


一、项目背景
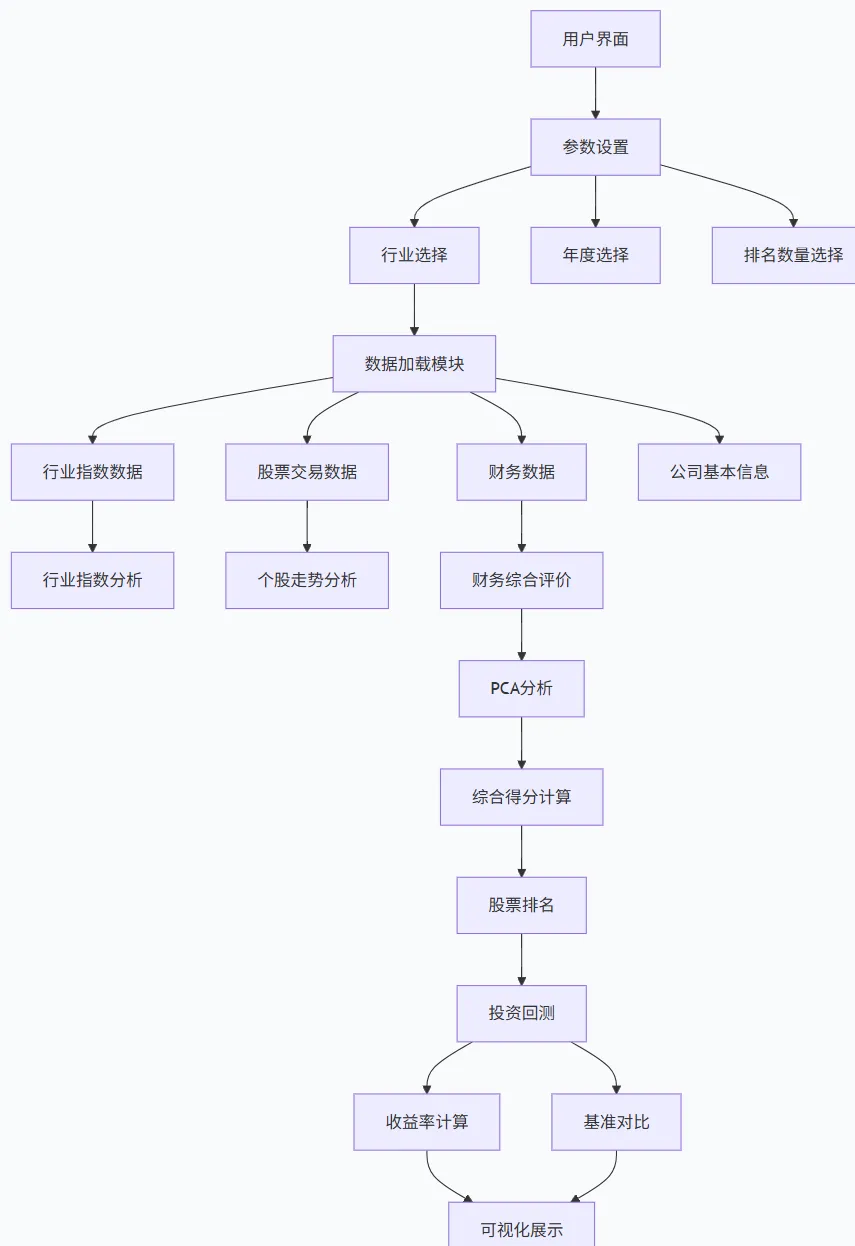
st_data函数实现,主要完成以下任务:首先,从本地文件中读取四个数据源,包括行业指数交易数据、股票交易数据、财务数据和上市公司基本信息。然后,根据用户选择的行业名称筛选出对应的行业指数数据,并进行排序和列名重命名,以便后续处理。如果该行业的数据量超过600条,则进一步关联该行业内的上市公司,获取这些公司的交易数据和财务数据。最后,返回行业指数走势图、个股走势图、行业指数数据、财务数据、股票交易数据和公司基本信息。如果数据量不足600条,则给出警告并返回空值。def st_data(nm, info):# 读取相关数据data = pd.read_csv('index_trdata.csv')trdata = pd.read_csv('stk_trdata.csv')findata = pd.read_csv('fin_data.csv')co_data = pd.read_excel('上市公司基本信息.xlsx')# 筛选指定行业的行业指数交易数据data_i = data[data['name'] == nm].copy()data_i = data_i.sort_values(['trade_date'])data_i.columns = ['指数代码', '行业名称', '交易日期', '开盘指数', '收盘指数', '成交量', '市盈率', '市净率']
