


系列导读当大模型参数突破万亿,决定 AI 效率的不只是算力峰值,还有数据从存储到计算的"流转效率"。本系列基于阿里云《AI 网络白皮书》,按 AI 业务的三大阶段——数据采集、模型训练、模型推理——拆成三篇,逐一拆解阿里云网络是如何"以网增算"的。这是第一篇:数据采集与预处理。
一、AI 训练的第一公里:你以为是算力,其实是IP和带宽
很多人讨论 AI,第一反应是GPU、是H100、是万卡集群。
但真正动手做过大模型的同学都知道:整个训练流程的第一步,是把 PB 级的原始语料从公网"扒"回来。
这件事看起来朴素,痛点却一点不少:
一个IP高频访问目标网站,几分钟就被封;
几十路爬虫并发,本地出口带宽瞬间打满;
数据采到了,分散在全球十几个Region,再回流到训练集群,跨地域带宽成了新瓶颈;
同步数据时还要和在线业务抢带宽,谁都跑不快。
一句话:没有海量公网 IP + 全球高速内网,再多GPU也只能"干等米下锅"。
二、阿里云怎么解?一张图看懂"采集->传输->预处理"全链路
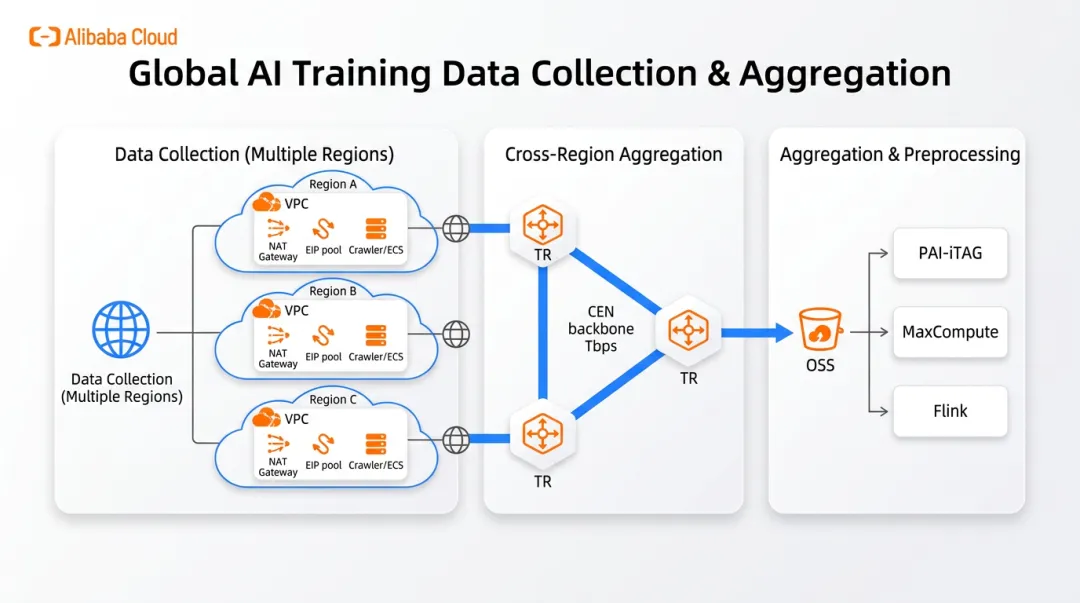
整张网络可以拆成三段,目标只有一个:让数据像快递一样,从全球节点低成本、合规、可控地汇聚到训练集群门口。
三、就近数据源做采集,把"IP围城"打破
数据源在哪里,采集程序就在哪里。这是阿里云方案的第一原则。
1)海量公网 IP 与带宽供给
在数据源附近的Region创建采集VPC,里面跑通用ECS或容器化的爬虫程序,出口走两条路:
NAT网关+EIP地址池:通过弹性公网IP池叠加SNAT,让同一个采集任务的请求随机使用不同公网IP出去,充分打散源IP,规避单IP封禁;
共享带宽:把多个EIP的带宽合在一起统一计费、统一调度,避免一个任务把带宽吃满影响其他任务。
2)IP 服务商生态:内网调用代理 IP
如果几百上千个EIP还不够用(典型的搜索/爬虫/电商比价场景),阿里云通过PrivateLink私网连接对接第三方代理IP服务商:
走云上内网调用代理 IP 池,比走公网调代理 API 更快、更安全、更稳定——这一步是很多企业自建采集体系的盲区。
3)合规与隔离
采集VPC推荐放在DMZ区,跟训练VPC、敏感数据VPC物理隔开;高敏感原始数据写入存储后,禁止公网直接访问,通过安全组、网络ACL、私网连接控制跨VPC 通信。
四、跨地域数据聚集,把数据"管道化"
数据采到了,分散在 N 个Region,怎么聚到训练所在Region的OSS?
阿里云的标准做法是:云企业网CEN + 转发路由器TR。
每个Region创建TR,把本地采集VPC挂上来;
各地域TR之间互联,主要Region之间是Tbps级互联带宽,每天有数百PB数据在Region间流动;
跨地域链路提供金/银/铜三档差分服务——离线训练数据走铜牌降本,在线推理走金牌保时延,互不干扰;
TR 上做QoS流量整形,把"采集大象流"和"算力池关键流"严格区分带宽,不让批量数据回传挤掉训练通信。
一个常被忽略的细节:ZooRoute 主动重路由技术,让跨地域链路故障在 1 秒内收敛,业务层完全无感知。这是 AI 训练这种"长任务"最怕踩的坑——一次抖动可能让 checkpoint 之前的训练全部白跑。
五、聚集Region内做预处理,能用云服务就别自建
数据落到训练 Region的OSS之后,下一步是清洗、标注、格式转换、特征工程。
阿里云的建议很务实:优先用现成的云服务,少自建。
PAI-iTAG:可视化数据标注平台,多人协同;
MaxCompute:海量数据SQL化清洗与转换;
Flink:流式预处理,适合日志类、行为类数据;
也可以在数据采集VPC里跑自己的CPU/GPU算力做预处理。
预处理好的数据再写回OSS,等待训练阶段按需拉取。
六、规划落地的4条建议
写到这里,做个总结。如果你正在为企业搭建 AI 数据采集网络,这 4 件事值得提前定:
① VPC分层:采集、预处理、训练、推理至少分在 4 个VPC或子网里,用安全组+私网连接控制跨域通信,不要一个VPC走天下。
② 出口架构:通用场景上NAT网关+EIP池+共享带宽;高并发反爬场景上PrivateLink + 第三方代理 IP。
③ 跨地域:用CEN+TR,提前规划带宽和金银铜链路等级,把训练通信和数据回传的带宽"账本"算清楚。
④ 预处理就近化:预处理紧贴OSS部署,能用 PAI-iTAG/MaxCompute/Flink 就别自己拉一套,省钱省运维。
七、彩蛋:这一篇没讲的事
数据准备好了,下一步就是怎么把它高效"喂"给GPU集群:
单台机头网卡跑到200Gbps、按需开RDMA是怎么做到的?
跨云算力池为什么需要400Gbps 单专线+专线倒换组?
ZooRoute故障收敛 < 1 秒到底是不是玄学?
这些就是下一篇《训练网络篇》要讲述的内容了。
