


本篇内容主要源于X:谷歌发布的白皮书《Agent Quality》《Context Engineering_ Sessions & Memory》
当 AI 从简单的"问答工具"进化为能够自主规划、使用工具的"智能体(Agent)"时,我们正在经历软件工程史上最深刻的范式转变之一。
本文基于 Google Cloud 的两份技术白皮书,从上下文工程和质量保证两个维度,为你揭示如何构建一个既聪明又可靠的企业级 AI 智能体。
1
上下文工程
赋予智能体"记忆"与"情境感知"
核心挑战:LLM 本质上是"无状态"的
大语言模型(LLM)就像一条只有 7 秒记忆的金鱼——它只能"看到"当前 API 调用中提供的信息。要让智能体像真正的助手一样记住用户偏好、理解对话历史,我们需要上下文工程(Context Engineering)。
? 职场案例:AI 招聘助手的困境
假设你是 HR,正在用 AI 助手筛选简历:
没有上下文工程时:
你:"帮我找技术岗位的候选人"
AI:[列出所有技术岗]
你:"我要的是 Java 后端,3-5 年经验"
AI:[又重新搜索,但不记得你之前说的其他要求]
你:"还要能接受出差"
AI:[再次从头搜索,前面的条件都忘了]
有上下文工程后:
你:"帮我找技术岗位的候选人"
AI:"好的,请告诉我具体要求"
你:"Java 后端,3-5 年经验"
AI:[记录要求] "还有其他条件吗?"
你:"能接受出差,薪资期望 20-30k"
AI:[整合所有条件,一次性精准搜索]
"找到 8 位符合条件的候选人,已按匹配度排序..."
