


内存与其他硬件加速器相辅相成,是充分释放AI PC 潜能的关键支撑。
在不断发展的人工智能(AI)领域,各行业对更强大数据模型的需求推动了模型规模的快速扩张。这一高速发展态势持续提升AI 模型的体量与复杂度,对计算性能和内存子系统性能提出了前所未有的要求,以处理和整合来自文本、音频、视频等各类输入的海量数据。随着AI 技术的持续进步,先进的内存解决方案不仅对大型数据中心至关重要,对边缘设备(包括将AI 能力直接赋能个人和专业设备的AI PC)而言也不可或缺。经过优化的内存解决方案,是推动各设备和平台下一代AI 驱动创新的重要助力。
本白皮书深入探讨AI PC 的架构层面,聚焦美光与联想的合作成果。基于搭载英特尔® 酷睿™ Ultra 9 处理器 185H(曾用研发代号 Meteor Lake)的联想 AI PC,对 DDR5 和 LPCAMM2 两种内存解决方案展开对比分析。报告重点阐述了这两种内存方案在实际 AI 工作负载下的性能指标、功耗节省效果及能效表现;同时,基于搭载英特尔 ® 酷睿™ Ultra 7 处理器 165U 的仁宝平台,测试并分析了单双通道内存的优劣,以及更高内存容量在各类 AI 工作负载中的优势。这份全面的分析揭示了不同内存解决方案对 AI PC 发展的影响与塑造作用,研究结果可为系统和产品架构师,以及原始设备制造商(OEM)、原始设计制造商(ODM)等核心 PC 行业从业者提供宝贵参考,助力其为自身平台选择并整合最优的内存子系统,为客户打造极致的 AI PC 使用体验。
推理速度提升 20%
在搭载中央处理器(CPU)、集成显卡(iGPU)和神经处理单元(NPU)的系统上运行 AI 推理时,16GB+16GB 双通道 DDR5 配置的推理速度平均比 32GB 单通道 DDR5 快 20%。
功耗降低 85% 以上
在各类基准测试中,LPCAMM2在 CPU、iGPU 和 NPU 全场景下的功耗比 DDR5 低约 85%。因此,LPCAMM2 的能效远超 DDR5,其内存子系统的能效(每瓦性能)最高可提升 7 倍。
AI PC 需配备16GB 以上内存
32GB 及以上的内存容量能有效避免内存不足错误,防止系统触发内存交换机制—— 该机制会导致系统运行速度下降多达50%。LPCAMM2 最高可支持 64GB 容量,为适配未来的高级模型做好了准备。
一、引言
在充满活力的 AI 领域,AI PC 平台的问世是一次重大的技术飞跃。这类平台通过实现本地数据处理,彻底革新了PC 处理复杂计算任务的方式,不仅提升了性能、增强了数据隐私与安全保护,还降低了延迟和网络拥塞,为用户带来更优质的使用体验。正如个人电脑、移动设备、云计算等过往的技术创新改变了我们生活的方方面面,近期生成式AI 的爆发式发展正推动各技术领域迎来前所未有的创新,AI PC 的诞生便是其中之一。
什么是 AI PC?
AI PC 是一款将AI 处理能力直接集成到硬件和软件中的计算设备。与传统PC 依赖应用软件或云服务完成AI 任务不同,AI PC搭载了专用的 AI 处理器或加速器,可通过本地执行矩阵运算实现 AI 功能。
