


一句话讲清楚?? 如果你让一个 Agent 通宵跑实验、改论文,第二天醒来最该问的不是“它写完了吗”,而是“它有没有把没证据的东西写得像真的”。上海交通大学开源的 ARIS ,解决的正是这个问题:一个模型负责推进想法、实验和写作,另一个不同模型家族的评审者负责挑错、追证据、要求返工。
这篇技术报告的标题是《 ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration 》。它讨论的不是又一个“端到端 AI 科学家”口号,而是一个更接近工程现场的问题:当 Coding Agent 已经能连续跑很多小时、能读论文、能改代码、能开实验、能写 LaTeX 时,我们到底该怎么约束它,才能不被一份漂亮但不可靠的研究报告骗过去?
论文给出的答案很硬:不要相信单个 Agent 长时间独立完成研究任务。 不是因为它一定会崩溃,而是因为它更危险的失败方式往往是“看起来成功”——实验跑了,图也画了,论文也生成了,但里面的数字、声明、引用和结论未必真的互相支撑。
ARIS 的核心价值就在这里:它把自主研究从“让一个 Agent 尽量聪明”改成“让一个研究系统尽量可追责”。这其实是 Coding Agent 进入科研场景后必须补的一课。
这篇论文真正关心的,不是“AI 会不会做科研”
过去两年,自动科研系统非常热。 AI Scientist 、 Agent Laboratory 、 data-to-paper 、 AI co-scientist 等工作都在尝试把文献调研、假设生成、实验和论文写作自动化。问题是,很多系统容易把重点放在“能不能一路跑通”。
ARIS 反过来问:一路跑通以后,谁来证明它没有骗你?
