


周一下午,领导发来一个微信。
茅台、腾讯、长鑫科技看一下。美股的MEGA7看一下。还有,韩国那边最近股市涨得厉害,看看三星、SK海力士。
后面跟了一句很轻的话:「这几家的最新年报都看看,下周一我们碰一下。」
这句话最阴险的地方在于,它听起来不像一个任务。
它听起来像让你顺手把会议室空调调低两度。
但你真正打开电脑以后,事情会立刻露出它本来的面目:A股去巨潮,港股去披露易,美股去SEC EDGAR,韩国去DART,台湾去MOPS,日本去EDINET,英国去FCA NSM。每个网站都很官方,每个网站都很严肃,每个网站都像在说:我只负责我这一亩三分地,你跨市场研究关我什么事。
你以为自己要开始分析竞争对手。
实际上,你先开始了一场官方披露系统环球旅行。
这就是做研究最烦人的地方。
最烦的往往不是分析。
分析至少还需要判断,需要取舍,需要把几个事实拧成一个结论。烦的是,在你开始动脑子之前,你要先交一笔很低级、很琐碎、很难对外解释的税。

我把它叫做碎玻璃税。
这件事不难。它甚至不配叫难。
找入口、搜公司、选年份、点下载、改文件名、放进文件夹。这些动作拆开看,每一步都很朴素,朴素到你不好意思抱怨。你总不能跟领导说,我今天没有开始分析,因为我在和一个官方披露网站的搜索框搏斗。
这话说出来显得人很菜。
但知识工作里真正消耗人的,恰恰经常是这种“不难但烦”的事。
举几个例子。
美股的SEC EDGAR非常权威,也非常像一个从上世纪穿越过来的系统。你想找苹果年报,直觉上会搜AAPL。但EDGAR底层更喜欢CIK编号,一串正常人很难主动记住的数字。进去以后,你会看到10-K、10-K/A、8-K、DEF 14A、S-1、424B4混在一起。这里面10-K是年报,10-K/A是修正版,8-K是重大事件,DEF 14A是股东会委托书。
如果你第一次用,最可能的反应是:好的,我承认它们都很重要,但我现在只想要那一份年报。
