



AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
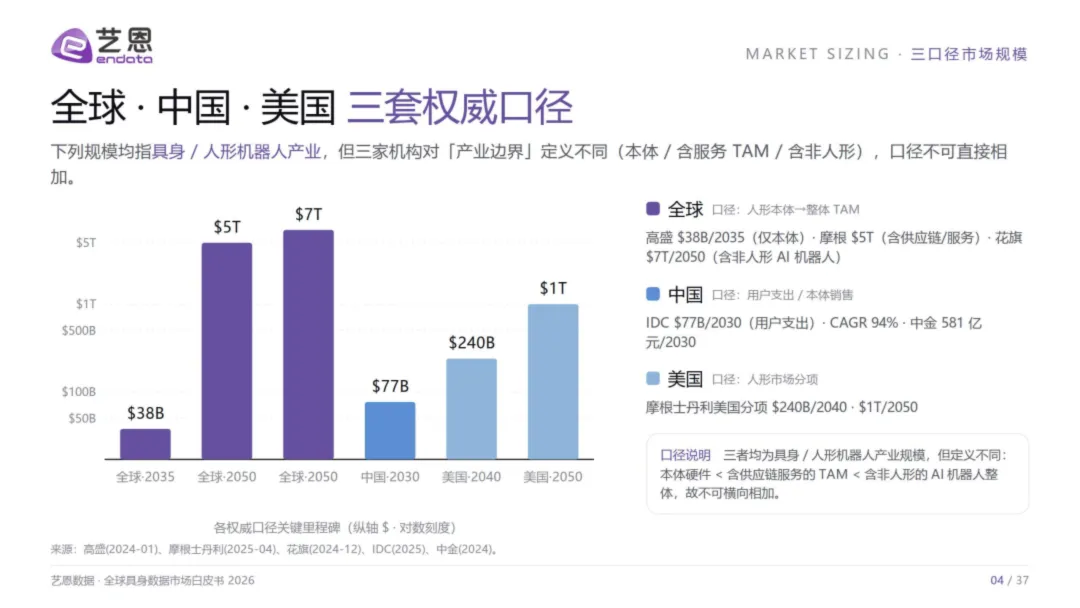
一、两万倍的差距,才是真正的起点
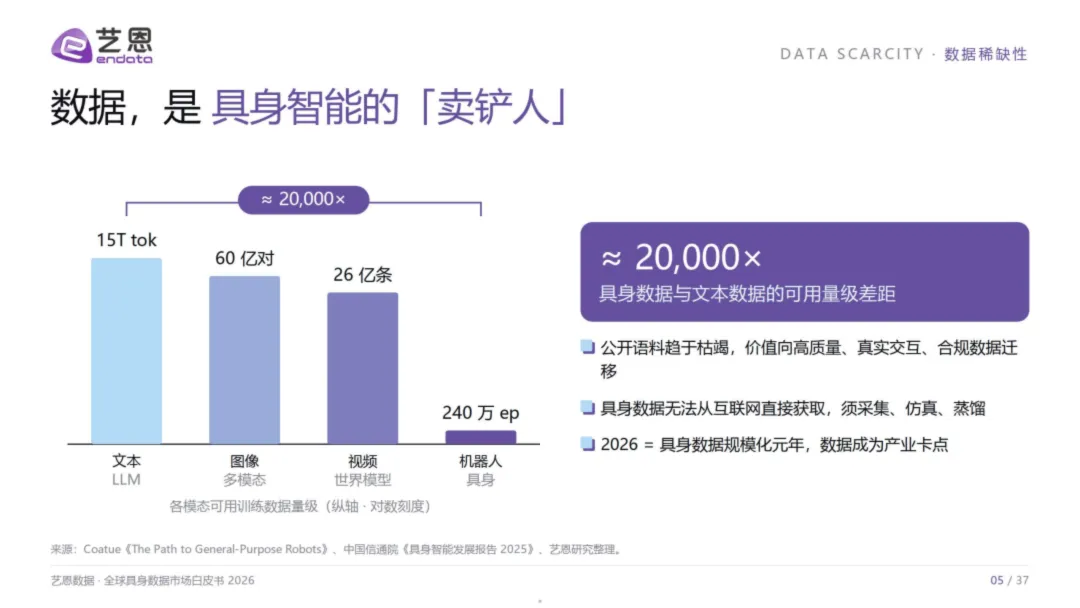
一个数字足以改写叙事:具身训练数据与文本数据的可用量级差距,约为20,000倍。
大语言模型吃掉了15万亿token的语料,才换来ChatGPT的一鸣惊人。而全球机器人领域目前仅有约240万条episode——连文本数据的零头都不够。这就是具身智能最残酷的底层现实:算法的 ceiling 不是算力,不是架构,而是数据供给。
艺恩这份白皮书没有像多数行业报告那样从本体出货量或融资额起笔,而是直接把刀插进最痛的地方——数据稀缺性。这个选择本身就是一种判断:当行业还在争论"谁家的机器人更灵活",真正的卡位战已经在上游悄然打响。
数据,是具身智能时代的"卖铲人"。 在淘金热中,卖铲子的人往往比淘金者更早盈利、更久存活。
二、四范式争锋:稀缺性的四种解法
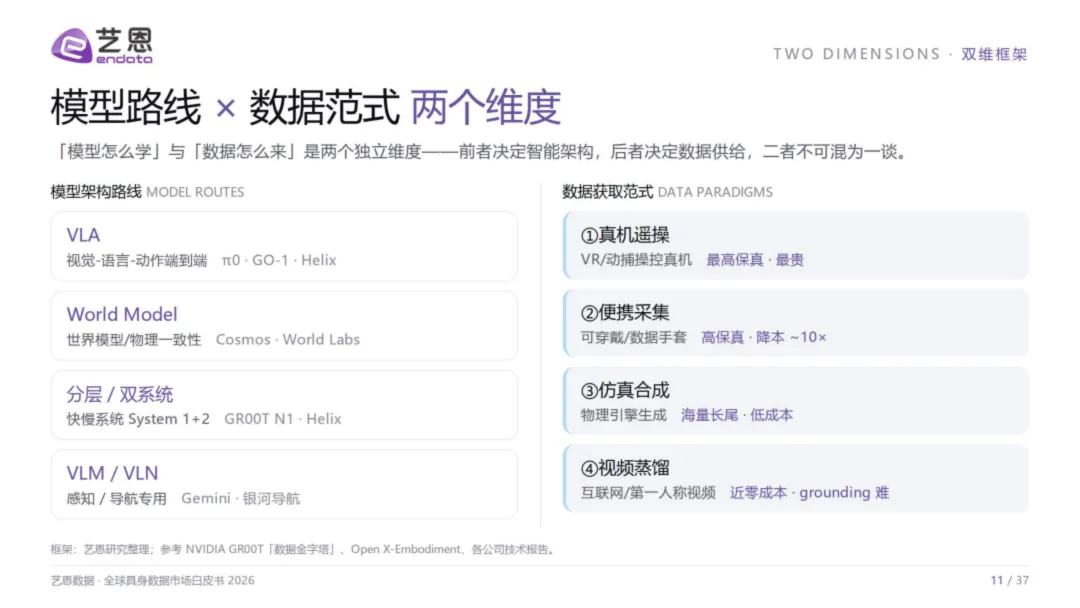
面对20,000倍的供给缺口,行业没有等一个终极方案,而是同时催生了四条数据获取路线——白皮书将其概括为"四范式",并用一张成本×保真度的2×2矩阵精准定位:
