


智能体(agent)从安全视角看,关键不在“它能说什么”,而在“它能做什么、能接触什么、能持续多久”。经典人工智能教材将 agent 抽象为“在环境中感知并采取行动的实体”,风险根源因此天然与“环境可控性/可写性”绑定。近年的 LLM 智能体进一步把“推理(reasoning)+行动(acting)”耦合在同一条轨迹里,并通过工具调用与外部系统交互,从而把攻击面从“内容/对话”扩展到“工具/权限/执行链”。
本报告提出一套面向安全治理的分级体系:以“两层分类逻辑”为骨架——第一层按“环境影响/控制力”(从只输出到可执行/可改系统)划分;第二层按“自主性/运行时长”(从短程交互到长程自治/多会话记忆)细分。分类论证主要基于 OWASP 对 LLM 应用风险的归纳(如 Prompt Injection、敏感信息泄露、插件设计不安全、过度代理/过度自治等)以及 英国国家网络安全中心将 Prompt Injection 视为“confused deputy/先天可混淆代理”问题的观点。
在此基础上,本报告设计了一个 0–100 的“安全风险评分模型”(分数越高风险越高),包含五个可量化子项:内容风险、数据风险、工具/权限风险、执行/代码风险、长期自主性风险,并给出权重、打分规则、分级阈值。评分不仅用于“贴标签”,更用于驱动差异化控制:例如对可执行代码的编程智能体,应优先落地沙箱、最小权限、命令/网络策略、供应链治理与审计;对长程自治型,应额外要求任务边界、可中断性、关键动作强制人工确认与持续监控。
最后,报告对 6 个典型智能体形态(AISearch、AI 生成漫剧、Manus、Cursor、Claude Code、OpenClaw)给出基于公开信息的示例评分、等级与安全建议;若产品细节未公开/未明确,均标注并说明对评分的影响。

智能体定义与范围
从安全分级的角度,需要把“智能体”从一般聊天/生成系统中区分出来。一个可操作的定义是:智能体 = 目标驱动(接收任务并规划步骤) + 可行动(通过工具/接口对环境产生影响) + 可累积状态(记忆/会话/文件)在一定程度上成立的系统。该定义与经典 agent 模型中“在环境中感知并行动”的抽象相一致,只是现代 LLM 智能体把“行动”具体化为工具调用(检索、文件、Shell、API、插件等)。
本报告覆盖的“智能体”范围,按能力与风险面,包含以下典型形态(示例产品来自公开文档/页面;若细节缺失以“未公开/未明确”标注):
搜索/检索型智能体(AISearch 类):以检索增强与总结为主,通常以只读方式访问网页/知识库并生成答案,主要风险集中在 Prompt Injection、RAG/检索投毒导致的错误引导与潜在数据外带。注:AISearch 在业界可能对应多种实现(浏览器检索、企业知识库 RAG、带轻量工具调用等);若具备写入/执行能力,应按更高类别重新分级(未公开/未明确)。
内容创作型智能体(AI 生成漫剧类):主要输出文本/图像/音视频等内容,通常不直接操作外部系统。其合规与内容安全风险在中国监管语境下尤为关键(违法信息、深度合成标识、未成年人保护等),但对“运行环境”的直接破坏性一般低于可执行类。注:若支持“一键发布/自动投放/自动分发”,内容风险与环境风险都会上升(未公开/未明确)。
自主任务执行型通用智能体(Manus 类):官方文档将其描述为“自主通用 AI agent”,类比“有自己电脑的虚拟同事”,并强调其在“完整沙箱虚拟计算机”内运行,具备互联网访问、持久化文件系统、可安装软件与创建工具等能力。
编程/代码智能体(Cursor、Claude Code 类):面向代码库与开发工具链,典型能力包括读代码库、改文件、运行命令、与 git/CI 集成、(通过连接器)访问外部数据源等。例如 Claude Code 文档明确其“读取代码库、编辑文件、运行命令并与开发工具集成”,并包含与 MCP 连接外部数据源、Hooks 运行 Shell、并行多 agent 等能力。Cursor 侧官方博客也将其 Agent 能力描述为可生成文件、运行终端命令、搜索代码库,并提示 CLI 能读/改/删文件、执行经批准的 Shell 命令且安全防护仍在演进。
