


六、测试结果与分析
(一)合成基准测试:Geekbench ML、AIMark、PCMark 10
本研究在测试设备上分别搭载DDR5 和 LPCAMM2 内存,运行表 2 中的通用工作负载和 AI 工作负载基准测试,对比二者的性能得分和 DRAM 功耗,并将 DDR5 的测试结果归一化为 1.0,以便更直观地解读数据。
功耗分析:测试结果显示,LPCAMM2 内存的 DRAM 功耗远低于 DDR5 SODIMM,仅为后者的 12%-13%,功耗节省超 85%。
性能分析:在 Geekbench ML 和 PCMark 10 测试中,LPCAMM2 与 DDR5 SODIMM 性能表现相当;而在 AIMark 测试中,LPCAMM2 的性能得分高出 20%。
两款内存均在系统默认配置下完成验证,未自定义工作频率,结合功耗和性能数据可得出结论:LPCAMM2的能效显著优于DDR5。
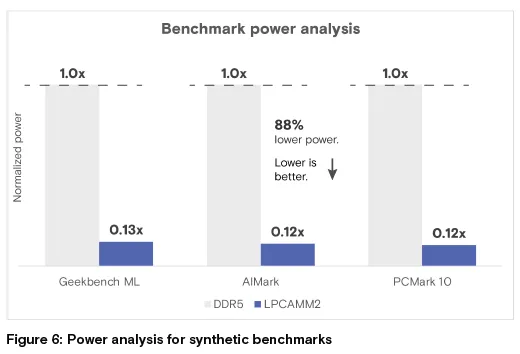
图 6:合成基准测试功耗分析
结论:LPCAMM2 功耗为 DDR5 的 0.13-0.12 倍,功耗降低 88% 左右(数值越低越好)
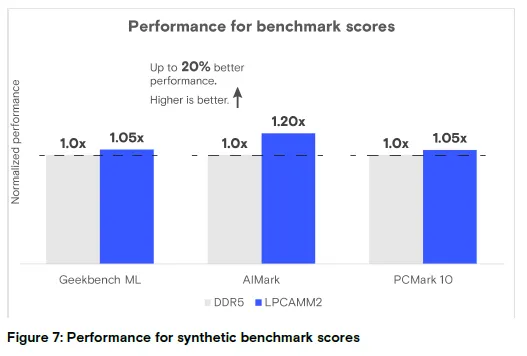
图 7:合成基准测试性能分析
结论:LPCAMM2 在 AIMark 中性能提升 20%,整体性能持平或优于 DDR5(数值越高越好)。
(二)Procyon® AI 计算机视觉基准测试
该基准测试包含 6 个精心挑选的神经网络模型,分别代表未来 AI 应用的核心领域(如下表),这些模型对应的基础任务可延伸出丰富的 AI PC 实际应用场景。模型文件大小与训练参数数量相关,但并非决定推理时间的关键因素,模型架构才是影响推理时间的主要因素。
表 5:Procyon® AI 计算机视觉基准测试表
模型 | MobileNetV3 | Inception-v4 | ResNet-50 | DeepLabv3 | YOLOv3 | ESRGAN |
用途 | 图像分类 | 图像分类 | 图像分类 | 图像分割 | 目标检测 | 超分辨率 |
参数量 | 390 万 | 4260 万 | 2560 万 | 210 万 | 6190 万 | 1670 万 |
模型大小 | 14.9MB | 162MB | 97.8MB | 8.06MB | 236MB | 63.8MB |
CPU 推理性能 | 1.0(基准) | 1.0(基准) | 1.0(基准) | 1.0(基准) | 1.0(基准) | 1.0(基准) |
iGPU 推理性能 | 1.2 | 1.66 | 1.69 | 1.64 | 1.75 | 1.72 |
NPU 推理性能 | 1.43 | 1.78 | 1.71 | 0.96 | 1.8 | 1.77 |