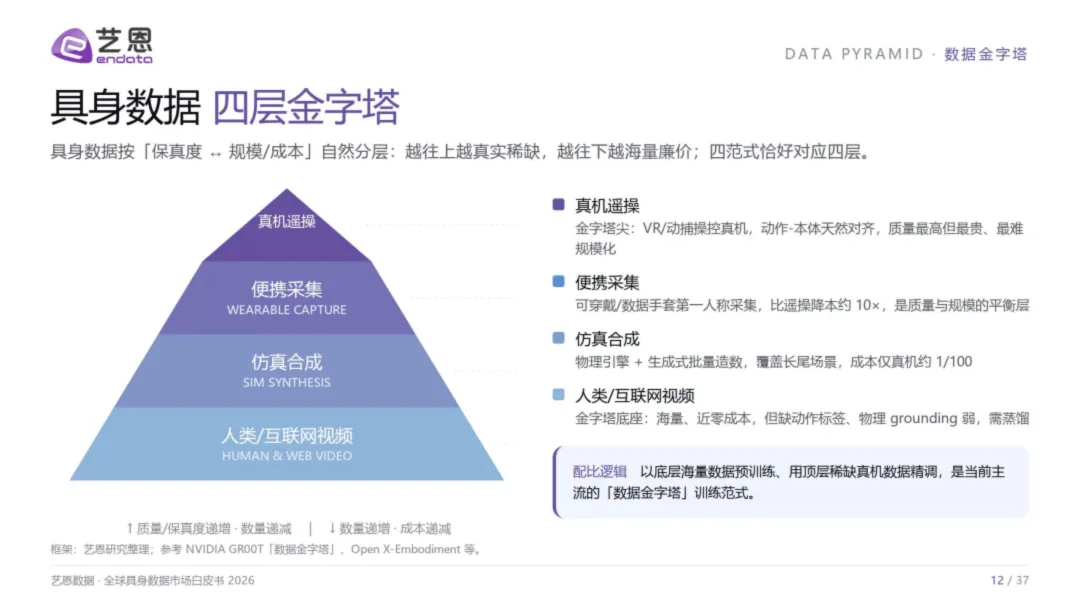
真机遥操——金字塔尖。VR或动捕操控真实机器人,动作与本体天然对齐,保真度最高,但单套设备超20万元,规模化是最难的坎。帕西尼感知以6D触觉传感+采集工厂切入,B轮融资破10亿元;诺亦腾凭借全球超50%的动捕份额,与智元共建数据工厂。
便携采集——平衡层。可穿戴设备或数据手套以第一人称视角采集,成本降至遥操的约十分之一,是保真与规模之间最务实的折中。它石智航SenseHub获Pre-A轮4.55亿美元,灵初智能以62+自由度触觉手套积累超10万小时数据。
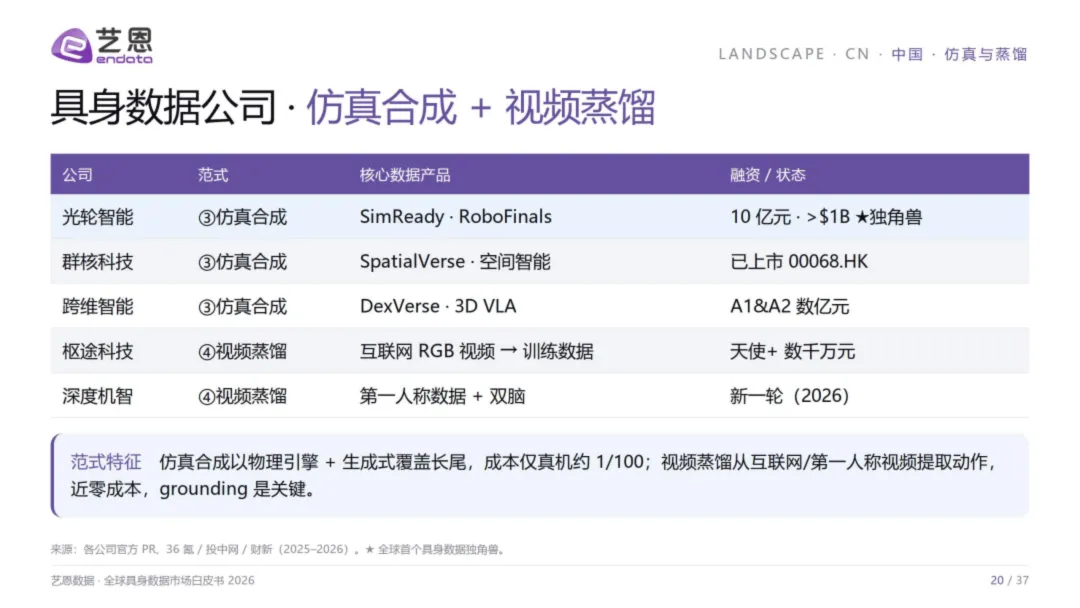
仿真合成——长尾覆盖者。物理引擎+生成式批量造数,成本仅为真机的百分之一。光轮智能正是此范式的旗舰——创始团队来自NVIDIA/Cruise/蔚来仿真部门,2025营收10倍增长,2026Q1已超2025全年,估值突破10亿元,成为全球首个具身数据独角兽。
视频蒸馏——近零成本的黑马。从互联网或第一人称视频中提取动作信号,海量供给、近乎零成本,但物理grounding是最大挑战——视频里的动作,机器未必能复现。枢途科技和Meta Ego4D是此路线的代表。