论文把这个风险叫作 plausible unsupported success ,可以理解成“貌似可信但缺乏证据支撑的成功”。这比普通失败更难处理。普通失败很明显:代码报错、训练中断、论文编译不过。但貌似成功不会提醒你,它会给出一个完整故事:某方法有效、某指标提升、某图证明了结论、某实验支持了主张。读者如果没有逐层追查,很容易把 Agent 的叙述当作事实。
在机器学习研究里,最危险的情况经常长这样:日志里确实有数字,图也画出来了,论文还写得很顺。但你往下一查,才发现提升来自一个临时评估脚本,正文里的结论根本没有对应实验文件。
更细一点看,常见坑包括:
ARIS 的判断是:如果 Agent 能做长周期任务,就必须同时建设“反作弊”和“追证据”机制。否则,自动科研只是在更快地产生需要人工排雷的内容。
一个保守但实用的假设:单 Agent 长任务默认不可靠
论文中有一句非常直白的系统假设:任何由单个 Agent 完成的长期任务都不可靠。
我更愿意把这句话理解成一个工程默认值:不是模型不聪明,而是只要任务链条足够长,早期一个小误读就可能滚成后面一整套看似合理的假结论。一个 Agent 从想法生成一路走到论文写作,中间的每一步都会影响下一步:早期文献理解错了,后面实验计划可能就错;实验指标没对齐,论文叙事可能就错;论文叙事一旦形成,后续自我评审又容易围着原叙事打补丁。
这也是为什么 ARIS 不把“自我反思”当作主安全机制。单模型自我评审的问题在于,生成者和评审者共享同一类归纳偏好,容易漏掉同一种盲点。 ARIS 推荐把执行者和评审者放在不同模型家族里:比如 Claude 系列负责执行, GPT 系列负责评审,或者反过来;也可以接入 Gemini 、 MiniMax 、 Kimi 、 DeepSeek 等 OpenAI-compatible 后端。