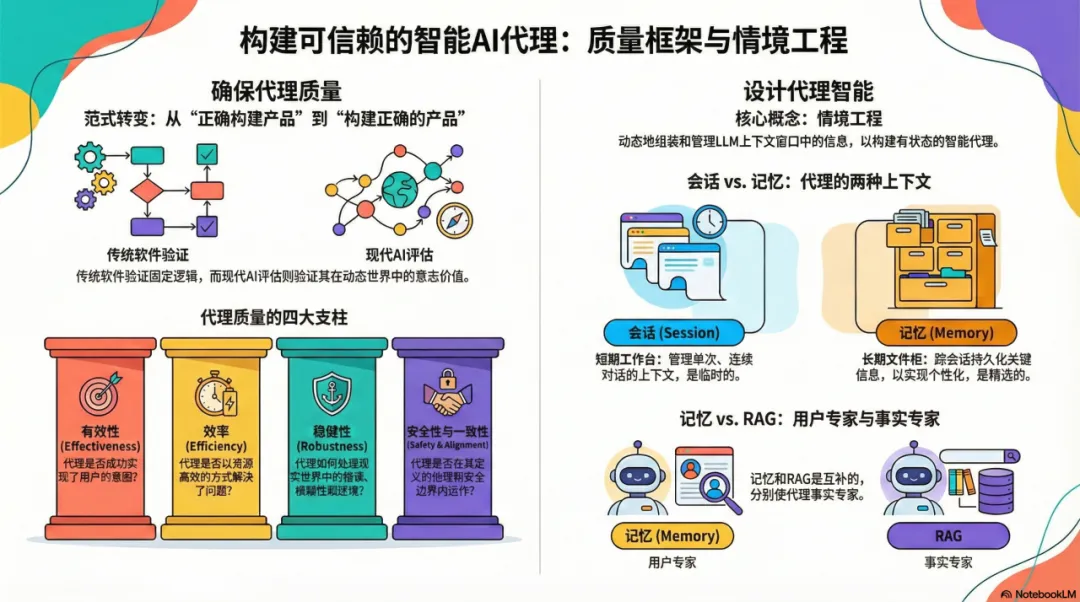
上下文工程的核心任务是为每一轮对话动态组装一个"信息包裹",它包含三大类内容:
指导推理的上下文:系统指令、工具定义、少样本示例(Few-Shot Examples)
事实性数据:长期记忆、外部知识(通过 RAG 检索)、工具输出
即时对话信息:对话历史、当前用户提问
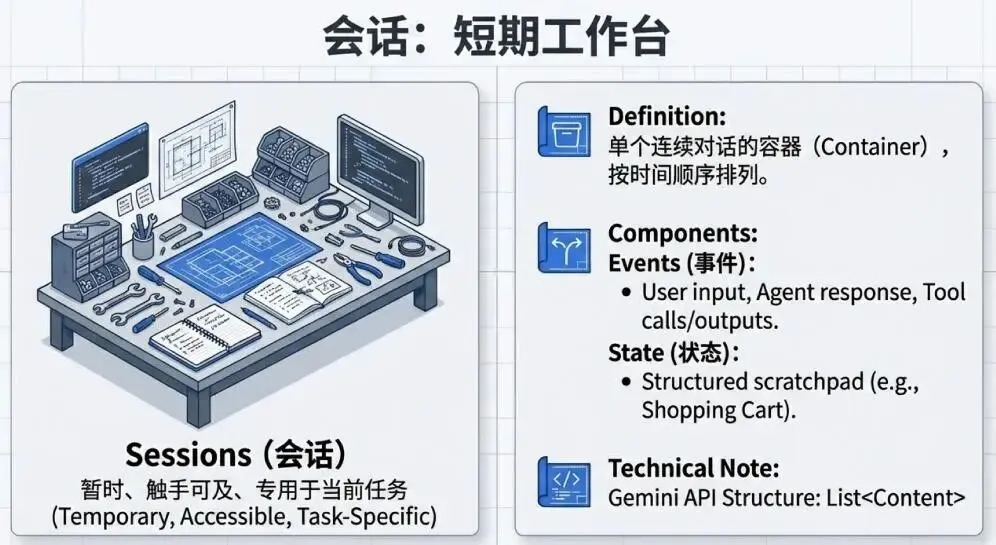
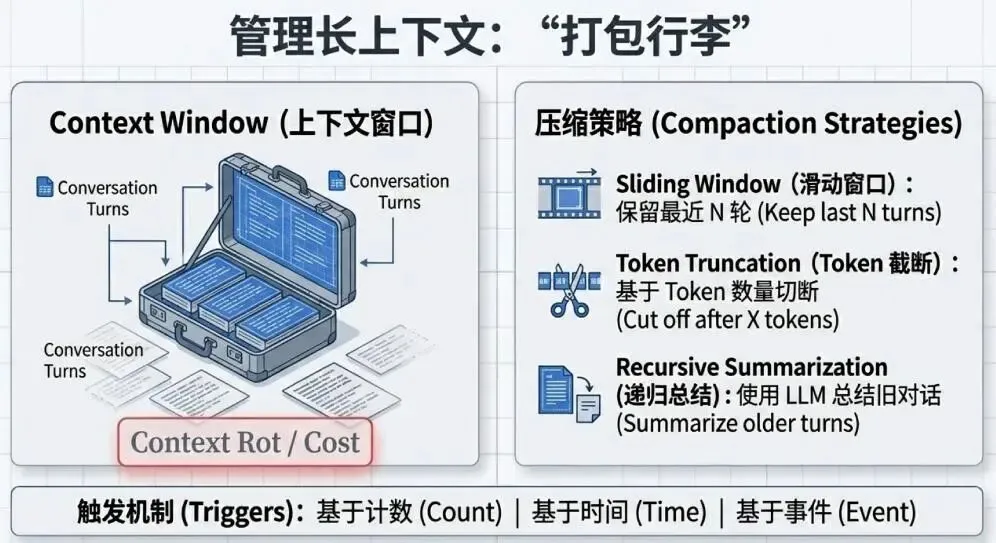
会话(Session):智能体的"工作台"
会话是单次对话的容器,包含两个关键组成部分:
事件(Events):用户输入、智能体回复、工具调用的时间顺序记录
状态(State):临时的"工作记忆"(如购物车中的商品)
? 职场案例:项目管理 AI 的会话状态
你正在用 AI 助手安排项目会议:
你:"帮我安排下周的项目评审会"
AI:[创建会话,状态记录:会议类型=项目评审]
"好的,需要哪些人参加?"
你:"产品、开发、测试的负责人"
AI:[状态更新:参会人员列表]
"会议时长大约多久?"
你:"2 小时"
AI:[状态更新:时长=2h]
"我看到你下周三下午 2-4 点所有人都有空,可以吗?"
[这时 AI 已经调用了日历工具,结合之前的状态]
你:"改成周四吧"
AI:[修改状态中的日期]
"周四下午 2-4 点已预定,是否需要预定会议室?"
