人工智能基础设施状况研究报告(2026)
出品 | 陈博观察 (ID: Drchenobservation)
编辑 | Will Chan

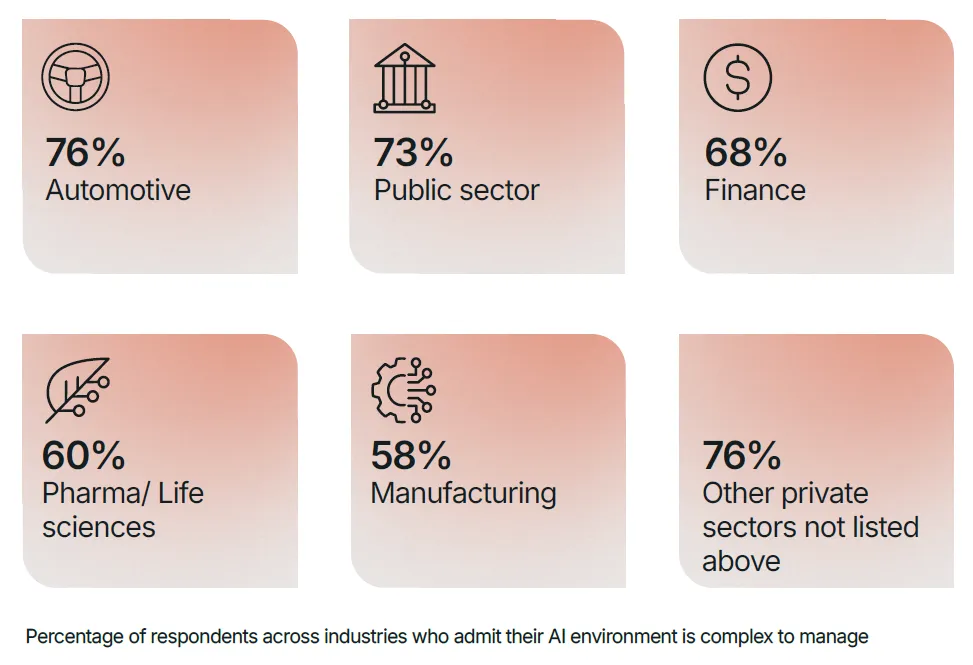
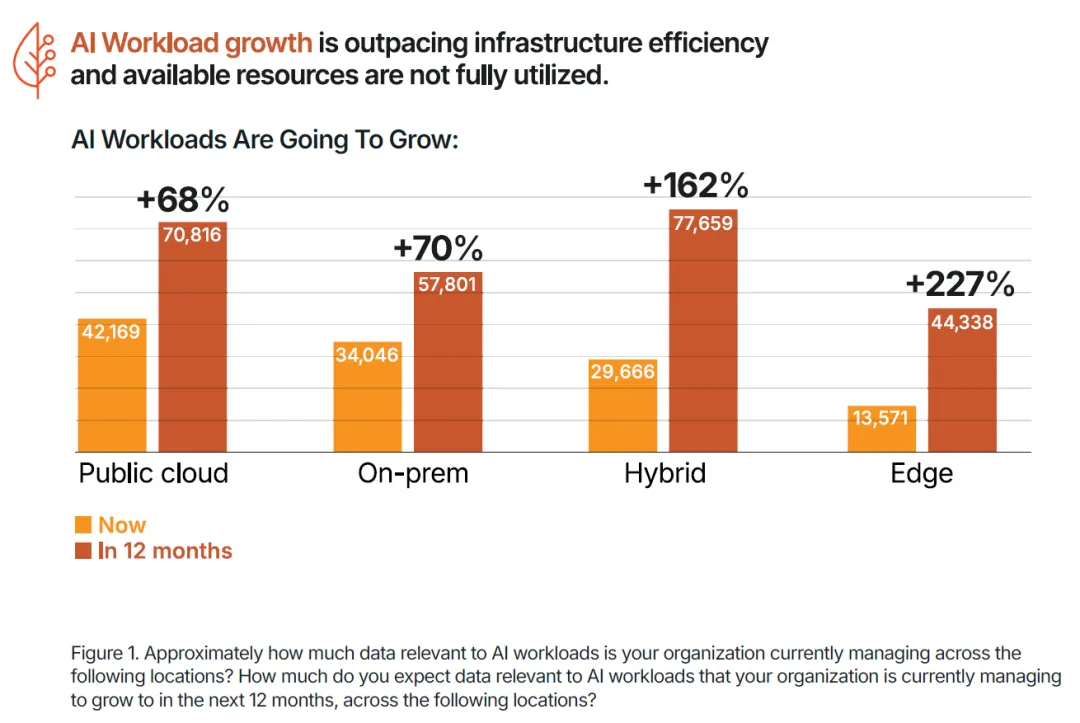
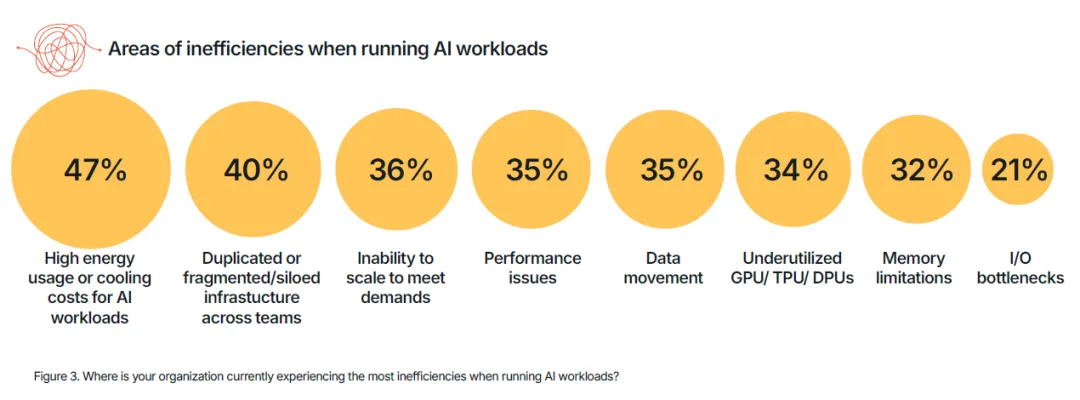
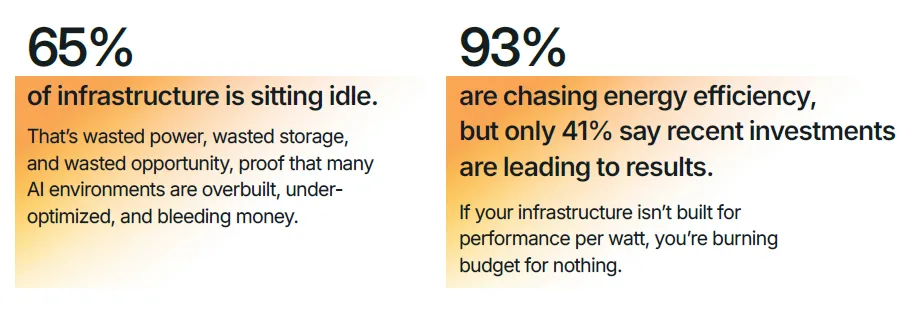
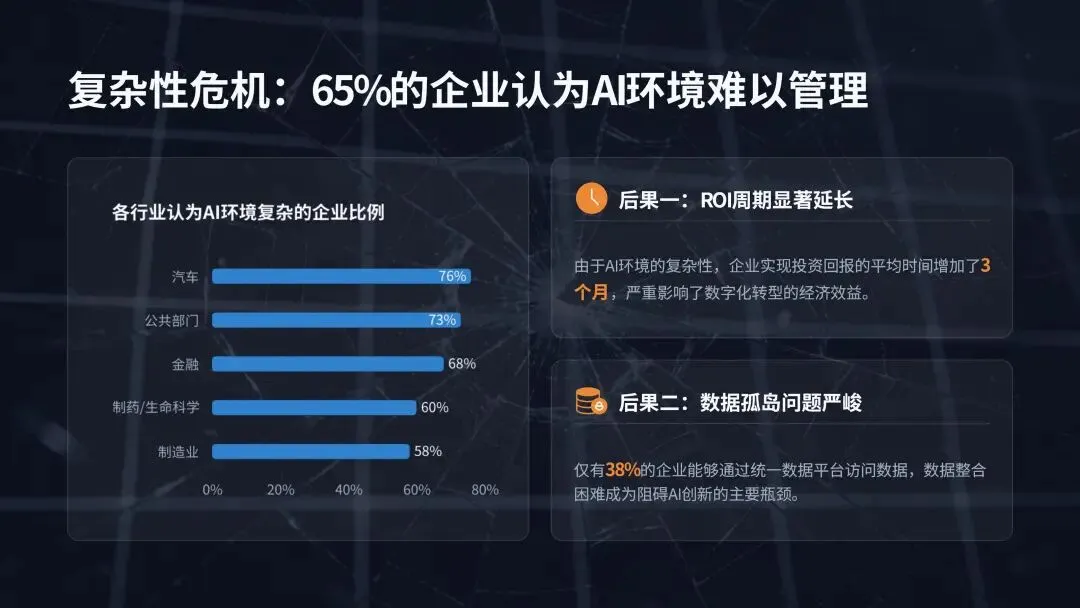
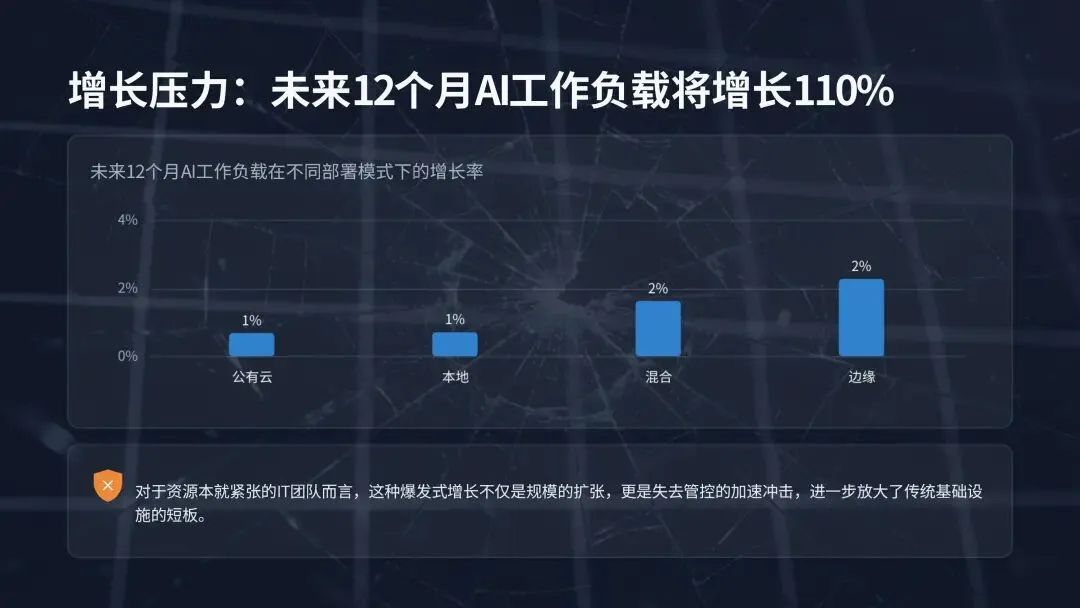
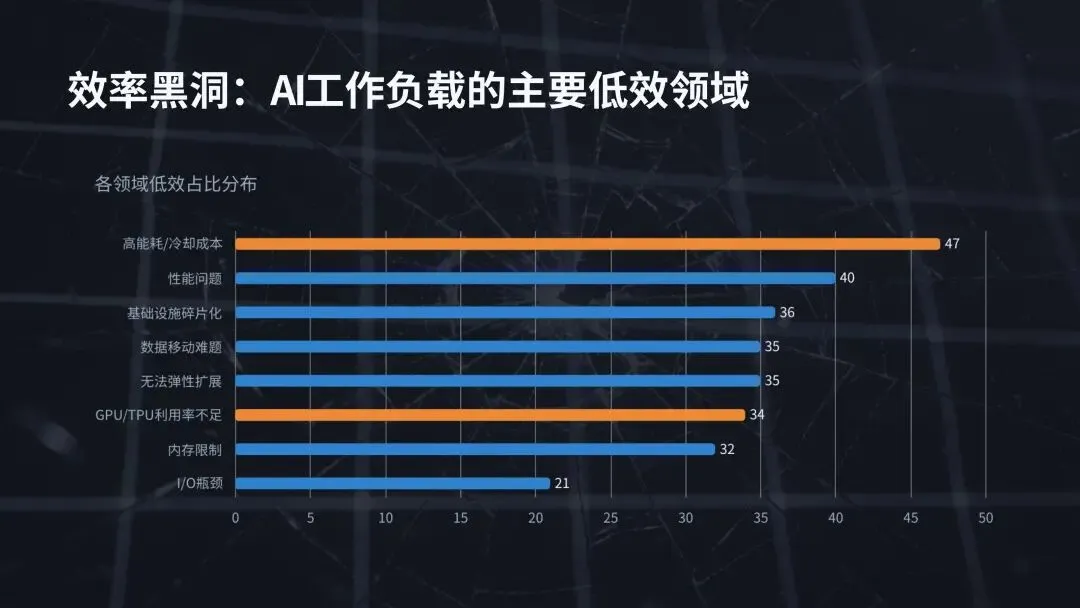
本报告基于 DDN 联合 Google Cloud、Cognizant 委托独立市场研究机构 Vanson Bourne 开展的专项调研形成,调研覆盖美国各行业 600 名 IT 与商业决策人,受访主体均为员工规模 1000 人以上的企业,核心覆盖金融、制造、汽车、公共部门、制药与生命科学等核心领域。调研核心结论明确:人工智能已全面进入生产落地时代,AI 项目成功的核心决定因素不再是算法、模型规模或预算投入,而是底层的 AI 基础设施能力。来源:DDN, State of AI Infrastructure Report 2026AI 技术的规模化落地已进入深水区,但支撑其运行的基础设施正成为绝大多数企业的核心瓶颈。调研数据显示,99% 的受访 IT 与商业领袖报告其 AI 工作负载存在效率低下问题,98% 承认团队内部存在显著的 AI 技能缺口,97% 一致认为云平台将在未来一年的 AI 项目规模化进程中发挥关键作用,93% 的企业正积极采取措施降低 AI 工作负载带来的能源环境影响。 上述行业普遍存在的痛点,直接引发了两大核心后果:65% 的受访者表示自身的 AI 环境过于复杂,团队已难以有效管理;54% 的企业在过去两年内出现过 AI 项目延期或直接取消的情况。随着 AI 需求呈指数级增长,数据复杂性攀升、能源成本高企、专业人才短缺三大问题,正持续暴露传统 IT 基础设施的底层缺陷。调研证实,将基础设施视为战略资产的企业,能比被动应对的企业更快实现 AI 投资回报;而缺乏战略性基础设施规划的企业,将陷入效率低下与业绩不达预期的恶性循环,最终将大部分时间耗费在系统故障修复而非技术创新上。AI 技术的发展速度已远超支撑其运行的传统系统迭代速度,基础设施的复杂性直接拖慢了 AI 投资回报的兑现节奏,成为企业 AI 规模化落地的核心胜负手。65% 的受访领导者明确承认,其企业的 AI 环境对团队而言已过于复杂,难以有效管理。这种复杂性带来的直接影响是,相关企业实现 AI 投资 ROI 的时间平均额外增加 3 个月,全行业 AI 基础设施投资的平均 ROI 兑现周期长达 14 个月。