超节点行业分析报告:正在成为新一代人工智能基础设施的关键形态
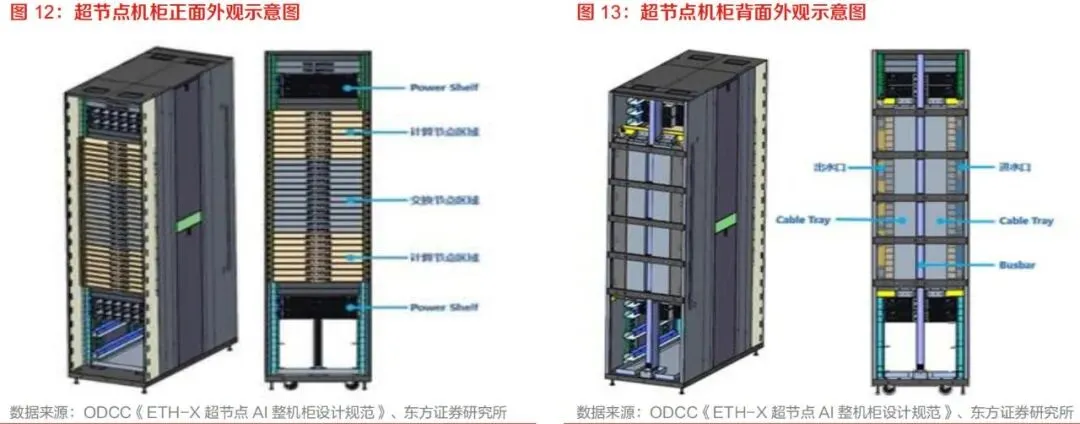
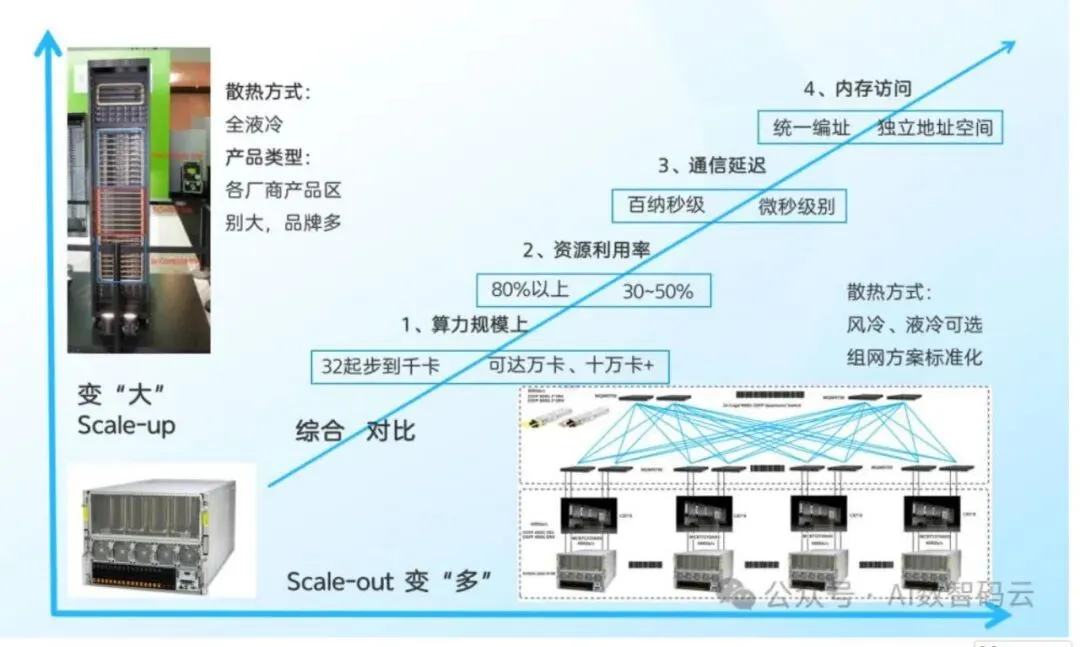
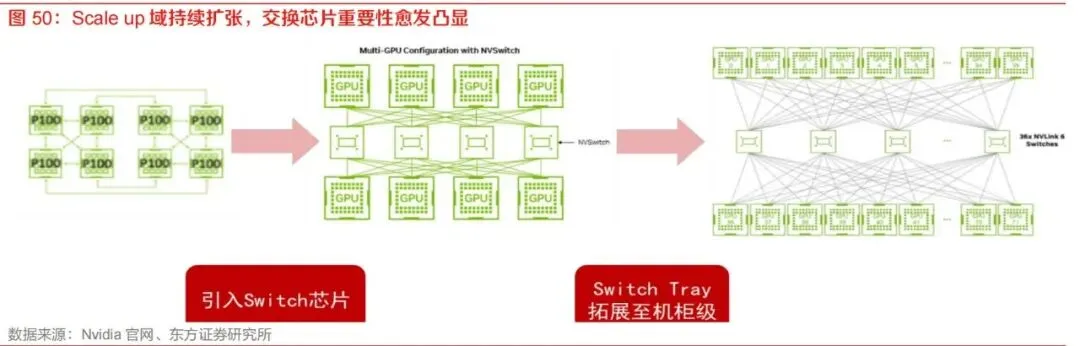
超节点正在成为新一代人工智能基础设施的关键形态,其本质并非简单地将传统八卡服务器扩展为更多算力卡的"堆叠",而是围绕大模型训练与推理中的通信墙、内存墙、能耗墙和集群效率衰减问题,对计算、互联、内存、供电、散热、整机柜交付和数据中心架构进行系统性重构。随着大模型从稠密架构走向MoE稀疏架构,从文本生成走向多模态、长上下文、复杂推理和智能体任务,单卡、单机、传统八卡服务器已难以满足高频All-to-All、All-Reduce、KV Cache共享、专家并行和张量并行需求。超节点通过在机柜内或多机柜间构建高带宽域,使数十、数百乃至上千颗AI加速芯片在逻辑上形成统一协同计算单元,成为大规模算力集群向十万卡、百万卡演进的基础模块。从产业视角看,超节点是国产算力体系突破单卡性能短板的重要路径。海外领先芯片厂商在先进制程、HBM带宽、互联协议和软硬件生态方面仍具优势,但国产AI芯片可通过更大规模的Scale up域、更开放的互联协议、更强的整机柜系统工程能力以及本土云厂商需求牵引,实现"以系统性能弥补单点性能差距"。在国产AI基础设施自主可控诉求增强、云厂商和运营商加大智算投入、开放互联协议逐步成熟的背景下,超节点有望成为国产算力产业链从单品竞争走向系统竞争的核心抓手。从投资和产业链配置角度看,超节点将带来五类显著增量:第一,Scale up网络扩大带动交换芯片、交换节点和高性能交换机需求提升;第二,计算节点与交换节点之间的高速互联催生铜缆、连接器、PCB背板、正交背板、光互连和OCS等环节需求;第三,单机柜功耗跃升使液冷从可选方案变成刚性配置,并推动冷板、快接头、Manifold、CDU、液冷工质和整机柜液冷系统放量;第四,服务器ODM从传统L10单机交付提升至L11/L12整机柜、多机柜系统交付,价值量和行业壁垒同步提升;第五,机柜功率从几十千瓦提升至百千瓦乃至兆瓦级,推动集中供电、Power Shelf、Busbar、PSU、HVDC、SST、BBU和高压直流配电体系升级。超节点行业处于从技术验证走向规模化放量的早期阶段。2024年至2025年是超节点标准、协议、样机和生态形成期,海外以NVLink、UALink、SUE、Infinity Fabric、TPU ICI等方案为代表,国内以华为灵衢UB、中国移动OISA、阿里ALS/磐久、字节EthLink、ETH+、海光HSL、腾讯ETH-X等体系为代表,开始形成多元化技术路线。2026年有望成为国产超节点放量元年,运营商、互联网大厂、国产AI芯片企业、服务器厂商和数据中心基础设施厂商将共同推动产业从"单点产品导入"进入"系统级批量交付"。行业的竞争焦点将从过去单一GPU性能、单机服务器成本和传统网络带宽,逐步转向"芯片—互联—系统—软件—数据中心"协同能力。具备完整系统工程能力、协议适配能力、整机柜热电结构设计能力、供应链整合能力和大客户绑定能力的企业,将获得更强竞争优势。对于国产厂商而言,超节点不仅是AI服务器形态升级,也是国产算力生态从分散适配向标准化、规模化、平台化演进的重要机会。超节点是指通过高速互联协议、专用交换芯片、统一内存语义和整机柜级系统设计,将多颗AI加速芯片、CPU、内存、网络、存储、供电与散热组件整合为一个高带宽、低时延、可协同调度的计算单元。其核心目标是突破传统服务器以单机八卡为主要单元的限制,使更大数量的XPU在同一高带宽域内共享计算和访存能力,从而提升大模型训练和推理效率。超节点并不是传统服务器数量的线性增加,而是基础设施架构的变化。传统AI集群通常以八卡服务器为基本节点,通过以太网、InfiniBand或RoCE构建Scale out网络;超节点则强调在更大的单元内部构建Scale up网络,把原本跨服务器的高频通信尽可能压缩到低延迟、高带宽、可内存语义访问的域内完成。其价值不只体现在峰值算力增加,更体现在模型并行效率、通信效率、显存利用效率、推理吞吐和能效比提升。传统八卡服务器以单机内部互联为主,适用于较小规模模型或以数据并行为主的训练任务。当模型参数规模、上下文长度、专家数量和并发推理需求提升后,模型并行和专家并行产生大量跨服务器通信,传统网络在带宽、时延和拥塞控制方面逐渐成为瓶颈。超节点通过引入机柜内交换节点、专用互联背板、高速连接器和统一互联协议,将多个计算节点整合为一个更大的逻辑计算系统。在交付形态上,传统服务器更多是单机交付,机柜、供电和制冷由数据中心侧完成集成;超节点强调整机柜交付甚至多机柜级交付,服务器厂商需要同时负责计算托盘、交换托盘、供电框、液冷管路、背板互联、线缆管理和系统测试。这使得服务器产业链价值从组装制造向系统设计与工程集成迁移。在软件与生态层面,传统服务器主要依赖标准PCIe、以太网、InfiniBand、RoCE等协议;超节点则需要更紧密的硬件与软件协同,包括内存语义互联、集合通信硬件加速、拓扑感知调度、故障隔离、统一管理和大模型框架适配。未来超节点竞争将不仅是硬件规格竞争,更是软硬一体系统效率竞争。本报告重点研究超节点在AI基础设施中的产业定位、技术演进、网络架构、产业链变化、国产替代机会、竞争格局、成本结构和风险因素。