相较于普通笔记本电脑,AI PC 具备多项性能优势,核心原因在于其搭载了针对AI 任务的专用硬件,能够本地处理面部识别、生物特征认证等敏感用户数据,保障数据隐私。二者的核心差异如下:
异构计算架构:AI PC 采用异构计算架构,融合了 CPU、集成 GPU 和 NPU。其中 NPU 为 AI 任务提供专用硬件加速,能效(每瓦性能)表现卓越,相关数据将在后续章节展示。
本地 AI 处理:AI PC 可本地运行 AI 模型,性能表现更优,减少了对云服务的依赖。这不仅降低了数据传输过程中的被拦截风险,还提升了隐私保护水平;而未搭载NPU 的普通笔记本电脑,本地AI 处理能力十分有限。
端侧 AI 加速器:AI PC 针对 AI 应用进行了优化,处理速度更快,能更高效地完成复杂 AI 任务。其搭载的 NPU 专为矩阵乘法和卷积运算设计 —— 这两种运算是 AI 和机器学习的基础。NPU 利用并行处理阵列同时执行多项运算,在提升性能的同时降低功耗,还能为 CPU 分担负载,使其专注于通用计算任务,也能让 iGPU 更好地完成视频剪辑、游戏等场景的复杂图像渲染工作。
高能效表现:凭借专用的硬件加速器,AI PC 在视频增强、图像识别等任务中具备更高的能效;而通用 CPU 在执行这类任务时效率较低,普通笔记本电脑因缺少该类加速器,运行 AI 工作负载时的能效表现不佳。
专属软件生态:AI PC 的软件生态针对 AI 应用和框架进行了优化,支持实时语言翻译、增强型视频会议等内置 AI 功能;而普通笔记本电脑的软件生态为通用型,内置 AI 功能十分有限。
强化的安全防护:搭载 AI 安全系统的 AI PC 能实时分析行为和模式数据,识别恶意软件、网络钓鱼等潜在威胁,全面提升系统安全性。
对普通用户而言,AI PC 带来了更优的性能、更强的安全性、更好的隐私保护和更高的能效。传统PC 需将数据传输至云端完成AI 任务,易受网络拥塞影响,而 AI PC 可本地处理这些任务,彻底改变了用户的 AI 应用使用体验。专业人士,尤其是创意和技术领域的从业者,能借助 AI PC 强大的端侧 AI 能力提升工作效率、保障数据隐私,并简化复杂工作流程。例如,作家和内容创作者可利用本地生成式 AI 优化文章措辞、快速头脑风暴。
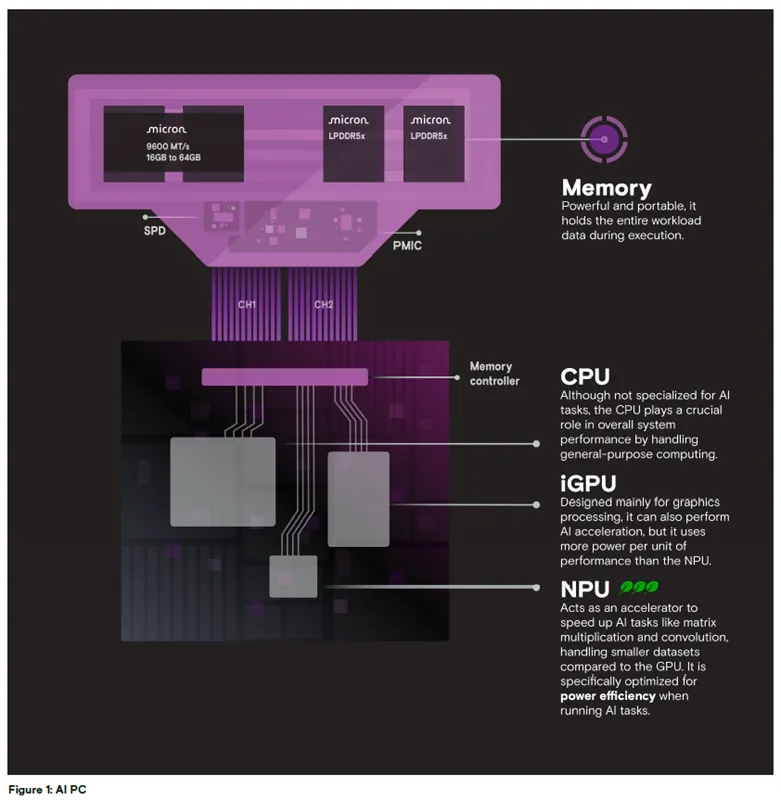
图 1:AI PC 架构示意图
内存:美光 9600 MT/s LPDDR5X,容量 16GB 至 64GB,集成 SPD、PMIC 芯片,性能强劲且便携性优异,可在任务执行期间存储全部工作负载数据。
CPU:配备内存控制器,虽非为AI 任务设计,但负责处理通用计算,对系统整体性能至关重要。
iGPU:主要为图形处理设计,也可实现AI 加速,但单位性能的功耗高于NPU。
NPU:作为加速器提升矩阵乘法、卷积等AI 任务的处理速度,处理的数据集规模小于GPU,专为 AI 任务的高能效运行优化。