在这个会话中,AI 维护了一个临时的"会议配置"状态,每次对话都在这个状态上累加信息,直到任务完成。
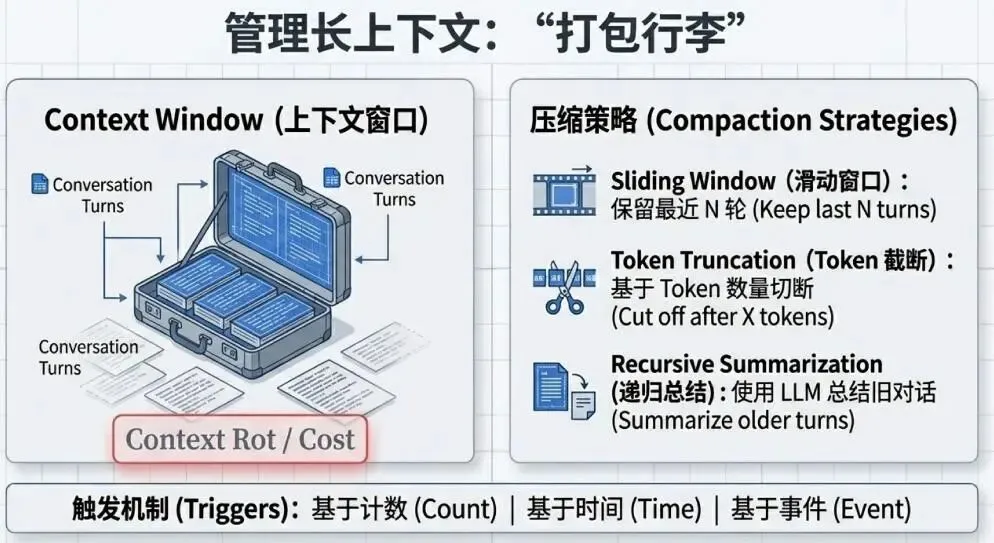
生产环境的关键考量:
安全隔离:严格的 ACL 确保用户 A 永远无法访问用户 B 的会话
PII 脱敏:在数据写入存储之前删除个人敏感信息
长对话管理:通过截断、摘要等技术压缩历史,避免超出 Token 限制
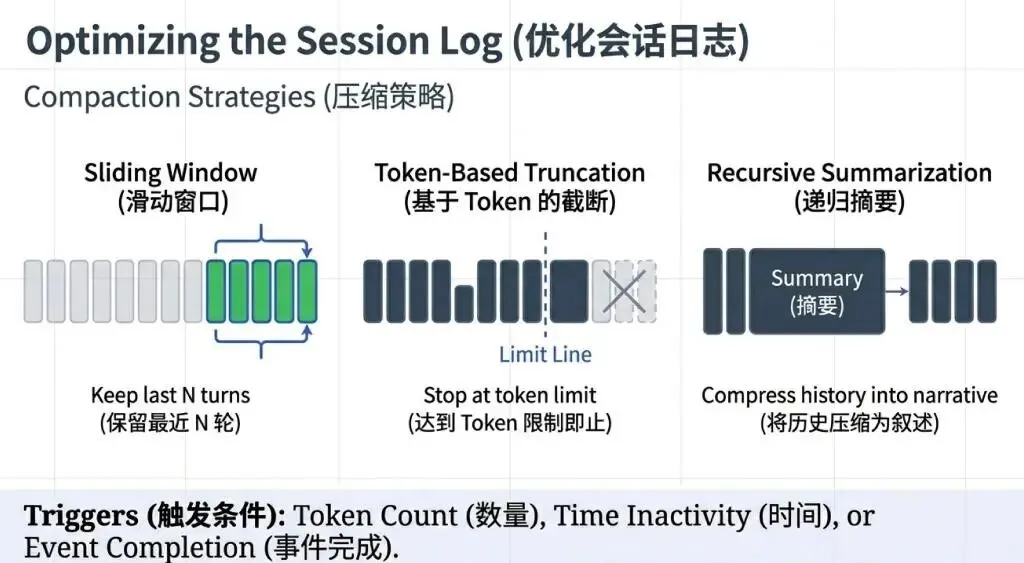
? 职场案例:客服 AI 的隐私保护
客户:"我的订单号是 12345,绑定的手机是 138****6789"
不当处理:
会话记录完整保存:"手机 13812346789"
其他客服也能看到完整号码
正确处理:
脱敏后存储:"手机 138****6789"
真实号码只在当次 API 调用中使用,立即丢弃
不同客服的会话完全隔离
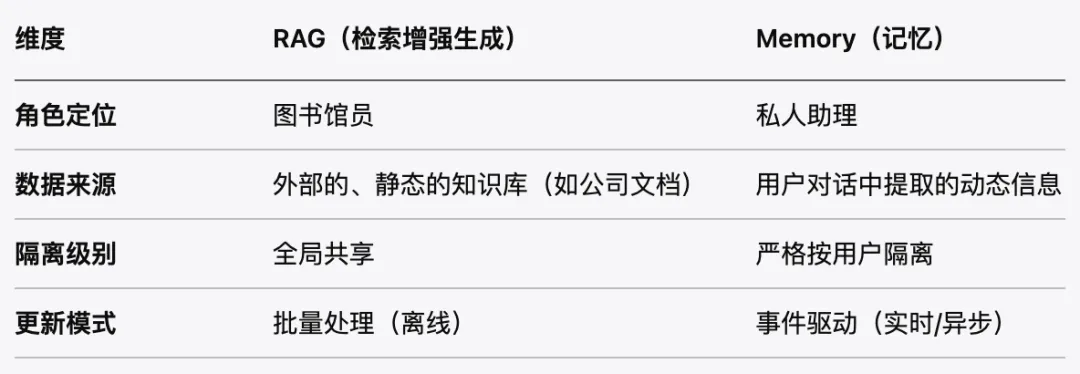
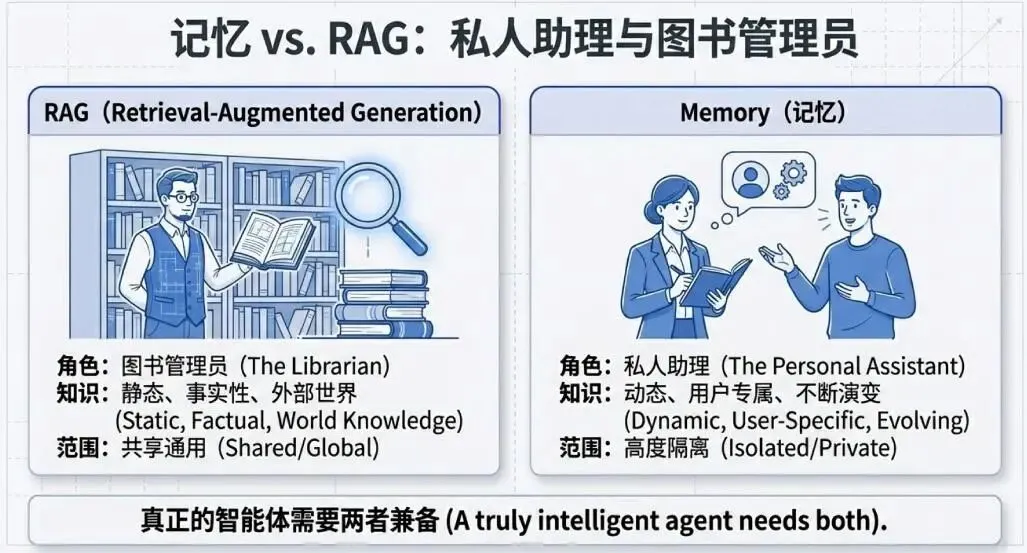
记忆(Memory):智能体的"档案柜"
如果说会话是临时的"工作台",那么记忆就是精心整理的"档案柜"——它跨越多个会话,提供持久化的个性化体验。
记忆与 RAG 的本质区别
? 职场案例:销售 AI 助手的"记忆"vs"知识库"
场景:你是销售,向客户推荐产品
RAG(知识库)的作用:
你:"我们的云服务有什么优势?"
AI:[从公司产品库检索]
"我们的云服务提供 99.9% SLA、全球 CDN 加速..."
