



?arXiv 26-Nov-2025 LLM相关论文(10/52)
?更多论文见主页/合集
?arXiv ID: arXiv:2511.20072
?论文标题: MTA: A Merge-then-Adapt Framework for Personalized Large Language Model
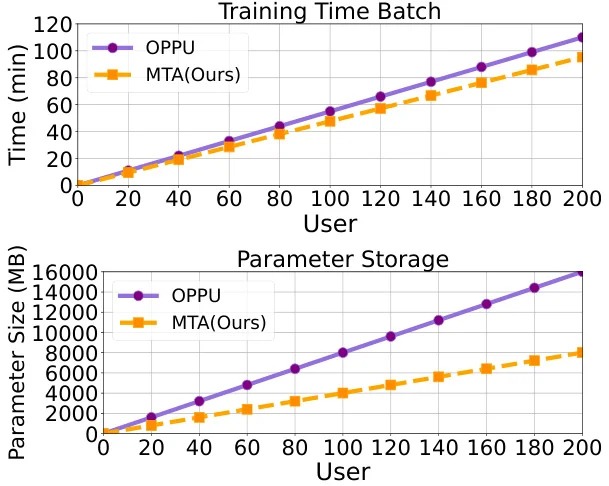
? 问题背景:传统个性化大语言模型(PLLMs)采用“一用户一LoRA”范式,面临存储成本随用户数量线性增长、数据稀疏场景性能下降两大挑战,难以满足大规模部署需求。
? 研究动机:为解决上述问题,研究者提出MTA框架,通过构建共享元LoRA库、动态融合及轻量适配三级机制,实现可扩展且数据高效的个性化。
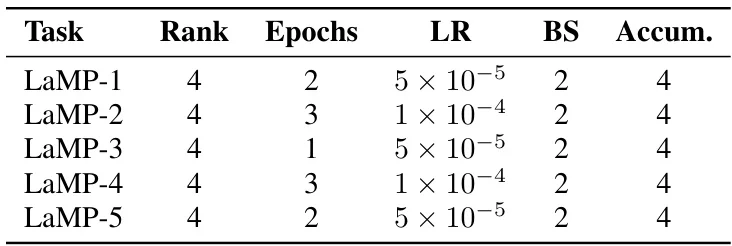
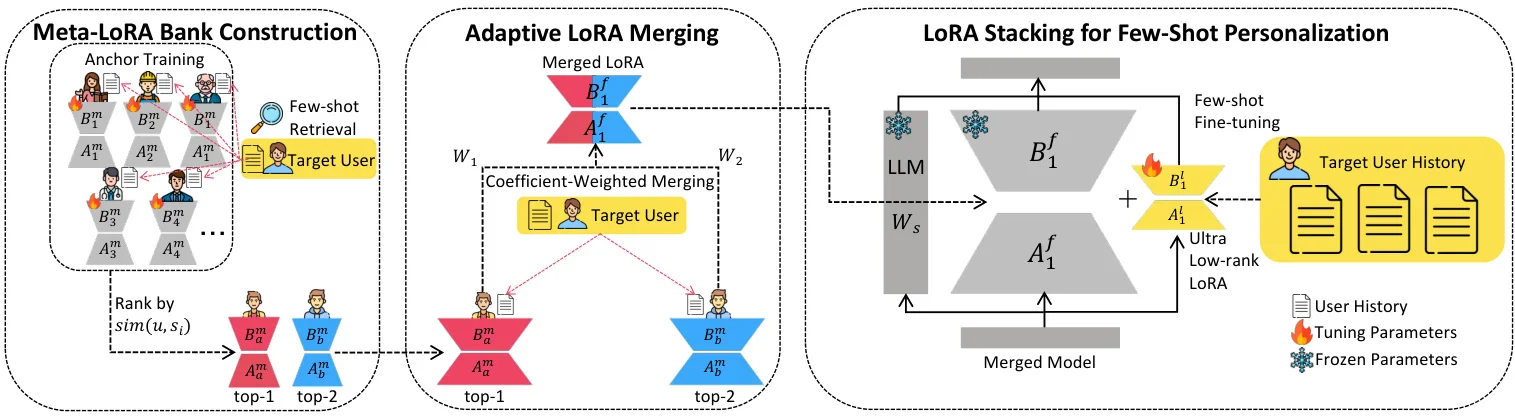
