


目录
1. Maia 200的背景与设计目标
2. 硬件基础:工艺节点与关键规格
3. 芯片微架构详解
4. 内存系统的结构与优化
5. 数据移动与片上网络
6. 扩展网络与互连技术
7. 系统集成与部署考虑
8. 软件栈与开发工具
9. 供应链分析与市场定位

1. Maia 200的背景与设计目标
1.1 推理成本效益:AI规模化的核心瓶颈
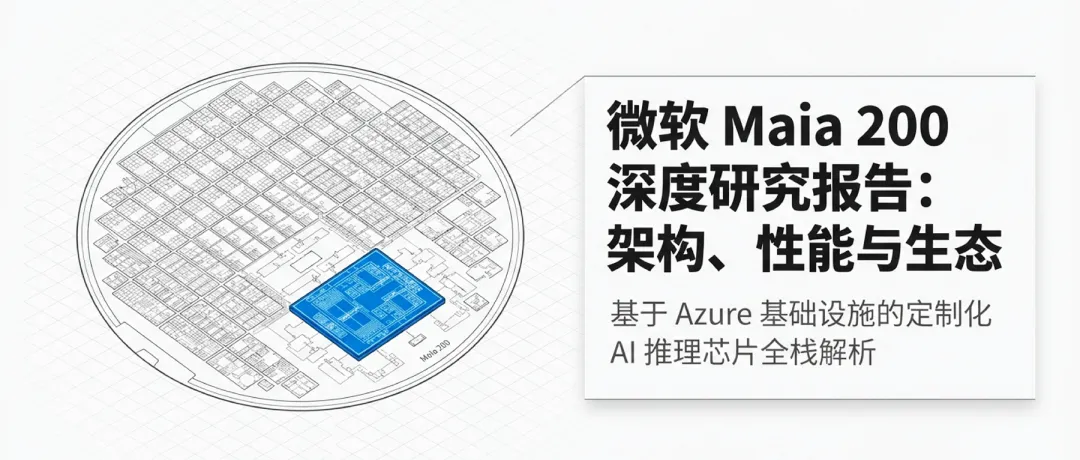
在生成式AI进入大规模应用阶段后,行业关注的重心正从“模型训练”转向“模型推理”。训练决定了模型的能力上限,而推理决定了商业化落地的成本下限。当前,AI行业面临着一个被称为“效率前沿(Efficient Frontier)”的挑战:在给定的成本、延迟和能效水平下,如何最大化模型产出的能力和准确性。

随着模型规模迈入万亿参数级别,传统的通用算力架构在应对复杂的Token生成任务时,其经济性开始捉襟见肘。不同的推理场景对硬件有着截然不同的需求:交互式Copilot要求极致的低延迟响应;批处理摘要和搜索任务强调单位成本下的高吞吐量;而复杂推理(Reasoning)则要求在长上下文和多步执行中保持持续的性能稳定性。
1.2 为什么需要专为推理优化的硬件
长期以来,AI算力高度依赖通用GPU。然而,GPU的设计初衷是兼顾图形渲染与通用计算,在单纯的推理负载中,其硬件资源利用率往往难以达到最优。
微软开发Maia 200的初衷,是希望打破“一刀切”的硬件架构限制。推理任务本质上是受限于内存带宽(Memory-bound)和数据移动效率的。Maia 200的核心设计目标是提高“单位美元性能(Performance per dollar)”。通过纵向整合芯片、软件栈、系统互连及数据中心基础设施,Maia 200旨在解决大规模Token生成带来的成本激增问题,使其在推理效率上比现有最新的通用硬件高出30%以上。
1.3 微软在异构基础设施中的定位
Maia 200并非孤立存在的硬件,它是微软“异构AI基础设施”战略的重要一环。微软的思路是在Azure云平台中提供多元化的算力组合,而非单一路径。
在该体系中,NVIDIA的GPU依然是高性能训练和尖端推理的重要支柱。而Maia 200作为自研的定制化ASIC(专用集成电路),主要承载微软内部的大规模推理负载,如GPT-5.2、Microsoft 365 Copilot以及Superintelligence团队的合成数据生成任务。通过这种自研芯片与第三方顶尖硬件的协同,微软能够更灵活地调配成本和资源,确保其云基础设施在推理经济性上处于领先地位。
2. 硬件基础:工艺节点与关键规格
2.1 TSMC 3nm工艺与大规模集成
Maia 200是微软首款采用台积电(TSMC)3nm制程工艺制造的AI加速器。这一领先工艺的应用,使得Maia 200能够在有限的芯片面积内集成远超前代的晶体管数量,从而在提升主频的同时显著降低了单位算力的功耗。
作为一款针对推理任务定制的ASIC,其物理设计更倾向于高密度的计算阵列与庞大的片上缓存。相比通用GPU,3nm工艺带来的漏电流控制和动态功耗优化,使得Maia 200能够在更严苛的热设计功耗(TDP)限制下,维持更长的高频运行时间。
2.2 核心性能指标:FP4与FP8的极致压榨
