


? 更新日期:2026-03-13? 来源:arXiv 2505.09343 - ISCA '25
引言:一场"建造超级大脑"的冒险
想象一下,你要建造一个前所未有的"超级图书馆":
? 这个图书馆需要记住人类所有的知识 ⚡ 但它的建造速度要非常快 ? 而且预算必须精打细算
这就是 DeepSeek-V3 团队面临的挑战——用不到 3000 张 GPU(NVIDIA H800),训练出世界顶级的大语言模型。
这篇论文不是普通的技术报告,而是一个关于如何用最少的钱办大事的精彩故事。
第一章:内存效率——让图书馆不再"爆仓"
? 传统方法的困境:越来越重的"书包"
想象每个学生(Token)上学时都要背着所有课本:

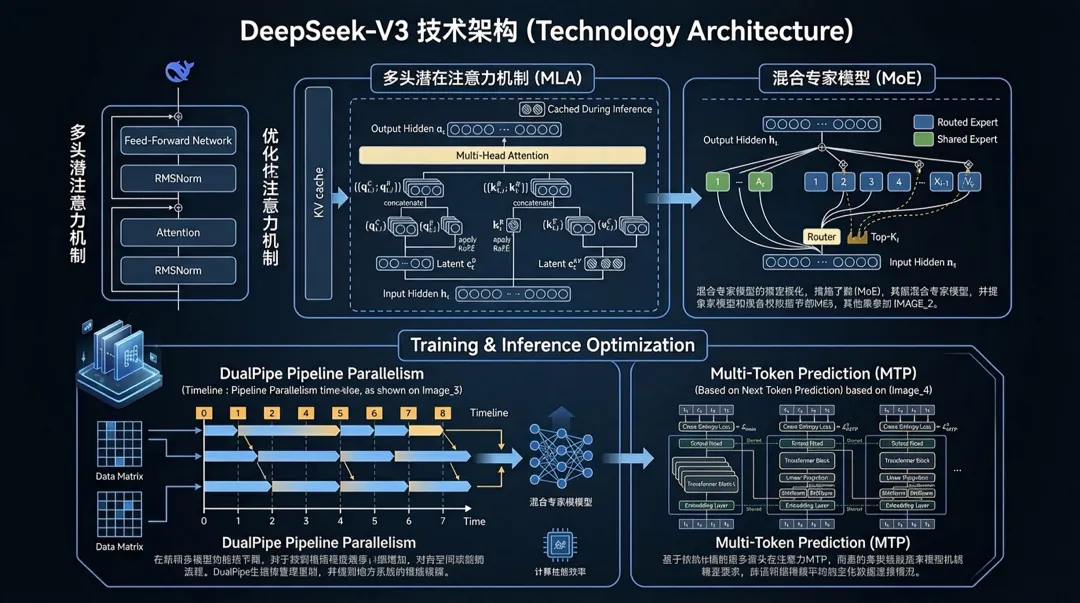
? 长颈鹿的智慧:MLA(多头潜在注意力)
寓言:长颈鹿的"压缩记忆法"长颈鹿的大脑很小,但它能记住很远的地方有没有水草。秘诀不是记住每一棵草的位置,而是记住"哪些区域可能有草"的特征。
DeepSeek-V3 采用了 Multi-head Latent Attention (MLA) 技术:

? 论文中的对比数据
| 模型 | KV缓存/Token | 内存节省 |
|---|---|---|
| 1 | ||
| ~50% | ||
| DeepSeek-V3 | 极小 | ~90%+ |
第二章:FP8 混合精度——"模糊数学"的胜利
? 核心问题:既要准又要快
寓言:米其林大厨的"快速出餐"秘诀五星级餐厅需要精确的每道菜,但客流量大时怎么办?大厨发明了"半成品预处理":复杂调味 → 精确做(保留BF16)简单翻炒 → 快速做(用FP8)最终成品依然美味,但上菜速度快一倍!
DeepSeek-V3 的 FP8 混合精度训练
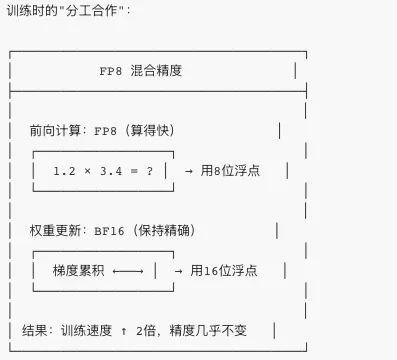
为什么 FP8 这么神奇?
- 内存减半
:8位 vs 16位,存储空间少一半 - 计算更快
:硬件对 FP8 有特殊优化 - 精度足够
:通过动态范围调整,FP8 可以表示很大或很小的数
第三章:MoE(混合专家)——"专业分工"的极致
? 工厂的启示
寓言:超级工厂的"按需分配"想象一个超级工厂:有 256 个"专家车间"但每次任务只激活 8 个车间其他车间"待命",不浪费电!这就是 MoE 的核心思想:不是所有专家都要上班,按需分配!
DeepSeek-V3 的 MoE 架构

