








数据中心霸权:算力工厂的崛起
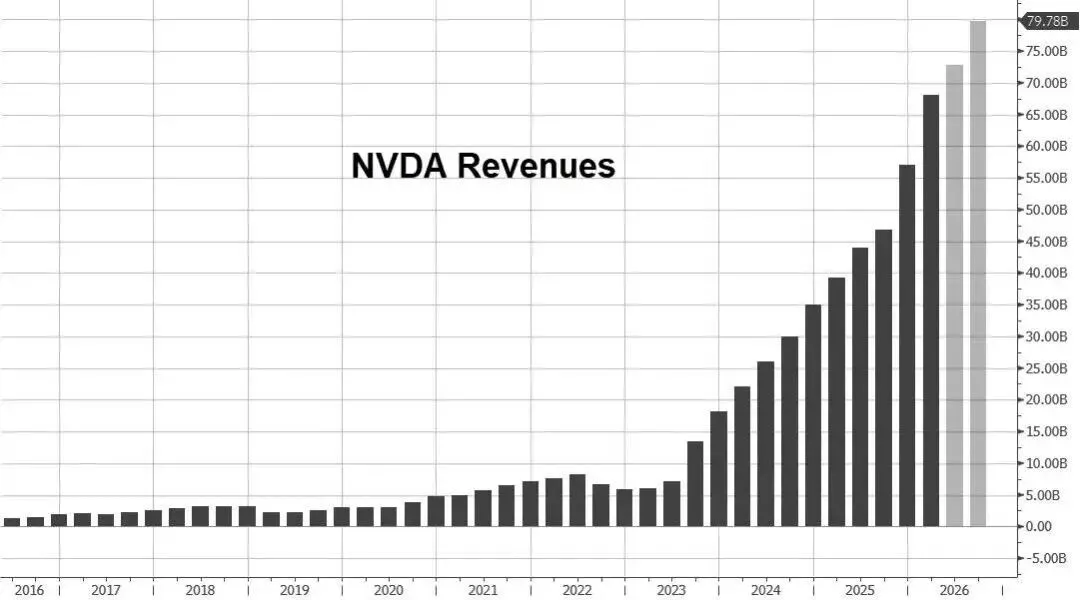
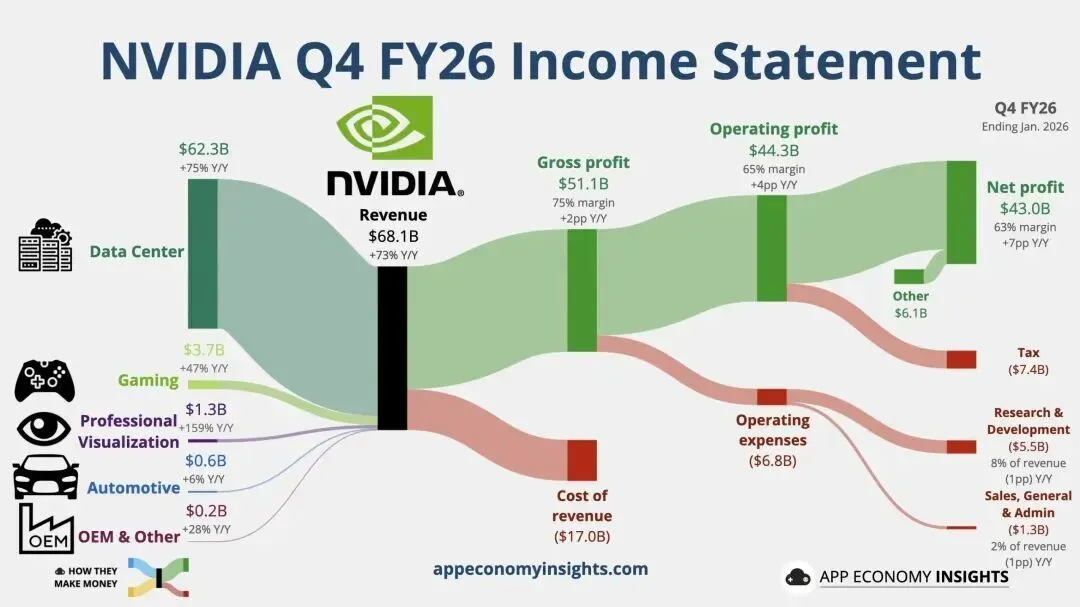
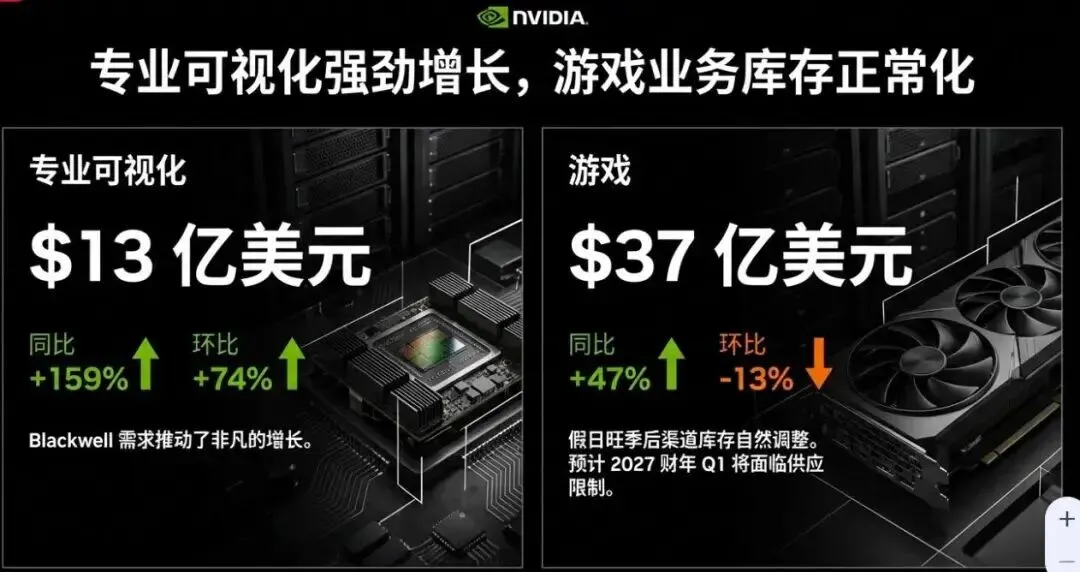
数据中心业务依旧是英伟达最核心的增长引擎,本季度营收达到创纪录的623.14亿美元,占总营收的比重高达91%。这一数字不仅是同比75%的增长,更是英伟达在数据中心领域统治地位的直接体现。

扫码免费进群
计算与网络的双轮驱动
英伟达的数据中心业务已不再仅仅依赖GPU 的销售。分析表明,计算收入(包括 GPU 及相关平台)和网络收入正在形成强大的协同效应。本季度计算收入为513亿美元,同比增长58%;而网络业务的表现更为亮眼,营收达到110亿美元,同比增长263%。
英伟达网络业务的爆发式增长证明了其从“芯片卖家”向“基础设施提供商”转型的成功。随着大规模 Blackwell 系统集群的部署,连接这些 GPU 的 NVLink 计算织网(Compute Fabric)以及 Spectrum-X 以太网平台成为了不可或缺的组件。英伟达甚至声称自己目前已是全球最大的网络业务公司,其网络年化收入已突破310亿美元,较收购Mellanox 时增长了10倍以上。
客户构成的多元化
英伟达CFO Colette Kress 指出,本季度虽然云服务商和超级计算客户(Hyperscalers)仍占据数据中心营收的50%以上,但增长动能已开始向其他领域扩散。
●主权AI (Sovereign AI):这是英伟达近年来重点发力的领域。2026财年主权 AI 的收入超过 300亿美元,较上年增长了两倍。加拿大、法国、荷兰、新加坡和英国等国政府正在积极建立本国的计算能力,以保障国家安全和文化主权。
●企业级AI:随着代理型AI(Agentic AI)在软件开发、医疗保健、法律服务等行业的渗透,企业对专用加速器的需求正处于爆发前夜 。
Blackwell 与 Vera Rubin:统治未来的技术底座
英伟达营收能够持续爆裂,核心在于其每年一次的快速架构迭代能力。Blackwell 系列目前已进入全面增产阶段,而下一代架构 Vera Rubin 的消息已经让市场再次屏息。
Blackwell Ultra (GB300) 的统治力
在第四季度,Blackwell 架构产品的需求被描述为“极其惊人(Off the charts)”。特别是GB300(Blackwell Ultra)系统,其采用了 HBM3e 内存,显著提升了推理和训练的性价比。相比上一代 Hopper 架构,Blackwell 在推理性能上提供了高达50倍的每瓦提升,并将每个token 的生成成本降低了35倍。这种成本优势对于需要大规模生成token 的代理型 AI 应用至关重要。
Vera Rubin:迈向下一代超级计算机
英伟达在CES 2026 上正式披露了 Rubin 平台。这不仅仅是一个 GPU,而是一套由六款核心芯片组成的 rack-scale 架构,旨在将数据中心视为一个单一的计算单元。
Rubin 平台的杀手锏在于对 HBM4 的支持以及全栈式的垂直集成。Vera CPU 采用英伟达自研的 Olympus 核心(基于 ARM 架构),通过 NVLink-C2C 互连与 Rubin GPU 实现无缝协作 。这种“CPU+GPU+网络”的三位一体设计,使得英伟达在系统级表现上大幅领先于依赖传统 x86 CPU 架构的竞争对手。
范式转移:从预训练到推理与代理型AI
黄仁勋在财报电话会议中反复强调,世界已经进入了“代理型 AI(Agentic AI)”的拐点。这一转型对算力需求产生了深远的影响。
“计算即收入” (Compute Equals Revenue)
英伟达提出了一个关键洞察:在AI 时代,计算不再是纯粹的成本,而是直接转化为收入的生产资料。随着Claude Code、OpenClaw 以及企业级代理系统的兴起,这些 AI 代理需要不断地生成 token 来进行推理、反思和执行任务。生成 token 的能力直接决定了企业变现 AI 的速度。因此,英伟达的 GPU 实际上是生成这些“盈利 token”的工厂。
推理主导的算力需求
随着模型pre-training 阶段逐渐转向推理(Inference)和逻辑思考(Reasoning),算力需求的逻辑也发生了改变。测试时缩放(Test-time scaling)定律表明,给模型更多的计算资源进行思考,它就能处理更复杂、更多步的任务。这意味着推理端的算力消耗将呈几何级数增长。英伟达通过Rubin 架构实现的10倍推理成本降低,正是为了满足这一庞大的市场需求 。