四范式不是"谁取代谁"的零和博弈,而是金字塔的四层——越往上越真实稀缺,越往下越海量廉价。主流训练策略是"底层海量预训练+顶层稀缺精调"的配比逻辑。NVIDIA的GROOT数据金字塔,正是这一分层思想的工程化呈现。
三、价值链上移:数据层的毛利率碾压硬件
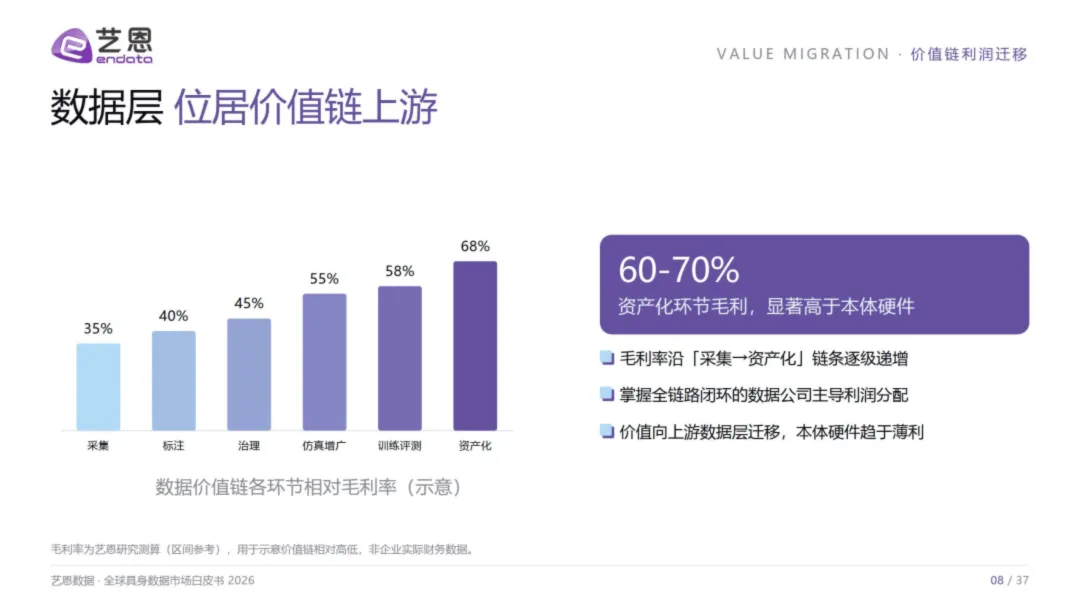
白皮书揭示了一条反直觉的利润迁移线:毛利率沿"采集→标注→治理→仿真增广→训练评测→资产化"逐级递增。
采集环节毛利约35%,到了资产化环节——数据集授权、DaaS订阅、评测基准服务——毛利飙升至60-70%。这意味着什么?掌握全链路闭环的数据公司,将主导利润分配;而本体硬件,正走向薄利。
这和智能手机产业的历史如出一辙:终端厂商拼价格,芯片和操作系统厂商拿走了利润的绝大部分。具身智能正在重演这一剧本——数据层就是未来的"芯片+OS"。
光轮智能的商业模式印证了这个判断:数据集授权+DaaS订阅+RoboFinals评测基准,三条变现路径均属于资产化环节,客户名单涵盖NVIDIA、Figure、1X、字节、智元、银河——它不造机器人,却服务于几乎所有头部玩家。
四、中美双轨:封闭飞轮 vs 开放分工
白皮书最值得深思的判断之一,是中美数据策略的"双轨"分野。