复杂性痛点在不同行业呈现出差异化的突出特征,其中汽车行业与其他未单独列示的私营领域,均有 76% 的受访者认为 AI 环境管理难度过高,公共部门为 73%,金融行业为 68%,制药与生命科学行业为 60%,制造业为 58%。具体来看,汽车与制造业面临海量传感器与仿真数据对传统系统的冲击,公共部门受困于治理规则与系统互操作性难题,金融行业需满足合规与风险管理的实时数据需求,即便是数据驱动属性极强的生命科学行业,也面临 AI 研究的速度与规模超出传统基础设施承载能力的困境。(二)AI 工作负载爆发式增长加剧基础设施承载压力未来 12 个月,全行业 AI 工作负载整体将增长 110%,不同部署模式的增长幅度呈现显著分化,其中边缘部署增长 227%,混合部署增长 162%,本地部署增长 70%,公有云部署增长 68%。这种爆发式的增长,对于本就资源紧张、能力承压的 IT 团队而言,不仅是规模扩张,更是失去管控的加速冲击,进一步放大了传统基础设施的短板。全行业 99% 的企业,即便是技术能力最领先的机构,都报告其 AI 工作负载中存在效率低下问题,这些问题持续消耗企业的预算、能源与生产效率。从诱因来看,76% 的决策者面临至少一项基础数据挑战,包括数据孤岛、数据集不可访问、无节制的云资源扩张等;65% 的受访者面临至少一项与传统系统相关的挑战,包括对过时基础设施的依赖、无法根据业务需求实现弹性扩展。除此之外,高能耗与冷却成本、跨团队基础设施重复建设与碎片化、CPU/GPU/TPU 资源利用率不足、内存限制、I/O 瓶颈等,均是行业普遍存在的低效痛点。从低效环节的分布来看,47% 的企业将高能耗与冷却成本列为首要低效问题,40% 存在工作负载性能问题,36% 存在跨团队基础设施重复建设或碎片化孤岛问题,35% 面临数据移动难题,35% 无法根据业务需求实现基础设施弹性扩展,34% 存在 GPU/TPU/DPU 利用率不足问题,32% 面临内存限制,21% 存在 I/O 瓶颈。这些效率问题带来的商业后果极为显著:54% 的企业在过去两年内出现过 AI 项目延期或取消的情况,而数据碎片化、基础设施过度复杂的企业,出现项目失败的概率是其他企业的 2 倍。专为 AI 规模化、简洁性与效率打造的专用基础设施,是当前企业实现 AI 成功的最大单一驱动因素。调研证实,对传统碎片化系统进行改造以适配现代 AI 工作负载的模式,几乎无法实现预期效果,甚至会直接导致项目失败。真正实现 AI 规模化突破的企业,均选择简化架构而非持续叠加工具,核心动作包括:现代化改造数据管道、整合分散的数据孤岛、部署专用 AI 基础设施,将计算、存储与数据移动能力统一在一个智能层中,从底层架构解决复杂性与低效问题。云计算已成为现代 AI 基础设施不可或缺的核心底座,97% 的 IT 与商业领袖一致认为,云平台将在未来 12 个月的 AI 项目规模化中发挥关键作用。云平台让 AI 规模化从技术可行变为商业可落地,其提供的可扩展性、弹性能力与前沿技术工具访问权限,能够帮助企业有效管理基础设施复杂性、消除容量瓶颈、简化模型实验流程,核心价值体现在四大维度:
