


最近一段时间,围绕 DeepSeek 的讨论极速升温。无论是即将到来的 V4 ,还是 Engram模块所代表的条件记忆思路,都在指向系统层面的可持续性发展方向。

从褐蚁的视角看,这一轮讨论的价值不在于某个模型是否领先,而在模型能力正在被拆解为多个可以独立优化的部分,记忆、推理、注意力和计算路径开始各自承担不同的工程角色。
Engram 所体现的,是一种系统转向路径。通过将部分模式重建和静态信息处理转移到可查找的记忆结构中,模型得以把更多算力留给推理本身。这种将记忆与推理解耦的思路,正在逐渐走上舞台,也正在改变部署侧的成本结构。
一旦记忆被外置,问题就不再只是模型怎么训得更好,而是系统如何承载这些能力。显存、内存、精度选择以及计算单元之间的分工,都会直接影响模型能否被稳定部署。
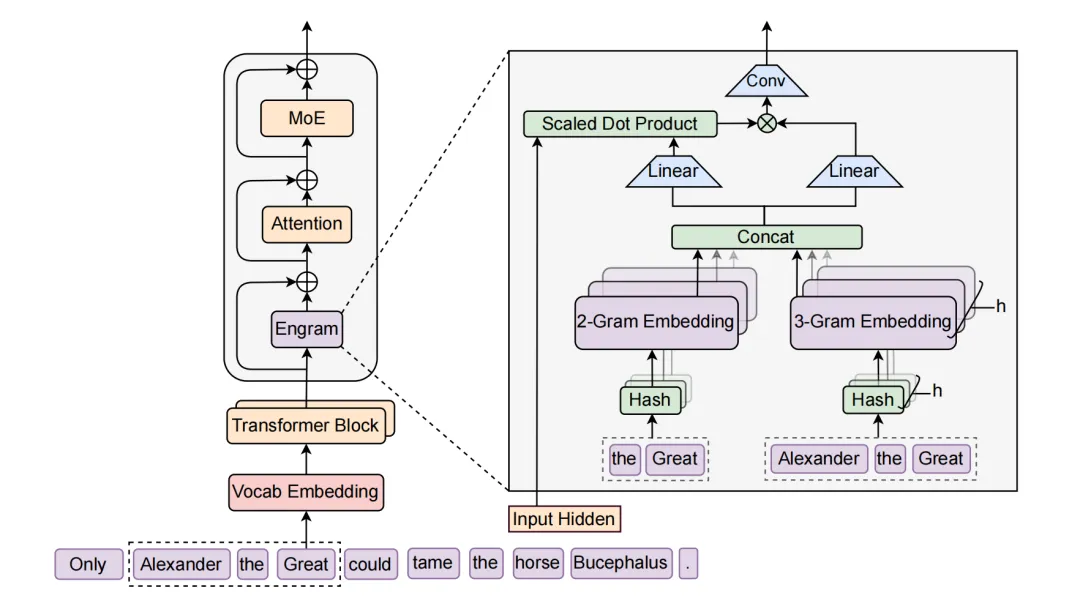
DeepSeek提出的Engram架构
这正是褐蚁长期关注的核心问题。在很多真实的本地部署环境中,模型并不是跑在理想化的无限算力条件下,而是运行在有限 GPU 数量、多卡协同和成本约束明确的系统中。工程挑战往往不来自模型本身,而来自精度与资源之间的错配。
工程挑战:精度与资源的平衡
随着 FP8 成为高端推理的常见选择,对某些ASIC硬件更友好的 int8 以及对推理加速更友好的 FP4 正在进入可讨论的工程区间。在部分新一代算力平台上,FP4 已经具备原生支持条件,这为进一步降低显存占用和部署成本打开了现实空间。但这一变化并不会自动转化为收益,前提是系统能够真正吃下这种精度结构。
与此同时,训练阶段的结构性设计开始显现长期价值。通过在训练阶段引入更合理的连接方式和约束机制,模型在后续推理和扩展中可以显著降低系统复杂度。这类设计往往不在发布时成为焦点,却决定了模型在真实环境中的表现上限。
从这个角度看,DeepSeek 所引发的讨论,更像是一面镜子。它让行业重新意识到,大模型竞争已经不再是单一性能指标的比拼,而是系统工程能力的较量。
大模型竞争不再是单一性能指标的比拼
对褐蚁而言,这一趋势并不陌生。真正的挑战从来不在于模型是否足够聪明,而在于如何让模型的能力以可控成本、可复制方式长期运行。当记忆被拆分,注意力被稀疏化,精度窗口被重新打开,系统级调度能力将成为决定性因素。
下一阶段的大模型基础设施,注定属于那些能够把模型变化转化为部署优势的系统方案。这一点,正在变得越来越清晰。
「?现在就来!」
立即扫描下方二维码,一键预约体验「褐蚁AI工作站」,极速了解详细产品配置、报价及私有化部署方案,便捷咨询下单!
