


想象一下,你手里有一台超级聪明的AI助手,它能帮你写文章、画图、分析数据,甚至能和你聊人生理想。但你知道吗?每和它对话一次,它背后消耗的电力,够一个普通家庭用一个星期。
这不是夸张。大模型的参数规模从亿级跃升至万亿级,数据中心的耗电量已经占到全社会用电量的近2%——这个数字还在以每年约10%的速度增长。而传统的电子芯片,正面临一个尴尬的处境:它们越来越快、越来越小、越来越省电的“进化”,正在撞上一堵看不见的墙。
这堵墙,叫作摩尔定律。
就在这个临界点,一项被MIT科学家称为“后摩尔时代颠覆性力量”的技术,悄悄走向了台前——光计算(Optical Computing)。它不替换电子计算机,而是用“光”来弥补电子计算机的短板:同样完成一次计算,光比电子更快、更省电且几乎不发热。
市场已经给出了最直观的答案:全球光子AI加速器市场规模在2025年已达到18亿美元,预计2034年将突破146亿美元,年复合增长率达26.1%[1]。光子集成电路市场规模则从2025年的179亿美元增至2034年的976亿美元[2]。
而在这场全球竞赛中,2026年4月,一家来自中国的公司——曦智科技,以“全球AI光算力第一股”登陆港交所,开盘暴涨超380%,市值一度突破800亿港元[3][4]。这是一个信号:光计算不再只是实验室里的科研课题,它已经开始走进现实。
光计算不是对传统电子计算的替代,而是一次算力架构的“升维”。它解决的不是“计算什么”的问题,而是“如何更快、更省地计算”的问题。在AI算力需求爆发与摩尔定律见顶的历史性交汇点上,谁率先突破光计算的商业化瓶颈,谁就能定义下一代算力基础设施的游戏规则。
2.1 传统芯片的“堵车”和“漏电”问题
要理解光计算为什么重要,先要理解我们手里这台传统电子芯片,正在经历什么“中年危机”。
你可以把传统芯片想象成一座超级大城市。这座城市里住着两种“居民”:计算单元(相当于处理器,是城市的“工厂”)和存储单元(相当于内存,是城市的“仓库”)。工厂要开工,需要从仓库里把原材料拉过来,把成品运回去。而负责跑腿运输的,是电子——它们在铜导线这条“公路”上奔跑。
问题来了:随着城市规模越来越大(芯片从微米级进入纳米级),跑腿的代价也越来越大。电子在导线里不仅会被“堵车”困住,还会出现“漏电”——就像水管老化后,即使关了水龙头也在滴水。芯片越做越小,电子“堵车”和“漏电”的问题反而越严重[5]。
这就是摩尔定律面临的困境。摩尔定律说的是:芯片上的晶体管数量,每18个月翻一番,价格还会下降一半。这个定律在过去五十年里一直生效,但现在,它正在被物理极限卡住脖子——不是因为人类不够聪明,而是因为电子在纳米尺度下的行为,实在太“不听话”了。
与此同时,大模型对算力的需求却在以指数级速度膨胀。训练一次千亿参数的大模型,需要消耗近百万度电。数据中心的散热系统比空调还复杂,电费账单让运营商们“睡不着觉”。
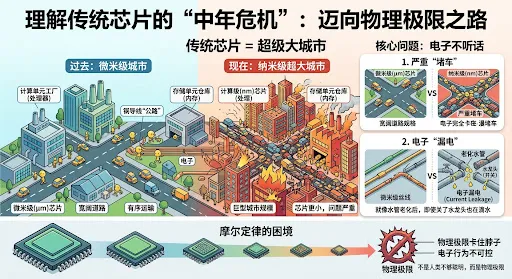
图一:传统芯片“中年危机”
面对这个死局,整个行业都在找新出路。比如华为在最近(2026年5月)提出的“韬(τ)定律”,就是选择在传统电芯片内部继续挖潜——既然晶体管很难再做小了,那就通过3D堆叠等技术把平面电路“折叠”起来,缩短信号传播的物理距离,用“时间缩微”来替代“几何缩微”[18]。
但这只是解法之一,如果直接跳出“电”的框架呢?这正是光计算的解题思路:直接把跑腿的从电子换成光子。
光子是光的最小单位。用光子来“跑腿”有什么好处?
第一,跑得快。 光子在波导(可以理解为光的“高速公路”)中以接近光速传播,比电子在铜导线里快得多。
第二,不怕堵。 不同波长的光可以在同一根波导中“并行”传输,各走各的路,互不干扰——就像一条公路上同时容纳了不同车道的大巴车、私家车、自行车,各自畅通无阻。
第三,几乎不发热。 光子不像电子那样会因为电阻而产生热量,传输同样带宽的数据,光互联比铜线互连可以节省60%至75%的能耗[5]。
打个比方:如果电子芯片是一个用人力搬运货物的仓库,那么光计算就是一个用传送带和无人机来送货的超级物流中心——不仅更快,而且几乎不需要“人力”(能耗)。
2.2 光计算的两条技术路线
看到这里,你可能会问:光计算听起来这么厉害,为什么现在才开始爆发?答案是:光计算内部有两条完全不同的技术路线,它们的成熟度天差地别。
第一条路线:经典光计算(Photonic Computing)——这是目前产业化的主战场。
它的思路简单直接:用光子替代电子,完成AI计算中最耗时的“矩阵乘法”这类任务。说白了,就是用光来“算”那些特别吃算力、又特别有规律的计算。芯片仍然运行经典计算范式,你输入一个确定的问题,它给你一个确定的答案。