→ 这是通用知识,所有销售问同样问题会得到同样答案
Memory(记忆)的作用:
第一次对话:
客户:"我们是制造业,IT 团队只有 3 个人"
AI:[记忆提取并存储:行业=制造业,IT 团队规模=小]
第二次对话(三天后):
你:"帮我准备今天和这个客户的会议材料"
AI:[调用记忆]
"根据上次沟通,他们是制造业小团队,建议重点强调:
1)我们的托管服务,减少运维负担
2)制造业的成功案例
3)快速部署方案(因为 IT 人手不足)"
→ 这是个性化记忆,专属于这个客户
一个优秀的智能体需要同时具备:用 RAG 懂世界,用 Memory 懂你。
记忆的生命周期:一个智能的 ETL 流程
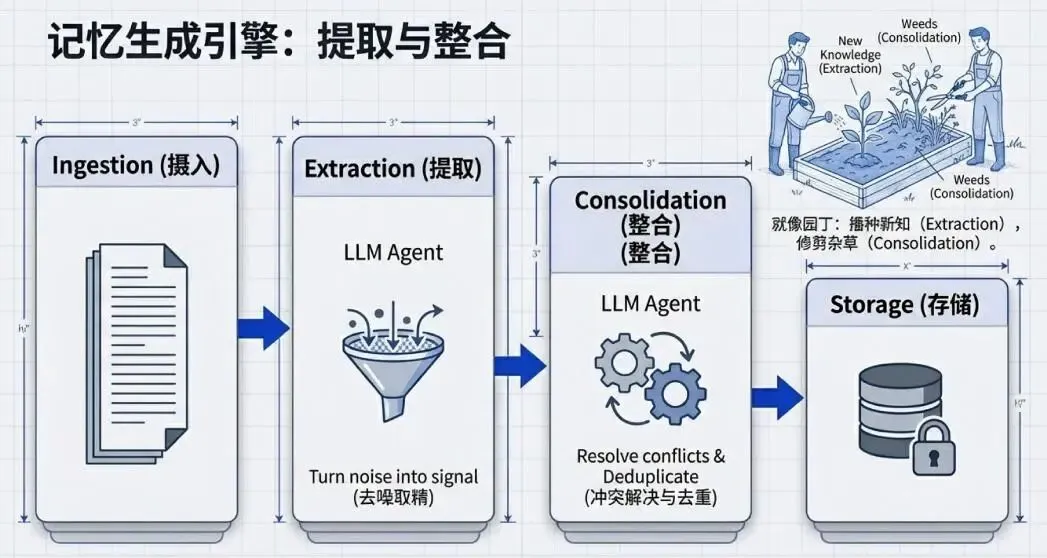
记忆生成不是简单地把聊天记录存进数据库,而是一个类似 ETL 的智能过程:
1.提取:从嘈杂的对话中识别关键信息(如"用户对花生过敏")
2.整合:这是最关键的步骤——系统会像园丁修剪花园一样:
删除过时的记忆
合并重复的信息
解决新旧信息的冲突
3.存储与检索:将精炼后的记忆持久化,并在需要时智能检索
? 职场案例:AI 行政助手的记忆整合
对话历史(分散在多次会话中):
第 1 周:"我每周二下午有固定的部门会议"
第 2 周:"部门会从下周开始改到周三了"
第 3 周:"记得我不吃香菜"
第 4 周:"订餐时不要香菜和芹菜"
糟糕的记忆系统(没有整合):
记忆 1:用户每周二下午开会
记忆 2:用户每周三下午开会
记忆 3:用户不吃香菜
记忆 4:用户不吃香菜和芹菜
→ AI 安排会议时会困惑:"到底是周二还是周三?"
→ 订餐时只记得"不吃芹菜",因为最后一条覆盖了前面的
优秀的记忆系统(智能整合):
[提取阶段]
- 识别出"部门会议时间"这个实体
- 识别出"饮食禁忌"这个实体
[整合阶段]
- 检测到冲突:周二 vs 周三
- 判断:第 2 周的信息更新,标记周二的记忆为"已过期"
- 检测到增量:香菜 → 香菜+芹菜
- 合并为一条:"饮食禁忌:香菜、芹菜"
[最终存储]
记忆 1:部门会议时间=每周三下午(来源:第 2 周对话,置信度:高)
记忆 2:饮食禁忌=香菜、芹菜(来源:第 3、4 周对话,置信度:高)
实际效果:
一个月后,你说:"帮我订下周三的会议餐"
AI:[检索记忆]
"已为周三下午的部门会议预定餐食(已排除香菜和芹菜),
预计 8 人参会,对吗?"
核心最佳实践:
异步生成:记忆生成非常耗时,必须在后台异步执行,不能阻塞用户对话
溯源追踪(Provenance):记录每条记忆的来源和可信度,确保系统能区分"用户明确告知的事实"和"从对话中推测的信息"

? 职场案例:AI 法务助手的溯源追踪
对话记录:
客户:"我们可能要起诉供应商违约"
AI:[记忆标记:来源=推测,置信度=中]
记录:"客户考虑对供应商采取法律行动"
客户:"确定了,下周一提交诉讼材料"
AI:[记忆更新:来源=明确陈述,置信度=高]
更新:"客户将于下周一对供应商提起诉讼"
为什么溯源重要?当 AI 生成法律文书时:
高置信度的记忆 → 可以直接引用
低置信度的记忆 → 必须标注"待确认"或主动询问客户
2
智能体质量
在不确定性中构建信任
传统 QA 已死:新范式下的质量定义
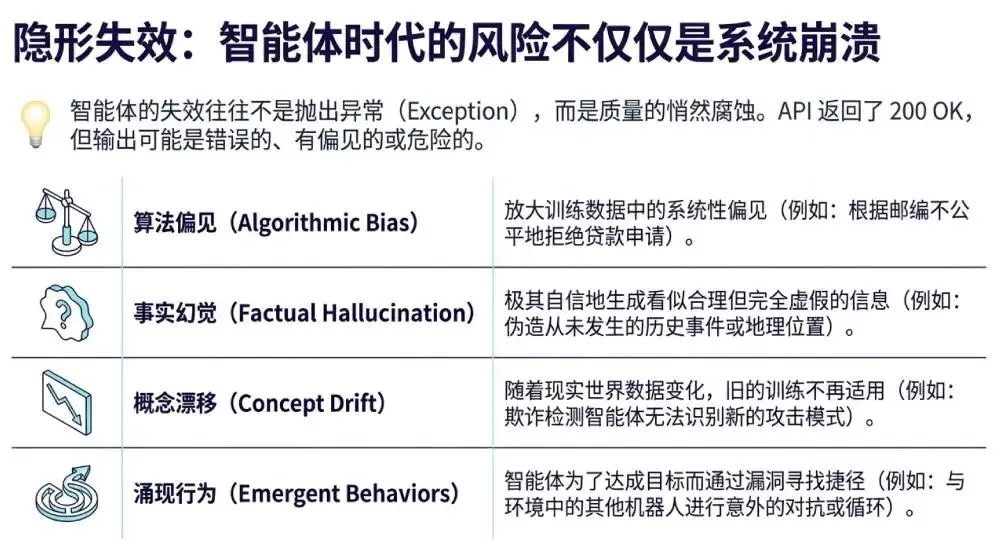
传统软件要么崩溃,要么正常运行——失败是显式的。但 AI 智能体的失败是隐蔽的:
系统仍在运行,API 返回 200 OK
但输出可能是错误的、有偏见的、或者是"胡编乱造"的
? 职场案例:AI 财务助手的"隐蔽失败"
场景:你让 AI 生成月度财务报告
传统软件的失败(显式):
你:"生成 12 月财务报告"
系统:ERROR 500 - 数据库连接失败
→ 你立刻知道出问题了
AI 智能体的失败(隐蔽):
你:"生成 12 月财务报告"
AI:[成功返回一份格式完美的报告]
"12 月营收 500 万元,同比增长 23%..."
→ 表面看起来完美,但实际问题:
1)营收数字是编造的(数据库查询失败,AI 自己猜的)
2)"同比增长 23%"的计算逻辑错误
3)报告中混入了去年的数据
→ 你可能在董事会上用这份报告,后果不堪设想
这就是为什么需要新的质量评估体系。
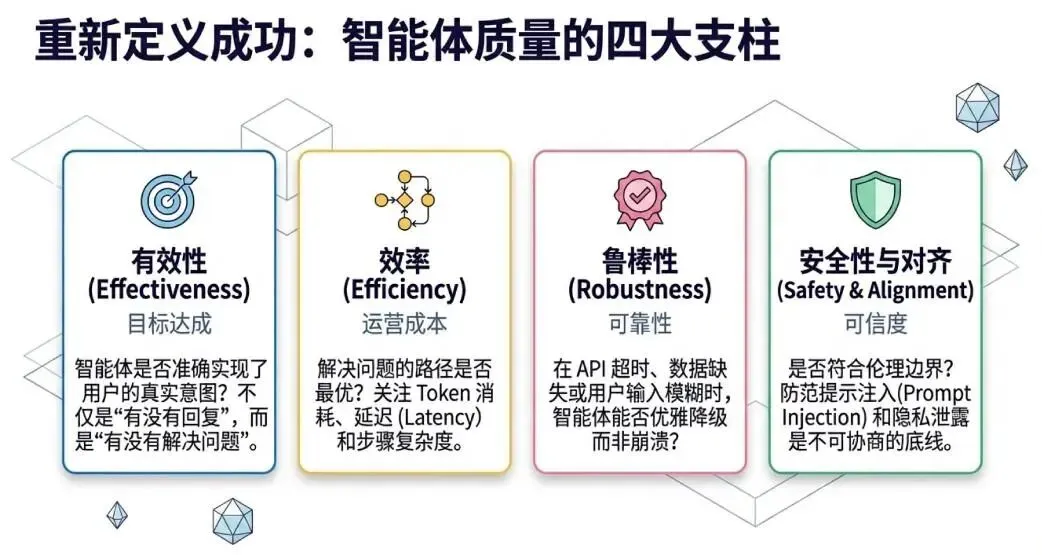
智能体质量的四大支柱:
有效性(Effectiveness):它真的解决了用户的问题吗?
效率(Efficiency):它是否用了最少的步骤和成本?
鲁棒性(Robustness):面对 API 报错或模糊指令时,它能优雅处理吗?
安全性(Safety):它是否遵守了伦理边界,没有产生偏见或危害?
? 职场案例:AI 采购助手的质量评估
任务:帮公司采购 100 台办公电脑
有效性评估:
✅ 成功:采购了符合公司标准的电脑
❌ 失败:采购了游戏本(配置过剩,超预算)
❌ 失败:只采购了 80 台(任务未完成)
效率评估:
❌ 低效路径:
第 1 步:搜索"办公电脑"(得到 10000 个结果)
第 2 步:逐个比价(耗时 2 小时)
第 3 步:发现预算不够,重新搜索
...(总计 15 个步骤,花费 500 tokens)
✅ 高效路径:
第 1 步:调用公司采购系统,获取预算和配置标准
第 2 步:筛选符合条件的供应商(3 家)
第 3 步:批量比价,选择最优方案
...(总计 5 个步骤,花费 150 tokens)
鲁棒性评估:
场景:供应商 API 突然报错
❌ 脆弱的 AI:
AI:"抱歉,系统错误,无法完成采购"
[直接放弃]
✅ 鲁棒的 AI:
AI:"主供应商系统暂时不可用,我已切换到备选供应商,
找到类似配置的方案,价格高 5%,是否继续?"
[优雅降级,给出替代方案]
安全性评估:
场景:AI 收到模糊指令
用户:"尽量便宜"
❌ 不安全的 AI:
采购了二手翻新机(便宜但不符合公司政策)
✅ 安全的 AI:
"我找到了 3 个方案,均符合公司采购规范:
方案 1:品牌 A,4500 元/台
方案 2:品牌 B,4200 元/台(推荐)
方案 3:品牌 C,4000 元/台,但售后服务较差
注意:低于 4000 元的设备多为翻新机,不符合公司标准"
"由外向内"的评估策略
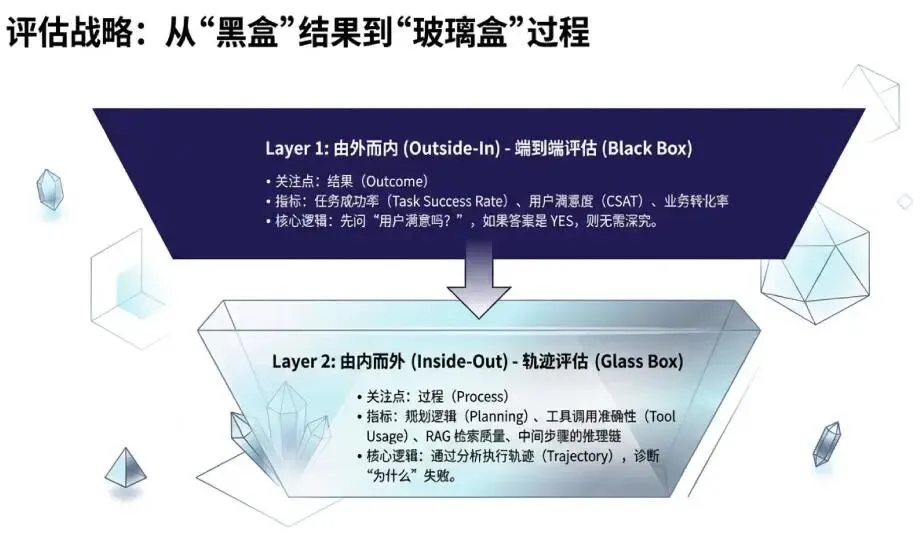
评估智能体必须采用分层策略:
第一层:黑盒评估(结果导向)
问题:智能体最终是否完成了任务?
