


APPLICATIONS系列连载 第 10 期
Time Series
Applications - Time Series
Time Series
ABSTRACT
近期时间序列研究在预测、异常检测、生成与基础模型等方向取得显著进展。在预测方面,工作聚焦于提升模型对复杂动态与长期依赖的建模能力。Mohapatra et al., 2025[1] 提出自适应稀疏注意力机制以处理多模态动态时间序列,而 Liang et al., 2025[2] 则通过自适应掩码损失与表示一致性约束增强预测鲁棒性。Wu et al., 2025[3] 从补丁视角出发构建选择性表示空间,Qiu et al., 2025[4] 提出基于分解的损失函数以分离趋势与季节成分,Liu et al., 2025[5] 则利用实例感知后验修正进一步提升预测精度。针对零样本场景,Auer et al., 2025[6] 的 TiRex 模型通过增强上下文学习实现跨长短时域的泛化。在异常检测领域,Cai et al., 2025[7] 引入自扰动机制与异常感知图动态建模多变量时间序列异常。Wagner et al., 2025[8] 则贡献了工业化工过程数据集以推动实际异常检测评估。时间序列生成方面,Chen et al., 2025[9] 提出单步算子学习加速条件扩散模型,Fadlon et al., 2025[10] 针对不规则数据设计含补全与掩码的扩散生成框架。基础模型研究同样活跃,Zhao et al., 2025[11] 通过结构化剪枝实现专业化时间序列基础模型,而 Hemmer et al., 2025[12] 在零样本动力系统推理中保持长期统计特性。这些工作共同推动了时间序列分析在方法创新与跨场景适用性上的进步。
01
基于生成式预训练与符号动力学的时间序列基础模型构建
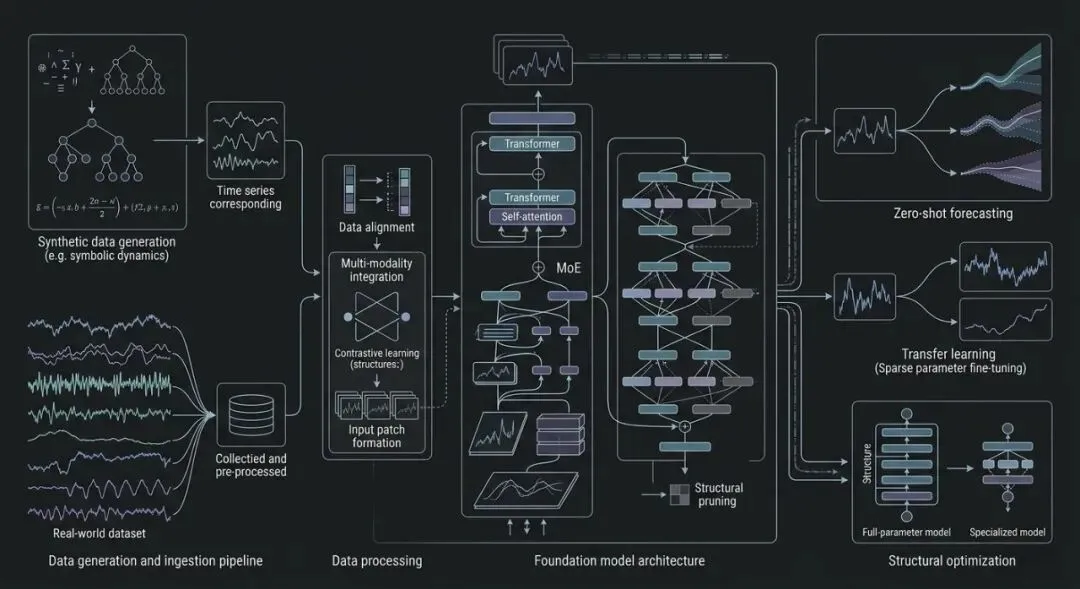
当前时间序列基础模型的研究正从大规模真实数据预训练转向合成数据驱动的范式。多个工作探索了通过复杂动力学系统生成高质量训练数据的方法,例如 Zhao et al., 2025[11] 提出的结构化剪枝策略表明,基础模型可以通过稀疏化实现专业化,而无需依赖海量真实数据。与之互补,SymTime 框架(片段中提及)采用双模态数据生成机制,基于随机二叉树算法构造符号表达式并生成响应时间序列,通过对比学习将时间序列与其生成符号系统对齐,从而覆盖更广的表示空间。然而,该机制面临符号表达式树过大、微分积分操作导致采样效率下降等局限,未来需引入常微分/偏微分方程以增强多样性。另一方面,Auer et al., 2025[6] 提出的 TiRex 则通过增强上下文学习实现零样本预测,其预训练数据来自多种频率的真实序列,与合成数据路线形成对比。在模型架构层面,PatchTST、TimesNet、iTransformer 等经典模型仍作为基线广泛使用,而 Time-MoE 系列(片段中提及)通过混合专家层扩展容量,其微调版本在 ETTh1 等数据集上取得了有竞争力的 MSE/MAE 结果。值得注意的是,Zhao et al., 2025[11] 的工作揭示了基础模型存在大量冗余参数,通过结构化剪枝可在保持性能的同时大幅降低计算成本,这为未来轻量化基础模型的设计提供了新思路。整体来看,合成数据与真实数据、全参数微调与剪枝专业化之间的权衡,构成了当前基础模型研究的核心张力。
02
检索增强与上下文学习在时间序列预测中的融合范式