曦智科技PACE系列、Lightmatter Envise、Ayar Labs TeraPHY,都属于这条路线[3][9]。这条路线的核心逻辑是:光做“重活”(大规模计算),电做“轻活”(控制、存储、协议),两者各展所长。
第二条路线:光量子计算(Optical Quantum Computing)——这是更具颠覆性但也更遥远的方向。
它的目标不是让光“替代”电子计算,而是直接用光子实现量子计算——利用光子的量子叠加态和纠缠特性,同时探索多种可能性,实现经典计算机根本无法企及的算力。这就好比从“用更快的传送带送货”直接跃升到“同时在多个平行宇宙送货”。
Xanadu的Borealis系统展示了128个光量子比特的计算能力,PsiQuantum拿到了超过7亿美元融资,押注在硅光芯片上集成百万量子比特级的光量子计算机[6][12]。这条路线前景诱人,但商业化时间表仍在十年以后。因此本文主要讨论的是经典光计算。
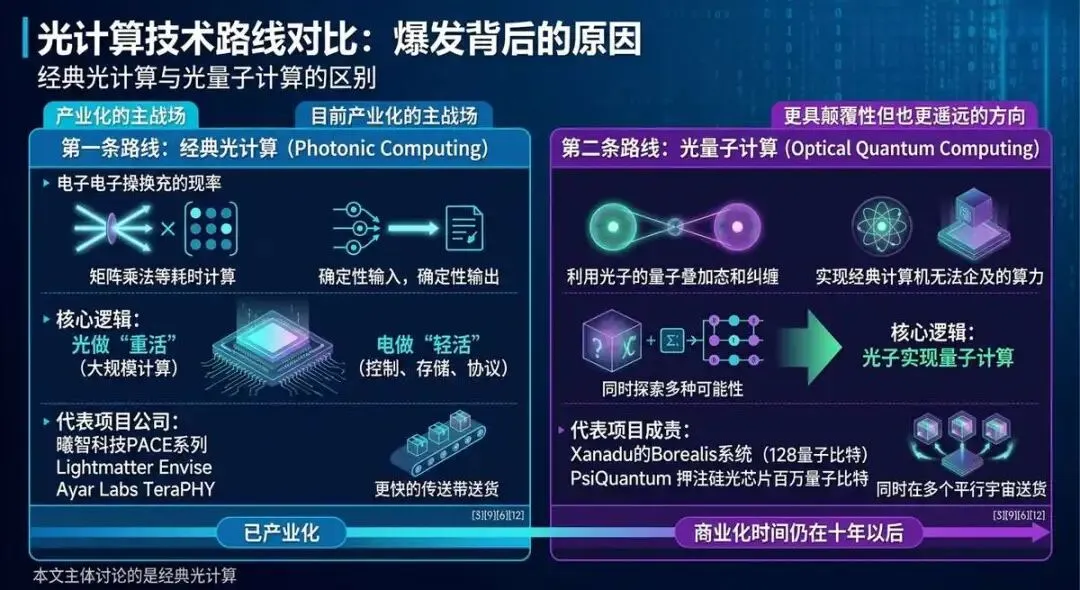
图二:光计算技术路线对比图
2.3 经典光计算四条技术路线,各有性格
经典光计算在具体实现上,有四条主要技术路线——每条都像一个性格鲜明的“人”。
第一条:MZI路线——最成熟稳重的老大哥
MZI(马赫-曾德尔干涉仪)的原理,有点像舞台上的灯光师通过控制两束光的相遇角度,来精确调整舞台的明暗——只不过在这里,“舞台明暗”就对应着“计算结果”。
这条路线是当前最成熟、落地最快的。曦智科技PACE系列和Lightmatter Envise都采用这个架构。它的优点是计算精度高、理论成熟,缺点是当计算规模变大时,需要的干涉仪数量会急剧膨胀,芯片面积不好控制[3][11]。
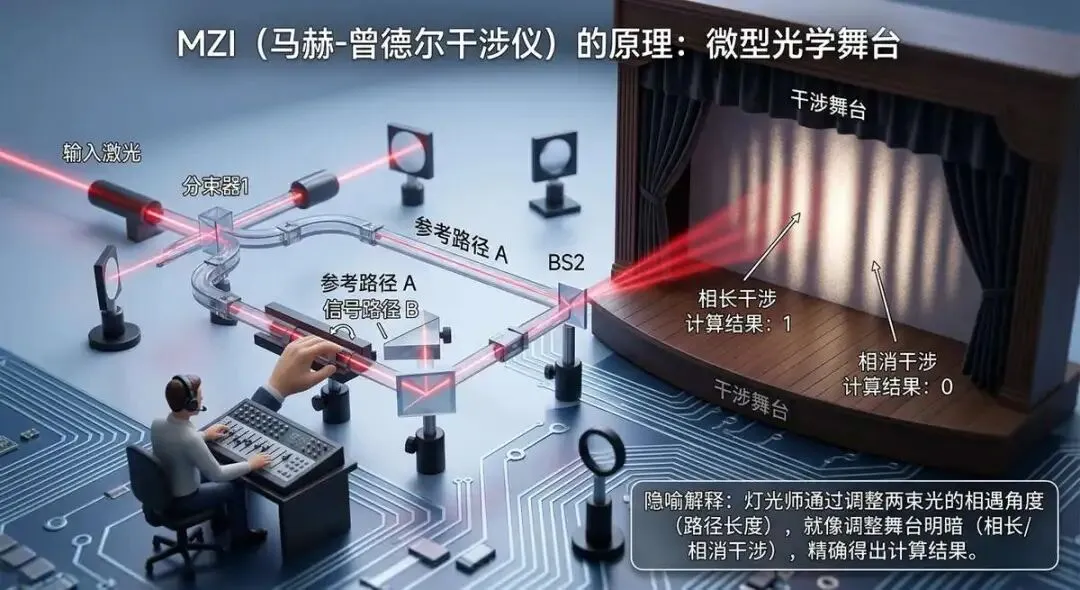
图三:MZI-原理示意图
第二条:微环谐振器(MRR)路线——小巧玲珑的波长魔法师
微环谐振器的工作方式,可以理解为一个精密的分拣系统:不同波长的光进入微小的环形结构后,各自沿着不同的路径走,通过调节“环”的谐振频率,就能精确控制哪束光通过、哪束光被阻挡。
这个路线的优势是器件尺寸小、集成度高。但“波长分拣”的能力是有限的,当规模扩大到一定程度,不同波长之间会互相干扰,性能的一致性就会下降[5]。
第三条:相变材料(PCM)路线——有记忆力的变色龙
相变材料就像一个“变色龙”,在晶态和非晶态之间切换时,对光的吸收率会发生变化。拿它来做芯片,就等于让芯片有了“记忆”——上一次计算的结果会"留"在材料里,直接影响下一次的计算。
这个路线的优势是不需要复杂的光学结构,适合做“存算一体”的芯片。缺点是“变色龙”来回变色次数多了,皮肤会“疲劳”——材料的多次读写寿命问题还没完全解决。
第四条:衍射深度神经网络(D²NN)路线——最硬核的物理派
MIT在这个方向积累最深。它的原理最“硬核”:直接在物理空间中,用光的衍射(一束光穿过有缝隙的障碍物时会扩散开来的现象)堆叠出神经网络层。光穿过多层结构的过程本身,就是一次完整的AI推理——不需要电控制,能效比极高。
但它的缺点也很明显:它是“一次性编程”的——设计好之后就只能做固定任务,不能像MZI路线那样灵活应对各种计算需求。
2.4 为什么是现在:三重历史性交汇
光计算在2023年之后突然加速,这不是偶然,而是三个关键条件在同一时期“同时成熟”的结果。
第一重:摩尔定律见顶,算力需求井喷。
芯片制程进入3nm以下(相当于一根头发丝的万分之一),电子互连的带宽瓶颈和能耗问题从“小麻烦”变成了“大瓶颈”。与此同时,ChatGPT引发的AI浪潮让算力需求在短时间内爆发式增长——传统电芯片已经很难同时满足“更快”和“更省”这两个需求了。
光计算恰好在此时提供了“更高带宽、更低时延、更低能耗”三条关键出路,直接命中了传统电芯片的三大痛点。
第二重:硅光代工生态走向成熟开放。
光计算芯片一直无法量产的瓶颈之一,是“找谁代工”的问题——能做硅光芯片的代工厂全球就那么几家,而且大多不向外部客户开放。
2025年,比利时imec将其最先进的iSiPP300硅光代工工艺授权给台湾联华电子(UMC),同年台积电宣布进军硅光代工领域[7]][8]。这意味着光计算芯片的量产从此不再只有“一座独木桥”,成本将从定制化向批量化大幅下降。
打个比方:之前光计算芯片就像找私人裁缝做衣服,量体裁衣、合身但贵、产能有限;现在代工厂开放了,变成了批量生产的流水线成衣——虽然个性化稍差,但成本大幅下降,普通人也能穿得起了。
