在通用AI时代,掌握知识脉络变得越发重要,懂得怎么做比记住所有知识更有效率。比如数据预测模型就需要理解是什么,怎么用
从预测下个季度的商品利润,到判断一个用户是否会流失,数据预测模型无处不在。但面对市面上琳琅满目的模型名称(回归、随机森林、神经网络……),很多初学者都会感到一头雾水:到底有哪些模型?我该用哪一个?跑出来的结果怎么看?
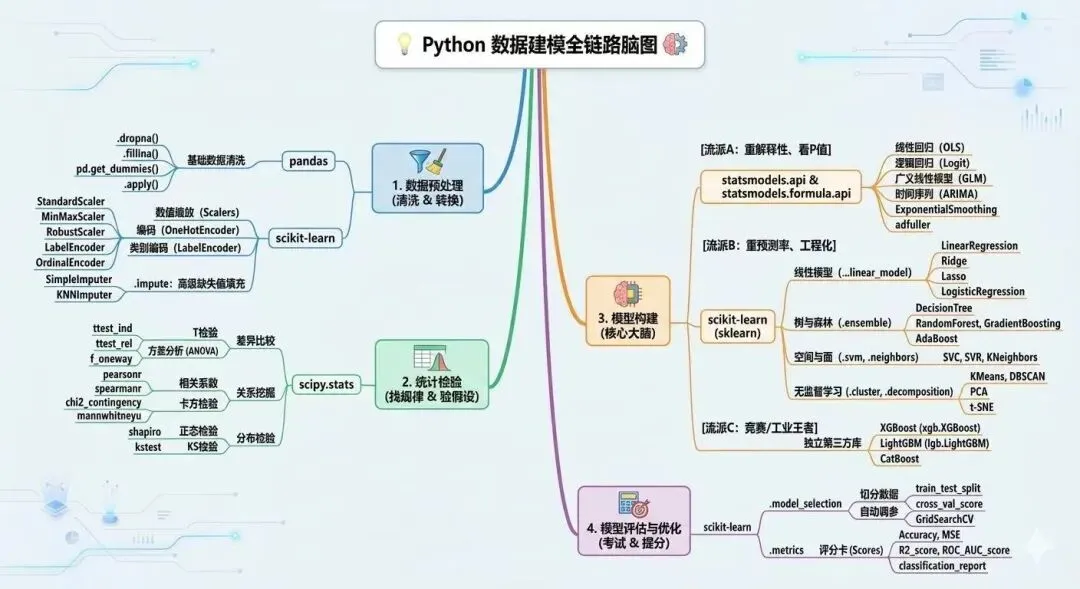
? Python 数据建模全链路脑图:
用Gemini 3.1 生图工具生成图片如下,对于中文小字还不是很完美,大概能看得出中文意思,字体边界比较模糊。
? 未来面对新任务,脑海可以过一遍“决策树”:
我要预测的是数字还是类别?
➡️类别(是/否,A/B/C):首选 逻辑回归 或 随机森林。
➡️数字(金额、温度):进入第2步
数据有没有强烈的时间顺序(昨天、今天、明天)?
➡️有(基于过去猜未来):选 Prophet 或 ARIMA。
➡️没有(寻找不同因素间的因果关联):选 线性回归 或 XGBoost
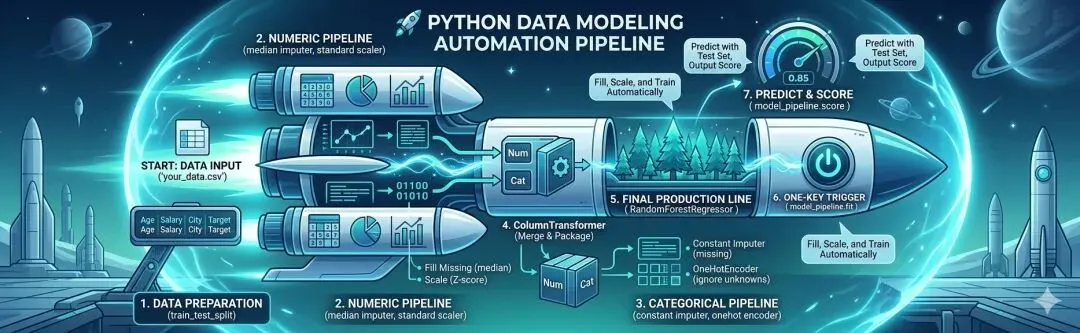
? Python 数据建模自动化流水线模板
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.ensemble import RandomForestRegressor
# 1. 准备数据
# 假设 X 有数值列 'Age', 'Salary' 和 类别列 'City'
data = pd.read_csv('your_data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
# 定义哪些列需要进行什么样的处理
numeric_features = ['Age', 'Salary']
categorical_features = ['City']
# 2. 定义【数值型数据】的处理流水线:缺失值填充 -> 标准化
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')), # 中位数填充
('scaler', StandardScaler()) # 标准化
])
# 3. 定义【类别型数据】的处理流水线:缺失值填充 -> 独热编码
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')), # 缺失值标记为missing
('onehot', OneHotEncoder(handle_unknown='ignore')) # 独热编码
])
# 4. 使用 ColumnTransformer 将上述处理逻辑打包(分而治之)
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 5. 构建【最终生产线】:预处理 ➡️ 模型训练
model_pipeline = Pipeline(steps=[
('preprocessor', preprocessor), # 第一步:数据预处理
('regressor', RandomForestRegressor()) # 第二步:模型拟合
])
# 6. 一键触发:训练与预测
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 这一行代码会自动:填充训练集缺失值、标准化、训练模型
model_pipeline.fit(X_train, y_train)
# 这一行代码会自动:用训练集的标准处理测试集、进行预测
score = model_pipeline.score(X_test, y_test)
print(f"模型得分: {score}")
用Gemini 3 生图模型,生成了这个图也蛮有意思的