


计算世界一场静默的革命正在发生,当冯·诺依曼架构的“柏林墙”横亘在算力增长之路上,三条技术路径正从不同方向发起冲击,它们或许将共同定义计算的下一个纪元。
深夜,硅谷某AI实验室的服务器集群依然轰鸣。一组研究人员正盯着屏幕上缓慢增长的训练进度条,他们的最新模型拥有1.8万亿参数,而每次完整训练需要消耗的电力足以支撑一个小镇数周运转。
超过70%的能耗并非用于矩阵乘法本身,而是消耗在将参数从高带宽存储器搬运到计算单元的路上——这就是计算领域著名的“内存墙”问题。
而在大洋彼岸的深圳,一支工程师团队正测试着一款奇特的芯片。当处理从摄像头传入的连续视频流时,它的功耗仅有传统方案的三十分之一。它的秘密在于:它根本不做传统意义上的“数据搬运”。
01 失衡的方程式:冯·诺依曼瓶颈的物理本质
要理解非冯诺依曼架构的革命性,我们需要回到问题的源头。1945年确立的冯·诺依曼体系,其核心“存储程序”思想将计算分离为三个物理单元:负责计算的CPU、负责存储的Memory,以及连接二者的数据总线。
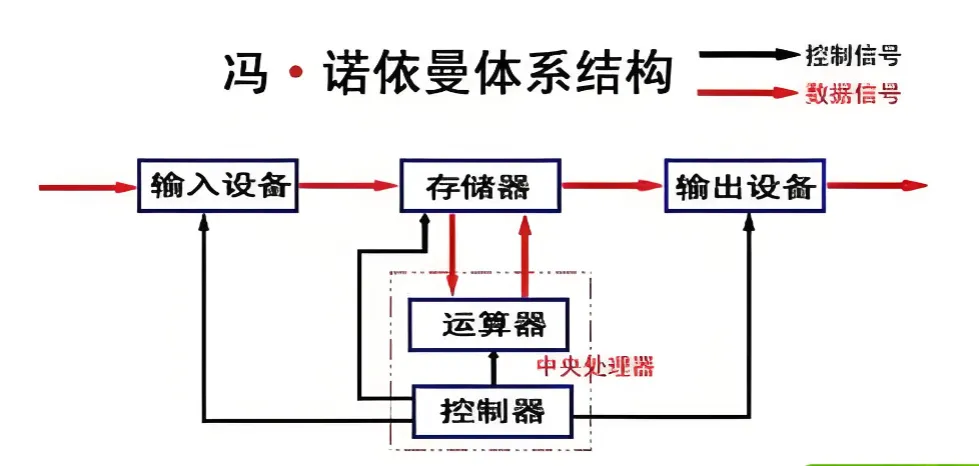
这套系统运行了七十年后,一个根本性的失衡出现了:计算单元的性能增长速度,远远超过了存储和互连系统的进化速度。
过去三十年,CPU的算力以每年约55% 的速度增长,而内存带宽的年增长率仅为10%,内存访问延迟的改善更是几近停滞。这导致了一个荒谬却普遍的现象:现代高端处理器在执行复杂任务时,超过60%-70% 的时间处于“饥饿”状态——计算核心空转,等待数据从内存中缓缓送达。
AI大模型的爆发将这个矛盾推向了极致。一个千亿参数模型的权重文件可能高达数百GB,远超任何芯片的片上缓存。训练过程变成了永不停歇的“数据搬运马拉松”:计算1秒钟,可能需要等待10秒钟的数据调度。
“内存墙”带来了三个维度的危机:
能耗危机:在7nm工艺下,从DRAM中搬运一个64位数据到计算单元的能耗,约是在片上SRAM中完成一次32位浮点计算能耗的200倍。这意味着AI计算的能量大多浪费在路上,而非思考本身。
性能危机:无论计算单元多强大,都受制于最慢的内存访问速度。提升算力变得事倍功半。
成本危机:为缓解瓶颈而不断堆叠的HBM等高速内存,已成为高端AI芯片最主要的成本中心之一,占比可达40%-50%。
物理学的基本规律已经表明,在现有架构框架内进行优化,边际效益正急剧递减。我们需要的不只是更宽的道路,而是重新设计城市的交通模式。
三条最主流的技术路径正在开辟新的可能性:存算一体、神经拟态计算、近存计算与先进封装。它们从不同的哲学出发,指向同一个目标:瓦解“存储”与“计算”之间的物理壁垒。
02 第一武器:存算一体——终极的融合与早期曙光
核心理念:让计算发生在数据存储的地方。
想象一下,如果图书馆的每本书在书架上就能自动完成阅读理解并输出摘要,那将节省多少搬运和查找的时间?存算一体正是这个思路在芯片级的实现:直接在存储器阵列中嵌入计算能力,省去数据移动步骤。
技术实现的三层路径:
1. 数字存算一体(当前主流)这是最务实的起点。利用现有的SRAM或嵌入式Flash存储器阵列,在存储单元周边布置计算电路(如乘加器)。虽然存储介质本身未改变,但通过极近的物理距离和定制化的数据流,仍然能大幅减少数据搬运。
代表案例:众多AI推理芯片采用此方案,针对卷积、注意力机制等固定模式优化。
2. 模拟存算一体(前沿突破)更具革命性。利用新型非易失存储器(如RRAM、PCM、MRAM)的物理特性(如电阻、电流)直接进行计算。一个交叉阵列即可同时完成存储和矩阵向量乘法,能效潜力巨大。
关键突破:2023年,清华大学团队在《自然》发表论文,基于忆阻器阵列实现了更高效的神经网络训练,展示了从“存算”到“存训一体”的潜力。
产业化先锋:国内如知存科技、新忆科技等公司已推出商用芯片,主要用于智能耳机、手表等设备的超低功耗语音关键词唤醒。