第三重:AI数据中心的能耗危机成为硬约束。
中国2024年数据中心用电量约1660亿千瓦时,占全社会用电量的1.68%[5]。在“双碳”目标压力下,能耗降低不再是“锦上添花”,而是选型的硬约束。光互联相比铜线可节省60%至75%的能耗——在政策压力下,这笔账越来越容易算得过来。
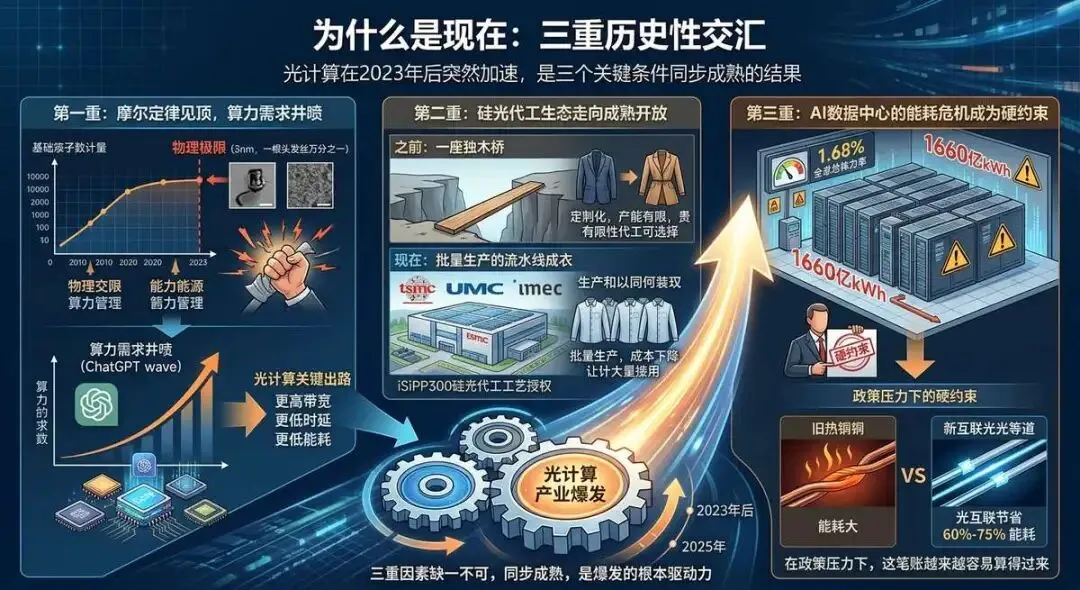
图四:光计算加速发展的三重因素
三重因素缺一不可:没有摩尔定律见顶,光计算就没有替代空间;没有代工生态开放,光计算就没有量产基础;没有能耗危机,光计算就没有市场动力。三者同步成熟,是光计算产业爆发的根本驱动力。
3.1 上游:光子材料与核心器件
硅光芯片——最底层的那块“地基”
整个光计算产业最底层的硬骨头,是硅光芯片的代工能力。
硅光芯片是什么?可以理解为:用做电脑芯片的工艺(CMOS工艺)来制造“光路”——在硅片上刻出比头发丝还细一万倍的光波导,让光在芯片里听话地跑起来。
硅的优势很明显:它和制造传统芯片的工艺完全兼容,可以直接嫁接全球现成的半导体代工体系,门槛最低、产能最稳。但硅有一个天然缺陷——它无法直接发光,就像一条公路没有“入口”,车进不去。
解决这个问题,需要借助Ⅲ-V族材料(比如磷化铟)。全球硅光代工领域,比利时imec是隐形冠军。2025年12月,联华电子获得imec授权,宣布将12英寸硅光工艺向商业代工开放——这意味着光计算芯片的量产从此不再只有imec这一座独木桥[7][8]。
Ⅲ-V族化合物半导体——光源的关键材料如果说硅光芯片是“公路网”,Ⅲ-V族化合物半导体就是公路的“入口匝道”——它负责把“光”送进硅芯片里。
这个领域全球主要被美国、日本、德国三国主导。中国在中高端外延片环节与上述国家仍有差距,是当前产业链中较为薄弱的环节之一,也是国内企业正在重点突破的方向。
薄膜铌酸锂——调制器的高速公路
薄膜铌酸锂是一种特殊的材料,特别适合做高速光调制器——也就是控制光信号“开关”和“变化”的核心器件。它的调制速度可以达到100GHz以上(一秒钟内信号变化超过1000亿次),而且信号损耗极低,是相干光计算和高速光互连的理想平台。
超低损耗波导材料——光的“高速公路”质量决定了芯片规模
波导是光在芯片中传播的通道,可以把它想象成光传输的“公路”。公路的质量(损耗率)直接决定了在芯片上能跑多少个“计算单元”——损耗越低,芯片上能集成的单元就越多,计算规模就越大。
氮化硅波导的损耗可以低至0.01 dB/cm,比硅基波导低两到三个数量级,是实现大规模光计算芯片的核心材料。荷兰LioniX International是全球氮化硅波导加工领域的领导者[5]。
EDA工具——光芯片的“设计软件”
盖房子需要设计软件,光芯片也需要。设计光芯片的设计师需要在计算机上模拟光在波导中怎么传播、怎么干涉、怎么衍射,还要考虑热效应、工艺偏差等实际问题。
目前全球 photonic EDA工具市场被Cadence和Synopsys垄断,两者合计占据超过80%的市场份额。国产 photonic EDA工具在器件库完备性和仿真精度上仍与头部产品存在差距——这是国内产业链中一个"卡脖子"的环节。
3.2 中游:光计算芯片与系统集成
光矩阵乘法芯片——直接用光子做计算的“大脑”
光矩阵乘法芯片是光计算产业的核心产品。它的工作方式可以这样理解:把一个数学矩阵(可以理解为一张布满数字的大表)“翻译”成光路中光的强弱分布,光穿过特殊设计的光学结构后,结果就直接出来了——不需要电子参与计算过程本身。
曦智科技PACE系列是这一赛道的代表产品。64×64矩阵运算(相当于计算一张64×64的数字表格的乘法)时间缩短至约3纳秒——比眨一次眼(0.1秒)快了三千万倍,而能耗比传统电芯片降低了一个数量级以上[3]。
光I/O互连芯片——解决数据传输的“堵车”问题
光I/O互连芯片解决的不是“怎么算”,而是“怎么传”——也就是GPU与GPU之间、服务器与服务器之间海量数据的高速传输问题。
在大规模AI训练集群中,通信带宽和时延往往比单卡算力更为关键——就像一个超级工程团队,如果成员之间传递信息的路太窄、速度太慢,那么每个人再强也没用。
Ayar Labs是这个赛道的领头羊,其TeraPHY光学I/O芯片已获英伟达、AMD批量采纳,单芯片带宽超过8 Tbps(相当于一秒钟传输4张蓝光电影的容量),误码率低至10⁻¹⁵以下——传输一万亿个数据比特,出错不超过一个[9]。
光电共封装(CPO)——把“光路”"和“电路”装进同一个盒子里
光电共封装是一种新型的封装技术,它把光引擎和计算芯片直接封装在同一块基板上——相当于把原本分散在不同建筑里的“物流中心”和“工厂”合并到同一栋楼里。