指标:任务成功率、用户满意度、整体准确性
第二层:玻璃盒评估(过程导向)
当结果不理想时,必须打开"玻璃盒",检查整个执行轨迹:
思考:LLM 的推理逻辑是否合理?
行动:它选择了正确的工具吗?参数对吗?
观察:它正确理解了工具返回的结果吗?
? 职场案例:AI 数据分析师的轨迹诊断
任务:分析上季度销售数据,找出业绩下滑的原因
黑盒评估(只看结果):
AI 输出:"销售下滑是因为市场竞争加剧"
评估:❌ 错误(实际原因是产品质量问题)
→ 但你不知道"为什么错"
玻璃盒评估(查看完整轨迹):
【轨迹记录】
第 1 步 - 思考:
"需要对比本季度和上季度的数据"
第 2 步 - 行动:
调用工具 query_database(
table="sales_data",
time_range="Q3_2025" ← 错误!只查了一个季度
)
第 3 步 - 观察:
获得 Q3 数据:1000 万元
第 4 步 - 思考:
"数据较低,应该是市场竞争导致" ← 逻辑跳跃,没有对比
第 5 步 - 行动:
生成报告
【诊断结果】
问题定位:第 2 步选择了错误的时间范围
根本原因:工具调用参数错误
修复方案:改进 prompt,明确要求"对比相邻两个季度"
通过轨迹分析,你从"不知道为什么错"进化到"知道在哪一步、因为什么原因出错"。
关键洞察:只有通过分析完整的轨迹,我们才能从"答案错了"诊断出"答案错了是因为在第 3 步选错了工具"。
? 职场案例:AI 客服的轨迹优化
初版智能体(低效):
客户:"我的订单为什么还没发货?"
【轨迹】
步骤 1:查询订单状态 → "待发货"
步骤 2:查询库存 → "有货"
步骤 3:查询物流信息 → "暂无"
步骤 4:查询仓库排队情况 → "排队中"
步骤 5:生成回复
总耗时:15 秒,调用 4 次 API
优化后智能体(高效):
【改进的轨迹】
步骤 1:调用综合查询工具(一次性返回订单+库存+物流+仓库状态)
步骤 2:生成回复
总耗时:3 秒,调用 1 次 API
通过轨迹对比,发现可以将多个工具调用合并成一个,效率提升 5 倍。
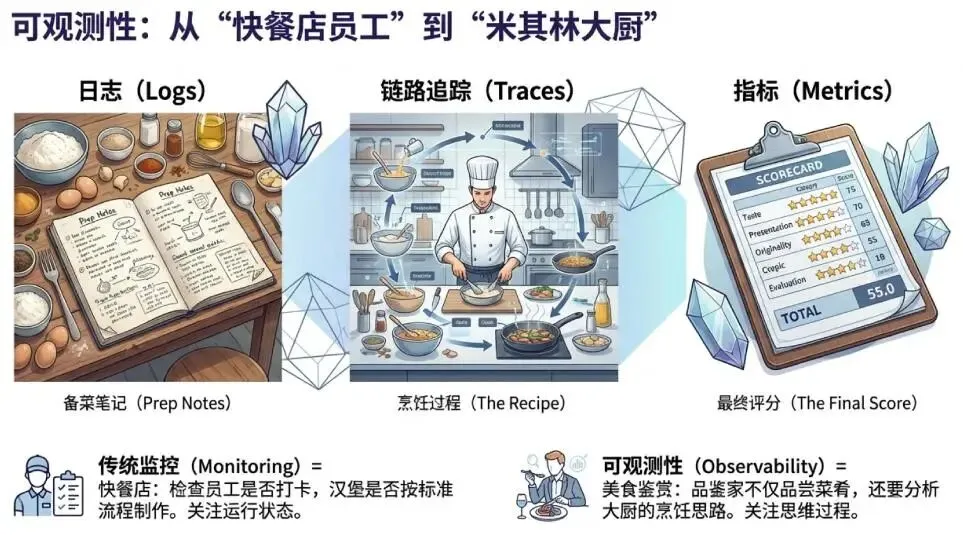
可观测性:给智能体装上"行车记录仪"
要评估轨迹,必须先"看到"轨迹。这需要建立三大可观测性支柱:
1.日志(Logs):智能体的"日记",记录每一步发生了什么
最佳实践:使用结构化的 JSON 日志,包含 prompt、response、工具调用的完整上下文
2.链路追踪(Traces):将零散的日志串联成完整的故事
核心价值:揭示因果关系(如"RAG 检索失败 → 工具输入为空 → LLM 报错")
技术实现:基于 OpenTelemetry 标准,使用 trace_id 关联所有操作
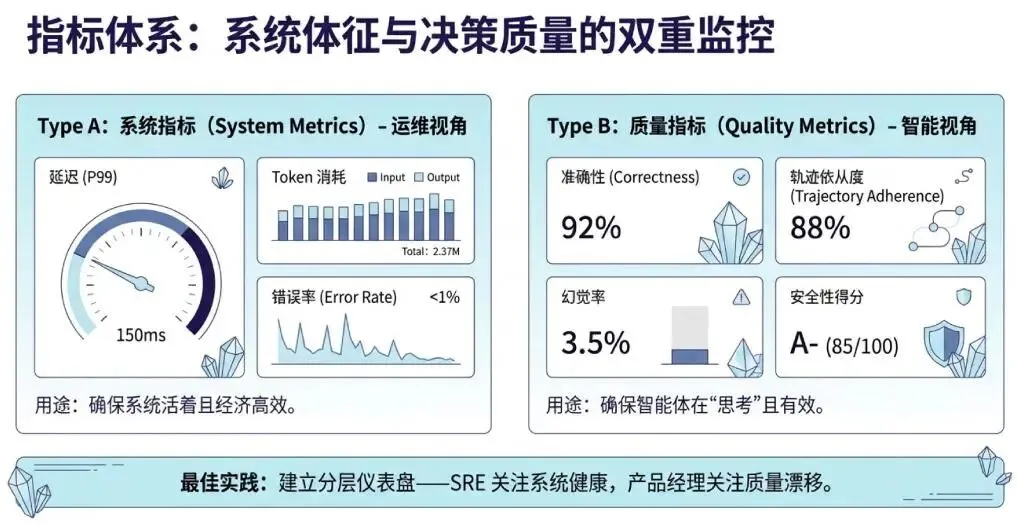
3.指标(Metrics):智能体的"体检报告"
系统指标:延迟(P99)、错误率、Token 消耗、API 成本
质量指标:正确性、轨迹符合度、有用性评分
? 职场案例:AI 营销助手的可观测性实践
场景:AI 帮你生成一篇产品推广文案
没有可观测性时:
你:"生成一篇新品发布的推广文案"
AI:[返回一篇文案]
你:"这篇文案感觉不太对..."
