


APPLICATIONS系列连载 第 6 期
Language, Speech and Dialog
Applications - Language, Speech and Dialog
Language, Speech and Dialog
ABSTRACT
近年来,语言、语音与对话领域的研究聚焦于提升大型语言模型(LLM)的推理能力与扩展多模态交互的智能边界。在推理与自我改进方面,Yue et al., 2025[1] 探讨了强化学习是否真正激励LLM超越基线的推理能力, 而 Xu et al., 2025[2]通过强化自博弈引导搜索与推理的协同,Mendes et al., 2025[3] 则展示了语言模型可通过自我改进状态值估计来增强搜索性能。在语音与对话系统方面,Ghosh et al., 2025[4] 提出了完全开放的大型音频语言模型 Audio Flamingo 3,Yu et al., 2025[5] 实现了无需编码器注入的全双工语音LLM SALMONN-omni,Wang et al., 2025[6] 实现了零样本文本到语音合成中的词级情感控制,Ju et al., 2025[7] 生成了高质量零样本播客, 而Zhang et al., 2025[8] 通过全非自回归流匹配推进了零样本对话生成。此外,Rodionov et al., 2025[9] 提出了并行LLM生成的高效并发注意力机制,Li et al., 2025[10] 则提出了改进的缩放定律 Farseer。这些工作共同推动了语言、语音与对话系统在推理增强、多模态交互与生成效率上的前沿进展。
01
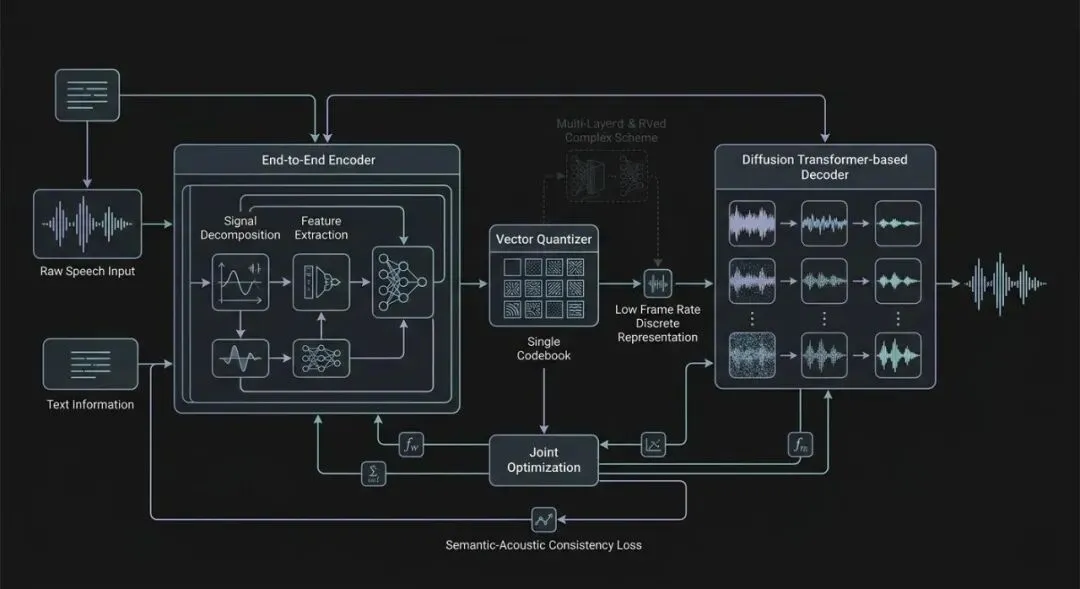
语音分词器的低帧率单层编码与语义-声学统一建模
当前语音语言模型的底层基础——语音分词器——正经历从多层级高比特率设计向极低帧率单层语义编码的范式转变。传统方案如EnCodec、SoundStream依赖多层残差向量量化(RVQ)与高帧率(>50 tokens/s)来保证信号重建质量,但这种结构使得语言模型在长序列建模时面临严重的计算与效率瓶颈。近期研究试图通过蒸馏自监督学习(SSL)模型的语义特征来获得低帧率单层表示,例如CosyVoice、SeedTTS等采用两阶段流水线:先量化SSL特征,再训练扩散模型解码重建。然而这种解耦设计引入额外依赖和训练复杂性,且在极端压缩(<20 tokens/s)下重建质量显著下降。TaDiCodec提出了一种端到端的文本感知扩散Transformer语音编解码器,以单一码本实现6.25Hz的超低帧率和0.0875 kbps的比特率,同时保持优秀的词错误率(WER)、说话人相似度(SIM)和语音质量(UTMOS)。该方案无需外部SSL模型,通过扩散自编码器联合优化量化与重建,并利用文本引导提升语义对齐。对比分析表明,这种单阶段、端到端的设计不仅简化了训练流程,还缩小了重建与生成之间的差距,为语言模型提供更紧凑且语义丰富的离散表示。此外,Yu et al., 2025[5] 的工作展示了独立语音LLM在不依赖外部编解码器注入的情况下实现全双工对话,进一步印证了轻量级分词器对于端到端语音交互的重要性。值得注意的是,低帧率分词器的成功也推动了对话生成任务的进步,Zhang et al., 2025[8] 利用非自回归流匹配实现了零样本对话生成,其中分词器的效率直接影响了生成速度与质量。总体而言,语音分词器正在从“信号压缩”向“语言建模友好”转型,未来的关键挑战在于如何在极低比特率下同时保持声学细节与语义丰富性,并进一步消除对辅助模型的依赖。
02
全双工对话系统的架构演进:从级联模块到独立语音语言模型