二、AI 应用场景
以下几类 AI 应用在 AI PC 上运行时,性能能得到显著提升。借助 AI PC 更强的处理能力、更低的延迟(数据本地处理,无需上传云端)和更高的能效,这些应用无论在个人还是专业场景,即使在移动状态下也能发挥重要作用。
实时语言翻译:AI PC 可本地实现实时语言翻译,无需依赖网络云服务,翻译速度更快、准确率更高。
增强型视频会议:AI PC 能为视频会议提供实时背景虚化、降噪、智能取景等功能,提升会议体验。
内容创作:AI PC 非常适合视频剪辑、图像增强、自动化内容生成等内容创作任务,其专用硬件能让这些任务的处理效率大幅提升。
语音转文字:AI PC 可实现实时语音转文字,适用于会议、讲座等需要快速准确转录的场景。
安全应用:AI PC 可本地运行网络钓鱼检测、恶意软件分析等安全应用,提升安全防护水平和隐私保护能力。
AI 助手:AI PC 可本地部署 AI 助手,在日程安排、提醒、信息检索等任务中表现出更优的性能和响应速度。
高级数据分析:AI PC 能更高效地完成复杂数据分析任务,是金融、医疗、科研等领域从业者和相关应用的理想选择。
三、神经处理单元(NPU)
将 NPU 集成到 PC 中是计算领域的一项重大进步,不仅让 AI 任务的处理更高效,还为全新的 AI 驱动应用和功能的诞生奠定了基础。大多数用户对 PC 中的 CPU 和 GPU 并不陌生:CPU 专为通用计算任务设计;而 GPU(包括集成 GPU)搭载了大量专用计算核心,可同时执行多项运算,聚焦性能表现,这一架构使其非常适合图像处理、图形渲染和AI 计算。
与之不同,NPU 是专为高效处理 AI 和机器学习运算设计的处理器,能最大化能效(每瓦性能),非常适合需要持续处理且不希望过度消耗电池的任务。凭借优异的能效,NPU能在移动 AI 设备中提供强大的 AI 能力,同时提升设备整体性能。这意味着,设备仅依靠电池供电就能高效处理 AI 任务,用户无需连接电源即可使用各类高级 AI 功能。
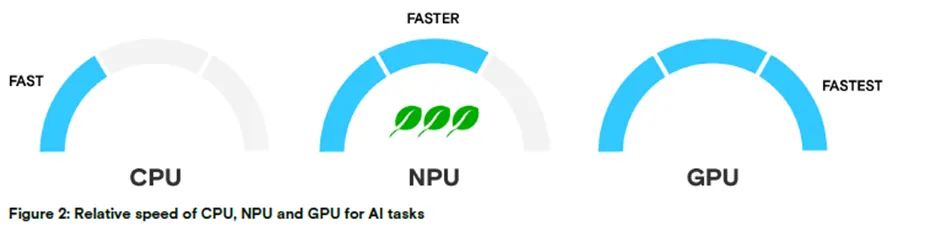
图 2:CPU、NPU、GPU 处理 AI 任务的相对速度
速度排序:CPU(慢)< NPU(中)< GPU(快)
性能、功耗与能效的关系
在 AI 任务计算中,NPU 的速度快于 CPU,但不及 GPU;不过 NPU 的功耗远低于 GPU,能效表现突出,非常适合需要持续处理的 AI 应用,尤其适用于无网络连接的工作场景。此外,NPU 负责处理 AI 相关任务时,能释放 CPU 和 GPU 的算力,使其专注于自身核心任务,从而提升系统整体性能。综上,NPU 与 GPU 形成互补,为 AI 任务提供了更高效的能效解决方案,助力 AI PC 实现更优的系统整体性能和更长的续航时间。
NPU 架构概述