下载下来以后,文件名可能长得像0000320193-24-000123。
非常严谨。也非常不像一个人类会在桌面上主动保存的文件名。
港股披露易也有自己的脾气。你最好知道公司代码,因为它不是每次都愿意用公司名称和你友好聊天。搜索结果里年报、中报、业绩公告、补充公告、董事会决议都可能挤在一起。更麻烦的是,有些公司不是12月财年,你按自然年去找,很容易觉得文件不存在,其实只是报告年度和公告日期错开了。
韩国DART更直接。它主要用韩文。如果你不会韩语,光是找到“사업보고서”这个年报按钮,就已经像完成了一次小型跨文化交流。
最坑的是,我知道你要说,为什么不去官网下载呢。你要知道,很多公司甚至都没有投资者关系的板块。
这些网站都不是不能用。
它们只是都默认你是一个本地、单市场、一次只查一家公司的用户。
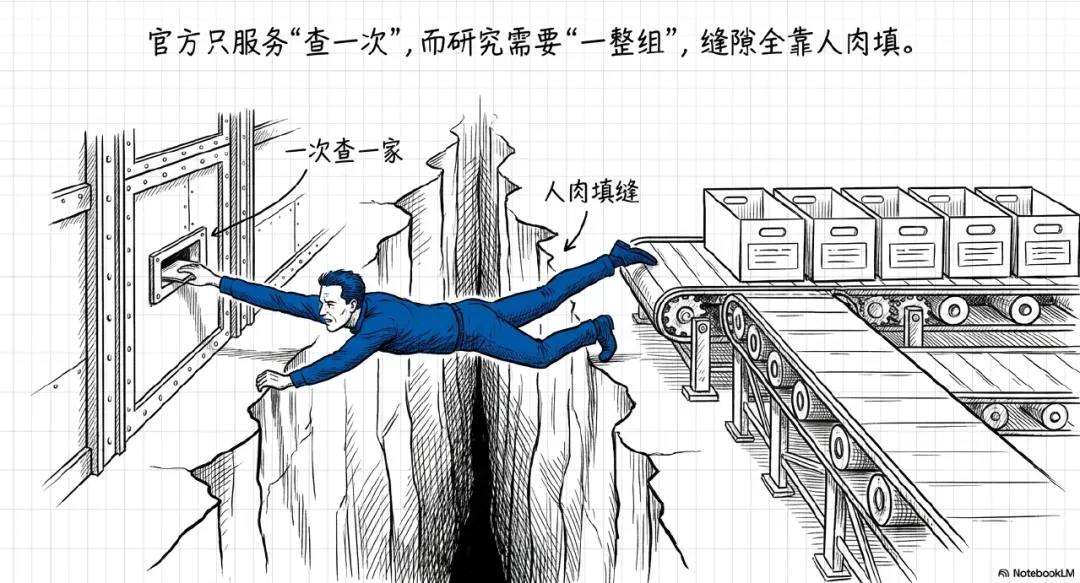
但研究工作不是这样。
你经常要一次看五家公司、三个年份、两个市场。今天看中国白酒和海外烈酒,明天看A+H双重上市,后天看一家中国公司和美国、日本、欧洲对手的披露口径差异。
官方系统都在服务“查一次”。
而你的工作是在做“一组研究”。
中间这道缝,就要靠人来填。
填缝的人,通常叫新人、分析师、项目经理,或者倒霉的自己。
以前我也觉得,这不就是前期资料收集吗?
做研究哪有不收集资料的。
后来我慢慢觉得,这个说法有问题。不是资料收集不重要,恰恰相反,它太重要了,所以不该每一次都靠人肉硬扛。
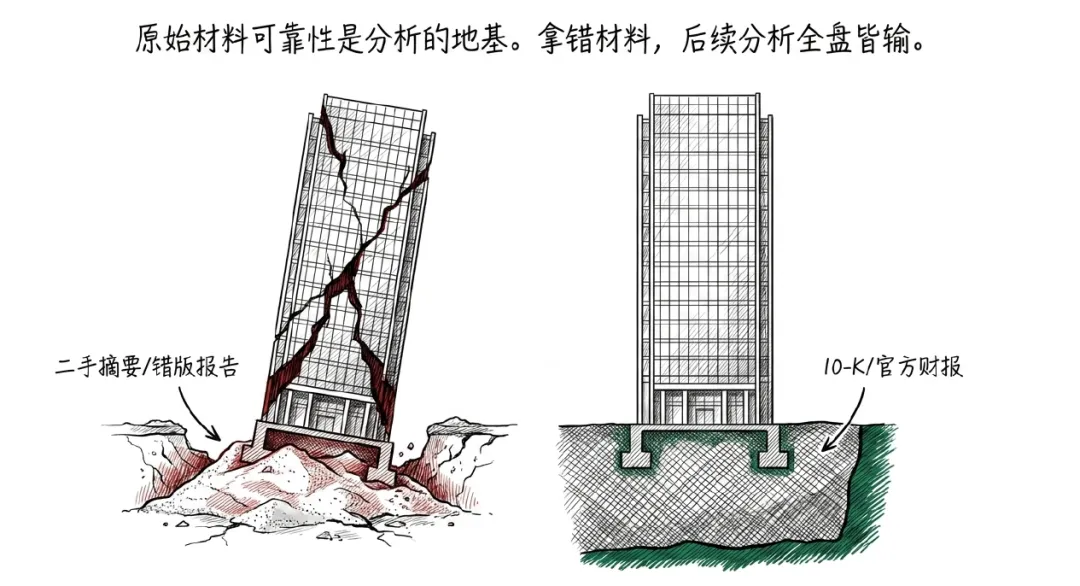
一份竞对分析,最前面的地基不是你的框架多漂亮,也不是PPT首页那张市场规模图多顺眼,而是那几份原始材料到底能不能信。你只有手握真正的原始材料,才能用那一堆skill去分析。
你拿的是官方披露文件,还是二手整理?