在计算精度上,Maia 200引入了对窄精度格式(Narrow Precision)的原生支持。推理任务对精度的敏感度通常低于训练,因此通过降低位数来换取吞吐量是提升效率的关键。
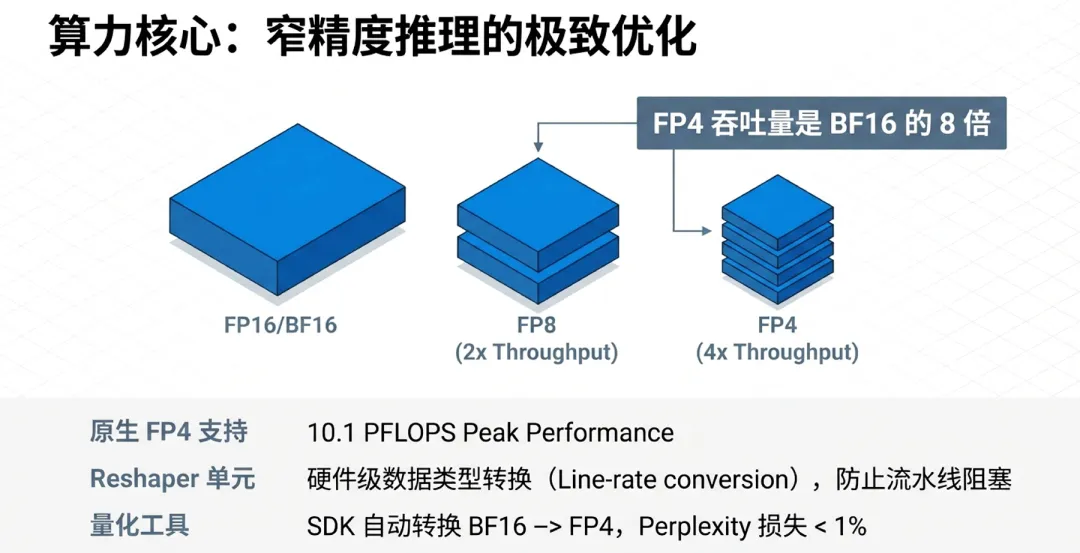
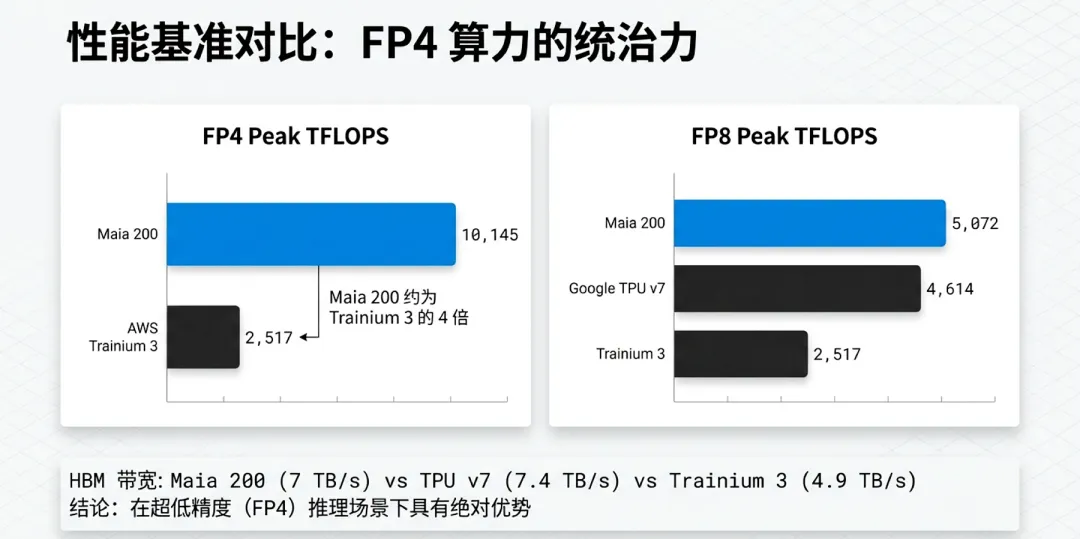
FP4性能:Maia 200拥有专门设计的FP4张量核心(Tensor Cores)。在FP4精度下,其峰值计算性能达到了惊人的量级。根据对比测试,其FP4推理性能是亚马逊第三代Trainium加速器的3倍。这种极低精度的支持,使得在处理大规模语言模型(LLM)时,能够在不显著损失精度的情况下,将吞吐量翻倍。
FP8性能:在主流的FP8精度下,Maia 200的性能表现同样优异,其吞吐能力甚至超过了Google第七代TPU。这意味着Maia 200在当前的量化标准下,依然拥有极强的普适性和竞争力。
2.3 功耗管理与能效比分析
能效比(Performance per Watt)是衡量推理芯片好坏的最终标尺。Maia 200的设计目标不仅是快,更是省。
热设计功率(TDP):尽管拥有顶级算力,Maia 200通过精细的功率门控(Power Gating)和频率调节机制,实现了优异的能耗控制。
能效水平:在FP4精度下,Maia 200可实现约13.5TFLOPS/W的能效表现。这使得在大规模机柜部署时,能够大幅降低数据中心的电力配套压力和散热成本。
2.4 与主流加速器的规格横向对比
为了更直观地体现Maia 200的地位,以下是与行业主流产品的关键规格对比:
规格维度 | Microsoft Maia 200 | NVIDIA Blackwell (B200) | Google TPU v7 (预估) |
工艺节点 | TSMC 3nm | TSMC 4NP | 3nm级别 |
内存容量 | 216GB HBM3e | 192GB HBM3e | 约150GB+ |
内存带宽 | 7 TB/s | 8 TB/s | 未公开 |
FP4性能 | 顶尖 (3x vs Trainium3) | 高 | 中高 |
主要定位 | 云端大规模推理 | 通用训练/推理 | 谷歌服务自用/推理 |
通过对比可见,Maia 200在内存容量和针对窄精度的优化上展现出了极强的后发优势,特别是在216GB HBM3e的支持下,其单卡承载超大模型的能力处于行业顶尖水平。
3. 芯片微架构详解
3.1 层次化架构:Tile、Cluster到Die
Maia 200的架构设计遵循了高度模块化和层次化的原则,以应对大规模并行计算的需求。
计算单元(Tile):芯片的基础计算单元是Tile。每个Tile都是一个功能完整的处理节点,包含了独立的执行引擎、本地SRAM缓存以及同步控制逻辑。这种设计确保了计算的局部性,减少了不必要的数据长距离搬运。
集群(Cluster):多个Tile组合成一个Cluster。在Cluster层级,硬件提供了更高速的数据共享机制和集合通信支持。通过这种层级组织,Maia 200能够灵活地在不同的模型切片(Sharding)之间分配算力。
全局集成:最终,大量的Cluster分布在3nm的大面积硅片(Die)上,通过高带宽的片上网络(NoC)进行互联,形成了一个庞大的算力池。
3.2 双执行引擎:TTU与TVP的协同