# 绘制行业收盘指数走势图plt.figure(figsize=(12, 6))f1, ax = plt.subplots()ax.set_title(f'申万{nm}行业指数走势图', fontsize=16, fontweight='bold')x1 = data_i['交易日期'].valuesy1 = data_i['收盘指数'].valuesax.plot(range(len(x1)), y1, linewidth=2, color='#1f77b4')
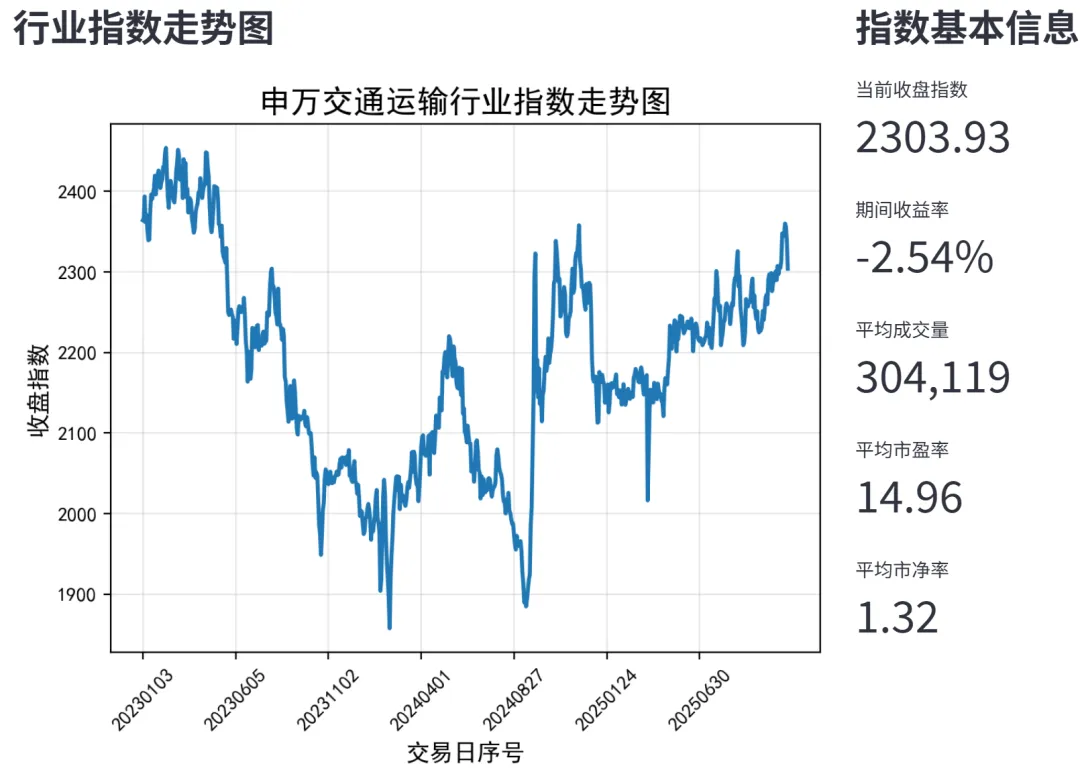
Fr函数完成。该函数首先筛选出指定年份的财务数据,然后进行数据清洗,去除负值和空值,确保数据质量。接着,对清洗后的财务指标进行标准化处理,以消除量纲影响。随后,采用主成分分析(PCA)方法,保留95%的方差信息,提取主成分。最后,根据各主成分的贡献率加权计算每只股票的综合得分,并按照得分从高到低进行排序。该模块返回一个包含股票代码、股票简称和综合得分的DataFrame,为后续的投资回测提供股票排名。def Fr(data, year):# 筛选指定年份的数据tdata = data[data['年度'] == year].copy()# 空值和负值指标处理data_x = tdata.iloc[:, 1:-1].copy()data_x = data_x[data_x > 0]data_x['股票代码'] = tdata['股票代码'].valuesdata_x = data_x.dropna()# 标准化处理X = data_x.iloc[:, :-1]scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 