论文用了一个很形象的类比:单模型自评更像随机噪声下的优化,跨模型评审更像对抗环境。后者更难“糊弄”,因为评审者会主动寻找执行者没有预料到的弱点。
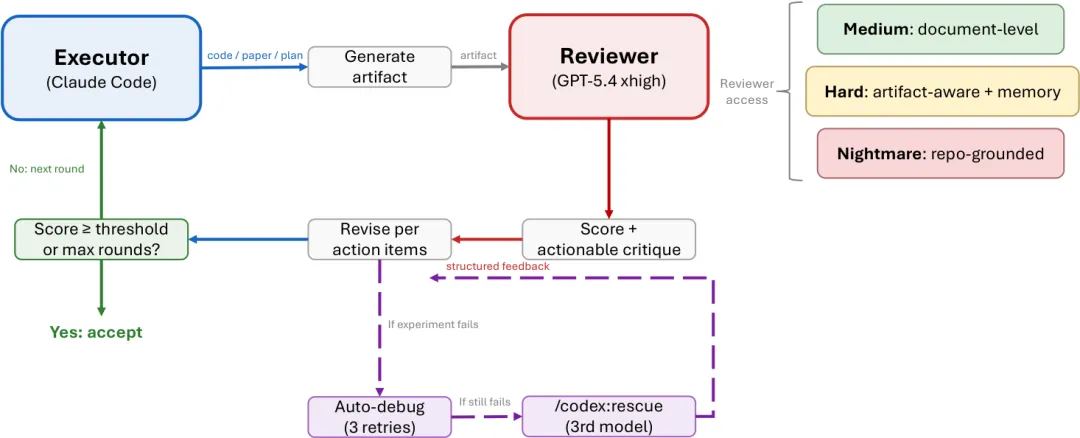
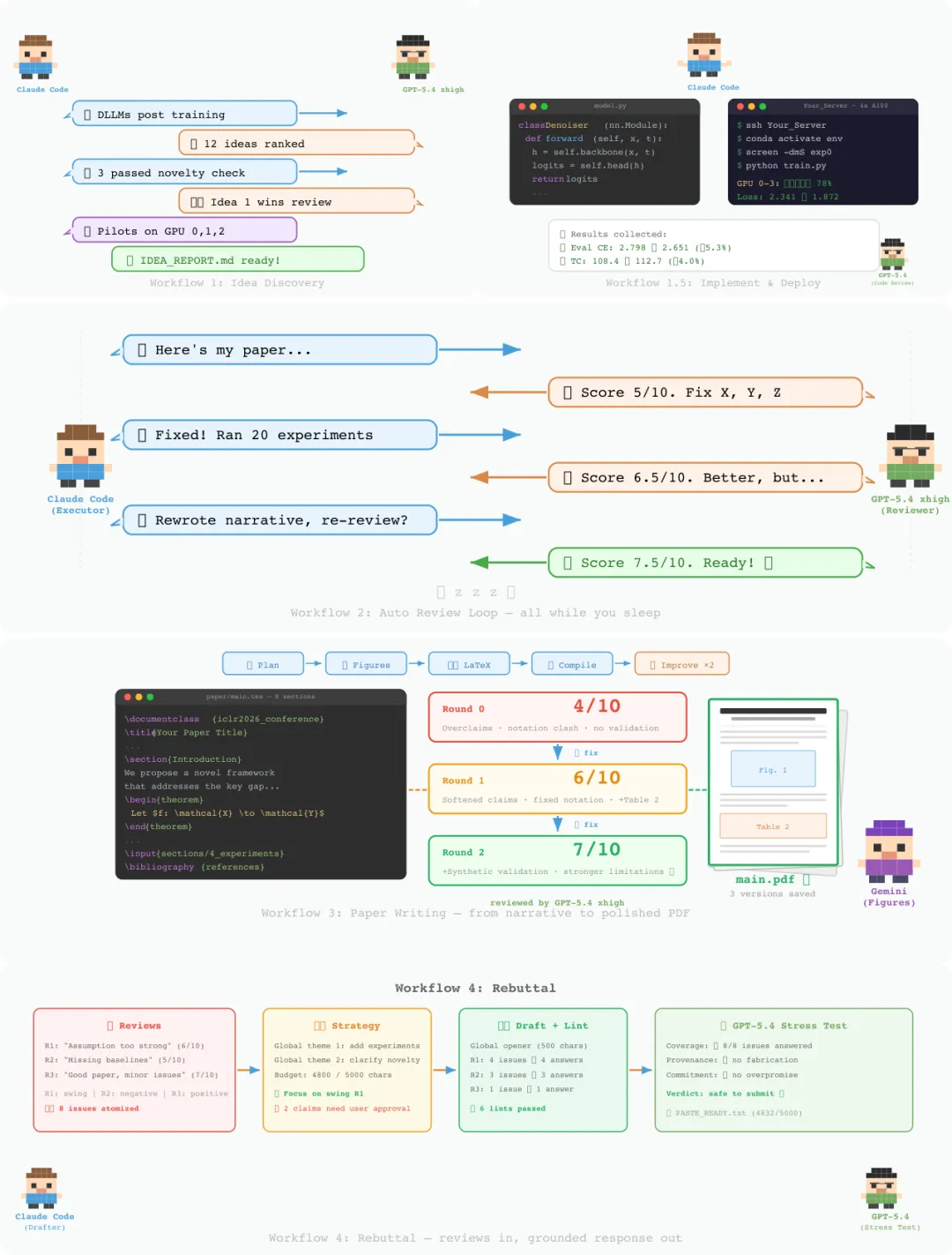
这里有个关键点: ARIS 并不是追求“多 Agent 越多越好”。它采用的是最小的两角色配置:执行者和评审者。这样既能打破自我评审盲点,又不会引入过高的协调成本。对于真实研究工作流来说,这个取舍比堆更多 Agent 更稳。
ARIS 的三层架构:执行、编排、保证
如果把 ARIS 看成一个科研工厂,它不是只雇了一个更聪明的工人,而是同时设计了工位、流程和质检线。对应到系统里,就是三层:执行层、编排层、保证层。
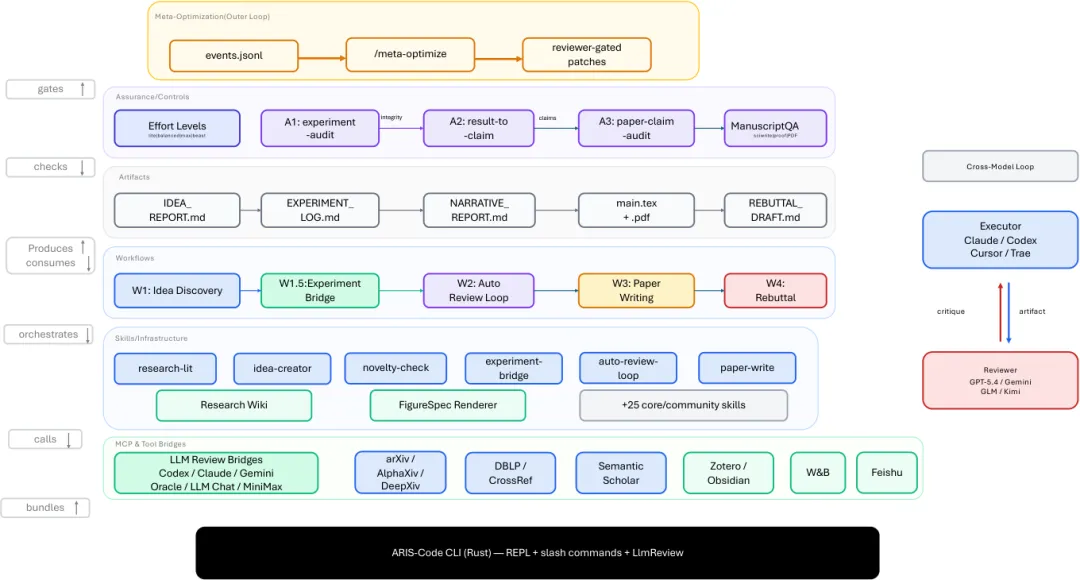
执行层: 提供 65 个以上 Markdown 定义的可复用技能,模型通过 MCP 桥接调用不同后端,研究过程中的论文、想法、实验和声明被写入持久化 research wiki 。 ARIS 还包含确定性图形生成能力,避免每次画系统图都靠模型自由发挥。
编排层: 负责把技能串成五条端到端工作流,并允许用户调节 effort level 。比如 lite 用于快速探索, balanced 是默认配置, max 和 beast 用于更深的检索、更高强度的评审和更多迭代。
保证层: 这是论文最值得看的一层。它包括三阶段证据到声明审计、五轮科学写作编辑、数学证明检查、 PDF 视觉检查和引用审计。它的目标不是让 Agent 写得更像论文,而是让论文中的每个重要声明都能回到证据链上。
