


OCP(Open Compute Project)在 2026 年 4 月正式发布了由 iPronics、Lumentum、Ciena、Lumotive 及卡内基梅隆大学等机构联合署名的 OCS(Optical Circuit Switching)白皮书,作为巴塞罗那峰会"开放 AI 数据中心生态"战略的核心交付物之一。
这是 OCS Subproject 自 2025 年 7 月成立以来,首次以正式技术文档形式,完整梳理 robotic、MEMS、liquid crystal、piezoelectric、silicon photonics、metasurface 共 6 大类 OCS 技术路线,并系统披露 5 大 AI 数据中心应用场景与 3 大未来用例。依托 Google Jupiter 与 TPUv4 实战数据,白皮书证实 OCS 替换 spine 层 EPS(Electrical Packet Switching)可实现网络功耗降低 41%、CAPEX 降低 30%、网络吞吐量提升 5×;LLM 训练在 TPUv4 Superpod 上较静态配置加速 3.3×,功耗再降 9%——可以说相对此前完全闭源、由 Google 独占近五年的工程实践而言是显性的开放化突破,光交换技术终于具备向广义产业链扩散的标准载体。
但是,OCP OCS 白皮书与同期发布的 NVIDIA MRC(Multipath Reliable Connection)、ESUN(Ethernet for Scale-Up Networking)协议规范在产业生态成熟度上仍存在数量级差距,后者已落地 OpenAI Stargate、Microsoft Fairwater 全量集群,前者仍以"Google 工程经验综述"为主——5 大用例中 2 大依赖学术论文(ACTINA、MixNet)未及大规模商用、其余 3 大几乎全部源自 Google 一家的实战数据,白皮书所标定的"标准化愿景"与"商业化生态"之间的鸿沟,尚未实现根本性弥合。
一、白皮书做对了什么:把 OCS 从黑箱拉到了明面
1.1 设计选择的合理性:OCS 精准切中了 AI 时代电交换的三堵硬墙
白皮书的论证起点是清晰的——modern AI/ML 工作负载在带宽、可预测延迟、大规模同步这三个维度同时撞墙,而 EPS 路线的代价已不可承受。具体数据:一座大型 DC 若部署 64 台 16 槽 chassis-based spine 交换机,每台约 30kW(400G 半填充 coherent 光模块),仅 spine 一层就要吃掉约 1.9MW 电力。OCS 通过直接在光域建立端到端 circuit、彻底绕开 OEO(Optical-Electrical-Optical)转换,把这块开销近乎完全消除——这是白皮书给出的第一性原理论证。
在工程上,Google 的 Jupiter Evolving 论文 [1] 已将这套逻辑量产化:用 OCS 替代 spine EPS 后,网络功耗降低 41%、CAPEX 降低 30%、burst 带宽提升 5×,且 spine 层不再受限于 leaf 交换机速率,从而摆脱了"leaf 升级 100G/400G/800G 就必须强制升级 spine"的连锁包袱。
这套架构选择背后的真正杀手锏,是协议无关与速率无关(protocol-agnostic, rate-agnostic)——光路一旦建立,承载什么协议、跑什么速率都不需要重新设计交换硬件,这意味着 OCS 设备的折旧周期可以拉到比 EPS 长得多,直接重塑数据中心 TCO(Total Cost of Ownership)模型。
1.2 共性缺陷:与同期 OCP 标准化进程并无二致——但只有 Google 一家有真实数据
OCP 在 2026 年 4 月一次性推出了一组完整规范:OCS 白皮书、NVIDIA 主导的 MRC、ESUN、SUE-T(Scale-Up Ethernet Transport)、Optics Reliability,覆盖从物理层到传输层、scale-up 到 scale-out 的全栈。但 OCS 白皮书与 MRC 规范在结构性短板上并无二致——两者都把成败押在"hyperscaler 工程经验能否真正向产业链复制"这一根命脉上,且都尚未跨越这道坎。