本研究以 CPU 的推理性能为基准(归一化为 1.0),对比 iGPU 和 NPU 运行这些模型时的性能提升。测试发现,6 个模型中有 4 个在 NPU 上的运行速度显著提升,约为 CPU 的 1.6 倍,且 NPU 性能略优于 iGPU;MobileNetV3 模型的性能提升幅度较小,但在 NPU 上的运行速度仍比 CPU 快 1.4 倍。整体而言,NPU 在所有模型中的表现均较为出色,仅在运行 DeepLabv3 模型时性能与 CPU 接近,而该模型在 iGPU 上的表现依旧亮眼。
考虑 FP16 和 INT8 精度
基于英特尔OpenVINO 框架的Procyon® AI 推理基准测试,支持不同硬件加速器以不同量化精度运行。GPU为图形相关任务优化,擅长浮点运算,同时支持整数精度;而NPU 则主要为整数精度设计。
为保证研究的全面性,本研究同时采集了INT8 和 FP16 精度下的测试数据,且两种精度得出的结论基本一致;为简化表述,下文仅展示FP16 精度的测试结果,并通过图表对比LPCAMM2 与 DDR5 的性能、功耗和能效。
结论:LPCAMM2 与 DDR5 在系统层面的性能差异较小,但 LPCAMM2 的能效(每瓦性能)显著更高。
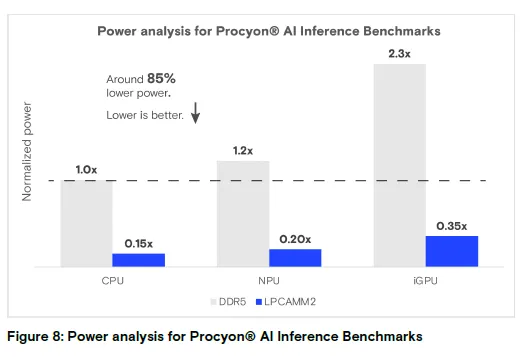
图 8:Procyon® AI 推理基准测试功耗分析
结论:LPCAMM2 在 CPU/NPU/iGPU 下的功耗均为 DDR5 的 0.15-0.35 倍,功耗降低约 85%(数值越低越好)。
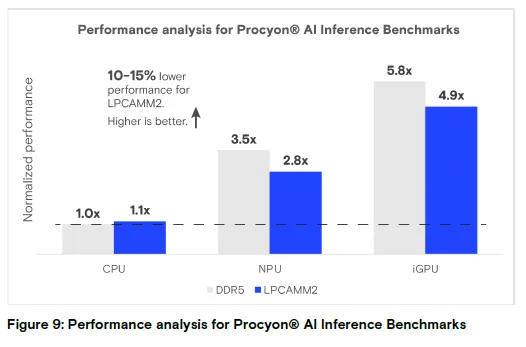
图 9:Procyon® AI 推理基准测试性能分析
结论:LPCAMM2 性能比 DDR5 低 10%-15%,但 NPU/iGPU 性能远高于 CPU(数值越高越好)。
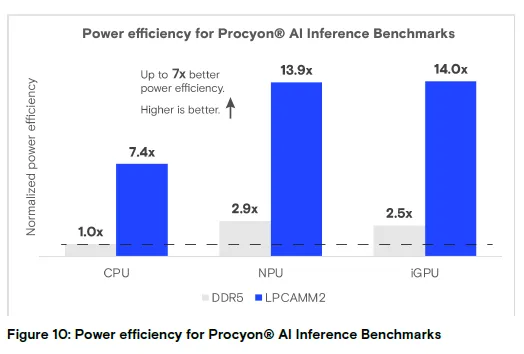
图 10:Procyon® AI 推理基准测试能效分析
结论:LPCAMM2 的能效最高比 DDR5 提升 7 倍(数值越高越好)。
(三)大语言模型(LLM)
本研究采用 LM Studio(0.2.25)工具,在特定硬件加速器上运行大语言模型,以此评估内存的能效⁶。分析分为两部分:仅在 CPU 上运行 Meta Llama 3,以及仅在 iGPU 上运行 Meta Llama 3;由于英特尔 NPU 的 Meta Llama 3 8B 模型仍在开发中,未纳入本次研究范围。
第一部分为仅 CPU 运行 Meta Llama 3 和 Mistral 7B Instruct,所有工作负载均由 CPU 独立执行;第二部分为仅 iGPU 运行 Meta Llama 3,推理任务全部交由 GPU 完成。