多通道个人助理/网关型智能体平台(OpenClaw 类):OpenClaw 官方文档将其定位为“自托管网关”,把 WhatsApp/Telegram/Discord/iMessage 等消息通道连接到“AI coding agents”,并强调 sessions、memory、多 agent 路由、插件通道与移动端节点等“agent-native”能力。同时其安全文档明确:它遵循“个人助理信任模型”,不是面向多租户/对抗用户共享的安全边界;若多人可对同一 tool-enabled agent 发消息,本质上共享了同一组“委托工具权限”。
此外,工具连接标准(如 MCP)会显著改变智能体的“权限半径”。Anthropic 将 MCP 描述为“让 AI 工具与外部数据源/工具建立双向连接的开放标准”,而 MCP 规范与安全最佳实践也强调:该协议带来任意数据访问路径与潜在代码执行路径,需要系统性安全设计。
分类分级框架
本报告采用“两层分类逻辑”,原因是:在智能体系统里,风险增量的主要来源通常不是“生成质量”,而是(1)对环境的可写性/控制力(是否能把输出变为动作),(2)自主性/运行时长(是否能在更长时间里积累上下文、触发更多动作、被注入更多不可信输入)。
分类层级示意(环境控制力 × 自主性)

该结构与 OWASP 强调的“过度代理/过度自治(Excessive Agency)”“不安全插件设计”“敏感信息披露”等风险项是一致的:当系统同时具备工具能力与较高自主性时,Prompt Injection 等输入操控更容易被“放大”为真实破坏。
六类可落地分类
为了便于实际治理,本报告把上述二维空间收敛为 6 类(每类给出典型特征与代表产品;代表产品以公开信息为依据):
这里将 Cursor/Claude Code 归入“编程执行型”,是因为其核心风险来自代码/命令与开发链路;而 Manus 归入“自主工作台型”,因为其文档强调“可在沙箱虚拟电脑里独立完成端到端任务并持久化上下文”。 OpenClaw 单独成类,是因为它更像“把 agent 权限带到真实消息通道上的网关”,且官方明确其信任模型不是多租户边界。
关键风险维度与具体威胁场景
本节按“六类智能体”逐类给出:内容风险、数据风险、工具/权限风险、执行/代码风险、长期自主性风险,并配具体威胁场景。总体上,OWASP Top 10 for LLM/GenAI Apps 覆盖了 Prompt Injection、敏感信息披露、供应链风险、不安全插件设计、过度代理等通用风险;NCSC 进一步提醒 Prompt Injection 更像“confused deputy”,应从系统设计上降低残余风险与影响面。
内容创作型(E0×S)
内容风险:可能生成违法违规、虚假误导、深度伪造等内容;中国监管要求服务提供者防范违法内容、进行深度合成标识、完善投诉处置等。
数据风险:通常仅处理用户提示词与素材;主要关注个人信息/著作权素材上传与留存(若平台允许上传训练/二次利用需另行评估,未公开/未明确)。
工具/权限风险:一般无外部工具写入,但若支持一键发布到社媒/内容平台则会升级为 E2(未公开/未明确)。
执行/代码风险:通常无。
长期自主性风险:通常低;若存在定时发布/批量生成则会提高“规模化危害概率”(未公开/未明确)。
典型威胁场景:攻击者通过“题材/提示词诱导”绕过审核,批量生成并传播虚假信息或违规内容;或利用多模态生成造成深度伪造与诈骗链路的一环。
检索问答型(E1×S)
内容风险:核心是“错误/幻觉/误导性总结”,并可能造成过度依赖。OWASP 在风险集中专门列出与误导相关的风险项(不同版本表述略有差异)。
数据风险:用户查询可能包含敏感信息;此外,若检索链路访问企业知识库,数据面显著扩大(未公开/未明确)。
工具/权限风险:虽大多只读,但“间接 Prompt Injection(来自网页/文档的隐藏指令)”会操控总结过程,甚至诱导系统把敏感信息拼进输出或触发外带。
执行/代码风险:一般无,但当检索与工具调用/执行串联时,风险会跨越到 E2/E3。
长期自主性风险:短程为主;若是“持续监测/定时报送”则变为 L,注入窗口更大(未公开/未明确)。
典型威胁场景:对 RAG 系统“投毒/后门化检索器”,使特定触发条件下输出被攻击者操控;学术研究已讨论针对检索增强的提示注入与后门攻击思路。
受控工具编排型(E2×S)
内容风险:除误导外,更危险的是“输出被当作指令”进入后端(OWASP 将“输出处理不当/不安全插件设计”视为关键类风险)。
数据风险:常连接工单、邮件、CRM、知识库等,敏感信息披露风险显著上升;NCSC 指出 AI 系统需与既有网络安全/风险管理并行,把“敏感数据不泄露给未授权方”作为目标之一。
工具/权限风险:当 agent 拥有“可写工具”(发邮件、改工单、下单、删文件)时,Prompt Injection 会从“把回答写坏”升级为“用你的权限做坏事”。NCSC 将其类比为“高权限组件被诱导代用户/攻击者执行动作”的 confused deputy。
执行/代码风险:取决于是否可执行脚本/宏/工作流。
长期自主性风险:若工具编排引入计划任务或多 agent 协作,会出现“二阶注入/跨 agent 权限放大”的系统性风险(研究与业界案例均提示需要职责隔离与监督执行)。
典型威胁场景:攻击者在外部数据源(网页、工单描述、邮件正文)埋入间接注入指令,诱导 agent 调用高危工具(例如导出客户列表、删除工单记录、向外部地址发送文件)。
编程执行型(E3×S)
内容风险:除了生成恶意代码/错误修复带来的逻辑缺陷,更现实的是“把危险命令包装成看似合理的构建/测试步骤”。
数据风险:代码库本身往往包含商业机密、密钥、凭证与内部接口信息;一旦被间接注入引导外带,后果严重。
工具/权限风险:编程智能体通常可调用 Shell、git、CI/CD 或连接器。Claude Code 明确以“权限系统”为核心:敏感操作需显式批准,并提供分层权限规则(read-only、bash、file modification 等)。
执行/代码风险:这是该类的主风险。Cursor 官方博客提醒其 Agent CLI 可读/改/删文件并执行经批准的 Shell 命令,且安全防护仍在演进;Cursor 也强调通过“agent sandboxing”缓解风险与减少审批中断,但指出审批会导致“approval fatigue”。
长期自主性风险:通常低于“自主工作台型”,但当并行运行多个 agent 时,审批疲劳会放大误批准概率;Cursor 与 Anthropic 都把这一点作为推动沙箱化的重要动因。
典型威胁场景(工具链层面的注入与劫持):学术研究已展示针对“工具选择”的提示注入:攻击者可通过污染工具文档/描述,操控 agent 的检索与选择阶段,诱导其持续选用恶意工具并执行未授权动作。
典型威胁场景(现实漏洞链路):安全研究披露 Claude Code 可被“恶意仓库配置/Hook/MCP 配置”等机制触发 RCE 或 API Key 外带,并给出 CVE 与修复信息(细节随版本变化,应以官方安全公告为准)。
自主工作台型(E3×L)
内容风险:交付物通常是报告、PPT、网站等“可直接使用的成品”,风险从“误导内容”扩展到“误导决策/误导执行”。
数据风险:Manus 文档强调其具备持久化文件系统与长任务上下文,且可通过 API“管理文件、触发任务并接收结果”,数据生命周期更长、聚合度更高。
工具/权限风险:Manus 工具页明确其 agent 工具可访问“浏览器与文件系统”,并执行任务、创建文件;这意味着任何输入操控一旦绕过边界,就可能落到真实文件与网络行为上。
执行/代码风险:即便在沙箱中运行,可安装软件/自造工具也会引入供应链与执行面风险;NCSC 的安全 AI 开发生命周期指南将“prompt injection、数据投毒、供应链与沙箱隔离”等作为需要系统化控制的点。
长期自主性风险:长任务与持久化状态意味着“攻击者可多轮迭代地找漏洞”,且注入窗口更长;NCSC 认为应关注降低残余风险与影响,而不是期待一次性消除注入。
典型威胁场景:攻击者通过“资料包/网页/附件”埋入间接注入,诱导 agent 在长链路中逐步收集本地文件、拼接成报告并外发,或安装带后门的依赖以便后续继续控制。
多通道网关与生态型(E2/E3×L)
内容风险:多通道意味着更接近“自动化传播面”;同样的错误/被操控内容更易扩散。
数据风险:OpenClaw 定位为“个人助理网关”,会链接真实消息账号与会话/记忆;其安全文档明确“允许的发送者可以驱动同一权限集合”,若共享工作区(如 Slack)就存在真实的“委托工具权限”风险。
工具/权限风险:OpenClaw 具备 plugin channels、multi-agent routing、mobile nodes 等能力;其威胁模型把“网关、通道集成、技能市场、MCP 服务器”等都纳入范围,并强调信任边界识别。
执行/代码风险:现实世界已出现“技能/插件生态投毒”案例:媒体与安全研究报道 OpenClaw 的技能市场出现恶意技能/恶意指令,诱导用户执行命令或窃取凭证;同时 OWASP 将供应链风险、插件设计不安全列为重要类目。
长期自主性风险:always-on + sessions/memory + 多入口,会显著扩大“注入窗口”和“误触发概率”;其官方安全文档也指出不存在“完美安全”配置,治理目标是明确谁能对 bot 说话、bot 能在何处行动、能触达什么资源,并从最小权限起步。
典型威胁场景:攻击者在共享聊天群中发送“看似正常的任务请求/链接/附件”,利用间接注入引导 agent 调用 exec/浏览器/文件工具进行外带;或通过技能供应链植入恶意逻辑,在后续多次会话中持续窃取数据。
安全评分模型
本报告给出一个“面向治理落地”的 0–100 风险评分:分数越高表示需要越强的隔离/审计/审批治理。模型设计原则是:把 OWASP 归纳的核心风险面(注入、敏感信息、插件/供应链、过度代理等)与 NCSC 强调的“先天可混淆代理”问题,映射为可衡量的五个维度,并让“工具/执行/自治”获得更高权重。
评分流程示意
I[收集证据: 能力/权限/运行形态/部署边界]S1[五维子项打分]W[按权重加权求和(0-100)]L[映射等级 L1-L4]G[生成治理要求: 沙箱/权限/审计/红队/上线门槛]R[持续复评: 版本更新/权限变更/事故与告警驱动]
五维度与权重
内容风险(10%):输出类型与传播链路带来的合规/误导风险。中国监管对生成式 AI 内容合规、标识与处置提出要求,可作为该项治理基线。 数据风险(25%):智能体可接触的数据敏感度、持久化程度、跨系统聚合程度。 工具/权限风险(25%):是否具备写入型工具、是否跨系统、是否存在共享委托权限、授权模型是否可控(如分层权限、允许/询问/拒绝规则)。 执行/代码风险(25%):是否可执行命令/脚本、写文件、安装软件、触达 CI/CD 或生产资源;以及供应链/扩展生态带来的可执行面。 长期自主性风险(15%):是否长程运行、是否有记忆/会话树/计划任务/多 agent;以及审批疲劳导致的“形式上有人审、实际上易误审”。
评分细则表(示例量表)
评分采用“分档”而非精确公式,目标是让评审在缺少完美信息时仍可落地。每一维先选档位,再按权重折算。
风险等级阈值与治理强度
L1(0–20):低风险,允许默认上线;以内容合规与基础日志为主。 L2(21–45):中风险,要求工具边界清晰、最小权限、输入输出审查与基础速率限制。 L3(46–70):高风险,要求沙箱/隔离、命令与网络策略、密钥治理、审计留痕、上线前红队测试。 L4(71–100):极高风险,要求强隔离(独立账号/主机/环境)、关键动作强制人工确认、多层检测与持续监控,并限制共享可达性(避免“多人共享同一委托权限”)。