你拿的是完整年报,还是年度报告摘要?
你拿的是原版10-K,还是10-K/A修正版?
这些问题听起来很细,甚至有点烦。但它们决定了后面的分析是不是站在地上。地基如果错了,后面写得越流畅,越像在沙滩上搭样板间。
这也是AI时代一个不太热闹、但很关键的变化。
大家现在更关心AI能不能写报告、画图、做PPT、总结会议。能,当然能。它写得还越来越快,越来越像那么回事。
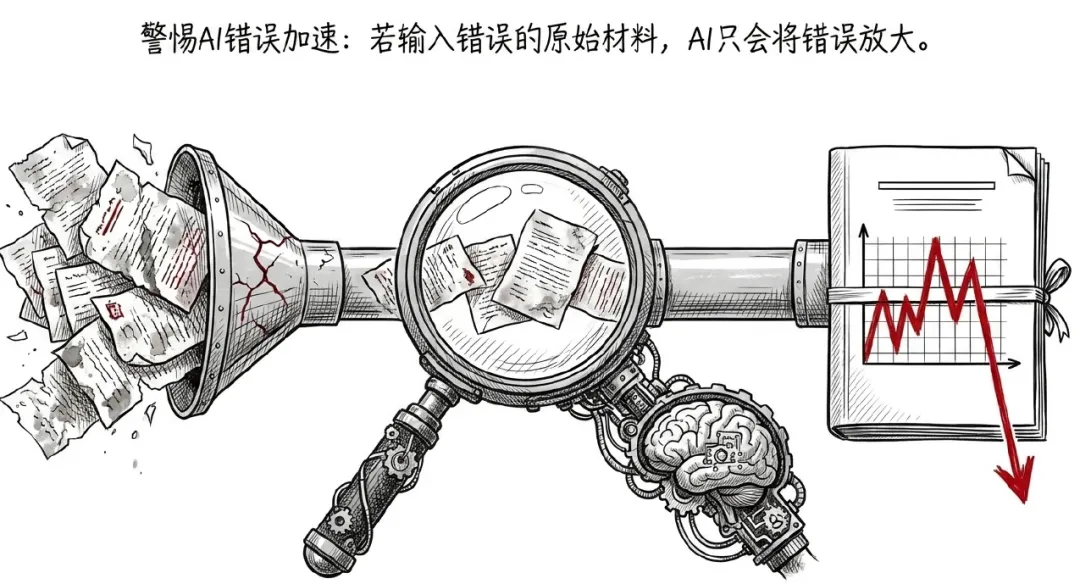
但输出越快,输入越要命。
如果你的原始材料是错的,AI不会神奇地把它纠正成对的。它很可能只是用更优雅的语言、更精致的结构、更自信的语气,把错误放大。以前你要花两天写出一份有问题的报告,现在半小时就能交付一份排版精美的错误。
这不是效率提升。
这是错误加速。
所以我现在越来越在意一个能力,叫材料可信度。
它不是“会搜索”。会搜索只是入门动作。材料可信度是你知道什么东西能信,什么东西要怀疑,什么时候该回到官方源头,什么时候不能拿二手摘要糊弄过去。
这个能力不性感。
没人会在简历上写“熟练下载年报”。写了也像一种自我伤害。
但很多真正严肃的研究,死就死在这里。数据口径没对齐,年度选错了,报告版本拿错了,双重上市公司用错市场披露文件,最后会议上吵了两小时,以为大家在争判断,回头一看,是材料从一开始就没站在同一个地面上。
这也是我为什么觉得,这类“下载年报”的小事,不该一直停留在手工劳动里。
它不是低端杂活。它是研究工作的第一道质量门。
过去我们默认“找材料”是新人先做的活。新人先去找,找完再给老人看;分析师先去拉,拉完再给经理判断;底层材料打包好了,上面的人再开始“真正思考”。
这套分工在过去勉强还能运行,因为人的时间便宜,工具能力有限,大家也习惯了让初级岗位承担大量机械动作。