主成分分析pca = PCA(n_components=0.95)Y = pca.fit_transform(X_scaled)gxl = pca.explained_variance_ratio_# 综合得分计算F = Y[:, 0] * gxl[0]for i in range(1, len(gxl)):F += Y[:, i] * gxl[i]
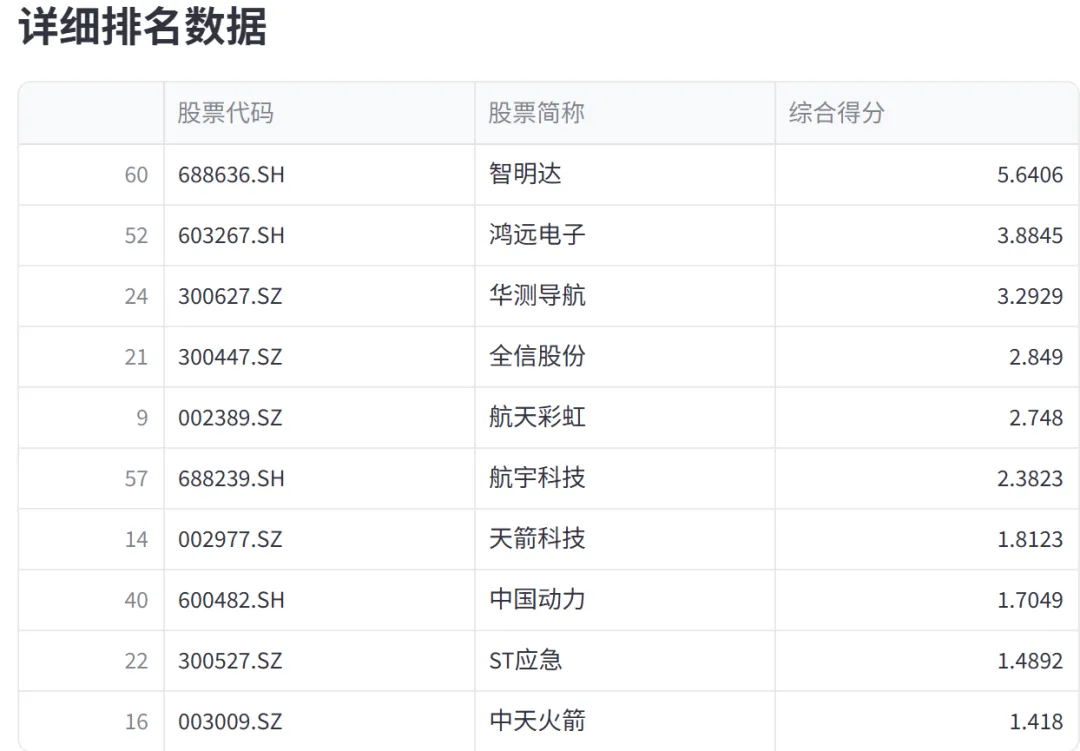
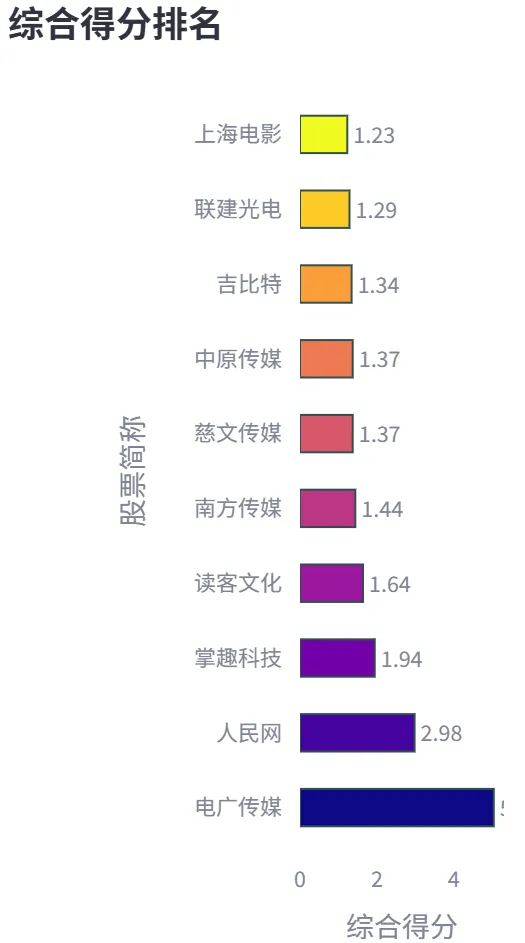
Tr函数实现。该函数接收财务综合评价模块输出的股票排名、年份和排名数量,选取前N名股票作为投资组合。然后,对于每只股票,使用tushare库获取其次年5月1日至12月31日的后复权价格数据,并计算持有期间的收益率。同时,获取同期沪深300指数的收益率作为基准。最后,计算投资组合的平均收益率,并与基准收益率进行比较。该模块返回组合平均收益率、基准收益率以及每只股票的详细收益率数据。其核心逻辑如下:create_return_visualization和create_ranking_visualization。前者用于创建收益率对比条形图,将每只股票的收益率以水平条形图展示,并在图中添加组合平均收益率和基准收益率的参考线。后者用于创建综合得分排名条形图,将股票按综合得分从高到低展示,并根据排名数量动态调整条形图的颜色、宽度和布局参数,以确保可视化效果清晰美观。效果展示分别如下图: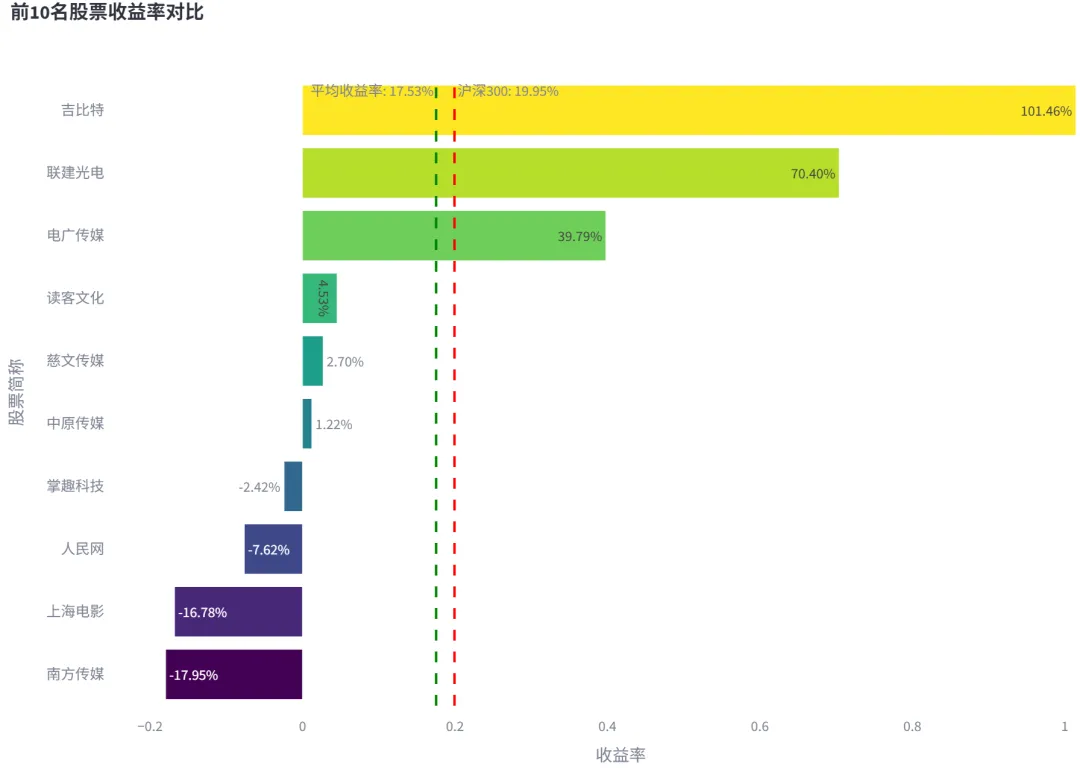
st_fig函数构建。该函数首先设置页面配置,包括页面标题和布局。然后,在侧边栏提供参数设置选项,包括行业选择、年度选择和排名数量选择。主内容区域根据用户选择的参数,依次展示原始数据、行业指数分析、个股分析、综合评价与投资回测结果。在展示过程中,使用了Streamlit的多种组件,如标签页、指标卡、展开器等,以增强用户交互体验。def st_fig():# 设置页面配置st.set_page_config(page_title="申万行业数据分析平台",layout="wide",initial_sidebar_state="expanded")# 侧边栏参数设置with st.sidebar:st.markdown("## ? 参数设置")nm = st.selectbox("选择申万一级行业", nm_L, key="industry_select")year = st.selectbox("选择分析年度", [2024, 2023, 2022], key="year_select")rank = st.selectbox("选择排名数量", [5, 10, 15, 20], key="rank_select")
# 原始数据展示st.markdown("## ? 原始数据")tab1, tab2, tab3, tab4 = st.tabs(["? 行业指数交易数据", "? 财务数据", "? 股票交易数据", "? 公司基本信息"])
已关注
关注
重播 分享 赞