



面向大模型训练与超算级算力需求,传统电分组交换(EPS)架构在带宽、延迟、功耗与规模化扩展上已逼近物理极限。拥塞、高功耗、不可预测的抖动与逐层光电转换损耗,正成为制约AI集群性能的核心瓶颈。在此背景下,光交换(OCS)以全光直通、无缓冲、协议无关、超低时延的原生优势,从前沿技术跃升为下一代数据中心网络的关键基石。
本文依据开放计算项目(OCP)2026年4月发布的白皮书,介绍OCS技术体系、实现路径、规模化部署实践与未来演进方向。
一、OCS核心定位:突破电交换瓶颈的全光架构
光交换的本质,是在光域直接建立端点到端点的物理光路,全程无光电光(O-E-O)转换、无数据包缓存、无存储转发,实现真正透明、无损、低时延的信号传输。这一机制从根源上解决了电分组交换在AI高带宽、强同步、大规模并行场景下的固有缺陷。
OCS为数据中心带来五大不可替代的核心价值:第一,全光路径带来极致低时延与无拥塞运行,消除队列延迟与缓存竞争;第二,支持高吞吐与大规模端口扩展,可平滑适配下一代网络速率;第三,能耗与成本显著优化,规模化部署可实现网络功耗降低41%、资本支出下降30%;第四,协议与速率无关,具备跨代兼容能力,保护基础设施长期投资;第五,支持物理层动态拓扑重构,大幅提升网络灵活性、资源利用率与故障恢复能力。