但现在这个逻辑有点过时。
不是因为新人不该做基础工作,而是因为很多基础工作已经应该被产品化、流程化、工具化。你让一个年轻人反复下载、重命名、归档,不是在训练他的判断力,只是在训练他的耐心。耐心当然也重要,但一个组织不能把低效说成磨炼。

磨炼和浪费,长得确实有点像。
区别在于,磨炼会让人能力增长,浪费只会让人熟练受苦。
所以我最近会推荐一个工具,叫Filings Atlas,中文名是全球披露图谱。
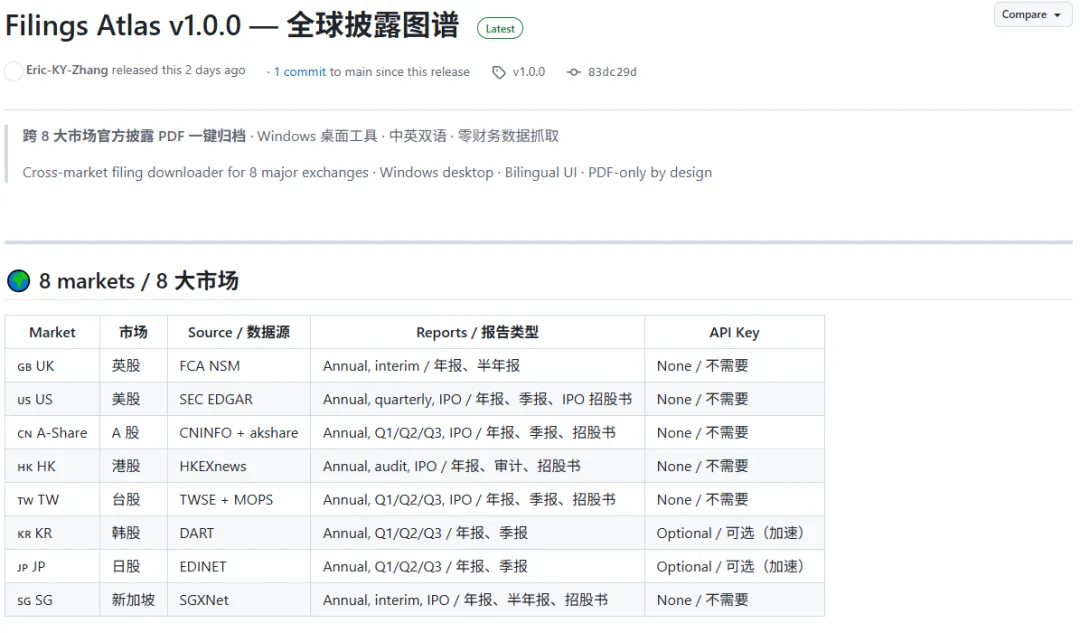
https://github.com/Eric-KY-Zhang/Filings-Atlas/releases/tag/v1.0.0
它只做一件事:批量拿到8个市场上市公司的官方披露PDF,统一命名,本地归档。
目前覆盖A股、港股、美股、韩股、台股、日股、英股、新加坡。输入股票代码,选年份和报告类型,点击下载,最后文件落到本地output文件夹里,文件名大概长这样:
A_600519_贵州茅台_2024_年报.pdf
HK_00700_腾讯控股_2024_年报.pdf
US_AAPL_Apple Inc_2024_年报.pdf
这几个文件名看起来没有任何技术奇迹。
但它们对研究工作很友好。
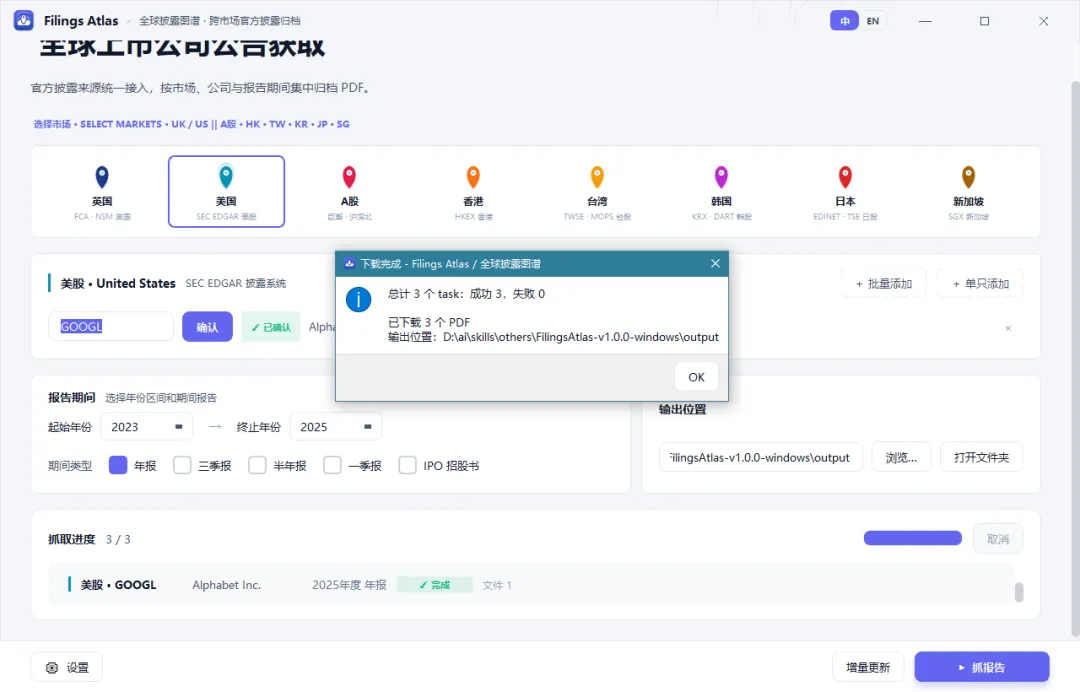
你一眼知道这是哪个市场、哪家公司、哪一年、哪类报告。你下次打开这个文件夹,不需要再像考古一样打开每个PDF确认身份。更重要的是,你可以把材料收集这件事从“每次临时开工”变成“一套稳定入口”。
它不能替你做分析。
也不应该替你做分析。
它更像一个很老实的同事,沉默地把文件拿齐、命名好、放到同一个地方,然后说:好了,你可以开始动脑子了。
我现在越来越喜欢这种克制的工具。它不假装比你聪明,也不急着替你下结论。它只是把那些本来不该消耗你注意力的动作拿走,让你把脑子留给真正需要判断的地方。
这里面有一个我自己踩过的坑。
这个工具早期版本里,我其实顺手做过财务数据抓取、三大报表数字提取、Excel底稿装填。
听起来很合理,对吧?
都已经下载年报了,为什么不顺手把数据也抓了?都已经识别公司了,为什么不顺手算指标?都已经做工具了,为什么不顺手生成底稿?
“顺手”这两个字,是很多产品变烂的起点。
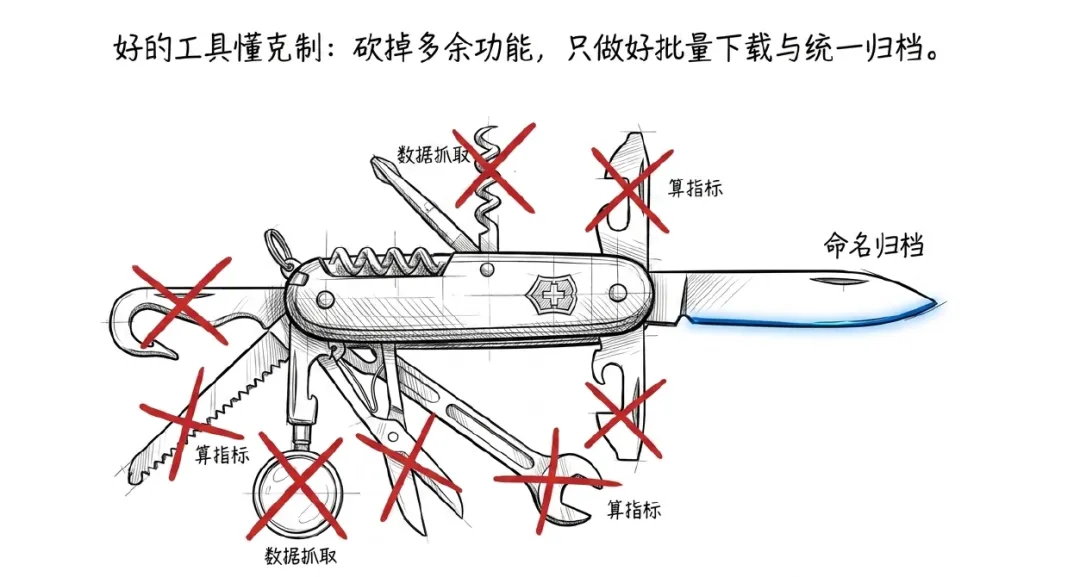
后来我发现,跨市场财务数据口径、字段名称、报表结构、披露格式,维护成本远超想象。而真正高频、真正让人烦的需求,反而朴素得多:我只是想稳定拿到官方PDF。
于是推倒重来。
砍掉数据抓取。
砍掉指标计算。
砍掉Excel底稿。
只保留官方PDF下载、统一命名、本地归档。
这件事给我的启发很大。很多时候,工具的价值不是“它还能顺手干什么”,而是“它终于不再多管闲事”。
一个工具如果能把一个具体痛点解决干净,就已经很值钱了。尤其是在知识工作里,那些看起来不起眼的前置动作,往往是后面所有高阶动作的地基。
地基不需要花里胡哨。
地基只需要别塌。
这件事往大了看,其实是一个材料供应链问题。
很多公司讲数字化,讲AI转型,讲知识库,讲数据中台。但回到一个最朴素的场景:一线员工能不能在十分钟内拿到可信、完整、命名清楚、来源可追溯的基础材料?
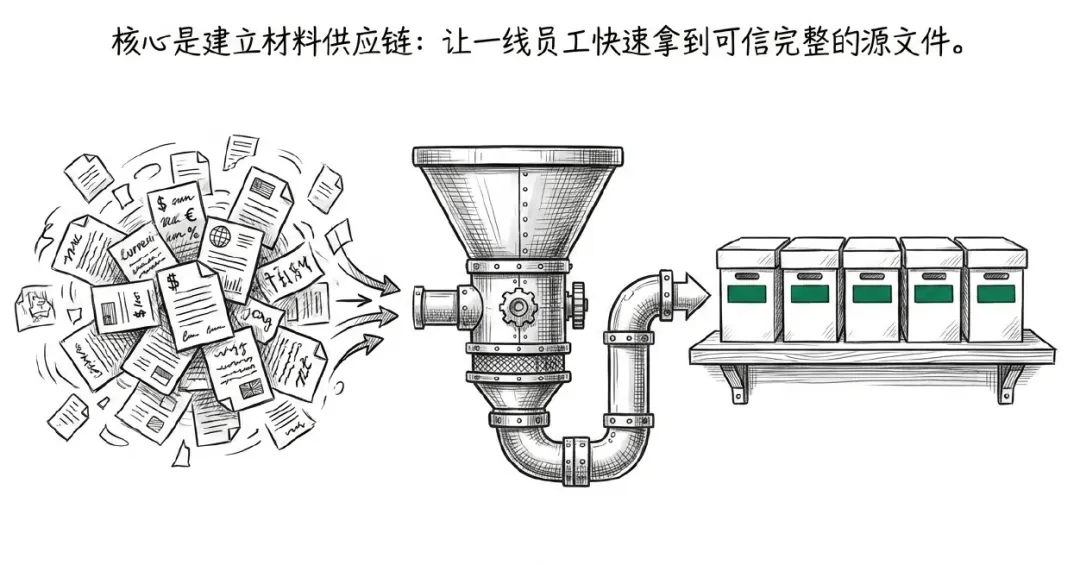
如果不能,后面那些词就有点悬。
你不能一边让大家拥抱AI,一边让他们在官方披露网站里手动捡玻璃。