测试结果显示,搭载LPCAMM2 的系统在大语言模型推理工作负载中,内存能效是DDR5 的 4 倍,这一显著提升主要得益于 LPCAMM2 更低的功耗—— 其工作功耗比 DDR5 低 57%-61%,待机功耗最高比 DDR5 低 80%(更多细节可参考 LPCAMM2 产品简介)。
仅 CPU 运行 Meta Llama 3 和 Mistral 7B Instruct
此前的 AI 基准测试结果表明,LPCAMM2 的性能优于 DDR5,但这些测试所用模型的规模和复杂度,远不及 Meta Llama 3、Stable Diffusion 等实际应用中的 AI 模型(这类模型需占用数 GB 的内存空间)。因此,有必要在这些高负载工作场景中,评估 LPCAMM2 与 DDR5 的能效。
右侧图表展示了仅CPU 执行推理时,DDR5和 LPCAMM2 的功耗和性能指标,核心结论如下:LPCAMM2 的性能与 DDR5 相当,但功耗显著更低,降幅超 70%;基准测试得分同样显示,二者在 CPU 上的性能表现相近。且仅 CPU 运行推理时,Mistral 7B Instruct 和 Meta Llama 3 的功耗、性能结果趋势一致,因此在后续仅 iGPU 的测试中,本研究仅选取 Meta Llama 3 展开分析。
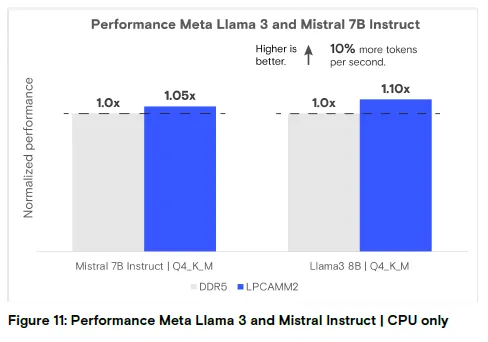
图 11:仅 CPU 运行 Meta Llama 3 和 Mistral Instruct 的性能分析
结论:LPCAMM2 的令牌生成速度比 DDR5 快 5%-10%,性能略优(数值越高越好)。
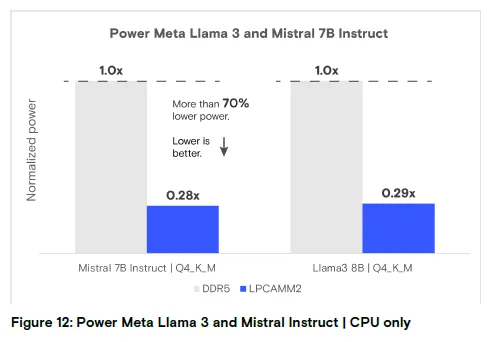
图 12:仅 CPU 运行 Meta Llama 3 和 Mistral Instruct 的功耗分析
结论:LPCAMM2 功耗仅为 DDR5 的 0.28-0.29 倍,功耗降低超 70%(数值越低越好)。
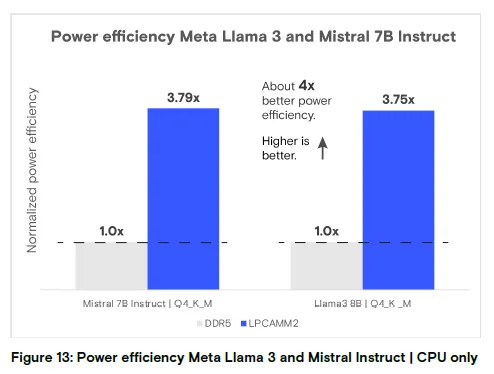
图 13:仅 CPU 运行 Meta Llama 3 和 Mistral Instruct 的能效分析
结论:LPCAMM2 的能效约为 DDR5 的 3.75-3.79 倍,提升近 4 倍(数值越高越好)。
仅 iGPU 运行 Meta Llama 3
本研究采用 SYCL直接编程语言和英特尔oneAPI 数学核心库(oneMKL,高性能 BLAS 库),在英特尔 ® 酷睿™ Ultra 9 处理器的内置英特尔 ® 锐炫™ GPU 上运行 Meta Llama 3。
集成 GPU(iGPU)采用主机共享内存架构,运行 Meta Llama 3 8B 模型需占用超 5.6GB 内存 —— 主机总内存需达到 16GB 及以上,其中最多一半内存会分配给 iGPU。
注:SYCL 的详细使用指南可参考 llama.cpp 项目。
