



发现最近行业内,大家评判大模型能力的维度有了一个变化:更重视模型的执行能力。
这是因为当大模型被应用于更加复杂的场景,需要大模型严格遵循各项指令,才能更好地完成任务,指令遵循、执行能力能直接决定一个大模型在产业应用的上限。
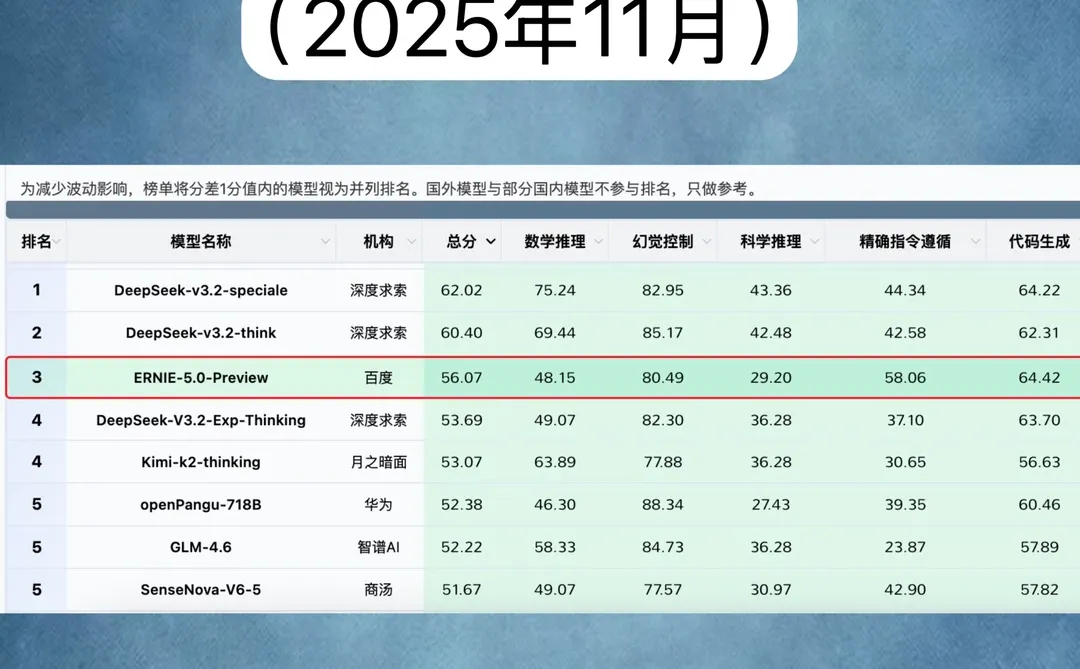
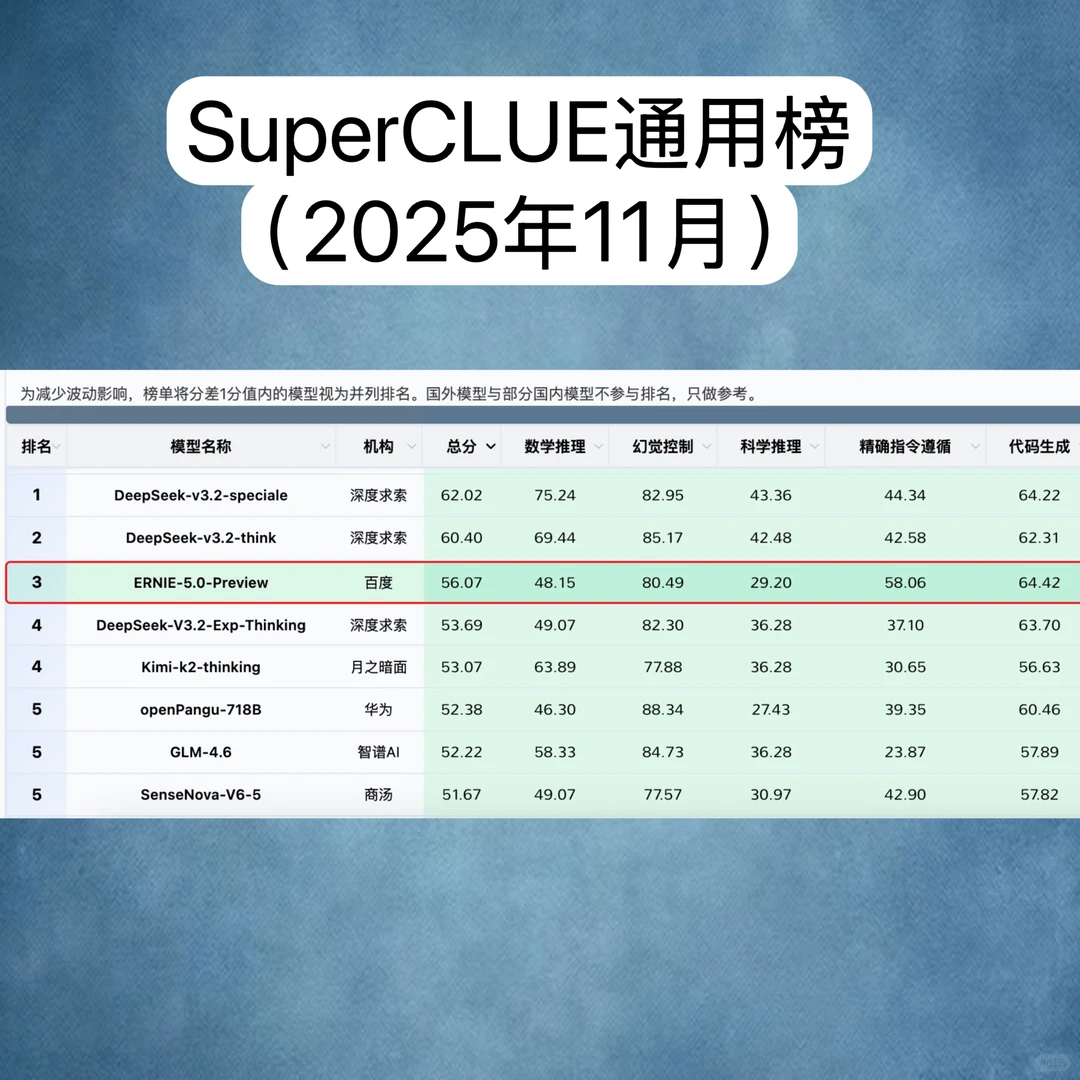
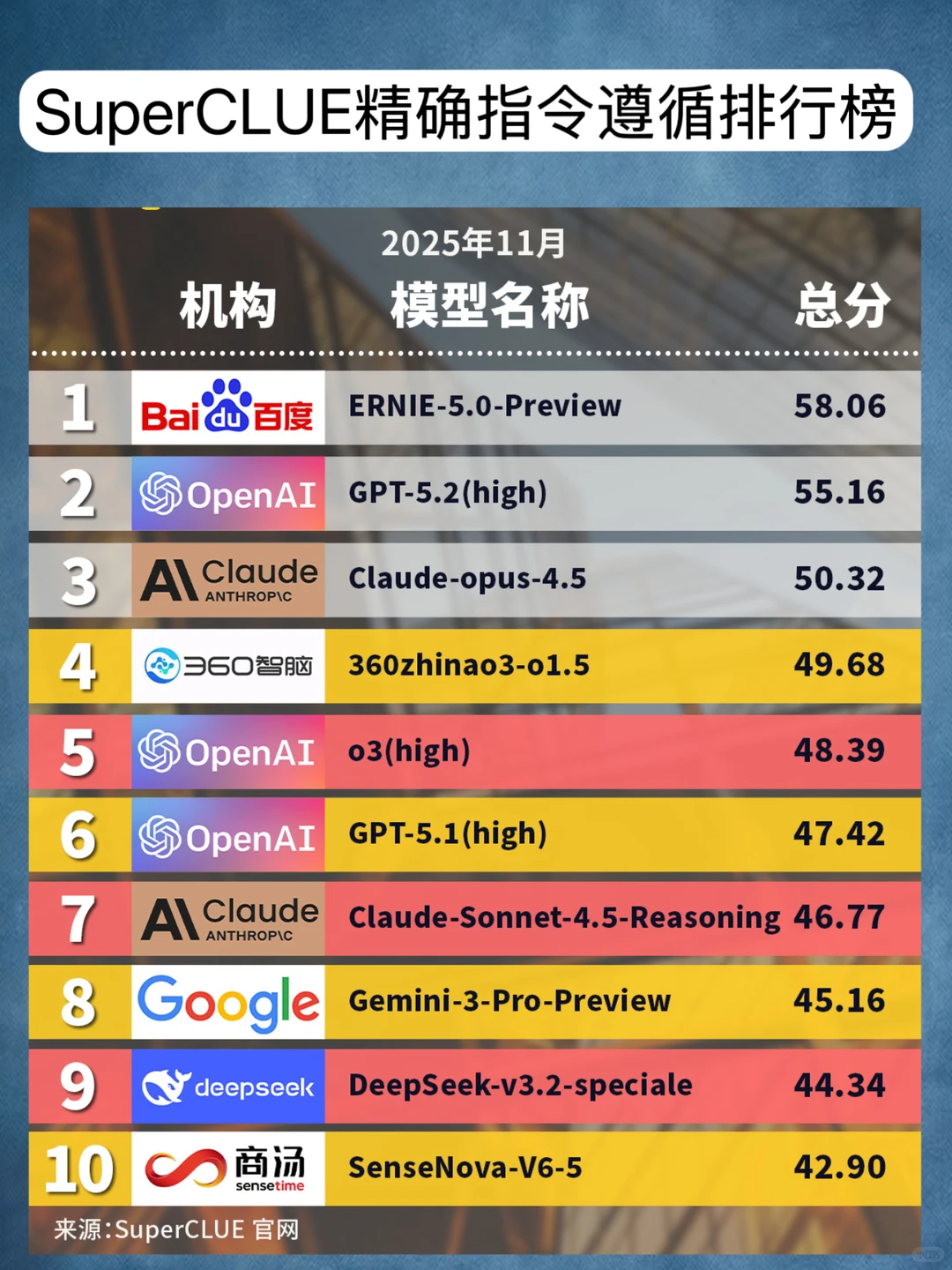
SuperCLUE在11月的最新榜单,就从精确指令遵循维度,重点评估大模型在在中⽂环境下的精确遵循复杂、多约束指令能⼒,重点评估模型将⾃然语⾔指令转化为符合所有要求的具体输出的能⼒。
测评结果显示,国内外主流⼤模型中,⽂⼼5.0 Preview以58.06分位居全球第⼀,GPT-5.2(high)和Claude-opus-4.5分别以55.16分和50.32分位居⼆、三。