这样一来,电信号传输距离从厘米级压缩到毫米级,功耗骤降,信号完整性大幅提升。Intel已推出商用CPO交换机产品,中际旭创2024年量产了51.2T CPO交换机,功耗比传统方案降低40%[10]。据LightCounting统计,2022至2025年间,AI服务器中CPO方案渗透率增长了41%[2]。
3.3 下游:三大应用场景
AI推理加速——当前最直接的商业化场景
AI推理是光计算当前最成熟、落地最快的应用场景。可以这样理解:AI推理就像考试时做“选择题”——模型根据输入的问题,从已有的知识中找出最匹配的答案。这个过程,本质上是一次或多次大规模矩阵乘法。而矩阵乘法,恰好是光计算最擅长的任务。
曦智PACE系列已部署到千卡GPU集群,将模型浮点运算利用率(MFU)平均提升超50%[3]——相当于在不更换“体力”的情况下,把“大脑”的效率提升了50%以上。
AI训练加速——更大的市场,更远的路
AI训练比AI推理的算力需求更大,但商业化路径也更长。好比如果要建一座大楼,打地基(训练)比装修(推理)需要更多的资源和时间。
光I/O互连在AI训练场景中率先落地——它替代的是GPU集群中的高速互连,把“公路”拓宽,而不是替代“工厂”本身。Ayar Labs TeraPHY芯片已进入英伟达和AMD的AI训练生态[9]。
数据中心光互联——正在发生的基础设施升级
全球数据中心光模块市场在2024年已达到数十亿美元规模,其中400G/800G光模块成为主流,1.6T光模块开始出货。中际旭创在800G和1.6T光模块市场上占据全球前三的位置[10]。
打个比方:数据中心的光互联升级,就像城市从"普通公路"升级到"高速公路网"——每辆车(数据)跑得更快,整座城市的物流效率大幅提升。
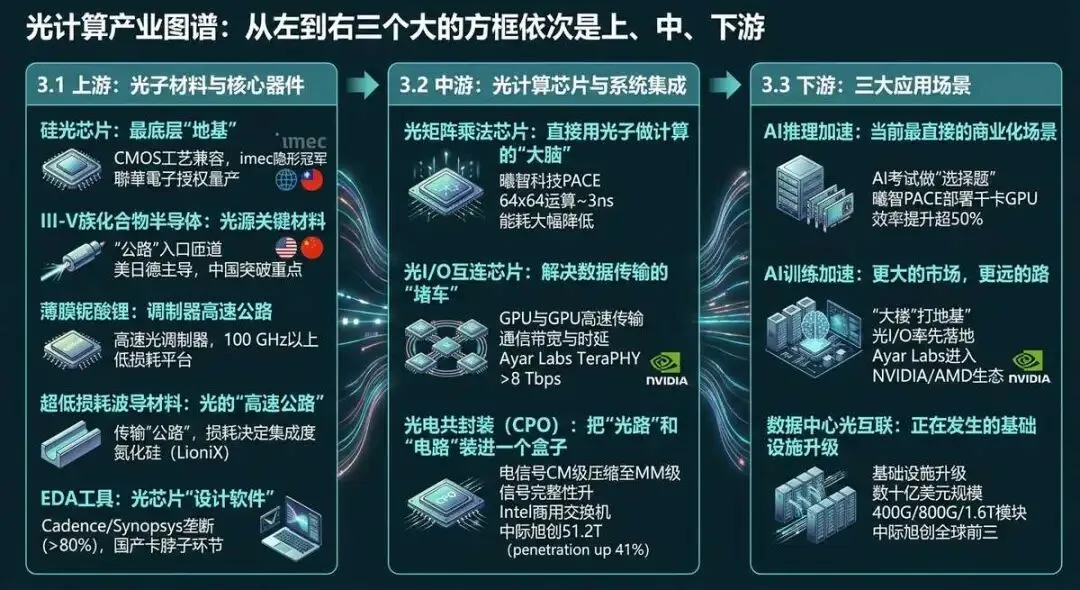
图五:产业链解析
4.1 美国:规则制定者,资本驱动
美国在光计算领域的优势,根本上源于其“实验室到资本”之间极短的转化链条。MIT、斯坦福等顶尖高校孵化出最前沿的光计算理论,风险资本在科研成果尚处于原理验证阶段时就已入局,创业公司在学术论文发表后的两三年内就能推出商业产品。
MIT是这场游戏的最重要源头。Lightmatter和Ayar Labs这两家目前全球最炙手可热的光计算独角兽,均从MIT孵化而出。Lightmatter由MIT光子计算实验室主任David Miller和首席科学家Nicholas Harris于2017年创立,其Envise平台是全球第一个商业化的光矩阵乘法AI加速芯片,2025年该公司将其光子处理器研究发表在《自然》期刊上[11]。Ayar Labs则走了另一条更为务实的路线:不做计算,只做互连。TeraPHY光学I/O芯片已摆进英伟达和AMD的供应链,单芯片带宽超过8 Tbps,误码率低至10⁻¹⁵量级[9]。
Intel是整个产业中容易被低估的力量。这家芯片巨头拥有全球最早的硅光量产平台,早在2020年就实现了硅光芯片的商用出货,积累的工艺经验是初创公司短时间内无法追赶的。
PsiQuantum拿到了超过7亿美元融资,押注的是在硅光芯片上集成百万量子比特级的光量子计算机[12]。Xanadu的Borealis系统在2022年展示了128个光量子比特的计算能力[6]。
4.2 欧洲:工坊精神,底层支撑
比利时imec是全球硅光代工领域最重要的存在。iSiPP300平台是全球最先进的硅光工艺平台之一,聚集了全球数百家光计算企业的研发流片需求。imec之所以能成为全球光计算产业的"基础设施",根本原因在于它是非营利研究机构,没有自己的产品要与客户竞争。2025年12月,imec将iSiPP300工艺授权给台湾联华电子,意味着12英寸硅光代工从此有了商业化开放的产能[7][8]。
荷兰LioniX International是全球氮化硅波导加工领域的隐形冠军,其TriPleX平台提供的超低损耗氮化硅波导,是实现大规模光计算芯片的核心材料基础。德国Fraunhofer研究机构在精密光学制造领域积累深厚,蔡司、肖特等百年光学企业的存在,为德国光计算产业提供了从材料到器件的完整供应链。英国Optalysys在2026年初获得了2300万英镑融资,走的是相变材料路线[13]。
欧洲的整体优势在于“底层平台能力”而非“终端产品”,短板在于缺乏类似美国那样的创业生态和风险投资文化。
4.3 日本:光通信王者,横向延伸
日本在光计算领域的优势并非凭空而来,而是从光通信的深厚积累中自然延伸而来。日本拥有全球最完整的光通信产业链,当光计算用光子替代电子进行计算和互连时,这些原本服务于光通信的技术和能力,有相当部分可以直接迁移过来。
NTT(日本电信电话)是日本光计算产业的核心推动者。2025年11月,NTT与加拿大公司OptQC签署合作协议,共同探索将光通信技术应用于百万量子比特规模的光量子计算机,目标是在2030年前实现[14]。
日本光学百年积累为光计算提供了另一个独特优势——精密光学元件。日本企业在光学镜头、光学玻璃、光学晶体(如铌酸锂晶体)领域拥有全球领先的技术和产能。
日本模式的局限同样明显:缺乏类似Lightmatter这样从实验室直接走出来的光计算创业公司,创新的活力和速度不如美国。
4.4 韩国:政府强力推动的国家意志
韩国在光计算领域的布局,展现了一种与中国颇为相似的"政府强力推动"模式——国家战略先行,政策资源导入,企业跟进落地。
韩国政府的态度非常明确:将光子技术列为国家战略技术,在“韩国数字战略”和“国家超级差距项目”中给予重点支持。2024年,韩国产业通商资源部将硅光和光计算列为下一代半导体重点方向,计划在未来五年内投入超过5亿美元支持研发和产业化。
Samsung Electronics是韩国光计算产业的核心参与者。三星在半导体制造领域拥有全球领先的工艺能力,这种制造能力一旦迁移到硅光芯片代工领域,将是巨大的竞争优势。韩华集团旗下的韩华光技术是韩国专业光器件企业,在光模块和光学元件领域有多年积累,正在向硅光领域延伸。
4.5 中国:全球竞争中最具爆发力的选手
中国的光计算产业,是全球格局中最值得关注的变量。它不像美国那样有MIT、斯坦福这样的学术源头,也没有欧洲那样成熟的代工生态,更没有日本几十年光通信积累的家底——但它有一个独一无二的优势:全球最大、增长最快的AI应用市场和最完整的电子制造业产业链。
中国光计算产业最独特的气质是“两条腿走路”:一头是华为这样在光通信领域有几十年积累的硬件老兵;另一头是曦智科技这样从美国学成归国、直接对标全球最前沿的海归创业公司。
曦智科技是中国光计算产业的标杆企业,2026年4月28日以“全球AI光算力第一股”登陆港交所,香港公开发售获得5784.7倍认购,开盘暴涨超380%,市值一度突破800亿港元[3][4]。曦智PACE系列芯片已量产并部署到千卡GPU集群,64×64矩阵运算MFU提升超过50%,已拥有44家客户。
华为在光计算领域的布局是“润物细无声”式的。华为海思光产品线有超过二十年的光通信研发积累,800G/1.6T光模块已在全球运营商市场大规模出货——这些能力迁移到硅光芯片和光计算领域几乎没有技术壁垒。
鲲游光电、光特科技等产业链配角,则撑起了光计算产业的细分赛道——一个做微纳光学器件,一个做硅光子芯片代工,它们不在聚光灯下,但如果没有它们,产业链就不完整。
在“十五五”规划中,多项政策明确支持光计算芯片和硅光技术作为未来产业的核心方向,推动算力技术的"换道突破"。
在地方层面,广东、上海、北京、重庆、湖北等省市相继出台专项政策。广东省的《加快推动光芯片产业创新发展行动方案(2024—2030年)》最为系统,提出打造千亿级光芯片产业集群,全力支持光计算、光神经网络等前沿技术研发[5]。北京市在《北京市算力基础设施建设实施方案(2024—2027年)》中明确鼓励企业探索采用光计算等新技术开展智算中心建设[15]。重庆市在《未来产业培育行动计划》中聚焦硅基光电子技术,推动光子技术发展。湖北省2025年政府工作报告将超高速混合光子集成芯片列为攻关突破方向。
六、区域案例:六大省市的差异化竞合
6.1 上海:光计算产业化高地
上海是中国光计算产业生态最完整的城市,已形成从芯片设计到封装测试到系统应用的完整链条。
曦智科技是理解上海光计算地位无法绕开的核心标的。2026年4月28日登陆港交所(01879.HK),开盘暴涨380%,市值一度突破800亿港元。核心技术基于三大自研芯片体系:片上光网络(oNOC)、片间光网络(oNET)、光子矩阵计算(oMAC),直接破解“内存墙”和“功耗墙”两大行业瓶颈。2025年3月发布的PACE 2(曦智天枢)集成超40000个光子器件,支持128×128矩阵,光矩阵规模是上一代的4倍,相关成果于2025年4月在《自然》发表[3]。
截至2025年12月31日,曦智科技已实现44家客户的商业部署,服务多个千卡GPU集群,将模型浮点运算利用率(MFU)平均提升超50%[3]。在中国Scale-up光互连市场以7920万元收入占据88.3%的份额,排名第一。团队174名研发人员(占员工总数67.2%),持有150项已授权专利(约80%为发明专利),持有260项发明专利正在申请[3]。
