


过去一年做Agent,我踩过最大的坑是:以为模型越强、上下文窗口越大,Agent就越聪明。
128K不够用?上200K。200K还不行?等1M的模型出来。
直到系统跑了几个月,我才意识到问题根本不在这里。
Agent变笨、失忆、人设漂移,这些问题的根源不是模型能力不足,而是我们一直把上下文当作"一次性输入",而不是"系统资产"来管理。
Google最近发布的70页白皮书《Context Engineering: Sessions & Memory》,把这件事讲透了。
今天把核心内容拆给你。
一、Agent的失忆症
做过Agent的人都遇到过这些问题:
对话长了,Agent开始"忘事",明明前面说过的信息,后面又问你一遍 跨Session信息丢失,每次新对话都像第一次见面 人设漂移,聊着聊着Agent的性格和风格就变了
很多人的第一反应是:模型不够强,换个更大的模型。
但Google这份白皮书告诉我们:这不是模型问题,是上下文工程问题。
二、什么是上下文工程?
Context Engineering是动态组装和管理LLM上下文窗口内信息的实践。
和Prompt Engineering的区别是什么?
Prompt Engineering是静态的——关注"怎么写提示词"。
Context Engineering是动态的——关注"每次调用时,往上下文窗口里放什么"。
一个形象的比喻:Prompt Engineering是写菜谱,Context Engineering是每次做菜时决定从冰箱里拿什么食材。
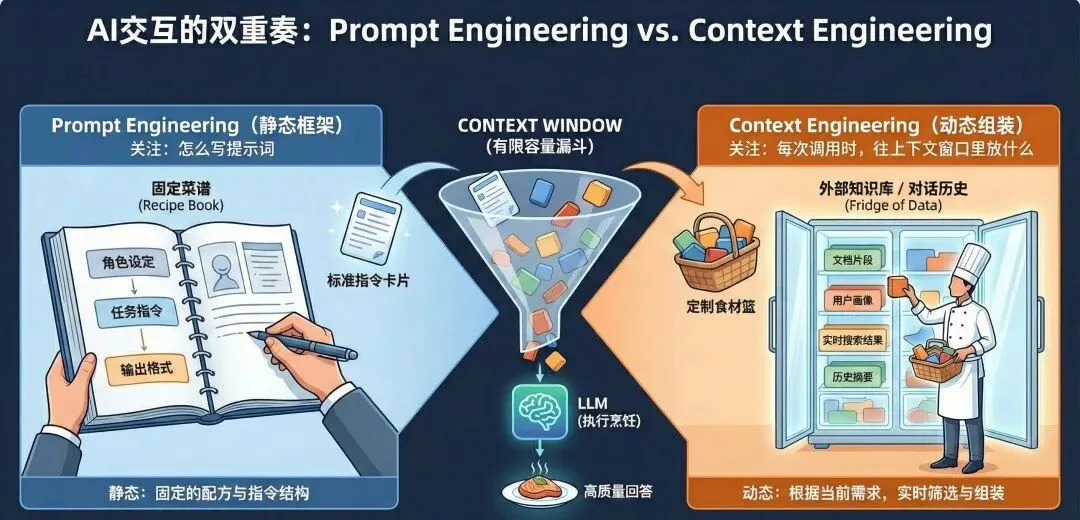
上下文窗口是稀缺资源,不是越多越好。
三、Context Rot:为什么塞得越多反而越傻?
这是白皮书中最重要的概念之一:上下文腐烂(Context Rot)。
Chroma在2025年7月发布的研究测试了18个主流LLM,结论很扎心:
随着输入长度增加,模型的准确率会持续下降。 即使是最简单的检索任务,性能也会随着上下文增长而变得越来越不稳定。
为什么会这样?
1. 注意力稀释。
Transformer架构中,每个token都要"关注"其他所有token。
上下文越长,模型的"注意力预算"就被摊得越薄。
就像一个人同时盯着100件事,每件事能分到的精力自然就少了。
2. 位置偏差。
LLM对上下文开头和结尾的信息更敏感,中间的信息容易被忽略。
这就是著名的"Lost in the Middle"问题。
如果关键信息恰好在中间位置,模型很可能"看不见"。
3. 信噪比下降。
塞进去的信息越多,噪音也越多。
关键信号被淹没在一堆无关细节里。
Anthropic的工程博客有一句话总结得很好:
Agent在循环中每一轮都会产生更多数据。 如果不加以管理,不断增长的上下文最终会耗尽Agent有限的"注意力预算"——就像人类有限的工作记忆一样。
所以,更大的上下文窗口不等于更好的性能。
128K、200K甚至1M的窗口,并不意味着你可以把所有东西都塞进去。
四、Session vs Memory:短期记忆和长期记忆的分离
白皮书的核心架构设计:把记忆分成两层——Session和Memory。
Session(会话)
短期容器,存储单次对话的历史和工作状态 生命周期:用户关闭对话时结束 内容:对话轮次、中间推理步骤、工具调用结果
Memory(记忆)
长期存储,跨Session持久化 生命周期:可能永久保留 内容:用户偏好、历史交互的关键信息、学到的知识
为什么要分开?