上述行业普遍存在的痛点,直接引发了两大核心后果:65% 的受访者表示自身的 AI 环境过于复杂,团队已难以有效管理;54% 的企业在过去两年内出现过 AI 项目延期或直接取消的情况。随着 AI 需求呈指数级增长,数据复杂性攀升、能源成本高企、专业人才短缺三大问题,正持续暴露传统 IT 基础设施的底层缺陷。调研证实,将基础设施视为战略资产的企业,能比被动应对的企业更快实现 AI 投资回报;而缺乏战略性基础设施规划的企业,将陷入效率低下与业绩不达预期的恶性循环,最终将大部分时间耗费在系统故障修复而非技术创新上。AI 技术的发展速度已远超支撑其运行的传统系统迭代速度,基础设施的复杂性直接拖慢了 AI 投资回报的兑现节奏,成为企业 AI 规模化落地的核心胜负手。65% 的受访领导者明确承认,其企业的 AI 环境对团队而言已过于复杂,难以有效管理。这种复杂性带来的直接影响是,相关企业实现 AI 投资 ROI 的时间平均额外增加 3 个月,全行业 AI 基础设施投资的平均 ROI 兑现周期长达 14 个月。复杂性痛点在不同行业呈现出差异化的突出特征,其中汽车行业与其他未单独列示的私营领域,均有 76% 的受访者认为 AI 环境管理难度过高,公共部门为 73%,金融行业为 68%,制药与生命科学行业为 60%,制造业为 58%。具体来看,汽车与制造业面临海量传感器与仿真数据对传统系统的冲击,公共部门受困于治理规则与系统互操作性难题,金融行业需满足合规与风险管理的实时数据需求,即便是数据驱动属性极强的生命科学行业,也面临 AI 研究的速度与规模超出传统基础设施承载能力的困境。(二)AI 工作负载爆发式增长加剧基础设施承载压力未来 12 个月,全行业 AI 工作负载整体将增长 110%,不同部署模式的增长幅度呈现显著分化,其中边缘部署增长 227%,混合部署增长 162%,本地部署增长 70%,公有云部署增长 68%。这种爆发式的增长,对于本就资源紧张、能力承压的 IT 团队而言,不仅是规模扩张,更是失去管控的加速冲击,进一步放大了传统基础设施的短板。全行业 99% 的企业,即便是技术能力最领先的机构,都报告其 AI 工作负载中存在效率低下问题,这些问题持续消耗企业的预算、能源与生产效率。从诱因来看,76% 的决策者面临至少一项基础数据挑战,包括数据孤岛、数据集不可访问、无节制的云资源扩张等;65% 的受访者面临至少一项与传统系统相关的挑战,包括对过时基础设施的依赖、无法根据业务需求实现弹性扩展。除此之外,高能耗与冷却成本、跨团队基础设施重复建设与碎片化、CPU/GPU/TPU 资源利用率不足、内存限制、I/O 瓶颈等,均是行业普遍存在的低效痛点。