与此同时,OCS也存在明确技术边界:作为路径交换,它仅支持一对一连接,无法实现电交换的一对多广播、逐包转发与负载均衡;纯光域运行使其不具备报文解析、QoS调度、流量检测与包级遥测能力;受光插入损耗限制,无放大条件下实用跳数通常限制在1至2级,难以像电交换机那样依靠信号再生实现多级级联。这些特性决定了OCS并非取代EPS,而是在关键场景形成互补与升级。
二、OCS主流技术路线:六大方案全景解析
OCS可通过多种物理机制实现,不同路线在端口规模、插入损耗、切换速度、可靠性与成本上存在明确权衡,白皮书将其归纳为六大技术方向。
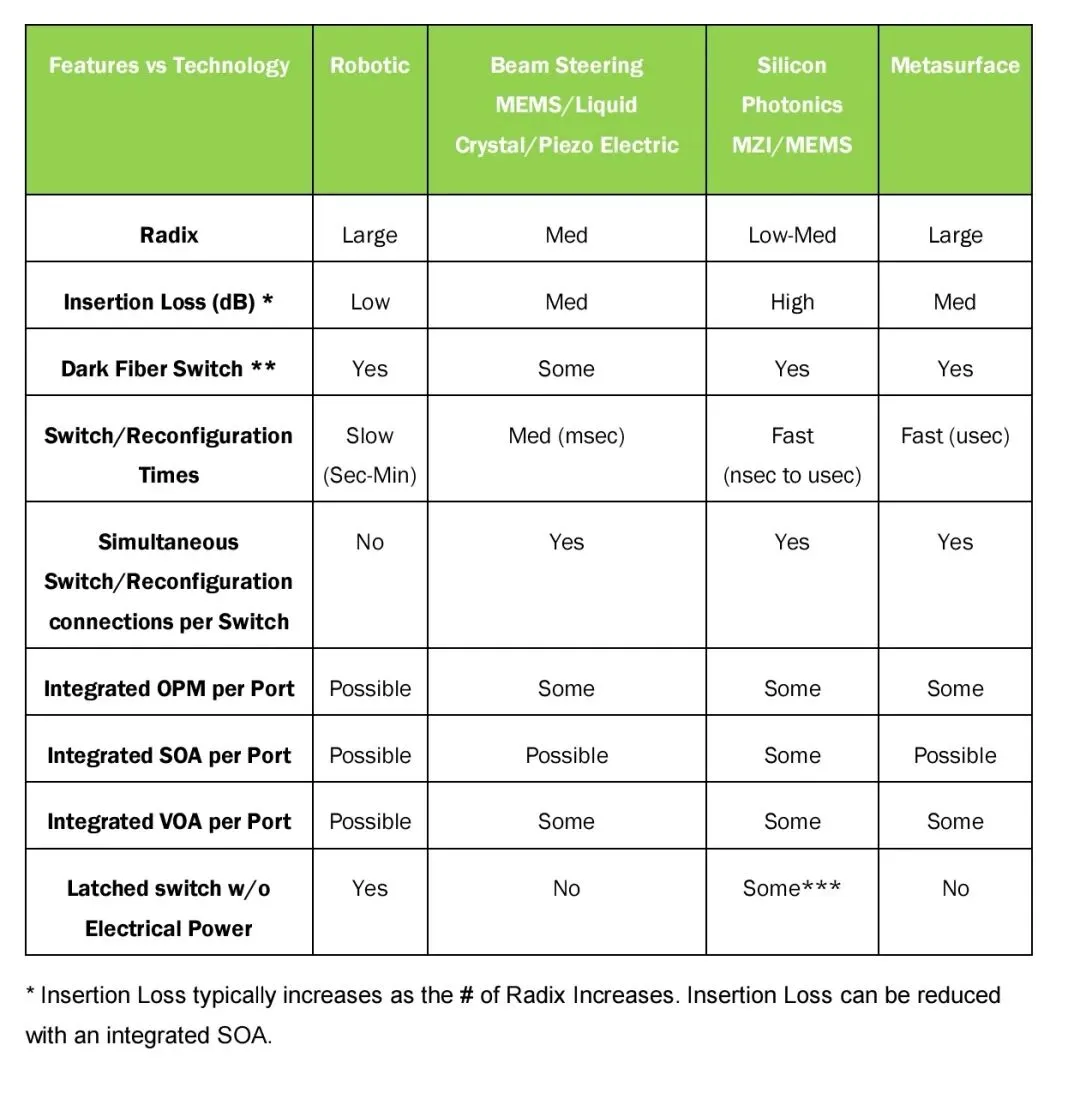
机器人机械切换方案等效于全自动光纤配线架,依靠电机驱动物理移动光纤完成光路连接,具备锁存特性,连通后无需持续供电,支持超大端口无阻塞交叉,插入损耗极低,可支持暗光纤切换,主要短板是重构速度慢,处于秒至分钟级,更适合低频次、高稳定的重配置场景。
微机电系统(MEMS)微镜方案通过二维或三维阵列式微小倾斜镜面,在自由空间实现光束精准转向,支持大端口数、较宽光带宽与适中插入损耗,是当前规模化部署的主流选择,缺点是对振动敏感,长期运行需精密对准保障。
液晶方案以固态形式工作,依靠电压调控液晶改变光偏振,实现无机械运动光路切换,驱动电压低、稳定性高,但对偏振敏感,需配合偏振分集组件才能适配真实网络信号。
压电驱动方案利用材料电致微变形实现光纤或镜面高精度对准,定位精度与重复性优异,常用于超高精度光束控制场景,系统复杂度高,需多执行器协同与精密装配。
硅光子方案基于CMOS兼容平台,在片上亚微米波导中依靠热光或电光效应实现光路调控,使用马赫-曾德尔干涉器、环形谐振器等光子器件,重构速度可达纳秒至微秒级,具备低成本大规模量产潜力,挑战在于端口规模提升时插入损耗与串扰上升,需集成半导体光放大器补偿性能。
超表面方案采用电可调亚波长像素控制光相位,实现无机械运动大角度自由空间光束转向,端口密度高、切换速度快、偏振不敏感,插入损耗不随端口数快速劣化,存在中等插入损耗与一定波长依赖性。