一个知识工作者最贵的资源,不是手速,是注意力。
你一天里真正能进行高质量判断的时间其实很少。大部分时候,我们的脑子都被各种边角料磨掉了:找文件、改格式、对版本、补字段、复制粘贴、确认来源。每一件都不大,但它们会把你的注意力切碎。
切碎之后,你再坐下来“深度分析”,其实已经半残。
所以我不认为下载年报只是下载年报。
它背后是一个更大的问题:我们到底有没有认真设计知识工作的材料供应链。
给不同读者几个特别具体的建议。
如果你是新人,不要满足于“我把资料找齐了”。你要多问一步:这些资料的来源、版本、年份、口径,能不能被下一个人复用?如果不能,你只是完成了一次搬运;如果能,你就在为团队留下资产。
如果你是中层,别再把资料收集简单丢给新人然后说“锻炼一下”。你应该检查的是流程:哪些材料每次都要找,哪些网站每次都要进,哪些命名每次都要改,哪些判断每次都靠人记。把这些东西写成规则,能工具化就工具化,不能工具化至少模板化。
如果你是管理者,别只问AI帮我们写了多少PPT、节省了多少工时。你应该问:我们有多少碎玻璃被扫掉了?有多少关键材料实现了可追溯?有多少业务判断不再靠“老员工心里有数”?

这比买多少账号重要。
因为账号是消耗品,规则才是资产。
而且这件事不是战略部、投研部、财务部的专属问题。
你去看很多办公室工作,本质上都有一条材料供应链。法务看合同,先要拿到正确版本、历史修改记录、补充协议和审批意见;市场做复盘,先要拿到真实投放数据、渠道口径、费用归属和转化口径;人力做组织盘点,先要拿到岗位编制、绩效记录、异动历史和访谈纪要。每个部门表面上都在做判断,实际上第一步都是先把可信材料摆上桌。
问题是,很多公司对“材料摆上桌”这件事没有敬畏。

