这两个领域。
实证落地细节:
医疗编码自动化:梅奥的研究人员利用XGBoost等机器学习模型,对急诊科(ED)的数十万份就诊记录进行了分析。研究结果令人振奋:模型在处理复杂的4级和5级专业计费代码(CPT codes)时,AUC值分别达到了0.94和0.95。在设定99%的高精度阈值下,该模型能够全自动处理57%的复杂病历,完全无需人工干预。这不仅大幅降低了行政成本,也减少了因人为错漏导致的医保拒付。
软件研发加速:梅奥通过“Mayo Clinic Platform”与微软紧密合作,是首批部署Microsoft 365 Copilot和GitHub Copilot Enterprise的医疗机构。AI工具被用于加速临床科研数据平台的构建,帮助工程师快速编写ETL(提取、转换、加载)脚本,处理FHIR标准的医疗数据。
深层洞察:
梅奥的案例揭示了AI在“规则密集型”任务中的绝对优势。无论是医疗计费规则还是数据交换标准,本质上都是高度结构化的逻辑。AI在此类任务上的表现往往优于人类,因为它们不会疲劳,也不会因疏忽而遗漏规则。
2.2.2 联合健康集团(UnitedHealth Group):算法偏见的警示录
案例复盘:
作为美国最大的健康险公司,UnitedHealth提供了一个重要的反面教材。其子公司NaviHealth开发的AI工具“nH Predict”因高达90%的错误率和频繁的拒赔建议,引发了集体诉讼和监管调查。
实证教训:
这一事件突显了“黑盒AI”在关键决策系统中的风险。尽管UnitedHealth辩称该工具仅用于提供参考,但在实际操作中,理赔人员往往过度依赖AI的判断。这迫使UnitedHealth在后续的AI战略中进行重大调整:
转向负责任AI:确立了“透明度、隐私、持续改进”三大原则,明确AI不得替代临床判断。
应用场景调整:将AI的重心从“决策端”移回“辅助端”,如临床文档自动生成、患者咨询汇总等风险较低的领域。目前,该集团已投产超过1000个此类AI应用。
► 2.3 制造业与科技业:物理与数字的融合
2.3.1 梅赛德斯-奔驰(Mercedes-Benz):生产线上的数字革命
实证落地细节:
奔驰将ChatGPT集成到其MO360数字生产生态系统中,开创了“自然语言编程”在工业现场的先河。
赋能一线工人:通过语音接口,生产线上的质量工程师可以直接询问:“上周C级轿车喷漆环节的主要缺陷是什么?”AI会自动将此查询转化为底层的SQL或API调用,并返回可视化的图表20。这打破了数据分析的技术门槛,使得不具备编程能力的一线员工也能利用数据优化生产。
效率目标:奔驰预计,通过此类数字化工具的普及,到2025年其乘用车生产效率将提升20%。
2.3.2 谷歌(Google):单体仓库(Monorepo)的红利
实证落地细节:
谷歌在AI编程上的激进程度令人咋舌。据报道,谷歌内部超过25%的新增代码由AI生成,部分团队甚至达到了50%。
Monorepo优势:谷歌拥有全球最大的单一代码仓库。这意味着其AI模型(基于Gemini)可以访问到公司历史上所有的代码、文档和测试用例。这种极度丰富且标准化的训练数据,使得AI生成的代码在谷歌内部环境中具有极高的可编译性和合规性,远超外部通用模型。
03
中国企业实证案例深读:
自主生态与全栈突破
与全球市场主要依赖SaaS模式不同,中国企业在AI编程助手的发展上呈现出鲜明的“私有化”、“全栈自主”和“信创适配”特征。面对外部技术封锁和内部数字化转型的双重压力,中国企业走出了独特的创新路径。
► 3.1 互联网巨头的“降本增效”战役
3.1.1 腾讯(Tencent):CodeBuddy与WeDev的深度耦合
实证背景:
腾讯拥有数万名研发人员,覆盖游戏、社交、金融科技等多元业务。在“降本增效”成为行业主旋律的背景下,腾讯将AI编程助手视为提升研发效能(研效)的战略抓手。
实证数据与落地细节:
覆盖率与生成率:根据《2025腾讯研发大数据报告》,腾讯内部AI代码助手(CodeBuddy)的渗透率已超过90%,50%的新增代码由AI辅助生成4。这一数字远超行业平均水平(通常在20-30%),显示了AI在腾讯研发体系中的核心地位。