从低效环节的分布来看,47% 的企业将高能耗与冷却成本列为首要低效问题,40% 存在工作负载性能问题,36% 存在跨团队基础设施重复建设或碎片化孤岛问题,35% 面临数据移动难题,35% 无法根据业务需求实现基础设施弹性扩展,34% 存在 GPU/TPU/DPU 利用率不足问题,32% 面临内存限制,21% 存在 I/O 瓶颈。这些效率问题带来的商业后果极为显著:54% 的企业在过去两年内出现过 AI 项目延期或取消的情况,而数据碎片化、基础设施过度复杂的企业,出现项目失败的概率是其他企业的 2 倍。专为 AI 规模化、简洁性与效率打造的专用基础设施,是当前企业实现 AI 成功的最大单一驱动因素。调研证实,对传统碎片化系统进行改造以适配现代 AI 工作负载的模式,几乎无法实现预期效果,甚至会直接导致项目失败。真正实现 AI 规模化突破的企业,均选择简化架构而非持续叠加工具,核心动作包括:现代化改造数据管道、整合分散的数据孤岛、部署专用 AI 基础设施,将计算、存储与数据移动能力统一在一个智能层中,从底层架构解决复杂性与低效问题。云计算已成为现代 AI 基础设施不可或缺的核心底座,97% 的 IT 与商业领袖一致认为,云平台将在未来 12 个月的 AI 项目规模化中发挥关键作用。云平台让 AI 规模化从技术可行变为商业可落地,其提供的可扩展性、弹性能力与前沿技术工具访问权限,能够帮助企业有效管理基础设施复杂性、消除容量瓶颈、简化模型实验流程,核心价值体现在四大维度:- 简化 GPU 资源获取,企业无需自建和管理本地基础设施与数据中心,即可便捷获取 AI 所需的 GPU 算力资源;
- 实现任意规模的即时访问,可按需规划和扩展加速器与存储资源,无需为峰值工作负载提前采购基础设施,可精准匹配业务需求调整资源规模,避免资源闲置浪费;
- 持续获取最新技术,无需承担大额资本支出与基础设施折旧风险,可随业务需求变化,持续应用最新的训练模型与 GPU 算力资源;
- 全链路适配 AI 生态系统,可利用云区域的全球覆盖能力,使用跨虚拟机规格、GPU、网络与存储的全托管 AI 优化基础设施,避免自建多个本地数据中心的高额成本与长周期问题。
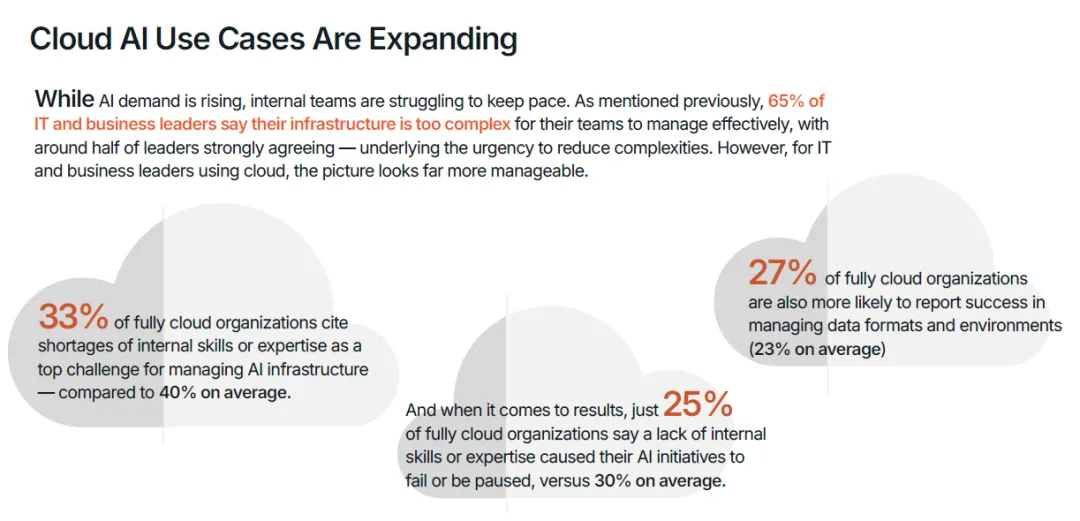
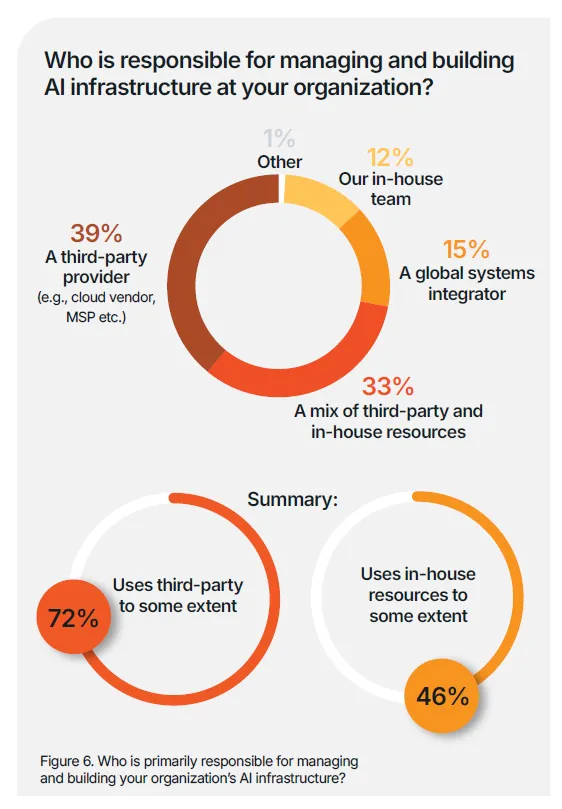
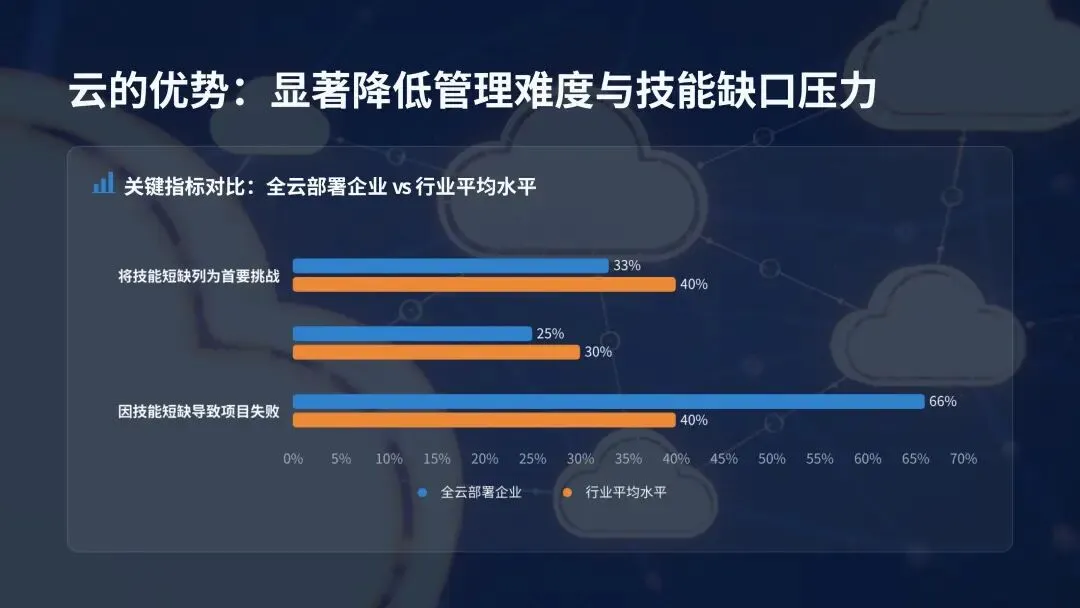
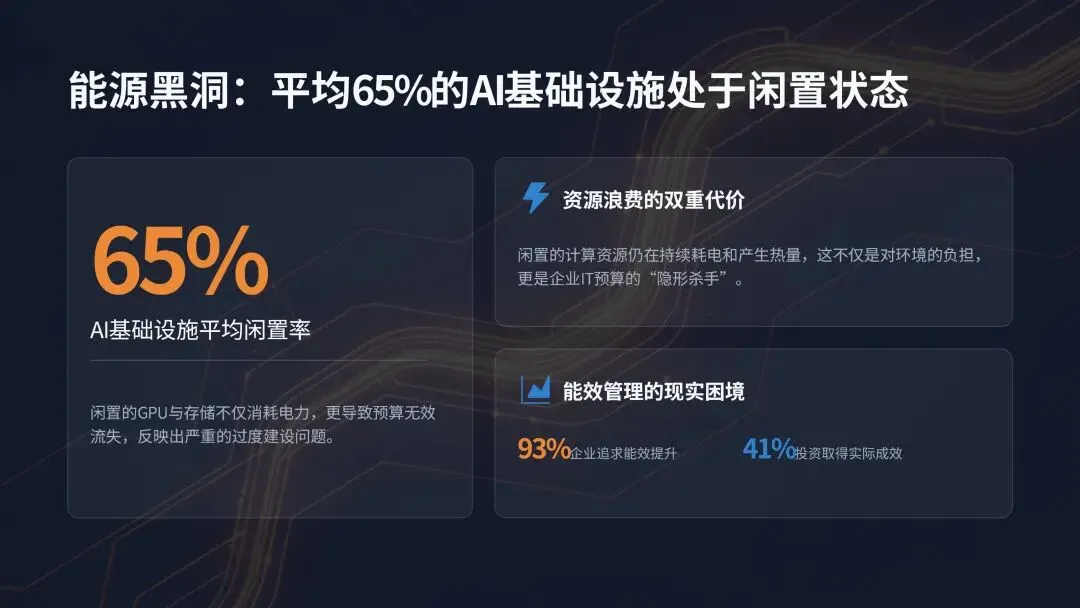
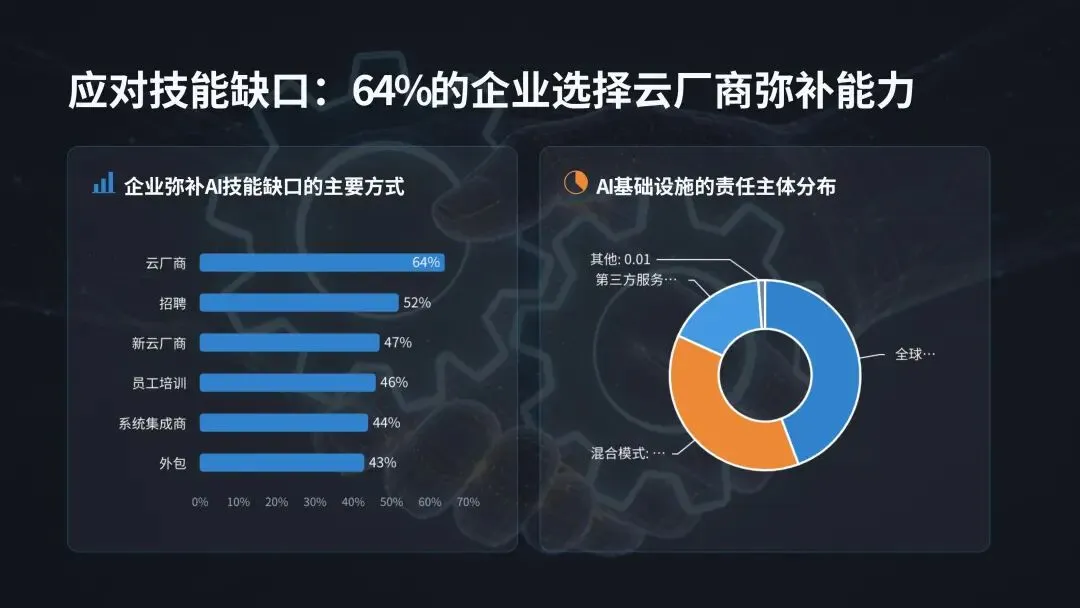
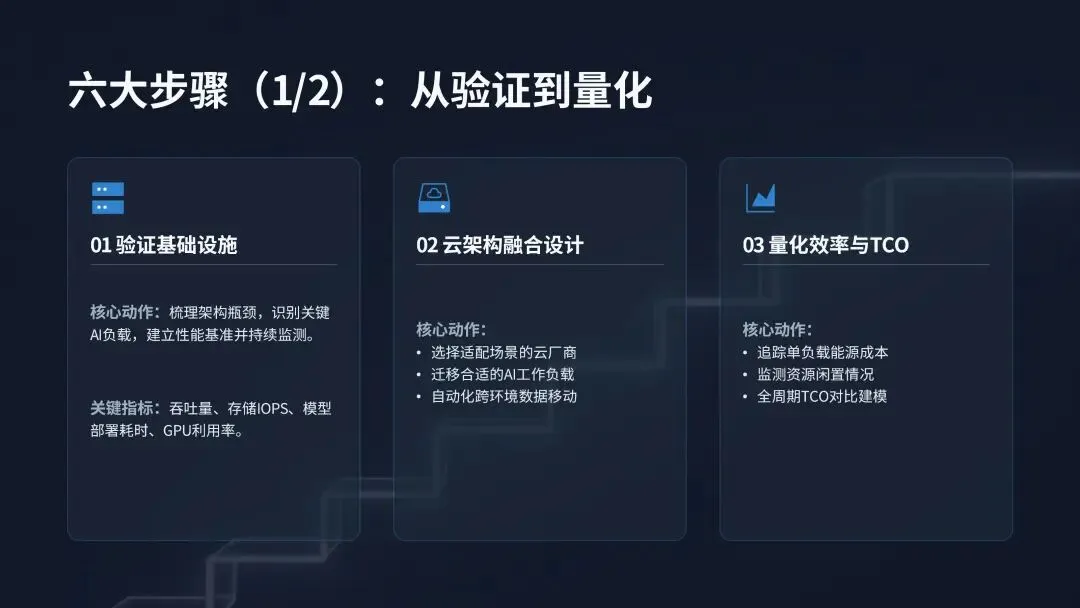
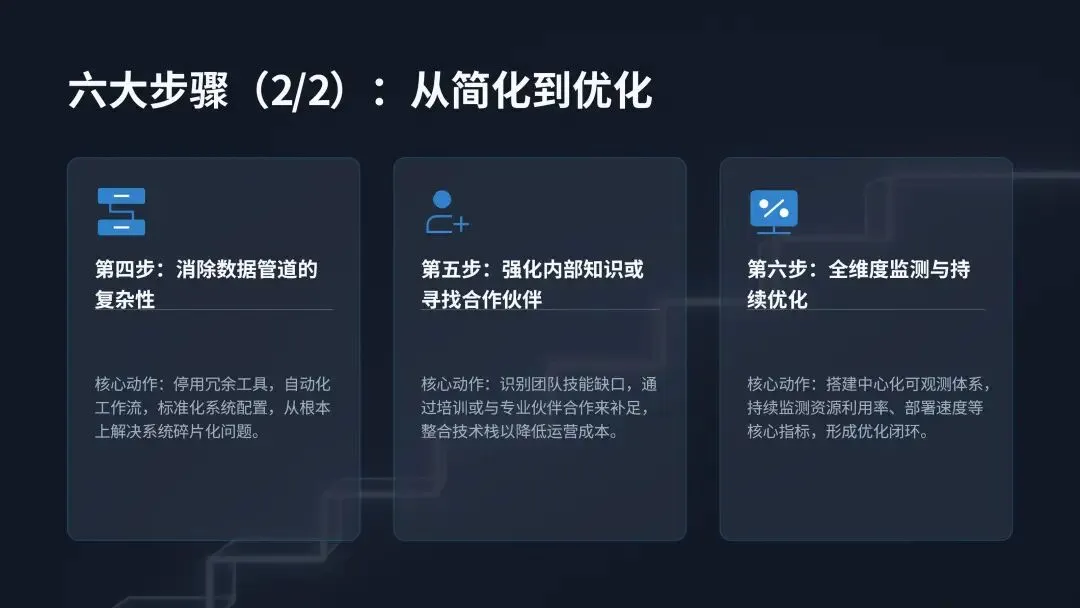