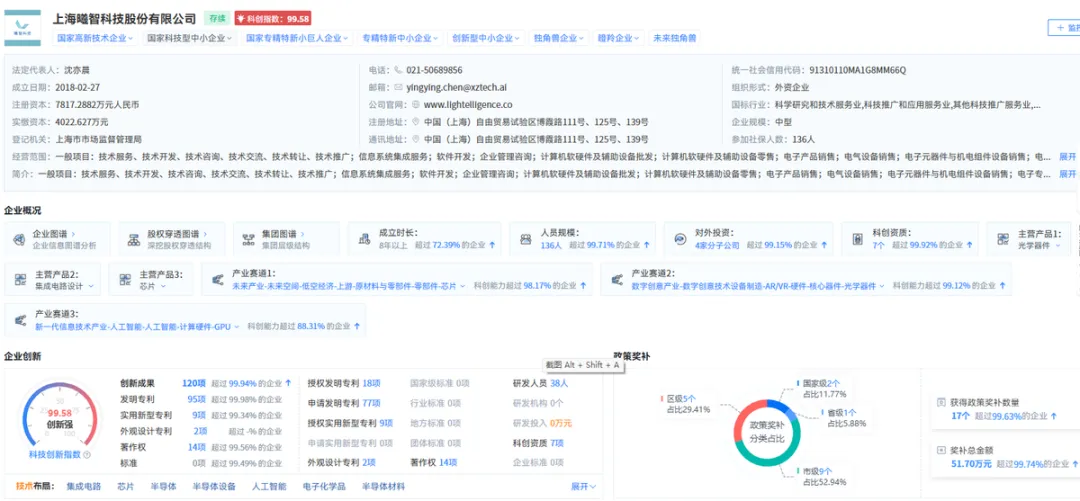
图六:博博查-企业画像-曦智科技
上海国投则围绕光计算全产业链战略布局,已投资集益威(芯片互联IP)、芯耀辉(芯片接口IP)、沐曦(GPU芯片)、盛合晶微(先进封装)等上下游企业,与曦智科技在芯片、封装和系统层面形成深度协同[3]。同时推动光计算与AI大模型结合——已投资MiniMax、阶跃星辰、无问芯穹等大模型企业,推动它们与曦智科技的技术对接。
鲲游光电专注微纳光学器件,已进入数据中心光互联供应链。上海微系统所(中国科学院上海微系统与信息技术研究所)拥有薄膜铌酸锂等前沿材料平台,在光电融合芯片设计方面积累深厚。
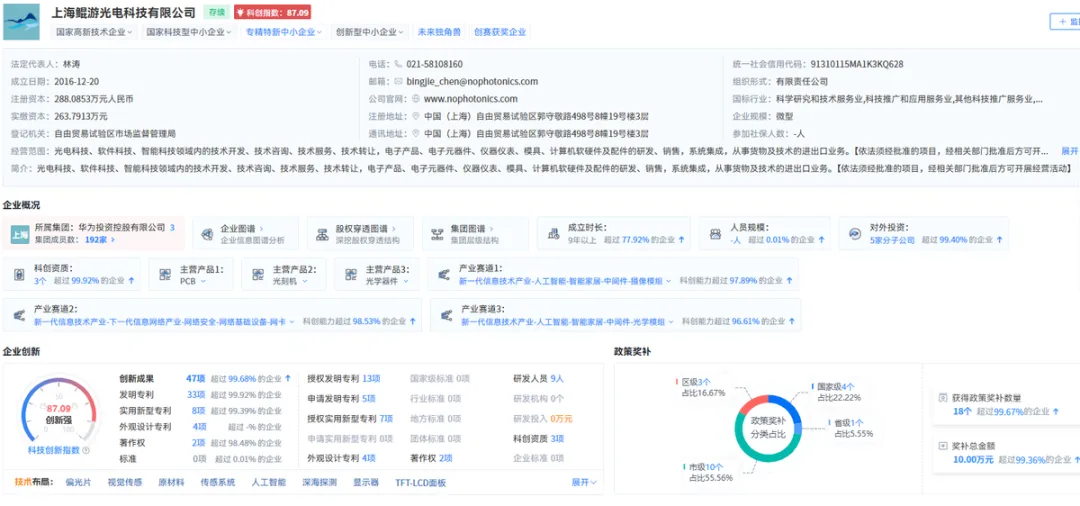
图七:博博查-企业画像-鲲游光电
6.2 北京:科研最强的国家队底座
北京是中国光计算基础研究的核心枢纽,以国家科研院所和顶尖高校为技术源头,形成全国最强的光电子研发梯队。
中科院半导体研究所1956年成立,是国家级半导体科学技术综合研究机构,运营国家光电子工艺中心和光电子器件国家工程研究中心两大国家级平台,拥有光电子材料与器件全国重点实验室和半导体芯片物理与技术全国重点实验室。2024年李明、祁楠研究团队研制出我国首款光电融合单片集成互连芯片,通过创新光电协同设计,共衬底集成硅光器件与CMOS电路,突破微环谐振器等关键器件技术[15]。
中国信息通信研究院(工信部直属)是最重要的算力网络标准化机构,2024年12月发布《算力互联互通标准体系1.0》,为全国算力互联网发展提供指导框架[16]。
6.3 广东:超万卡集群先行者
广东是中国光计算产业化的重要基地,以鹏城实验室的超算实践和华为的全面布局为核心。
深圳的鹏城实验室运营着鹏城云脑Ⅱ,算力规模达1000P,问鼎全球IO500存储性能榜单十连冠。鹏城云脑Ⅲ建成后更将达到16000P,是前代的16倍,支撑万亿参数大模型完整训练需求[16]。在这样的超大规模集群里,光互联带来的带宽提升和能耗降低会被成倍放大——一个百分点的效率提升,在16000P规模下就是数百千瓦的功耗节省。
华为将集团总部放在深圳,使其成为广东光计算产业的另一极。这家公司在光通信领域有全球最深厚的积累,光模块、CPO、硅光芯片均有自主研发布局。无论GPU来自英伟达还是国产芯片,都需要华为的光模块来完成节点间的数据传输。这种"基础设施"属性,让华为成为广东乃至全国光计算版图中最不可或缺的存在。
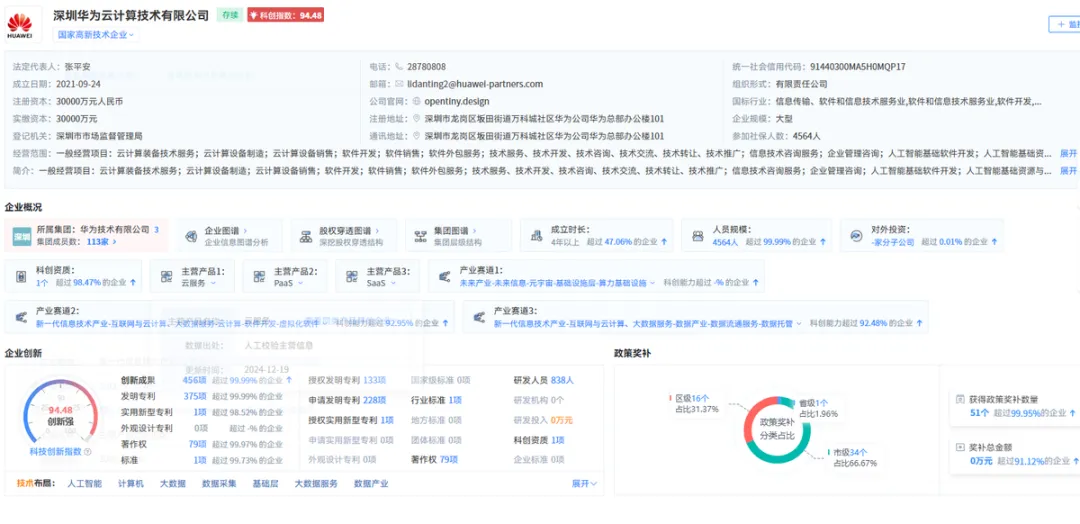
图八:博博查-企业画像-华为云
6.4 江苏:最扎实的制造底座
江苏的光计算产业不像上海那样有明星公司,也不像广东那样有超大集群,它的特点是“细粒度极高”——在光电子制造的每一个细分环节,都有一到两家全国领先的企业。
苏州“高光之城”战略的精髓在于围绕光子本身建立了覆盖材料、芯片、器件、系统的完整制造链条。长光华芯的高功率激光器芯片技术全国领先,天孚通信的1.6T光引擎已实现量产,光特科技则承接了国内大多数光计算企业的流片需求。
星钥光子(长光华芯+亨通光电+东辉光学联合)正在建设全国首条8英寸90nm制程硅光产线,这意味着江苏有望成为国内第一个拥有完整硅光量产能力的省份,不必再依赖imec或台积电的代工服务[17]。
太湖光子产业投资基金2022年由苏州高新区管委会发起设立,总规模100亿元,重点围绕光子产业进行投资布局,已孵化10多家上下游企业[17]。
6.5 浙江:最活跃的系统集成与阿里生态
浙江的光计算产业与阿里巴巴深度绑定,这带来了一个独特优势:这里是光计算与AI大模型系统集成最紧密的地方。
达摩院的光计算研究不是做器件,而是做系统——它关注的是光计算芯片放进阿里云服务器集群后,如何与现有网络协议、调度系统、散热架构协同工作。2025年,达摩院联合燧原科技推出的xPU-CPO原型系统,实现了功耗降低3.5倍的目标;与壁仁科技、中兴通讯合作推出的光跃LightSphere X分布式光路交换解决方案,获得了当年世界人工智能大会的最高奖项SAIL奖[3]。
之江实验室由中国工程院院士王坚领导,在硅光和光子集成方向有政府专项支持,与阿里系形成技术-产业的双向协同。
6.6 陕西:超快光学与光子学的重镇
陕西西安拥有全国乃至全球在超快光学与光子学领域最具影响力的科研机构,为中国光计算产业的前沿探索提供了不可替代的底层技术支撑。