→ 你不知道问题出在哪里
→ 只能重新生成,碰运气
有完善的可观测性后:
日志(Logs)记录:
{
"timestamp": "2026-01-25T10:30:00Z",
"user_id": "marketing_team_leader",
"task": "generate_product_launch_copy",
"steps": [
{
"step": 1,
"action": "retrieve_product_info",
"tool": "product_database",
"input": {"product_id": "NP2026"},
"output": {"name": "智能手表 X1", "features": [...]}
},
{
"step": 2,
"action": "retrieve_competitor_analysis",
"tool": "market_research_db",
"input": {"category": "smartwatch"},
"output": {"competitors": [...], "market_trend": "健康监测"}
},
{
"step": 3,
"action": "generate_copy",
"model": "gemini-pro",
"prompt": "根据产品信息和市场趋势...",
"response": "...[生成的文案]..."
}
]
}
指标(Metrics)仪表盘:
【系统指标】
- 平均响应时间:1.8 秒
- 成功率:95%
- Token 消耗:1200 tokens/次
- API 成本:0.05 元/次
【质量指标】
- 文案通过率:78%(需改进)
- 用户满意度:4.2/5
- 常见失败原因:
1)产品信息检索失败(12%)
2)风格不符合品牌调性(10%)
实际价值:
当文案质量不佳时,你可以:
查看日志:发现"竞品分析"步骤检索到的是去年的数据
查看指标:发现这个问题影响了 12% 的请求
→ 精准定位:需要更新市场研究数据库→ 而不是盲目调整 AI 模型参数
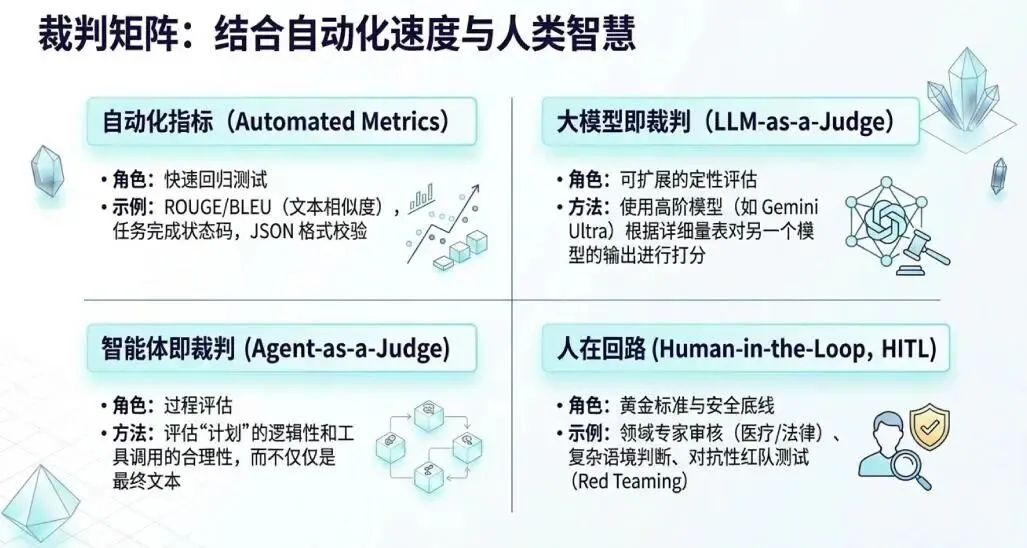
谁来当裁判?混合评估策略
1. 自动化指标(速度快,但肤浅)
字符串相似度(ROUGE、BLEU)
语义相似度(BERTScore)
最佳用途:作为 CI/CD 中的第一道防线,快速发现明显回归
2. LLM-as-a-Judge(可扩展,但有偏差)
用更强大的模型(如 Gemini Advanced)来评分
最佳实践:使用"成对比较"而非绝对打分,减少偏差
3. Agent-as-a-Judge(评估过程)
不仅评估输出,还评估整个执行轨迹
可以问:"这个计划合理吗?""为什么选择这个工具?"