效能提升:统计显示,引入AI助手后,腾讯内部的平均编码时长缩短了40%。
平台化整合:腾讯并未将AI助手作为一个独立的IDE插件,而是将其深度集成到公司级研发效能平台“WeDev”中。这意味着AI不仅能感知代码,还能感知需求(Requirement)和缺陷(Bug)。例如,当开发者在WeDev上领取一个修复Bug的任务时,AI助手会自动拉取相关的代码片段,并尝试生成修复方案。
开源协同(Oteam):腾讯强大的内部开源文化为AI提供了高质量的训练数据。标准化的代码规范、完善的文档和测试用例,使得AI模型(基于混元大模型)能够学习到腾讯特有的编程范式。
3.1.2 蚂蚁集团(Ant Group):金融级AI编程的极致严谨
实证背景:
作为支付宝的母公司,蚂蚁集团的技术栈承载着万亿级的资金流转,对代码的安全性、稳定性和合规性要求极高。
实证数据与落地细节:
CodeFuse与全生命周期管理:蚂蚁推出的CodeFuse不仅用于代码生成,还贯穿了代码迁移、重构、测试和运维的全流程。蚂蚁利用其庞大的历史代码库对模型进行了深度SFT(监督微调),使其具备了理解复杂金融业务逻辑的能力。
业务价值验证:在信贷审批系统的开发维护中,AI辅助的代码重构帮助将贷款决策速度提升至3.2秒,同时保持了仅0.38%的违约率。虽然这主要归功于风控模型,但AI编程工具加速了底层系统的迭代周期。
采用率与反馈循环:在蚂蚁内部应用“支小宝”的开发中,新版AI工具的问答采纳率提升了20%。蚂蚁非常重视RLHF(基于人类反馈的强化学习),通过收集内部开发者对AI生成代码的修改和采纳数据,不断优化模型。
开源与标准:蚂蚁开源了CodeFuse模型,并发布了Fin-Eval评测基准,这是行业内首个专门针对金融领域AI编程能力的测试标准,填补了通用评测在垂直领域的空白。
3.1.3 阿里云(Alibaba Cloud):通义灵码的生态普惠
实证数据与落地细节:
市场表现:通义灵码已服务超万家企业,每日推荐代码超3000万次,AI代码生成占比超过25%。
权威评测:在2024年6月中国信通院组织的首轮代码大模型评估中,通义灵码在通用能力、专用场景和应用成熟度等维度均表现优异,获得最高的“4+级”评级。
落地案例:在中华财险、长安汽车等传统企业中,通义灵码被用于辅助Java和C++开发,显著降低了传统行业数字化转型的技术门槛。
► 3.2 传统行业与ICT巨头的突围
3.2.1 中国工商银行(ICBC):体制内的AI4SE变革
实证背景:
作为“宇宙行”,工行拥有全球银行业最庞大的IT架构之一,面临着将核心业务系统从大型机(Mainframe)迁移到分布式架构的艰巨任务(主机下移)。
实证数据与落地细节:
组织保障:工行组建了专门的“AI4SE”(AI for Software Engineering)工作团队,系统性推进智能研发。
生成占比:截至2024年,工行内部AI生成的代码占比已达32%。
典型场景:
1) 异构语言转译:工行北京分行利用AI助手,成功将大量遗留的ProC代码转换为Python。ProC作为一种古老的嵌入式SQL C语言,人才极其匮乏。AI的介入不仅解决了“谁来写”的问题,还通过自动化转换保证了业务逻辑的一致性。
2) 信贷国产化:在信贷系统国产化改造中,AI助手帮助开发人员快速生成适配国产数据库(如GaussDB、OceanBase)的SQL语句,屏蔽了底层数据库语法的差异。
部署模式:出于绝对的安全考量,工行采用了完全的私有化部署模式,确保核心银行系统的代码不出内网。
3.2.2 华为(Huawei):全栈自主的绝地反击
实证背景:
在外部制裁的极端压力下,华为必须构建从芯片(Ascend)、框架(MindSpore)到模型(Pangu)再到工具(CodeArts)的完全自主研发链条。
实证数据与落地细节:
CodeArts Snap:基于华为自研的盘古研发大模型,CodeArts Snap专注于华为内部广泛使用的C/C++、Java及自研语言。
功能实证:在华为内部的操作系统(OpenHarmony/openEuler)和数据库(openGauss)开发中,CodeArts Snap展现了强大的单元测试生成能力。利用静态分析技术,它能够深入理解复杂的函数调用关系,生成高覆盖率的测试用例。
安全特性:针对核心知识产权保护,CodeArts Snap提供了“只检索不生成”(RAG Only)模式。在这种模式下,AI仅被允许在企业私有知识库中检索代码片段进行推荐,严禁利用模型自身的“记忆”生成可能侵权或泄密的外部代码。
3.2.3 吉利汽车(Geely):软件定义汽车的加速器
实证背景:
随着汽车向智能化转型,软件代码量呈指数级增长。吉利汽车软件中心面临着交付周期短、安全标准高(ISO 26262)的双重挑战。
实证数据:
吉利汽车数智中心AI产品专家透露,通过引入AI编程助手,其在编码阶段的效率提升了30%,带动项目整体提效10%。更重要的是,AI工具被集成到符合功能安全标准的开发流程中,辅助生成符合MISRA C++规范的代码,确保了车载软件的安全性。
04
生产力悖论:
数据背后的冷思考与度量重构
尽管上述案例充满了令人振奋的增长数据,但2025年的一项关键学术研究为行业泼了一盆冷水,揭示了“体感提升”与“实际产出”之间的巨大鸿沟。
► 4.1 METR实证研究:资深开发者的“减速”现象
研究概述:
非营利研究机构METR在2025年初进行了一项严格的随机对照试验(RCT)。研究招募了16名经验丰富的开源开发者,让他们在熟悉的复杂代码库中完成真实的任务(Bug修复、新功能开发)。
惊人发现:
主观与客观的背离:开发者在实验前预测AI会提升24%的效率,在实验后自我感觉提升了20%。然而,客观的计时数据显示,使用AI工具(主要是Cursor Pro + Claude 3.5/3.7)实际上导致任务完成时间增加了19%。
原因剖析:
1) 审查成本(Review Overhead):AI生成的代码看似完美,但往往包含细微的逻辑错误或幻觉。资深开发者花费了大量时间去调试和验证AI生成的代码。这种“阅读与修正”的认知负荷(Cognitive Load)往往高于直接编写代码。
2) 上下文迷失:在处理庞大且复杂的遗留代码库时,AI往往难以获取完整的依赖关系和架构约束,导致生成的代码无法直接运行,需要大量人工修改。
3) 盲目自信:开发者倾向于高估AI的正确性,导致在后期集成测试时才发现Bug,返工成本高昂。
► 4.2 生产力悖论的深层逻辑
METR的研究并非孤例。它揭示了AI编程目前的局限性:AI擅长生成样板代码(Boilerplate),但在涉及复杂系统逻辑和隐性知识(Tacit Knowledge)的任务中,它可能成为干扰源。
这解释了为什么腾讯、谷歌等公司能取得成功,而独立开发者可能感到受阻:
基础设施的差异:大公司拥有高度标准化的代码库和完善的自动化测试体系(CI/CD)。当AI生成代码后,系统能立即运行数千个测试用例进行验证,快速反馈错误。而缺乏这种基础设施的团队,只能靠人工肉眼审查,效率自然下降。
任务类型的差异:大公司的“降本增效”往往包含大量重复性的搬砖工作(如DTO转换、CRUD接口),这是AI的舒适区。而开源项目的核心维护者往往处理的是极具创造性和复杂性的架构问题。
► 4.3 ROI度量模型的重构
传统的“代码行数”或“工时节省”已不足以衡量AI的价值。Gartner和IDC建议企业采用更立体的度量框架:
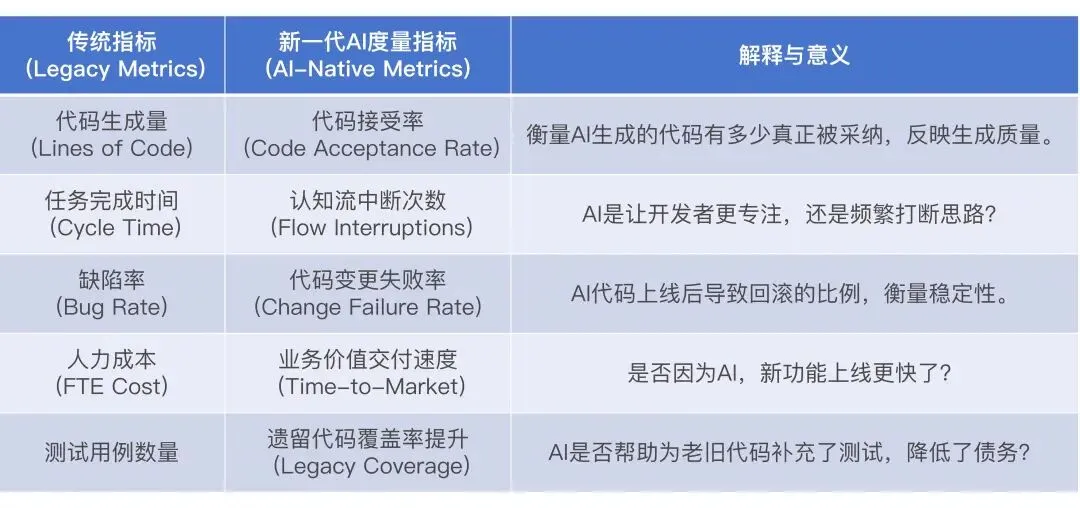
实证应用:
高盛的ROI模型不仅计算节省的时间,还计算了“新员工上手时间”(Time-to-productivity)的缩短。贝恩公司建议企业关注“释放出的时间流向何处”——如果是流向了更高价值的架构设计和业务创新,才是真正的ROI。
05
中美AI编程发展路径的对比分析
基于上述大量实证案例,我们可以清晰地看到中美两国在AI编程领域形成了截然不同的生态位。
► 5.1 驱动力与部署模式
美国/全球模式:
主导力量:以公有云巨头(Microsoft/GitHub, AWS, Google)和SaaS初创公司为主。
核心逻辑:市场驱动,强调个人开发者的体验(Developer Experience)和创新速度。
部署形态:SaaS为主。GitHub Copilot是绝对的主流,企业只需购买License即可使用,数据通常会上传至云端进行处理(尽管有隐私承诺)。
优势:模型迭代极快,算力资源丰富,生态整合度高(如VS Code插件市场)。
中国模式:
主导力量:平台型巨头(BAT, 华为)+ 行业龙头(工行、吉利)。
核心逻辑:政策与市场双驱动。除了降本增效,还肩负着信创替代、数据主权和供应链安全的政治任务。
部署形态:私有化部署(On-Premise)或专属云是主流。特别是金融、政务、国企领域,数据严禁出域。工行、华为的案例均体现了这一点。
优势:深度适配国产软硬件环境(如昇腾芯片、麒麟OS),更懂中文业务语境,且在垂直领域(如金融风控)的定制化程度更深。
► 5.2 核心挑战的差异
合规挑战:
美国企业更关注版权(Copyright)和偏差(Bias)。例如,GitHub Copilot曾因生成与受版权保护的代码一模一样的片段而面临诉讼。
中国企业更关注内容安全和数据出境。根据《生成式人工智能服务管理暂行办法》,企业必须确保AI生成的内容符合社会主义核心价值观,且关键数据不得流向境外服务器。
算力与模型策略:
美国拥有顶级的GPU资源,倾向于训练万亿参数的通用模型(如GPT-5级别),试图用“暴力美学”解决所有问题。
中国受限于高端GPU供应,更倾向于发展“小而美”的专用模型(如CodeFuse, CodeArts)和高效推理技术。DeepSeek(深度求索)的崛起证明了中国在算法优化(如MoE架构、低精度训练)上的独特优势,这在代码辅助这种对延迟极度敏感的场景中,反而可能形成成本和速度的双重竞争力。
06
未来展望与战略建议
► 6.1 技术预测:Agentic R&D的到来 (2026-2027)
随着推理模型(Inference Models,如OpenAI o1, DeepSeek R1)的成熟,AI编程将进入Agentic R&D(代理式研发)阶段。
从Copilot到Autopilot:AI将不再是被动等待指令的助手,而是能够主动扫描代码库,识别潜在的技术债务、安全漏洞或性能瓶颈,并自动提交PR(Pull Request)。
自我修复系统:在运维(Ops)侧,AI将与监控系统结合,实现故障的秒级定位和自动愈合(Self-healing),真正实现AIOps的闭环。
► 6.2 组织变革:Prompt Engineer的消亡与System Architect的崛起
简单的提示词工程(Prompt Engineering)将被模型内化的能力取代。企业将不再需要只会写代码的“码农”,而是需要:
系统架构师:能够理解复杂系统交互、设计高可用架构,并指导AI完成实现的专家。
AI治理专家:负责审核AI生成的代码是否合规、安全,并管理AI模型的生命周期。
► 6.3 战略建议
对于正在探索AI编程落地的企业技术管理者,本报告提出以下建议:
不要迷信通用ROI,建立分层度量体系:
a.对于初级开发者,关注其成长速度和代码质量提升。
b.对于资深开发者,关注其“认知流”是否被打断,以及是否将时间转移到了架构设计上。
实施“分级部署”策略:
a.核心域(Core Domain):涉及核心竞争力的代码,必须采用私有化部署或深度微调的模型(参考高盛、工行、华为模式),确保知识产权不外泄。
b.通用域(Utility Domain):非核心的工具脚本、前端页面,可大胆使用SaaS服务降本。
拥抱“测试驱动开发”(TDD)的回归:
AI生成代码越快,对自动化测试的需求就越迫切。没有完善测试覆盖的AI代码生成,无异于饮鸩止渴。企业应优先投资自动化测试基础设施。
针对中国企业的特别建议:
a.充分利用信通院等机构的标准认证,选择合规的国产工具。
b.关注信创生态的适配,利用AI加速遗留系统向国产架构的迁移(参考工行案例)。
报告声明:
本报告基于截至2026年1月的公开数据、企业财报、技术博客、学术论文及第三方咨询机构报告整理而成。引用的数据和案例旨在反映行业趋势,具体实施效果因企业技术环境、组织文化及落地策略而异。