Maia 200微架构中最具创新性的设计是其内部的“双子星”引擎架构。针对深度学习任务中的不同计算特质,它将计算任务剥离给两个专用的处理器核心:
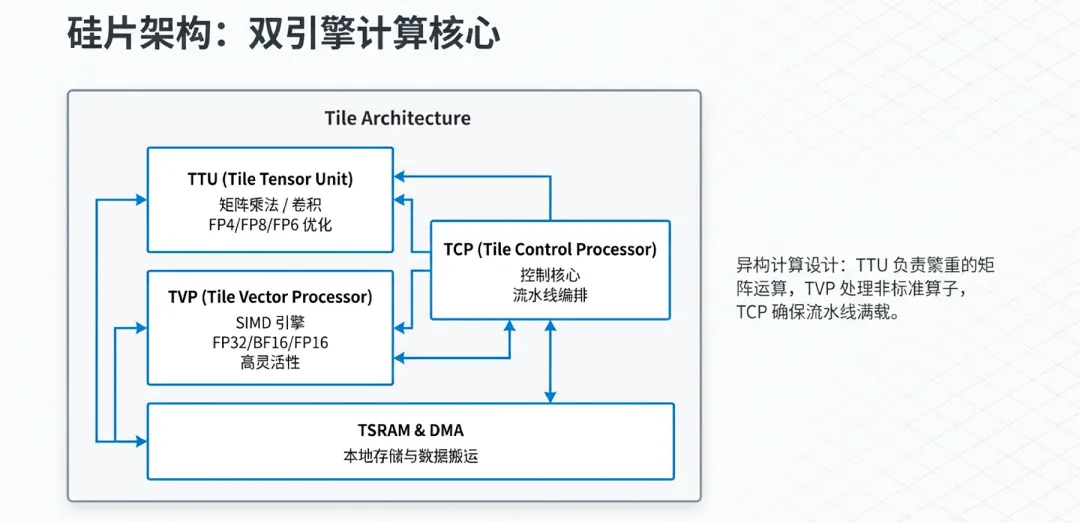
3.2.1 张量任务加速器(TTU - Tensor Task Unit)
TTU是Maia 200的“算力大户”,专门为密集型矩阵运算(如GEMM)设计。
核心功能:驱动原生的FP8和FP4张量核心。
优化重点:TTU拥有极高的算力密度,通过优化的流水线设计,它可以在极低周期内完成大规模张量乘法,是处理LLM中Attention机制和全连接层的主力。
3.2.2 向量与预处理引擎(TVP - Tensor Vector Processor)
TVP是一个高度灵活的向量处理器,负责处理张量运算之外的“细碎”任务。
核心功能:处理激活函数(如GeLU、Silu)、层归一化(LayerNorm)、旋转位置编码(RoPE)以及数据重塑(Reshape/Transpose)任务。
软件可编程性:与固化逻辑的TTU不同,TVP具有更强的可编程性,允许开发者通过代码定义复杂的算子。
协同机制:在实际运行中,TTU和TVP是异步并行的。当TTU还在进行密集的矩阵运算时,TVP可以预先准备下一层的数据或处理当前层的非线性变换,从而消除计算盲区。
3.3 同步机制与数据重塑支持
在高性能推理中,计算单元之间的同步开销往往是性能杀手。Maia 200在硬件层面引入了精细的同步原语:
硬件同步:Tile之间通过硬件信号量实现微秒级的快速同步,避免了传统的软件轮询或中断带来的延迟。
原子操作与数据重塑:架构中集成了专门的数据重塑硬件支持。在模型推理中,经常需要改变数据的维度(如从[Batch, Seq, Head, Dim]转换为[Batch, Head, Seq, Dim]),Maia 200的TVP和DMA系统可以在数据从SRAM移动到寄存器的过程中,“顺便”完成这种格式转换,实现近乎零开销的数据重组。
4. 内存系统的结构与优化
4.1 层次化存储架构:从HBM到片上SRAM
Maia 200采用了典型的两级内存层次结构,旨在最大化减少数据从外部内存向计算核心移动的开销。
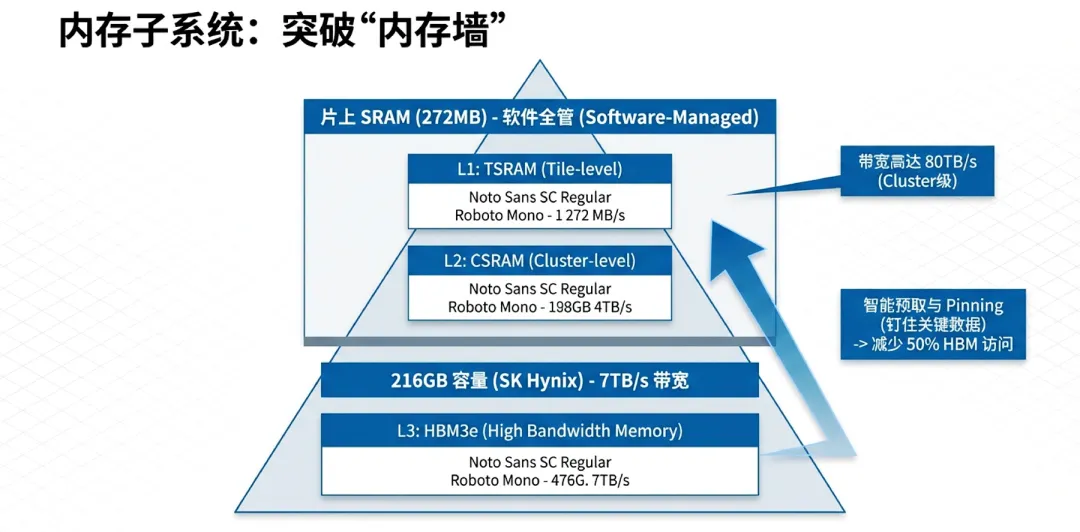
片上SRAM(272MB):相比于通用GPU较小的L1/L2缓存,Maia 200配备了高达272MB的片上SRAM。这并非简单的缓存,而是可以由软件直接管理的暂存存储器(Scratchpad Memory)。这种设计允许编译器显式地控制数据驻留,确保推理过程中的频繁读写(如KV Cache的中间状态)尽可能留在片上,避免昂贵的HBM访问。
HBM3e主存:外挂内存方面,Maia 200集成了216GB的HBM3e。这在当前自研芯片中属于顶级配置,其总带宽达到7 TB/s。大容量设计意味着它可以单卡装载更大规模的参数量,或者在处理长上下文(Long Context)时提供更充裕的缓存空间。
4.2 独家供应:SK Hynix的12层堆栈技术
Maia 200的内存系统拥有深厚的供应链整合背景:
技术规格:每个加速器封装了6个由SK Hynix提供的12层(12-high)HBM3e堆栈。