检索增强生成(RAG)技术正被系统性地引入时间序列预测领域,以弥补纯参数化模型在长尾分布和罕见模式上的泛化不足。片段中列举了 ReTime、RATD、RAFT 和 TimeRAG 等多种方法,它们均从训练集中构建检索数据库,并通过检索相关历史序列来辅助预测。ReTime 采用关系检索与内容合成,RATD 将检索结果用于引导扩散模型的去噪过程,RAFT 则结合多分辨率框架与检索机制。这些方法通常需要针对下游任务进行微调,而 TimeRAG 进一步将检索结果融入生成过程。与这些需要微调的方案不同,Auer et al., 2025[6] 的 TiRex 实现了真正的零样本预测,其核心在于通过上下文学习(in-context learning)直接利用输入序列中的模式,无需额外检索数据库。此外,Hemmer et al., 2025[12] 的工作关注动力系统的长期统计量保持,其零样本推理能力与检索增强形成互补——前者依赖物理约束,后者依赖数据驱动。在效率方面,检索方法面临数据库构建和检索延迟的挑战,而上下文学习则受限于上下文窗口长度。未来趋势可能将检索与上下文学习结合,例如在预训练阶段引入检索增强的对比目标,或设计混合架构同时利用检索结果和上下文信息。值得注意的是,Chen et al., 2025[9] 提出的单步算子学习为条件扩散模型提供了高效采样途径,这或许能加速检索增强扩散模型的推理过程。
03
面向不规则、多模态与缺失数据的时间序列建模突破
真实世界的时间序列往往具有不规则采样、多模态异步和严重缺失等特性,而现有基准大多假设规则、干净的数据,导致研究与实践之间存在显著鸿沟。Time-IMM 数据集(片段中提及)专门针对这一挑战,定义了九种不规则类型,包括触发式、约束式和伪影式机制,并配套 IMM-TSF 基准库,为不规则多模态多变量时间序列提供了标准化评估平台。在建模方法上,Fadlon et al., 2025[10] 提出了一种扩散模型,能够从不规则数据中生成规则时间序列,同时完成缺失值填充和掩码处理,将不规则性转化为生成任务的一部分。Mohapatra et al., 2025[1] 的 MAESTRO 则通过自适应稀疏注意力机制处理多模态动态时间序列,在保持计算效率的同时捕捉跨模态依赖。对于非平稳信号,Wu et al., 2025[13] 提出小波典型相干分析,能够揭示时变频率域的相关结构,为不规则采样下的非平稳分析提供了理论工具。此外,Draxler et al., 2025[14] 的工作聚焦混合类型事件序列,将离散事件与连续时间建模统一,扩展了不规则时间序列的应用场景。这些方法从不同角度(生成、注意力、频域、事件建模)应对不规则性,但尚未形成统一框架。未来需要建立更全面的基准,并探索将多种策略(如扩散填充+稀疏注意力)集成到端到端模型中。
04
任务导向的损失函数设计与后处理优化策略
时间序列预测的性能提升不仅依赖模型架构,还高度依赖于损失函数的设计和后处理策略。传统 MSE/MAE 损失无法充分捕捉时间序列的多尺度结构,Qiu et al., 2025[4] 提出的 DBLoss 将分解思想融入损失函数,显式惩罚趋势、季节性和残差分量的预测误差,在多个长时预测基准上优于标准损失。Liang et al., 2025[2] 则从表示一致性角度出发,提出自适应掩码损失,通过保留核心表示并约束掩码区域的重建,提升模型对缺失和噪声的鲁棒性。后处理方面,Liu et al., 2025[5] 提出实例感知的后验修正方法,在模型输出基础上根据每个样本的局部统计特性进行自适应调整,显著改善了长时预测的累积误差。对于异常检测任务,Cai et al., 2025[7] 设计了自扰动异常感知图动力学,通过图结构学习捕获多变量间的动态依赖,并利用自扰动机制增强对异常模式的敏感性。工业场景中,Wagner et al., 2025[8] 的 NoBOOM 提供了化学过程数据集,并强调异常检测需要兼顾时序依赖和过程物理约束。在分类任务中,Ying et al., 2025[15] 提出基于滑动窗口的层次化变量分组方法 SGN,通过分组注意力捕获变量间的局部交互,提升了多变量时间序列分类的准确率。这些工作表明,任务特定的损失函数和后处理模块正成为提升模型泛化能力和鲁棒性的关键杠杆,未来有望与基础模型架构联合优化。