测试结果表明,仅iGPU 运行 Meta Llama 3 8B 模型的推理速度,比仅CPU 运行快近 1 倍;DDR5 和 LPCAMM2 在 iGPU 推理中的性能(每秒令牌数)表现相当,但 LPCAMM2 的 DRAM 功耗大幅降低,比 DDR5 低 80%。
整体而言,仅iGPU 运行 Meta Llama 3 8B 模型时,搭载LPCAMM2 的系统能效(每瓦性能)是DDR5 系统的 2.6 倍。
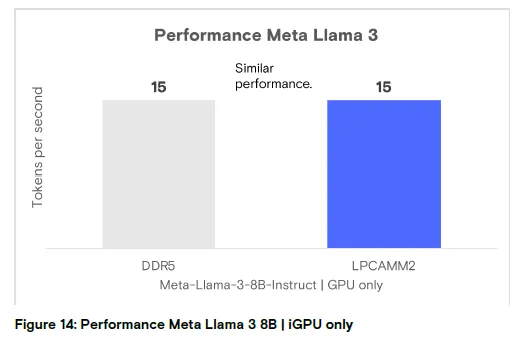
图 14:仅 iGPU 运行 Meta Llama 3 8B 的性能分析
结论:DDR5 与 LPCAMM2 性能表现基本一致(数值越高越好)。

图 15:仅 iGPU 运行 Meta Llama 3 8B 的功耗分析
结论:LPCAMM2 功耗仅为 DDR5 的 0.2 倍,功耗降低 80%(数值越低越好)
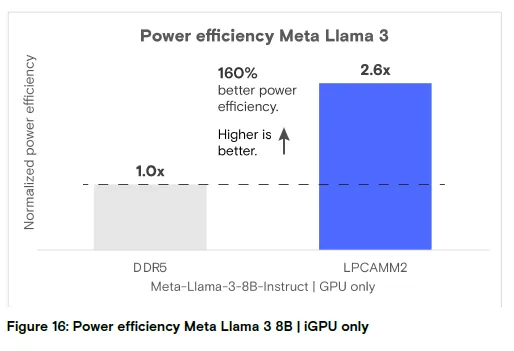
图 16:仅 iGPU 运行 Meta Llama 3 8B 的能效分析
结论:LPCAMM2 的能效是 DDR5 的 2.6 倍,提升 160%(数值越高越好)。
(四)AI 加速器与内存的功耗和性能综合分析
通过对不同加速器、不同内存类型在各类工作负载下的DRAM 功耗和性能分析可得出:GPU性能表现最佳,但功耗也更高;NPU则兼顾高性能与高能效。在内存方面,LPCAMM2在实现与 DDR5 相当性能的同时,实现了可观的功耗节省。
下图基于Procyon® AI 计算机视觉基准测试结果,展示了不同内存类型与各硬件加速器(CPU、NPU、iGPU)搭配的功耗和性能分布:纵轴代表性能,横轴代表DRAM 功耗,气泡大小代表整体能效(气泡越大,能效越好),而左上角为最优象限(性能最高、功耗最低)。测试数据表明,NPU或 iGPU 搭配 LPCAMM2 完成 AI 加速时,能实现最高的内存能效,是 AI PC 的最优选择。
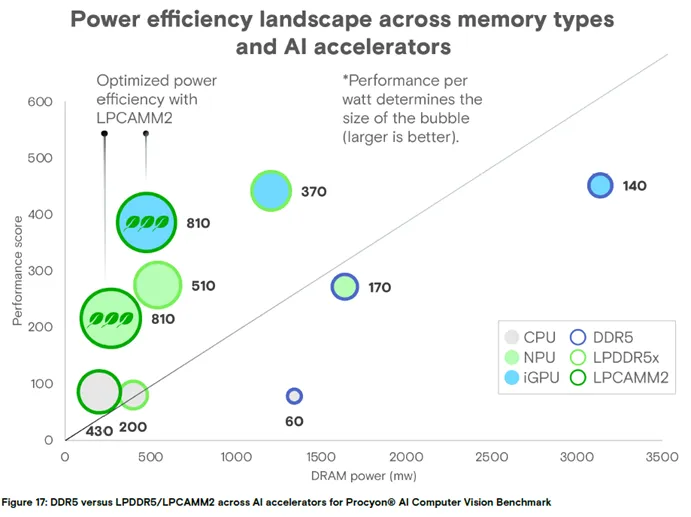
图 17:不同内存类型与 AI 加速器的能效分布
结论:LPCAMM2 搭配 NPU/iGPU 时,处于能效最优象限,为 AI PC 的最佳组合。
(五)系统层面的AI 推理分析
前文的功耗和性能分析表明,在各类AI 工作负载和硬件加速器中,LPCAMM2的能效均显著高于DDR5(参考图 10、图 13);但要确定哪款硬件加速器在功耗、性能和可扩展性上表现最优,还需对系统流水线进行更深入的微架构分析。
本研究采用英特尔 ® VTune™ 性能分析器捕获CPU 的微架构流水线使用率,虽该工具仅能获取CPU 的流水线数据,但可通过分析搭载NPU/iGPU 时 CPU 的微架构使用率,表征各类硬件加速器的性能,从而评估纯 CPU 系统、CPU+NPU 系统、CPU+iGPU 系统的整体能效。