从这个结构可以看出, ARIS 的核心不是“提示词大全”,而是 harness engineering :围绕模型搭一套状态、工具、权限、评审和恢复机制。模型权重当然重要,但在长周期任务里,外部 harness 决定了模型如何记忆、如何检查、如何返工、如何避免把错误带到下一轮。
五条工作流:从想法到 rebuttal
ARIS 把科研过程拆成五条工作流。这里最值得普通研究者先看的,不一定是“想法生成”,而是后面的自动评审和论文写作:真正决定论文能不能被信任的,往往不是点子多新,而是证据有没有被逐条拧紧。
| 阶段 | 输入 | 输出 | 关键能力 |
|---|---|---|---|
| 想法发现 | 研究方向 | 排名想法报告 | 文献、头脑风暴、新颖性检查 |
| 实验桥接 | 实验计划 | 可运行代码与结果 | 实现、代码审查、 GPU 部署 |
| 自动评审 | 草稿与结果 | 改进论文 | 多轮评审、修订、补实验 |
| 论文写作 | 叙事报告 | 编译 PDF | 大纲、图表、 LaTeX 、审计 |
| Rebuttal | 论文与评审 | 可粘贴回复 | 解析意见、安全门、压力测试 |
第一条工作流负责生成想法。它会做文献调查,生成多个候选方向,再通过独立评审者做新颖性检查和排名。第二条工作流把实验计划转成能跑的代码,先做代码审查和单 GPU sanity check ,再部署到完整后端。
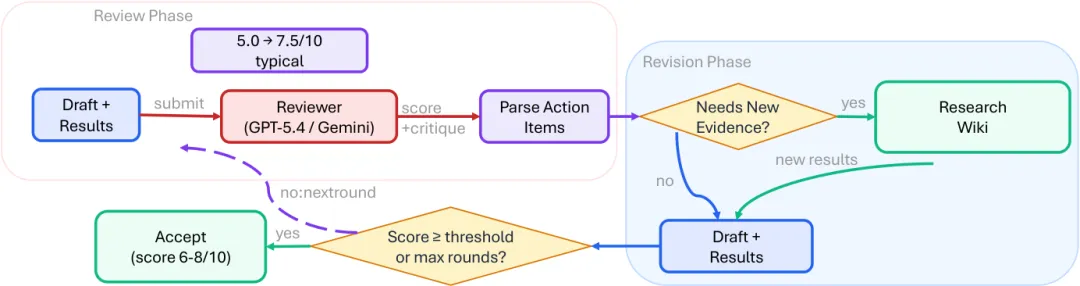
第三条工作流是自动评审循环,也是论文里最有代表性的部分。执行者把草稿和结果提交给评审者,评审者打分、指出问题、要求补实验或修改叙述。执行者完成修改后再送审。循环直到评分达到阈值,或者达到最大轮数。
第四条工作流负责论文写作。它不是简单地让模型“写一篇论文”,而是先做结构规划和 claims matrix ,再生成图表、写 LaTeX 、做五轮科学编辑、检查声明、编译 PDF ,并让评审者看源文件和最终 PDF 。