美国走"封闭飞轮"。 Tesla用FSD同源视觉数据喂养Optimus,Figure自采遥操数据闭源训练,NVIDIA虽然开源Cosmos与GROOT生态,但本质是拉开发者进入自家算力轨道——数据飞轮一旦闭环,外部玩家很难切入。
中国走"开放+专业化分工"。 光轮、它石、帕西尼、灵初等独立数据公司沿四范式各自做深,智元甚至开源了百万级AgiBot World数据集。这种分工模式更易形成数据交易市场,也更适应中国场景丰富、工程化快、采集成本低的现实优势。
两条路线各有胜算:封闭飞轮壁垒深,但迭代慢、生态窄;开放分工灵活快,但标准缺位、协同成本高。最终谁赢,取决于哪条路更快解决20,000倍的稀缺问题。
五、2026:数据规模化元年,也是泡沫检验年
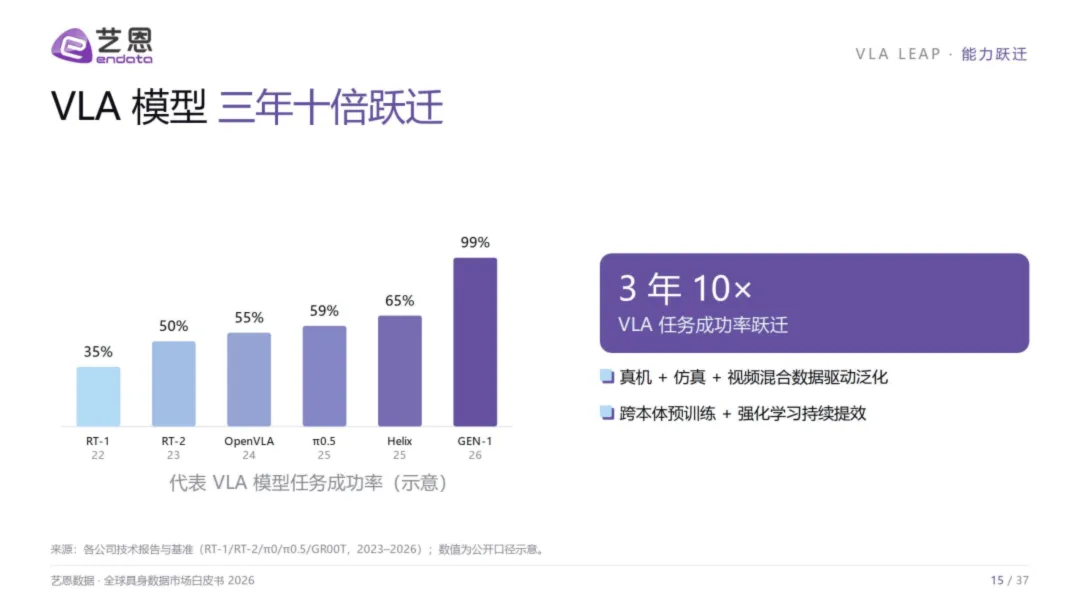
白皮书将2026定义为"具身数据规模化元年"——真机+仿真+视频混合数据开始爆发,VLA模型三年十倍跃迁(从RT-1到GEN-1,任务成功率从约35%冲向近99%),世界模型从概念走向工程化。
但冷静的参照系同样清晰:UBS已警示估值领先于商业化的泡沫风险,多数出货仍流向科研、数采与展示,而非真正的终端用户场景。Sim2Real鸿沟——仿真保真度与真实物理的差距——仍是核心挑战。数据合规与版权、采集与评测标准,也都在建设中。