(二)云部署显著降低 AI 管理难度与技能缺口压力尽管全行业 65% 的企业表示 AI 基础设施过于复杂,团队难以有效管理,但全云部署的企业,其面临的挑战与项目失败风险显著低于行业平均水平。数据显示,33% 的全云企业将内部技能或专业人才短缺列为 AI 基础设施管理的首要挑战,低于行业平均的 40%;仅 25% 的全云企业表示,内部技能短缺导致其 AI 项目失败或暂停,低于行业平均的 30%;27% 的全云企业在数据格式与环境管理方面取得成功,高于行业平均的 23%;66% 的全云企业将其 AI 基础设施投资描述为战略性与前瞻性的,远高于行业平均的 40%。这一结果证实,云应用通过简化基础设施管理、降低运营复杂性,有效弥补了企业的 AI 技能缺口,让技术团队能够将工作重心从底层运维转向更具战略性的业务创新任务。当前企业对云基础设施的 AI 应用已形成规模化落地,70% 的受访者将云用于 AI 数据运营,69% 用于支持 AI 开发与模型实验,51% 用于搭建中心化 AI 数据枢纽与数据湖仓,44% 用于模型训练与微调,38% 用于模型推理与服务。随着 AI 技术的持续迭代,检索增强生成(RAG)、大规模模型推理等云 AI 应用场景,未来的普及度将进一步提升,成为云平台支撑 AI 落地的核心增量场景。企业必须将云作为 AI 基础设施战略的核心组成部分进行投资与应用,而非可选补充项。核心落地动作包括:选择针对企业自身 AI 应用场景,已构建配套工具、技能、功能与应用的云厂商;识别并将能最大程度发挥云厂商能力优势的 AI 工作负载迁移至云端;通过策略自动化跨边缘、核心与云端的数据移动,确保 AI 基础设施的资源利用率最优化。AI 的下一个规模化约束条件不再是计算能力,而是能源供给与利用效率。调研数据显示,近半数(47%)的受访者将能源使用与冷却成本列为 AI 工作负载的首要低效环节,93% 的企业正积极寻求降低 AI 工作负载的能源环境影响。随着 AI 训练与推理循环的持续不间断运行,数据中心的电力需求急剧攀升,行业诞生了全新的 AI 价值衡量标准:每瓦 AI 产出(也称为每瓦令牌数),即系统每单位能耗可产生的有效语言、商业洞察或决策能力,这一指标直接反映了基础设施将电力转化为智能的核心效率。国际能源署(IEA)发布的数据显示,全球数据中心的电力需求到 2030 年可能实现翻倍,这一增长趋势凸显了未来十年能源效率对于 AI 发展的核心地位。这不仅是企业的运营成本挑战,更是关乎行业发展的经济与环境挑战,基础设施的能源利用效率,将直接决定企业 AI 战略的规模化上限与可持续发展能力。调研数据显示,企业平均 65% 的 AI 基础设施处于闲置状态。闲置的 GPU 仍会持续消耗电力,闲置的存储设备仍需要配套冷却系统运行,这些闲置资源不仅造成了电力与存储能力的浪费,更直接证明多数企业的 AI 环境存在过度建设、优化不足的问题,持续造成企业预算的无效流失。