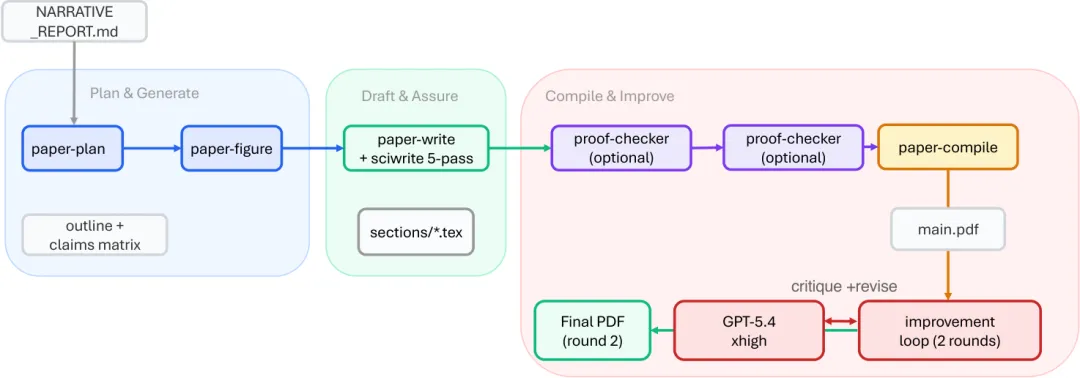
第五条工作流是 rebuttal 。系统会解析评审意见,拆成具体 concern ,制定回复策略,起草文本,并通过三道安全门检查:不能编造,不能过度承诺,必须覆盖所有关键问题。这个环节非常实用,因为 rebuttal 最怕的不是写得慢,而是为了安抚审稿人写出没有证据的承诺。
证据到声明审计: ARIS 最关键的安全网
如果只看“多模型协作”, ARIS 可能像一个常见的 Agent pipeline 。但它真正有价值的地方,是把 evidence-to-claim audit 做成了系统层机制。
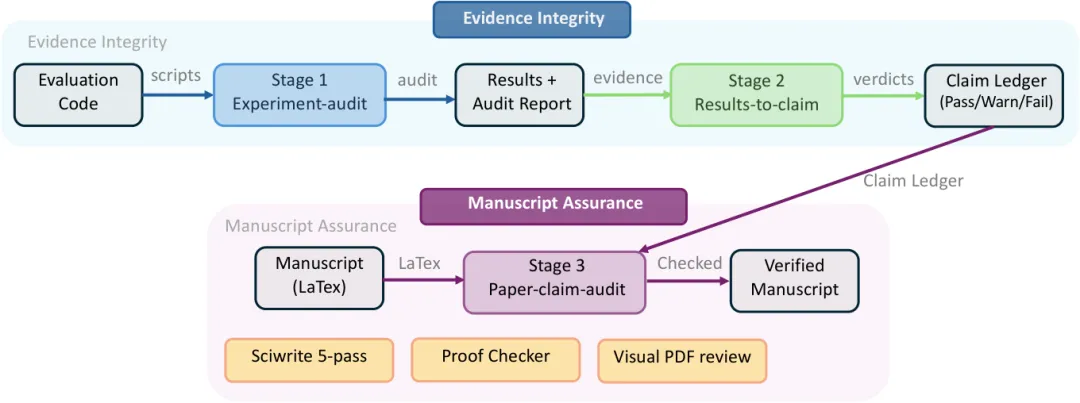
这个审计分三阶段。
第一阶段是实验完整性审计。 评审者读取评估代码和输出文件,检查模型派生标签、自归一化指标、幽灵结果、死代码指标、范围膨胀等问题。这里不只是看结果好不好,而是看结果有没有可能被评估方式“造”出来。
第二阶段是结果到声明映射。 系统把候选实验声明和已有证据对应起来,给每个声明标注 supported 、 partially supported 或 invalidated 。如果第一阶段已经发现完整性问题,对应声明不能被标成完全支持。
第三阶段是论文声明审计。 一个 fresh 、 zero-context 的评审者读取论文源文件、原始结果和配置文件,逐条检查正文里的定量声明。它会看数字是否匹配、是否只挑最好 seed 、配置是否一致、增量计算是否正确、是否缺少证据。
我觉得这个设计比“再让模型检查一遍论文”强很多。普通检查容易变成语言层面的润色, ARIS 则强迫系统回答一个更朴素的问题:你这句话从哪来的?