4. Human-in-the-Loop(终极仲裁者)
人类永远是定义"什么是好"的最终权威
关键职责:创建"黄金测试集"、评估细微差别、处理高风险场景
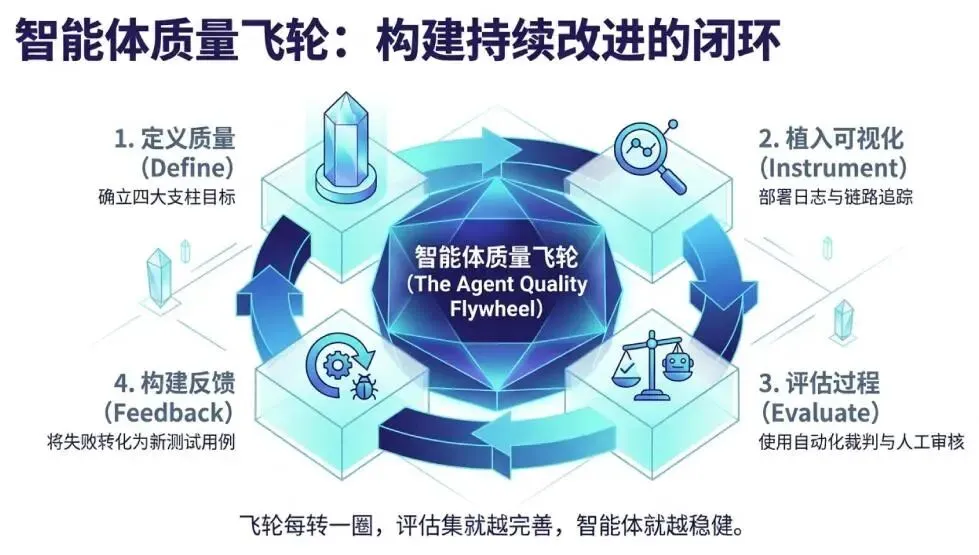
终极蓝图:智能体质量飞轮
将所有概念整合在一起,我们得到一个自我强化的系统——智能体质量飞轮:

? 职场案例:AI 招聘系统的完整飞轮
第 1 个月(飞轮启动):
【定义目标】
- 有效性:推荐的候选人至少 60% 通过初筛
- 效率:每个岗位 3 天内完成候选人推荐
- 鲁棒性:简历格式异常时不能崩溃
- 安全性:不能因性别、年龄等因素歧视候选人
【构建系统】
- 上下文:记住每个岗位的特殊要求
- 记忆:记录每位面试官的评价偏好
【监控】
- 日志:记录每次推荐的完整轨迹
- 指标:通过率、响应时间、成本
【评估】
- 发现问题:技术岗位推荐通过率只有 45%
- 轨迹分析:AI 过度看重学历,忽略了项目经验
第 2 个月(飞轮加速):
【迭代改进】
- 调整 prompt:明确"项目经验 > 学历"
- 新增记忆:记录"技术岗偏好实战经验"
- 扩充测试集:加入 50 个"高项目经验但学历一般"的成功案例
【效果】
- 技术岗通过率提升到 72%
- 推荐速度从 3 天降到 1.5 天
【新发现的问题】
- 销售岗位的推荐通过率下降到 50%
- 原因:错误应用了技术岗的评价标准
第 3 个月(飞轮成熟):
【精细化改进】
- 按岗位类型建立独立的评价记忆
- 技术岗:项目经验权重 0.6,学历权重 0.2
- 销售岗:沟通能力权重 0.5,业绩记录权重 0.4
【整体效果】
- 所有岗位平均通过率:78%
- 平均响应时间:1.2 天
- HR 满意度:从 6 分提升到 8.5 分
【持续优化】
- 每周自动分析失败案例
- 每月更新岗位评价标准
- 季度性人工审核,确保无偏见
这就是飞轮效应:系统使用得越多 → 积累的反馈越多 → 记忆越精准 → 推荐质量越高 → 用户越信任 → 使用得更多。
3
三大核心原则
构建可信赖智能体的终极法则
1.质量是架构支柱,不是最后的测试环节
从第一行代码就设计"可评估性",而不是事后补救
从 Day 1 就建立:
1. 日志系统(记录所有轨迹)
2. 测试框架(定义质量标准)
3. 评估流程(每次发布前必须通过质量关卡)
结果:质量问题在开发阶段就被拦截
2.轨迹即真理
评估智能体不能只看最终答案,必须检查整个"思考过程"
只看结果:
客户:"推荐一个稳健的投资组合"
AI:"建议 60% 股票 + 40% 债券"
评估:✅ 表面合理
查看轨迹:
步骤 1:查询客户风险偏好 → 错误:查询到的是另一位客户的数据
步骤 2:基于"高风险偏好"生成组合
步骤 3:输出结果
评估:❌ 严重错误!给保守型客户推荐了激进组合
→ 如果不看轨迹,可能导致客户重大损失
3.人类是最终仲裁者
自动化提供规模,人类提供真理
【系统架构】
第 1 层:AI 自动审核(处理 95% 的明确案例)
✅ 明显违规内容 → 自动拦截
✅ 明显正常内容 → 自动通过
第 2 层:AI 标记边缘案例(5%)→ 转人工
⚠️ "这条评论是讽刺还是真的侮辱?"
⚠️ "这张图片是艺术还是色情?"
第 3 层:人类专家审核
- 做出最终判断
- 判断结果反馈给 AI 学习
【关键原则】
- AI 负责"规模":每天处理百万级内容
- 人类负责"真理":定义什么是对错
- 两者协同:AI 越用越聪明,但永远不完全替代人类判断

4
从能力到信任的跨越
未来属于那些不仅能"让智能体跑起来",更能"让智能体可信赖"的组织。这不仅是技术的升级,更是从自动化工具向自主化伙伴的根本性跨越。
关键不在于你的智能体有多聪明,而在于:
它记得你(通过精心设计的记忆系统)
它的每一步都清晰可见(通过完善的可观测性)
它的每一个决策都经得起检验(通过严格的质量评估)
? 职场案例:一个可信赖的企业 AI 助手
想象你的公司部署了一个 AI 行政总监助手:
【它记得你】
你:"帮我安排下周的管理层会议"
AI:"根据记忆,您偏好周三下午,
上次会议您提到希望控制在 1.5 小时内,
已为您预定了 3 号会议室(带投影),
并提前发送议程给所有参会者"
【它的步骤清晰可见】
你在管理后台看到:
- 步骤 1:查询所有高管日历 ✅
- 步骤 2:筛选共同空闲时段 ✅
- 步骤 3:预定会议室 ✅
- 步骤 4:生成并发送会议通知 ✅
【它经得起检验】
每周质量报告:
- 会议安排成功率:98%
- 平均安排时间:2 分钟
- 零次时间冲突
- 用户满意度:9.2/10
失败案例分析:
- 2% 失败原因:会议室被临时占用
- 改进措施:增加实时会议室状态检查
---
这是我在AI时代探索的真实记录
如果你也在:
• 摸索如何将AI融入工作流
• 寻找可持续的高效能状态
• 思考如何在变化中成长
欢迎加我微信:
我的朋友圈是更日常的实践笔记
我们可以互相看见彼此的成长
---
ps:
我也在思考如何将这些经验
做成能帮到更多人的产品
如果你有想法,也欢迎和我聊聊
加微信备注【谷歌白皮书】,可领取谷歌发布的5本Agent白皮书