


Google和Kaggle之前联合办了一个5天的AI Agent课程,本文章是第三天提供的文档《Context Engineering: Sessions, Memory》的内容梳理和总结。
本文并非单纯的翻译,而是在个人理解的基础上归纳总结。
获取原文在我的公众号回复:Google Agent Course CE
由于本文内容主要涉及开发,就不再进行分视角的总结。只从开发的角度精炼了一份短的文章,需要的话,公众号回复:Google Agent Course CE Summary
同时,本文内容较长,公众号查看可能不是很方便,想要获取原文PDF可以评论区回复:Google Agent Course CE Doc
Agent的核心—上下文工程
在第一天的文章中我们总结过Agent构成的四要素,其中LLM(大语言模型) 提供了核心的推理能力(大脑),Tools(工具) 赋予了行动的手段(手),Process(流程) 定义了任务的执行逻辑(神经系统)。
读完Google这份Agent白皮书,我才理解了什么是Agent
第二天的文档中,我们深入了Tools的相关内容,学习了如何构建一个恰当的工具,以及MCP协议的相关内容。
到目前我们对Agent已经有了一个“轮廓”上的了解了——一个借助工具和流程去实现自己想法的大脑。在今天的这份文档中,我们将要深入Agent的核心,了解Agent开发中最核心,最决定成败的工作——Context Engineering(上下文工程)。
在白皮书的第一天中,我们总结了AI Agent开发圣经,第一条就是LLM的本质是一个概率预测模型。现在我们更进一步为什么是概率模型?
从架构演进来看,当前 LLM(如 Gemini、GPT)本质上是由 Transformer 架构中的 Decoder(解码器)组件演变而来的。
Decoder 的核心机制是自回归。它的工作方式极其单纯:它根据你当前给它的输入,然后计算概率,预测出下一个字是什么。输完这个字,它的任务就结束了。
形象的来说,LLM是一个编故事大王,他会根据你所提供的背景信息,去编出一个合理的故事。
因此LLM本质上是无状态的。
除了预训练数据外,模型对世界的认知、对用户的了解、以及对当前任务的推理,完全受限于你在单次 API 调用中提供的“上下文窗口”(Context Window)。这就引出了 Agent 开发中最核心、也最复杂的工作——Context Engineering(上下文工程)。
从上层来看,当前的Prompt,MCP,以及最近新出的Skill和我们今天探讨的上下文工程,本质都是帮助LLM构建出更恰当的上下文。
上下文工程一种动态的系统工程,它即是在第一篇文章中所提到的“上下文窗口精选”(Context Window Curation):
目标:在每一次对话的毫秒级瞬间,精准地计算出模型当前需要什么信息——既不能太少导致幻觉,也不能太多导致“上下文腐烂”(Context Rot)或成本失控。
内容:它动态组装了多个复杂的组件,不仅包含即时的对话历史,还融合了长短期记忆(Memory)、外部知识(RAG)、以及工具的输出结果。
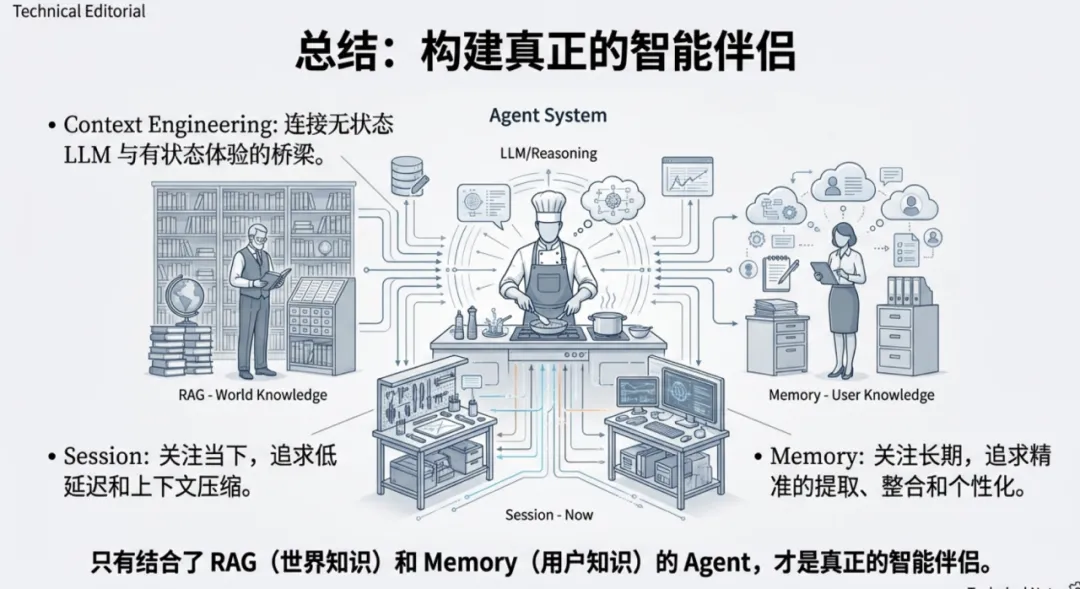
价值:如果说 RAG 让 Agent 成为了世界知识的专家,那么 Context Engineering(特别是其中的 Memory 机制)则让 Agent 成为了懂你的专家。
在这篇文章中,我们将探讨如何通过会话(Sessions)与记忆(Memory)的精细化工程,打破 LLM 的无状态限制,构建出真正具备持久记忆与个性化能力的智能 Agent。
一、
上下文工程
为了让大型语言模型(LLMs)能够记忆、学习并进行个性化交互,开发人员必须在其上下文窗口内动态整合和管理信息——这一过程被称为上下文工程。
1.1
从Prompt Engineering到Context Engineering
我们需要区分Prompt Engineering(提示词工程)和Context Engineering(上下文工程)这两个核心的概念,虽然这两个都是对上下文进行操作,但其关注的内容是有所区别的:
提示词工程:侧重于精心设计优化且通常静态的系统指令。
上下文工程:关注的是整个动态数据内容的构建。它根据用户身份、对话历史和外部数据,战略性地选择、摘要和注入信息。
正如白皮书中所做的精彩比喻:上下文工程就像是顶级大厨的助手。如果只给大厨(LLM)一张菜谱(Prompt),在有限的时间内他或许只能做出勉强及格的菜肴;但如果有了助手能精准地准备好所有高质量的食材、切好的配料和趁手的工具(Context),那么大厨就能稳定地输出米其林级别的体验。
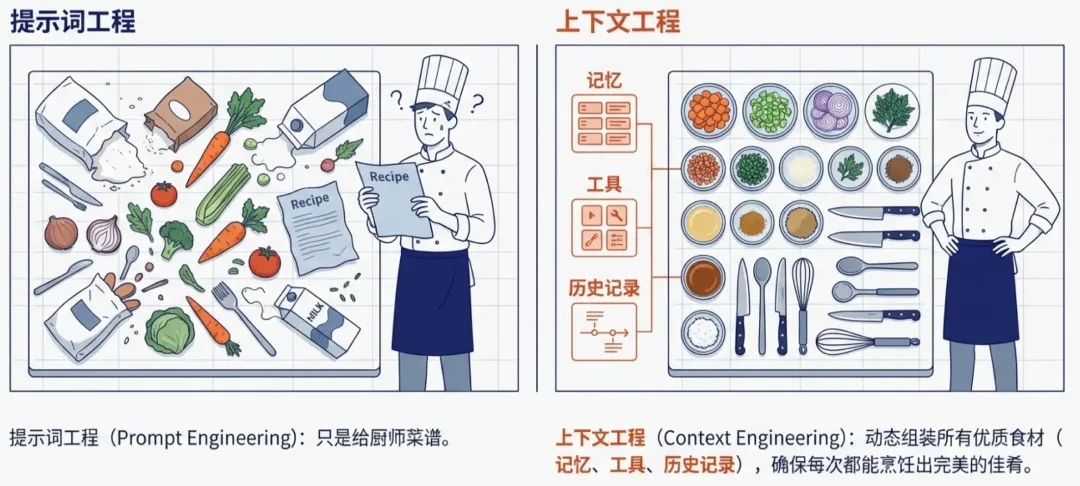
其实国内和国外的ChatBox(Gemini、GPT、DeepSeek、元宝、豆包)的一个主要的差距就在上下文工程,Gemini和GPT目前都有了跨对话记忆的能力,而国内的这几家到现在都还没有跟进。
1.2
Context的构成
一个经过上下文工程处理的Context不仅仅是一段对话记录,它应该包含三类信息:
1. 引导推理的上下文:定义了智能体的基本推理模式和可用行动
系统指令:定义智能体角色、能力和约束条件的高级指示。
工具定义:智能体可用于与外部世界交互的API或函数的模式。
少样本示例:通过上下文学习引导模型推理过程的精选示例。
2. 证据与事实数据:是智能体推理的依据
长期记忆:跨多个会话收集的关于用户或主题的持久知识。
外部知识:从数据库或文献中检索到的信息,通常使用检索增强生成(RAG)。
工具输出:工具返回的数据或结果。
子智能体输出:由被委派执行特定子任务的专业智能体返回的结论或结果。
其他:与用户或会话相关联的非文本数据(例如,文件、图像)。
3. 即时对话信息:是当前会话的锚点
对话历史:当前交互之前的对话内容。
状态/暂存区:智能体用于即时推理过程的临时、进行中的信息或计算。
用户提示词:当前需要立即解决的查询。
有效的推理通常依赖于上下文学习(即大语言模型从提示中的演示示例中学习如何执行任务的过程)。当智能体使用与当前任务相关的少样本示例而非依赖硬编码示例时,上下文学习可能会更有效。
1.3