更新频率不同:Session每轮都在变,Memory只在有价值的信息出现时才更新。
检索方式不同:Session是顺序访问(最近的对话历史),Memory是语义检索(找相关的过往知识)。
管理策略不同:Session需要压缩和截断,Memory需要提取和整合。
这种分离让系统可以针对不同类型的"记忆"采用不同的优化策略。
五、三种Session压缩策略
对话越来越长,Session迟早会撑爆上下文窗口。怎么办?
Google给出了三种压缩策略:
1. Keep Last N Turns(保留最近N轮)
最简单粗暴:只保留最近N轮对话,更早的直接丢弃。
优点:实现简单,延迟可预测。缺点:如果重要信息在早期对话中,就丢失了。适用场景:任务边界清晰、每轮对话相对独立的场景。
2. Token-based Truncation(Token截断)
设定一个Token上限,尽可能多地保留消息,超出部分从最早的开始删。
优点:比"保留N轮"更灵活,能适应长短不一的对话。缺点:可能在语义不完整的地方截断。适用场景:对话轮次长度差异大的场景。
3. Recursive Summarization(递归摘要)
用LLM把较早的对话压缩成摘要,只保留关键信息。
优点:信息保留率最高,能跨越很长的对话历史。缺点:摘要本身会引入信息损失和偏差,而且增加额外的LLM调用成本。适用场景:需要长期上下文但又受Token限制的复杂任务。
Manus团队在他们的Context Engineering博客中提了一个有趣的思路:把文件系统当作终极上下文。
意思是:压缩策略应该是可恢复的。
网页内容可以从上下文中删除,只要URL还在;文档内容可以省略,只要路径还在sandbox里。这样既能压缩上下文长度,又不会永久丢失信息。
六、Memory的ETL管道
Memory的管理比Session复杂得多。白皮书描述了一个完整的"记忆ETL"流程:
1. Extraction(提取)
在对话过程中,用LLM识别出"值得记住"的信息。
不是什么都记,只记有信号的内容。比如:
用户说"我们公司有200多个开发者,正在做微服务迁移" 提取出:公司规模(200+开发者)、当前项目(微服务迁移)、技术背景(分布式系统)
关键是要有预定义的主题范围——告诉LLM什么类型的信息值得提取,什么可以忽略。
2. Consolidation(整合)
新提取的信息要和已有的Memory合并。这一步最复杂,需要处理:
去重:不能创建两条语义相同的记忆。冲突解决:用户偏好会变。之前说"我是素食主义者",现在说"我在尝试海鲜素"。怎么办?
白皮书的方案是时间戳优先+置信度评分+显式纠正:
更新的信息覆盖旧的(时间戳优先) 用户明确纠正的权重最高(显式纠正) 反复被提及的信息置信度更高(强化)
3. Retrieval(检索)
什么时候把Memory注入上下文?有两种策略:
主动检索(Proactive):每轮对话都预先拉取可能相关的Memory。简单,但可能增加延迟和噪音。
被动检索(Reactive):Agent在需要时主动调用`query_memory`工具查询。高效,但需要Agent有足够的判断力知道什么时候该查。
白皮书建议用混合评分来排序检索结果:相关性(语义相似度)× 时效性(最近访问)× 重要性(被强化的次数)。
还有一个细节:Memory注入到上下文的位置很重要。
放在System Message里权重高但有偏差风险,放在对话历史里更自然但容易被忽略。
七、总结
读完这份白皮书,最大的感受是:
Agent的智能上限,取决于你喂给它什么。
模型能力是基础,但如果上下文管理一塌糊涂,再强的模型也会表现得像个失忆症患者。
Context Engineering正在成为Prompt Engineering之后的下一个关键技能。
它不是"怎么写提示词"的问题,而是"怎么设计整个信息流"的问题。