NPU 是一款专为加速神经网络计算设计的专用处理器,内置多个内存管理单元(MMU)、直接内存访问(DMA)引擎和乘加运算单元(MAC)—— 也被称为硬件加速模块,可执行神经网络的核心运算:乘加运算。NPU 中 MAC 单元的数量决定了其并行处理能力,直接影响其性能表现(性能以每秒万亿次运算,即TOPS 为单位)。了解影响TOPS 指标的各项参数,是深入理解NPU 性能的关键。
TOPS 的计算以每秒运算次数(OPS)为基础:一次乘法运算和一次累加运算各计为 1 次操作,因此每个 MAC 单元每时钟周期可完成 2 次操作。由此可得,OPS 等于 MAC 单元数量的 2 倍乘以其工作频率,最终将 OPS 除以 1 万亿,即可转换为 TOPS。
计算公式:TOPS = (2 × MAC 单元数量 × 工作频率) ÷ 1 万亿
MAC 单元数量
一次乘加运算包含两个核心操作:乘法运算,以及向累加器的加法运算。每个MAC 单元每时钟周期可执行一次乘法和一次加法,实际每时钟周期完成 2 次操作(即上述TOPS 公式中的系数 2)。不同 NPU 的 MAC 单元数量固定,且可根据架构设计支持不同精度的运算。
工作频率
频率指 NPU 及其 MAC 单元(包括 CPU、GPU)的时钟速度,即每秒时钟周期数,直接影响设备整体性能。频率越高,单位时间内可执行的运算越多,处理速度也就越快;但提升频率会导致功耗和发热量增加,可能对设备续航和用户体验产生负面影响。处理器的TOPS 值通常以峰值工作频率为基准标注。
内存与令牌生成
当数据集和模型参数规模超出片上内存容量时,NPU需依靠外部内存进行存储。NPU针对矩阵乘法做了优化,在 AI 和机器学习应用的初始令牌生成中表现尤为出色。根据功耗和延迟要求,后续的令牌处理和生成任务可由多个 CPU 核心与 NPU 协同完成。
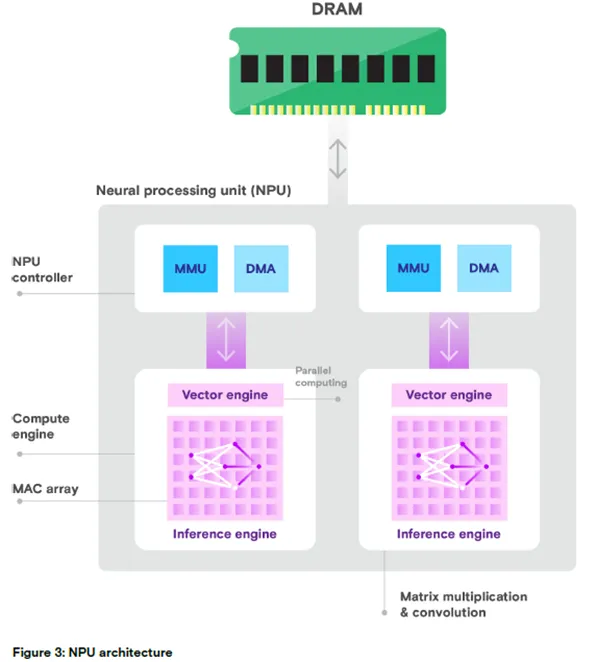
图 3:NPU 架构示意图
核心组件:DRAM、NPU 控制器、MMU、DMA、向量引擎、并行计算模块、计算引擎、MAC 阵列、推理引擎;
核心功能:矩阵乘法、卷积运算。
英特尔 ® 酷睿™ Ultra 9 处理器 185H 的 NPU 将 AI 能力直接集成到芯片中,兼容英特尔 ®OpenVINO™工具套件等标准化编程接口,采用多引擎架构,包含两个神经计算引擎:推理引擎和向量引擎。
向量引擎:用于 NPU 的并行计算,提升运算效率和性能;
推理引擎:执行矩阵乘法、卷积等高层级计算工作负载,减少数据移动,专注于固定功能运算。
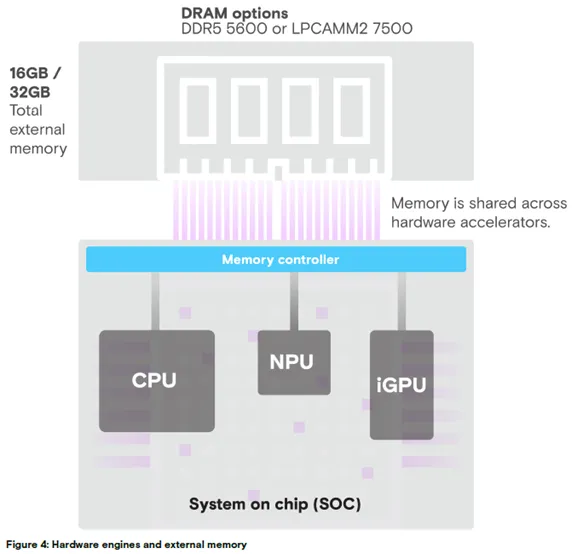
图 4:硬件引擎与外部内存架构
外部内存总容量:16GB/32GB;
内存类型:DDR5 5600 或 LPCAMM2 7500;
核心架构:片上系统(SOC)集成内存控制器,CPU、iGPU、NPU 共享外部内存。
在统一内存架构中,NPU、iGPU 与 CPU 共享系统内存,所有处理单元(CPU、GPU、NPU)共用主内存。该架构灵活性高,但当多个计算单元同时从内存读取数据时,有限的内存带宽易引发性能瓶颈。因此,设计支持更高带宽的内存系统,是实现异构计算平台最优系统性能的关键。