运行生命周期
上述上下文的内容并不是一次性设置的,而是在每一轮对话中都发生的连续循环,如下图:
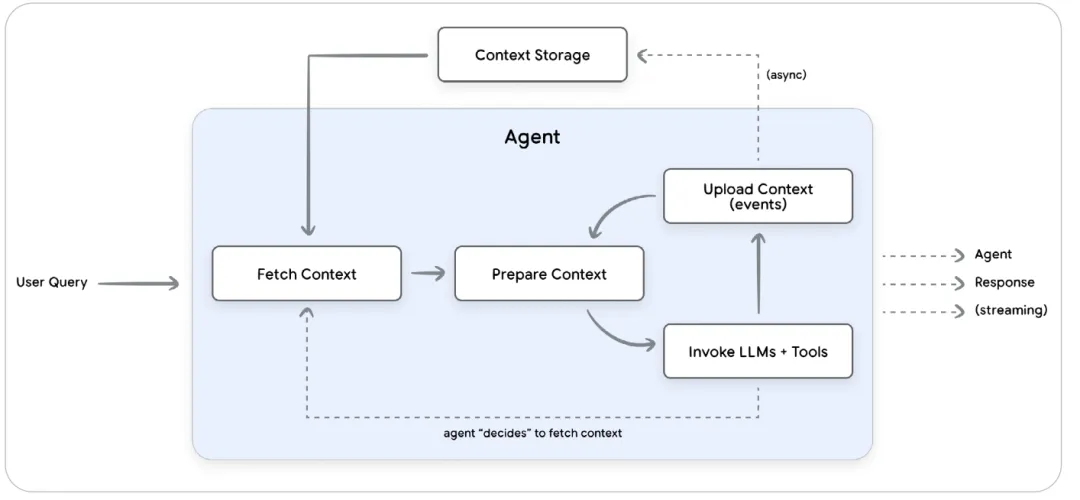
1. Fetch Context(获取上下文):根据用户查询(User Query),检索相关的记忆、RAG 文档和近期事件。
2. Prepare Context(准备上下文):是整个系统中的关键。这是一个阻塞式(Blocking)过程,动态构建最终发送给 LLM 的 Prompt。Agent 必须等上下文准备好才能思考。
3. Invoke LLM & Tools(调用模型与工具):执行推理循环,直到生成最终回复。
1.4
核心挑战
随着对话的进行或Agent的使用,历史记录会不断的增长,这就导致我们将要面临上下文工程中的两个核心问题:
1. 成本与延迟:更长的内容意味着更多的Token以及更高的费用和更慢的响应速度。
2. 上下文腐烂(Context Rot):随着上下文变长,模型关注关键信息的能力会下降(注意力分散)。
? 注意力机制的稀释效应
Transformer 的核心机制是自注意力(Self-Attention)。简单来说,模型在生成每一个 Token 时,都会计算当前 Token 与上下文中所有其他 Token 的相关性权重。这个权重是通过 Softmax 函数进行归一化的,所有权重的和必须等于 1。
原理:当上下文长度 N 增加时,Softmax 的分母变大。如果上下文中充斥着大量无关的噪音,注意力分数就会不可避免地被分散到这些无关 Token 上。
后果:关键内容的权重被稀释。正如白皮书指出,随着 Token 数量增加,上下文中的噪音会导致性能下降。这不仅是成本问题,更是信噪比下降导致的推理精度问题。
自回归的误差累积
Day 1 的文档明确指出,LLM 本质上是一个“最大化奖励函数的概率预测模型”。
原理:Decoder-Only 架构是自回归的,即每一个输出都是基于之前的输出生成的。
后果:白皮书提到,长上下文会导致 "autoregressive errors"(自回归误差)。当上下文过长且包含干扰信息时,模型在中间步骤产生的微小幻觉或错误注意力,会在后续的推理链条中被放大,导致模型最终迷失在无关细节中。
后续会出一篇文章详细讲解注意力机制的。
因此,上下文工程的一个核心内容就是压缩,通过一定的策略在保留关键信息的同时控制Token数量。
1.5
上下文的两大支柱
在整个生命周期中有两个基本组件:
Session(会话):与智能体进行的整个对话的容器,包含按时间顺序排列的对话历史和智能体的工作记忆。
Memory(记忆):长期持久性机制,用于跨多个会话捕获和整合关键信息,为LLM智能体提供连续且个性化的体验。
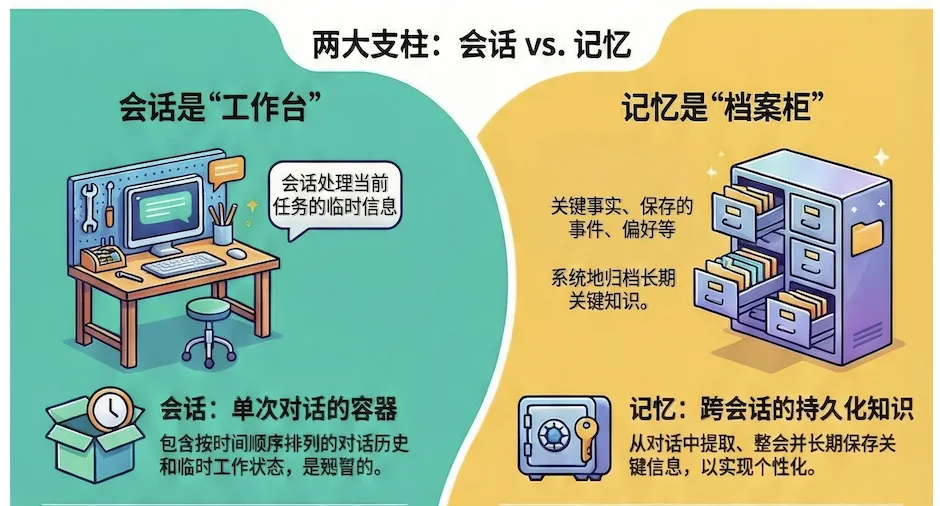
一个形象的比喻如上图所示:
你可以将会话视为你用于特定项目的工作台或书桌。当你工作时,上面摆满了所有必要的工具、笔记和参考资料。所有东西都触手可及,但同时也是临时的,且专用于手头的任务。
项目完成后,你不能把整个杂乱的办公桌一股脑儿塞进储藏室。相反,你要开始创建“记忆”的过程,这就好比整理一个井然有序的文件柜。你会审视办公桌上的材料,丢弃草稿和多余的笔记,只将那些最重要的、最终定稿的文件归档到贴有标签的文件夹中。
这个类比直接反映了高效智能体的运作方式:会话充当单次对话的临时工作台,而智能体的记忆则是精心整理的文件柜,使其能够在未来的交互中回忆起关键信息。
二、
Session
2.1
Session的本质:状态容器
从系统设计的角度看,Session 是单个用户与 Agent 进行连续交互的隔离容器。
1. 定义:在LLM交互中Session 是一个按时间顺序排列的事件日志加上当前的运行状态。它是临时的、高保真的,包含了未被压缩的原始交互细节。
2. 内容
用户输入
智能体响应
工具调用 or 工具输出
3. 数据结构
Events:不可变的追加日志
定义:Events 是按时间顺序排列的交互记录
操作特性:Append-only。一旦写入,原则上不可修改(除非进行压缩/截断操作)。随着对话轮数增加,Events 列表会线性增长。
数据形态:类似于 Gemini API 中的 List[Content] 对象。每个 Event 包含 role(User/Model/Tool)和 parts(文本/多模态数据)。
典型内容:用户输入、模型回复、工具调用请求 (Tool Call)、工具执行结果 (Tool Output)。
映射:通常被直接序列化为 LLM 的 Conversation History。Agent 框架(如 ADK)负责将内部的 Event 对象转化为模型特定的格式(如 Gemini 的 Content 对象),直接填入 Context Window。
State:可变的结构化快照
定义:State 是 Agent 的暂存区。
操作特性:Mutable。它在对话过程中会被反复读取、修改、覆盖。它不记录历史轨迹,只保存当前的值。
数据形态:通常是一个结构化的字典 (Dictionary) 或对象 (Object)。
典型内容:购物车清单、当前填写的表单字段、循环计数器、API 调用的中间变量(如 {"items": ["apple"], "status": "active"})。
映射:通常需要显式注入。State 数据不会自动出现在对话历史中,开发者必须将其序列化为字符串(如 JSON 字符串),并注入到 System Instructions 或作为 Tool 的上下文参数,以便模型感知当前的业务状态。
使用 Events 当你需要记录发生了什么(叙事性)、维护多轮对话的上下文,利用 LLM 的 In-Context Learning 能力理解前文引用、提供审计日志;
使用 State 当你需要记录现在是什么(事实性)、存储结构化的业务数据(如 User ID, Order ID)、在工具调用之间传递参数,或者进行复杂的控制流跳转(如 LangGraph 的条件边)。
2.2
框架层的抽象
虽然核心思想相似,但不同的智能体框架以不同的方式实现会话、事件和状态。智能体框架负责为大型语言模型(LLMs)维护对话历史和状态,利用此上下文构建大型语言模型请求,并解析和存储大型语言模型的响应。
