


1. 中国AI存储行业概览
1.1 AI基础设施概览
随着新一波AI发展浪潮来临,大模型的训练和推理需要进行海量数据处理和高并发计算,在过去3年内对包括计算、存储和网络在内的AI基础设施的需求显著增加,并将在未来保持这样的增长趋势。
根据部署模式的不同,AI基础设施可分为云端部署和本地部署两类。云端部署的AI基础设施由第三方云服务商运营,用户在云端按需租用计算、存储与网络资源,具有弹性高、部署快、前期投入低等特点,尤其在互联网、中小企业、初创公司中广泛应用。而本地部署的AI基础设施部署在企业自有或受控环境中,资源完全由企业掌控,更注重数据主权与系统可控性。随着AI在智能制造、金融机构、电信运营商及技术企业等领域的深入应用,有越来越多需要构建可控、高性能的AI基础设施的客户开始选择本地部署。
根据灼识咨询的资料,中国AI基础设施市场规模在2024年达到人民币2,176亿元,占全球AI基础设施市场约15%。预计市场规模将在2030年扩大至人民币10,991亿元,复合年增长率为31.0%,预测届时中国在全球市场的占比将上升至约25%。其中,预计本地部署AI基础设施市场规模将从2024年的人民币1,088亿元增长至2030年的人民币5,770亿元,复合年增长率为32.1%。
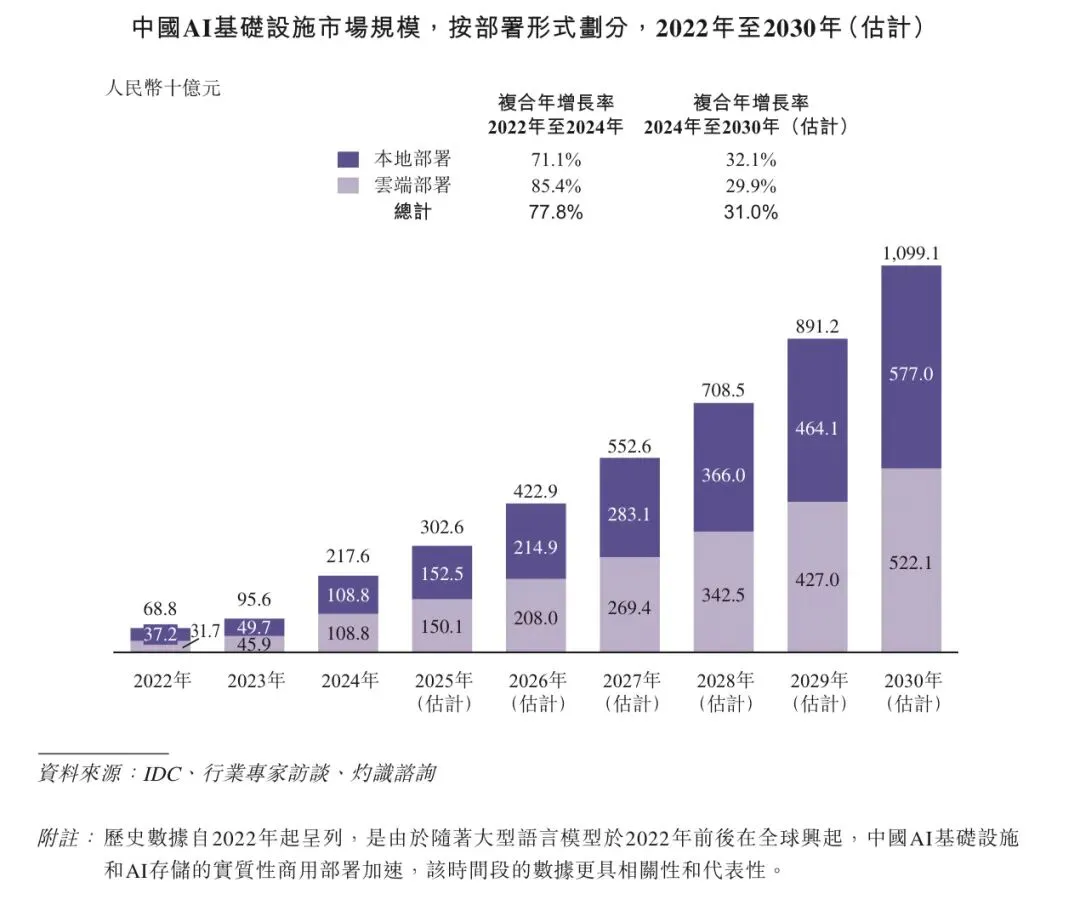
1.2 AI存储概览
AI的工作流程通常包括数据采集与清洗、模型训练以及推理应用等环节。在这一过程中,大量非结构化数据需要被持续收集、处理、计算与再存储,对数据流的稳定性与吞吐能力要求极高。存储系统贯穿了AI全生命周期的数据读写作业,其性能、可扩展性及安全性直接影响各类计算任务的效率、成本和数据治理水平。随着数据体量的迅速增长,高效、安全的存储系统已成为极其关键的AI基础设施组成。
此外,存储的客户黏性在整个IT系统中都是极高的,一旦部署特定存储系统,数据迁移成本包括数据搬迁、系统兼容性调整、业务中断风险以及运维流程重构等均非常高。这使得企业在选择存储系统时极为谨慎。
云计算时代的存储系统主要面向事务型与归档型负载,优化方向集中在容量扩展、成本控制和访问可靠性,在设计上偏向静态数据的长久保存与低频次访问。但在面对有高并发、多节点并行访问和低延迟特征的AI任务时,这样的传统架构易出现数据读写的瓶颈,并最终限制算力发挥。因此,AI的普及应用也要求存储系统的协同进化,对存储的需求从容量管理升级为智能数据底座,其重要性随AI应用规模的扩大而持续提升。
AI存储是指专为AI任务设计并优化的数据存储系统,旨在满足AI任务中对超大容量数据保存和高性能数据读写的要求。未来,企业内部长期积累的、高价值的专有数据,将成为其在AI浪潮中的核心竞争力。本地部署的AI存储能让企业在安全可控地管理数据,防止泄露与外部使用。此外,本地部署支持数据的持续回流与迭代,使企业能够构建自主的数据飞轮,形成自己的智能壁垒。这意味着,本地部署的AI存储不仅是数据主权的保障,更是长期竞争力的基石。
根据灼识咨询的资料,中国本地部署AI存储装机量在2024年达到13.4EB,并预计在2030年扩大至67.2EB,复合年增长率为30.9%。同时,中国本地部署AI存储市场规模在2024年达到人民币141亿元,并预计在2030年增长至人民币719亿元,复合年增长率为31.1%。
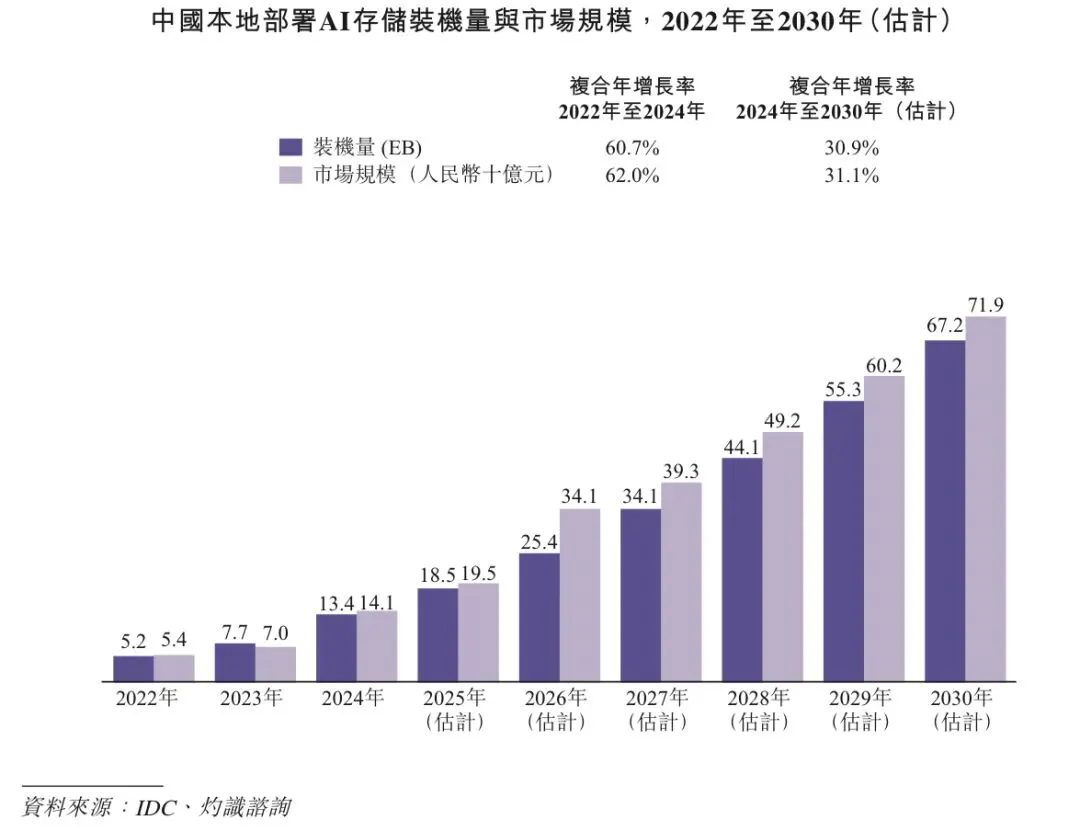
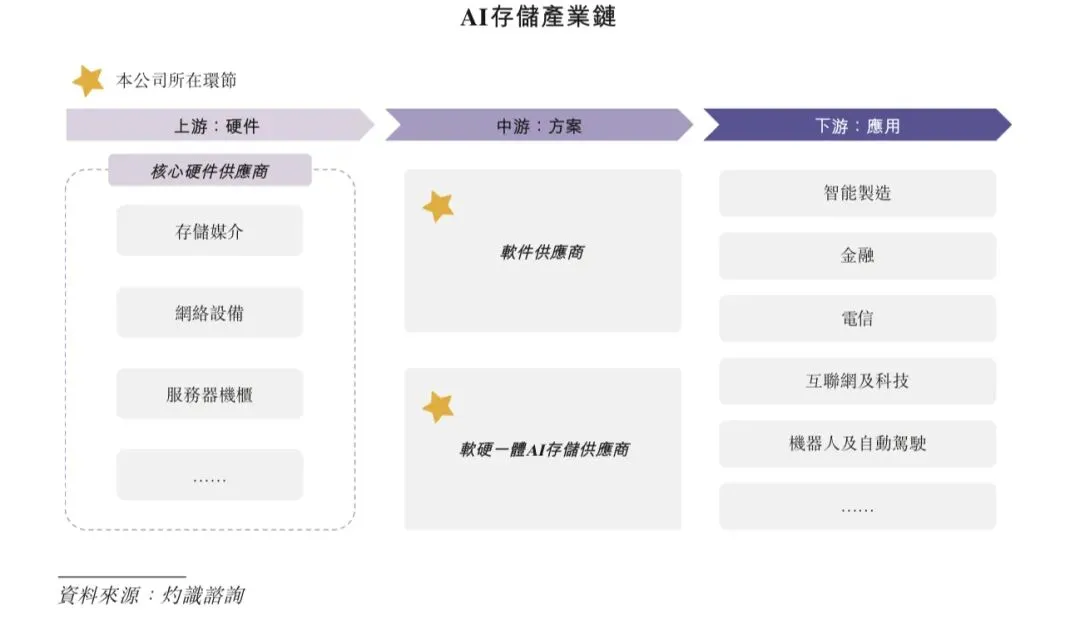
1.3 AI存储产业链