已落地的商业化场景提供了锚点:医疗康复(Wandercraft FDA通过,傅利叶覆盖40+国家)、物流仓储(Agility Digit在GXO,京东自营)率先盈利;工业制造和商业服务正在试点;家庭服务的万亿想象,则至少还需三年以上的等待。
六、悬念未解
这份白皮书最大的价值,不在数据罗列,而在它提出的问题比结论更有张力:
四范式终将收敛还是长期并行?封闭飞轮与开放分工哪条路更快跨越数据鸿沟?当数据资产化真正到来,谁有资格定义"好数据"的标准?以及——在20,000倍的稀缺面前,"卖铲人"自己,会不会也缺铲?
2026年的具身数据市场,像极了2012年的云计算——基础设施刚刚成型,赢家尚未锁定,所有人都知道方向,但没人确信路径。艺恩这份白皮书,是这场基础设施竞赛的第一份战报。它不预测终局,但清晰地标出了起跑线。
起跑线上的关键命题只有一个:数据够不够,决定了具身智能能不能从实验室走进真实世界。 在这个命题面前,所有关于形态、关节和步态的讨论,都是次要叙事。
本文基于艺恩《全球具身数据市场白皮书》撰写,详细内容请查阅原文。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群













AI科普馆:打开AI世界之窗