中科院西安光学精密机械研究所(西安光机所)是超快光学与光子学领域权威机构,超快光科学与技术全国重点实验室所在地。该所长期从事高速光电器件和光子集成技术研究,2025年研制出单端口速率2Tbps的硅基微环调制光IO芯片,岸线带宽密度达4Tbps/mm,是当前OIO光互连单纤速率的全球最高报道,融合高性能微环调制器、高增益雪崩光电探测器与光电协同设计,代表了国内集成光子频率梳和超高速光互连芯片的最高水平[16]。
光计算产业正处于从“技术验证”到“规模商业化”的关键转折期。未来五年,产业发展将围绕五条主线展开。
主线一:AI推理加速率先完成商业闭环。 曦智科技PACE系列已证明光计算在AI推理场景中的商业可行性:64×64矩阵运算MFU提升超过50%,3纳秒级响应速度,已部署到真实GPU集群[3]。预计2026至2028年,随着PACE 3等面向大语言模型推理的产品量产,光计算在AI推理市场的渗透率将从目前不足0.5%开始显著抬升。
主线二:光电共封装进入数据中心规模部署。 CPO的核心价值在于“距离压缩”:将光引擎和计算芯片封装在同一基板上,将电信号传输距离从厘米级压缩到毫米级,功耗骤降。据LightCounting统计,2022至2025年间,AI服务器中CPO方案渗透率已增长41%[2]。预计2027年前后,主流云厂商将在新建AI集群中全面引入CPO。
主线三:硅光代工生态走向开放化与规模化。 2025年是一个转折点:比利时imec将iSiPP300工艺授权给台湾联华电子,意味着12英寸硅光代工从此有了商业化开放的产能[7][8]。预计2026至2028年,台积电将正式推出硅光代工服务,全球光计算芯片的量产成本有望在现有基础上下降30%至50%。
主线四:AI训练集群的光互联替代。 当GPU集群规模从千卡扩展到万卡甚至更大时,节点间参数同步的通信量呈指数级增长,传统铜线互连的带宽瓶颈成为系统性能的主要制约因素。Ayar Labs的TeraPHY芯片瞄准的正是这一痛点,用光互联替代InfiniBand,以光信号实现GPU域的横向扩展[9]。
主线五:量子光学计算探索“混合架构”长期路线。 NTT与OptQC在2025年11月签署合作协议,探索将光通信技术应用于百万量子比特规模的量子计算机,目标2030年实现[14]。这种“以光驭量子”的思路,可能是光量子计算商业化路径最短的方向。
光计算之所以被寄予厚望,根本原因在于它解决的不是某一个单点问题,而是整个算力体系的架构性瓶颈——当摩尔定律放缓,当大模型对算力的需求没有上限,当数据中心的能耗账单变成不可承受之重,光计算提供了三条根本性的解决路径。
带宽维度的突破:光信号的带宽容量是铜线的10至100倍,光是唯一能够支撑未来百T级带宽需求的技术路径[9]。
能耗维度的突破:光互联相比铜线可节省60%至75%的能耗[2],在“双碳”战略背景下将成为数据中心选型的关键考量。
时延维度的突破:光在波导中的传播速度接近光速,纳秒级响应相比微秒级的电计算响应,意味着在高频交易、实时AI推理、工业控制等场景中,体验的代际差距[3]。
光计算的产业化仍处于早期阶段:光计算芯片在AI推理市场的渗透率在2025年仍不足0.5%[3],预计到2030年才有望达到5%以上。硅光代工生态的开放刚刚起步,高端薄膜铌酸锂等关键材料仍依赖进口,photonic EDA工具链的成熟度距离电芯片EDA还有相当距离。
展望未来,中国在光计算领域的最大优势是全球最大的AI应用市场、全产业链协同能力和系统性政策支持。曦智科技已证明中国团队不仅能做光计算科研,更能将其商业化并部署到真实的生产环境中。在国家政策的大力支持下,在AI算力需求的强劲拉动下,中国光计算产业正迎来从“技术验证”到“规模商业化”的拐点。
正如中国移动在2025年《面向新型智算的光计算技术白皮书》中所言:“光计算的发展成熟需要产学研用各方凝心聚力,助力我国实现算力技术的‘换道突破’和产业的‘弯道超车’”[5]。
后摩尔时代,光计算的故事才刚刚开始。
[1] Dataintelo. Photonic AI Accelerator Market Research Report 2034. https://dataintelo.com/report/photonic-ai-accelerator-market, 2025.
[2] LightCounting. Co-Packaged Optics Market Report 2025. https://www.lightcounting.com/, 2025.
[3] 36氪欧洲. 全球最大光计算芯片独角兽拟IPO,腾讯百度参投. https://36kr.com/p/3746188060738305, March 2026.
