


DATA-CENTRIC AI系列连载 第 16 期
Data augmentation
Data-centric AI - Data augmentation
Data augmentation
ABSTRACT
近年来,数据增强在提升模型泛化能力与鲁棒性方面扮演着关键角色,研究焦点已从传统图像领域扩展至大语言模型、图结构数据和多模态学习。针对LLM推理能力的提升,LogicTree通过合成多步逻辑数据增强复杂推理 Wang et al., 2025[1],而Prismatic Synthesis利用梯度引导的数据多样化策略有效改善推理泛化 Jung et al., 2025[2]。在偏好对齐与奖励建模中,有限偏好数据的问题通过潜在空间合成得以缓解 Tao et al., 2025[3],同时大规模开放偏好数据集HelpSteer3-Preference为跨任务、跨语言场景提供了高质量标注资源 Wang et al., 2025[4]。面向数据分布不平衡与长尾问题,扩散模型被用于图数据增强 Marrium et al., 2025[5],多轮生成式方法提升了长尾实例分割的样本效率 Kim et al., 2025[6],而基于错配检测的增强策略则针对多模态不平衡学习提出了解决方案 Hwang et al., 2025[7]。此外,通过投影无关的通用数据增强实现LLM领域自适应 Lee et al., 2025[8],以及利用多智能体模拟教学进一步强化模型能力 Yue et al., 2025[9]。这些工作共同推动了数据增强从单一模态向复杂推理、分布偏移和低资源场景的系统性发展。
01
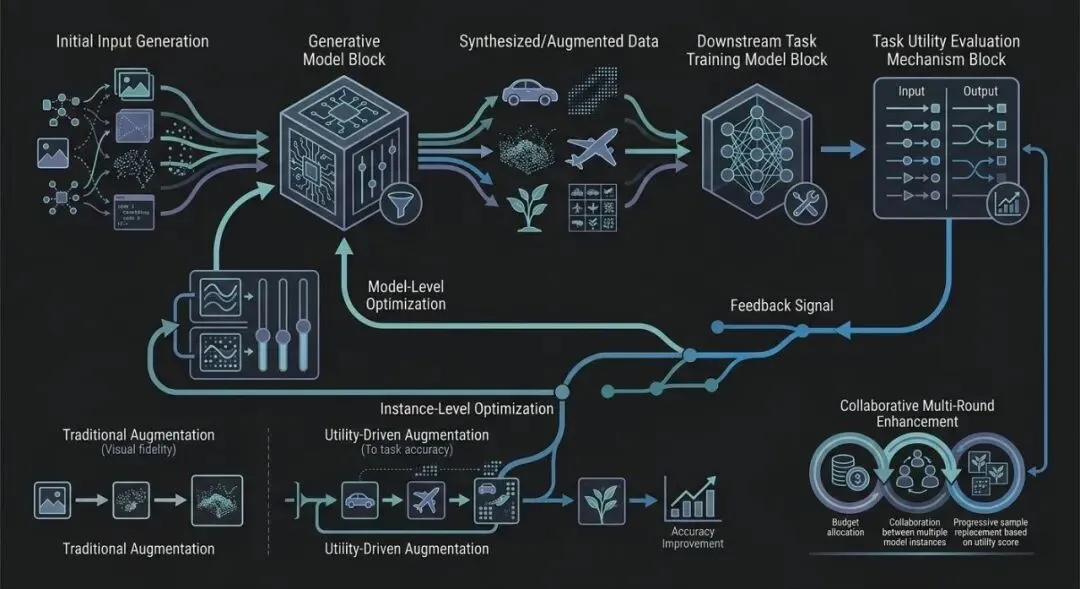
从视觉保真到任务效用的生成式增强范式转向
当前生成式数据增强的核心矛盾已从“如何生成逼真样本”转向“如何生成对下游任务有用的样本”。早期方法主要优化合成数据的视觉质量或多样性,例如通过LoRA微调对齐分布或通过提示扰动增加多样性,但这类方法往往忽视不同任务和模型架构对训练数据分布的特殊需求。UtilGen框架首次系统性地提出任务效用评估机制,通过元学习的权重分配网络量化每个合成样本对特定任务的价值,并基于此信号进行模型级和实例级的双级优化——模型级使用直接偏好优化调整生成器参数,实例级则优化提示嵌入与初始噪声。这种范式转变在多轮协作增强方法中得到呼应:假设模型反馈能持续提升增强质量,通过累积预算和协作机制逐步替换低效用样本。与仅关注视觉特征的方法相比,效用驱动的方法在八个基准数据集上平均提升3.87%的准确率,甚至首次实现仅用3倍合成数据训练的ResNet-50超越真实数据基线。这一趋势同样体现在其他工作中:Kim et al., 2025[10] 针对风险规避微调生成信息样本,强调样本的“信息量”而非视觉真实性;Tao et al., 2025[3] 在有限偏好数据下通过潜在空间合成改进奖励模型,同样绕开对原始数据分布的简单复制。这些工作共同指向一个核心共识:数据增强的设计目标应从“像真实数据”转变为“对任务有效”。
02
多模态与结构化数据中的稀缺性与不平衡应对策略
多模态和结构化数据场景下,数据增强面临更复杂的异质性和不平衡挑战。Hwang et al., 2025[7] 提出的MIDAS方法专门针对多模态学习中的模态不平衡问题,通过度量不同模态间的对齐程度来识别弱势模态,并基于错位信号生成有针对性的增强样本。在CREMA-D和Food-101数据集上,MIDAS超越了传统混合方法(如Mixup)以及端到端联合训练,其关键创新在于不单独优化每个模态的增强,而是利用模态间的交互信息指导生成过程。对于图结构数据,Marrium et al., 2025[5] 引入扩散模型引导的图数据增强,在保持图拓扑结构的同时生成新节点和边,解决了传统图增强方法(如节点丢弃、边扰动)可能破坏语义的问题。而在视频深度重建领域,Ma et al., 2025[11] 提出的Puzzles方法采用无界视频深度增强,通过几何变换和物理感知增强(如光照、运动模糊)合成丰富的训练样本,弥补了真实视频深度数据在多样性和数量上的不足。这些方法均体现出对数据内在结构(模态对齐、图拓扑、时空连续性)的深度利用,而非简单的像素级操作。跨论文比较可以发现,MIDAS侧重于模态间的判别性信息,而Marrium等侧重于图结构的生成一致性,Ma等则强调物理现实感——尽管任务不同,但都通过建模数据本身的固有约束来提升增强的针对性。
03
面向大型语言模型的推理增强与领域适应
大型语言模型的推理能力和领域适应性高度依赖训练数据的质量和多样性,数据增强在此扮演关键角色。Wang et al., 2025[1] 提出的LogicTree通过实例化多步合成逻辑数据来增强复杂推理,其核心是自动构造包含中间推理步骤的树状结构样本,使模型学会分解问题。与之形成对比的是Jung et al., 2025[2] 的Prismatic Synthesis,该方法采用基于梯度的数据多样化策略,通过优化合成数据的梯度方差来提升泛化性,而非仅增加数据量。两者代表了两种增强思路:结构化知识注入与分布多样性驱动。在领域适应方面,Lee et al., 2025[8] 提出的PANGEA利用投影将非相关通用数据映射到目标域,实现无监督领域适应,突破了传统增强必须依赖源域数据的限制。而Yue et al., 2025[9] 的MASTER则通过多智能体模拟教学环境,让多个教师模型协作生成教学数据,以增强LLM在特定任务上的表现。这些工作展示了LLM增强的多样性:LogicTree注重逻辑链的显式构造,Prismatic Synthesis强调梯度空间中的覆盖,PANGEA关注特征投影的可迁移性,MASTER则利用多智能体交互产生更自然的教学对话。不同方法对合成数据的控制粒度存在显著差异,从离散的逻辑步骤到连续的梯度信息,再到整体的对话场景。
04
迭代反馈与多轮协作的增强机制优化
数据增强不再是一次性生成静态集合,而是演变为基于模型反馈的迭代优化过程。多轮协作增强范式在实例分割任务中展现成效:Kim et al., 2025[6] 提出的样本高效多轮生成式增强方法,通过在每轮训练后利用当前模型反馈识别困难样本或长尾类别,并针对性地生成新样本,同时引入预算分配机制控制每轮的生成数量,显著提升了长尾场景下的性能。其核心假设与UtilGen中的协作增强假设一致:模型反馈能持续提升增强质量,且需要满足模型容量充足和分布控制等条件。在偏好数据收集方面,Wang et al., 2025[4] 的HelpSteer3-Preference构建了跨任务、多语言的人工标注偏好数据集,但更重要的是其揭示了标注数据本身的不完备性,间接支持了通过合成数据扩展偏好分布的思路。与单轮生成不同,迭代方法面临合成偏差累积问题:合成样本的统计误差与生成偏差共同影响最终性能,多轮协作需要平衡新样本的信息增益与旧样本的保留价值。这类机制在实践中的关键挑战是如何高效评估每一轮中合成样本的任务效用,避免陷入计算开销过大的全训练评估循环。当前主流方案包括元学习权重网络或代理模型快速评分,但如何设计更轻量的效用预测器仍是开放问题。
REFERENCES
[1] LogicTree: Improving Complex Reasoning of LLMs via Instantiated Multi-step Synthetic Logical Data. NeurIPS 2025.
[2] Prismatic Synthesis: Gradient-based Data Diversification Boosts Generalization in LLM Reasoning. NeurIPS 2025.
[3] Limited Preference Data? Learning Better Reward Model with Latent Space Synthesis. NeurIPS 2025.
[4] HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages. NeurIPS 2025.
[5] Diffusion-Guided Graph Data Augmentation. NeurIPS 2025.
[6] Sample-Efficient Multi-Round Generative Data Augmentation for Long-Tail Instance Segmentation. NeurIPS 2025.
[7] MIDAS: Misalignment-based Data Augmentation Strategy for Imbalanced Multimodal Learning. NeurIPS 2025.
[8] PANGEA: Projection-Based Augmentation with Non-Relevant General Data for Enhanced Domain Adaptation in LLMs. NeurIPS 2025.
[9] MASTER: Enhancing Large Language Model via Multi-Agent Simulated Teaching. NeurIPS 2025.
[10] Generating Informative Samples for Risk-Averse Fine-Tuning of Downstream Tasks. NeurIPS 2025.
[11] Puzzles: Unbounded Video-Depth Augmentation for Scalable End-to-End 3D Reconstruction. NeurIPS 2025.
PREVIOUS
第 15 期 — Computer Vision: Vision Models & Multimodal
NEXT ISSUE
Data-centric AI — Data-centric AI methods and tools
深入解析数据为中心的AI领域前沿进展

- END -