Research Wiki :让失败想法也成为资产
长周期科研还有一个常被忽略的问题: Agent 容易失忆。今天试过的失败方向,明天换个会话又重新提出来。人类研究者不会这么干,因为我们会记得“这条路走不通”。但普通 Agent 如果只依赖上下文窗口,很难形成这种跨会话判断。
ARIS 的 research wiki 用四类实体保存研究状态:论文、想法、实验和声明。它们以结构化 Markdown 页面保存,并通过 extends 、 contradicts 、 addresses_gap 、 inspired_by 、 tested_by 、 supports 、 invalidates 、 supersedes 等关系组成轻量知识图谱。
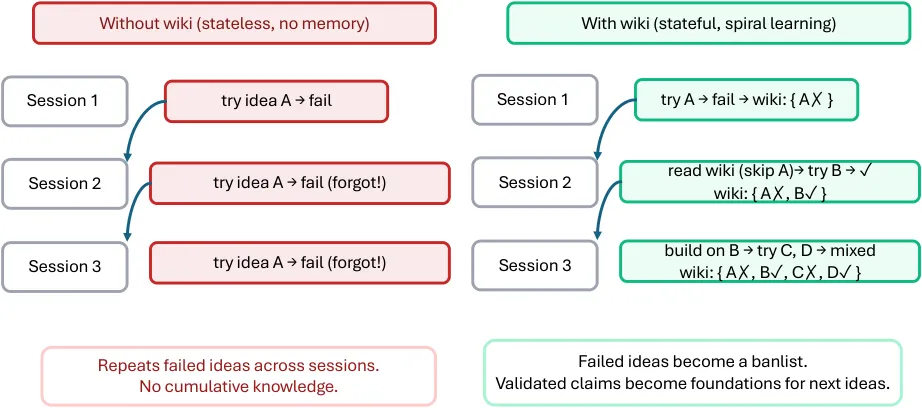
这件事对自动科研特别重要。真正的研究不是一次性 prompt ,而是螺旋式积累。失败实验、无效想法、被推翻的 claim ,都是下一次决策的重要输入。 ARIS 选择把这些状态写成可版本化的文本文件,而不是藏在某个数据库或会话状态里,这也让它更容易被不同 Coding Agent 复用。
为什么它强调 Markdown 技能,而不是封闭平台
ARIS 的技能层由 Markdown 文件定义。每个 SKILL.md 写清楚输入、输出、步骤、质量门槛和失败处理。论文强调这个选择是为了可移植性:同一套技能可以在 Claude Code 、 Codex CLI 、 Cursor 等环境中使用,不必绑定某个封闭平台。
这点和很多“Agent 平台”思路不同。平台方案通常提供完整运行时,优点是集成度高,缺点是迁移成本高。 ARIS 更像一种研究工作流规范:用普通文本描述技能,用文件系统保存状态,用不同模型桥接做执行和评审。
当前实现里,论文报告了这些规模信息:
| 维度 | 当前状态 |
|---|---|
| 技能 | 65 个以上 Markdown 技能 |
| 工作流 | 5 条端到端工作流 |
| 模型桥接 | 6 类 MCP 桥接 |
| 执行环境 | 3 个已测试, 3 个已适配 |
| 记忆 | 每项目 research wiki |
| 强度预设 | lite 、 balanced 、 max 、 beast |
这让 ARIS 更像给 Coding Agent 配了一套“科研操作系统”。你可以不使用它的全部工具,但它提出的几个约束很值得借鉴:技能要可读,产物要可追踪,评审要独立,证据要能回查。
早期部署证据:一个夜间运行从 5.0 到 7.5
论文没有声称 ARIS 已经证明自己比所有系统更强。它提供的是早期部署经验,而且明确说这些结果是观察性的,不能直接归因于 ARIS 。
最具体的案例是一个约 8 小时的夜间运行。系统完成了四轮 review-revise 循环,内部评审分数从 5.0 提升到 7.5 ,期间启动了 20 次以上 GPU 实验,并删除了一些缺乏证据支持的声明。
所以标题里的“5 分到 7.5 分”最好别理解成性能广告。真正有意思的是,这 2.5 分不是靠把摘要写得更漂亮拿到的,而是靠删掉不稳声明、补跑实验、重新对齐证据链换来的。换句话说, ARIS 想优化的不是文风,而是证据纪律。
论文也很克制地指出,这不是因果证明。交叉模型评审是否真的优于同模型评审,还需要 compute-matched benchmark 。附录提出了一个未来评估协议:用公开预印本草稿构建任务池,对比单模型自评、同模型双 Agent 、跨模型、反向跨模型等条件,再用盲审者评估 issue recall 、 false positive 、 actionability 、修订质量、成本和延迟。
这种克制反而增加了可信度。自动科研系统最怕把 demo 当科学结论, ARIS 至少知道自己还需要被验证。
和已有系统相比, ARIS 的差异在哪
论文把 ARIS 和 AI Scientist 、 AI Scientist-v2 、 Agent Laboratory 、 data-to-paper 、 AutoGen 、 MetaGPT 、 OpenHands 等系统做了功能层面对比。为了适合手机阅读,我把核心差异压缩成下面这张小表。
| 系统 | 跨模型评审 | 组合技能 | 保证栈 |
