全球大模型数据市场白皮书:当算力见顶,数据成为AI时代的价值坐标
艺恩数据 ENDATA · NEEQ 871430
当算力见顶,数据成为AI时代的价值坐标
全球大模型数据市场白皮书(2026年版)核心解读
广义市场规模 2025约100-160亿$
公开语料中位2028年耗尽
Scale AI估值290亿$
01 | 市场与拐点:从「更多数据」到「更对的数据」
进入2025-2026年,随着算力竞赛逼近边际、公开互联网语料趋于枯竭,数据已从「可廉价获取的原料」转变为决定模型上限的稀缺生产要素。市场的核心命题,正由「数据规模」转向「数据质量、专业度与合规性」。
经常被引用的「AI训练数据集」狭义口径,仅约28-32亿美元(2024-25),只统计打包数据集+标注软件,显著低估了真实市场。本白皮书采用广义口径 = 数据集 + 采集标注 + RLHF/专家数据 + 合成数据,自下而上测算:2024年约60-90亿美元,2025年约100-160亿美元(买方支出毛口径)。
? 市场规模增速
20-35%
全球AI训练数据相关市场年复合增速(多家机构共识区间)
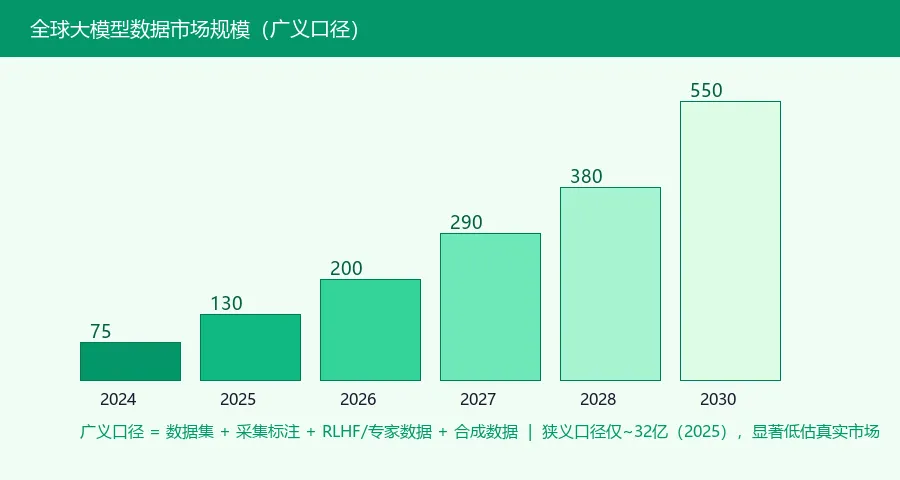
▲ 全球大模型数据市场规模(广义B口径)· 2024-2030预测
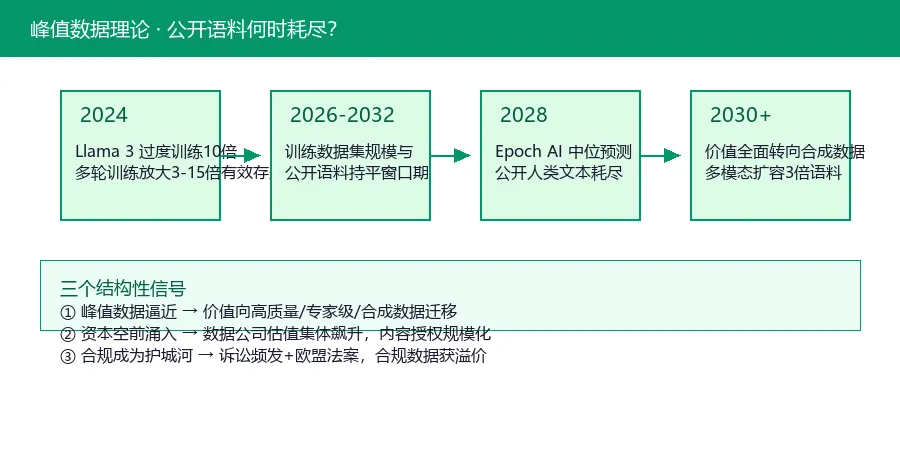
峰值数据:公开语料何时耗尽?
Epoch AI(经ICML 2024同行评审)测算:可用人类公开文本存量约300万亿token。若当前趋势持续,训练数据集规模将在2026-2032年间与公开语料持平,中位数预测约2028年。
⚡ 三个结构性信号
① 峰值数据逼近——公开语料趋于枯竭,价值向高质量、专家级、合规与合成数据迁移;
② 资本空前涌入——数据与专家公司估值集体飙升,内容授权走向规模化;
③ 合规成为护城河——诉讼频发叠加欧盟透明度义务,合规数据获显著溢价。
02 | 价值链与资本:八层结构,价值层层递进
数据价值链可分八层,核心规律是:越靠近「专家级、多模态、可验证」的一端,单位价值越高、可复制性越低。当通用网络语料见顶,价值链上半部(⑤-⑧)的稀缺溢价持续抬升。

① 预训练语料
web/书籍/代码 · 规模化基础,边际价值随枯竭下降
③ RLHF/偏好数据
对齐人类偏好,决定模型「好用」程度
⑤ 专家/领域数据
PhD级 · 突破专业能力天花板,溢价最高
⑧ 多模态数据
图像/视频/4D · 最稀缺、溢价最高的层级
03 | 资本图谱:估值狂飙,资本以真金确认数据稀缺
2025年,全球数据市场迎来估值大年。头部公司估值以十亿、百亿美元量级跃升,标志数据已从「配套服务」升级为「核心战略资产」。

● · · · ● · · · ●
连锁反应:中立性即资产
Meta入股Scale AI后,因数据机密性顾虑,Google、OpenAI、xAI等削减或暂停与Scale的合作,为Surge、Mercor让出空间——这印证了数据供应行业「中立性」本身即为核心资产。
「人类知识的累积总和,已基本在AI训练中被耗尽。大体上去年就发生了。」
—— Elon Musk, 2025/1(via The Guardian)
04 | 合规与监管:从「成本项」转为「定价项」
截至2025年10月,全球追踪到的AI版权诉讼达51-166起。法院核心分野正在形成:「合法获取」可能构成合理使用,「盗版内容」则明确不被宽宥——这直接抬高合规数据溢价。
?? 美国
Anthropic版权和解15亿$
NYT诉OpenAI审理中
三法官:2支持训练方
?? 欧盟
《AI法案》2024/8/1生效
训练数据透明度成硬约束
合规→法定义务
?? 中国
北京/广州/杭州互联网法院
AI生成内容版权可版权性确立
出海视频版权风险上升
⚠️ 出海风险提示:MiniMax/海螺遭迪士尼等12家起诉(2025/9,加州中区),指控大规模盗用版权角色。2026/5法官驳回撤案动议,进入证据开示阶段——中国AI公司出海需高度重视海外版权合规。
05 | 全球格局:中美双核,两套逻辑
中美数据市场由两套不同逻辑驱动:美国是「前沿实验室拉动 + 专家数据溢价 + VC催化」;中国是「数据要素国家战略 + 垂类模型驱动」。

? 大模型数量
1509个
中国已发布大模型,全球占比约40%
? AI企业数量
5300+家
中国AI企业(中国信通院2025)
? 日均Token消耗
140万亿/日
2026/3,较2024初增千倍(国家数据局)
? 数据产业规模预测
7.5万亿
2030年我国数据产业规模预测
中国三大政策支柱
① 「数据要素×」三年行动(2024-2026):聚焦12行业,2026年底打造300+示范场景
② 数据资源入表(财政部《暂行规定》2024/1/1施行):数据从费用化转为资产负债表内显性化
③ 数据标注产业专项(国家发改委2024/12):目标2027年产业规模大幅跃升,已建成7大国家数据标注基地
06 | 未来展望:从「规模」到「质量与专业化」
合成数据主导
Gartner预测2030年占比超真实数据
2027-2030
专家数据崛起
RL环境/Agentic data/可验证奖励成新焦点
现在-2028
具身AI/世界模型
既消耗数据,也生成未训练的合成数据
2026-2032
中美双核
美国前沿+专家溢价;中国数据要素+垂类落地
持续分化
结语:胜负手正从「更多算力」转向「更优质、更合规的数据」;公开语料枯竭非终点,而是价值化的起点。谁掌握稀缺合规数据,谁就掌握下一代AI的定价权。
—— 本文基于艺恩数据《全球大模型数据市场白皮书(2026年版)》撰写 ——

5G创见 · 九宝 · 用绿版排版