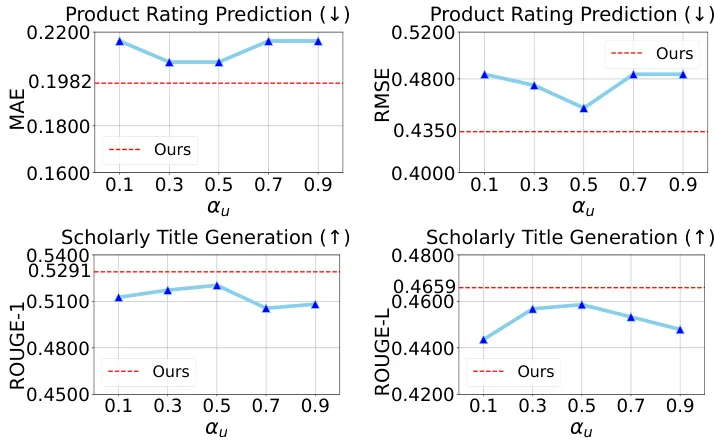
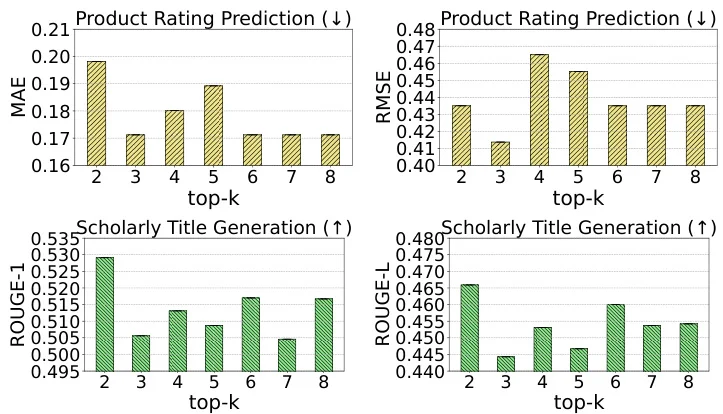
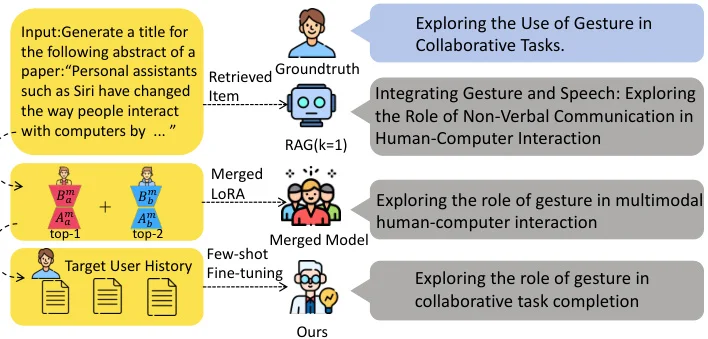
? 方法简介:MTA包含三阶段:1) 基于锚用户构建元LoRA库;2) 根据用户相似度动态融合多个LoRA;3) 堆叠超低秩LoRA进行小样本适配,兼顾协同知识与细粒度偏好。
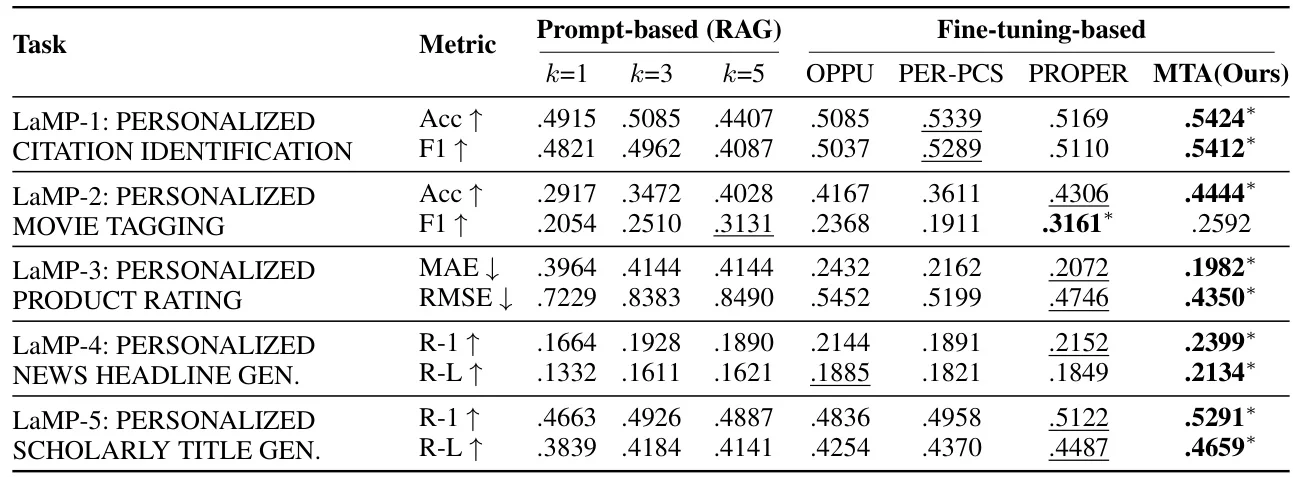
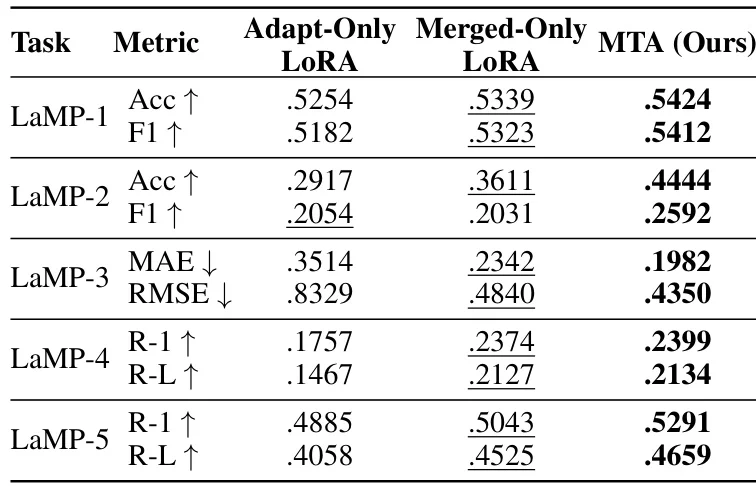
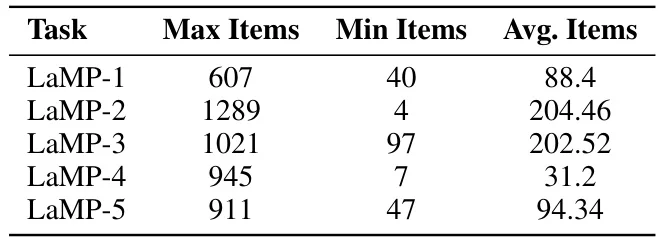
? 实验设计:在LaMP基准的五个任务上测试,选取100个历史数据稀疏用户,对比RAG、OPPU等基线。评估指标涵盖准确率、F1、ROUGE等,验证了MTA的显著优势。
?更多论文见主页/合集
?arXiv ID: arXiv:2511.20072
?论文标题: MTA: A Merge-then-Adapt Framework for Personalized Large Language Model
? 问题背景:传统个性化大语言模型(PLLMs)采用“一用户一LoRA”范式,面临存储成本随用户数量线性增长、数据稀疏场景性能下降两大挑战,难以满足大规模部署需求。
? 研究动机:为解决上述问题,研究者提出MTA框架,通过构建共享元LoRA库、动态融合及轻量适配三级机制,实现可扩展且数据高效的个性化。
? 方法简介:MTA包含三阶段:1) 基于锚用户构建元LoRA库;2) 根据用户相似度动态融合多个LoRA;3) 堆叠超低秩LoRA进行小样本适配,兼顾协同知识与细粒度偏好。
? 实验设计:在LaMP基准的五个任务上测试,选取100个历史数据稀疏用户,对比RAG、OPPU等基线。评估指标涵盖准确率、F1、ROUGE等,验证了MTA的显著优势。