|---|---|---|---|
| AI Scientist | 无 | 否 | 部分 |
| Agent Laboratory | 无 | 否 | 否 |
| data-to-paper | 无 | 否 | 部分 |
| AutoGen | 无 | 部分 | 否 |
| ARIS | 默认 | 是 | 是 |
这张表不能理解为“ARIS 全面优于这些系统”。它比较的是特性,不是最终科研质量。 ARIS 的独特点在于把“跨模型评审、组合式技能、端到端科研、保证栈、跨平台可移植”同时放进一个工程系统里。
我的理解是, ARIS 不像传统意义上的 Agent framework ,也不像单篇自动论文生成器。它更像一个面向研究任务的 harness :它承认模型会犯错、会偷懒、会过度叙事,所以从系统设计上给模型上锁、留痕、追证据、找人挑错。
真实使用时,我会重点关注三件事
我最担心的一点是:很多团队会学 ARIS 的多 Agent 外壳,却没学到它真正严格的地方——评审者必须直接读原始产物,而不是听执行者复述。否则所谓评审只是换一个模型继续讲故事。论文明确要求评审者读取被引用产物,这个原则应该成为所有 Coding Agent 审查流程的默认规则。
第二件事是 research wiki 。它不能只存成功结果。失败方向、被证伪想法、无效实验同样重要。很多团队做 Agent 记忆时喜欢存“有用结论”,但科研里最有用的经常是“别再试这个”。这类负结果如果不进入长期记忆, Agent 会反复浪费算力。
第三件事是审计不能只看论文文本。论文写得顺不顺和结论对不对是两件事。 ARIS 的三阶段审计把代码、结果、 claim ledger 、正文声明拉到同一条证据链上,这是它最值得复用的设计。
当然,它也有明显限制。
第一,不能保证正确。 跨模型评审能减少一些错误,但不是形式化验证。模型仍然可能一起漏掉关键问题。
第二,可能放大评审者偏好。 如果评审模型持续偏好某种方法或写法,执行者可能过拟合评审者,而不是提升真实科学质量。
第三,隐私和安全要认真处理。 Repository-level review 可能把源代码、实验结果、配置文件发给外部模型 API 。涉及敏感代码或未公开研究时,必须限制评审访问范围,或者等待本地评审路由成熟。
第四,目前缺少受控评测。 论文给的是部署观察和设计论证,还不是严格 benchmark 结果。把它用于真实科研流程时,仍然需要人工负责最终判断。
对 Coding Agent 生态的启发
ARIS 这篇技术报告有一个很现实的信号: Coding Agent 的竞争正在从“模型能不能完成任务”转向“系统能不能管理长期任务”。
短任务靠模型能力,长任务靠 harness 。尤其是科研、工程重构、数据分析这类链路长、证据多、责任重的任务,单纯提升模型上下文和推理能力还不够。系统必须知道哪些信息要保存,哪些产物要审计,哪些声明需要证据,什么时候需要第三方评审,失败后如何恢复。
如果把 ARIS 的思路迁移到普通研发团队,我会建议先落地五个轻量规则:
这些规则不需要完整复刻 ARIS ,也能显著提高 Agent 工作流的可靠性。
最后说说我的判断
ARIS 最吸引我的地方,不是“睡觉时 AI 自动写论文”这个宣传点,而是它承认自动科研的主要风险不是做不出来,而是做出来的东西像真的。
这其实比很多宏大的 AI 科学家叙事更成熟。科研不是把文本和图表拼成论文,而是让声明、证据和方法彼此咬合。 ARIS 的跨模型对抗协作、证据到声明审计、 research wiki 和 Markdown 技能体系,都是在把这种咬合关系工程化。
它还没有证明自己是最优解,但它提出了一个很好的方向:未来的强 Agent 不是一个孤立的大模型,而是一套能持续记录、独立质疑、追踪证据、及时返工的系统。
如果你已经在用 Coding Agent 做论文、实验或长周期工程任务,这篇论文值得读。它不会告诉你“AI 科学家已经来了”,但会提醒你:如果没有审计和证据链,你得到的可能只是更快、更完整、更难发现问题的幻觉。
资源链接
? 论文链接
https://arxiv.org/abs/2605.03042
? 代码仓库
https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep