



“通信行业深度报告:超节点:光、液冷、供电、芯片的全面升级”由开源证券发布。
本报告共计:27页。完整版PDF电子版报告下载方式见文末。
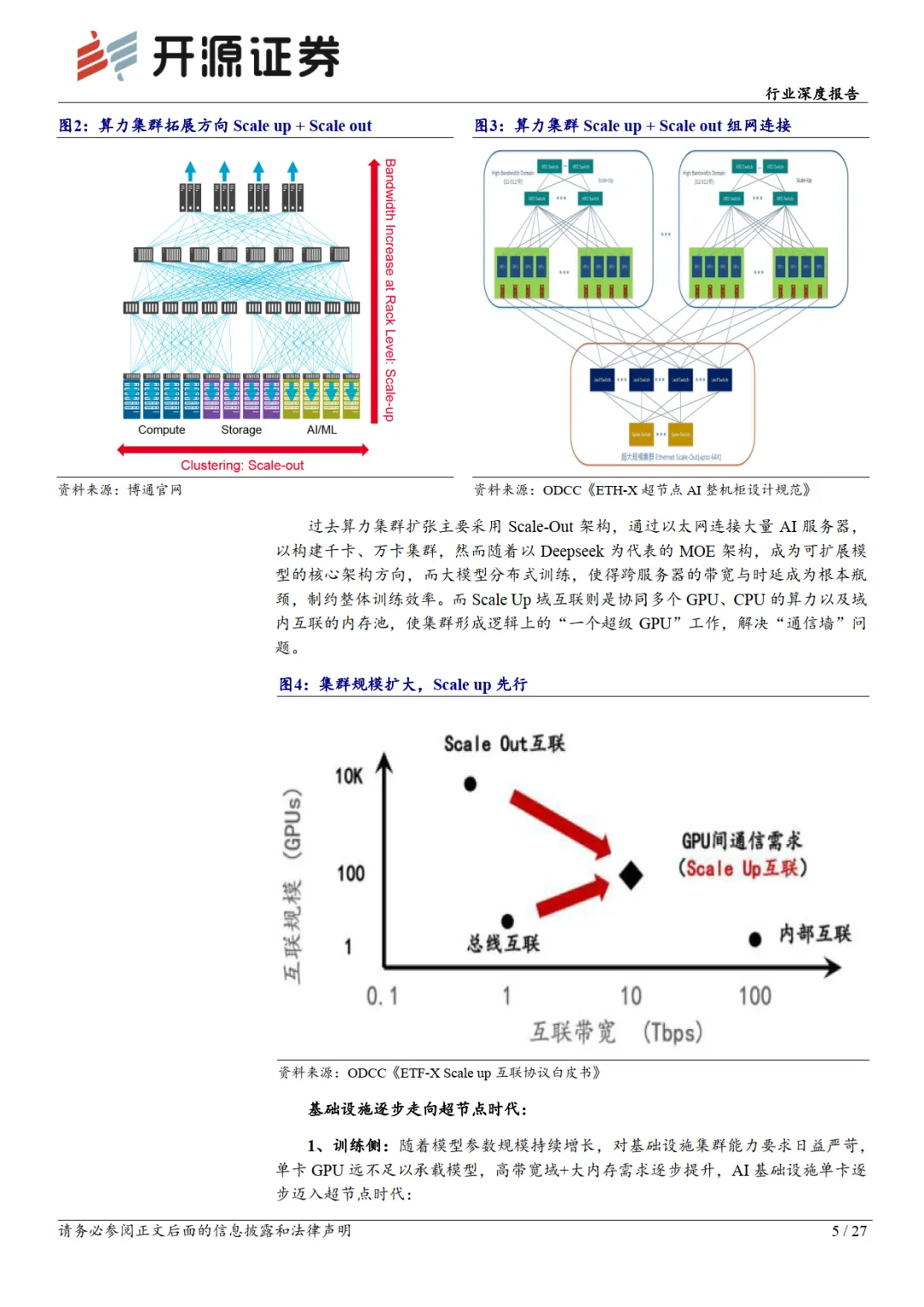
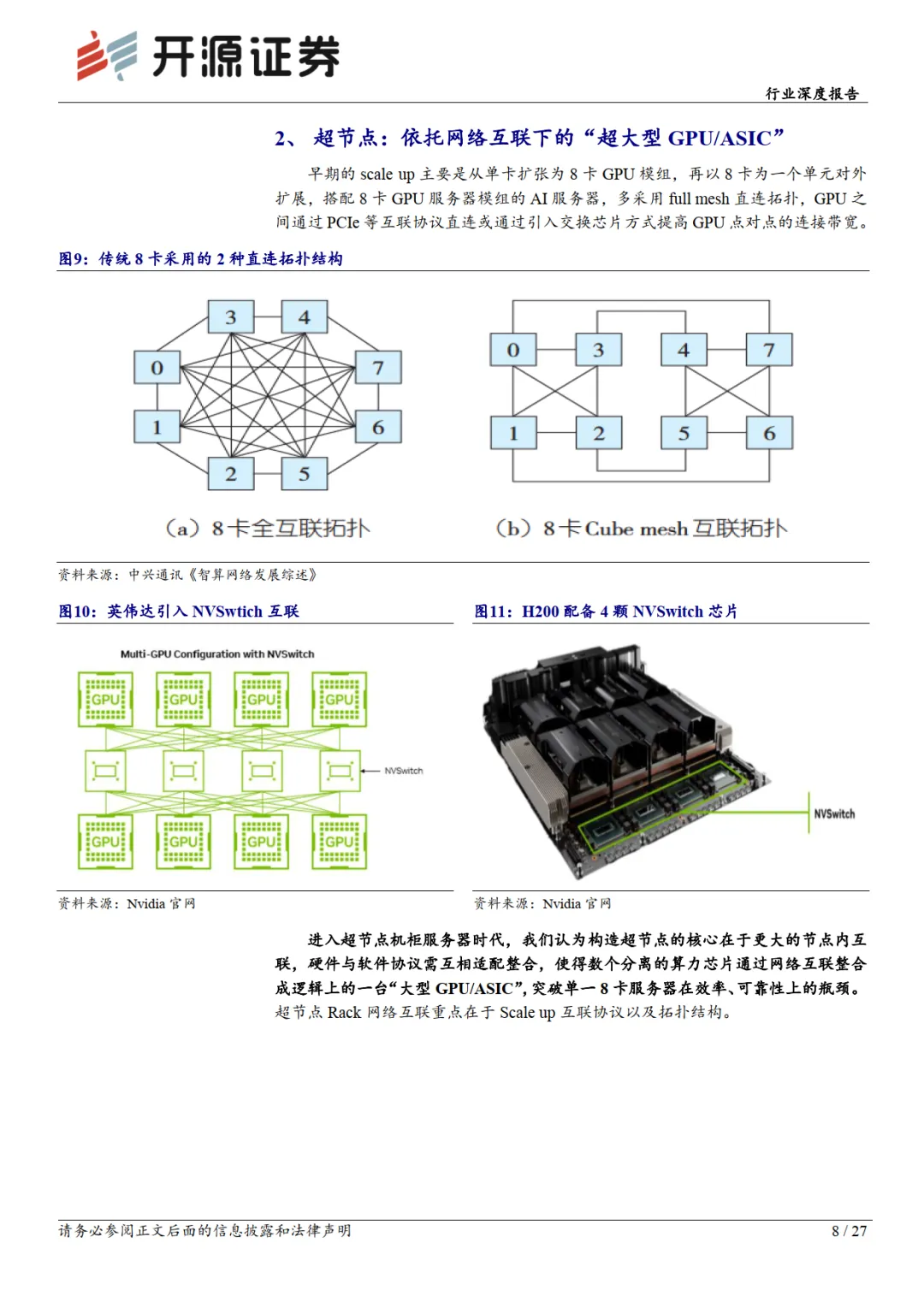
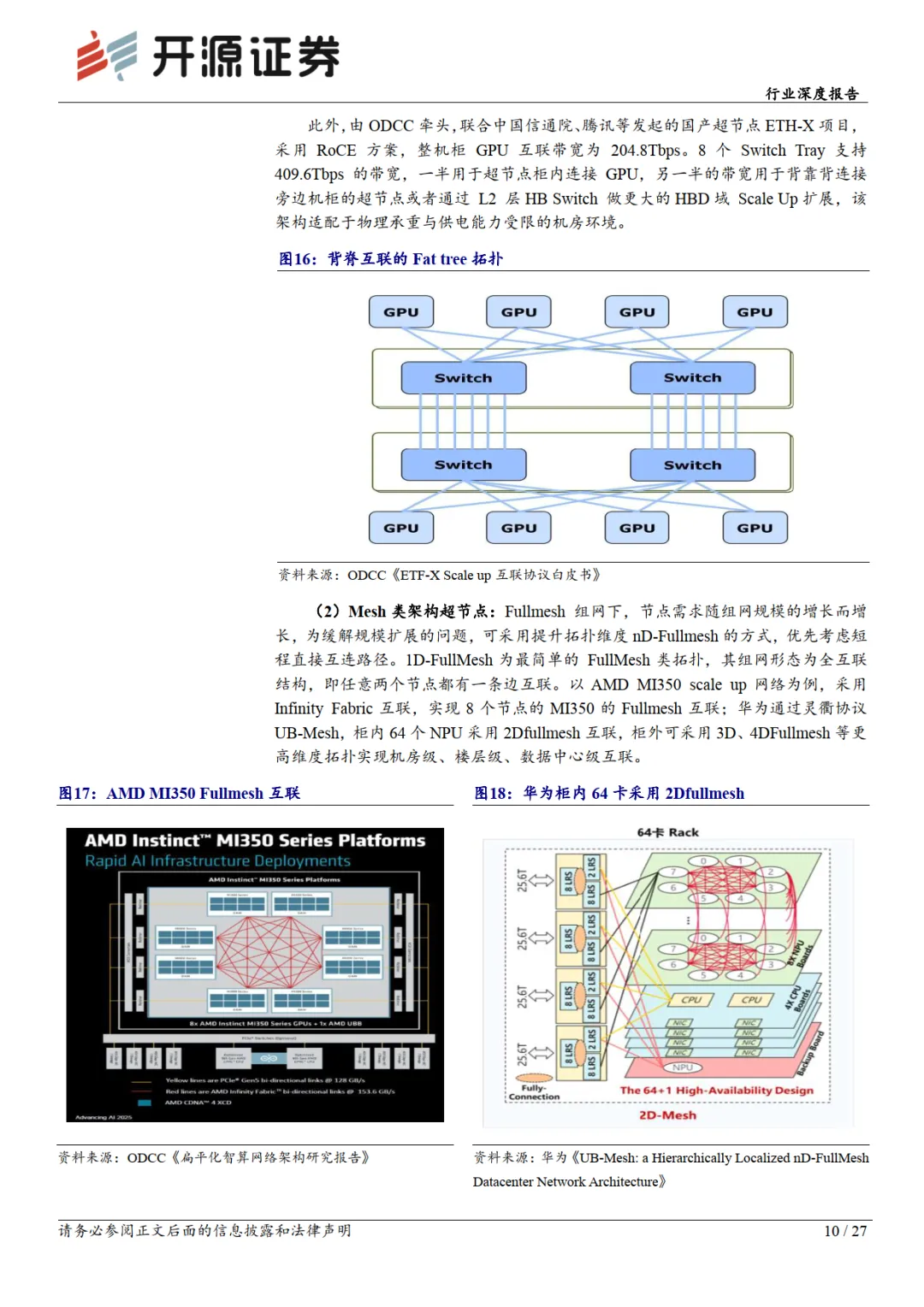
超节点:依托网络互联下的“超大型 GPU/ASIC”
超节点集群(SuperPod)最早由英伟达提出,随着AI 模型迭代对算力需求不断增长,集群从千卡扩散至万卡、百万卡等,而扩张方式主要为Scale Up(纵向扩展)和Scale Out(横向扩展)两个维度。我们认为构造超节点的核心在于更大的节点内互联,硬件与软件协议需互相适配整合,使得数个分离的算力芯片通过网络互联整合成逻辑上的一台“大型 GPU/ASIC”,突破单一 8 卡服务器在效率、可靠性上的瓶颈。超节点Rack 网络互联重点在于Scale up 互联协议及拓扑结构。