尽管全行业 93% 的企业都在追求 AI 能源效率提升,但仅有 41% 的企业表示,近期在能源效率领域的相关投资取得了实际成效,凸显了行业 “重投入、轻效果” 的普遍困境。现代 AI 工作负载不再是规整、可预测的循环运行模式,而是持续、多阶段、数据密集型的不间断运行,需要计算、内存与存储之间的持续协同,因此能源效率无法在架构搭建后补充优化,必须从设计阶段就融入基础设施的底层架构中。能源感知型基础设施可通过三大核心方式实现降本增效:保持 GPU 的充分利用率,避免其因数据等待出现闲置空耗;以匹配 GPU 运算的速度并行移动数据,消除数据传输带来的算力空窗;跨工作负载与数据中心设施动态管理电力与冷却资源。通过上述方式,企业可实现更高的资源利用率、更低的总体拥有成本与可量化的可持续发展收益,在电力供给决定增长上限的时代,从每千瓦电力中挖掘更多的 AI 商业价值。AI 的发展不仅依赖基础设施,更依赖专业人才的支撑,但全行业普遍存在的 AI 技能缺口,已成为企业规模化落地的核心阻碍,而生态合作正是企业弥补能力短板、加速 AI 落地的核心路径。98% 的 IT 与商业领袖承认其团队存在 AI 相关技能缺口,83% 的企业表示团队当前已在 AI 工作负载管理中面临显著困难,68% 的企业承认未来 6 个月内尚未做好管理 AI 工作负载的准备,即便到一年之后,仍有 65% 的企业无法做好相关准备。出现这一困境的核心原因在于,传统 IT 职能是为数据库、应用程序、网络等可预测的标准化系统设计的,无法适配现代 AI 持续、数据密集型的工作流模式。外部行业研究同样印证了这一挑战的严峻性:65% 的企业因技能短缺直接放弃了 AI 项目,68% 的企业高管表示其企业存在中度至重度的 AI 技能赤字。面对普遍存在的技能缺口,企业采取了多元化的应对措施,其中 64% 的企业选择通过云厂商(如 Google Cloud、OCI、AWS)弥补能力缺口,52% 计划招聘更多具备 AI 专业技能的员工,47% 选择使用新型云厂商(如 GPU 或 AI 即服务提供商),46% 计划对现有员工进行保留与技能提升,44% 选择与全球系统集成商合作,43% 选择将相关业务外包给第三方服务提供商,仅有 1% 的企业表示未面临 AI 技能缺口。大多数企业已认识到,外部专业能力不是应对技能缺口的权宜之计,而是 AI 时代的战略赋能工具。调研数据显示,72% 的企业依赖第三方专业能力搭建和管理 AI 基础设施,仅有 12% 的企业完全依靠内部团队完成相关工作。从责任主体分布来看,39% 的企业由全球系统集成商负责 AI 基础设施的搭建与管理,33% 由第三方服务商与内部资源混合负责,15% 由第三方服务商(如云厂商、MSP 等)独立负责,1% 由其他主体负责。内部团队与外部合作伙伴的协同,形成了显著的互补价值:合作伙伴拥有成熟的参考架构与规模化落地经验,内部团队能提供关键的业务领域洞察与合规管控,二者结合可打造可复用的技术框架,简化 AI 运营流程,将单纯的外包转化为深度协作,帮助企业在 AI 规模化落地的同时,同步构建自身的核心能力。