研究对象包括超节点整机柜、分机柜超节点、Matrix/级联超节点,以及相关的Scale up互联协议、交换芯片、服务器ODM、液冷、供电、PCB背板、铜缆连接器、光互连和数据中心配套设施。AI大模型的能力提升长期遵循算力、数据和参数规模共同扩张的逻辑。早期深度学习模型以计算机视觉和推荐模型为主,参数规模相对有限,单卡或单机即可完成训练。随着Transformer架构成为基础模型主流,模型从十亿、百亿参数扩展到千亿、万亿参数,训练任务逐步从单机走向多机,从单模态走向多模态,从短文本理解走向长上下文推理和复杂任务执行。近年来,Scaling Law的影响范围从预训练扩展到后训练和推理阶段。大模型不仅在预训练中消耗巨大算力,在强化学习、人类反馈对齐、长思维链推理、多轮工具调用和智能体任务中也持续消耗计算资源。尤其是推理侧,模型不再只是一次性生成答案,而是通过搜索、规划、调用工具、编写代码、执行验证、自我修正等步骤完成复杂任务,每一步都消耗Token和算力,推理需求成为AI基础设施扩容的新驱动力。在这种趋势下,单卡性能提升虽仍重要,但系统扩展效率变得更加关键。若算力卡数量增加而通信效率下降,实际可用算力会被通信开销吞噬,模型训练时间和推理成本难以下降。超节点正是在这一背景下出现,其核心价值是把更多算力卡纳入高带宽、低时延、可协同调度的域内,使系统实际有效算力接近理论峰值。3.2 MoE架构提高对Scale up网络的要求MoE,即混合专家模型,是大模型降低推理成本、提升参数容量的重要方向。与稠密模型每次前向计算都激活全部参数不同,MoE模型包含多个专家网络,每个Token根据路由机制只激活部分专家,从而在扩大总参数规模的同时控制单次计算量。MoE架构适合构建更大模型,也更适应多任务、多模态和复杂推理场景。但MoE的优势伴随着更高通信复杂度。专家并行要求不同GPU或不同节点之间频繁进行Token分发和结果回传,All-to-All通信成为训练和推理中的重要瓶颈。随着专家数量增加,跨节点通信频次和带宽需求显著提升。若仍依赖传统Scale out网络完成高频专家路由,通信时延和网络拥塞会降低GPU利用率,使昂贵算力资源长时间等待数据。超节点通过扩大高带宽域,使更多专家和更多并行维度能够在低延迟域内完成交互,从而提升MoE模型训练和推理效率。对于张量并行、专家并行、序列并行等通信密集型任务,超节点能够减少跨服务器通信对性能的拖累,并通过统一内存语义和集合通信优化提高系统吞吐。过去市场对AI基础设施的关注更多集中在训练侧,认为大模型训练是最主要算力消耗来源。但随着AI应用落地,推理侧的算力需求正在快速增长。长上下文、多模态、智能体和实时交互应用对推理系统提出更高要求:一方面需要更高并发和更低延迟,另一方面需要更大的KV Cache容量和更强内存带宽。在大语言模型推理中,Prefill阶段偏计算密集,Decode阶段偏访存密集。随着上下文长度提升,KV Cache存储和访问成为关键瓶颈。传统单机显存容量有限,无法高效承载超长上下文、多用户并发和复杂智能体任务。超节点通过更大规模的显存池化、更高带宽互联和更灵活的PD分离、AE分离等架构优化,有助于缓解推理中的内存墙问题。推理场景的另一个重要变化是能效比成为核心指标。云厂商和企业客户不仅关注单卡峰值算力,也关注每瓦Token生成能力、单位Token成本、机柜部署密度和数据中心总拥有成本。超节点通过提升系统协同效率和降低通信开销,有望在大规模推理场景中实现更优单位能耗产出。3.4 百万卡集群需要Scale up与Scale out协同算力集群扩展存在两个基本方向:Scale up和Scale out。Scale out是横向扩展,通过网络连接更多服务器或更多超节点,形成大规模集群;Scale up是纵向扩展,在单服务器、单机柜或多机柜内构建更大高带宽域,提升域内协同计算能力。过去AI集群主要依靠Scale out扩展,未来在MoE和大模型高频通信需求下,Scale up的重要性显著提升。在十万卡、百万卡集群中,若每张卡都通过传统网络进行频繁通信,网络复杂度、拥塞风险、故障率和调度难度都会急剧上升。更合理的架构是先通过超节点形成高效的基础计算单元,再将多个超节点通过Scale out网络连接起来。这样可将最频繁、最敏感的通信限制在超节点内部,把跨超节点通信更多用于数据并行、流水并行等相对可容忍时延的任务。因此,超节点是未来大规模AI集群的"地基"。它既能提升单个计算单元的效率,也能降低上层集群组网难度。对于国产算力集群而言,构建更大规模、更高效率的超节点,是实现自主AI基础设施规模化部署的重要前提。典型超节点机柜由计算节点、交换节点、ToR交换机、供电单元、供电母线、线缆或背板互联、液冷系统和管理系统组成。计算节点通常包含AI加速芯片、CPU、PCIe Switch、内存、存储、DPU/NIC等部件,是算力承载主体;交换节点负责连接多个计算节点中的XPU,提供Scale up域内高速互联;供电系统负责将机房级电力转换为机柜级和节点级稳定供电;液冷系统负责解决高密度算力带来的散热问题。计算节点与交换节点之间的连接方式直接影响超节点性能。常见方式包括高速铜缆、Cable tray、正交背板、零背板、光纤互联和铜光混合互联。短距离、高密度、低成本场景下铜缆和背板具备优势;当互联规模扩大到多机柜甚至千卡级时,光互联和OCS的重要性提升。超节点还需要统一管理系统,对计算、网络、供电、散热、故障状态和拓扑资源进行监控与调度。随着机柜功耗和互联复杂度提高,单点故障对系统可用性影响更大,管理系统需要具备故障隔离、链路重构、拓扑感知和自动化运维能力。从物理形态看,超节点可分为整机柜超节点、分机柜超节点和Matrix/级联超节点。- 整机柜超节点将计算节点和交换节点集成在同一个机柜内,具备高度集成、低延迟和系统化交付优势,典型产品包括NVL72、国产64卡或128卡机柜方案等。这类方案适合对低时延、高带宽、统一供电和液冷要求较高的场景,但设计难度和供应链门槛也较高。