具体到 OCS,白皮书自己承认了三条硬约束:
其一,one-to-one 电路特性——OCS 不具备 packet-level 多播或 fan-out 能力,在突发流量与 fan-out 拓扑场景下必须保留 EPS,只能做 hybrid 部署;
其二,无包级 telemetry——OCS 完全在光域工作,无法做 QoS 强制、流量检查、per-packet 分析,这意味着数据中心运维体系需要重新设计监控栈;
其三,插入损耗约束 hop 数——不引入高功率激光或 SOA(Semiconductor Optical Amplifier)放大的情况下,OCS 实用 hop 数被限制在 1-2 跳,这与 EPS 依靠电再生跨越任意多跳形成根本对照。更深一层的隐忧白皮书没有说透:5 大用例中,A(spine 替换)、B(TPU Superpod)、C(failure resiliency)三项全部基于 Google 的 Jupiter 与 TPUv4——TPUv4 Superpod 用了 64 个 Cube × 64 TPU = 4096 TPU,每 Cube 连接 48 台 128 端口 MEMS OCS——而 D(ACTINA)、E(MixNet)两项尚在论文阶段。换言之,OCS 在 2026 年仍是 Google 一家独白,与其说"行业共识",不如说"行业默认 Google 的工程结论可被推广"。
二、技术演进:从 ms 级 spine 替换走向 ns 级 in-workload 重构
将 spine 层从耗能的多层 packet switch 中解放,只是 OCS 的第一战。白皮书更具雄心的部分,是描绘了一条清晰的演进阶梯——切换时间从 ms 级降到 ns 级、重配置粒度从"每作业一次"细化到"每迭代一次",由此衍生出两条主流路径。
路径一:成熟的 spine 层替换(Google Jupiter / TPUv4 模式)。这条路线已被工业验证,核心是用大端口数、慢重配置的 MEMS OCS 替换 spine。Google Jupiter Evolving [1] 用 OCS 作 DCNI(Data Center Network Interconnect)层,使 fabric 可在 aggregation block 之间增量改写、避免破坏性升级;TPUv4 [2][3] 则把 OCS 推进到 AI cluster 内部,通过 X/Y/Z 三组 OCS 让 Cube 在每个训练作业开始前重组成 torus、3D mesh 等任意拓扑,直接换得 LLM 训练 3.3× 加速与 9% 功耗降低,且在 99.9% server 可用率下、1024-TPU slice 的有效吞吐量从静态配置的 25% 提升到可重构架构的 75%。该路径的最大特征是重配置粒度=作业(per-job),OCS 在作业切换间隙完成切换、计算过程中完全静态,因此对 ms 级切换时间完全容忍。NVIDIA 同期论文 [4] 给出的 320×320 OCS 作 spine/leaf 保护层,也属于这一阵营。
路径二:计算-通信周期内的动态重构(ACTINA / MixNet 模式)。这是白皮书更激进的展望,核心是用小端口数、快重配置的 OCS 嵌入到 GPU 通信路径中,做亚迭代级(intra-iteration)重构。Columbia + NVIDIA 的 ACTINA [5][6] 提出的 OCS-BCube,把 Mach-Zehnder Interferometer(MZI)级联 DWDM(Dense Wavelength Division Multiplexing)梳状激光器集成进 GPU 端的 silicon photonics transceiver,允许每端口按波长动态重配,实测较 OCS-enabled 3D Torus 提速 1.84×、能耗较 OCSFT-2L 降 1.72×、tokens-per-joule 改善 1.75×。