内部与外部表示:开发者操作的是框架内部的标准化对象(如 ADK Event),而 LLM 需要的是特定的 API 格式(如 Gemini 的 role 和 parts)。框架负责在运行时将内部 Session 对象序列化(Serialize)为 LLM 可理解的 Context Payload。
解耦价值:这种抽象层防止了 Agent 逻辑与特定模型供应商的 API 耦合(Vendor Lock-in),实现了模型的可替换性。
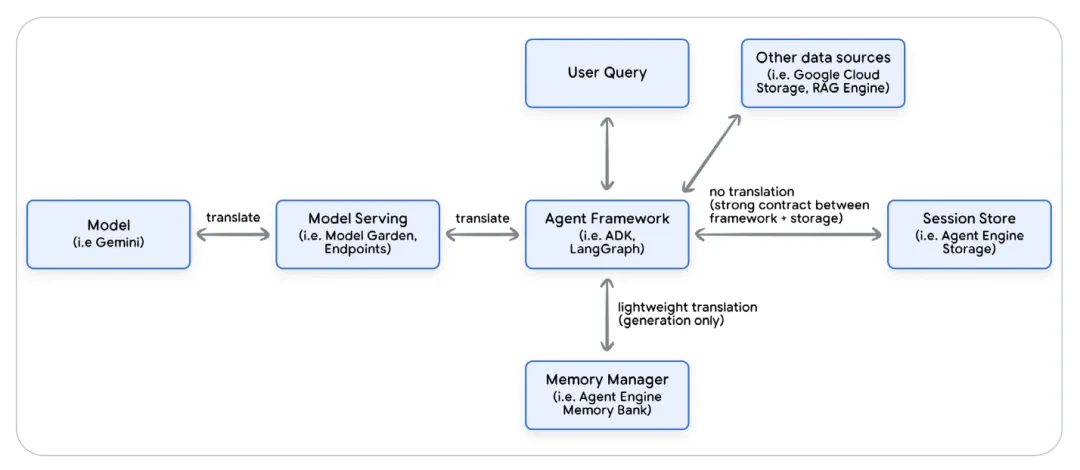
框架差异
ADK 使用显式的 Session 对象,该对象包含一个 Event 对象列表和一个单独的状态对象。Session就像一个文件柜,其中一个文件夹用于存储对话历史(事件),另一个用于存储工作记忆(状态)。
VS
LangGraph没有正式的“会话”对象。相反,状态就是会话。这个包罗万象的状态对象包含对话历史(作为Message对象列表)和所有其他工作数据。与传统会话的仅追加日志不同,LangGraph的状态是可变的。它可以被转换,并且像历史压缩这样的策略可以改变记录。这对于管理长对话和令牌限制非常有用。
这类的框架差异,在不同框架进行交互时会产生问题,其解决方案我们放在多智能体系统中进行介绍。
2.3
多智能体系统
在分布式 Agent 系统中,Session 管理的复杂度呈指数级上升,核心矛盾在于共享状态与隔离性的权衡。白皮书提出了两种主要模式:
1. 共享/统一历史
机制:所有 Agent(Root Agent 和 Sub-agents)读写同一个全局 Session Log。
适用场景:紧耦合的协作任务。例如,一个 Agent 的输出直接作为下一个 Agent 的输入。
实现细节:即使是子 Agent 的中间推理步骤,也会被追加到主日志中,形成单一事实来源。
2. 独立/隔离历史
机制:每个 Agent 维护自己私有的 Session Log。交互通过显式的消息传递(Message Passing)进行,即 A2A (Agent-to-Agent) Protocol。
适用场景:松耦合系统。Agent 之间互为“黑盒”,只关心输入输出,不关心彼此的内部推理过程(CoT)。
挑战:
不同框架(如 LangGraph Agent 调用 ADK Agent)之间的 Session 对象是不兼容的。因为 Session 存储通常与框架内部的 Schema 强绑定。
解决方案:Session Store 不适合做跨框架的数据交换。真正的互操作性应通过Memory Layer(架构无关的数据层)来实现,而非强行转换 Session 格式。(? 即将其Session内容抽取出来,存储到公用的存储中间件中这使其能够作为通用的公共数据层。这种模式允许异构智能体通过共享公共认知资源来实现真正的协作智能,而无需定制翻译器。)
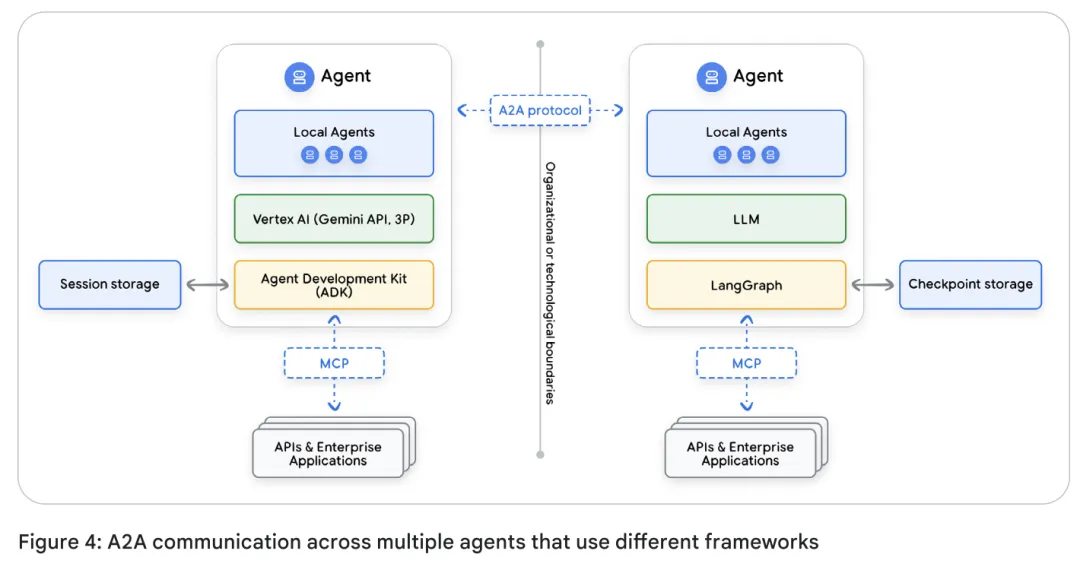
2.4
生产级建议
1. 将智能体迁移到生产环境时,其会话管理系统必须从简单的日志系统发展为强大的企业级服务。
2. 关键三个关键领域:安全性和隐私性、数据完整性以及性能。
安全性和隐私性
严格隔离是最关键的安全原则。
一个会话归单个用户所有,系统必须实施严格的隔离,以确保一个用户永远无法访问另一个用户的会话数据(即通过访问控制列表)。对会话存储的每个请求都必须针对会话所有者进行身份验证和授权。
处理个人身份信息(PII)的最佳实践是在会话数据写入存储之前对其进行脱敏。这是一项基本的安全措施,可大幅降低潜在数据泄露的风险和“影响范围”。
数据完整性与生命周期管理
一个生产系统需要明确的规则来规定会话数据如何随时间存储和维护。会话不应永久存在。你可以实施生存时间(TTL)策略来自动删除非活动会话,以管理存储成本并减少数据管理开销。
明确数据保留策略,规定会话应保存多长时间后进行归档或永久删除。
系统必须确保操作以确定的顺序追加到会话历史中。保持事件正确的时间顺序对会话日志的完整性至关重要。
性能与可扩展性
为减少延迟,降低传输数据的大小至关重要。一项关键优化措施是在将对话历史发送给智能体之前对其进行筛选或压缩。例如,可以移除那些陈旧、不相关且对当前对话状态不再需要的函数调用输出。
2.5
核心算法:上下文压缩
在简单架构中,会话是用户与智能体之间对话的不可变日志。然而,随着对话规模的扩大,对话的令牌使用量会增加。现代大型语言模型能够处理长上下文,但仍存在局限性,尤其是对于延迟敏感型应用。此时会影响的问题有:
上下文窗口限制:每个LLM都有一次可以处理的最大文本量(上下文窗口)。如果对话历史超过此限制,API调用将失败。
API成本:大多数LLM提供商根据您发送和接收的令牌数量收费。较短的历史记录意味着令牌更少,每轮成本更低。
延迟:向模型发送更多文本需要更长的处理时间,导致用户的响应速度变慢。压缩可使智能体保持快速响应的感觉。
质量:随着标记数量的增加,由于上下文中的额外噪声和自回归误差,性能可能会下降。
与一个优秀的智能体长时间的对话,就好比一位精明的旅行者为长途旅行收拾行李箱。一趟成功的旅行不在于你能携带多少东西,而在于只携带需要的东西。
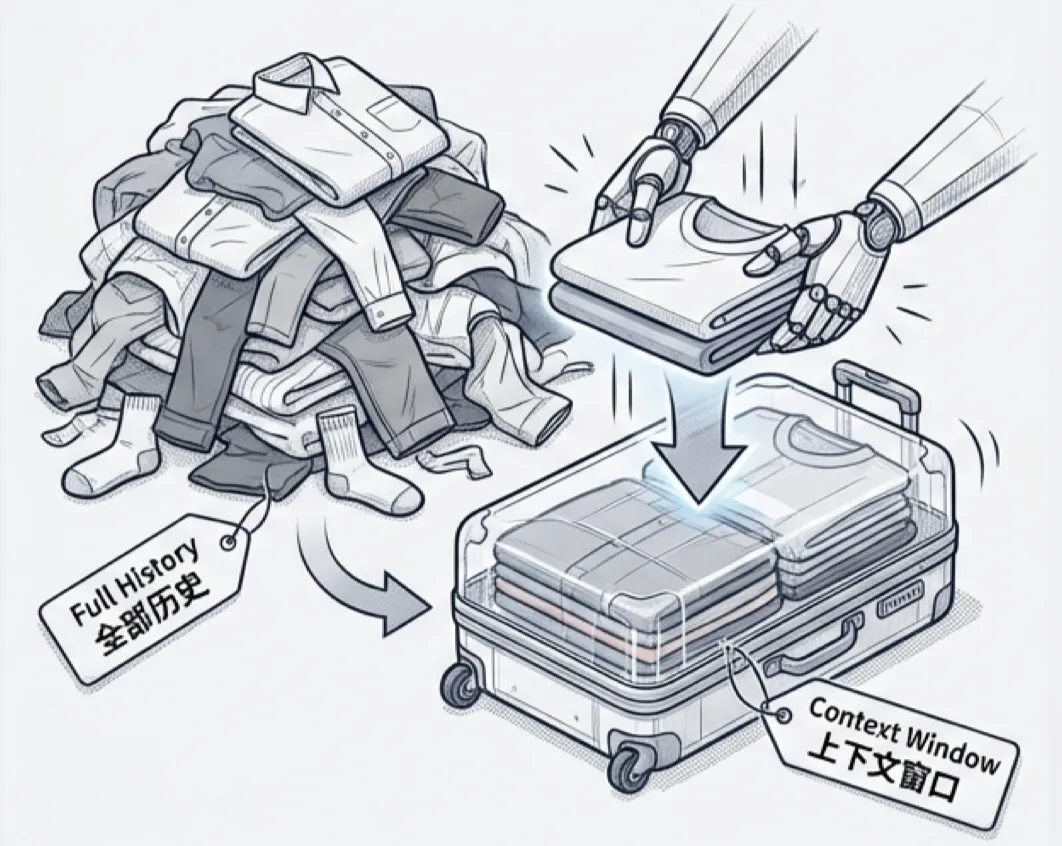
常用的压缩算法有(通常为后台异步执行的):
截断 (Truncation)
滑动窗口:仅保留最近 N 轮对话(Last N turns)。
基于 Token:从最新消息向前回溯,直到达到 Token 限制(如 4000 tokens)。
递归总结 (Recursive Summarization)
周期性调用 LLM,将旧的对话历史(Oldest N messages)替换为一段高密度的自然语言摘要。这是一种以计算换空间的策略。
触发机制 (Triggers)
Count-based:达到 X 轮或 Y Token 时触发。
Time-based:用户不活跃 Z 分钟后触发(利用空闲时间进行计算)。
Event-based:检测到任务完成(Task Completion)时触发清理。
2.6
如何保证压缩的“高信噪比”?
