



On Data Engineering for Scaling LLM Terminal
Capabilities
报告原文地址:https://arxiv.org/pdf/2602.21193
概述
NVIDIA的最新研究报告《On Data Engineering for Scaling LLM Terminal Capabilities》聚焦于解决大型语言模型在终端操作能力训练中的数据稀缺问题。报告通过引入Terminal-Task-Gen——一个轻量级的合成任务生成管道,系统化探索了数据工程策略如何显著提升模型在命令行环境中的表现。核心结论显示:基于高质量数据微调的Nemotron-Terminal模型家族(8B/14B/32B参数)在Terminal-Bench 2.0基准测试中实现突破性进展,其中32B模型性能从3.4%提升至27.4%,甚至超越参数量大15倍的Qwen3-Coder-480B模型。关键洞察包括:
数据质量优于参数规模:精准的数据工程设计能让中小模型在终端任务中媲美巨型模型。
合成与适配双轨策略:结合数据集适配(快速扩量)和技能型合成任务(精准优化)是突破数据瓶颈的关键。
失败轨迹的价值:保留模型执行中的错误轨迹进行训练,反而能增强其错误恢复和鲁棒性。
一、问题背景:终端能力训练的挑战
随着Claude Code、Codex CLI等工具的出现,LLM在终端交互中的实用性日益凸显。然而,当前顶尖终端代理的训练数据策略大多未公开,导致研究者只能通过试错探索,效率低下。报告指出两大瓶颈:
基础资源稀缺:缺乏多样化的任务提示、依赖文件及预配置环境。
轨迹收集复杂:真实人类交互难以捕获,而基于LLM代理的合成生成因需频繁初始化环境而成本高昂。
终端能力的提升现有两大路径:改进代理框架或优化底层模型。其中,数据集适配器(如Terminal-Bench提供的工具)可将现有数学、代码数据集转化为终端任务格式,但这类适配器继承源数据集的结构假设,可能限制其在序列环境交互中的效果。
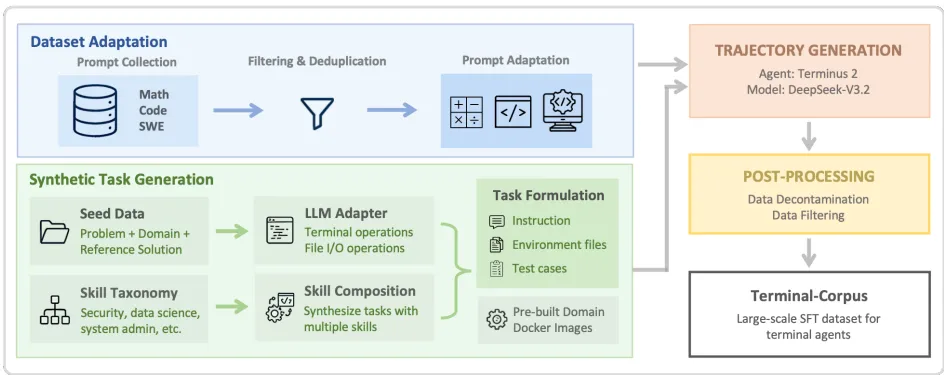
二、核心方法:Terminal-Task-Gen数据工程管道
1. 数据集适配器——快速扩量基础
报告选取数学(16.3万提示)、代码(3.5万提示)、软件工程(3.2万提示)三大领域的高质量数据集,通过Terminus 2代理框架将其转化为终端任务格式。例如,数学问题会追加指令“请将最终答案保存至/app/solution.txt”,确保任务可执行性。这种适配器策略高效利用现有问题库,为模型构建基础终端能力。
2. 合成任务生成——精准技能优化
种子生成:以现有问题为灵感,要求LLM生成包含具体软件工程要求(如安装依赖、文件读写)的终端任务,并配套测试用例。
技能生成:基于9大领域(如安全、数据科学)的原始技能分类,组合3-5种技能生成新颖任务。例如,安全领域任务可能要求“设计绕过认证的漏洞利用方案”。
关键创新是使用预构建的Docker镜像(如数据科学镜像预装pandas),替代每任务生成环境,大幅提升生成效率。
表1:Terminal-Bench 2.0模型性能对比(精度%)
模型类型 | 模型 | 参数规模 | 精度 |
|---|---|---|---|
开源模型 | Qwen3-32B | 32B | 3.37 |
Nemotron-T-32B | 32B | 27.4 | |
闭源模型 | GPT-5-Mini | - | 24.0 |
Gemini 2.5 Flash | - | 16.9 |
三、实验成果:数据驱动的性能飞跃
1. 整体性能提升
在Terminal-Bench 2.0的89个任务上,Nemotron-Terminal模型实现量级突破:
8B模型:从2.5%提升至13.0%(5.2倍增长)。
32B模型:以27.4%超越480B的Qwen3-Coder(23.9%),证明数据工程可弥补参数差距。
2. 分领域能力突破
如表4所示,模型在原有薄弱领域展现颠覆性进步:
数据查询:32B模型从0%提升至60%。
模型训练:从0%升至50%。
安全任务:从2.5%增长至27.5%。
这表明合成数据直接填补了基础模型的功能空白。
表4:分领域性能对比(Nemotron-Terminal-32B vs Qwen3-32B)
任务领域 | Qwen3-32B | Nemotron-T-32B |
|---|---|---|
数据查询 | 0% | 60% |
模型训练 | 0% | 50% |
安全任务 | 2.5% | 27.5% |
3. 数据策略的关键发现
过滤策略:保留失败轨迹(无过滤)的训练数据效果优于仅保留成功轨迹(性能差约7%),说明错误样本对鲁棒性有正面价值。
课程学习无效:混合训练所有数据源的单阶段策略优于先适配器后合成任务的两阶段课程。
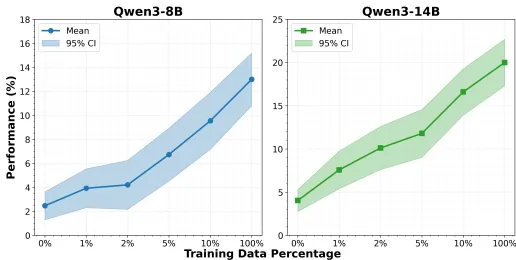
数据规模效应:如图4所示,模型性能随训练数据量增加而持续提升,14B模型增益幅度大于8B模型。
四、行业启示与未来方向
报告通过系统化实验证明:终端能力提升的核心在于数据质量而非模型规模。开源发布的Terminal-Corpus数据集和Nemotron-Terminal模型为社区提供了可复现的基准。未来,结合强化学习利用可验证的执行反馈,可进一步扩展至长周期任务的自校正与规划优化。
NVIDIA此项研究为LLM终端代理训练提供了数据工程的标准化蓝图,其“适配器扩广度+合成任务挖深度”的双轨策略,以及保留错误轨迹的训练理念,对高效开发实用型AI代理具有普适指导意义。