混合集成方案则融合多种技术优势,例如硅光子与MEMS微执行器结合、空间交换与波长交换协同,在高速切换与低损耗之间取得平衡,代价是设计与制造复杂度显著提升,多数仍处于产业化早期。
三、OCS规模化落地:三大生产级部署场景
截至2026年,OCS已从实验室走向超大规模生产环境,以Google为代表的厂商已完成全栈验证,形成三大成熟商用场景。
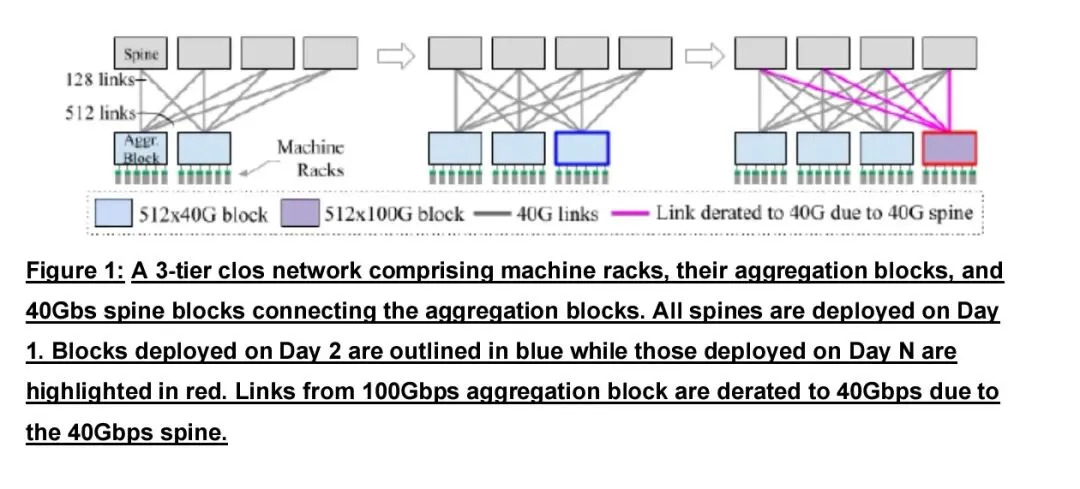
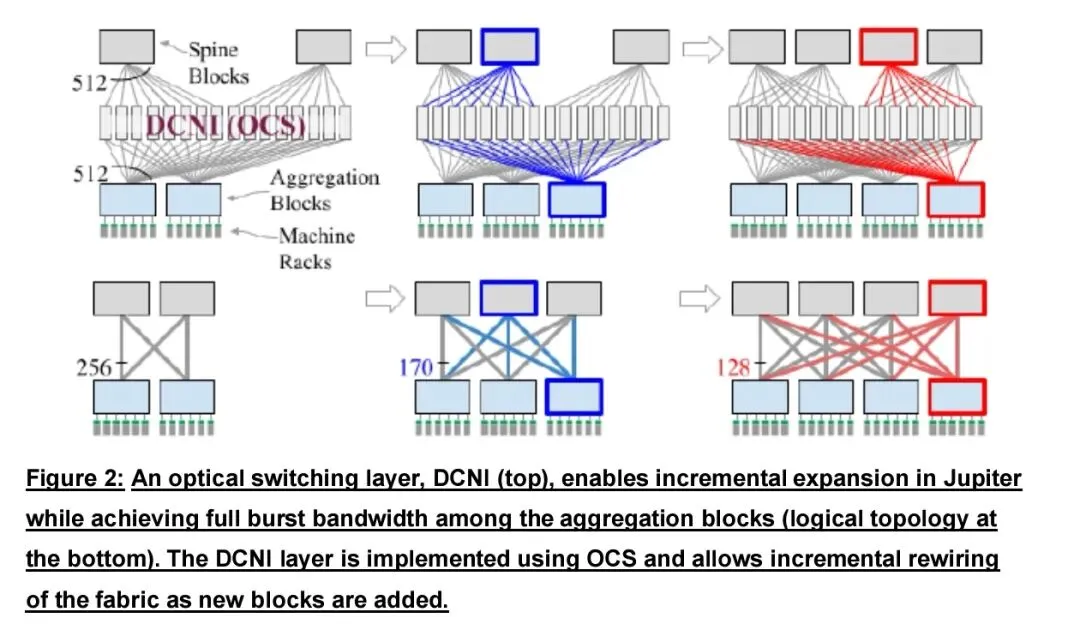
最主流的应用是电分组交换骨干层替换,采用大端口OCS设备直接替代数据中心Spine层电交换机,叶交换机通过OCS层实现扁平化直连。这一模式可彻底消除骨干层电交换机带来的巨大功耗,在典型超大规模部署中,单数据中心骨干层功耗可降低兆瓦级;同时OCS层速率透明,叶层升级到更高速率时无需同步升级骨干,避免带宽瓶颈。Google在Jupiter网络中采用该架构,实现网络功耗降低41%、资本支出下降30%、网络吞吐量提升5倍,部署周期显著缩短,唯一约束是流量需具备可预测性,以实现容量最优配置。
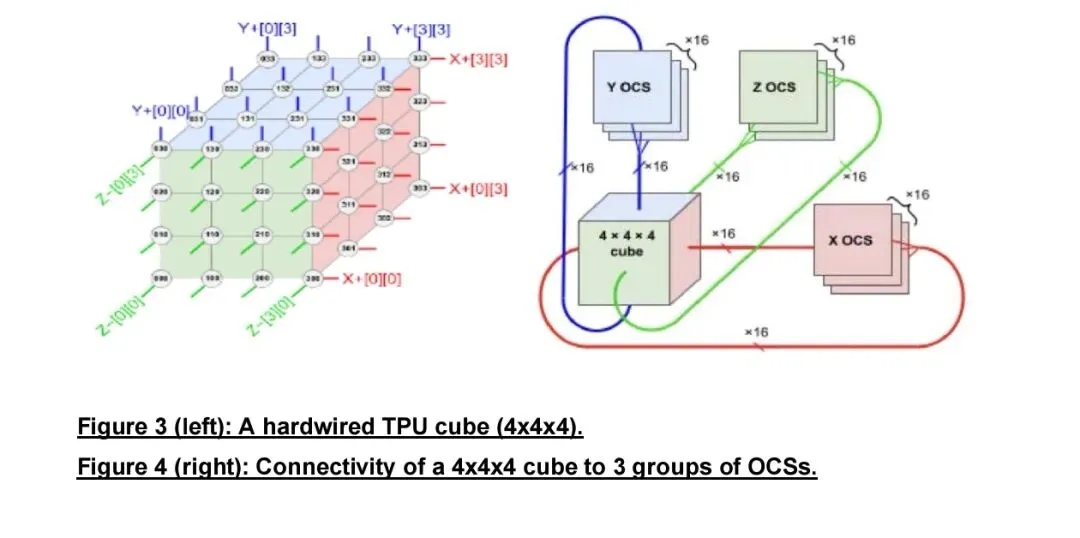
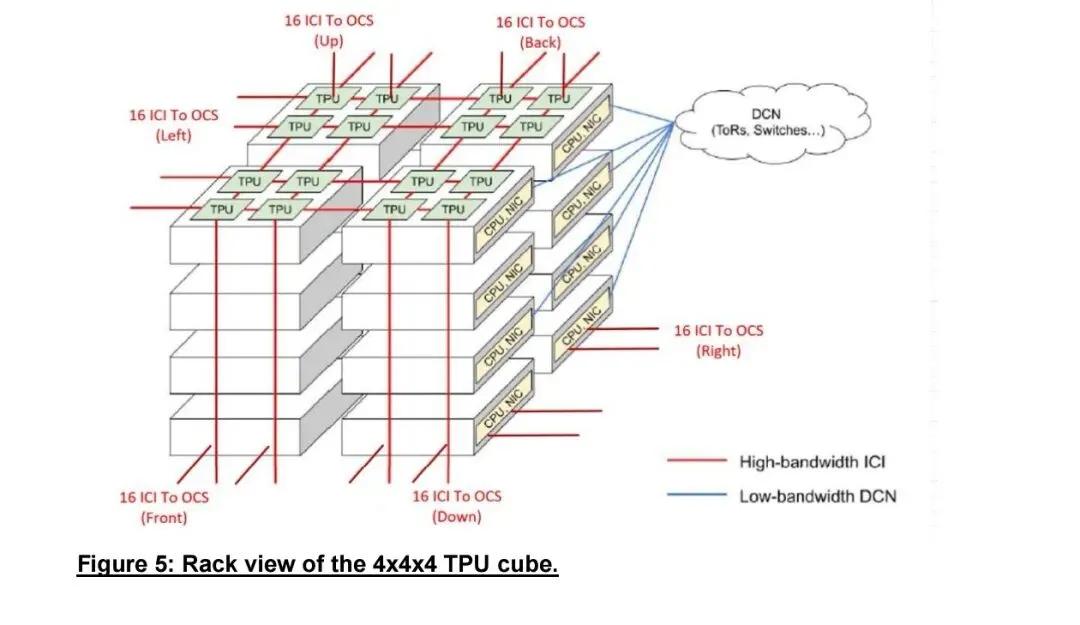
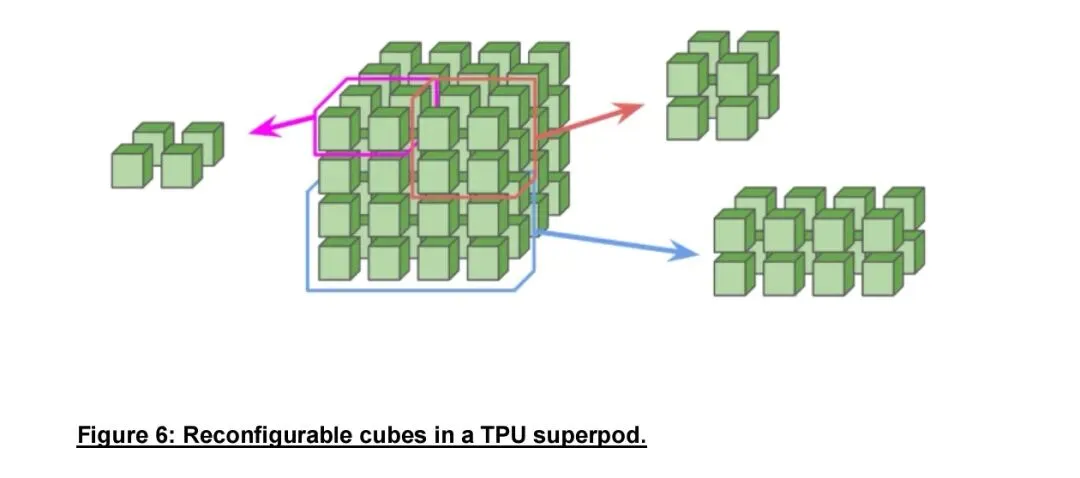
第二大核心场景是AI集群从静态到动态重构,已规模应用于Google TPUv4及后续超级集群。TPU以Cube为基本单元,每个Cube集成16台服务器、64颗TPU,64个Cube组成Superpod,共4096颗TPU。每个Cube通过三组共48台128端口MEMS-OCS与全局光交换网连接,由软件控制平面实现按任务动态重构。该架构带来三大收益:可根据作业通信模式构建环形等专用拓扑,大模型训练性能提升3.3倍,功耗降低9%;故障时可物理绕过失效Cube,同等可用性条件下有效吞吐量从25%提升至75%;支持集群逻辑隔离,多任务并行运行,资源利用率与安全性同步提升。
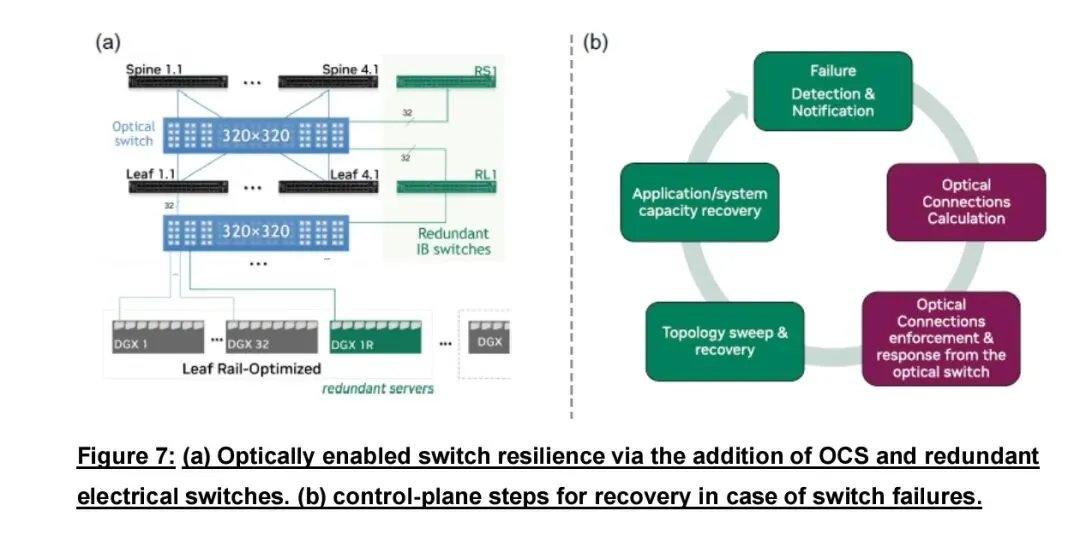
第三大场景是硬件故障物理层弹性自愈。AI集群规模扩张后,交换机、链路、光模块故障常态化,传统软件重路由难以恢复满性能,甚至引发任务中断。OCS将物理连接变为可编程资源,控制平面检测故障后自动重构光路,绕过故障节点,快速恢复目标拓扑与全带宽,任务无需重启、回滚 checkpoint或长期降频运行。该模式无需大量冗余备份资源,以共享备用光路池实现全网保护,在提升可用性的同时降低过度配置带来的成本与功耗。
四、OCS未来演进:五大前沿应用方向
白皮书明确指出,OCS的价值远未被完全释放,下一代创新将聚焦更动态、更精细、更贴近AI算力内核的场景。
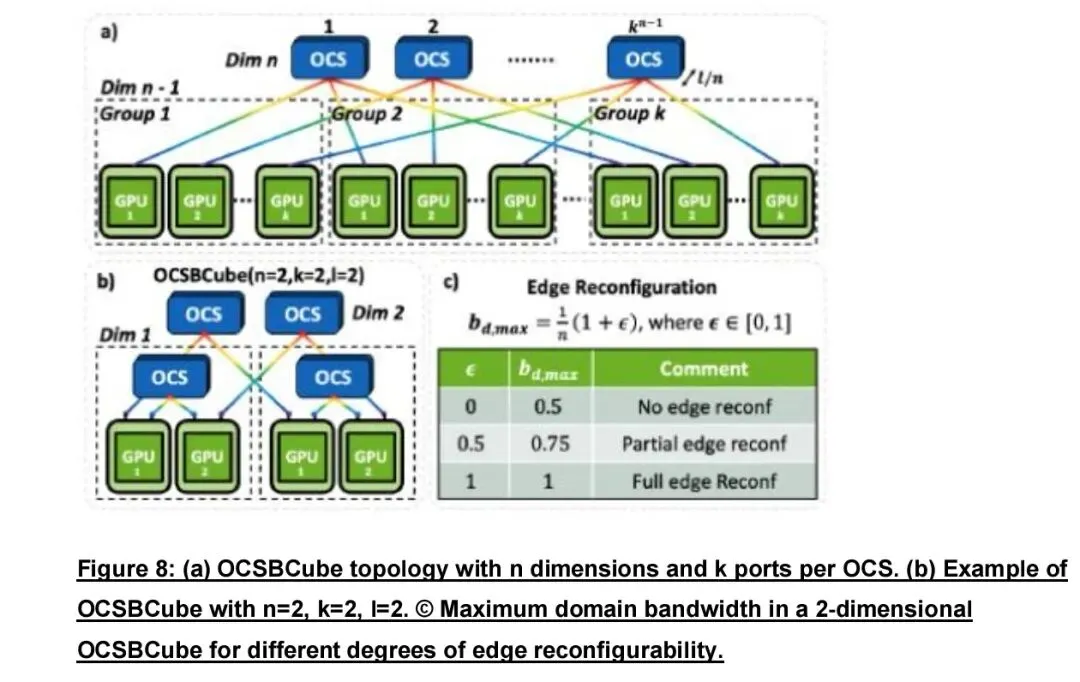
面向训练中动态集群实时重构,哥伦比亚大学与NVIDIA提出ACTINA架构,创新设计OCS-BCube光互联拓扑,完全移除电分组转发,在GPU端直接集成硅光子多端口可重构收发器,支持波长级动态分配与实时带宽调度,可在训练迭代内部完成精细光重构,缓解热点拥塞。实测相比3D Torus拓扑迭代速度提升最高1.84倍,能耗降低最高1.72倍,每焦耳算力效率提升1.75倍。
SC 25:哥伦比亚大学与 NVIDIA 联合提出 ACTINA框架,优化 OCS AI 网络性能与能效
