


✍️ 导读随着生成式人工智能(Generative AI)从万亿参数向十万亿参数级模型跨越,单芯片算力已无法应对庞大的吞吐压迫。行业核心痛点已从单纯的“晶圆微缩”演变为严重的“互连带宽赤字”与“供电/散热电热墙”。 本文全面拆解台积电(TSMC)在 2026 VLSI 研讨会上的核心技术发布,为您揭示台积电如何通过超大面积 CoWoS-S/L、晶圆级 COUPE 三维光电引擎、嵌入式深沟道电容(eDTC)以及全新的智能体 AI(Agentic AI)设计网络,重构大算力异构芯粒(Chiplet)集群的物理层底座。
01. 报告信息速览与 AI 互连三大物理瓶颈
? 报告文献卡片
报告主题: Advancing Package and System Integration for Next-Generation AI(面向下一代人工智能的高级封装与系统集成演进) 发布会议: 2026 IEEE VLSI Symposium on Technology and Circuits 核心主讲人: Dr. Lee-Chung Lu(卢立忠 博士,TSMC Senior Fellow 兼副总裁)
? 下一代大算力计算集群的“物理天花板”
Scale-in / Scale-up / Scale-out 维度的互连赤字: 在单个封装内部(Scale-in),传统凸点间距(Bump Pitch)限制了晶片与存储间的通信位宽;在机架内部系统级互连中(Scale-up),传统的铜走线面临巨大的高频插入损耗与衰减;在机架间网格互连时(Scale-out),传统光电转换接口体积大、能效(pJ/bit)极差。 瞬态大电流引发的供电墙(Power Wall): AI ASIC 核心在极低工作电压( 甚至更低)下,其动态瞬态电流已逼近上千安培。由于封装沿途垂直引脚(TSV/Bump)存在电感寄生效应,高频同步开关噪声(SSN)会引发严重的 AC IR Drop(动态电压坍塌)。 前后道脱节的“组合设计地狱”: 先进封装涉及多个逻辑芯粒、多层 HBM 内存、三维光电引擎以及数万级微孔路由。传统 EDA 软件分步、断层式的解算流程,在庞大的设计空间面前面临计算时间爆炸的僵局。
02. 先进异构集成核心概念储备库
在深入剖析台积电的核心技术演进前,必须夯实以下跨学科先进封装基石:
CoWoS-S 与 CoWoS-L (Chip-on-Wafer-on-Substrate): 台积电引以为傲的 2.5D 先进封装平台。CoWoS-S 采用大面积纯硅中介层(Silicon Interposer);CoWoS-L 则采用成本更低、结构更弹性的重布线层(RDL)基板,并在局部高密通信区内嵌精密硅连接桥(LSI Bridge)。 SoIC-X (System-on-Integrated-Chips Face-to-Face): 台积电最硬核的 3D 堆叠技术品牌。其核心特征是采用无凸点(Bump-less)的晶圆级混合键合(Hybrid Bonding)工艺,打通 EIC 与 PIC(或逻辑芯片间)的垂直壁面阻抗。 Agentic AI Flow (智能体 AI 设计流): 将大语言模型(LLM)与自动化规划代理(Agents)深度引入电子设计自动化(EDA)工具链的新型设计范式。用于在极短时耗内自主搜索出兼顾时序、电源完整性与可靠性的多物理场最优解。
03. Scale-In / Up / Out 三维带宽极限扩张:台积电的解耦逻辑
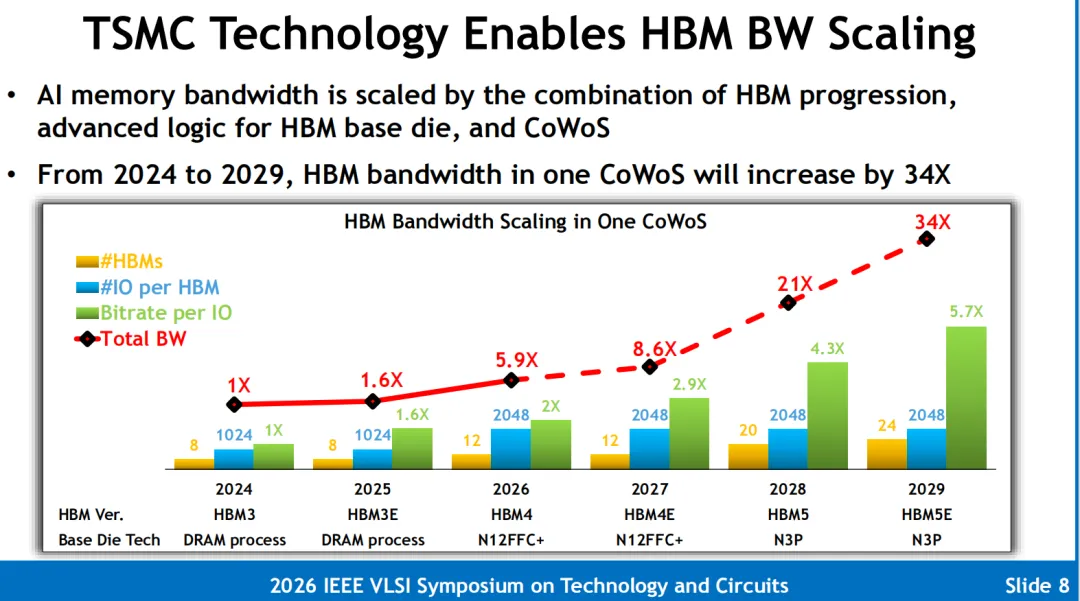
卢立忠博士在演讲中明确指出,大算力集群必须在三大物理互连维度同步实施降维重构,实现整体算力 34 倍至 48 倍的暴力跃升。
图片解说与运行机制: 如原图所示,展示了台积电 3DFabric 技术从 2.5D 平面拼接向 3D 垂直堆叠演进的结构路径。清晰呈现了从高密有引脚微凸点(Micro-bump)向无凸点(Bump-less)混合键合(Hybrid Bonding)过渡时的晶片界面,以及光罩大面积拼接(Reticle Scaling)的面积倍率演进。
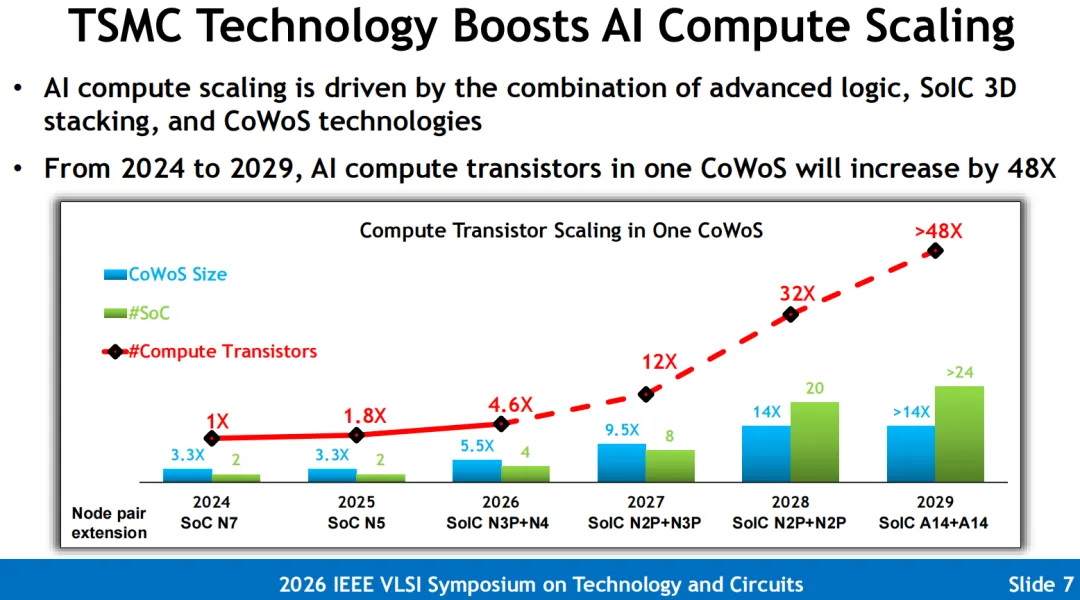
1. Scale-in (封装内部):微细 Bump Pitch 与 CoWoS 极限拼接
高密混合键合演进: 传统的微凸点(Micro-bump)间距卡在 。台积电通过将 SoIC 混合键合间距极限压缩至 轴线以下(数据来源:Slide 5),实现了较传统方案高出数个数量级的片上垂直互连密度(增加至 16-160 倍),并将每比特通信能效(Energy per Bit)榨取到纯本征的超低损耗状态。 光罩大面积拼接(Reticle Scaling): 为了容纳更多的计算核心(ASIC)与多达 8层、12 层的 HBM 堆叠,台积电宣布其 CoWoS 先进平台的光罩尺寸在 2026 年已成功步入 6 倍至 8 倍标准 Reticle 尺寸,并在工艺路线图上规划了未来向 12 倍、14 倍乃至超越 14 倍超大尺寸有机/硅中介层拼接的全面演进。
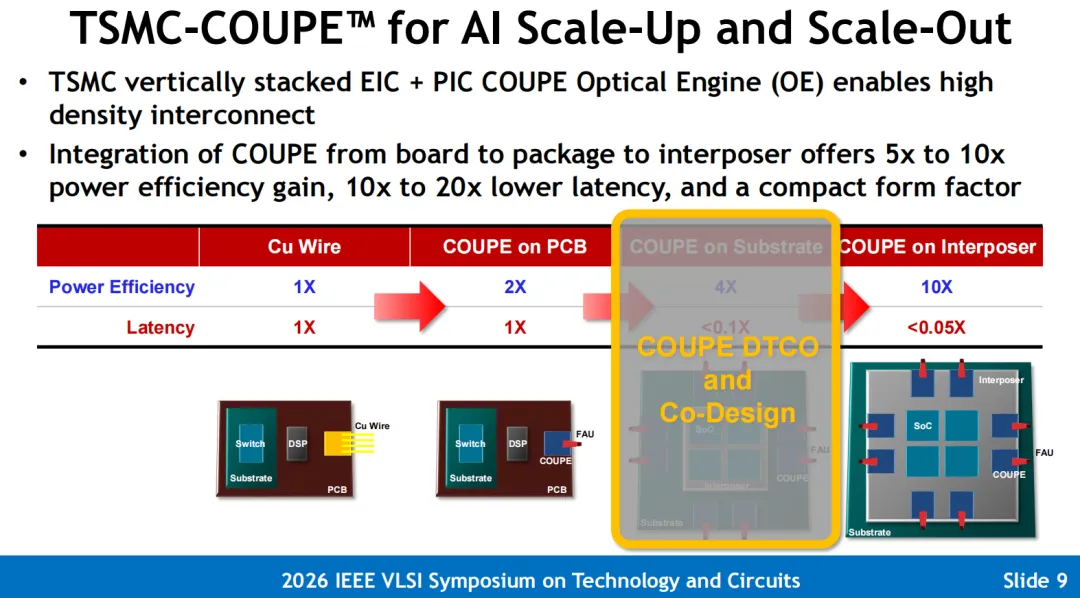
2. Scale-up & Scale-out (系统与网络级):COUPE 光电引擎与系统整合
针对机架间极速通信,台积电推出了其标志性的 3D 硅光引擎平台——COUPE(紧凑型通用光电引擎):
F2F异构集成的优势: 借由 SoIC™ 晶圆级 Face-to-Face(F2F)键合技术,将控制放大电芯片(EIC)无凸点直接倒扣在底部的硅光子芯片(PIC)之上。**这一物理结构将光电界面的寄生电容直接暴击削减了 85%**,将单通道射频通信截止带宽推高至 以上。 从插拔式向 CPO 迈进: 整个 COUPE 三维引擎不仅能无缝集成于插拔式光模块中,更能作为标准的共封装光学(CPO)组件无缝卡入到台积电 3D Fabric 的高端 MCM/CoWoS 封装外围,与最先进的计算核心及高带宽内存自由级联,彻底打破了传统网络铜缆的“功耗墙”与“长度极限”。
04. AI 功率墙对冲策略:片上电容技术与热设计(DTCO)
面对单芯片功耗攀升至上百瓦、瞬态电流跳变极端的大动态 PDN 环境,台积电在硅中介层内部及封装周边实施了跨代的无源组件工艺升级,全面维持大算力供电轨的 AC 电压纹波平稳:
eDTC(嵌入式深沟道电容)的跨代飞跃: 传统芯片内采用的 MIM(金属-绝缘体-金属)电容受限于平面面积,其容值密度有限。台积电通过在硅中介层内部引入高深宽比的三维刻蚀,推出了 eDTC 技术,使其片上去耦电容密度较传统 MIM 暴涨了 4.2 倍。这一超高储能密度能够在安培级瞬态电流大跳变发生时,提供极限贴近芯片底层的瞬态电荷注入,将电源电压抖动(AC IR Drop)死死压制在安全红线以内。 集成稳压器(IVR)的协同级联: 配合片上高密度 eDTC,台积电进一步在封装层级嵌入了高性能集成稳压器(IVR),实现了从大电压输入向芯片内极低逻辑电压的高效、快速本地降压调控。 热技术协同优化(Thermal DTCO): 针对极限发热热点(Hotspots),台积电通过深入优化垂直硅通孔(TSV)在层压介质中的热传导系数、微观微凸点处的物理材料热阻分布,并全面导入芯片热模型(CTM)与封测前端几何设计的双向敏捷联动,确保了 600W+ 大功耗计算核心与敏感存储(HBM)堆叠间的安全温度边界。
05. 3DIC 设计方法学重构:当后道设计走向智能体 AI(Agentic AI)
随着 2.5D/3D 高密度互连的物理维度的剧烈暴涨,传统依靠工程师手动调打试错的设计流已彻底崩溃。为此,台积电宣布全盘重构其 3DIC 设计自动化规范,正式引入前沿的智能体 AI 设计流(Agentic AI Flow):
图片解说与运行机制: 面对极为错综复杂的多电源域(MPD)基板布线与凸点电迁移(EM)约束,台积电构建了一套基于 AI 引擎的 Divide-and-Conquer(分而治之)解算闭环。算法输入各电源域的功率密度与电流剖面,AI 引擎在内部巨大的解算空间中自动自适应寻优,并输出帕累托最优解点矩阵(Pareto Points),使原先动辄耗时数周的高难拓扑评估直接收敛为秒级的快速 Inference 模式。
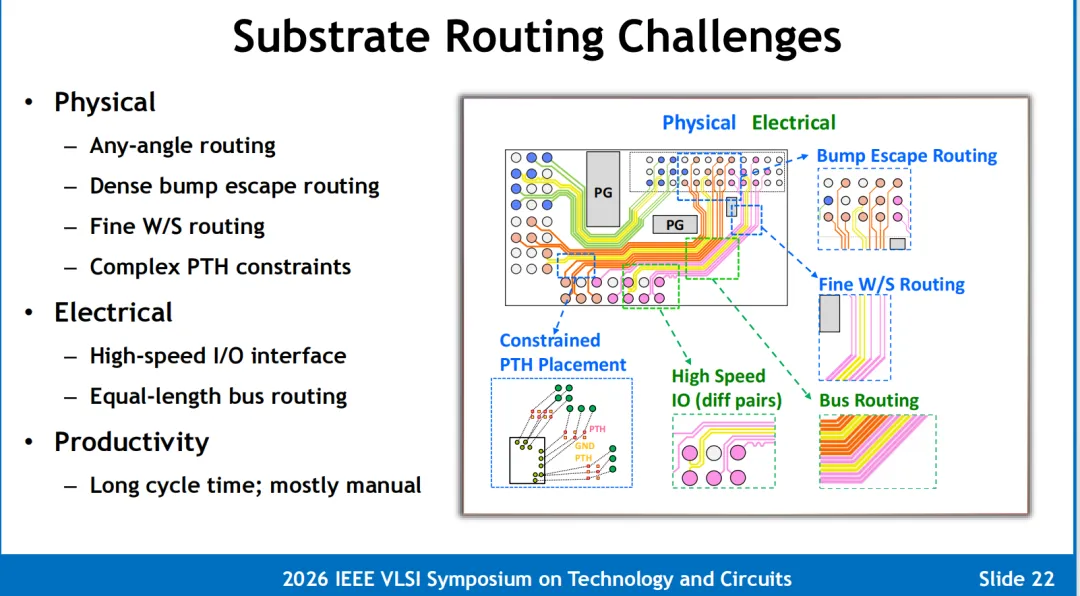
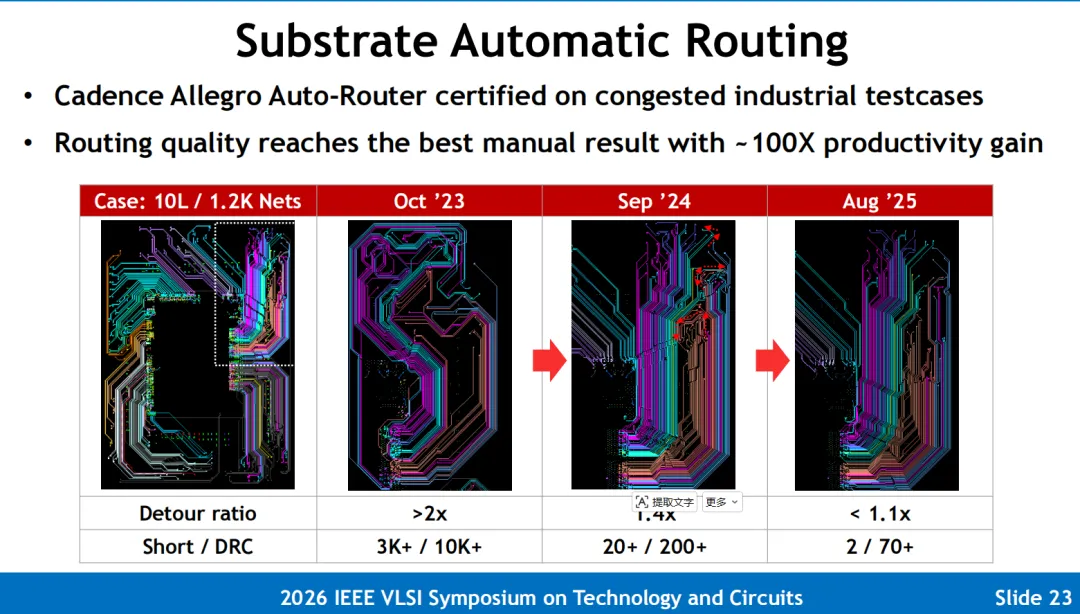

在全栈工作流中,大语言模型(LLM)与 DRL 智能体被解耦为三大核心代理卡位:
设计优化智能体 (Design Optimization Agent): 专注于高频高速接口通道(如 112G/224G/448G SerDes 以及 HBM4 垂直总线)的物理层特阻匹配与自动 TDR 修复。 物理设计智能体 (PD Agent): 自动自适应搬移芯粒位置、摆放去耦电容并规整 BGA 焊球地图,实现芯片 PPA(性能、功耗、面积)的跨代级自动化拉升。 协同编码与 DRC 助手 (DRC Agent & Copilot): 负责自动化生成后道物理验证所需的 EDA 运行脚本(Runsets Coding),并担任高级设计规则检查(DRC)助手,大举清除了前后道交叉带来的协作断层,使大算力 3DIC 芯片的设计生产率实现指数级暴涨。
06. 核心工程技术结论
台积电在 VLSI 2026 上发表的这份顶规报告,为全球下一代半导体异构级联与大算力人工智能基建确立了全新的技术范式:
后摩尔时代的带宽与功耗双重跨越: 明确论证了纯粹的前道微缩红利已难以为记。下一代万亿参数 AI 集群的成败,将完全取决于由 SoIC 混合键合、超大尺寸 CoWoS 面板拼接以及三维光电引擎(COUPE)共同构成的物理层立体高速网络。 后道 EDA 设计流的智能化跃迁: 证实了将大语言模型与 Agentic AI 智能体引入高密度封装设计链,是化解超大型多芯片异构系统在多物理场(SI/PI/TI/EM)联合设计中面临“计算爆炸”的唯一出路。台积电通过在芯片内引入高密度 eDTC 并协同 AI 代理全自动 sign-off 布局布线,正式打通了从工艺制程到算法大脑的端到端软硬件壁垒,全盘奠定了未来高效能 AI 算力扩容的确定性轨道。
? 参考文献 (References)
[1] L.-C. Lu, "Advancing Package and System Integration for Next-Generation AI," in TSMC Keynote Presentation at the 2026 IEEE VLSI Symposium on Technology and Circuits, Honolulu, HI, USA, June 2026, pp. Slides 0-26.
[2] M. F. Chen, T. H. Yu, H. T. Cheng, S. Liu, C. H. Tsou, R. Lu, S. Y. Hou, and K. C. Hsu, "Optical and Electrical Characterization of a Compact Universal Photonic Engine," in Proceedings of IEEE 75th Electronic Components and Technology Conference (ECTC), 2025, pp. 54-58.
[3] S. Ryu et al., "Holistic Design Optimization of 3D-IC Package Substrate Interconnections in Multiple Power Domain Environments based on Hierarchical Reinforcement Learning," in Proceedings of DesignCon 2026, Santa Clara, CA, Feb. 2026, pp. 197-212.
本文由微信公众号【芯有灵矽】独家整理发布。我们致力于分享最硬核的底层半导体工艺、信号/电源完整性分析(SI/PI)及光电共封装多物理场联合仿真技术。如需转载,请注明出处。