AI存储产业链主要包括上游基础硬件供应商、中游软件及软硬一体解决方案提供商和下游应用终端客户。
上游:AI存储所需的核心硬件,包括存储介质(HDD、SSD等)、网络设备、服务器机柜等。
中游:AI存储解决方案提供商,通过配套分布式文件系统、数据调度与缓存管理等底层系统软件,整合软硬件资源,提供解决方案,是产业链的价值核心。
下游:AI存储终端客户,涵盖智能制造、金融、电信、互联网与科技、机器人及自动驾驶等领域的企业。该等用户通常对数据主权、存储性能及可扩展性均具有较高要求。
2. 中国分布式AI存储行业概览
2.1 存储系统面向AI任务的挑战
训练侧的「I/O 墙」。目前主流的大模型参数规模普遍达到十亿以上,训练集群通常有上千乃至上万块AI芯片在同时工作。训练过程需要AI芯片不断读取海量数据、并定期保存模型快照(checkpoint),产生短时间内的巨大读写压力。同时,训练期间会有大量小文件被随机访问,显著增加存储系统的管理和响应负担。传统存储难以支撑这种高强度并发访问,容易导致AI芯片长时间闲置等待数据,整体训练效率大幅下降。
推理侧的「内存墙」。更长的上下文和更复杂的交互,是大模型的一大发展趋势。为了支持这些特性,大模型需要保留大量中间计算结果作为缓存,而缓存通常存放在AI芯片的显存中,来保证其能被高速读写。未来,可以预见这部分缓存的规模将迅速膨胀,远超AI芯片的显存容量,而传统存储系统不具备媲美缓存的高速读写性能,因此企业不得不为显存而继续采购昂贵的AI芯片,导致推理成本仍有极大的优化空间。
数据侧的「重力墙」。企业的数据往往分散在不同系统中,原始数据可能在大容量的存储系统中里,而训练又需要高读写性能的存储支撑。数据在这些系统之间迁移耗时长、成本高,还容易造成数据孤岛和版本混乱的问题。