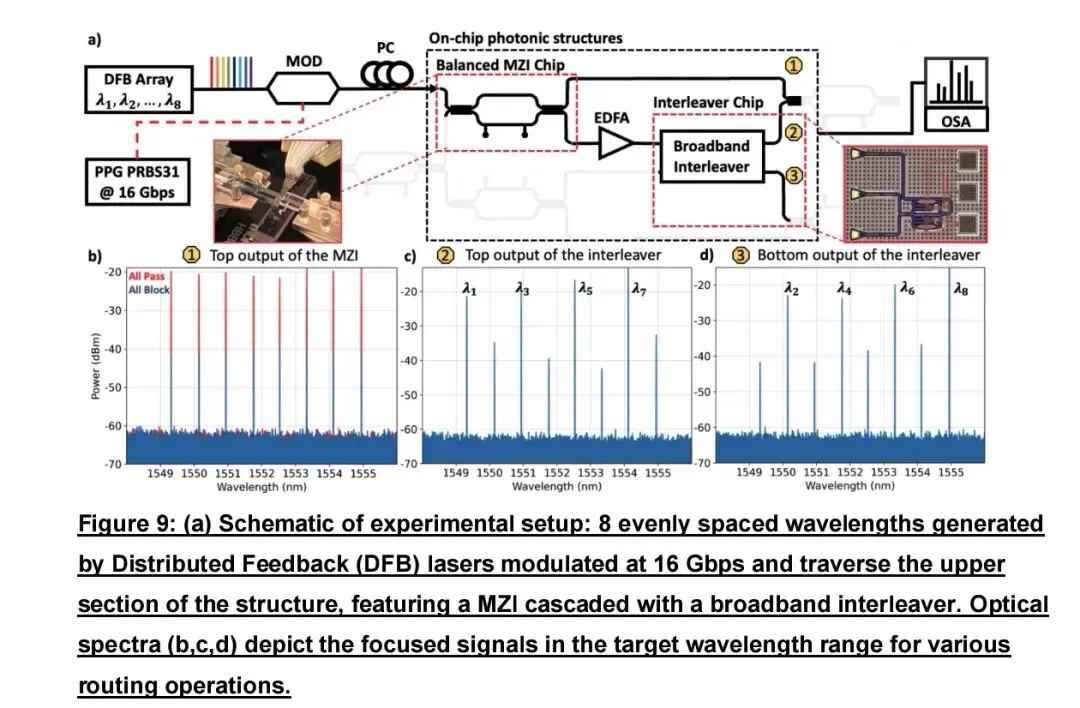
针对混合专家(MoE)模型训练优化,MixNet hybrid光电架构应运而生。MoE的专家并行(EP)通信量大、局部性强、迭代间变化平缓,MixNet用OCS构建区域光交换网,专门承载EP的动态全对全流量,数据并行与流水线并行流量仍走电分组网,在计算阶段提前完成光路径预配置,不阻塞通信阶段。实验显示,该方案可使MoE模型训练时间缩短1.6倍。
港科大MixNet入选SIGCOMM 2025:区域重构OCS光交换让MoE训练成本效率显著提升1.2-2.3倍
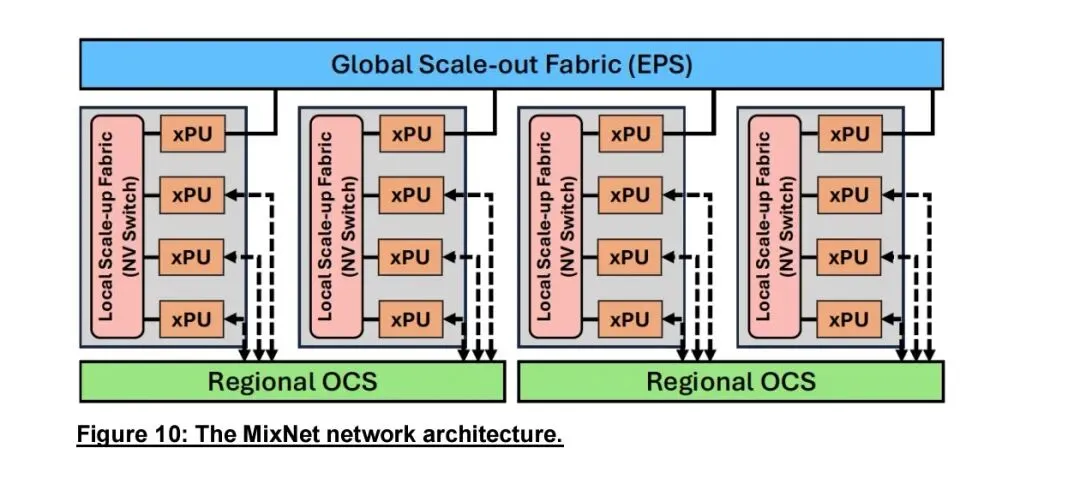
OCS也是量子网络的关键使能器件。量子态不可克隆、不可测量,传统电交换的光电转换会直接导致量子态坍缩,OCS全光透明传输可保持纠缠光子的相位、偏振等量子特性,支持量子隐形传态、纠缠分发与分布式量子计算,是量子互联网的底层交换基础。