MoE 带来的优势
| 指标 | 传统模型 | DeepSeek-V3 MoE |
|---|---|---|
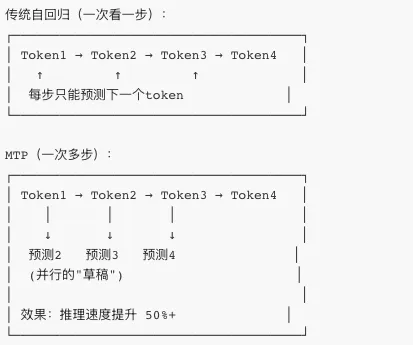
第四章:多token预测——"一次多看几步"
? 人类的"预见"能力
寓言:象棋大师的"读心术"新手棋手只能看一步棋,大师能看 10 步!DeepSeek-V3 的 Multi-Token Prediction (MTP)就像让 AI 也学会"提前预判"。
传统 vs MTP
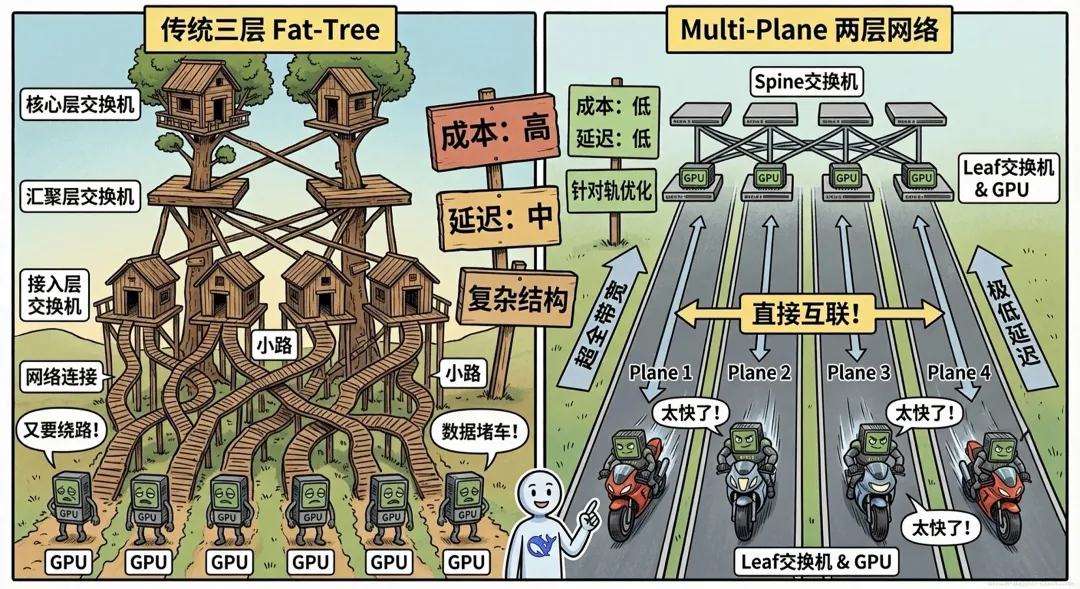
第五章:网络架构——"高速公路"的设计
? 城市交通的启示
寓言:高速公路 vs 乡间小路如果城市里只有乡间小路,再好的车也跑不起来。DeepSeek-V3 采用了创新的 Multi-Plane Network:传统三层网络 → 两层网络减少 30% 的网络设备成本延迟更低!
网络拓扑对比
第六章:硬件协同设计——软硬结合的哲学
? 真正的创新:不是"堆硬件"
这篇论文最核心的观点是:**硬件和模型需要"一起设计"**。
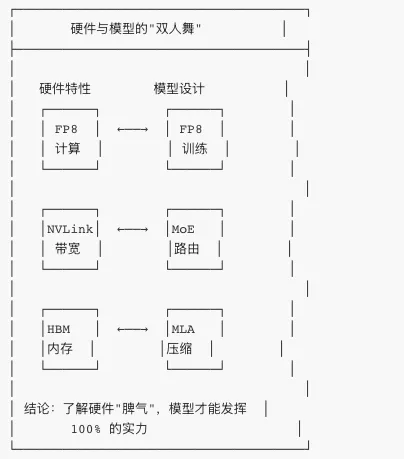
总结:DeepSeek-V3 教我们的事
| 创新 | 比喻 | 效果 |
|---|---|---|
给未来的启示
论文最后展望了硬件的发展方向:
- 更低精度的计算单元
:FP4、FP2 也许在未来 - Scale-up 和 Scale-out 融合
:单机多卡和多机互联不再分家 - 低延迟通信
:让分布式训练像单机一样快
参考资料
论文:arXiv:2505.09343 会议:ISCA 2025 作者:DeepSeek-AI 团队