信息的压缩本质上是有损的。在 Agent 开发中,我们追求的不是“无损”,而是高信噪比。
正如 Day 1 所述,Agent 的本质是上下文窗口的精选。我们需要丢失那些寒暄和废话,以换取模型在有限窗口内对关键逻辑的聚焦。
那么,如何让 LLM 判断什么信息是重要的?在 Context Engineering 的架构中,这通过一套基于 LLM 的 ETL(抽取-转换-加载)流水线来实现。
判断“重要性”的权力并非凭空交给模型,而是通过以下三个层级的工程手段进行约束和引导:
1. 定义层面:通过 Prompt 和 Schema 设定“关注域”
模型无法凭空猜出什么重要,因为“重要”是相对于业务场景而言的。白皮书明确指出,“有意义”不是一个通用概念,而是由 Agent 的用途定义的。
我们需要在系统指令中通过以下方式“硬编码”判断标准:
话题定义: 在 Prompt 中明确列出需要提取的“话题”。例如,对于一个客服 Agent,重要信息是“订单号”、“故障现象”;而对于一个心理咨询 Agent,重要信息则是“情绪状态”、“长期目标”。如果信息不匹配任何预定义话题,就被视为噪音丢弃。
结构化约束: 强迫 LLM 输出特定的 JSON 结构。例如定义一个 { "seat_preference": string } 的 Schema。模型在生成时,必须从对话中提取符合该结构的信息。凡是填不进这个 Schema 的闲聊(如“今天天气不错”),自然就被过滤掉了。
少样本学习: 这是最有效的工程手段。给模型展示几个 Examples:输入是一段包含废话的对话,输出是提取出的精炼 Fact。通过上下文学习,模型会模仿这个逻辑,学会忽略类似“嗯嗯”、“好的”这样的无意义 Token。
2. 运行时层面:LLM 驱动的提取与整合
在运行时,我们不是简单地截断对话,而是运行一个后台的异步进程,利用 LLM 作为编辑器来判断重要性。
提取阶段: 这是一个过滤过程。输入是原始的 Session Log,输出是候选的 Memory Items。LLM 此时扮演的是一个过滤器,它根据上述的 Prompt 定义,将非结构化的对话“蒸馏”为原子化的事实。
整合阶段: 这是最高级的判断逻辑。LLM 此时扮演的是仲裁者。它需要对比“新提取的信息”和“已有的记忆”,并执行操作:
更新:如果新信息比旧信息更具体或有时效性(例如用户修改了收货地址),则覆盖。
忽略:如果新信息只是旧信息的重复,则丢弃。
删除:如果新信息否定了旧信息(例如用户说“我不喜欢吃辣了”),则删除旧条目。
这个过程被称为自我编辑,通过这种主动的冲突解决机制,保证留下的都是经过验证的“高价值”信息。
3. 检索层面:多维度的重要性评分
即便信息被存下来了,在推理时也不可能全量加载。此时,“重要性”的判断变成了检索时的排序算法。
白皮书建议使用三个维度来计算一个记忆片段的得分:
1. 相关性:语义向量搜索的相似度。
2. 时效性:时间衰减函数。通常越新的记忆权重越高(除非被标记为永久记忆)。
3. 重要度:这是一个独立权重。在记忆生成时,可以让 LLM 对该条记忆的“含金量”打分(例如 1-10 分)。
「例如」
“用户叫张三”可能得 10 分(核心事实)。
“用户今天中午吃了面条”可能只得 2 分(琐事)。
在检索时,高分记忆更容易被选中进入上下文窗口。
? 总结
我们并不是让 LLM “凭感觉”去判断重要性,而是通过 Context Engineering 构建了一套规则系统:
用 Schema 和 Few-Shot 告诉它“看什么”。
用 Consolidation 流程 让它进行“新旧比对”。
用 Importance Scoring 给记忆打上“权重标签”。
这种“有损压缩”实际上是一种降噪处理。虽然我们丢失了原始对话的语气词和冗余细节,但我们保留并强化了对决策至关重要的状态与事实,这正是构建生产级 Agent 的核心所在。
三、
Memory
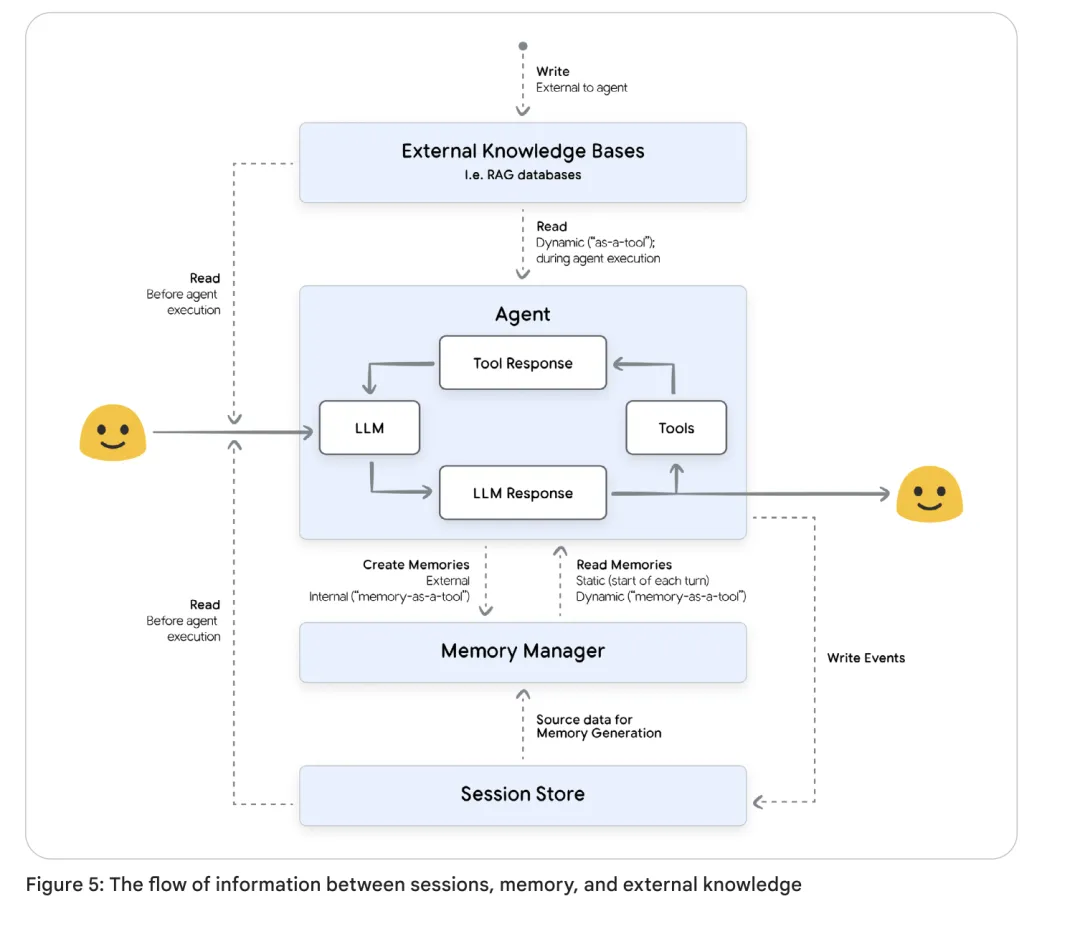
记忆和会话之间是一种共生关系:会话是生成记忆的主要数据来源,而记忆是管理会话大小的关键策略。
记忆对智能体的提升:
个性化:最常见的用例是记住用户的偏好、事实和过去的互动,以定制未来的响应。例如,记住用户最喜欢的运动队或他们在飞机上的首选座位,能创造更有帮助且更具个性化的体验。
上下文窗口管理:随着对话变长,完整的历史记录可能会超出大型语言模型(LLM)的上下文窗口。记忆系统可以通过生成摘要或提取关键事实来压缩这段历史,在每一轮对话中无需发送数千个标记就能保留上下文。这既降低了成本,又减少了延迟。
数据挖掘与洞察:通过(以聚合的、保护隐私的方式)分析众多用户的存储记忆,您可以从噪声中提取洞察。例如,零售聊天机器人可能会发现许多用户正在询问特定产品的退货政策,从而标记出潜在问题。
智能体自我提升与适应:智能体通过创建关于自身表现的程序性记忆,从先前的运行中学习——记录哪些策略、工具或推理路径带来了成功的结果。这使智能体能够建立有效的解决方案手册,使其能够随着时间的推移适应并改进问题解决能力。
3.1
职责划分
在人工智能系统中,创建、存储和利用记忆是一个协作过程。从最终用户到开发人员的代码,技术栈中的每个组件都扮演着独特的角色。
1. 用户:提供记忆的原始源数据。在某些系统中,用户可能直接提供记忆(即通过表单)。
2. 智能体(开发者逻辑):配置如何决定记住什么内容以及何时记住,协调对内存管理器的调用。在简单架构中,开发者可以将逻辑实现为始终检索内存并始终触发生成。在更高级的架构中,开发者可以将内存实现为工具,由智能体(通过LLM)决定何时应检索或生成内存。
3. 智能体框架(例如ADK、LangGraph):提供用于内存交互的结构和工具。该框架起到连接作用。它定义了开发人员的逻辑如何访问对话历史并与内存管理器交互,但本身并不管理长期存储。它还定义了如何将检索到的内存填充到上下文窗口中。
4. 会话存储(即Agent Engine Sessions、Spanner、Redis):存储会话的逐轮对话。原始对话将被输入到内存管理器中以生成记忆。
5. 内存管理器(例如 Agent Engine Memory Bank、Mem0、Zep):负责内存的存储、检索和压缩。存储和检索内存的机制取决于所使用的提供者。这是一种专门的服务或组件,它接收智能体识别的潜在内存并处理其整个生命周期。
提取是从源数据中提取关键信息。
巩固会筛选记忆以合并重复的实体。
存储将内存持久化到持久数据库中。