该分析有助于明确程序执行过程中的瓶颈所在,以及随着硬件加速器性能提升,瓶颈如何在内存和计算之间转移。本研究捕获了搭载LPCAMM2 时,各硬件加速器(CPU、iGPU、NPU)运行 Procyon® AI 计算机视觉基准测试的微架构流水线使用率,发现随着硬件加速器计算能力的提升,工作负载对内存的依赖性逐渐增强,因此需要更高性能的内存子系统提供支撑。
基于英特尔 VTune™ 性能分析器的微架构分析
对 Procyon® AI 计算机视觉基准测试的CPU 使用率分析表明,使用GPU 和 NPU 加速器时,CPU 使用率显著降低:搭配 GPU 时,CPU 使用率下降 85%;搭配 NPU 时,CPU 使用率下降 90%。
CPU+NPU 和CPU+iGPU 配置下的 CPU 使用率更低,原因在于大量计算任务被卸载至加速器,释放了 CPU 周期,可用于处理其他系统任务。这一能力对 AI PC 至关重要,使其能在运行 AI 工作负载的同时,全速处理传统工作负载,实现多任务并行。
此外,搭配 GPU 加速器时,CPU 的平均工作频率有所提升;而搭配 NPU 时,CPU 平均工作频率下降 10%(从 3.0 GHz 降至 2.7 GHz),这意味着搭载 NPU 的系统更易实现更优的功耗表现。综上,从 CPU 使用率和工作频率的分析结果来看,NPU 是最优选择。
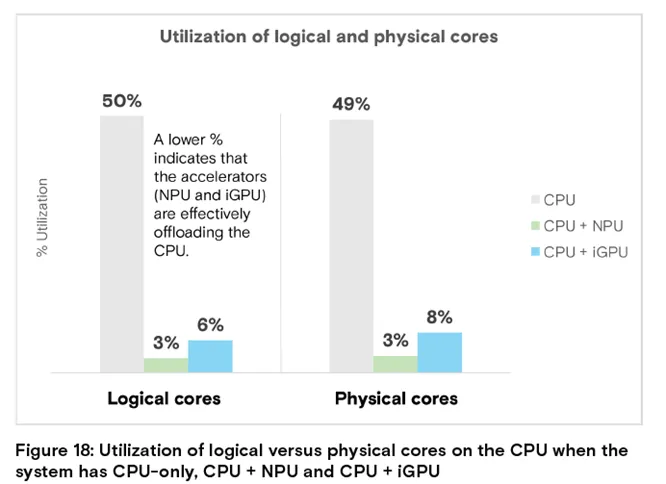
图 18:纯 CPU、CPU+NPU、CPU+iGPU 系统的 CPU 逻辑核心与物理核心使用率
结论:CPU+NPU/iGPU 系统的核心使用率仅 3%-8%,加速器有效分担了 CPU 负载(数值越低越好)。
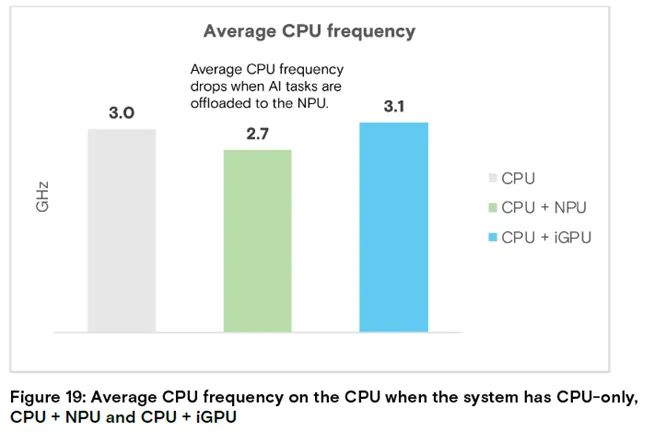
图 19:纯 CPU、CPU+NPU、CPU+iGPU 系统的 CPU 平均频率
结论:搭配 NPU 时 CPU 平均频率降至 2.7GHz,功耗表现更优。
为进一步验证 NPU的效能,本研究分析了任务卸载至加速器时,CPU性能核(P 核)、能效核(E 核)和低功耗能效核(LPE 核)的使用率。
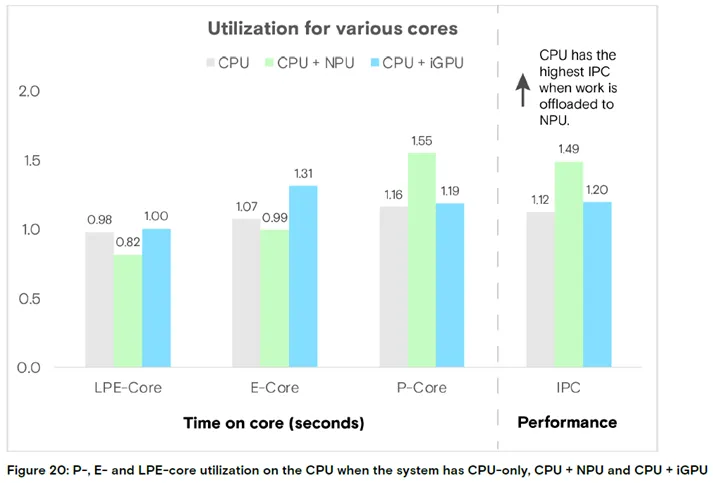
图 20:纯 CPU、CPU+NPU、CPU+iGPU 系统的 P 核 / E 核 / LPE 核使用率及 IPC
结论:搭配 NPU 时 CPU 的每时钟周期指令数(IPC)达 1.55,为三者最高,流水线利用效率最优。
从上图可发现:GPU加速时主要调用 E 核,而 NPU 加速时主要调用 P 核;尽管 NPU 加速时频繁使用 P 核,但 CPU 的平均工作频率仍低于 GPU 加速的场景。此外,与纯 CPU 和 GPU 加速场景相比,NPU 加速时 LPE 核的使用率显著更低。
NPU 加速时,CPU 的每时钟周期指令数(IPC)比 GPU 加速时高 25%,比纯 CPU 场景高 30%。这一分析进一步证实,NPU 能高效利用 CPU 流水线。
