


ChatGPT技术深度分析报告:对话式AI的突破、局限与未来。ChatGPT作为现象级AI产品,重塑了人机交互模式,其核心技术与行业影响成为焦点!本报告基于技术原理与实际表现,全面解析ChatGPT的核心优势、关键技术、现存不足及发展方向,为行业观察与应用探索提供参考。
核心要点(文末附完整报告下载方式)
01 核心概览
爆发式传播:2022年11月发布,5天用户破100万,2个月达1亿,传播速度远超主流社交平台,引发行业震动。 行业影响:推动Google紧急发布Bard、微软追加百亿投资并整合进New Bing与Office套件,国内外大厂纷纷跟进布局。 核心定位:基于GPT-3.5系列模型微调,采用对话式交互设计,具备回答后续问题、承认错误、质疑不当前提、拒绝不当请求的核心能力。
超强理解能力:支持多轮对话、异构数据融合(多语言、代码混合),能精准捕捉多样化用户意图,适配诗词解读、系统终端模拟等复杂场景。 丰富生成能力:可创作小说、诗歌、代码等多体裁内容,模仿鲁迅、胡锡进等不同风格,支持中英文等多语言输出,满足多样化表达需求。 类人化交互:具备基础世界认知与自我认知,能坚守价值原则拒绝非法请求,通情达理适配用户语境,如根据需求调整文案正式度、理性回应争议话题。
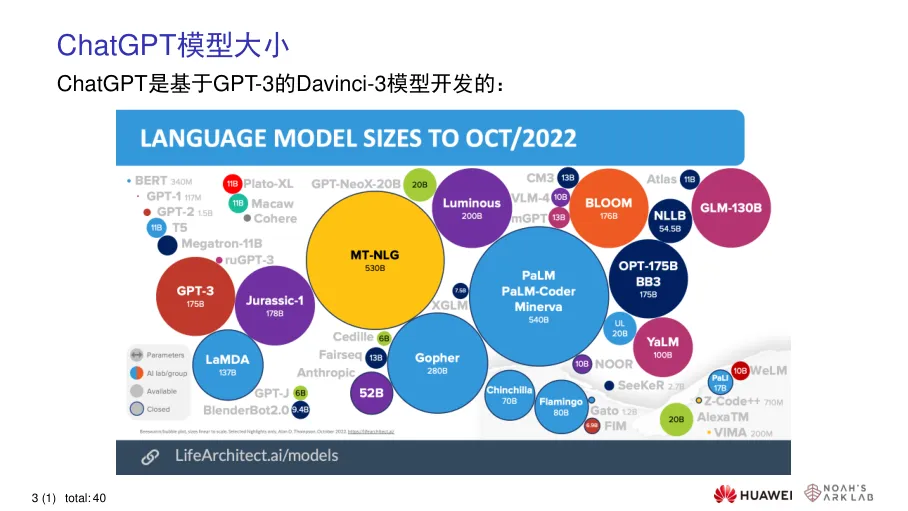
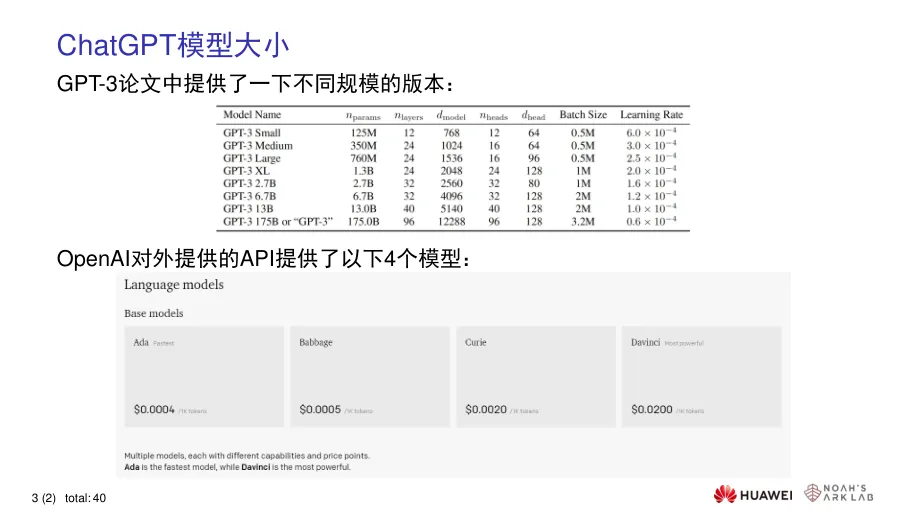
03 关键技术预训练语言模型(PLMs):基于Transformer架构与自注意力机制,通过海量无标注数据预训练,具备基础语言理解与生成能力,典型代表包括BERT、GPT系列。 大型生成式预训练语言模型(LLMs):继承GPT-3 1750亿参数规模,支持零样本、少样本学习与思维链推理,通过上下文学习适配各类下游任务,展现涌现能力。 人类反馈强化学习(RLHF):通过监督微调、奖励模型训练、近端策略优化三阶段,结合人工标注数据优化模型输出,提升回答的有用性、真实性与无害性。
预训练语言模型(PLMs):基于Transformer架构与自注意力机制,通过海量无标注数据预训练,具备基础语言理解与生成能力,典型代表包括BERT、GPT系列。 大型生成式预训练语言模型(LLMs):继承GPT-3 1750亿参数规模,支持零样本、少样本学习与思维链推理,通过上下文学习适配各类下游任务,展现涌现能力。 人类反馈强化学习(RLHF):通过监督微调、奖励模型训练、近端策略优化三阶段,结合人工标注数据优化模型输出,提升回答的有用性、真实性与无害性。
04 现存不足
事实与常识错误:易生成看似合理但错误的内容,如混淆苏格拉底著作、颠倒珍珠港事件因果,缺乏真实信息来源校验机制。 逻辑与数学能力薄弱:面对简单逻辑推理(如亲属关系判断)和数学问题易出错,缺乏严谨的推理链条与计算能力。 输入敏感性与表达冗余:对提问措辞微调敏感,可能出现同题异答;回答过度冗长,频繁重复自身身份信息,存在过度优化问题。 价值观保护机制不完善:偶尔响应有害指令或展现偏见,对复杂伦理场景判断不足,存在误导用户的潜在风险。
05 未来方向
与检索结合:接入实时检索工具,弥补训练数据时效性不足问题,提升事实性回答的准确性与可靠性。 调用外部能力:整合计算工具、专业数据库等外部资源,强化数学运算、逻辑推理等薄弱环节,拓展应用边界。 多模态融合:实现文本、图像、语音等多模态信息的理解与生成,打造更丰富的交互体验,适配更多场景需求。 终生持续学习:构建动态学习机制,支持模型在部署后持续吸收新信息,无需全量重训即可更新知识与能力。






报告免
费领取
关注公众号,在公众号聊天界面回复
【获取资料】(建议直接复制标蓝字),获取报告全文PDF