54% 的受访领导者正在搭建融合云端与本地部署的 AI 基础设施生态(即均衡型企业),核心目标是实现敏捷性与管控力的平衡,同时充分利用本地资本支出的沉淀价值与云端的新技术获取能力,最大化云平台的灵活性与按需实例的资源优势。调研数据证实,这种均衡型架构能为企业带来显著的价值提升:41% 的受访者强烈认同基础设施效率低下限制了 AI 的经济价值,而这一比例在均衡型企业中降至 32%;均衡型企业出现 GPU 利用率不足问题的概率,比行业平均水平低 17%;仅 35% 的均衡型企业表示,未来 12 个月提升 GPU 效率将是重大障碍,低于行业平均的 41%。没有企业能仅凭自身力量实现 AI 的规模化落地。企业需要打造与外部合作伙伴互补而非竞争的内部团队,第三方专业能力不是内部能力的替代品,而是能力倍增器。其中,内部团队提供业务背景、治理体系与长期发展愿景,合作伙伴则带来专业工具、规模化落地能力与前沿技术积累,加速项目落地进程。行业内最成功的企业,均践行三大核心行动:将内部团队的业务理解与合作伙伴的技术专业能力深度结合;采用均衡型基础设施架构降低系统集成摩擦;将合作关系视为运营模式的核心组成部分,而非单纯的外部依赖。生态合作正成为 AI 时代的企业核心竞争力,掌握这种内外协同平衡的企业,将实现更快的 AI 规模化、更有效的复杂性管理,以及长期可持续的 AI 性能。六、落地实践指南:构建 AI 技术栈的六大核心步骤基于全行业的调研洞察与成功实践,报告为 IT 与 AI 领导者提供了六大可落地的实操步骤,帮助企业搭建支撑可持续 AI 成功的基础设施底座,核心逻辑不是盲目增加资源投入,而是实现更智能的架构设计与运营管理。在增加计算资源之前,先全面梳理并明确现有架构的有效环节与瓶颈问题,核心动作包括:识别企业最高影响力的 AI 工作负载,及其对应的部署位置(云、核心、边缘);全面梳理存储、计算、网络、编排和数据管道之间的全链路依赖关系;建立基准性能指标并持续监测,核心监测指标包括单工作负载吞吐量(如样本 / 秒或 MB / 秒)、存储 IOPS 与实际利用率、模型交付到生产部署的全流程耗时、GPU 活跃时间与闲置率。将云作为企业 AI 的核心运营模式,而非例外补充选项,核心动作包括:选择针对企业自身 AI 应用场景,已构建配套工具、技能、功能与应用的云厂商;识别并将能最大程度发挥云厂商能力优势的 AI 工作负载迁移至云端;通过策略自动化跨边缘、核心与云端的数据移动,确保 AI 基础设施的资源利用率最优化。不合理的规模化只会放大基础设施的资源浪费,核心动作包括:追踪单工作负载的能源使用与冷却成本;持续监测节点闲置时间和 GPU 加速器利用率不足情况;针对混合、本地和 GPU 即服务配置,开展全周期总拥有成本(TCO)对比建模,建模过程中需纳入资源利用率因素,而非仅考虑采购成本。