语音交互系统正从传统的半双工(轮换式)模式向全双工(同时听与说)模式快速演进,架构设计也随之发生根本性变化。早期全双工系统如dGSLM和Moshi采用独立模型实现流式处理,但仍需外部模块管理语音活动检测(VAD)和对话控制,导致系统复杂度高且存在错误传播。另一类方案如VITA和Freeze-Omni采用“模型即服务器”范式,将语音编码器和合成器与LLM级联,但上下文整合能力有限。 最新突破来自Yu et al., 2025[5]的SALMONN-omni,它首次提出无需编解码器注入的独立语音LLM架构,能够在一个模型中同时处理语音输入和生成,支持轮换、回响、上下文相关的打断(barge-in)等全双工对话特性。该工作通过强化学习进一步优化对话策略,在自然交互中表现出更低的延迟和更高的连贯性。与级联方法相比,独立架构避免了外部模块的冗余和误差累积,使得模型能够以端到端方式学习对话的动态节奏。此外,Ju et al., 2025[7] 在零样本播客生成中展示了高质量的长篇对话合成,其背后的语音语言模型同样需要全双工能力来模拟真实对话中的重叠和打断现象。另一重要趋势是将强化学习应用于对话策略优化,Chopra et al., 2025[11] 提出的反馈感知蒙特卡洛树搜索在目标导向信息获取任务中表现出色,其框架可推广至语音对话系统中的主动询问与确认。可以预见,全双工能力将成为下一代语音LLM的标配,而独立架构因其简洁性与可扩展性正逐渐成为主流,但如何在有限计算资源下维持低延迟和高保真度仍是实际部署中的关键课题。
03
长语音处理与实时交互中的效率与建模挑战
随着语音语言模型的应用场景从短句命令扩展到长篇幅对话、播客和演讲,处理长语音序列的效率问题日益凸显。传统Transformer模型在语音序列上的二次复杂度使得长输入成为瓶颈。FastLongSpeech专门针对大语音语言模型提出加速长语音处理的方案,通过优化编码器结构和注意力机制来降低计算开销。与文本语言模型不同,语音序列的帧率通常远高于文本(即使经过分词器压缩),因此序列长度仍可能达到数千甚至上万。当前主流方法包括采用流式编码、窗式注意力或分层压缩。例如,Yu et al., 2025[5] SALMONN-omni 在实现全双工对话时必须同时处理用户输入和系统输出,对实时性要求极高,其独立架构避免了外部模块的串行延迟。另一方面,Zhang et al., 2025[8] 提出的CoVoMix2使用全非自回归流匹配,显著提升了对话生成的速度,但其对长序列的处理能力仍需评估。在播客生成中,Ju et al., 2025[7] 的MoonCast展示了高质量零样本长对话合成,其中涉及多说话人管理和内容连贯性,长语音的建模质量直接影响最终效果。此外,Shi et al., 2025[12] 提出的KORGym为LLM推理评估提供了动态游戏平台,虽然面向文本,但其对长上下文推理的测试方法可启发语音领域的评估设计。值得注意的是,语音语言模型在处理长语音时还面临“遗忘”问题——模型难以在长序列中维持主题一致性。部分工作尝试将语音分割成语义段落并引入记忆机制,但尚无统一解决方案。未来研究需要平衡压缩率、实时性与建模能力,尤其需要发展适用于语音的稀疏注意力或状态空间模型,以突破长语音处理的效率瓶颈。
04
强化学习与人类反馈在语音生成与对话策略优化中的应用
强化学习(RL)在语音领域的应用正在从传统的ASR词错误率最小化扩展到对话策略优化、情感表达控制和生成质量对齐等更高层次的任务。早期RL主要用于优化任务导向型口语对话系统,通过对话模拟学习最优策略。近期,RL被用于提升语音语言模型的全双工交互能力——Yu et al., 2025[5] SALMONN-omni 利用RL优化回响、打断等对话行为,使模型能更自然地适应人类交互节奏。在语音生成方面,Wang et al., 2025[6] 提出了词级别情感表达控制的零样本TTS方法,其中情感强度调节可视为一种连续动作空间,RL有助于在保持语音自然度的同时精准控制情感。类似地,SpeechAlign等工作使用人类偏好反馈来优化语音生成,类似于RLHF在文本LLM中的成功应用。然而,语音领域的RL训练面临独特挑战:奖励函数的设计往往依赖多个客观指标(如WER、MOS、说话人相似度)或主观评价,而这些指标之间存在权衡。Shi et al., 2025[13] 提出的ARECHO框架通过自回归链式假设优化实现了多指标联合评估,为RL提供了更可靠的奖励信号。