- 分机柜超节点将计算节点和交换节点分布在不同机柜或标准化设备中,通过铜缆或光纤互联实现Scale up。其优势是硬件标准化程度较高,扩展和维护相对灵活,适合运营商、云厂商和多芯片生态共存场景。但相较整机柜方案,布线、时延、功耗和系统集成复杂度更高。
- Matrix/级联超节点是在多个整机柜或分机柜超节点基础上进一步扩展,通过二级或多级高带宽域实现百卡、千卡乃至更大规模互联。该形态是未来超大规模集群的重要方向,但对拓扑设计、交换芯片容量、光互连、故障管理和系统调度提出更高要求。
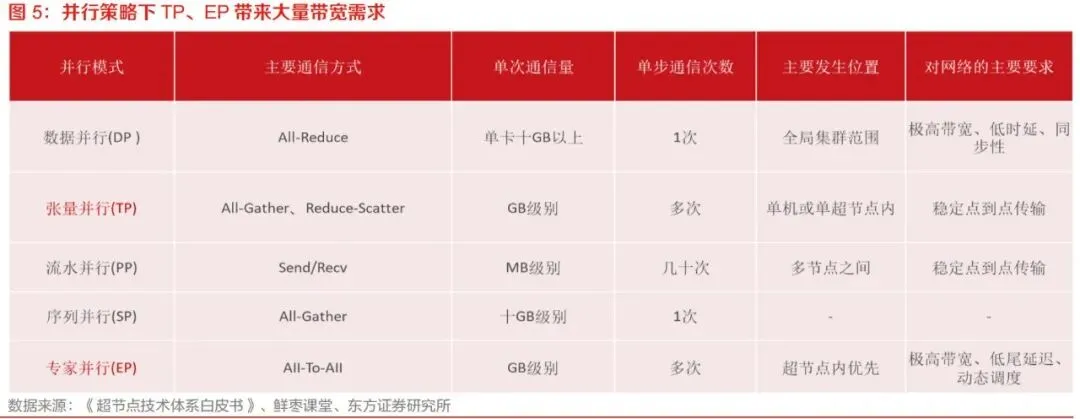
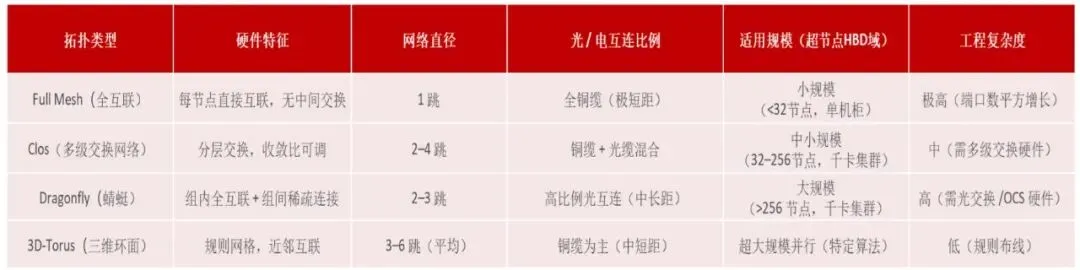
超节点网络架构主要包括Clos、Full-Mesh、Torus、Dragonfly和Dragonfly+等路线。- Clos架构具备较好的全局带宽和无阻塞通信能力,是当前高性能AI互联中的主流方案之一。其通过交换层级实现多个计算节点之间的高带宽互联,适合All-to-All和All-Reduce等通信模式。缺点是交换层级增加会提升成本、功耗和复杂度,扩展到更大规模时对交换芯片容量要求较高。
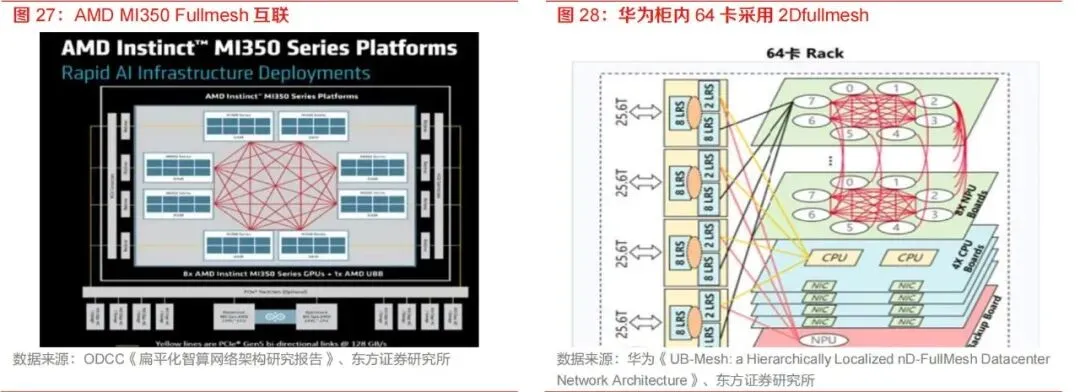
- Full-Mesh架构中各节点之间直接互联,短距离通信效率高,适合较小规模或二维、三维扩展场景。其优点是结构直观、时延低,但随着节点数量增加,链路数量迅速增长,布线和端口资源成为瓶颈。因此,Full-Mesh更适合结合层级化设计或局部化拓扑使用。
- Torus架构常见于TPU等自研芯片体系,通过二维或三维网格连接邻近节点,具备较好的扩展性和故障隔离能力。其相邻通信效率较高,但全局通信性能受限于跨截面链路数量,面对大规模All-to-All通信时可能不如胖树或Clos架构。
- Dragonfly和Dragonfly+强调通过组内高带宽互联和组间稀疏全局链路实现低网络直径和较高成本效率。该架构在超算场景已有较多应用,适合大规模集群,但对路由、流量调度和拥塞控制要求较高。未来在超大规模超节点互联中,Dragonfly+可能成为性能与成本之间的重要折中方案。
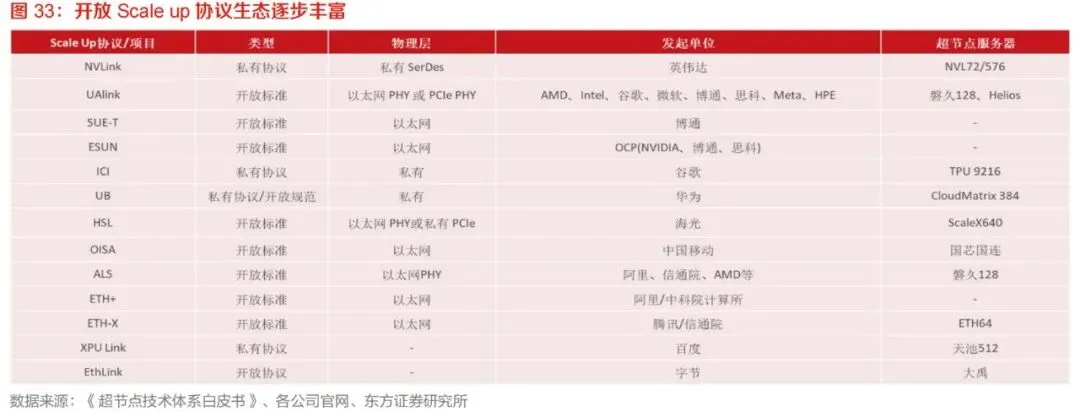
Scale up协议决定XPU之间如何进行高速通信、内存访问、同步和集合通信。过去高性能互联协议相对封闭,典型如NVLink、Infinity Fabric等厂商自有体系。这些协议在性能上具备优势,但生态绑定较强,限制了第三方芯片、服务器和云厂商的灵活组合。随着超节点成为AI基础设施关键形态,产业开始推动开放Scale up协议。UALink、SUE、OISA、ALS、ETH+、EthLink等方案均体现了以开放标准降低生态锁定、增强多芯片互联能力的趋势。开放化协议有助于国产AI芯片、国产交换芯片、国产服务器和云厂商形成统一生态,避免每家企业重复建设私有协议带来的碎片化问题。开放协议的挑战在于性能、兼容性和成熟度。Scale up网络要求极低时延、高带宽、内存语义支持和高可靠性,普通以太网协议难以直接满足,需要在链路层、传输层、报文格式、拥塞控制和集合通信加速方面进行深度优化。因此,未来开放协议能否成功,不仅取决于联盟成员数量,也取决于是否能在真实大模型训练和推理场景中达到商业化性能要求。超节点产业链可分为上游核心硬件、中游整机柜系统和下游应用客户三大环节。- 上游包括AI加速芯片、CPU、HBM、交换芯片、PCIe Switch、DPU/NIC、PCB、连接器、铜缆、光模块、硅光芯片、电源器件、SiC/GaN功率器件、液冷零部件等。该环节决定超节点的性能上限和成本结构,技术壁垒高、国产替代空间大。
- 中游包括服务器ODM/OEM、整机柜集成商、网络设备厂商、液冷系统厂商、供电系统厂商和数据中心基础设施厂商。中游企业负责将上游部件集成为可交付、可运维、可规模部署的超节点系统,是超节点产业化落地的关键。随着交付从单机走向整机柜,中游价值量显著提升。
- 下游客户主要包括互联网云厂商、运营商、AI大模型公司、金融机构、科研机构、政府智算中心和大型企业私有化部署客户。下游需求决定超节点放量节奏。当前国内需求主要由运营商智算集群、互联网大厂自研AI Infra、国产大模型训练推理和地方智算中心建设驱动。
AI加速芯片是超节点最核心的价值环节。海外以NVIDIA、AMD、Google TPU等为代表,国内则包括华为昇腾、寒武纪、海光、昆仑芯、壁仞、燧原、摩尔线程等路线。单卡性能、显存容量、互联带宽、软件生态和供货能力决定芯片在超节点中的竞争力。国产芯片短期面临先进制程、HBM、编程生态和模型适配方面的挑战,但在本土供应安全、政策支持、客户共创和系统级优化方面具备机会。超节点为国产芯片提供了一种现实路径:通过更大Scale up域、更高系统并行度和更强软件适配,弥补单颗芯片性能差距,满足国产大模型训练与推理需求。未来AI芯片竞争将从单卡算力参数转向系统级能力。芯片厂商需要提供高带宽互联接口、内存语义能力、集合通信加速、稳定驱动栈和主流框架适配,并与服务器、交换芯片、云平台共同优化端到端效率。5.3 交换芯片与交换节点:Scale up网络的核心增量交换芯片是超节点Scale up域的核心组件。传统八卡服务器更多依赖节点内部直连或有限交换,而超节点需要通过Switch tray将数十至上百颗XPU连接在同一高带宽域内。随着XPU互联带宽从数百GB/s提升至TB/s级,交换芯片容量、端口速率、时延、功耗和可靠性要求同步提升。交换芯片的增量来自两方面:一是单个超节点内部新增交换节点,使交换芯片从传统数据中心网络的ToR/Spine场景进入机柜内部Scale up场景;二是随着高带宽域扩大,多层交换拓扑将提升交换芯片配比。未来若HBD从64卡、128卡扩展到512卡、1024卡甚至更大规模,交换芯片用量和价值量将显著提升。国产交换芯片企业若能在25.6T、51.2T、102.4T等高端产品上实现规模应用,并适配OISA、ETH+、ALS等开放协议,将有机会在国产超节点生态中取得关键地位。该环节具备较高壁垒,也将成为国产算力基础设施自主可控的重要突破口。5.4 铜缆、连接器与PCB背板:高速互联的基础材料超节点内部高速互联带来大量铜缆、连接器和PCB背板需求。计算节点与交换节点之间需要低损耗、高速率、低时延连接,112G、224G乃至更高速率通道对材料、工艺和结构设计提出更高要求。在单机柜或短距离互联场景下,铜缆具有成本低、时延低、部署成熟的优势,是当前较具性价比的方案。但当XPU数量继续增加、跨机柜距离拉长时,铜缆布线复杂度、重量、散热和信号完整性问题会凸显。正交背板和零背板方案可缩短传输路径、降低信号损耗、提升系统稳定性,但物理扩展能力有限,制造精度要求较高。光互连将随着超节点规模扩大而提升渗透率。对于多机柜、千卡级或更大Scale up域,光纤、光模块、硅光、CPO和OCS具备更高带宽密度和更优远距离传输能力。未来超节点互联可能呈现"柜内铜互联+柜间光互联+大规模OCS动态重构"的混合架构。AI服务器功耗快速提升,传统风冷逐渐接近极限。当单机柜功耗达到30KW以上时,液冷经济性开始凸显;当功耗达到50KW以上时,液冷逐渐成为必选;当机柜功耗达到100KW以上,风液混合甚至全液冷成为主流方向。超节点机柜通常集成大量XPU、交换芯片、DPU、NIC、内存和电源模块,热密度显著高于传统服务器。液冷系统包括冷板、快接头、Manifold、CDU、液冷工质、管路、泵、换热器和监控系统等。随着超节点向更高功耗发展,液冷对象将从GPU/CPU扩展到交换芯片、DPU、内存、光模块和电源模块,液冷系统价值量持续提升。液冷行业的竞争重点不只是单个冷板制造能力,而是端到端系统能力。领先企业需要具备热仿真、冷板设计、泄漏检测、工质管理、快速交付、现场运维和与服务器结构协同设计的能力。国产液冷厂商若能绑定头部服务器和云厂商,将在超节点放量中获得较大成长空间。超节点重构供电系统。传统服务器通常在每台服务器内部配置电源模块,而超节点倾向采用集中供电方式,由Power Shelf统一完成AC/DC转换,通过Busbar向计算节点和交换节点供电,再在节点内进行精准降压。这一方式可减少冗余电源占用空间,提高供电效率,并释放更多空间用于部署算力和散热组件。随着机柜功耗提升,PSU功率等级从3.3KW向5.5KW、18KW乃至更高等级演进,Power Shelf价值量同步提升。机柜侧电压也从传统12V向48V、54V甚至更高电压发展,以降低电流、减少铜损和母线体积。在数据中心层面,AI机柜功率迈向百千瓦和兆瓦级,将推动HVDC和SST等新型供电架构发展。高压直流减少多级转换损耗,提高能源效率;固态变压器通过高频电力电子器件实现更高效率、更小体积和更灵活控制。供电系统将从服务器配套件升级为AI数据中心基础设施核心环节。海外超节点生态以NVIDIA为核心,NVLink和NVSwitch构成其高性能Scale up网络基础。NVIDIA通过GPU、CPU、NVLink、NVSwitch、整机柜、软件栈和云服务合作形成完整闭环,在训练和推理市场占据领先地位。其优势不仅来自芯片性能,也来自CUDA生态、模型框架适配、开发者基础和大客户粘性。AMD正通过Instinct GPU、Infinity Fabric、UALink和Helios机架方案扩大AI基础设施市场份额。相较NVIDIA,AMD更积极参与开放互联生态,希望通过开放标准降低客户锁定担忧,并联合云厂商、CPU、网络和系统伙伴构建可替代方案。Google TPU则代表垂直一体化路线,通过自研芯片、Torus拓扑、光互连和自有云平台形成端到端优化。该模式强调芯片、模型和云服务深度协同,但生态开放性相对有限。博通、Marvell等芯片与网络厂商在交换芯片、定制ASIC、硅光和以太网Scale up方面扮演重要角色。博通推动SUE方案,试图将以太网生态引入Scale up领域,使更多厂商可基于以太网技术构建开放超节点。国内超节点生态呈现"芯片厂商+云厂商+运营商+服务器ODM+网络设备+液冷供电"的多方协同格局。华为基于昇腾和灵衢UB构建相对完整的超节点体系,具备芯片、互联、服务器、软件和行业客户协同能力。运营商侧,中国移动推动OISA协议和国产超节点采购,有望成为国产Scale up生态的重要组织者。互联网大厂积极布局自研超节点。阿里通过ALS和磐久超节点推动云基础设施升级;字节通过EthLink和大禹超节点强化内部AI集群能力;腾讯联合信通院和产业伙伴推动ETH-X;百度围绕昆仑芯和天池超节点推进国产AI Infra。大厂的作用不仅是采购方,更是架构设计者、标准推动者和生态组织者。服务器厂商方面,华勤技术、浪潮信息、工业富联、联想、中兴通讯、紫光股份等具备整机柜交付、供应链整合和大客户服务能力。随着超节点从L10单机交付转向L11/L12级交付,服务器厂商的价值量和客户绑定关系有望提升。网络设备和交换芯片厂商方面,锐捷网络、盛科通信等企业有望受益于Scale up网络扩展。液冷方面,英维克、申菱环境、高澜股份等企业具备数据中心冷却系统经验;供电方面,欧陆通、英诺赛科、天岳先进、杰华特、纳芯微等企业可参与PSU、功率器件和电源管理环节。国产超节点的核心逻辑不是在短期内单卡性能全面超越海外领先GPU,而是通过系统架构创新实现可用算力提升。若国产单卡性能存在差距,可通过扩大Scale up域、优化互联协议、提高内存容量、降低通信开销和提升整机柜能效来补足。对于部分大模型训练和推理任务,系统整体吞吐、显存容量和通信效率可能比单卡峰值更关键。国产超节点还具备供应链安全和本土生态适配优势。在外部限制不确定性增强的背景下,国内云厂商、运营商和政府智算中心对国产AI基础设施需求增强。超节点能够将国产芯片、国产服务器、国产交换、国产液冷和国产电源整合为可交付系统,形成产业协同效应。但弯道超车并非必然。国产生态仍需解决软件框架适配、模型迁移成本、互联协议标准不统一、芯片供给稳定性、HBM供应、系统可靠性和大规模运维经验不足等问题。未来2至3年将是国产超节点从可用走向好用、从样机走向规模商业化的关键窗口期。超节点成本主要由AI加速芯片及HBM、CPU和内存、交换芯片与交换节点、高速互联组件、PCB背板、服务器结构件、液冷系统、供电系统、整机柜集成与测试、软件适配和运维系统构成。其中AI加速芯片仍是最大成本项,但相比传统八卡服务器,超节点中网络、液冷、供电和结构件价值占比显著提升。交换节点成本将随着Scale up域扩大而提升。高端交换芯片、Switch tray、连接器和背板构成新增价值。若超节点采用多层拓扑或跨机柜互联,光模块、硅光、OCS和高性能线缆成本也会增加。液冷和供电是传统服务器中相对低占比但在超节点中快速提升的环节。高功耗机柜要求更复杂冷板、更高流量CDU、更高可靠性快接头和更严密泄漏监控;供电侧则需要大功率PSU、Power Shelf、Busbar、BBU和高压直流配套。整机柜集成测试也成为成本和价值的重要组成部分。超节点降本主要来自规模化、标准化、国产化和系统优化。- 规模化能够摊薄研发、验证、结构设计和供应链成本。超节点涉及复杂的热、电、信号、软件和可靠性验证,前期投入较高。随着运营商和云厂商批量采购,供应链规模效应将逐步体现。
- 标准化有助于降低生态碎片化成本。若每家芯片厂商、云厂商和服务器厂商采用不同互联协议、结构尺寸和管理接口,将增加适配成本并限制产业扩张。OISA、ETH-X、ALS、UALink、SUE等开放协议和设计规范的成熟,将有助于形成更统一的产业接口。
- 国产化可降低供应风险并改善成本结构。交换芯片、光模块、连接器、PCB、液冷、供电和服务器制造等环节国内企业基础较好,若能实现规模替代,将降低整体采购成本。AI芯片和HBM是更具挑战的环节,但也将决定国产超节点长期成本竞争力。
- 系统优化则通过提高MFU、降低通信开销、提升每瓦Token生成能力来降低单位算力成本。对于客户而言,购买成本只是总拥有成本的一部分,电费、机房空间、冷却系统、运维和模型效率同样重要。超节点若能显著提升有效算力利用率,即便硬件单价较高,也可能具备更低TCO。
短期内,超节点仍处于高端导入阶段,产品价格和毛利率受定制化程度、芯片供应、交付能力和客户结构影响较大。头部客户会更关注系统性能和交付确定性,而非单纯低价。具备早期项目经验和核心客户绑定的厂商,有望获得较高价值留存。中期看,随着超节点标准化和供应链成熟,部分环节价格可能下降,但整机柜系统价值量仍将高于传统服务器。交换节点、液冷、供电和高速互联带来的新增价值将对冲部分硬件降价压力。服务器ODM可能从低毛利组装模式转向更高附加值系统集成模式。长期看,超节点价格将取决于AI应用商业化和单位Token成本下降速度。如果推理需求持续爆发,客户愿意为更高能效、更高吞吐和更低延迟支付溢价;若AI应用变现低于预期,云厂商资本开支放缓,超节点价格竞争可能加剧。超节点的市场空间不能简单等同于AI服务器市场,也不能仅按GPU数量线性外推。更合理的测算方式是:先以AI服务器、AI基础设施和中国智能算力市场作为总量基础,再判断其中高端训练、大规模推理、运营商智算中心和行业私有化部署中,哪些负载需要采用超节点形态,最后结合超节点渗透率、单卡价值量和整机柜交付价值进行情景测算。从公开数据看,全球AI基础设施和中国智能算力市场均处于高速增长阶段。IDC数据显示,2025年二季度全球用于AI部署的计算与存储硬件基础设施支出达到820亿美元,同比增长166%,并预计全球AI基础设施支出到2029年将达到7580亿美元。IDC同时指出,AI基础设施支出主要由AI服务器拉动,其中服务器在AI Centric支出中占比约98%,带加速器服务器是AI平台首选基础设施,在2025年二季度占AI服务器基础设施支出的91.8%,预计到2029年将超过95%。这意味着超节点的可服务市场主要嵌入在"加速服务器+高密度AI机柜+大规模智算集群"之中。从AI服务器口径看,IDC数据显示,2024年全球人工智能服务器市场规模预计为1251亿美元,2025年将增至1587亿美元,2028年有望达到2227亿美元,其中生成式人工智能服务器占比将从2025年的29.6%提升至2028年的37.7%。TrendForce集邦咨询预计,2026年全球AI Server出货量将同比增长28%以上,主要受北美CSP持续加强AI基础设施投资以及AI推理服务负载快速增长驱动。上述数据说明,超节点不是孤立市场,而是AI服务器向高密度、高互联、高能效形态升级后的结构性增量。从中国市场看,IDC与浪潮信息联合发布的《2025年中国人工智能计算力发展评估报告》显示,2024年中国智能算力规模达到725.3 EFLOPS,同比增长74.1%;中国人工智能算力市场规模为190亿美元,同比增长86.9%。该报告预计,2025年中国智能算力规模将达到1037.3 EFLOPS,2026年达到1460.3 EFLOPS;中国人工智能算力市场规模2025年将达到259亿美元,2026年将达到337亿美元。按照1美元兑7.2元人民币的测算汇率,2026年中国人工智能算力市场规模约为2426亿元人民币。中国智算云服务市场同样快速扩张。IDC《2025上半年中国智算云基础设施市场(AI IaaS)跟踪》显示,2025年上半年中国AI IaaS整体市场同比增长122.4%,市场规模达到198.7亿元人民币;其中GenAI IaaS市场同比增长219.3%,市场规模达到166.8亿元人民币,占AI IaaS的83.9%。这表明生成式AI已成为智算云基础设施投资的核心驱动力,而生成式AI训练、推理和智能体负载正是超节点最具适配性的应用方向。大模型训练是超节点最确定的早期应用场景。千亿级、万亿级模型训练需要大量张量并行、流水并行、数据并行和专家并行协同。尤其在MoE模型中,专家并行带来的All-to-All通信频繁发生,传统八卡服务器和Scale out网络容易成为瓶颈。超节点通过扩大高带宽域,将更多XPU纳入低延迟互联范围,可显著降低跨节点通信开销,提高训练效率。市场空间方面,大模型训练需求主要由头部互联网公司、基础模型公司、科研机构和国家级智算中心拉动。以全球AI服务器市场为基准,2025年全球AI服务器市场规模为1587亿美元。若假设其中10%至15%用于需要超节点或类超节点架构的高端训练集群,则2025年全球训练侧超节点可服务市场约为159亿至238亿美元。到2028年,全球AI服务器市场预计达到2227亿美元,若高端训练集群中超节点渗透率提升至20%至25%,则训练侧超节点可服务市场约为445亿至557亿美元。中国市场方面,2026年中国人工智能算力市场规模预计为337亿美元,折合约2426亿元人民币。若其中15%用于高端训练型超节点集群,则训练侧超节点可服务市场约为364亿元人民币;若渗透率提升至25%,对应市场空间约为607亿元人民币。考虑到国产大模型训练、运营商智算中心建设和国产AI芯片集群扩容需求,训练侧将是国产超节点率先规模化落地的市场。推理市场是超节点未来更具弹性的增长来源。AI应用正在从聊天机器人扩展到办公、搜索、编程、视频生成、智能客服、金融分析、工业设计和企业智能体。推理负载的核心变化是Token消耗快速增长,同时长上下文、多轮工具调用和智能体任务提高了对KV Cache、显存容量、显存带宽和多并发调度能力的要求。IDC中国AI IaaS数据可以侧面反映推理和应用端需求的快速增长。2025年上半年,中国AI IaaS市场达到198.7亿元人民币,其中GenAI IaaS为166.8亿元人民币,占比超过八成,且同比增长219.3%。这说明生成式AI相关云端算力需求已经从早期训练扩展到模型服务、推理调用和行业应用部署。测算推理侧市场时,可将AI IaaS和AI服务器中的GenAI部分作为参考。全球口径下,IDC预计生成式人工智能服务器占AI服务器比例将从2025年的29.6%提升至2028年的37.7%。以全球AI服务器市场2025年1587亿美元测算,2025年生成式AI服务器市场约为470亿美元;以2028年2227亿美元测算,2028年生成式AI服务器市场约为840亿美元。若其中20%至30%的高并发、长上下文、大模型推理负载采用超节点或高密度整柜架构,则2028年全球推理侧超节点可服务市场约为168亿至252亿美元。中国口径下,若以2025年上半年GenAI IaaS 166.8亿元人民币为基础,简单年化后约为333.6亿元人民币。若其中20%至30%的高端推理云基础设施逐步采用超节点形态,则对应中国推理侧超节点年化可服务市场约为67亿至100亿元人民币。该测算仅反映云端IaaS口径,不包含互联网大厂自建推理集群、政企私有化部署和端到端行业解决方案,因此实际潜在空间更大。8.3 智算中心与运营商云:国产超节点规模化采购的关键抓手运营商和地方智算中心是国产超节点的重要客户。运营商具备机房、网络、政企客户和集中采购优势,正在从传统通信网络运营商向算力基础设施运营商转型。国产超节点符合运营商自主可控、规模采购、标准化建设和绿色数据中心改造需求。东方证券报告披露,中国移动2026年至2027年人工智能超节点设备集中采购项目采购规模为6208张AI加速卡,折合776套超节点设备,最高投标报价为20.70亿元人民币。按该口径测算,单套设备均价约266.8万元人民币,单张AI加速卡对应约33.34万元人民币;若折算为384张AI加速卡规模,对应约1.28亿元人民币。该采购案例提供了国产超节点早期市场的可观测价格锚。若以中国2026年人工智能算力市场规模约2426亿元人民币为基础,假设运营商、智算中心和政企云等高密度部署场景中有15%至25%采用超节点形态,则对应市场空间约为364亿至607亿元人民币。若按照中国移动集采案例中384卡规模约1.28亿元人民币的价格锚测算,364亿至607亿元人民币可对应约284至474个384卡级超节点集群,或约10.9万至18.2万张AI加速卡的系统级部署需求。需要注意的是,该测算使用的是公开集采价格作为参考,实际价格会随芯片类型、互联架构、液冷比例、供电方案和交付等级变化。运营商市场的战略意义不仅在规模,还在标准化。一旦运营商通过集采推动OISA、ETH-X、国产交换芯片、国产服务器和国产液冷方案规模落地,将有助于降低国产超节点生态的验证成本,并为后续政企行业客户提供样板工程。金融、制造、能源、医疗、政务、交通等行业正在探索私有化大模型部署。这类客户对数据安全、合规、本地化和可控性要求较高,通常不会完全依赖公有云推理服务。行业大模型的部署规模可能低于互联网大厂训练集群,但对稳定性、运维便利性和整体解决方案要求更高。企业私有化市场初期更可能采用小规模超节点或分机柜超节点方案,例如32卡、64卡、128卡级别,用于行业模型微调、知识库推理、智能客服、工业设计、金融风控和政务应用。随着企业AI应用从试点走向生产,推理并发和长上下文需求提升,行业私有化超节点市场将逐步打开。从市场空间看,中国AI IaaS市场2025年上半年已达到198.7亿元人民币,但企业私有化部署并不完全体现在IaaS口径中。若以2026年中国人工智能算力市场2426亿元人民币为总量基础,假设行业私有化和政企专属智算场景占其中10%至15%,且其中20%采用超节点或类超节点高密度架构,则对应市场空间约为49亿至73亿元人民币。该市场短期规模低于云厂商和运营商,但客户数量多、场景分散、解决方案附加值高,适合服务器厂商、云厂商和行业集成商共同开拓。基于公开数据和渗透率假设,可以形成三层市场空间判断:- 全球TAM口径。以IDC全球AI服务器市场为基础,2025年全球AI服务器市场为1587亿美元,2028年为2227亿美元。若超节点及类超节点高密度整柜架构在2025年渗透率为10%,2028年提升至25%,则全球超节点可服务市场空间约从159亿美元提升至557亿美元。
- 中国SAM口径。以IDC与浪潮信息发布的中国人工智能算力市场为基础,2026年中国市场规模预计为337亿美元,折合约2426亿元人民币。若超节点在高端训练、推理、运营商智算中心和行业私有化场景中的综合渗透率为15%、25%、35%,则对应中国超节点可服务市场分别约为364亿元、607亿元和849亿元人民币。
- 国产SOM口径。考虑国产AI芯片、国产互联协议、国产服务器和国产液冷供电体系仍处于导入期,短期可获取市场主要来自运营商、国产智算中心、互联网大厂国产化集群和政企专属云。若以2026年中国超节点可服务市场364亿至607亿元人民币为参考,国产方案获取30%至50%份额,则国产超节点实际可获取市场约为109亿至304亿元人民币。随着国产芯片供给、互联协议和软件生态成熟,该比例有望进一步提升。
- 全球AI基础设施方面,2025年二季度AI计算与存储硬件支出为820亿美元,2029年预计达到7580亿美元,数据来源为IDC《Worldwide Artificial Intelligence Infrastructure Forecast, 2025--2029》。超节点嵌入加速服务器、高密度AI机柜和大规模智算集群之中,长期空间随AI基础设施支出扩大。
- 全球AI服务器TAM方面,2025年市场规模为1587亿美元,2028年为2227亿美元,数据来源为IDC《2025中国人工智能计算力发展评估报告》。若超节点渗透率2025年为10%、2028年为25%,则2025年市场空间约159亿美元,2028年约557亿美元。
- 全球GenAI服务器方面,2025年占AI服务器比例为29.6%,2028年提升至37.7%,数据来源同上。若20%至30%高并发推理负载采用超节点,则2028年推理侧约168亿至252亿美元。
- 中国人工智能算力市场方面,2026年预计为337亿美元,约2426亿元人民币,数据来源为IDC与浪潮信息《2025年中国人工智能计算力发展评估报告》。综合渗透率15%、25%、35%分别对应约364亿、607亿、849亿元人民币。
- 中国AI IaaS方面,2025年上半年市场为198.7亿元,GenAI IaaS为166.8亿元,数据来源为IDC《中国智算云基础设施市场(AI IaaS)(2025上半年)跟踪》。GenAI IaaS年化约333.6亿元,其中20%至30%高端推理采用超节点,对应约67亿至100亿元人民币。
- 运营商超节点集采价格锚方面,中国移动采购6208张AI加速卡、776套设备,最高投标价20.70亿元,数据来源为东方证券《超节点:国产算力进攻的"矛"》。单卡约33.34万元,384卡约1.28亿元,可作为国产超节点早期单价测算参考。