SIGCOMM 2025 的 MixNet [7] 则更进一步——针对 MoE(Mixture-of-Experts)训练的 EP(Expert Parallelism)流量,利用"EP 通信局部化(每群 8-32 GPU)"和"相邻迭代流量模式渐变可预测"两条洞察,在前一迭代的计算阶段就完成下一迭代的 OCS 重配,实测 Mistral 8×7B MoE 训练时间较静态 fat-tree 加速 1.6×。这条路径在白皮书中的地位明确——是未来,不是现在。
未来终极演进:OCS + CPO + wavelength-reconfigurable transceiver。白皮书 Figure 11 给出的 MixNet 升级版本——co-packaged optical ports 直接挂在 xPU 上、跨 server 通过 regional OCS 互联——基本上勾勒出了未来 5-10 年的 AI 网络终局:scale-up 层由 NVSwitch 类 fabric 承担、scale-out 由 EPS 承担、regional 跨服务器通信由 OCS + CPO 承担,三者通过统一控制面协同。这一架构的隐含前提是 CPO 与可重构波长 transceiver 必须成熟,而后者目前在实验室阶段——白皮书引用的 OFC 2024 短文 [6] 用 8 路 DFB 激光 × 16Gbps,只是原理验证。
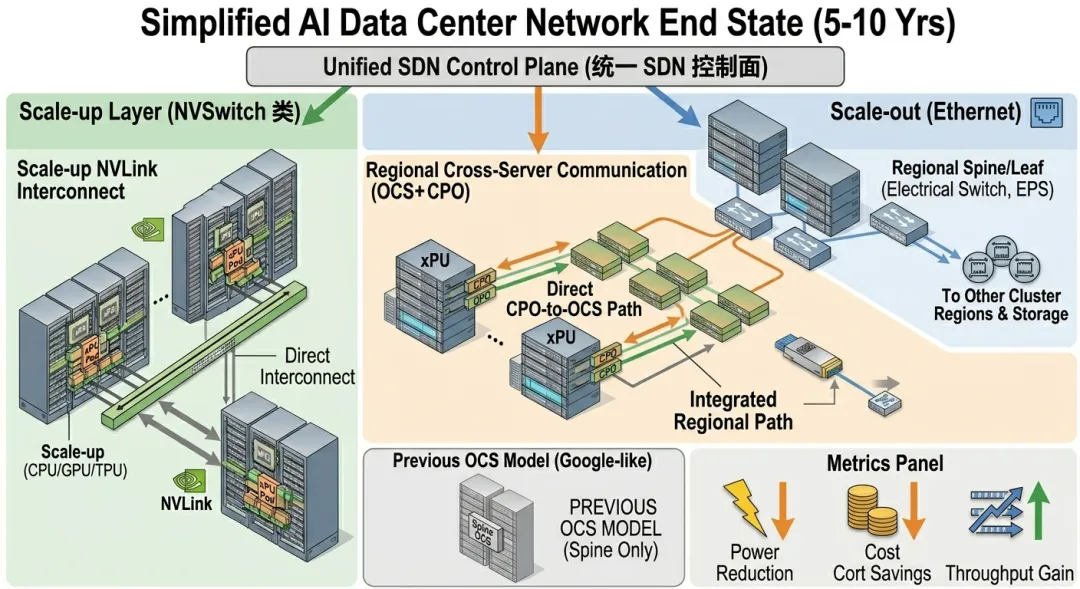
三、被白皮书克制处理的三个真问题
白皮书是一份合格的"OCS 教育文档",但有三个真问题被显著克制——这恰恰是判断 OCS 落地节奏时不可忽略的变量。
其一,6 大技术路线的 SDN 控制面碎片化。白皮书在第 4 章列出 robotic、MEMS、liquid crystal、piezoelectric、silicon photonics、metasurface 共 6 大类,每类的端口规模、插入损耗、切换时间、是否需要持续供电(latching)各异——robotic 可达 large radix 但切换以秒分钟计、silicon photonics ns-µs 级但 radix 低、metasurface 切换 µs 但插入损耗中等。要在这 6 套迥异的硬件上做出真正可替换的统一控制面,远比统一以太网 NIC 抽象难得多。白皮书提到的 gNMI、gNOI、OpenConfig 软件接口,目前主要由 Google 主导——这就引出第二个真问题。
其二,"Google 独唱"的产业风险。客观说,Google Jupiter [1]、TPUv4 [2][3]、Lightwave Fabrics [11]、ACTINA(NVIDIA 联署)[5]——白皮书 12 篇 reference 中有 5 篇来自 Google 或 Google 合著。其他 hyperscaler 在 OCS 上的实战数据几乎完全空白。从历史经验看,任何技术从一家独占走向多家共建,中间至少需要 3-5 年的"第二玩家入场期",而当下竞争最激烈的玩家(Meta、Microsoft、AWS)目前在 OCS 上要么沉默、要么走自研路径——这意味着 OCP OCS 标准实际能影响的"非 hyperscaler 部署"客户(neocloud、co-location、企业 AI),短期内会发现"标准很美好、可落地的产品矩阵不齐全"。