企业 AI 运营的核心阻力来自系统碎片化,而非规模扩张本身,核心动作包括:全面停用冗余工具和无法适配 AI 需求的传统系统;自动化资源配置、监测和模型调优工作流;标准化系统配置,降低人为操作错误与新工作负载的部署就绪耗时。第五步:强化内部知识储备或寻找合作伙伴填补技能缺口AI 基础设施必须适配现有团队的能力边界,或通过专业合作伙伴补足能力短板,核心动作包括:识别 MLOps、数据工程和基础设施团队的核心技能缺口,制定针对性的补齐计划;联合专业合作伙伴落地培训项目,系统性提升团队的 AI 基础设施技能水平;借助合作伙伴加速项目交付周期,科学判断是否需要长期的专业服务与技术支持;整合厂商技术栈,降低运营摩擦与团队培训成本。无法实现全面监测,就无法完成有效优化,核心动作包括:搭建跨计算、存储和编排层的中心化可观测体系;持续监测四大类核心指标,分别是资源利用率(GPU、CPU、存储)、部署速度(构建 - 训练 - 运行全流程)、单节点功耗和热输出、停机时间、事件发生率与故障恢复时间;基于监测数据,持续识别基础设施的优化空间并落地改进措施,形成闭环优化体系。本次调研的核心结论清晰表明,AI 已全面进入生产落地时代,AI 项目成功的核心决定因素,不再是算法、模型规模或预算投入,而是经过优化的底层 AI 基础设施。当前企业普遍面临基础设施复杂性高、全链路效率低下、能源约束加剧、专业技能缺口显著四大核心挑战,这些挑战直接导致过半企业出现 AI 项目延期或取消,大幅拉长了 AI 投资的 ROI 兑现周期。未来,AI 基础设施的发展将呈现三大核心趋势:一是架构从碎片化堆叠走向统一化、专用化,专为 AI 工作负载设计的全栈基础设施将成为行业主流,传统系统改造适配的模式将逐步被市场淘汰;二是部署模式从单一架构走向云、本地、边缘协同的均衡型混合架构,最大化兼顾业务灵活性、成本控制与数据管控力;三是价值衡量标准从峰值算力转向每瓦产出效率,能源利用效率将成为 AI 规模化的核心约束,同时也将成为企业的核心竞争力。同时,企业无法仅凭自身能力应对 AI 时代的基础设施挑战,云厂商、专业基础设施提供商、系统集成商组成的生态合作体系,将成为企业 AI 规模化落地的核心加速器。那些将基础设施视为战略资产、而非后台支撑系统的企业,将实现更快的 AI 创新落地、更短的 ROI 兑现周期,以及更可持续的长期规模化发展,最终在 AI 生产时代建立起难以复制的核心竞争优势。
【特别声明】本文为陈博观察原创内容,如需转载或引用请注明上述版权信息。文中相关插图已标注来源单位,版权完全归相关单位以及原作者所有;未标注的插图为本公众号绘制(部分素材借助AI工具完成)或来源于网络公开资料,如涉及侵权,请联系我们处理(yujianchenwei@163.com)。此外,本文仅供研究参考用,在任何情况下,文中的任何信息和结论均不构成对任何个人的投资与决策建议。