第一,全球超节点潜在空间来自AI服务器结构升级。以2028年全球AI服务器2227亿美元为基础,即使仅有25%进入超节点或类超节点高密度整柜形态,对应市场也超过550亿美元,具备成长为高端AI基础设施主流形态的潜力。第二,中国超节点市场具备百亿级到千亿级成长空间。以2026年中国人工智能算力市场约2426亿元人民币为基础,15%至35%的综合渗透率即可对应364亿至849亿元人民币市场空间。考虑国产算力自主可控和运营商集采推动,国产超节点有望在2026年前后进入规模化放量阶段。第三,推理侧将决定中长期天花板。训练侧是超节点早期落地场景,但推理侧Token消耗、长上下文、智能体和多模态应用将持续扩大超节点需求。随着AI应用从模型训练走向日常生产力工具和行业业务系统,超节点将从"训练基础设施"扩展为"训练+推理+智能体基础设施"的通用算力底座。AI算力基础设施已成为数字经济和科技竞争的重要底座。国内政策持续支持人工智能、算力网络、东数西算、数据中心绿色低碳、国产芯片和关键软硬件自主可控。超节点作为高端智算基础设施,与这些政策方向高度契合。国产超节点的发展不仅是产业升级问题,也涉及供应链安全和科技自主。外部先进芯片供应不确定性增强,使国内客户更加重视国产AI芯片、国产服务器和国产互联协议。政策和产业资本有望继续支持国产算力生态建设。标准化是超节点产业规模化的关键。当前国内外Scale up协议仍处于多路线并行阶段,海外有NVLink、UALink、SUE等,国内有UB、OISA、ALS、ETH+、EthLink、ETH-X等。多协议并存有利于创新,但也可能带来生态割裂。未来标准竞争将围绕性能、开放性、生态成员、商业落地和客户采纳展开。开放协议若能形成广泛产业联盟,并在真实客户集群中证明性能和稳定性,将更有可能成为主流。对于国产生态而言,建立统一接口、统一管理和统一测试认证体系尤为重要。超节点机柜功耗大幅提升,对数据中心PUE、供电效率和冷却效率提出更高要求。监管和客户都将更加关注绿色算力。液冷、高压直流、余热回收、智能能耗管理和更高效率电源将成为超节点部署的重要配套。数据中心从传统10KW级机柜走向100KW级甚至MW级AI机柜,需要在土建、供电、制冷和运维标准上升级。超节点产业发展将反向推动数据中心基础设施标准变化。AI基础设施竞争正在从单卡性能、单机服务器性能,转向超节点和集群级系统性能。未来客户将更关注MFU、每瓦Token、单位训练成本、故障恢复效率、模型适配效率和总拥有成本。单个硬件指标仍重要,但不再足以决定竞争结果。封闭协议在性能和生态控制方面具备优势,但客户对供应链锁定和多芯片适配的担忧推动开放协议发展。未来开放Scale up生态将持续丰富,以太网技术栈可能在Scale up场景中获得更大空间。国产超节点尤其需要开放标准来整合分散生态。超节点功耗提升使液冷成为必然趋势。短期以风液混合为主,中长期随着芯片功耗和机柜密度继续提升,全液冷将成为高端超节点主流。两相冷板、微通道冷板、浸没式液冷和更高功率CDU等技术将持续演进。单机柜超节点解决64至144卡级互联,多机柜Matrix超节点将进一步扩展到384卡、512卡、1024卡甚至更大规模。跨机柜互联将推动光互联、OCS、Dragonfly+、Torus和多层Clos架构发展。超节点并非简单硬件设备,而是需要与模型框架、编译器、通信库、调度系统和运维平台深度结合。未来领先厂商将提供软硬一体解决方案,包括超节点硬件、AI框架适配、集群管理、能耗优化和模型部署服务。超节点是AI Infra从"服务器堆叠"走向"系统级算力单元"的关键跃迁。其出现源于大模型训练和推理对高带宽、低时延、大内存和高能效的刚性需求,也源于十万卡、百万卡集群时代对基础计算模块的重构。未来AI数据中心不会只是更多服务器的集合,而会以超节点作为基本单元,通过Scale up构建高效域内协同,再通过Scale out实现大规模集群扩展。对于中国市场而言,超节点具备更特殊的战略意义。国产AI芯片短期在先进制程和单卡性能上仍面临挑战,但可通过超节点实现系统级性能提升,推动国产算力生态从单卡替代走向整机柜和集群替代。随着开放协议、国产交换芯片、液冷、供电和服务器系统工程能力成熟,国产超节点有望成为本土AI基础设施的重要底座。总体判断,超节点行业仍处于早期成长阶段,但产业趋势明确、技术路线逐步清晰、客户需求快速形成。2026年前后有望成为国产超节点从样机验证走向规模交付的关键阶段。中长期看,随着AI应用进入高频推理和智能体时代,超节点将从高端训练集群扩展到大规模推理基础设施,成为AI产业链中确定性较强、价值链较长、国产替代空间较大的重要赛道。- 超节点 :通过高速互联和整机柜系统设计,将多颗AI加速芯片整合为统一高带宽计算域的系统形态。
- Scale up :纵向扩展,在单机、单机柜或多机柜内部扩大高带宽计算域,提高域内协同效率。
- Scale out :横向扩展,通过网络连接更多服务器或超节点,形成更大规模算力集群。
- HBD :高带宽域,指在低时延、高带宽互联下形成的协同计算和访存范围。
- MoE :混合专家模型,通过多个专家网络和路由机制提升模型参数容量并控制计算成本。
- TP :张量并行,将模型张量切分到多张加速卡上并行计算。
- EP :专家并行,将MoE模型中的不同专家分布到不同加速卡或节点上。
- All-to-All :多节点之间相互交换数据的通信模式,在MoE专家路由中非常关键。
- All-Reduce :多节点之间进行梯度或数据聚合的集合通信模式。
- KV Cache :大模型推理中存储历史Key/Value的缓存,对显存容量和带宽要求较高。
- CDU :冷量分配单元,液冷系统中负责换热和冷却液循环管理的关键设备。
- Busbar :供电母线,用于机柜内高电流低损耗供电。
- HVDC :高压直流供电,可减少电力转换环节并提升数据中心供电效率。
- SST :固态变压器,采用电力电子器件实现高效变压和整流的新型供电设备。
- OCS :光电路交换,可通过动态光路重构提升大规模网络灵活性和效率。