其三,与电交换强化路线的边界划分仍未明确。同期 OCP 通过的 NVIDIA MRC 走的是"在 Ethernet 上加多路径 + 微秒级 failover"的强化路线,适用场景与 OCS 高度重叠——都瞄准 AI 集群的 scale-out 大流可靠传输。白皮书隐含的边界划分是"OCS 接 spine、MRC 接 transport"——但在 Meta Clemente、NVIDIA GB300 NVL72、OpenAI Stargate 这些 2026 年实际部署的 100k 卡集群里,究竟谁先吃掉哪一层,白皮书没有正面回答。中性的判断是:短期(1-3 年)MRC 路线因可立即量产、不需要改光纤层而占主流;中期(3-5 年)OCS 在 spine 与 AI cluster 内部互联吃下显性份额;长期(5-10 年)二者通过统一 SDN 控制面收敛进 hybrid 架构。
四、结语
OCP OCS 白皮书是 2026 年 4 月光交换技术走出 Google 大门、登上开放标准化舞台的标志性文件:它系统梳理了 OCS 6 大技术路线、5 大已落地与未来用例,把 41% 功耗下降、30% CAPEX 降低、5× 吞吐量提升、3.3× LLM 训练加速这一组关键数字定型;它在第二章用 Openness、Efficiency、Impact、Scale、Sustainability 五条 OCP 信条把 OCS 嵌进开放生态价值观;它在第六章把视野延展到量子网络、可预测延迟、资源解耦三个未来场景,给产业留下了想象空间。
客观而言,这份白皮书与同期发布的 NVIDIA MRC 规范一样,始终未能从根本上解决"hyperscaler 工程经验如何复制到开放生态"这一结构性难题——OCS 路线高度依赖 Google 一家的实战数据、6 大硬件技术路线在 SDN 控制面上仍处于碎片化、与电交换强化路线的部署边界仍未划定。光交换演进并非一代定型的终点式突破,而是循序渐进、持续迭代的长期进程。
当前 AI 网络演进路线已清晰成型:短期电交换强化路线(MRC、ESUN)依托即装即用提供生态成熟的高密度方案;中期 OCS 在 spine 层与 AI cluster 内部互联(Google Jupiter、TPU Superpod 模式)构筑 ms 级重配置 + 大端口数的优选方案;长远依托 CPO 与波长可重构 transceiver(ACTINA / MixNet 路径),可进一步迈向亚迭代级 ns 切换 + GPU 端直接挂光口的终极形态。
从黑箱到白皮书、从一家独占到开放标准化,是光交换技术走向产业基础设施的一次重要阶段性突破,但面向"光电混合 AI 数据中心"的真正终局,标准化进程才刚刚启程,生态构建、互操作认证、多厂家协同部署等关键攻坚环节,后续仍有广阔的优化与演进空间。
参考链接
1、OCP OCS 白皮书(2026 年 4 月):https://www.opencompute.org/documents/ocp-ocs-white-paper-april-2026-final-pdf
2、OCS Subproject 主页:https://www.opencompute.org/projects/optical-circuit-switching
3、Poutievski et al.,Jupiter Evolving: Transforming Google's Datacenter Network via OCS and SDN, ACM SIGCOMM 2022
4、Jouppi et al.,TPU v4: An Optically Reconfigurable Supercomputer for ML, ISCA 2023
5、Wu et al.,ACTINA: Adapting Circuit-Switching Techniques for AI Networking Architectures, SC 2025
6、Liao et al.,MixNet: A Runtime Reconfigurable Optical-Electrical Fabric for Distributed MoE Training, ACM SIGCOMM 2025
7、Liu et al.,Lightwave Fabrics: At-Scale OCS for Datacenter and ML Systems, ACM SIGCOMM 2023