超节点新增scale up 互联需求,光、液冷、供电、芯片等环节迎升级
超节点服务器Rack 主要由计算节点Computer tray、交换节点Switch tray、TOR switch 交换机、供电单元Power shelf、供电母线Busbar、电缆桥架Cable tray、液冷散热配套等单元组成,随着超节点服务器渗透率不断增长,除了持续带动对算力卡、交换芯片、交换机的需求外,也有望持续拉动高功率电源、高压UPS/HVDC、服务器液冷散热、铜缆、PCB、光通信等板块的需求。
超节点助力国产集群性能提升,或弥补单卡算力差距,助力国产AI 发展
从单卡和集群性能对比上看,据SemiAnalysis 和CDCC 公众号,尽管国产芯片在制程上略有落后,单颗昇腾910C 芯片BF16 性能仅为GB200 模组的1/3,但通过超节点集群的方式,单个CloudMatrix 384 集群BF16 性能总体则是NVL72 的1.7 倍,其总内存容量为后者3.6 倍,总内存带宽为后者2.1 倍,有效弥补了国产芯片在算力层面上的短板。截至2025 年9 月,Atlas 900 A3 SuperPoD 已累计部署超300 套,服务超20 位客户。此外,华为公布Atlas 950 SuperCluster 和Atlas 960 SuperCluster,算力规模分别超过50 万卡和达到百万卡,通过持续扩大国产超节点规模的方式,有望实现国产AI 基础设施性能的弯道超车,助力国产AI 生态发展。
幻影视界整理分享报告原文节选如下:







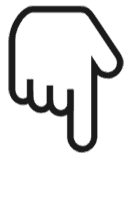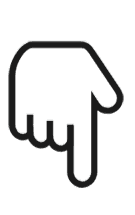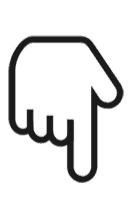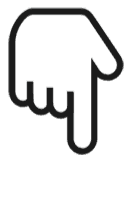 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。