典型智能体评分示例与建议
说明:以下打分基于公开信息与“典型部署假设”。若某产品在你的实际落地中具备额外能力(例如自动发布、直连生产、共享账号、多租户对抗场景),应上调对应分项。对 AISearch、AI 生成漫剧这类“形态名”由于实现差异大,按“常见最小实现”计分,并标注未公开/未明确点。
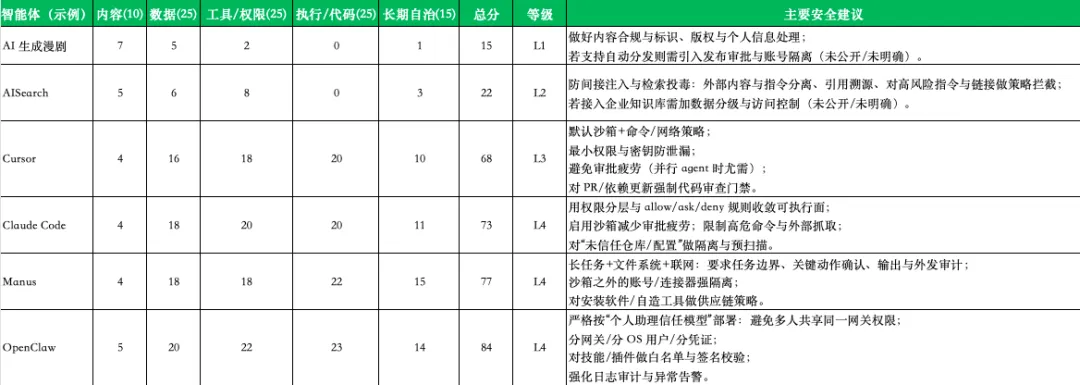
与表格相匹配的关键依据(节选):
Manus 被定位为可在“沙箱虚拟电脑”里计划与执行长任务,具备互联网访问与持久化文件系统,并通过 API 触发任务、管理文件。 Cursor 明确其 Agent 可生成文件、运行终端命令,CLI 能读/改/删文件并执行经批准的 Shell 命令;且其官方文章强调审批疲劳与沙箱化的权衡。 Claude Code 文档提供分层权限系统与安全策略(如默认阻断部分高危抓取命令、敏感操作需批准),并讨论通过沙箱减少审批疲劳。 OpenClaw 官方安全文档强调它不是多租户对抗边界,若多人可对同一 agent 发消息,本质是共享委托权限;同时现实中出现技能生态被用于恶意扩展/窃取数据的案例。
缓解措施与治理建议
治理思路建议采用“分级即分控”:分类与评分输出的不是一个标签,而是一套强制控制清单与审计要求。该思路与 NIST AI RMF 的“GOVERN–MAP–MEASURE–MANAGE”持续式风险管理框架一致:先治理与定责,再映射风险场景、度量与监控、最后在运行中持续管理。 同时也契合 NCSC 的“secure by design & lifecycle”建议:在设计、开发、部署、运维阶段分别落地控制,并把日志监控、供应链、安全默认值视为关键。
以下建议按“技术—流程—监管/合规—审计与监控”四条线组织,便于产品与安全团队协作拆解。
技术控制重点应围绕“信任边界 + 最小权限 + 可执行面收敛”。OWASP 对提示注入的缓解建议强调:控制 LLM 访问后端系统的权限(单独 token、最小权限)、在特权动作加入人工环节、将外部内容与用户提示分离、在 LLM 与插件/下游系统之间建立信任边界并持续监控输入输出。 对编程与可执行类 agent,这些原则需要具体化为:默认沙箱/虚拟化隔离、网络 egress 白名单、文件系统 allowlist、命令 allow/deny 策略、密钥不落盘与输出脱敏、对依赖安装与脚本执行做策略门禁。 对于通过连接器/协议扩展工具能力的场景,MCP 的安全最佳实践与规范也提示要把授权、信任与实现漏洞作为重点评估对象。
流程控制要把“审批”从 UI 按钮升级为“可证明的决策机制”。Cursor 与 Anthropic 都指出“对每个命令都弹审批”会导致审批疲劳;因此更稳妥的做法是:用沙箱边界减少审批频次,把审批资源集中在“跨出沙箱边界”的动作上,并对批准动作做结构化记录(谁在何时批准了什么、在什么上下文下)。 同时,必须在上线前完成威胁建模与红队测试。OpenClaw 的威胁模型文档明确把网关、通道集成、技能市场、MCP 服务器等纳入范围并持续维护;这类“living threat model”模式适合 agent 平台化产品。 NCSC 也强调在设计阶段就要做威胁建模,并在供应链选择、外部组件接入、第三方模型/权重导入时做隔离与扫描。
监管与合规建议按“内容—数据—安全能力”三条主线对齐:内容创作类至少满足生成式 AI 服务的内容合规、标识、投诉处置等要求;涉及个人信息与训练数据治理则需按监管要求取得同意、保证数据来源合法并提升数据质量。 对工具/执行类 agent,合规通常不足以覆盖“权限误用与执行链攻击”,因此还需要把网络安全要求(身份认证、访问控制、最小权限、日志留存)强制化到产品默认配置中;OpenClaw 的安全文档把“谁能对 bot 说话”“bot 被允许在哪里行动”“bot 能触达什么”视为配置的核心三问,可作为合规落地的配置模板。