检索会获取相关记忆,为新的交互提供上下文。
职责划分确保开发人员能够专注于智能体的独特逻辑,而无需构建用于内存持久化和管理的复杂底层基础设施。重要的是要认识到,内存管理器是一个主动系统,而不仅仅是一个被动的向量数据库。虽然它使用相似性搜索进行检索,但其核心价值在于能够随着时间的推移智能地提取、整合和管理记忆。托管记忆服务(如Agent Engine Memory Bank)负责记忆生成和存储的整个生命周期,让您能够专注于智能体的核心逻辑。
3.2
区分RAG和Memory
在架构上必须严格区分 Memory 与 RAG,虽然两者都是外部存储,但两者解决的是不同维度的问题:
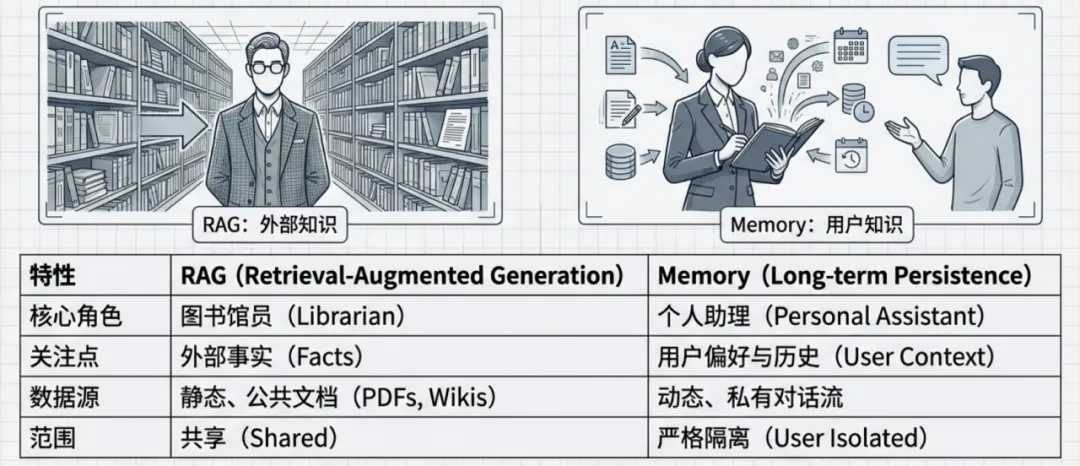
一个真正的智能体Agent需要RAG来理解世界,Memory来理解用户。
更详细的对比如下表:
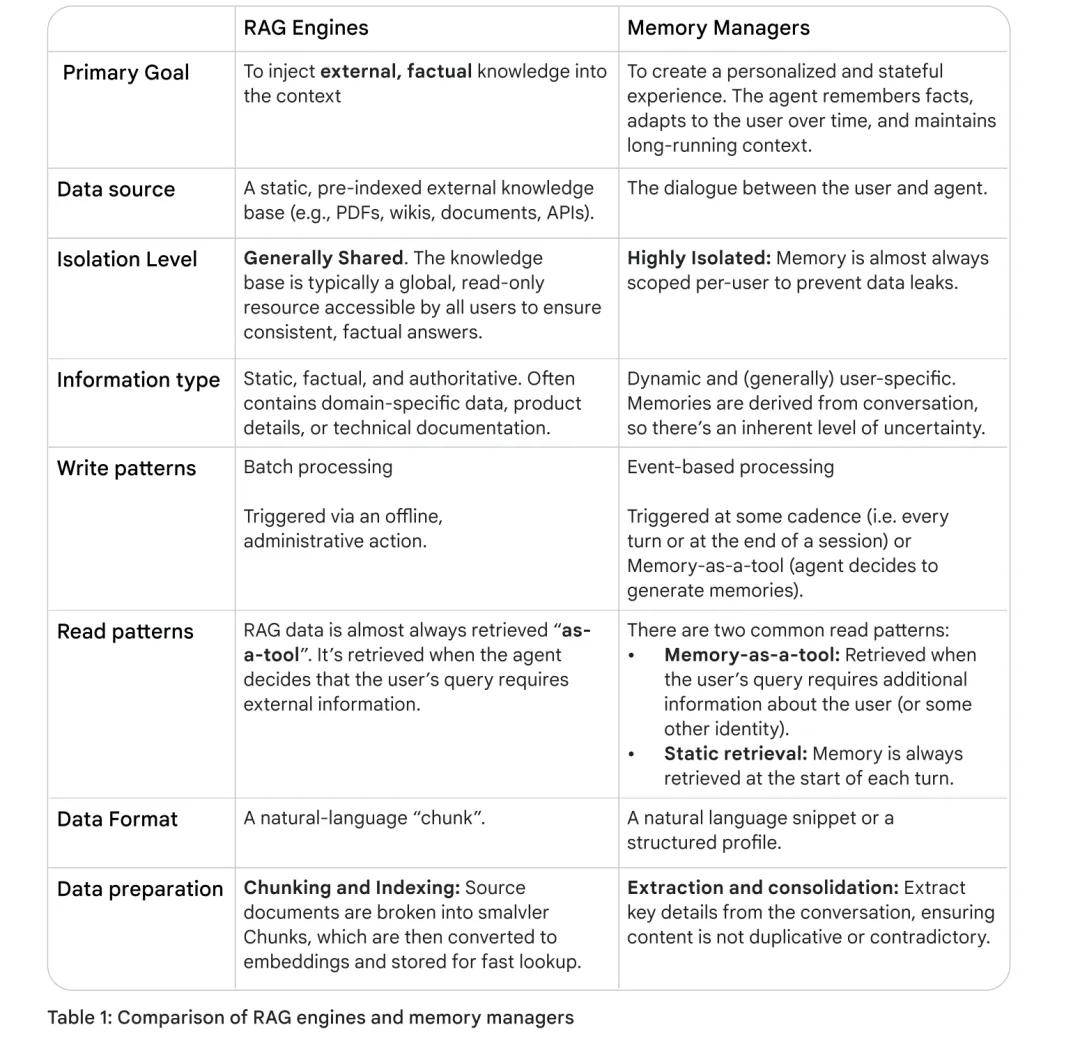
3.3
记忆的划分
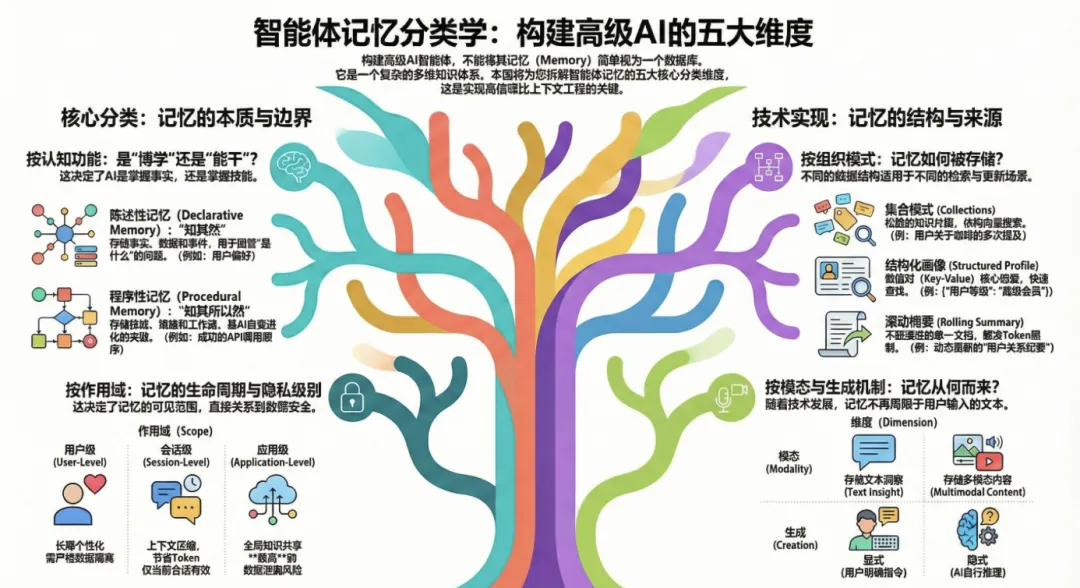
在上下文的架构体系中,记忆并非单一的数据存储形式,而是一个多维度的知识体系。为了构建复杂的 Agent,我们需要从认知功能、作用域、组织模式、模态以及生成机制这五个维度对记忆进行精细划分。
1.按认知功能划分
这是最基础的划分,源于认知科学,决定了 Agent 是“博学”还是“能干”。
陈述性记忆 —— "Knowing What"
定义:Agent 对事实、数据和事件的认知。这是目前大多数 Memory Manager主要支持的类型。
细分
语义记忆 (Semantic):通用的世界知识或领域知识(例如:“Python 是一种编程语言”)。
情景/实体记忆 (Episodic/Entity):关于特定用户的事实(例如:“用户叫张三,喜欢靠窗座位”)。
示例:Agent 发现对于某个 API,先调用 A 再调用 B 会报错,必须先调用 C。这种“成功的调用链”被存为程序性记忆,指导未来的执行。
2.按作用域划分
作用域决定了记忆的可见性和生命周期,直接关系到隐私安全与数据隔离。
用户级
定义:最常见的模式。记忆与特定 user_id 绑定,跨所有会话持久存在。
用途:深度个性化。让 Agent 建立长期的用户画像。
安全:必须严格隔离,实施 ACL(访问控制)。
会话级
定义:注意,这不同于原始的 Session Log。 它是指从当前会话中提取出的、经过压缩的“精炼事实”。
用途:上下文压缩。当会话过长时,用这些提取出的 Insight 替换掉冗长的原始对话记录,以节省 Token 并保持注意力。
生命周期:仅在当前任务或会话中有效。
应用级
定义:所有用户共享的全局记忆。
用途:系统广播、基本常识或全局的程序性记忆。
风险:极高的数据泄漏风险。必须经过严格的去敏处理,绝不能包含任何 PII(个人敏感信息)。
3.按组织模式划分
这决定了记忆在存储层的数据结构,影响检索策略。
集合模式
结构:一堆松散的自然语言片段或半结构化数据。
场景:存储大量非结构化的观察。例如“用户提到过几次关于咖啡的偏好”。
检索:依赖向量相似度搜索。
结构化画像模式
结构:类似“名片”或数据库表的键值对。
场景:核心事实。例如 { "name": "Alice", "account_type": "Premium" }。
特点:不断更新,而非追加。适合快速查找确定性信息。
滚动摘要模式
结构:单一的、不断演进的自然语言文档。
场景:维护一段关于“用户-Agent 关系”的完整叙事。
机制:新信息不是存为新条目,而是融合进现有的摘要中。适合解决上下文 Token 限制问题。
4.按模态划分
随着多模态 Agent 的兴起,记忆不再局限于文本。
多模态源 (Memory from Multimodal Source) —— 主流方案
机制:输入是多模态(图/音/视),但存储的是文本 Insight。
例子:用户发了一张客厅照片。Agent 存的记忆是文本:“用户的客厅是现代简约风格,有一张灰色沙发。”
优势:易于检索和索引。
多模态内容 (Memory with Multimodal Content) —— 高级方案
机制:输入和存储都是多模态数据。
例子:用户说“记住这个 Logo 的设计”。Agent 直接将图片文件作为记忆存储,并建立索引。
挑战:需要专门的基础设施来支持非文本数据的检索。
5.按生成机制划分
显式 vs. 隐式 (Explicit vs. Implicit)
显式:用户明确指令(“记住我的生日是10月26日”)。信任度高。
隐式:Agent 从对话中推理得出(“用户在看球赛门票 -> 推测用户喜欢体育”)。信任度较低,需要验证。
结构化 vs. 非结构化 (Structured vs. Unstructured)
结构化:符合预定义 Schema(如 JSON)。适合程序调用。
非结构化:自然语言描述。适合作为 LLM 的推理上下文。
在Agent的开发中,不要把 Memory 简单理解为一个 Vector DB。它是一个分类分级系统。 你需要根据业务需求,决定你的 Agent 需要的是陈述性还是程序性记忆,是用户级还是应用级作用域,并选择合适的组织模式(画像还是集合)。这种精细的分类是实现上下文高信噪比的关键。
3.4
存储架构
在记忆的存储架构不仅仅是选择一个数据库,而是决定了 Agent “如何思考” 以及 “如何联想”。存储架构的选择直接决定了 Agent 是擅长寻找概念相似性,还是擅长进行结构化推理。
1. 两大核心架构范式
记忆通常存储在 向量数据库(Vector Databases) 或 知识图谱(Knowledge Graphs) 中,或者两者的结合。
向量数据库 (Vector Databases) —— 擅长“模糊联想”
机制:将记忆(通常是自然语言片段)转化为高维嵌入向量(Embeddings)。检索时,计算 Query 向量与记忆向量之间的距离。
适用场景:非结构化记忆
适用于寻找语义相似(Semantically Similar)的内容,而不是关键词匹配。
例如:“原子事实”(Atomic Facts)或用户偏好的自然语言描述(“用户喜欢在安静的地方工作”)。
优势:能够捕捉细微的语境和概念联系,对模糊查询的容错率高。
知识图谱 (Knowledge Graphs) —— 擅长“结构化推理”
机制:将记忆存储为 实体(Nodes) 和 关系(Edges) 的网络。检索时,通过图遍历(Traversal)来发现直接或间接的连接。