2.2 分布式存储是AI存储的最佳解决方案
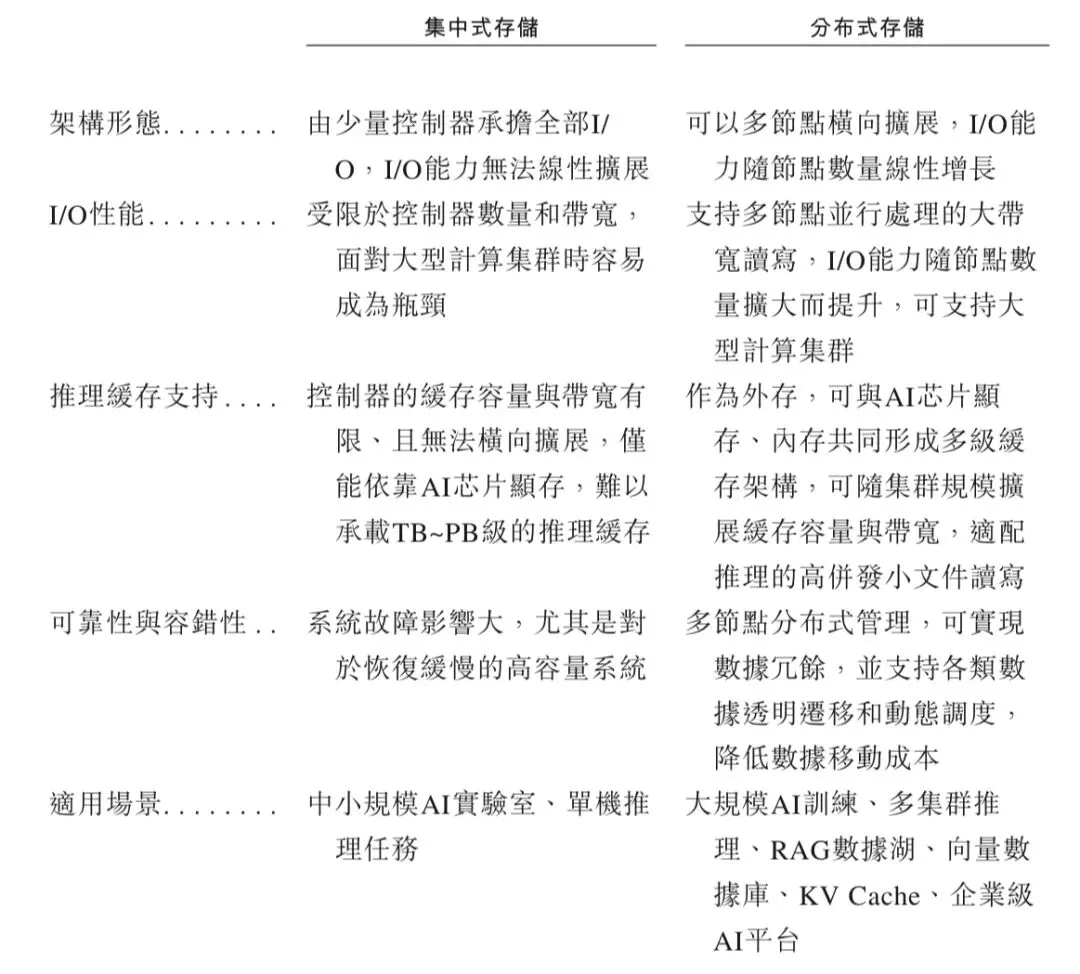
根据架构不同,AI存储可分为集中式存储与分布式存储两类。
集中式存储以单一存储节点为核心,数据管理与访问均在该节点上完成,架构相对简单,适用于数据规模较小、并发需求有限的AI场景,但难以满足日益增长的性能和扩展性要求。分布式AI存储则通过多个存储节点的协同工作,将数据分片存储在不同节点上,实现数据的并行读写与负载均衡。这样的设计既能提供大容量和高吞吐性能,也能通过副本冗余与容错机制,确保数据在高负载条件下的稳定性与可靠性。
因此,对于AI训练和推理任务,分布式存储已成为主流架构选择。下表总结了集中式与分布式存储的特点。
分布式AI存储架构以软件为中心,核心软件层负责元数据管理、数据分片、负载均衡与冗余保护,硬件资源则被统一抽象与调度,形成灵活可扩展的资源池,从而实现系统的横向扩展与高效交付。
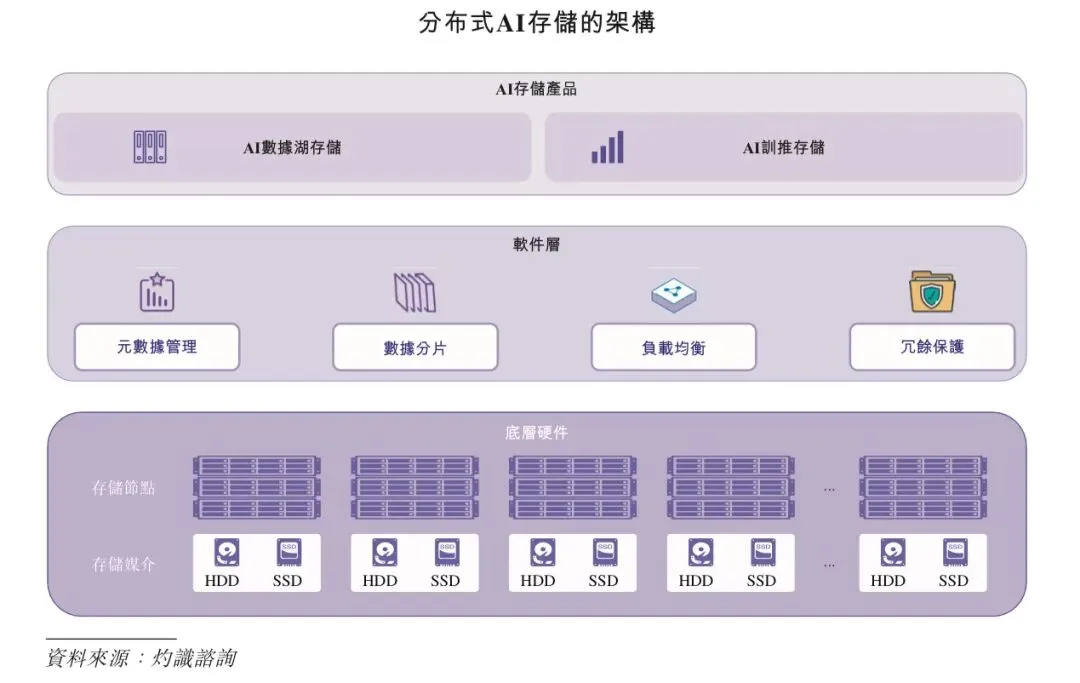
对于本地部署存储而言,实体部署架构直接可见,且与系统设计紧密耦合,因此区分集中式存储和分布式存储具有意义。相比之下,云端存储将底层基础设施对用户进行抽象化处理,且预设采用分布式架构,因此从用户或服务的角度来看,这种区分基本上无关重要。因此,本文中对分布式存储的讨论仅指本地部署存储。
2.3 分布式AI存储的产品分类
分布式AI存储的产品根据任务需求可分为两类:AI数据湖存储和AI训推存储。
2.3.1 AI 数据湖存储
AI数据湖存储主要面向AI生命周期中长期留存的温、冷数据,如训练样本归档、历史模型版本、日志数据及中间特征文件等。此类系统强调高容量密度、成本效率与数据可靠性,通过分层存储、压缩编码与副本冗余技术实现低成本的数据持久化。
其部署规模通常与整体数据资产规模直接挂钩。对于拥有海量数据资源的客户,AI数据湖存储构成其数据湖与知识库体系的底座,用于支撑长期的数据积累与治理。系统性能指标以容量利用率、存储成本、数据恢复可靠性等为核心。
2.3.2 AI 训推存储
AI训推存储聚焦AI计算阶段对热数据的高并发访问需求,是模型训练与推理性能释放的关键环节。其系统架构通常采用高带宽互联、分布式文件系统与数据分片机制,以实现高吞吐、低延迟、强一致性的访问体验。
与AI数据湖存储不同,AI训推存储是AI基础设施中与算力最紧密耦合的系统,其部署规模与AI算力规模高度相关,强调数据局部性与算存协同优化,常与AI集群的高速网络深度绑定,以减少数据传输瓶颈。
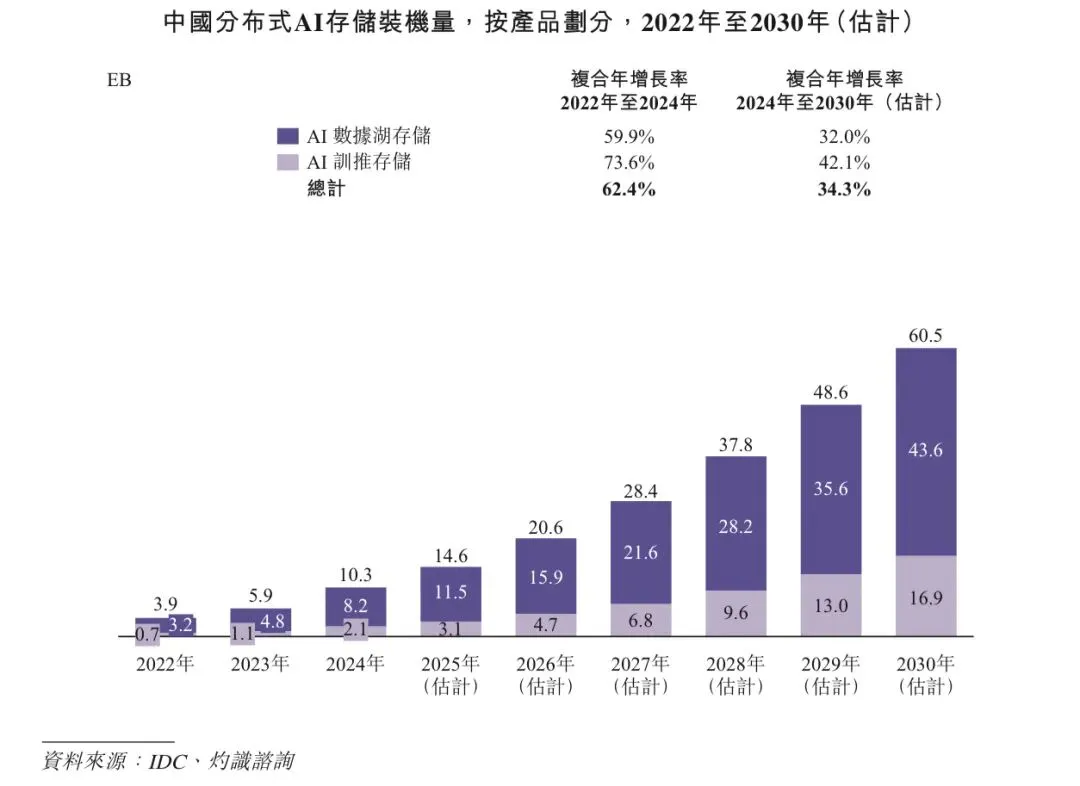
根据灼识咨询,中国分布式AI存储装机量在2024年达到10.3EB,并预计在2030年扩大至60.5EB,复合年增长率为34.3%。于2024 年,AI数据湖存储占市场的约80%,而AI训推存储占20%。预计以上占比将于2030年分别转为约72%及28%。
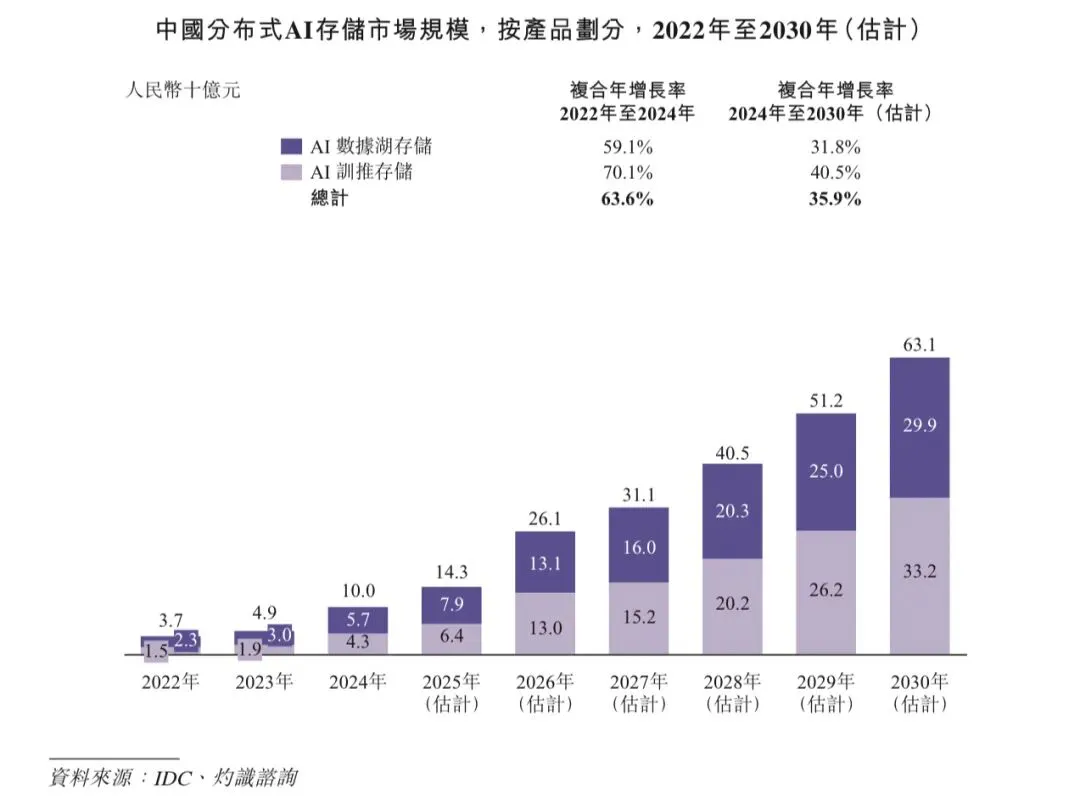
同时,根据同一资料来源,中国分布式AI存储市场按收入计在2024年达到人民币100亿元,并预计在2030年增长至人民币631亿元。
2.4 分布式AI存储的交付模式
分布式AI存储的交付模式分为两类:以软件为核心的一站式交付与软件交付。
以软件为核心的一站式交付通常交付软硬一体机,依托于软件的调度算法,配套提供经过预配置的硬件和网络,直接交付给客户。在分布式AI存储系统的质量控制和兼容性验证过程中,软硬件一体的交付模式凭借其软硬件的深度耦合及系统级优化能力,拥有更强的系统兼容性和稳定性,同时也减低了运维售后风险。
软件交付只提供存储系统的软件层(文件系统、对象存储、分布式调度等),客户根据存储系统要求采购硬件设备、并完成软硬件集成。IT集成能力和硬件维护能力较强、或对特定硬件供应商有较强需求的客户,通常会选择这种模式。在中国市场,许多大型互联网企业、科研机构以及国有企业出于合规性和国产化的考虑,通常需要单独采购特定的服务器、网络和算力等硬件资源,其后在其现有基础设施上部署分布式AI存储软件。
2.5 市场驱动因素
数据体量的爆炸式增长。随着AI模型参数规模和训练数据集的迅速扩大,全球数据总量呈指数级上升,尤其是图像、视频、语音等非结构化数据的占比显著提升。这一趋势对存储系统的容量、扩展性及成本控制提出更高要求,推动企业持续加大在高密度与弹性存储方面的投入。
AI 场景对存储容量及性能要求逐渐提高。在大模型训练、推理及生成类应用中,存储系统不仅要具备海量数据承载能力,更需支撑高并发访问与低延迟传输。分布式AI存储通过多节点并行与高速互联,实现数据的高效流动与性能线性扩展,成为满足AI场景计算密集型需求的关键基础设施。
企业用户对跨平台兼容与灵活架构的需求不断增加。随着多云与混合云环境普及,企业希望在不同计算平台之间灵活调用与迁移数据,分布式存储凭借开放式架构与模块化设计,可实现资源的弹性扩展与异构系统的无缝协同。
合规与数据主权推动本地部署存储的占比增加。在数据安全、隐私保护及行业监管要求日益严格的背景下,越来越多企业选择自建可控的分布式存储系统,以确保核心数据的安全可控与本地合规存储,从而进一步推动分布式AI存储市场的渗透与发展。
2.6 中国分布式AI存储市场竞争格局
中国分布式AI存储市场解决方案供应商大致上可分为独立厂商和非独立厂商。独立厂商是专注于提供存储系统解决方案的厂商,不依附于其既有的硬件组件、服务器或其他业务体系,因此具备很强的生态合作开放性与上游硬件供应链的灵活性。独立厂商可以避免单一硬件选择带来的供应链风险,能为客户选择最适配其需求与场景的组合。下表展示了分布式AI存储独立与非独立厂商的对比。

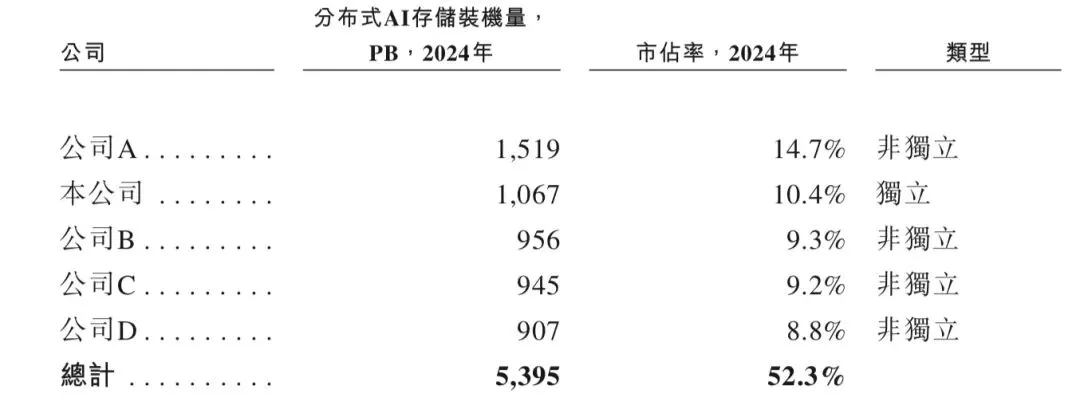
鉴于部分供应商(特别是独立供应商)的一大部分收入来自软件解决方案,而其他供应商的收入主要来自一站式解决方案,因此市场参与者的收入不能直接比较。然而,各供应商软件配置的装机量则有统一基准,可供比较。根据灼识咨询的资料,按2024 年装机量计,中国五大分布式AI存储解决方案供应商合计持有市场份额的52.3%。按2024年装机量计,星辰天合是中国第二大分布式AI存储解决方案供应商,也是最大独立解决方案供应商,市场份额为10.4%。

同时,星辰天合在分布式AI存储平台的多个关键维度上展现出行业领先的能力。在同业当中,星辰天合提供最全面的协议兼容性,是首个支持单个系统异构芯片的参与者,并推出首个在单一集群内支持块、对象及文件的分布式存储平台。
2.7 竞争壁垒
软件核心能力。分布式AI存储的核心竞争在于底层软件算法的成熟度,包括调度算法、元数据管理、数据布局与资源优化等,这些能力决定了系统在复杂AI任务下的数据流效率与资源利用率。
性能优化能力。在AI训练等高并发、大吞吐场景下,系统需保持稳定的读写性能与低延迟响应。厂商需具备深厚的系统优化能力,以保障算力集群的持续高效运行。
交付与服务能力。AI存储系统往往涉及数百个节点,需要跨机架、多集群甚至多数据中心部署、集成、测试验证,同时不同企业对数据主权和合规的要求以及部署环境也存在较大差异。分布式AI存储服务商必须具备端到端交付能力、可以实现方案的快速部署及一站式交付方案,从而提高客户满意度。
生态兼容性。分布式AI存储需与主流AI框架及多种计算平台深度集成,从而减少数据传输与等待的时间,简化开发者的对接流程,增强存储架构的拓展性,形成广泛的生态适配性,以提升客户使用的便利性与扩展性。
客户黏性与长期支持。行业客户对系统稳定性与长期运维依赖度高,厂商需具备规模化运维能力与持续技术支持能力,通过软件更新、服务延展与生态绑定形成高客户黏性。
3. 价格与成本趋势分析
分布式AI存储系统的成本结构主要包括储存媒介(SSD及HDD)、计算服务器、网络设备和系统软件。其中,SSD及HDD是对系统性能最关键的组件,也是存储硬件的主要部分,此乃由于其直接决定存储效能、可拓展性及整体资本支出。
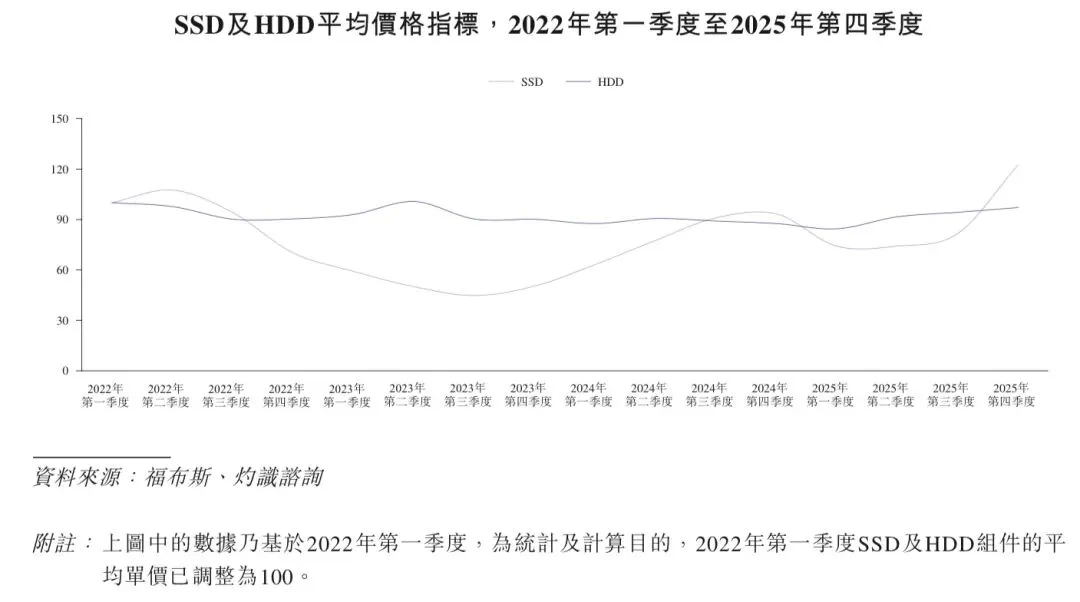
在历史期间,SSD的单价呈现明显的周期性波动,其特征是价格快速下跌后出现部分回升,导致其价格波动幅度相对较大。相较之下,HDD的单价走势则更为稳定,在较窄的范围内进行平缓且有限的调整,这反映其作为一种成熟且具有成本锚定作用的存储媒介的地位。特别是,SSD及HDD的价格在2025年下半年均出现反弹,其中SSD的涨幅更为显著。在供应收紧和需求复甦的推动下,预计该上升趋势将于2026年持续。下图展示SSD及HDD的历史价格走势。
【免责声明】本文摘自星辰天合港股招股书,版权归原作者所有,仅用于知识分享与交流,非商业用途!对文中观点判断均保持中立,若您认为文中来源标注与事实不符,若有涉及版权等请告知,将及时修订删除!查看更多报告请关注微信公众号