REFERENCES
[1] MAESTRO : Adaptive Sparse Attention and Robust Learning for Multimodal Dynamic Time Series. NeurIPS 2025.
[2] Abstain Mask Retain Core: Time Series Prediction by Adaptive Masking Loss with Representation Consistency. NeurIPS 2025.
[3] Enhancing Time Series Forecasting through Selective Representation Spaces: A Patch Perspective. NeurIPS 2025.
[4] DBLoss: Decomposition-based Loss Function for Time Series Forecasting. NeurIPS 2025.
[5] Improving Time Series Forecasting via Instance-aware Post-hoc Revision. NeurIPS 2025.
[6] TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In-Context Learning. NeurIPS 2025.
[7] Self-Perturbed Anomaly-Aware Graph Dynamics for Multivariate Time-Series Anomaly Detection. NeurIPS 2025.
[8] NoBOOM: Chemical Process Datasets for Industrial Anomaly Detection. NeurIPS 2025.
[9] Single-Step Operator Learning for Conditioned Time-Series Diffusion Models. NeurIPS 2025.
[10] A Diffusion Model for Regular Time Series Generation from Irregular Data with Completion and Masking. NeurIPS 2025.
[11] Less is More: Unlocking Specialization of Time Series Foundation Models via Structured Pruning. NeurIPS 2025.
[12] True Zero-Shot Inference of Dynamical Systems Preserving Long-Term Statistics. NeurIPS 2025.
[13] Wavelet Canonical Coherence for Nonstationary Signals. NeurIPS 2025.
[14] Transformers for Mixed-type Event Sequences. NeurIPS 2025.
[15] SGN: Shifted Window-Based Hierarchical Variable Grouping for Multivariate Time Series Classification. NeurIPS 2025.
PREVIOUS
第 9 期 — Applications: Robotics
NEXT ISSUE
Computer Vision — 3D Rendering & Reconstruction
深入解析计算机视觉领域前沿进展

- END -