适用场景:结构化记忆
适用于处理复杂的关系网和多跳推理(Multi-hop Reasoning)。
例如:“知识三元组”(Knowledge Triples):Alice (Entity) -- works_at (Relation) --> Google (Entity)。
优势:能够回答关于实体关系的精确问题(“Alice 的同事都有谁?”),并支持逻辑推理。
2. 终极形态:混合架构
为了兼得两者的优势,推荐使用 混合架构模式。
实现方式
以知识图谱为骨架,存储实体和关系。
同时对图中的节点(Entities)和边(Relationships)生成 向量嵌入(Vector Embeddings)。
价值
既能进行 语义搜索(找到概念相关的节点),又能进行 图遍历(发现结构上的关联)。
这是构建复杂 Agent 的“最佳实践”,因为它模拟了人类大脑既有模糊联想又有逻辑推理的特性。
3. 架构分层:Session 存储 vs. Memory 存储
在生产级系统中,必须严格区分“热数据”与“冷数据”的存储设施:

4. 生产环境的工程考量
当记忆系统从原型走向生产时,存储架构面临分布式系统的一系列挑战:
全局一致性与复制
对于大规模应用,记忆管理器必须在底层处理 多区域复制 ,以保证低延迟读取。
关键约束:客户端复制是不可行的。因为记忆的 整合过程需要对数据有一个“单一事务性视图”,以防止在合并冲突时产生数据损坏。因此,复制必须由数据库层内部处理。
并发控制
当多个事件同时触发记忆更新时(例如用户快速发送多条消息),会出现竞争条件。
解决方案:使用 事务性数据库操作 或 乐观锁 (Optimistic Locking)。
架构补充:引入 消息队列 (Message Queue) 来缓冲高并发的写入请求,防止压垮记忆生成服务。
缓存层
为了应对昂贵的检索操作(如复杂的图查询或 Reranking),可以在存储层之上引入缓存,暂存最近检索过的记忆结果。
记忆的存储架构并非简单的“把数据存进数据库”。
它是一个 分层系统:底层是处理高并发日志的 Session Store(Redis/Spanner),上层是负责知识推理的 Memory Store(Vector+Graph Hybrid)。在这个架构中,Memory Store 扮演了跨框架、跨 Agent 的 通用数据层(Universal Data Layer) 角色,通过规范化的数据结构实现了智能体的互操作性。
3.5
核心机制:ETL流水线
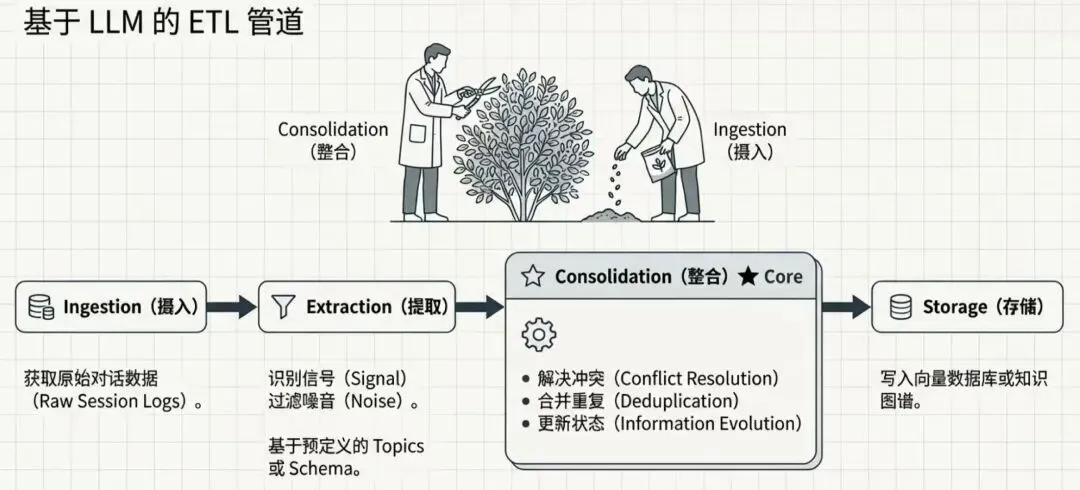
记忆管理并非一个被动的存储介质(如简单的 Vector DB),而是一个主动的、由 LLM 驱动的数据处理管道。白皮书将其定义为一个自动化的 ETL 过程,负责将非结构化的、高噪声的会话流化为结构化的、高信噪比的知识库。
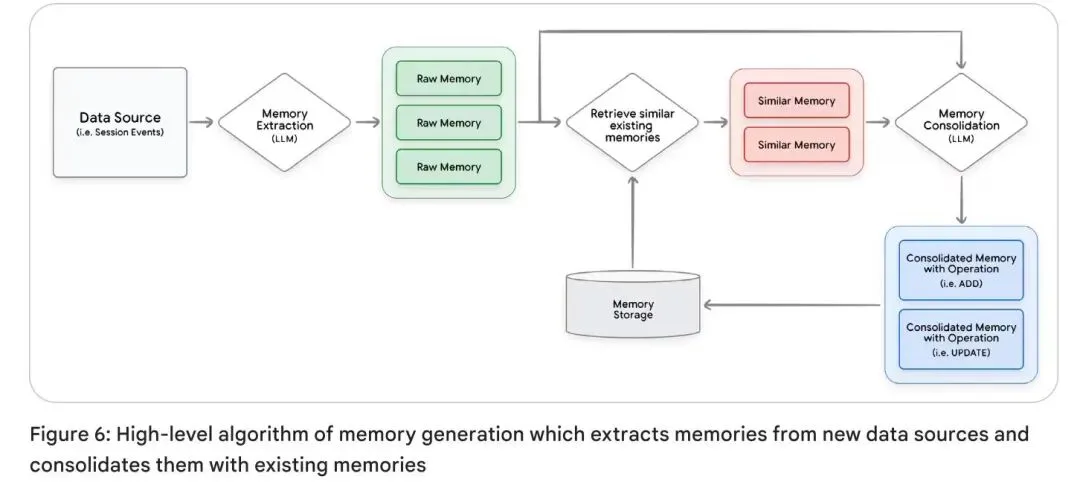
该流水线包含四个核心阶段:摄入(Ingestion)、抽取(Extraction)、整合(Consolidation)与存储(Storage)。
1. 阶段一:摄入
这是流水线的入口。
输入数据:原始的、未加工的数据源。最典型的是会话日志,即用户与 Agent 的多轮对话记录。
触发机制:摄入通常由事件触发,包括:
会话结束
轮次间隔
显式调用
2. 阶段二:抽取与过滤
此阶段的目标是降噪。LLM 在此充当过滤器,负责从冗长的对话中识别并提取出具有持久价值的原子事实,同时丢弃寒暄、填充词和无关信息。
定义“有意义” :系统必须通过 Schema 或 Prompt 严格定义什么是“值得记忆的”。白皮书提出了三种工程手段:
结构化 Schema:要求 LLM 输出符合特定 JSON 结构的字段(如 {"seat_preference": "window"})。
自然语言话题定义:在 System Prompt 中描述需要关注的主题(如“提取所有关于用户饮食偏好的信息”)。
少样本学习 (Few-Shot Examples):提供输入输出对,演示如何从对话中提取高保真记忆。这对处理复杂或含蓄的意图尤为有效。
输出:提取后的产物通常是结构化数据或经过清洗的自然语言片段,此时它们尚未写入主库,仅作为“候选记忆”。
3. 阶段三:整合—— 流水线的核心
这是记忆系统与普通 RAG 或日志系统的本质区别。整合是一个自我编辑和冲突解决的过程。系统利用 LLM 对比“新提取的候选记忆”与“现有的存储记忆”,以维护知识库的一致性与演进。
输入
新提取的候选记忆(来自阶段二)。
从库中检索到的、与新记忆语义相关的现有记忆
LLM 决策逻辑:LLM 分析两者关系,决定执行以下事务性操作之一:
CREATE:新信息是全新的,库中无相关记录。
UPDATE:新信息修正或细化了旧信息(例如:用户从“喜欢水果”更新为“喜欢苹果,但对香蕉过敏”)。
DELETE / INVALIDATE:新信息否定了旧信息(例如:用户说“我搬家了,旧地址作废”),或者旧信息已过期。
IGNORE:新信息是冗余的,库中已存在且无变化。
解决的核心问题
信息重复:防止同一事实被多次存储。
信息冲突 :解决前后矛盾的用户陈述。
信息演进 :将孤立的事实串联成更完整的画像。
4. 阶段四:存储
经过整合后的规范化数据被持久化到数据库中。
架构选择:通常采用混合存储
向量数据库 (Vector DB):存储非结构化的自然语言记忆,支持语义检索(Relevance)。
知识图谱 (Knowledge Graph):存储实体及其关系(Nodes & Edges),支持结构化推理。
索引更新:在写入数据的同时,系统会重新计算 Embeddings 或更新图结构,确保新记忆即刻可被检索。
3.6
信任的保证:记忆的治理
在构建企业级 Agent 时,必须正视 LLM 的一个核心缺陷:“Garbage in, confident garbage out”(垃圾进,自信的垃圾出)。为了确保 Agent 决策的可靠性,记忆系统不能仅存储数据本身,必须完整记录数据的血缘关系(Lineage)。记忆溯源是实现数据完整性、冲突解决和隐私合规的底层依赖。
1. 记忆溯源
记忆溯源是指记录每一条记忆条目的元数据(Metadata),用于追踪其来源、生成时间和置信度。 在工程实现上,记忆不再是一个简单的字符串,而是一个包含来源引用的复杂对象。它解决了两个根本问题:
信任评估:Agent 在推理时应该多大程度上相信这条记忆?