供应优势:SK Hynix是该领域目前的领先供应商。微软通过独家供应协议,确保了在大大规模部署阶段HBM内存的稳定性。216GB的容量不仅超过了NVIDIA H100,甚至在密度上也极具竞争力,为万亿参数模型的推理提供了坚实的物理基础。
4.3 窄精度存储格式与硬件转换机制
为了进一步提升内存效率,Maia 200实现了“存储与计算”的精度分离优化:
FP4/FP8原生存储:硬件支持以窄精度格式直接存储激活值和权重。这意味着同样的内存容量可以存放比FP16精度多2到4倍的数据。
硬件即时转换:内存控制器中集成了转换逻辑,当数据从HBM移动到Tile内部的计算引擎时,硬件可以自动完成精度的解压或对齐操作,而不需要消耗额外的计算周期。这种“边搬运边转换”的机制是Maia 200实现高吞吐量的秘诀之一。
4.4 推理负载中的实际应用:KV Cache优化
在LLM推理(尤其是生成式任务)中,KV Cache的管理是决定延迟的关键。
大内存的红利:216GB的内存容量使得Maia 200能够支持超长的Token序列(如128k甚至更高),而不会因为内存溢出导致推理中断。
带宽利用率:凭借7 TB/s的带宽,Maia 200在处理Batch Size较大的批量推理任务时,能够更快速地加载权重,显著降低了每个Token生成的延迟(Time Per Output Token),这对于提升Copilot等交互式产品的用户体验至关重要。
5. 数据移动与片上网络
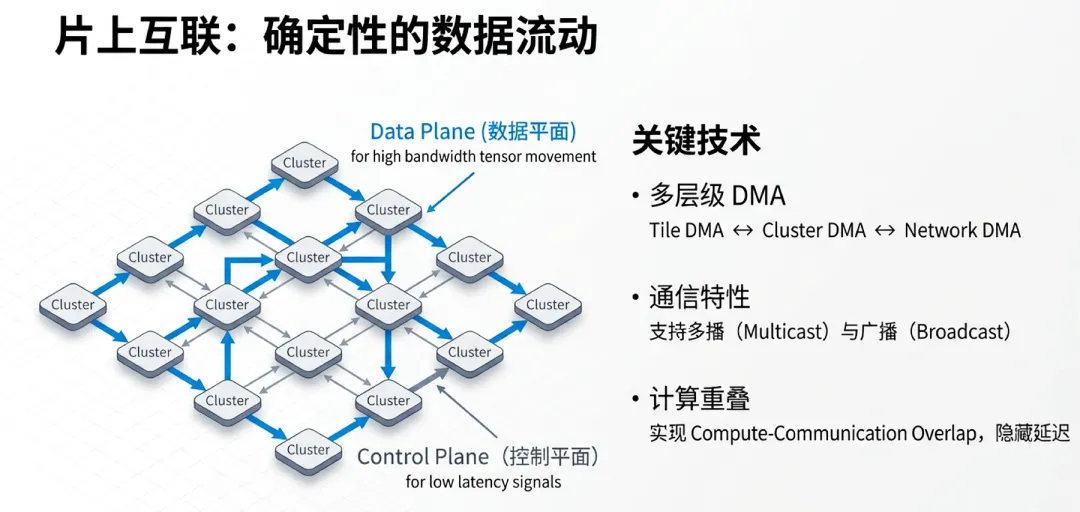
5.1 分层DMA子系统与多维数据管理
Maia 200设计了一套高度精密的分层直接内存访问(DMA)子系统,专门应对AI推理中频繁且复杂的数据搬运需求。
多维数据传输支持:不同于传统只支持一维连续内存拷贝的DMA,Maia 200的DMA引擎原生支持1D、2D甚至多维(ND)的数据描述。这意味着它可以直接处理张量切片(Slicing)、步进(Strided)读取等操作。
异步搬运机制:DMA系统与计算引擎完全解耦。在TVP或TTU执行当前指令的同时,DMA已经在后台并行地将下一批次所需的权重或KV Cache数据从HBM预取到SRAM。这种深度流水线化(Pipelining)的设计,最大程度地掩盖了内存访问延迟。
5.2 NoC架构:逻辑平面与流量分离
Maia 200的片上网络(NoC, Network-on-Chip)是连接Tile、Memory Controller和I/O接口的“高速公路”。
逻辑平面分离:为了防止不同类型的通信互相干扰,NoC在物理上支持多个逻辑通信平面。例如,权重的读取(高带宽需求)和指令控制流(低延迟需求)运行在不同的虚拟通道上。这种流量分离确保了关键控制信号不会被海量的数据搬运阻塞。
高并发带宽:NoC的设计不仅考虑了点对点延迟,更优化了全局聚合带宽。它支持数以百计的Tile同时发起内存请求,并能通过复杂的仲裁机制确保每个Tile的服务质量(QoS)。
5.3 针对推理任务的特定优化
Maia 200在数据移动层面引入了几项专门针对LLM推理优化的技术:
硬件级广播(Broadcast):在模型并行(Model Parallelism)中,经常需要将同样的张量分发到多个计算核心。Maia 200支持在NoC层面直接进行硬件广播,只需一次内存读取操作,即可同时填充多个Tile的SRAM,极大降低了内部带宽消耗。