审计、监控与告警需要覆盖“模型输入—工具调用—环境副作用—数据流向”全链路。NCSC 指出 AI 系统开发与运维中日志监控、更新管理与信息共享是运维阶段的关键;OWASP 也建议对输入输出做持续监控以发现弱点。 对长程自治/多通道型平台,还应把“异常会话轨迹”“异常工具序列”“异常数据外发(目的地、体量、频率)”“权限策略变更”纳入告警,并将高危动作设计为可中断、可回滚、可隔离。
局限性、未决问题与未来改进方向
首先,这套分级体系是“以能力与部署边界为核心的风险刻画”,并不能替代针对具体业务的威胁建模与红队验证。NIST AI RMF 明确其强调持续风险管理而非一次性清单式合规;落地时需要把评分作为“门禁与复评触发器”,而不是最终结论。
其次,Prompt Injection 及其衍生问题存在“结构性残余风险”。NCSC 直言应避免把 Prompt Injection 简化成可被单点修复的“类 SQL 注入”,更应将其视为“先天可混淆代理”的 confused deputy 类问题,工程上要做的是降低影响面、降低可用权限、提升可检测性——如果系统不能容忍残余风险,可能就不适合接入 LLM/agent。 OWASP 中文版文档也指出 LLM 不区分指令与外部数据,因此不存在模型内部“万无一失”的预防,只能通过权限、边界、人工环节与监控来减轻影响。
第三,评分对“未公开/未明确信息”敏感:例如是否默认启用沙箱、连接器授权模型、日志留存策略、是否允许自定义插件/技能、是否存在共享委托权限等,都会显著改变工具/执行/自治三项得分。这要求组织建立“证据优先”的评估机制:没有证据就按更坏假设评分,或要求供应商提供安全证明材料(权限模型、审计日志样例、隔离机制说明、漏洞响应 SLA 等)。
第四,未来攻击会更多集中在“工具链与生态面”,而非单纯对话越狱:学术研究已讨论针对工具选择阶段的注入/劫持(污染工具文档让 agent 选错工具),以及 RAG/检索器被投毒后触发特定行为;这些都会让“外部依赖与工具元数据”成为新的高价值目标。 相应地,未来改进方向包括:为工具与连接器建立“可验证身份与签名”(减少身份碎片化与静态密钥滥用),把策略引擎前置到每次工具调用前做实时评估,并为 agent 的行动轨迹提供更强的可解释与可复盘能力(可审计的计划—执行—证据链)。
参考文献(References)
[1] S. Russell and P. Norvig. Artificial Intelligence: A Modern Approach – Agents. Berkeley AI Materials, 2021.https://aima.cs.berkeley.edu/4th-ed/pdfs/newchap02.pdf
[2] J. Wei, X. Wang, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv, 2022.https://arxiv.org/abs/2210.03629
[3] OWASP Foundation. OWASP Top 10 for Large Language Model Applications v1.1. OWASP GenAI Project, 2024.https://genai.owasp.org/wp-content/uploads/2024/05/OWASP-Top-10-for-LLM-Applications-v1_1_Chinese.pdf
[4] UK National Cyber Security Centre. Guidelines for Secure AI System Development. NCSC, 2023.https://www.ncsc.gov.uk/files/Guidelines-for-secure-AI-system-development.pdf
[5] UK National Cyber Security Centre. Prompt Injection Is Not SQL Injection. NCSC Blog, 2024.https://www.ncsc.gov.uk/blog-post/prompt-injection-is-not-sql-injection
[6] Manus AI. Manus Documentation – Introduction. Manus AI Documentation.https://manus.im/docs/introduction/welcome
[7] Manus AI. Manus Tools Documentation. Manus AI Documentation.https://manus.im/tools
[8] 中华人民共和国国家互联网信息办公室. 生成式人工智能服务管理暂行办法. 2023.http://www.moj.gov.cn
[9] Anthropic. Introducing the Model Context Protocol. Anthropic Engineering Blog, 2024.
[10] Anthropic. Claude Code Sandboxing Architecture. Anthropic Engineering, 2024.https://www.anthropic.com/engineering/claude-code-sandboxing
[11] Anthropic. Claude Code Documentation Overview. Claude Code Docs.https://code.claude.com/docs/en/overview
[12] Anthropic. Claude Code Permission Model. Claude Code Docs.https://code.claude.com/docs/en/permissions
[13] Anthropic. Claude Code Security Model. Claude Code Docs.https://code.claude.com/docs/en/security
[14] Cursor Team. Cursor CLI Agent Architecture. Cursor Engineering Blog.https://cursor.com/blog/cli
[15] Cursor Team. Agent Sandboxing in Cursor. Cursor Engineering Blog.https://cursor.com/blog/agent-sandboxing
[16] OpenClaw Project. OpenClaw Documentation.https://docs.openclaw.ai/
[17] OpenClaw Project. OpenClaw Gateway Security Model.https://docs.openclaw.ai/gateway/security
[18] OpenClaw Project. Threat Model Atlas for OpenClaw.https://docs.openclaw.ai/security/THREAT-MODEL-ATLAS
[19] Y. Li et al. Backdoored Retrievers for Prompt Injection Attacks on Retrieval-Augmented Generation. NDSS Symposium, 2026.https://www.ndss-symposium.org/wp-content/uploads/2026-s675-paper.pdf
[20] OWASP Foundation. OWASP Top 10 for LLM Applications 2025 Update. OWASP, 2025.