数据一致性:当源数据发生变化或被删除时,如何维护衍生记忆的一致性?
2. 信任层级体系
白皮书明确指出,不同来源的数据具有不同的可信度权重。在进行记忆整合或推理时,系统应遵循以下信任优先级:
L1: 引导数据—— 最高信任
定义:从受信任的内部系统(如 CRM、HR 系统)预加载的数据。
用途:解决“冷启动”问题,为 Agent 提供确定的基准事实
L2: 用户显式输入 —— 高信任
定义:用户通过明确指令(如“记住我的生日是...”)或填写表单提供的数据。
特性:意图明确,通常视为用户层面的事实。
L3: 对话隐式推断 —— 中/低信任
定义:Agent 从非结构化对话中通过推理提取的信息(如“用户在看球赛 -> 推测用户喜欢体育”)。
风险:这是幻觉的高发区,需要后续验证或通过多源佐证来提升置信度。
L4: 工具输出 —— 最低信任/临时
定义:外部 API 返回的数据。
特性:通常具有强时效性(易过期)且脆弱。白皮书建议此类数据通常不应作为长期记忆存储,更适合作为短期缓存。
3. 工程应用:基于溯源的治理策略
记录溯源信息主要服务于以下四个核心治理场景:
冲突解决
当新提取的信息与现有记忆发生逻辑冲突时(例如旧记忆显示“住在北京”,新信息显示“住在上海”),系统依靠溯源信息进行仲裁,而非简单的时间覆盖:
权重仲裁:如果新信息来自“隐式推断”,而旧信息来自“显式输入”,则保留旧信息。
佐证机制:如果多个低置信度的来源都指向同一个事实,可以提升该记忆的置信度。
级联删除与一致性
这是分布式数据系统中的经典难题。记忆往往是由原始会话日志衍生而来的。
场景:用户撤回了某次对话的授权,或要求删除某条原始记录。
机制:通过血缘图谱(Lineage Graph),系统必须能识别并删除所有由该源数据衍生出的记忆。如果无法做到这一点,将导致严重的隐私合规(GDPR/CCPA)风险。
重建策略:更精确的做法是删除受影响的记忆,并基于剩余的合法源数据触发重生成流程。
生命周期管理与修剪
溯源信息中的“时间戳”和“初始置信度”是记忆老化算法的输入参数:
时间衰减:基于创建时间降低检索权重。
置信度阈值:定期清理那些初始置信度低且长期未被再次验证的“孤立记忆”。
推理时的动态置信度
溯源不仅仅用于后台管理,它直接参与推理过程。 在构建 Context Payload 时,不仅要注入记忆的内容,还应注入其动态置信度分数。
实现方式:在 System Prompt 中,将记忆标记为“高确定性”(来自 CRM)或“推测性”(来自之前的对话)。
价值:这允许 LLM 在回答时表现出适当的谨慎(例如:“根据之前的对话,您似乎对...感兴趣”,而不是绝对的断言),从而降低模型幻觉带来的用户体验风险。
记忆溯源将 Agent 的记忆系统从一个“黑盒数据库”提升为一个可审计、可解释、可回滚的知识图谱。对于系统架构师而言,在设计 Schema 时必须包含 source_id, source_type, created_at, confidence_score 等字段,以支持上述治理逻辑。
四、
记忆的检索与推理
如果说 ETL 流水线是记忆的“写入”过程,那么检索与推理则是记忆的“读取”与“应用”过程。这是 Agent 运行时的必经之路,直接决定了系统的响应延迟、Token 成本以及最终回答的准确性。
4.1
记忆检索策略
检索不仅仅是简单的向量相似度搜索。为了在有限的上下文窗口内提供最高信噪比的信息,生产级系统必须采用多维度的评分与优化机制。
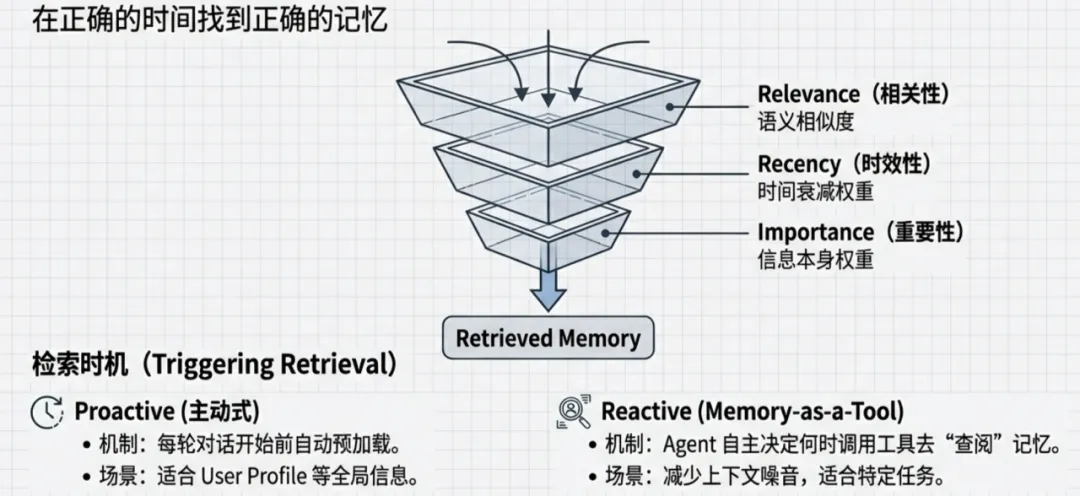
1. 多维评分算法
单纯依赖语义相似度(Vector Similarity)会导致检索出虽然语义相关但已过时或细枝末节的信息。白皮书建议采用混合评分公式:
Score = f(Relevance, Recency, Importance)
相关性 (Relevance):基于 Embedding 的余弦相似度,衡量记忆与当前 Query 的语义距离。
时效性 (Recency):应用时间衰减函数(Time-decay function)。对于非永久性事实,越新的记忆权重越高。
重要度 (Importance):这是一个生成时(Generation-time)确定的静态属性。例如,“用户对花生过敏”(高重要度)在检索时的优先级应高于“用户喜欢蓝色”(低重要度),即使后者在语义上与 Query 更接近。
2. 高级检索优化
针对高精度需求场景,可引入以下计算密集型策略,但需权衡延迟预算:
查询重写
利用 LLM 将用户模糊的原始 Query(如“还是老样子”)改写为精确的检索 Query(如“用户上次点的咖啡是什么”)。这能显著提高召回率,但增加了一次 LLM 调用延迟。
重排序
两阶段检索:第一阶段使用向量搜索快速召回 Top-N(如 50 条)候选记忆;第二阶段使用 Cross-Encoder 或 LLM 对这 50 条进行精细打分排序,截取 Top-K(如 5 条)进入 Context。这能大幅提升 精确度。
缓存层
针对静态的 Proactive Retrieval(如用户画像),应在存储层之上构建缓存,避免重复计算 Embedding 和数据库查询。
3. 性能指标
检索系统的核心 SLA 指标包括:
Recall@K:目标记忆出现在前 K 个检索结果中的概率。
Latency:作为阻塞式操作,P99 延迟通常要求控制在 200ms 以内。
4.2
检索时机架构
架构师需要在“上下文完整性”与“Token/延迟成本”之间做出权衡,主要有两种模式:
1. 主动检索 (Proactive Retrieval / Static)
机制:在每一轮对话开始前,强制检索相关记忆并注入 Context。
适用场景:用户画像(User Profile)、核心业务规则。
实现:通过 PreloadMemoryTool 或 BeforeModelCallback 钩子实现。
优缺点:
确保 Context 总是包含基础背景,减少幻觉。
即使当前 Query 不需要记忆(如“你好”),也会消耗检索资源和 Token。
2. 反应式检索 (Reactive Retrieval / Memory-as-a-Tool)
机制:将记忆检索封装为一个 Tool(如 load_memory(query))。Agent 在推理过程中,根据任务需求自主决定是否调用以及查询什么。
适用场景:情景记忆(Episodic Memory)、细节查询。
实现:定义工具描述,明确告知 LLM 数据库中包含哪些类型的信息(如“包含用户饮食偏好、历史订单”),引导其正确调用。
优缺点:
极其节省 Token,仅在必要时加载;查询意图更精准。
增加了一次 LLM 推理往返(Round-trip),增加了端到端延迟;且依赖模型遵循指令的能力(可能出现该查不查的情况)。
4.3
推理与上下文注入
一旦记忆被检索出来,如何将其放置在 Prompt Payload 中(即 Context Placement)直接影响 LLM 的注意力分配和推理逻辑。
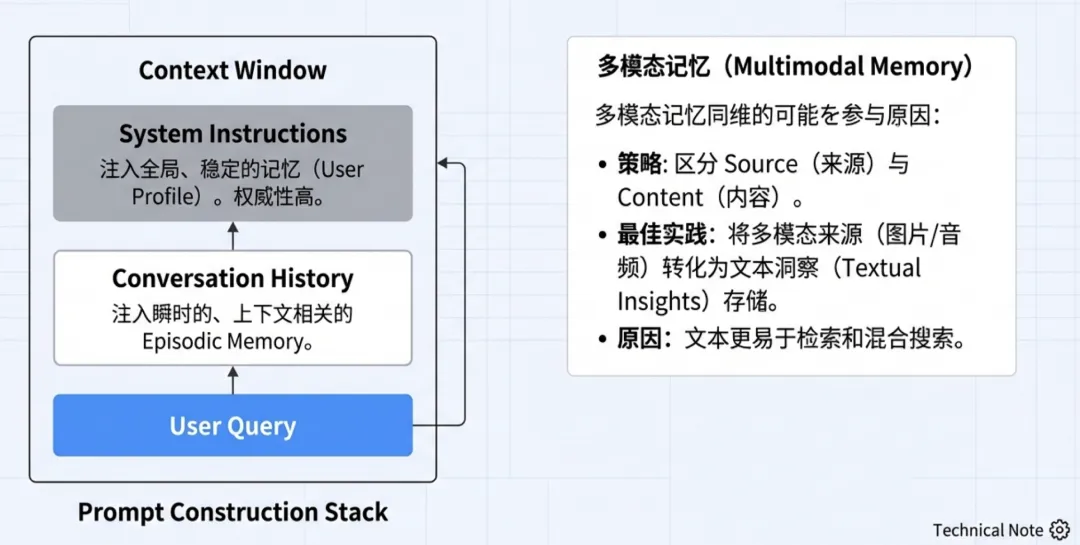
1. 注入位置策略
System Instructions(系统指令区)
内容:放置全局性、静态的记忆(如用户姓名、核心性格设定、长期目标)。
优势:权威性高(High Authority),对模型行为有全局约束力;将背景与当前对话清晰分离。
劣势:可能导致过度影响(Over-influence),即模型强行将无关话题与记忆挂钩;通常不支持多模态数据。
模板示例:
system_instruction =You are a helpful assistant.<USER_PROFILE>* Name: Alice* Preference: Vegan</USER_PROFILE>
Conversation History(对话历史区)
内容:放置瞬时、特定情境的记忆(如“上周的会议记录”)。
方式:
工具输出插入:作为 ToolMessage 插入历史流。
虚拟轮次注入:在 User Message 之前伪造一条 System/User 消息包含记忆。
风险:对话注入(Dialogue Injection)。模型可能混淆“记忆”与“用户刚刚说的话”。必须清晰标注来源(如 [Memory Retrieved]: ...)。
2. 动态置信度注入 (Dynamic Confidence)
这是对抗“垃圾进,自信垃圾出”的关键技术。在推理时,不应只注入记忆的事实内容(Fact),还应注入其元数据(Metadata),特别是基于溯源(Provenance)计算出的置信度。
实现逻辑:
对于来自 CRM 的数据,标记为“已验证事实”。
对于来自历史对话推断的数据,标记为“推测”或附带时间戳。
Prompt 示例:
(High Confidence, Source: CRM): User phone is 555-0199.(Low Confidence, Source: Chat Inference, 2 years ago): User might be interested in hiking.