此外,Kang et al., 2025[14] 展示了将LLM智能体蒸馏为小模型的技术,这一思路可迁移至语音领域——使用RL训练的大模型作为教师,蒸馏出轻量级实时对话模型。在更广泛的推理优化中,Zhao et al., 2025[15] 提出的Absolute Zero方法证明即使在没有外部数据的情况下,通过自博弈RL也能提升推理能力,这对语音对话策略学习具有启发意义。综合来看,RL正成为语音生成与对话系统中不可或缺的一环,但如何设计多目标奖励、减少样本复杂度以及避免奖励黑客行为,仍是该方向有待突破的核心问题。
REFERENCES
[1] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?. NeurIPS 2025.
[2] AceSearcher: Bootstrapping Reasoning and Search for LLMs via Reinforced Self-Play. NeurIPS 2025.
[3] Language Models can Self-Improve at State-Value Estimation for Better Search. NeurIPS 2025.
[4] Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models. NeurIPS 2025.
[5] SALMONN-omni: A Standalone Speech LLM without Codec Injection for Full-duplex Conversation. NeurIPS 2025.
[6] Word-Level Emotional Expression Control in Zero-Shot Text-to-Speech Synthesis. NeurIPS 2025.
[7] MoonCast: High-Quality Zero-Shot Podcast Generation. NeurIPS 2025.
[8] CoVoMix2: Advancing Zero-Shot Dialogue Generation with Fully Non-Autoregressive Flow Matching. NeurIPS 2025.
[9] Hogwild! Inference: Parallel LLM Generation via Concurrent Attention. NeurIPS 2025.
[10] Predictable Scale (Part II) --- Farseer: A Refined Scaling Law in LLMs. NeurIPS 2025.
[11] Feedback-Aware MCTS for Goal-Oriented Information Seeking. NeurIPS 2025.
[12] KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation. NeurIPS 2025.
[13] ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation. NeurIPS 2025.
[14] Distilling LLM Agent into Small Models with Retrieval and Code Tools. NeurIPS 2025.
[15] Absolute Zero: Reinforced Self-play Reasoning with Zero Data. NeurIPS 2025.
PREVIOUS
第 5 期 — Applications: Health
NEXT ISSUE
Applications — Neuroscience, Cognitive Science
深入解析应用领域前沿进展

- END -