[4] 36氪. 曦智科技登陆港交所:全球AI光算力第一股开盘暴涨380%. https://36kr.com/p/3746188060738305, April 2026.
[5] 中国移动. 面向新型智算的光计算技术白皮书(2025年). https://www.fxbaogao.com/detail/5125011, 2025.
[6] Xanadu. Borealis: A programmable photonic quantum processor. https://www.xanadu.ai/products/borealis, 2022.
[7] imec. UMC Licenses imec's iSiPP300 Technology for Silicon Photonics. https://www.imec-int.com/en/press/umc-licenses-imecs-isipp300-technology-extend-silicon-photonics-capabilities-next-generation, December 2025.
[8] imec. Imec in 2025: an overview. https://www.imec-int.com/en/articles/imec-2025-overview, 2025.
[9] Ayar Labs. Optical Connectivity for AI Compute Fabrics. https://ayarlabs.com/blog/optical-connectivity-for-ai-compute-fabrics/, 2025.
[10] 中际旭创. Eoptolink Demos Its NX200 and NX300 Series OCS Solution at OFC 2026. https://www.eoptolink.com/news/13-new-products/367-eoptolink-demos, 2026.
[11] Lightmatter. Photonic AI Acceleration — A New Kind of Computer. https://lightmatter.co/blog/a-new-kind-of-computer/, 2025.
[12] PsiQuantum. Quantum Computing at Scale — The Path to 1 Million Qubits. https://www.psiquantum.com/, 2024-2025.
[13] Optalysys. Optalysys secures £23m funding to advance photonic computing. https://optalysys.com/resource/optalysys-secures-23m-funding-to-advance-photonic-computing/, January 2026.
[14] NTT. NTT and OptQC Sign Collaboration Agreement for Optical Quantum Computing. https://group.ntt/en/newsrelease/2025/11/18/251118a.html, November 2025.
[15] 北京市人民政府. 北京市算力基础设施建设实施方案(2024—2027年). https://www.beijing.gov.cn/zhengce/, 2024.
[16] 高文院士. 中国算力网的全球视野与自主之路——2025算力网发展大会. https://hub.baai.ac.cn/view/50366, 2025年11月.
[17] 苏州国家高新技术产业开发区. 苏州太湖光子中心:打造中国光子产业新高地.https://news.qq.com/rain/a/20240515A08LM000, 2024年5月.
[18] EETOP. 华为"韬(τ)定律"论文全文!. https://www.eetop.cn/semi/6965611.html, 2026年5月.
本文由博博查·科创大脑·AI智能体生成
编辑:张亦弛
编审:宋毅怡


博博查科创大数据平台网址:
https://bocha.boshiyun.com.cn
或扫描下方微信小程序?
账号试用请联系:宋女士
18805065725(微信同号)