QoS优先级保障:推理任务对延迟非常敏感。Maia 200的数据通路支持优先级调度。例如,当系统正在进行后台的权重预加载时,如果前方出现紧急的Token生成请求,NoC会优先分配带宽给延迟敏感型任务,确保交互式Copilot响应的流畅性。
5.4 软硬件协同:由编译器驱动的数据编排
不同于通用GPU依赖复杂的硬件缓存调度算法,Maia 200的数据移动很大程度上是由其软件栈(编译器)静态编排的。
确定性路径:编译器在编译阶段就计算好了每个数据块何时移动、存放在SRAM的哪个位置。这种确定性排布消除了硬件动态调度带来的不确定性震荡,使得Maia 200在处理高吞吐量负载时,其性能表现极为稳定,几乎不出现不可预见的掉速。
6. 扩展网络与互连技术
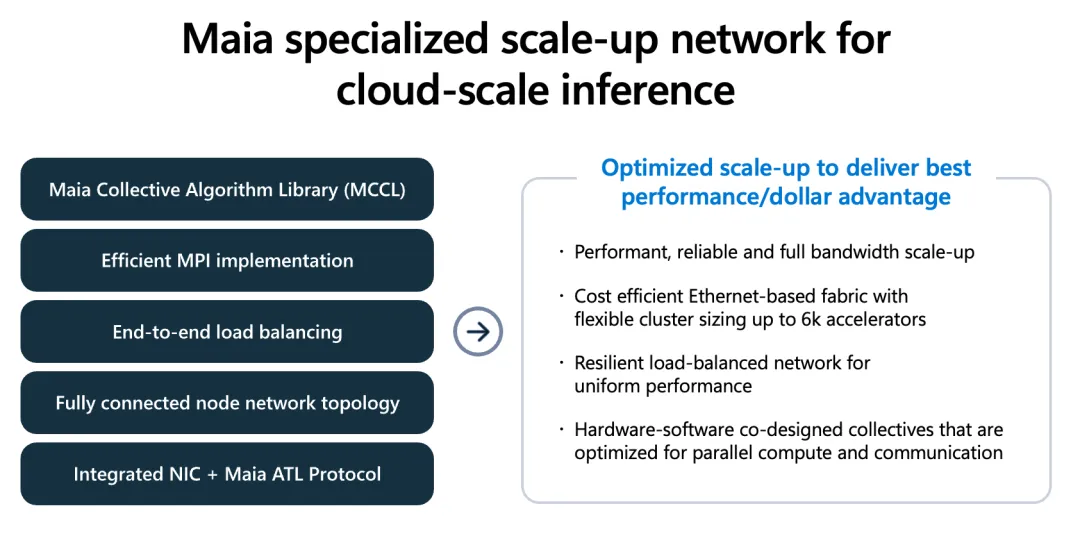
6.1 集成网卡与 ATL 协议:软硬一体的互连革命
Maia 200与通用GPU最大的不同之一,在于它将网卡(NIC)直接集成到了芯片封装内部,而不是通过PCIe总线连接外部网卡。
减少跳转(Hop Reduction):集成NIC设计消除了传统架构中CPU参与数据转发带来的延迟,使得芯片到芯片(Chip-to-Chip)的通信路径最短化。
ATL协议(Azure Transport Layer):微软为Maia开发了专门的ATL协议。相比传统的TCP/IP或普通的RoCE,ATL协议移除了大量针对通用互联网设计的冗余校验,针对数据中心内部的AI流量进行了极致精简。它支持硬件级的可靠传输(Reliable Transport)和拥塞控制,确保在大规模并发通信时不会出现数据包丢失导致的计算停顿。
6.2 两级拓扑:FCQ与交换级扩展
为了支持数以万计的芯片互连,Maia 200采用了高效的两级网络拓扑结构:
FCQ(Fully Connected Quad):在机架内部,每四个Maia 200加速器通过超高带宽的直接互连形成一个“全连接四元组(FCQ)”。在这个范围内,芯片间的数据交换速度极快,适用于算子内部的张量并行(Tensor Parallelism)。
二层交换扩展:FCQ之外,通过自研的交换机系统,成百上千个FCQ被组织成大规模集群。这种设计平衡了本地通信的极致带宽与全局扩展的可伸缩性,使得整个数据中心可以被视为一个巨大的“逻辑超级计算机”。
6.3 微软集合通信库(MCCL):算法与计算重叠

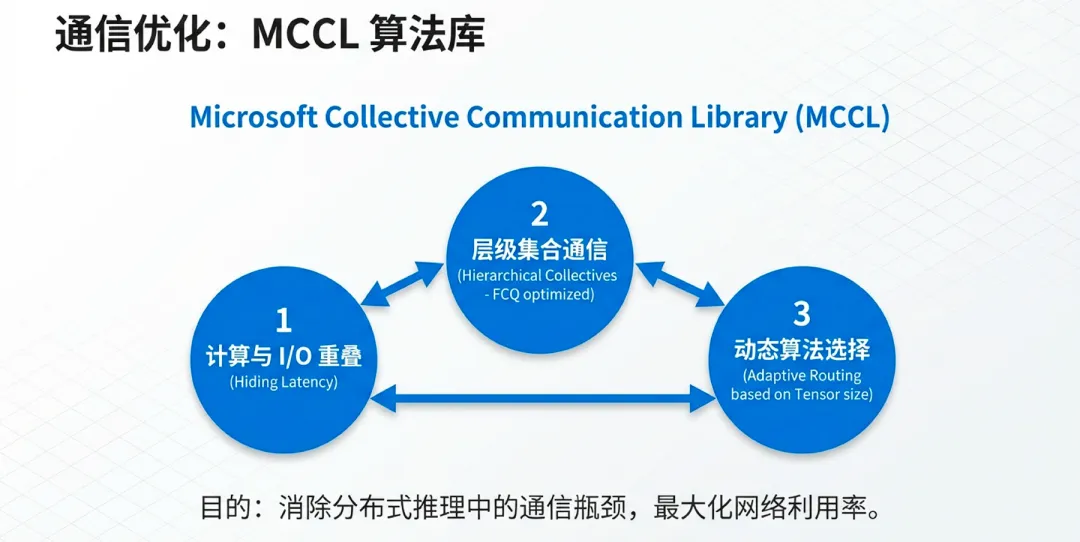
硬件互连需要软件库的配合才能发挥威力。微软推出了MCCL(Microsoft Collective Communication Library),它是针对Maia架构深度优化的集合通信操作库。
算法优化:MCCL针对All-Reduce、All-To-All等常用AI算子进行了拓扑感知(Topology-aware)优化。它能自动识别数据是在FCQ内部流动还是需要跨机架传输,并选择最优路径。
通信与计算重叠(Overlapping):凭借Maia 200独立的DMA和网卡引擎,MCCL可以在TTU执行矩阵计算的同时,异步处理跨节点的数据交换。通过这种“计算不等待通信”的策略,系统整体的有效利用率(MFU)提升了15%以上。
6.4 规模化部署下的可靠性与鲁棒性
在万卡级别的集群中,任何一个节点的微小故障都可能导致任务崩溃。