⽂⼼5.0在实际应用场景的优势还是很明显的,能够在真实场景中稳定高效地完成任务,在产业场景有更大的应用空间,这也是大模型的核心价值所在。
其实现在大模型能力比拼的不止是单纯的参数较量,而是包含执行力等在内的综合能力的较量,文心5.0 Preview的指令遵循能力较强,也代表了国产大模型的能力方向,可以预见,未来我们能在更多产业中看到AI解决方案的落地。
#百度 #⽂⼼⼀⾔ #⽂⼼ #⽂⼼⼤模型 #AI #AI⼤模型 #科技 #AI技术 #⼲货分享
这是因为当大模型被应用于更加复杂的场景,需要大模型严格遵循各项指令,才能更好地完成任务,指令遵循、执行能力能直接决定一个大模型在产业应用的上限。
SuperCLUE在11月的最新榜单,就从精确指令遵循维度,重点评估大模型在在中⽂环境下的精确遵循复杂、多约束指令能⼒,重点评估模型将⾃然语⾔指令转化为符合所有要求的具体输出的能⼒。
测评结果显示,国内外主流⼤模型中,⽂⼼5.0 Preview以58.06分位居全球第⼀,GPT-5.2(high)和Claude-opus-4.5分别以55.16分和50.32分位居⼆、三。
⽂⼼5.0在实际应用场景的优势还是很明显的,能够在真实场景中稳定高效地完成任务,在产业场景有更大的应用空间,这也是大模型的核心价值所在。
其实现在大模型能力比拼的不止是单纯的参数较量,而是包含执行力等在内的综合能力的较量,文心5.0 Preview的指令遵循能力较强,也代表了国产大模型的能力方向,可以预见,未来我们能在更多产业中看到AI解决方案的落地。
#百度 #⽂⼼⼀⾔ #⽂⼼ #⽂⼼⼤模型 #AI #AI⼤模型 #科技 #AI技术 #⼲货分享