随着加速器性能的提升,性能瓶颈会同时出现在计算和内存层面。本研究通过分析各加速器下的微架构流水线插槽使用率,探究内存子系统能否有效支撑性能不断提升的加速器。
典型的 CPU 执行流水线插槽状态分为三类:已完成、因错误推测丢弃、因前端 / 后端操作阻塞。其中后端阻塞又可分为内存阻塞和核心(计算)阻塞;内存限制还可进一步分为DRAM 阻塞和缓存阻塞,而DRAM 阻塞又包括带宽阻塞和延迟阻塞。
这一精细化分析有助于理解内存子系统如何应对高级加速器的需求,以及潜在的优化方向。
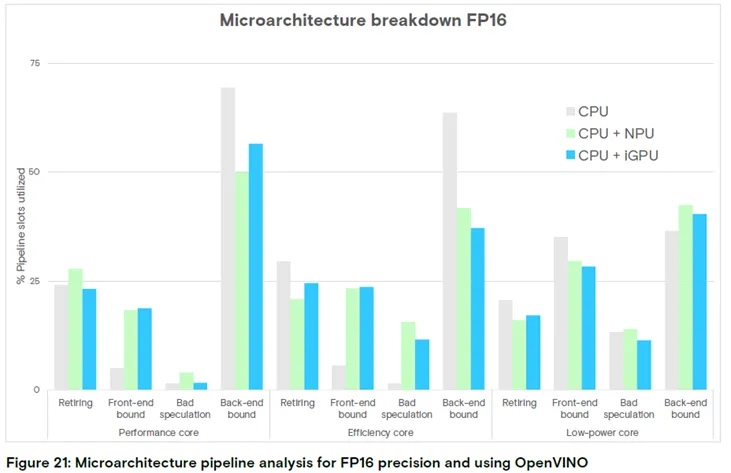
图 21:FP16 精度、OpenVINO 框架下的微架构流水线分析
结论:执行任务向高性能核心转移时,前端操作和错误推测导致的插槽阻塞减少,已完成插槽数增加,但后端操作阻塞显著上升。
图 21 显示,当任务执行向高性能核心转移时,因前端操作和错误推测导致的流水线插槽阻塞减少,已完成插槽数增加,但后端操作引发的插槽阻塞大幅上升;在NPU 加速场景中,已完成操作数随CPU 核心性能提升而增加。由于高性能核心的后端操作阻塞是明显的瓶颈,需进一步分析缓存和DRAM 的延迟。
图 22 展示了从内存总线读取数据消耗的时钟周期(带宽阻塞),以及等待数据的时钟周期(延迟阻塞)占比:在iGPU 和 NPU 加速场景中,延迟导致的时钟周期占比高于带宽,说明 CPU 花费在等待响应上的时间,比访问数据总线的时间更长。
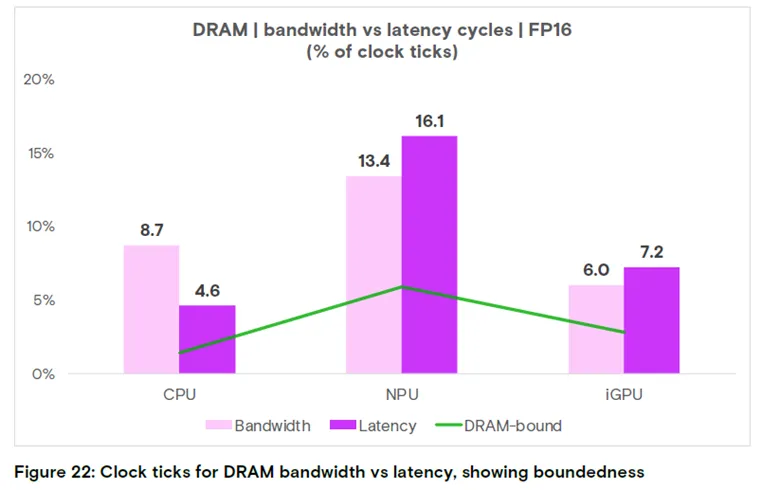
图 22:FP16 精度下 DRAM 带宽与延迟的时钟周期占比
核心结论:NPU/iGPU 加速时,内存延迟阻塞占比更高,CPU 等待数据的时间更长。
整体而言,随着AI 加速器计算能力的提升,工作负载对内存的依赖性逐渐增强(同时受带宽和延迟限制),因此内存是实现 AI 加速器最优性能的关键。
结合 NPU 更优的能效(每瓦性能),以及 LPCAMM2 的 DRAM 功耗比 DDR5 最高低 80% 的特点,NPU 与 LPCAMM2 的组合是 AI PC 的理想选择。
(六)AI 模型的内存使用率
本部分分析各类 AI应用和工作负载下的系统内存使用率:在运行Windows 24H2 系统的设备中,空闲状态下的基准内存使用率约为6GB。本研究以 CPU 运行 Procyon® AI 计算机视觉基准测试的内存使用率为基准(归一化为 1.0),对比模型加载至 iGPU 和 NPU 时的内存使用率,发现NPU 运行任务时的内存使用率最高,几何平均值为 CPU 的 1.37 倍。
表 6:Procyon® AI 计算机视觉基准测试的内存使用率
| 模型 | ||||||
| 用途 | 图像分类 | 图像分类 | 图像分类 | 图像分割 | 目标检测 | 超分辨率 |
