





? 1. SFT 是教“答案”,RFT 是教“思考路径” 传统微调(SFT)是让模型模仿人类的最终输出。但在 Agent 场景下,这远远不够。 Agent RFT 的核心逻辑是:允许模型在训练中真的去调用工具,真的去撞墙,然后根据结果(Reward)来调整权重。
实战数据:在 FinQA 任务中,模型不仅学会了回答问题,还学会了更省钱的策略——从乱调工具变成了标准的 Search -> List -> Cat 路径,Token 消耗大幅降低。
? 2. 延迟与成本的“魔法优化” 大家做 Agent 最头疼的是什么?慢!贵! Cognition(Devin 的开发商)在分享中提到一个关键数据: 通过 RFT,他们的 Agent 从 Planning 模式进入执行模式的交互轮次,从 8-10 轮直接砍到了 4 轮。 这意味着什么?Latency 减半,推理成本减半。 这对于商业化落地是致命级的优势。
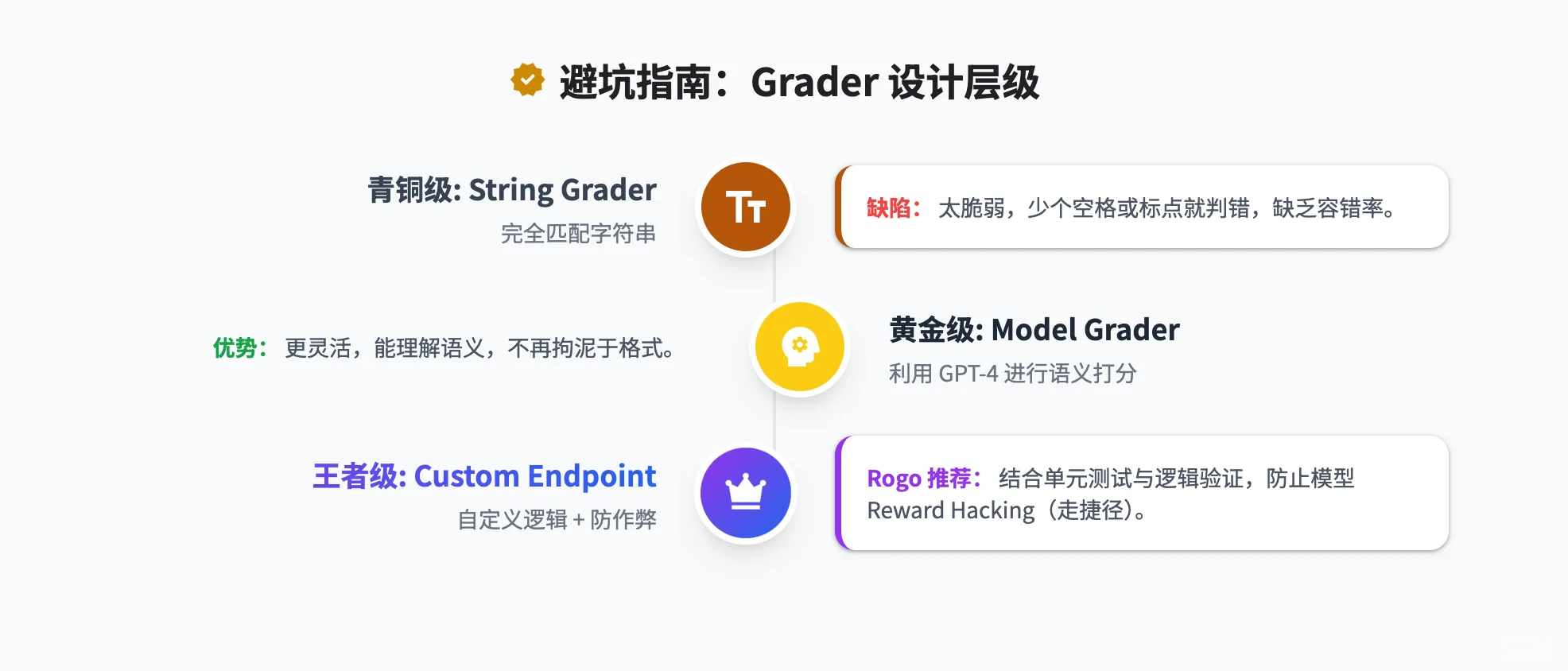
? 3. 成败的关键:Grader(评分器)的设计 很多人以为 RFT 难在算法,其实难在 Grader。
Rogo 的案例:因为 Grader 设计有漏洞,模型极度聪明地学会了“刷分”(Reward Hacking),导致验证集分数飙升到 1100%,但实际能力没涨。
研究员建议:不要只用简单的 String Match(字符匹配),要上 Model Grader,甚至要把 Tool Call 的过程(是否看了正确的文件)也纳入评分标准。
? 给开发者的建议(抄作业版):
别急着 RFT:先由 Prompt Engineering 榨干模型潜力,确保你的 Baseline 不是 0 分(否则模型学不会)。
环境要仿真:训练环境的工具必须和生产环境一致,别搞“特供版”。
RFTaaS 是趋势:预测一下,国内云厂商马上会跟进 RFT 平台服务。凡是支持微调的平台,如果不做 RFT,就会掉队。
? 总结:Agent 的竞争已经从“模型强不强”转变为“你会不会教模型用工具”。RFT 就是那个教鞭。
实战数据:在 FinQA 任务中,模型不仅学会了回答问题,还学会了更省钱的策略——从乱调工具变成了标准的 Search -> List -> Cat 路径,Token 消耗大幅降低。
? 2. 延迟与成本的“魔法优化” 大家做 Agent 最头疼的是什么?慢!贵! Cognition(Devin 的开发商)在分享中提到一个关键数据: 通过 RFT,他们的 Agent 从 Planning 模式进入执行模式的交互轮次,从 8-10 轮直接砍到了 4 轮。 这意味着什么?Latency 减半,推理成本减半。 这对于商业化落地是致命级的优势。
? 3. 成败的关键:Grader(评分器)的设计 很多人以为 RFT 难在算法,其实难在 Grader。
Rogo 的案例:因为 Grader 设计有漏洞,模型极度聪明地学会了“刷分”(Reward Hacking),导致验证集分数飙升到 1100%,但实际能力没涨。
研究员建议:不要只用简单的 String Match(字符匹配),要上 Model Grader,甚至要把 Tool Call 的过程(是否看了正确的文件)也纳入评分标准。
? 给开发者的建议(抄作业版):
别急着 RFT:先由 Prompt Engineering 榨干模型潜力,确保你的 Baseline 不是 0 分(否则模型学不会)。
环境要仿真:训练环境的工具必须和生产环境一致,别搞“特供版”。
RFTaaS 是趋势:预测一下,国内云厂商马上会跟进 RFT 平台服务。凡是支持微调的平台,如果不做 RFT,就会掉队。
? 总结:Agent 的竞争已经从“模型强不强”转变为“你会不会教模型用工具”。RFT 就是那个教鞭。