自愈能力:ATL协议和MCCL配合,支持快速路径重路由。如果某个交换端口出现异常,系统可以在微秒级感知并自动绕行,无需重新启动整个推理任务。
确定性延迟:由于采用了定制协议和专用网络硬件,Maia 200集群展现出了极高的延迟确定性(Deterministic Latency)。这对于需要严格实时响应的Copilot应用至关重要,避免了因为网络拥塞导致的“打字机式”回复卡顿。
7. 系统集成与部署考虑
7.1 机架规模架构(Rack-scale Architecture)
Maia 200的设计不仅仅局限于芯片本身,它被视为一个完整的“机架级计算机”。微软重新设计了整个机架结构,以最大化计算密度和资源利用率。
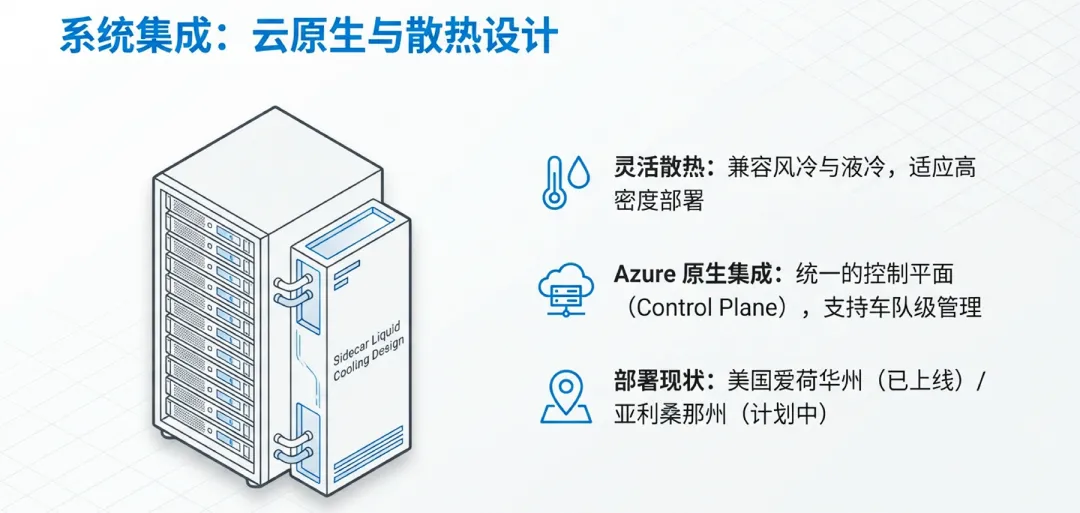
垂直整合设计:机架内部的供电、网络交换和液冷分配单元(CDU)均经过定制,专门匹配Maia 200的热特性和功耗曲线。这种紧凑的设计使得单个机架能够容纳比传统通用GPU机架更多的计算节点。
Sidekick散热模块:为了应对3nm芯片在高负载下的巨大发热,微软引入了名为“Sidekick”的配套散热系统。它像一个小冰箱一样紧贴在机架旁边,通过循环冷却液带走热量,确保芯片在进行大规模推理任务时不会因过热而降频。
7.2 全液冷设计:突破能效物理极限
在Maia 200的部署中,液冷(Liquid Cooling)不再是可选项,而是核心组件。
冷板集成:机架内的每个Maia 200节点都配备了定制的液冷冷板。相比传统的风冷,液冷能更均匀地导出HBM3e内存和计算核心产生的热量。
PUE优化:通过这种端到端的散热设计,微软显著降低了数据中心的制冷能耗。配合Maia 200本身的高能效比,整套系统的电源使用效率(PUE)达到了行业领先水平,直接转化为了更低的Token推理成本。
7.3 灵活的资源池化与电力分配
数据中心的电力供应是稀缺资源。Maia 200机架具备智能的电力动态分配能力:
峰值平抑:硬件和固件层级集成了灵敏的电流监测系统,能够根据实时负载调整工作电压。在处理突发的高并发推理请求时,系统可以短时间进入“加速模式”,而在空闲时则迅速降至超低功耗状态。
模块化部署:机架采用模块化设计,可以像积木一样快速部署到Azure全球的各个区域。这种标准化的基础设施确保了微软能够在全球范围内快速扩展其 AI 推理能力。
7.4 物理层与软件层的解耦与联动
虽然基础设施是物理的,但它与Azure的软件调度层深度联动:
热感知调度:Azure的资源调度器能够实时监控机架的温度状态。如果某个机架的冷却循环效率出现微小波动,调度器会自动将计算任务迁移到温度更低的区域,从而延长硬件寿命并保障服务的稳定性。
故障隔离:机架级的电源和网络冗余设计确保了即使单个机架内的某个组件失效,受影响的范围也会被限制在最小单元内,这对于承载Microsoft 365 Copilot这种关键业务至关重要。
8. 软件栈与开发工具
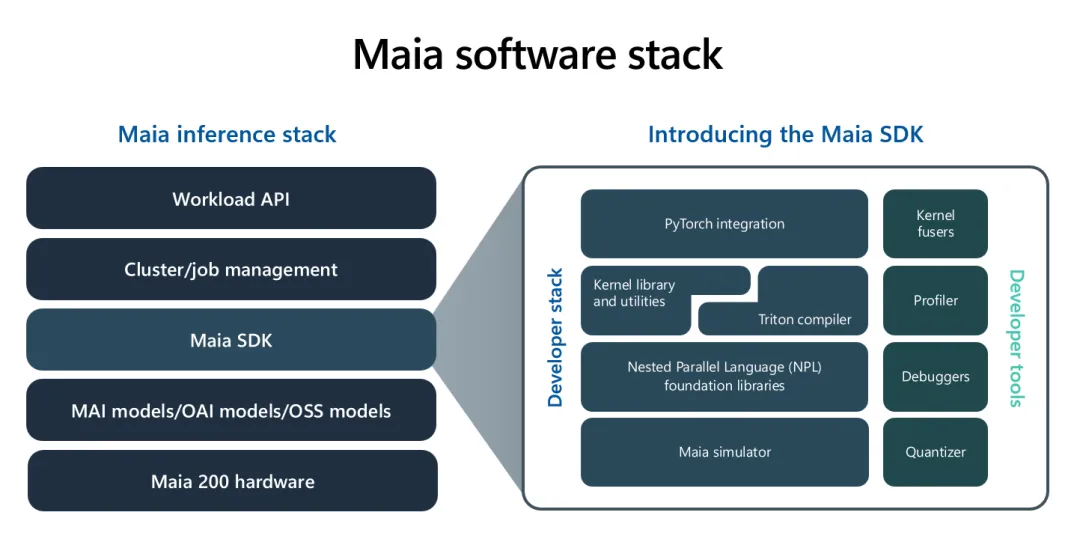
8.1 统一推理栈:从模型到硬件的无缝映射
Maia 200并非让开发者从零开始编写驱动,而是通过一层高度抽象且标准化的软件栈,将复杂的硬件特性隐藏在熟悉的编程框架之下。
PyTorch原生支持:微软开发了专门的设备后端,使得主流的PyTorch模型可以几乎“无感”地迁移到Maia 200上。开发者只需通过少量的配置更改,即可利用Maia的专用张量核心。
ONNX Runtime集成:作为微软自研的推理引擎,ONNX Runtime针对Maia 200进行了深度适配。通过图形重写(Graph Rewriting)和算子融合(Operator Fusion),它能自动将模型中的复杂子图合并为适合TTU和TVP执行的高效指令序列。
8.2 Triton编译器:打破ASIC的编程壁垒
为了解决ASIC灵活性不足的问题,Maia 200深度集成了OpenAI开源的Triton编译器。
高效算子生成:开发者可以使用类Python的语法编写高性能内核(Kernel)。Triton编译器会自动处理Tile管理、内存对齐以及TUP/TVP的任务调度。
减少手写汇编:相比于以往需要通过昂贵的人工手写CUDA或汇编代码,Triton使得在Maia上自定义算子变得极其高效。这确保了当新的AI模型架构(如不同变体的Attention机制)出现时,软件栈能迅速响应。
8.3 NPL:显式控制的数据并行语言
针对需要追求极致性能的底层专家,微软提供了嵌套并行语言(NPL, Nested Parallel Language)。
显式SRAM管理:开发者可以通过NPL直接控制数据在272MB片上SRAM和HBM3e之间的移动时机。这对于优化长上下文推理中的KV Cache管理具有决定性作用。
近乎巅峰的利用率:通过NPL进行精细调优,内核可以达到硬件理论峰值性能的90%以上,远超通用编译器的自动化水平。
8.4 开发者工具链与仿真环境
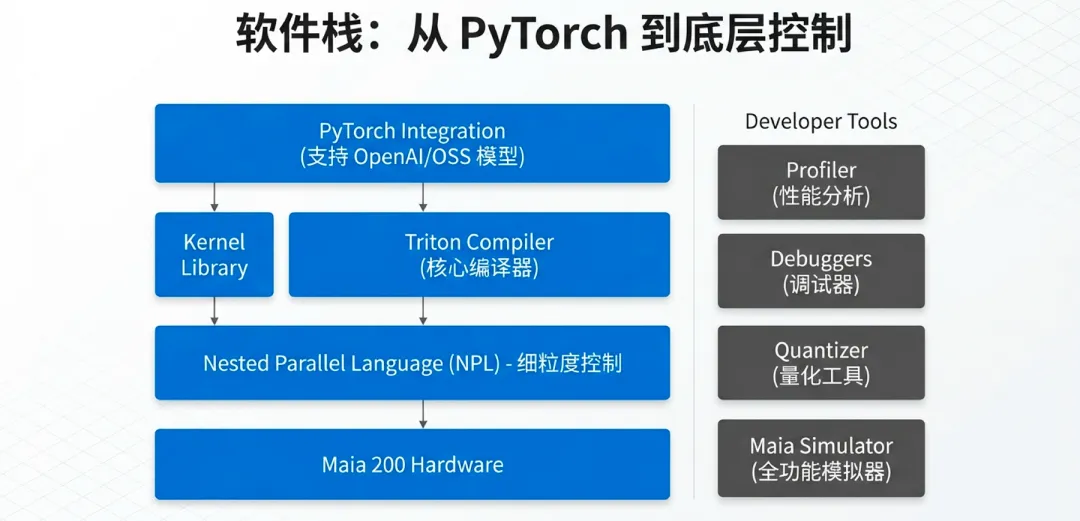
为了加速模型上线,微软提供了一套完整的开发辅助工具:
Maia模拟器:开发者可以在没有物理芯片的情况下,通过高度精确的周期级模拟器测试代码逻辑。
成本计算器(Cost Calculator):这是一个独特的工具,它能根据模型结构和预期的Batch Size,预估在Maia集群上运行的Token成本和延迟。
调试与性能剖析(Profiler):深度集成在Azure开发环境中的Profiler可以精确显示每一条指令在芯片内部的流动状态,帮助开发者找出NoC拥塞或计算气泡。
8.5 软硬协同:量化与验证套件
考虑到Maia 200 对FP4/FP8的强依赖,软件栈内置了强大的自动量化工具。它能在保持模型准确性的前提下,自动寻找最优的缩放因子(Scaling Factors),将 FP16 模型转化为能充分发挥芯片性能的窄精度格式。
9. 供应链分析与市场定位
9.1 供应链深度整合:以SK Hynix为核心的排他性保障
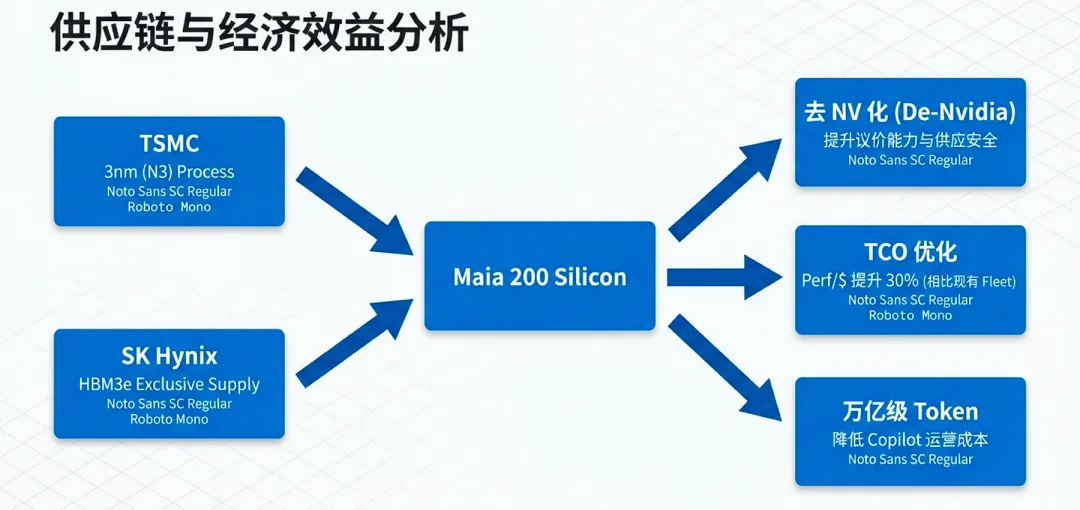
Maia 200的成功不仅依赖于微软的设计能力,更离不开底层半导体供应体系的支持。在HBM内存全球紧缺的背景下,微软采取了深度的纵向整合策略。
HBM3e独家供应:SK Hynix(SK海力士)是Maia 200最核心的硬件合作伙伴。每个加速器封装的6个12层(12-high)HBM3e堆栈均由其独家提供。这种深度绑定的供应协议,确保了微软在竞争对手面临“缺芯”困境时,能够维持稳定的出货和部署速度。
ASIC设计与制造:在3nm工艺上,微软与台积电(TSMC)保持了最优先级的协作。同时,虽然微软强调“内部设计”,但在底层物理设计与接口标准上,微软利用了成熟的ASIC产业生态(如与博通等公司的协作惯例),确保了芯片从流片到量产的高良率。
9.2 竞品对比:与NVIDIA、AWS及Google的技术博弈
Maia 200的设计指标极具针对性,旨在推理效率这一细分战场上“跳跃式”超越同行。
与NVIDIA (Blackwell)的对比:尽管NVIDIA在训练领域拥有统治地位,但Maia 200通过更专用的FP4张量核心和更大的216GB显存,在纯推理任务中实现了更优的单位美元性能。
与AWS (Trainium3)的对比:在FP4精度下,Maia 200的推理性能达到了亚马逊第三代Trainium加速器的3倍。
与Google (TPU v7)的对比:在主流的FP8吞吐量测试中,Maia 200的表现也超过了谷歌第七代TPU的预估水平。
这种对比表明,微软的策略是通过“后发优势”和“场景定制”,在特定的推理负载中建立起成本护城河。
9.3 核心应用方:OpenAI与微软超级智能团队
硬件的价值最终由顶层应用决定。Maia 200拥有全球最顶尖的“种子用户”:
OpenAI:作为微软最重要的战略伙伴,OpenAI深度参与了Maia 200的算力需求定义。Maia 200将首批承载GPT-5.2等新一代模型的推理压力。
微软超级智能团队(Superintelligence Team):由Mustafa Suleyman领导的团队正利用Maia 200进行大规模的合成数据生成(Synthetic Data Generation)和强化学习任务。这种“需求端驱动设计”的模式,使得芯片在研发阶段就能精准匹配未来模型的计算特性。
9.4 微软Foundry模式下的算力共享
微软并不仅将Maia 200视为自用工具,它还通过Microsoft Foundry模式向外部合作伙伴开放算力。
降低门槛:开发者可以通过Azure的特定区域访问基于Maia 200的计算实例,享受比传统GPU实例更低的Token计费。
生态闭环:通过向初创公司、研究机构提供Maia算力,微软正在构建一个基于自研芯片的软硬件闭环生态,进一步巩固其在AI基础设施市场的领导地位。
----------
参考文献:
Guthrie, S. (2026, January 26). Maia 200: The AI accelerator built for inference. The Official Microsoft Blog. https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/
Dighe, S., & Levin, A. (2026, January 26). Deep dive into the Maia 200 architecture. Azure Infrastructure Blog, Microsoft Tech Community. https://techcommunity.microsoft.com/blog/azureinfrastructureblog/deep-dive-into-the-maia-200-architecture/4489312
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)