3. 架构创新:从“计算为中心”到“存储为中心”存算一体不仅仅是硬件的改变,更迫使软件和系统架构的重构。传统的“计算中心”模型变为“数据不动,计算主动”的新范式。这需要全新的编程模型、数据布局算法和编译器技术。
商业化黎明:边缘的星星之火
存算一体当前正处于从技术验证到早期商业落地的转折点,其特点非常鲜明:
市场切入点:超低功耗、特定任务的边缘AI场景是绝对主流。如智能传感、可穿戴设备中的始终在线语音识别、轻量级图像识别。
优势:能效比(TOPS/W)可比传统架构高1-2个数量级,响应延迟低。
挑战:计算精度受限(模拟计算尤甚)、编程灵活性差、制造工艺和良率挑战大、通用性弱。
现实定位:短期内无法替代通用处理器,而是作为专用协处理器,在能效敏感场景建立根据地。它的发展更像特种部队,在特定任务中展现无可比拟的优势。
03 第二武器:神经拟态计算——仿生的异步革命
核心理念:模仿大脑,以事件驱动,而非时钟驱动。
如果存算一体是从空间上融合计算与存储,那么神经拟态计算则是从时间维度和工作模式上进行颠覆。它抛弃了传统计算机全局同步的“心跳”(时钟信号),转而模仿大脑的异步、稀疏、事件驱动的工作方式。
技术实现的三大支柱:
1. 脉冲神经网络这是与神经拟态硬件匹配的“软件”。SNN的神经元不像人工神经网络那样在每个周期都传递连续的数值,而是只在特定时刻发出稀疏的脉冲(Spike)。信息编码在脉冲的时序和频率中,这使得处理动态时序信号(如视频、音频)具有天然优势。
2. 事件驱动架构芯片没有全局时钟。每个“神经元”和“突触”电路只在接收到输入脉冲时才被激活并消耗能量,没有事件时则处于接近零功耗的静默状态。这种“无事不登三宝殿”的特性,使其在稀疏数据场景下能效极高。
3. 存算一体特性在神经拟态芯片中,模拟生物突触的可塑性(即权重)的单元,往往与计算单元紧密耦合,天然具有存算一体的特征,进一步减少了数据搬运。
代表玩家与进展:
英特尔Loihi系列:最知名的神经拟态研究芯片,已发展至第二代Loihi 2。其特点是高度的灵活性和可编程性,主要用于科研机构探索嗅觉识别、机器人触觉、优化问题求解等新应用范式。
IBM TrueNorth:早期的开创性工作,展示了极低的功耗。
国内研究:清华大学、中国科学院等机构在SNN算法、类脑芯片架构上均有深厚积累,但大规模商业化产品尚在孕育。
商业化黎明:寻找“杀手级应用”
神经拟态计算可能是三条路径中最具长远颠覆性,但也最需要耐心的。
当前阶段:高级研究与原型探索。主要用于学术界和工业研究实验室,探索传统架构不擅长的低功耗实时感知、时空信息处理、组合优化等问题。
优势潜力:超低功耗、超低延迟、处理非结构化信息的天然优势。
核心挑战:算法生态不成熟(SNN训练困难,与传统AI生态割裂)、编程模型抽象度低、缺乏公认的“杀手级应用” 证明其不可替代性。
未来展望:它可能不会取代主流计算,而是在边缘感知与实时控制(如自动驾驶的传感器融合、无人机避障)、脑机接口、新型AI范式等领域开辟全新的细分市场。它的商业化,有赖于一个全新应用生态的缓慢生长。
04 第三武器:近存计算与先进封装——务实的工程革命
核心理念:如果无法彻底融合,那就无限贴近。
这是目前产业化程度最高、最主流的“非冯”路径。它不追求物理上的彻底融合,而是利用先进封装和互连技术,将计算芯片和存储芯片在物理距离上无限拉近,用“超级高速公路”取代“普通公路”,以极高的带宽和极低的延迟来缓解(而非解决)内存墙问题。
核心技术栈:
1. 高带宽存储器HBM是近存计算的标志性成果。它通过硅通孔技术将多个DRAM芯片堆叠在一起,并与底层逻辑芯片通过硅中介层进行超高速互连。最新HBM3e的带宽已突破1TB/s,是GDDR6的5倍以上,访问延迟也大幅降低。
产业地位:已成为高端GPU和AI加速卡的标配,完全主流化。
2. 2.5D/3D先进封装这是实现近存计算的“基建”。通过将计算芯粒和存储芯粒并排(2.5D)或垂直堆叠(3D)在同一个封装基板或中介层上,实现芯片级的超高密度互连。