效果:迫使 LLM 在生成回答时表现出适当的认知不确定性(Epistemic Uncertainty),例如使用“根据之前的记录,您似乎...”而不是绝对断言。
4.4
特殊场景:程序性记忆的推理
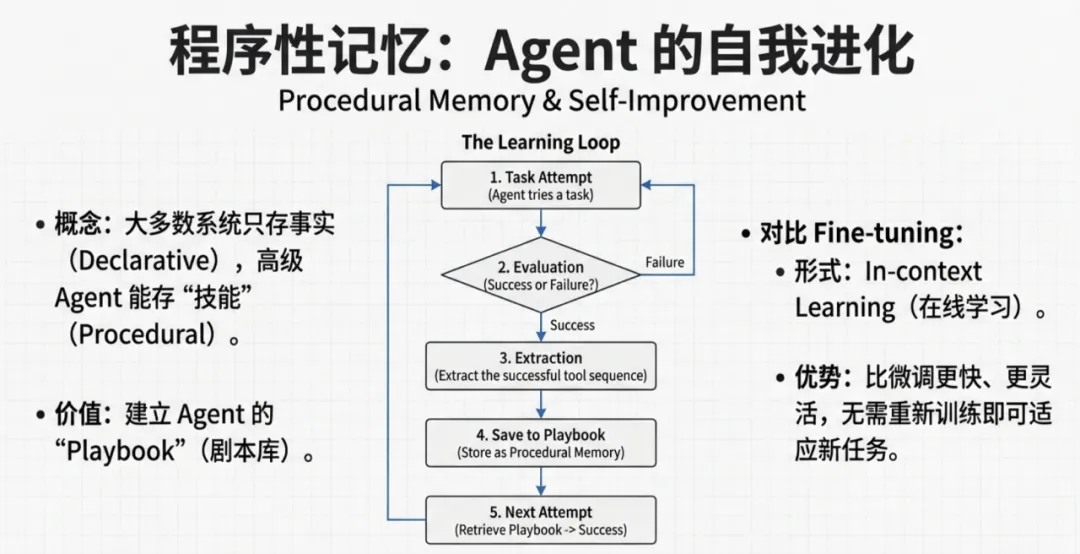
对于程序性记忆(Procedural Memory / "Knowing How"),检索和推理的逻辑与陈述性记忆完全不同。
检索目标:不是检索“答案”,而是检索“计划(Plan/Playbook)”。
In-Context Learning (ICL):将检索到的成功工作流(Successful Workflow)作为 Few-Shot Examples 注入 Prompt。
机制:
当前任务:“如何调用 API X?”
检索:找到过去成功调用 API X 的 Trace。
推理:模型模仿过去的成功路径,而不是从零规划。
价值:这是实现 Agent 自我进化与在线学习的替代方案,无需微调模型权重即可修正行为。
在上下文工程中,记忆检索与推理是一个从数据到决策的闭环:
算法层:通过 Relevance + Recency + Importance 保证检索质量。
架构层:通过 Proactive vs. Reactive 策略平衡成本与延迟。
表达层:通过 System Instructions vs. History Injection 以及置信度标注,引导 LLM 正确使用记忆。
这一过程的核心目标是将 Agent 从一个“查数据库的机器人”转变为一个“具备连贯认知与情境感知能力的智能体”。
五、
生产环境
从原型走向生产,Agent 系统的关注点从单纯的“回复质量”转移到了高并发、低延迟、数据一致性、安全性与治理等分布式系统工程问题上。
以下从四个维度进行详细拆解:
5.1
运行时架构与性能
生产环境的核心矛盾在于 LLM 的无状态特性与用户对低延迟体验的需求之间的冲突。
1. 热路径上的会话管理
低延迟读取:Session 数据位于用户交互的“热路径”上。每次推理前必须从数据库加载完整历史。生产环境必须使用高吞吐、低延迟的存储(如 Redis, Spanner),且需在同区域部署以减少网络开销。
上下文压缩:随着对话增长,Token 成本和延迟线性增加。生产系统必须实施自动压缩策略,包括滑动窗口截断或后台递归摘要,以维持 TTFT(首字延迟)在 SLA 范围内。
不可变日志:为了保证推理的可复现性和审计,Session Store 应设计为 Append-only 的日志结构,保证事件顺序的确定性。
2. 异步记忆生成
解耦设计:记忆的 ETL(提取与整合)过程涉及多次 LLM 调用,属于高延迟操作。绝不能在主请求的阻塞路径中执行。必须采用事件驱动架构:Agent 响应用户后,将 Session Events 推送至消息队列,由后台 Memory Service 异步消费处理。
并发控制 :在分布式环境中,针对同一用户的记忆更新可能发生竞争。存储层需实现乐观锁或事务机制,防止数据覆写。同时需引入消息队列缓冲高并发写入,防止压垮记忆服务。
全局一致性:对于全球化部署,记忆存储需处理多区域复制。由于整合逻辑依赖数据的一致性视图,复制必须由数据库层处理,而非客户端。
5.2
安全与数据隐私
引用 Day 1 的观点,Agent 应被视为继人类和服务账户后的第三类安全主体,需建立纵深防御体系。
1. 身份与授权
Agent 身份:每个 Agent 必须拥有独立的、可验证的加密身份(如 SPIFFE),不能简单继承用户权限或使用通用 Service Account。
最小权限原则 :通过集中式策略引擎,精确控制 Agent 对工具和数据的访问权限(例如:销售 Agent 只能读 CRM,不能读 HR 系统),控制“爆炸半径”。
严格隔离 :Session 和 Memory 必须基于 user_id 或 tenant_id 实现严格的 ACL 隔离,防止跨租户数据泄漏。
2. 数据清洗与防护
PII 红移:在数据持久化(写入 Session/Memory Store)之前,必须集成自动红移工具(如 Model Armor),剥离或脱敏个人敏感信息(PII)。这是合规(GDPR/CCPA)的底线。
防投毒:针对记忆系统,需防范 Prompt Injection 导致的错误记忆植入。写入前的校验和清洗机制是必要的。
5.3
数据完整性与生命周期
生命周期管理
Session 不应无限期保留。需设定 TTL(Time-To-Live)策略,自动归档或删除非活跃会话,以控制存储成本。
Memory 需实施主动修剪,基于时间衰减或置信度阈值清理陈旧知识,维持检索的高信噪比。
溯源与一致性
级联删除:当用户撤销原始数据(如某次对话)的授权时,系统必须具备通过血缘关系(Lineage)追踪并删除所有衍生记忆的能力。
版本控制:支持记忆的版本回滚,以应对错误的整合操作。
5.4
治理与可观测性
中央网关
建立统一的控制平面,所有 Agent 流量(User-to-Agent, Agent-to-Tool)必须经过网关。在此处统一实施认证、鉴权、限流和日志记录,防止“智能体蔓延”。
全链路追踪
Agent 的执行是非确定性的。生产环境需要类似微服务的全链路追踪能力,记录完整的“思考-行动-观察”链条,以便在出现幻觉或错误时进行根因分析。
互操作性
采用标准协议(如 A2A 协议)和框架无关的数据层(Memory Layer),确保异构 Agent(如 ADK 开发的 Agent 与 LangGraph 开发的 Agent)之间能够协作,而不是形成数据孤岛,。
总结:生产环境的 Agent 系统设计,本质上是在有限的上下文窗口和严格的延迟预算约束下,构建一个高可靠、强一致、可审计的分布式状态管理系统。

END