大家默认材料会自己出现。默认有人能在群里翻到。默认老同事知道上一版在哪里。默认那个Excel虽然叫“最终版2-修改-新-真的最终版”,但大家都能猜出来哪个是真的。
这种默认,在AI时代会变得越来越危险。
因为AI不擅长猜公司里的潜规则。它不知道哪个文件才是老板口中的“上次那个版本”,不知道哪个表虽然名字旧但口径新,不知道某个数据因为去年组织调整已经不能直接同比。人和人之间还能靠眼神、记忆和一句“你懂的”糊过去,AI不懂这一套。
你不给它干净输入,它就会给你漂亮废品。
所以材料供应链不是一个低阶问题,而是AI能不能真正进入业务的前置条件。没有这层,AI再强也只是坐在会议室外面等人递资料。递进去的是错的,它就认真地错;递进去的是乱的,它就努力地乱;递进去的是过期的,它就用最先进的模型帮你复述过去。
我不是说每家公司都要做一个Filings Atlas。这个工具只是一个小例子。真正值得带走的是后面的思路:当你发现自己每次都在同一个地方受苦,不要急着提高忍耐力,先想想它能不能被拆成规则。
能被拆成规则的痛苦,就有机会被工具拿走。
拿走之后,你不是更闲了。
你是终于可以把注意力拿回来。
回到开头。做竞对分析最烦的,根本不是分析。
烦的是,你还没开始分析,就先被一堆官方系统、文件名、版本号、编码、年份口径、报告类型拖进泥地里滚了一圈。滚完之后,你还要假装自己精神饱满,打开PPT写“核心结论”。
这不合理。
AI时代最该被消灭的,不只是写周报、画图表、做网页这种显眼工作。还有这些藏在知识工作前面的、朴素到没人愿意认真命名的碎玻璃。
别小看它们。
很多时候,真正拉开差距的不是谁更会写结论,而是谁能更快、更稳、更可追溯地把可信材料放到桌上。
分析从来不是从第一页PPT开始的。分析从材料到位的那一刻才开始。
关注【BIE卷了】,换个姿势,不硬卷。
/ 作者:zb