代表案例:AMD的MI300A是典范,将CPU、GPU和HBM通过3D堆叠集成,实现了远超传统封装的内存带宽。
3. Chiplet与异构集成这是近存计算的未来形态。将大芯片拆解为多个功能单一的“芯粒”(如计算芯粒、I/O芯粒、缓存芯粒),然后通过先进封装集成。FPGA、专用加速器都可以作为芯粒,与通用计算单元和HBM“混搭”,实现定制化的近存计算系统。
商业化黎明:已成为高性能计算的基石
近存计算是三条路径中唯一已实现全面商业化和产业主导的。
市场现状:数据中心、高性能计算、高端图形处理的绝对主流选择。任何追求极致性能的芯片,都无法回避HBM+先进封装的方案。
优势:性能提升显著且直接、兼容现有软件生态(无需颠覆性重写)、技术相对成熟。
挑战:制造成本高昂(中介层和封装占芯片成本比例越来越高)、散热挑战巨大(高密度集成带来热密度急剧上升)、供应链集中(先进封装产能被少数厂商控制)。
产业意义:它代表了通过系统工程和集成创新来突破瓶颈的现实主义路径。虽然理论创新性不如前两者,但其对产业的实际推动力目前是最大的。它也在客观上为Chiplet生态和国产芯粒间互连标准的发展提供了强劲动力。
05 三条道路的比较与融合未来
维度 | 存算一体 | 神经拟态计算 | 近存计算与先进封装 |
核心理念 | 存储即计算,物理融合 | 仿脑异步,事件驱动 | 存储紧贴计算,工程优化 |
技术成熟度 | 早期商用(边缘) | 研究探索/原型 | 完全成熟/主流 |
产业化阶段 | 边缘AI利基市场 | 寻找杀手级应用 | 数据中心标配 |
能效潜力 | 极高(10-100倍提升) | 极高(稀疏事件下) | 高(相对传统架构) |
通用性/灵活性 | 差(专用) | 中等(适应特定范式) | 好(兼容现有生态) |
主要挑战 | 精度、灵活性、制造 | 算法生态、编程模型、应用 | 成本、散热、供应链 |
国产化机遇 | 与国际差距较小,可同台竞技 | 基础研究并跑,应用生态可自主定义 | 面临先进封装产能和IP的追赶压力 |
通过对比可以发现,这三条路径并非简单的替代关系,而是互补与融合的关系。
未来的计算架构,极有可能是一种“混合异构”模式:
以经过近存计算强化的传统CPU/GPU作为通用计算和复杂控制的“大脑”。
在关键能耗瓶颈处,嵌入存算一体的专用加速核作为“高效器官”,处理规整、固定的高密度计算。
在感知和实时交互界面,采用神经拟态处理器作为“感官神经”,以极低功耗处理流式时空信号。
而Chiplet与先进封装,则是将这些异构单元紧密集成在一起的“躯干和血脉”。
这种融合,对软件栈提出了前所未有的挑战,也催生了异构统一编程模型、跨平台编译器等新的软件创新机遇。
06 结语:从架构革命到产业生态
非冯诺依曼架构的革命,其意义远超几种新硬件的出现。它标志着计算产业从围绕单一通用架构的纵向深化,进入一个多元架构竞争并存、软硬件协同创新的“架构春秋时代”。
对于中国算力产业而言,这既是挑战,更是机遇。
在存算一体和神经拟态领域,全球均处于早期,中国的研究和产业界有机会从源头参与规则制定,培育自主的IP和生态。
在近存计算领域,虽需追赶先进封装等制造短板,但在HBM控制器设计、Chiplet互连协议(如中国推出的ACC标准)等方面,仍有广阔的自主创新空间。
架构的突破不会一蹴而就,商业化的黎明也总是先照亮一两个特定的山头。但可以确定的是,对“内存墙”的这场围攻已经全面展开。每一种武器,都代表了对计算本质的一次重新思考,也都将在未来的计算版图中,占据属于自己的一席之地。
下一站,我们将从硬件的架构革命,转向软件范式的关键变迁——《第三支柱:流式计算——从“实时数据处理”到“实时业务操作系统”》。我们将看到,当数据从静态的“湖”变为奔流的“河”,支撑其上的软件栈如何演变,并成为驱动未来商业的核心引擎。
免责声明:本文仅供学习、工作探讨,不做任何决策及推荐等意见和价值。
系列总览: