2025大模型API服务行业分析报告解读(33页附下载)
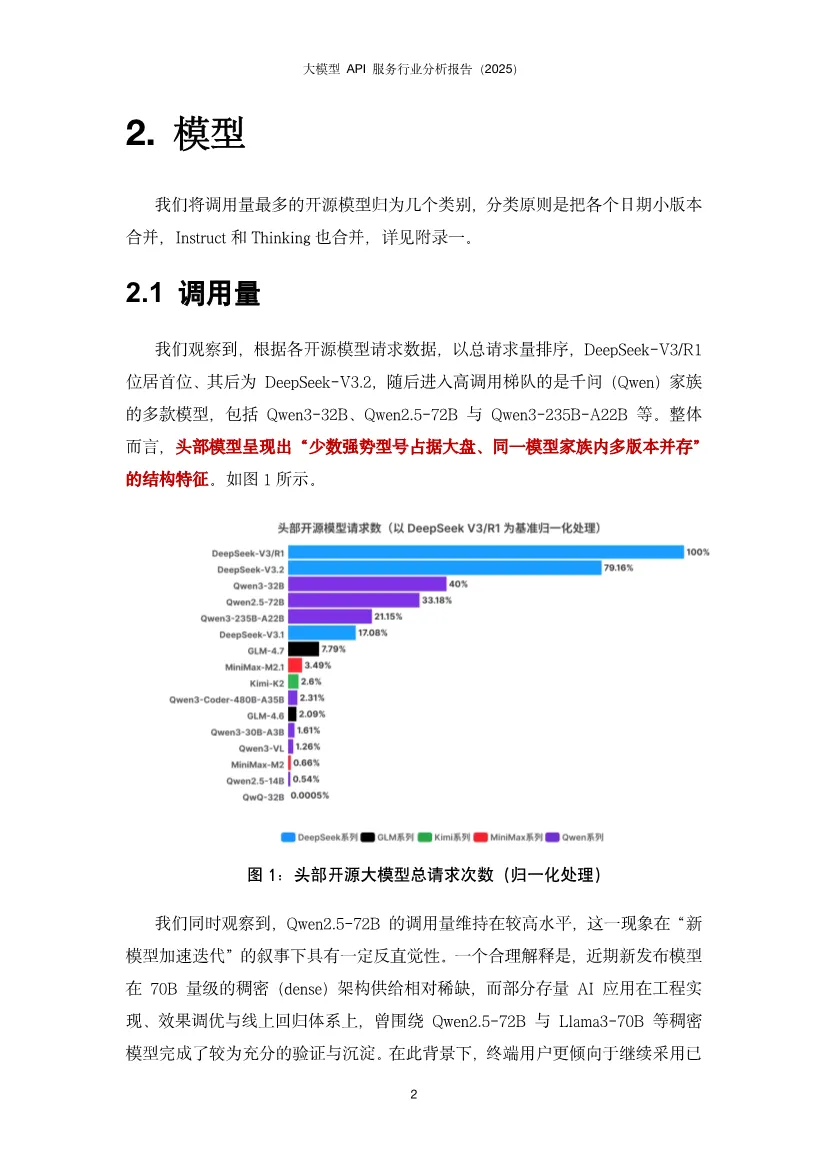
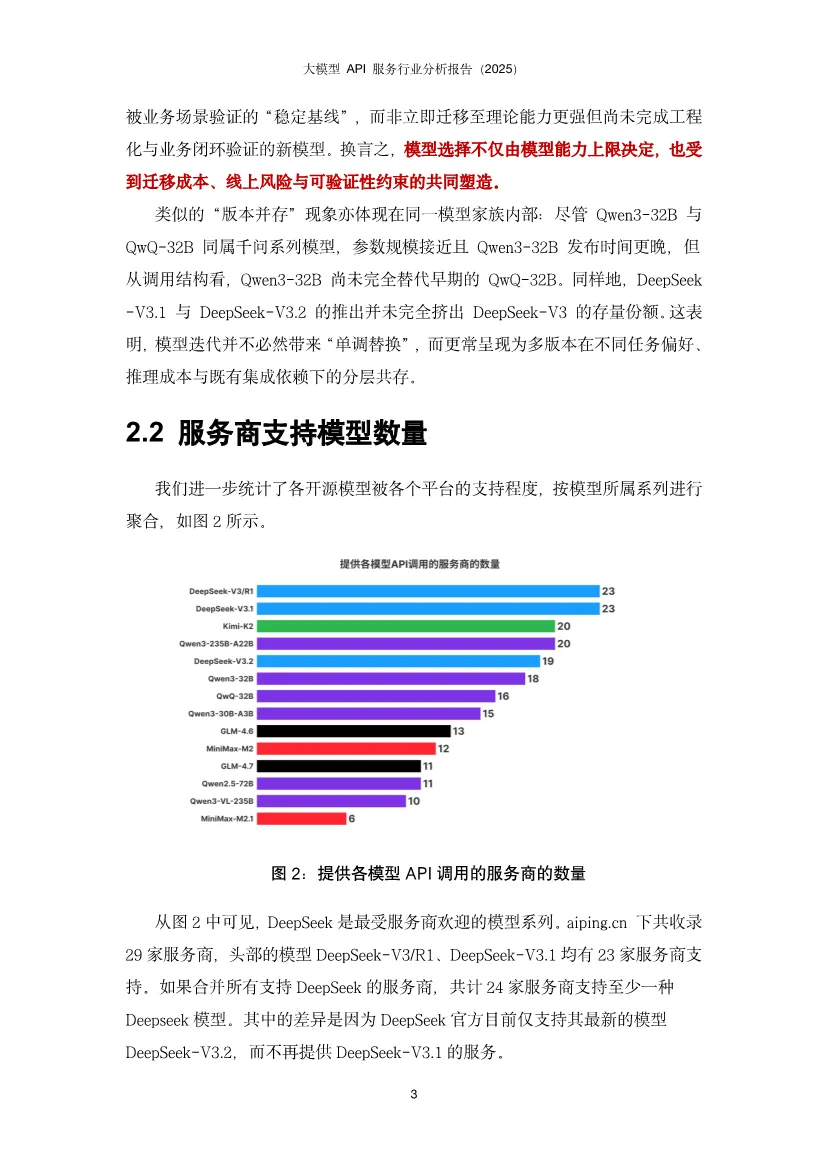
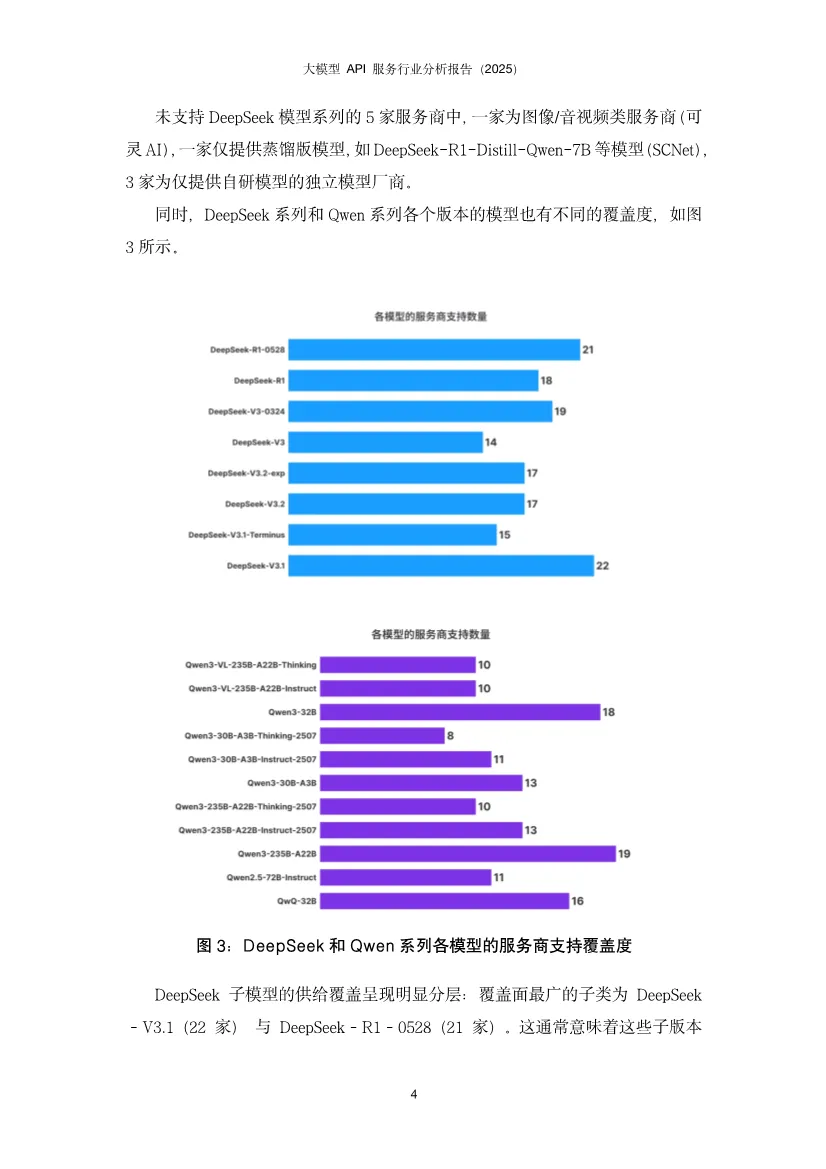
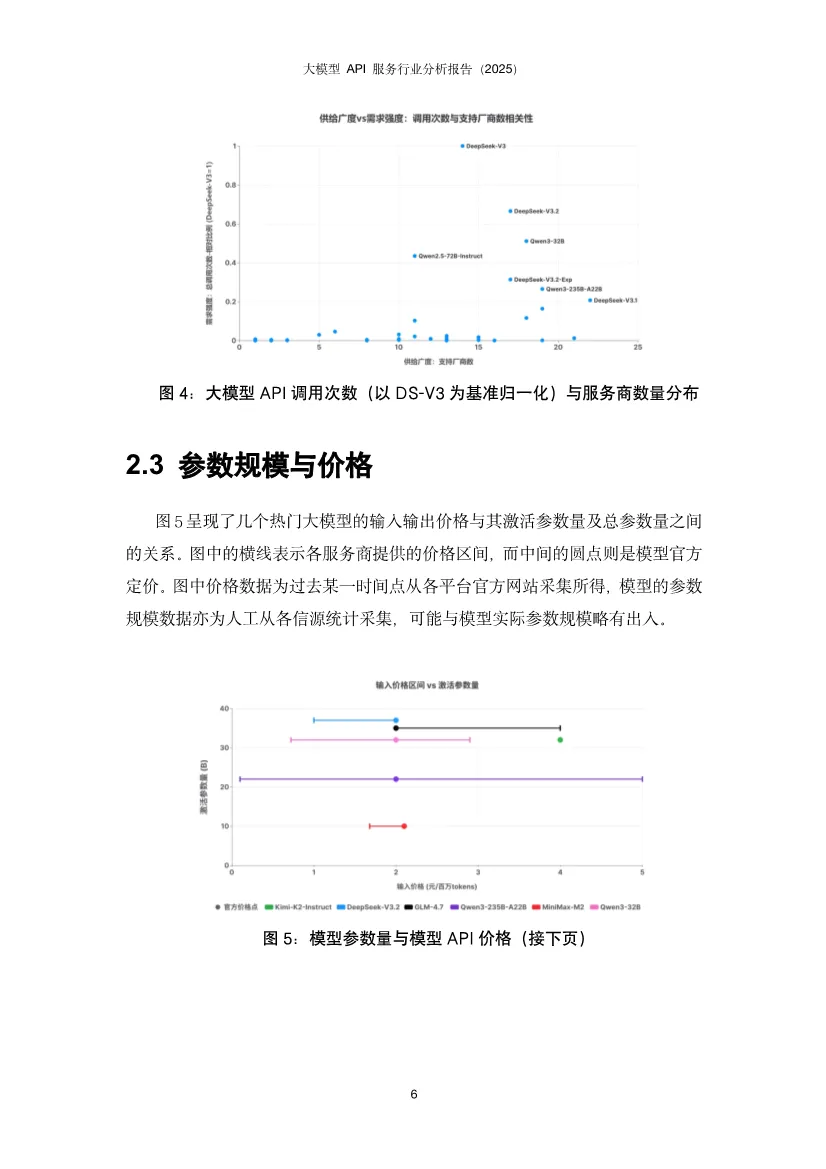
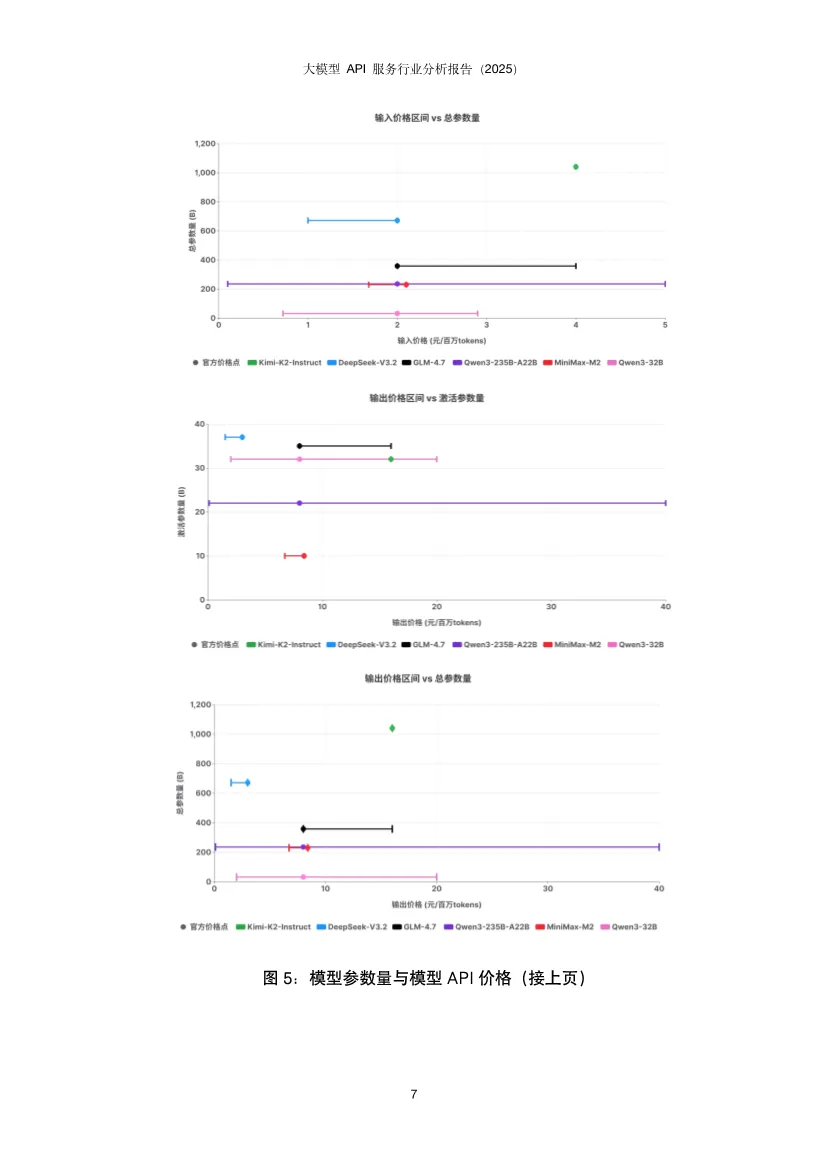
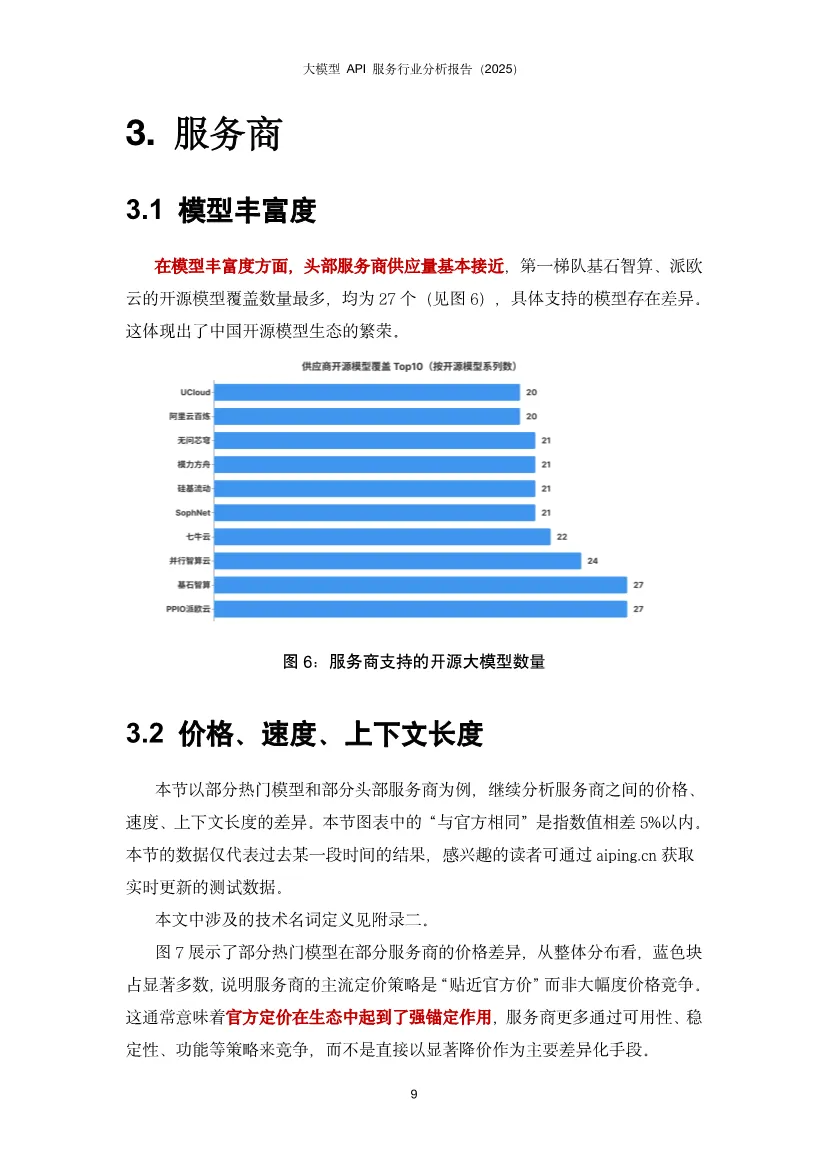
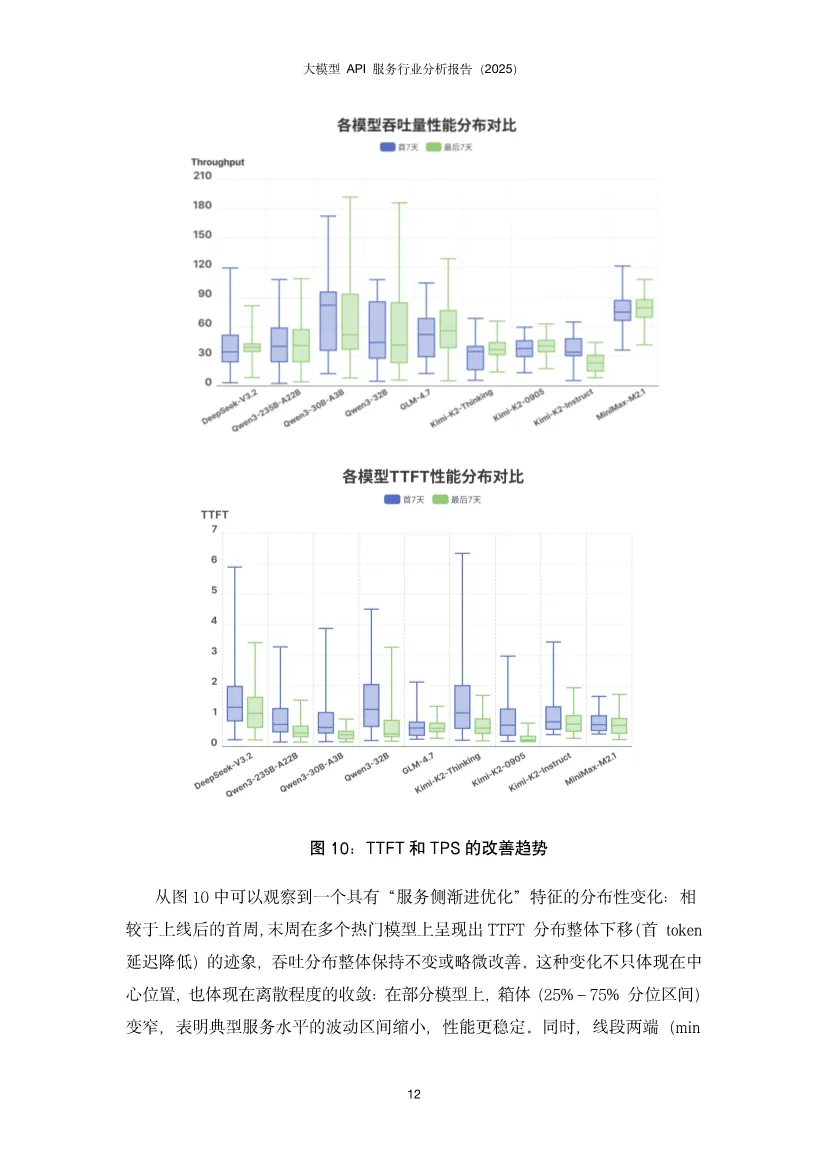
这份报告揭示了中国大模型API服务市场正从"野蛮生长"走向"精细运营"阶段,核心竞争点已从单纯的价格战转向性能、稳定性与智能调度的综合能力竞争。基于AI Ping平台2025年Q4真实调用数据,报告描绘出一幅供给端快速扩张、需求端深度分化、中间层智能路由价值凸显的生态全景图。开源模型调用呈现DeepSeek与Qwen双寡头格局。DeepSeek-V3/R1以绝对优势占据调用量首位,其后是DeepSeek-V3.2;Qwen家族的多款模型(Qwen3-32B、Qwen2.5-72B、Qwen3-235B-A22B等)紧随其后,形成"少数强势型号占大盘、同一家族多版本并存"的稳定结构。反直觉现象:Qwen2.5-72B等高调用量"老模型"并未被新版本快速替代。这源于企业应用的工程惯性——大量AI应用已围绕这些稠密架构完成验证、调优与线上回归体系,迁移成本高且风险大。用户更倾向于选择"经过业务验证的稳定基线",而非理论更强但未经工程化验证的新模型。这表明模型选择是能力、成本与可验证性的综合博弈,而非简单的性能追逐。服务商覆盖度:DeepSeek系列获得最广泛支持,29家服务商中有24家提供至少一种DeepSeek模型。Qwen系列呈现"基础模型覆盖最广、指令模型次之、思考版本最少"的梯度,揭示供给侧"易得性优先"与需求侧"任务效用导向"的结构性错位。价格并非核心变量。多数服务商定价紧贴官方,小幅调整,说明官方定价在生态中起强锚定作用。尽管如此,SophNet、SCNet等少数服务商采取激进低价策略,暗示价格战存在于长尾市场,而非主流战场。激活参数比总参数更贴近成本。MoE模型的总参数量反映"模型体量",但单次推理的实际计算量由激活参数决定。数据显示,即便激活参数量相近,价格区间仍可显著分化。这意味着定价机制尚未完全反映技术成本结构,为精细化运营留下空间。上下文长度是隐性门槛。多数服务商能对齐官方规格,但存在"窗口缩水"现象。对于RAG、长文档问答、代码库理解等场景,上下文从32K缩水到16K可能导致服务从"可用"直接降为"不可用"。这比性能波动的影响更致命,因为它直接决定了服务能否进入生产环境。性能异质性远超价格差异。在首字延迟(TTFT)和端到端完成速度上,第三方服务商与官方API差异显著,且官方渠道并不天然最优。大量数据显示第三方可系统性超越官方,同时也有部分服务商性能不及官方。这强化了评测与路由的核心价值:将"同模型不同服务商"的不确定性转化为可优化的决策问题。性能持续优化是行业常态。对比模型上线首周与末周数据,TTFT分布整体下移,箱体(25%-75%分位区间)变窄,极端慢启动情形减少。说明服务商在持续进行算力优化、调度改进与缓存策略调优。性能优化是持久战,而非一次性配置。接口质量分化严重。部分平台在失败场景缺乏明确错误返回,表现为长时间无响应后超时;不同平台失败率差异显著,高并发下失败率放大;错误返回规范性不一致,状态码与真实原因不匹配,信息泛化缺乏上下文。这些问题导致接口行为可预期性下降,直接影响大规模场景下的系统稳定性。慢响应高度集中。少数服务商在百万级调用量下慢响应比例低于0.3%,体现成熟基础设施优势;也有服务商在较小调用量下慢响应比例高达5%,指向资源冗余不足、冷启动频繁、调度链路长等问题。性能差异已成为用户用脚投票的核心依据。输入输出结构差异显著。新闻资讯类任务呈现"长输入、短输出"特征,依赖大量上下文检索;创意写作与商业服务为"长输入、长输出",成本与体验高度敏感;内容营销偏向"中输入、高输出";专业服务、知识翻译等则集中在"中短输入、中等输出",对延迟与稳定性更敏感。这揭示单一路由目标(只看价格或速度)无法覆盖所有场景,必须感知任务形态才能"提速降本不牺牲体验"。模型与任务存在稳定匹配结构。不同模型在不同任务类别上的使用占比呈现强烈集中,而非均匀分布。部分模型在知识/语言任务上占主导,另一些在创意写作、内容营销等风格化场景中占优。企业客户一旦验证某模型能稳定满足特定场景的质量、成本与交付约束,调用会固化到生产流程中,导致跨任务偏好差异更明显、模型间分工边界更清晰。路由策略偏好性能导向。调研显示,"性能优先"策略用户占默认路由的77.1%,说明推理速度是获客与留存的关键竞争要素。当模型服务同质化,延迟和吞吐更直接映射产品可用性与用户感知质量,成为用户主动选择的首要目标。智能路由将不确定性转化为优化空间。通过持续观测、动态选择与自动故障切换,智能路由在成本与性能上实现显著优化:- 成本降低36%:在约150万次请求样本中,智能路由总成本4577元,对比官方定价7355元,节省37.8%。- 吞吐提升90%:DeepSeek-V3.2模型在智能路由下平均TPS提升约90%,长输出(>1000 token)场景提升更显著。- 长尾优化:分位数角度观察,低速情况减少、高速情况增多,极端慢启动/低吞吐情形发生频率降低。路由策略需任务感知。基于输入输出长度将任务分为四象限:长入长出型需联合成本最小化;短入长出型优先优化输出价格;短入短出型以低延迟为主;长入短出型则聚焦输入价格与预填充性能。这种精细化策略比单一维度路由效果提升一个数量级。快速跟进者:SophNet、UCloud、七牛云、派欧云等能在模型发布当日完成上线,以"上架延迟"换"早期流量与开发者心智",抢占生态位。聚焦优化者:蓝耘将资源集中于DeepSeek-V3.2,商汤大装置模型覆盖有限但吞吐能力突出。这表明 "广覆盖"与"深优化"存在现实权衡 ,在算力与工程资源约束下,企业必须做出战略选择。缓存机制成为成本治理手段。阿里云百炼与MiniMax提供显式缓存控制能力,缓存命中费用约1-3折,使缓存不仅是性能优化,更是成本治理的重要方式。UCloud支持OpenAI、Anthropic、Google全协议覆盖,差异化定位明显。未来路径:分层供给——以广覆盖满足多样性,同时对少数高占比任务模型组合投入深度优化,并以可观测、可回滚的智能路由机制动态平衡。单纯的"多模型矩阵"增加运维复杂度,聚焦少数核心模型更易建立性能壁垒。1. 开源模型持续繁荣:DeepSeek引爆的开源浪潮将延续,更多非传统厂商(小米、美团等)加入,模型迭代速度加快。服务商上架范围更广,但供需错位问题将加剧,需求侧对Thinking、Instruct等专用版本需求更迫切。2. 性能竞争白热化:行业整体服务水平持续提升,TTFT降低、吞吐提高。但服务商分化加剧,极致优化者将获得获客留存优势。长上下文、高吞吐将成为差异化竞争点。3. 接口协议适配进入深水区:随着Agent工具调用、多模态模型普及,MCP、Skills等新协议涌现。服务商若不能快速全面适配,将面临生态淘汰。协议完整性、参数准确性、返回格式一致性将成为基础能力。报告最终揭示,大模型API服务市场已完成从"供给稀缺"到"供给过剩"的转变,核心矛盾从"有没有"转向"好不好用"。价格高度收敛使性能成为首要差异化维度,而官方渠道并非最优解的事实,让智能路由从"可选项"变为"必需品"。应用侧的场景分化为路由优化提供了丰富空间,任务感知的路由策略可带来30-40%的成本节约和近一倍的性能提升。服务商必须在"广覆盖"与"深优化"间做出战略抉择,而分层供给+智能路由是兼顾两者的可行路径。2026年的竞争将是交付质量的竞争:吞吐、尾延迟、稳定性、上下文能力与接口完整性。那些将AI深度融入基础设施、构建起可观测、可优化的路由治理能力的服务商,将在下一阶段的淘汰赛中胜出。对于应用开发者,依赖单一服务商已成过去式,多云智能路由将是标配能力。部分内容预览
 —
—
—



扫描识别下方二维码可自助开通会员
—

本篇资料已更新至情报猿资料分享平台
咨询会员服务、了解完整版资料获取方式
请加微信号“qbyuan888”
—
免责声明:以上报告均系本平台合作用户通过公开、合法渠道获得,报告版权归原撰写/发布机构所有, 如 涉 侵 权 , 请 联 系 删 除 ;资料为推荐阅读,仅供参考学习,如对内容存疑,请与原撰写/发布机构联系。





 如何快速获取相关资料?
如何快速获取相关资料?