| 参数量 | ||||||
| 模型大小 | ||||||
本研究采用 LM Studio 工具在边缘 PC 设备上加载 Meta Llama 3 7B 模型,模拟语言模型的执行过程,发现设备内存使用率从空闲状态的 6GB 大幅升至 15GB,内存占用增加约 9GB。
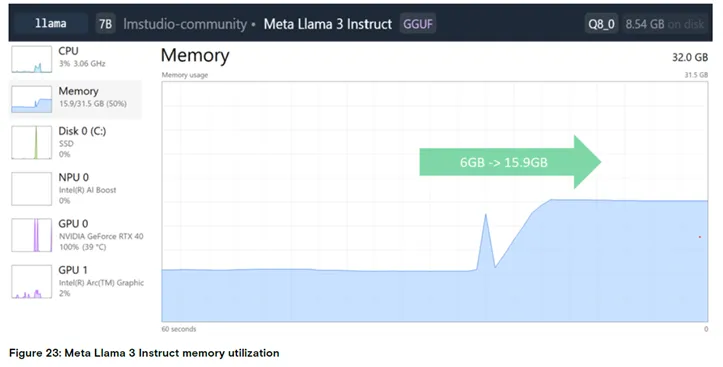
图 23:Meta Llama 3 Instruct 的内存使用率
结论:模型加载后内存使用率从 6GB 升至 15.9GB,占 32GB 总内存的 50%。
(七)Stable Diffusion 模型测试
本研究基于英特尔 ®酷睿™ Ultra 7 处理器 165U,在操作系统的三种笔记本电源配置下,对 Stable Diffusion 模型展开测试:
Stable Diffusion 的处理过程包含四个核心步骤:文本设备、U-Net设备、U-Net-neg设备和变分自编码器(VAE)设备,每个步骤对保障扩散过程的稳定性和准确性均至关重要,其中 U-Net 设备和 U-Net-neg 设备为计算密集型步骤。
用户选择不同的电源配置,对应不同的计算资源分配策略(如下表)。随着AI PC 的发展,Stable Diffusion 等 AI 工作负载可根据用户偏好(如性能优化)智能选择计算资源(CPU、iGPU、NPU),实现计算任务的智能调度,而非随机分配,为用户带来更优质的使用体验。
表 7:Stable Diffusion 电源模式与计算单元分配表
电源模式 | 最佳能效 | 平衡模式 | 最佳性能 |
文本设备 | CPU | CPU | CPU |
U-Net 设备 | NPU | GPU | GPU |
U-Net-neg 设备 | NPU | NPU | GPU |
VAE 设备 | GPU | GPU | GPU |
16GB 单通道DDR5 vs 32GB 双通道 DDR5
在不同内存配置下运行Stable Diffusion AI 模型,发现性能差异显著:
这一结果表明,要充分释放AI PC 上 AI 工作负载的性能,需配备足够的内存容量。
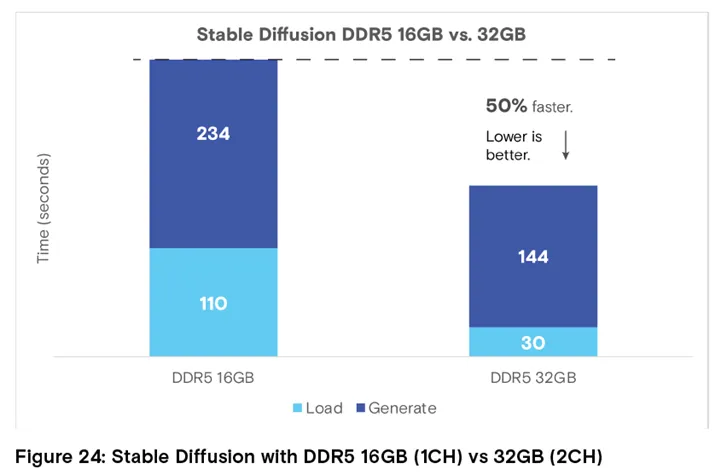
图 24:16GB 单通道 DDR5 与 32GB 双通道 DDR5 运行 Stable Diffusion 的性能对比
结论:32GB 双通道 DDR5 的加载和生成时间均显著降低,整体性能提升 50%(数值越低越好)。
(八)单通道与双通道对比
本实验的测试系统搭载英特尔® 酷睿™ Ultra 7 处理器 165U(研发代号 Meteor Lake)和 5600 MT/s DDR5 SODIMM 内存,基于 Procyon® AI 计算机视觉基准测试,探究单双通道内存配置对推理性能的影响,并在英特尔OpenVINO 框架下,对 CPU、iGPU、NPU 所有硬件引擎展开测试。
表 8:DDR5 单双通道运行 Procyon® AI 计算机视觉基准测试的性能对比
CPU 型号 | DRAM 类型 | 数据速率(MT/s) | 内存通道 | CPU | NPU | iGPU |
英特尔 ® 酷睿™ Ultra 7 165U | DDR5 SODIMM | 5600 | 单通道 | 109.0 | 448.0 | 314.0 |
双通道 | 153.0 | 537.0 | 384.0 | |||
双通道性能提升幅度 | 40% | 20% | 22% |
通道数量的影响:内存通道增加会提升 DRAM 整体带宽,进而提升系统整体性能。测试发现,与单通道配置相,双通道 DDR5 的性能提升 20%-40%。通过双通道提升内存带宽,能大幅增强系统处理 AI 工作负载的效率,这对需要高数据吞吐量和快速访问的应用而言至关重要。但需注意,增加内存通道会增加整体成本和主板设计复杂度。
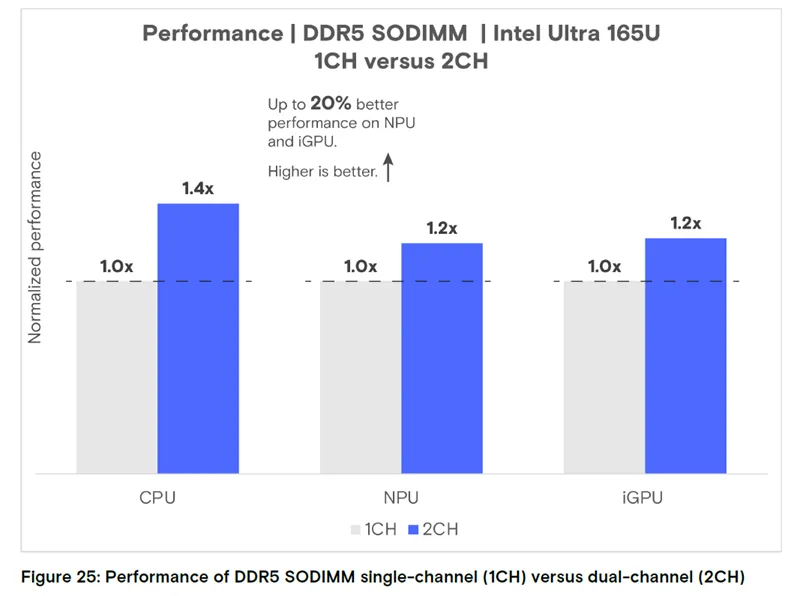
图 25:英特尔 Ultra 165U 平台 DDR5 SODIMM 单双通道性能对比
结论:双通道在 NPU/iGPU 上的性能提升约 20%,CPU 上提升 40%,整体性能显著优于单通道(数值越高越好)。
七、结论
随着 AI 模型的持续发展,其复杂度和规模不断提升,兼具高性能、大容量和高能效的先进内存解决方案的重要性也将日益凸显。其中,LPCAMM2等先进内存技术凭借远超DDR5 的能效,以及与DDR5 相当的性能,成为满足AI PC 需求、推动 AI PC 架构发展的关键技术。
AI PC 的核心需求之一,是能同时运行多个复杂模型,且不会产生过高的功耗—— 这对维持设备续航、保障用户在运行AI 任务的同时流畅处理通用应用至关重要。值得关注的是,LPCAMM2与 NPU 是互补的组合,二者搭配可实现电池供电下的高效 AI 任务处理,让用户无需连接电源即可使用高级 AI 功能,使搭载 LPCAMM2 的 AI PC 兼具强大性能和便携性。
此外,随着 AI 工作负载的不断升级和模型规模的扩大,AI PC 对内存容量和带宽的需求也愈发迫切。16GB 以上的内存容量是处理现代 AI 应用密集型数据处理和模型训练任务的必要条件。本研究发现,许多 AI 工作负载对内存的依赖性较强,更高的内存带宽和更大的容量能为其带来显著的性能提升。例如在Stable Diffusion 任务中,将内存从单通道升级为双通道、容量从16GB 提升至 32GB 后,计算时间大幅缩短。更大的内存容量能让任务处理更高效,降低延迟,提升系统整体性能。
需重点说明的是,系统架构对确定AI PC 的最优内存配置起着关键作用,DDR5和 LPCAMM2 的选择需结合系统架构的具体需求和目标应用场景,核心考量指标包括能效、内存延迟、带宽以及AI 加速器的利用率。