在低抖动确定性时延领域,OCS为AI与高性能计算提供刚性保障。大规模同步操作对延迟波动极度敏感,电交换的缓存竞争会产生长尾延迟,拖慢全局聚合操作。OCS提供物理级独享光路,无转发、无竞争、时延高度恒定,彻底消除抖动,保障大规模集群协同性能稳定。
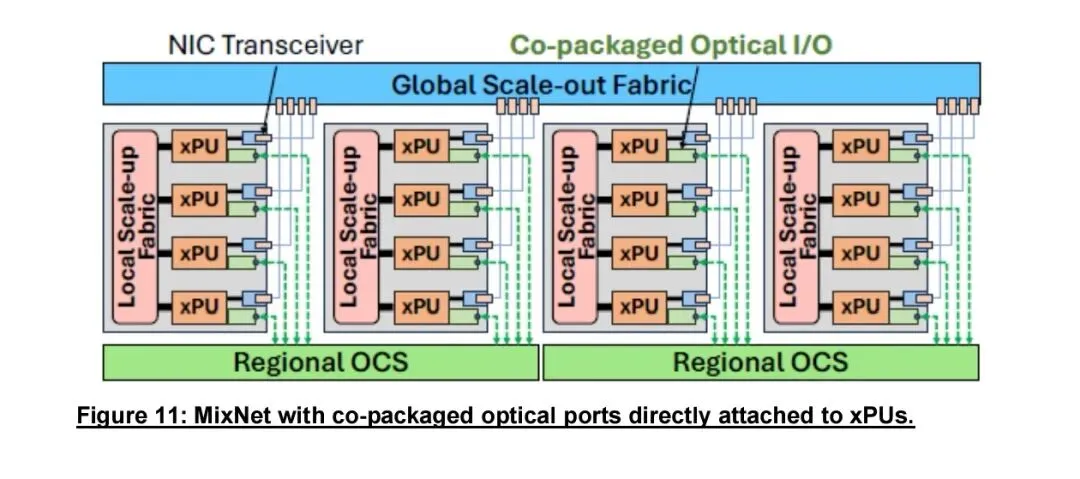
最后,OCS将支撑数据中心资源解聚落地。传统资源池化受限于电交换机端口密度与高速铜缆传输距离,多级跳传带来高时延与高功耗。OCS速率无关、可通过波分复用高效扩展带宽,无光电转换与队列延迟,可实现计算、存储、内存、加速卡的远距离、低时延、高效率解聚互联。
◆ 结语
2026年,光交换已完成从前沿技术到核心基础设施的蜕变,成为AI与超大规模数据中心的必选路线。以Google为代表的规模化部署验证了OCS在降功耗、减成本、提性能、增强韧性能方面的不可替代性。随着硅光子、超表面、混合集成等技术持续成熟,以及控制平面与编排系统不断完善,OCS将从骨干层、AI集群互联向更广泛的场景渗透,驱动下一代数据中心全面走向全光化、可编程化与高能效化。
在全球算力爆发式增长的趋势下,OCS不仅是网络架构的升级,更是支撑AI可持续发展的关键底座,其产业生态与规模化应用将进入高速扩张周期。