


一、报告摘要
2026 年 4 月,全球前沿 AI 大模型领域在不到两周内连续迎来三款旗舰模型的发布: 4 月 16 日 Anthropic 发布 Claude Opus 4.7,4 月 23 日 OpenAI 发布 GPT-5.5,4 月 24 日 DeepSeek 发布 V4 系列预览版(V4-Pro / V4-Flash)。 三款模型几乎同时将上下文窗口推进至 100 万 tokens 量级,在编程、智能体(Agent)、多步推理与世界知识等领域的基准成绩都达到了新的高度,但在能力侧重、定价结构与开源策略上呈现出显著差异。
本报告基于各厂商官方公布的数据、第三方评测机构(Artificial Analysis、Counterpoint Research、Omdia 等)的独立测评及主流科技媒体(Reuters、CNBC、VentureBeat、Fortune、SCMP 等)的公开报道,对三款旗舰模型进行横向(同时间点对比)与纵向(同系列代际演进)的多维评测,并结合 DeepSeek 与华为的合作模式探讨开源 AI 与国产硬件协同发展的未来走向。
核心发现
- 性能上限:
在大多数公开基准测试上,Claude Opus 4.7 与 GPT-5.5 仍然保持领先,DeepSeek V4-Pro-Max 在编程类基准(LiveCodeBench、Codeforces)上反超部分闭源模型,在智能体浏览(BrowseComp)上接近 GPT-5.5。 - 性价比:
DeepSeek V4-Pro 输出 token 价格约为 Claude Opus 4.7 的 1/7,GPT-5.5 的 1/8.6;V4-Flash 价格更低,在同尺寸级别仅为 GPT-5.4 Nano 的一小部分。 - 效率突破:
DeepSeek V4-Pro 在 100 万 tokens 上下文设置下,单 token 推理 FLOPs 仅为 V3.2 的 27%,KV 缓存仅为 10%,长上下文处理效率出现代际跳跃。 - 硬件协同:
DeepSeek V4 与华为 Ascend 实现“day-zero”适配,整条 Ascend SuperNode 产品线全面支持 V4 推理,标志着头部中文 AI 模型与国产芯片软硬件协同进入新阶段。
二、各模型基本信息概述
2.1 DeepSeek V4 系列
DeepSeek V4 由中国杭州的 DeepSeek-AI 团队于 2026 年 4 月 24 日发布预览版,包含 V4-Pro 与 V4-Flash 两款模型,均采用 MIT 开源协议,在 Hugging Face 上提供权重下载,目前定位为 “preview”(预览),DeepSeek 表示将利用预览期收集真实场景反馈后再形成稳定版本,但未公布最终版本时间表。
关键技术参数
- V4-Pro:
1.6 万亿(1.6T) 总参数 / 49B 激活参数,采用 MoE(混合专家)架构。 - V4-Flash:
284B 总参数 / 13B 激活参数。 - 上下文窗口:
两款模型均原生支持 1,000,000 (1M) tokens,最大输出 384K tokens。 - 训练规模:
预训练数据量超过 32 万亿 tokens。 - 架构创新:
引入 CSA+HCA(混合稀疏注意力 + 流形约束超连接)、mHC、Muon 优化器及 FP4/FP8 混合精度;后训练采用领域专家分别训练 + On-Policy Distillation(OPD)统一蒸馏的两阶段流程。 - 推理模式:
支持 Thinking / Non-Thinking 双模式,提供 low / medium / max 三档推理强度。
API 价格
- V4-Pro:
输入 $1.74 / 1M tokens,输出 $3.48 / 1M tokens。 - V4-Flash:
输入 $0.14 / 1M tokens,输出 $0.28 / 1M tokens。
2.2 Anthropic Claude Opus 4.7
Claude Opus 4.7 由 Anthropic 于 2026 年 4 月 16 日发布并全面可用(GA),Model ID 为 claude-opus-4-7,在 Claude.ai、Anthropic API、Amazon Bedrock、Google Cloud Vertex AI 与 Microsoft Foundry 同步上线。
关键技术参数
- 上下文窗口:
100 万 (1M) 输入 tokens,最大输出 128K tokens,1M 上下文不收取额外溢价。 - 模态支持:
文本 + 视觉,首次将图像分辨率上限提升到 2576px / 3.75MP(约为 4.6 版本的 3.3 倍)。 - 推理强度:
low / medium / high / xhigh(新增) / max,xhigh 为推荐用于编程与智能体任务的折中档。 - 分词器:
采用全新 tokenizer,同样的文本相比 Opus 4.6 可能多产生 1.0–1.35 倍的 token 数(最多 +35%)。 - 特色能力:
加强了文件系统记忆、自验证(self-verification)与长时程智能体可靠性,docx redlining、pptx 编辑等知识工作场景显著提升。
API 价格
输入: $5 / 1M tokens; 输出: $25 / 1M tokens(与 Opus 4.6 持平) 提示缓存最高节省 90%,Batch API 节省 50%。
2.3 OpenAI GPT-5.5
GPT-5.5 由 OpenAI 于 2026 年 4 月 23 日发布,4 月 24 日正式上线 API。OpenAI 在官方公告中称其为 “自 GPT-4.5 之后第一款从底层完全重训(retrained)的基础模型”,此前 GPT-5.1 / 5.2 / 5.3 / 5.4 都基于同一基座的后训练迭代,是 GPT-5 系列的代际跨越。
关键技术参数
- 上下文窗口:
100 万 (1M) tokens,首次将该规模引入 OpenAI 的 API 主线;高于 272K 的请求会按 2× 输入、1.5× 输出加价。 - 模型变体:
标准版 gpt-5.5 与高精度版 gpt-5.5-pro。 - 推理强度:
none / low / medium(默认)/ high / xhigh。 - 定位:
明确面向智能体场景—— OpenAI 描述为可“执行一系列操作、调用工具、自我检查并持续推进直至任务完成”。 - 基准定位:
在 Artificial Analysis 综合智能指数(AA Intelligence Index v4.0)上以 60 分排名第一,领先 Claude Opus 4.7 与 Gemini 3.1 Pro Preview(均为 57)3 分。
API 价格
- GPT-5.5:
输入 $5 / 1M tokens,输出 $30 / 1M tokens(相比 GPT-5.4 的 $2.5/$15 翻倍)。 - GPT-5.5 Pro:
输入 $30 / 1M tokens,输出 $180 / 1M tokens。 Batch / Flex 价格为标准的 50%; Priority 为 2.5×。
三、关键参数横向对比
3.1 总体规格速览
| 参数维度 | DeepSeek V4-Pro | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|
表 1:三款旗舰模型基础参数对比 (来源:各厂商官方文档)
3.2 主要基准测试成绩
下表整理了三款模型在各家官方公开技术报告或博客中可进行直接比较的基准成绩。 需要说明的是,各厂商在公布数据时使用的测试 harness、prompt scaffold 与推理强度可能不同,Anthropic、OpenAI 都已公开承认部分基准存在数据污染或脚手架敏感问题,因此小幅差异不应被解读为决定性差距。
| 基准 (Benchmark) | 测量维度 | DeepSeek V4-Pro-Max | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|
表 2:主要公开基准测试成绩对比 (来源:Anthropic、OpenAI、DeepSeek 官方技术报告及 VentureBeat、Artificial Analysis 综合)
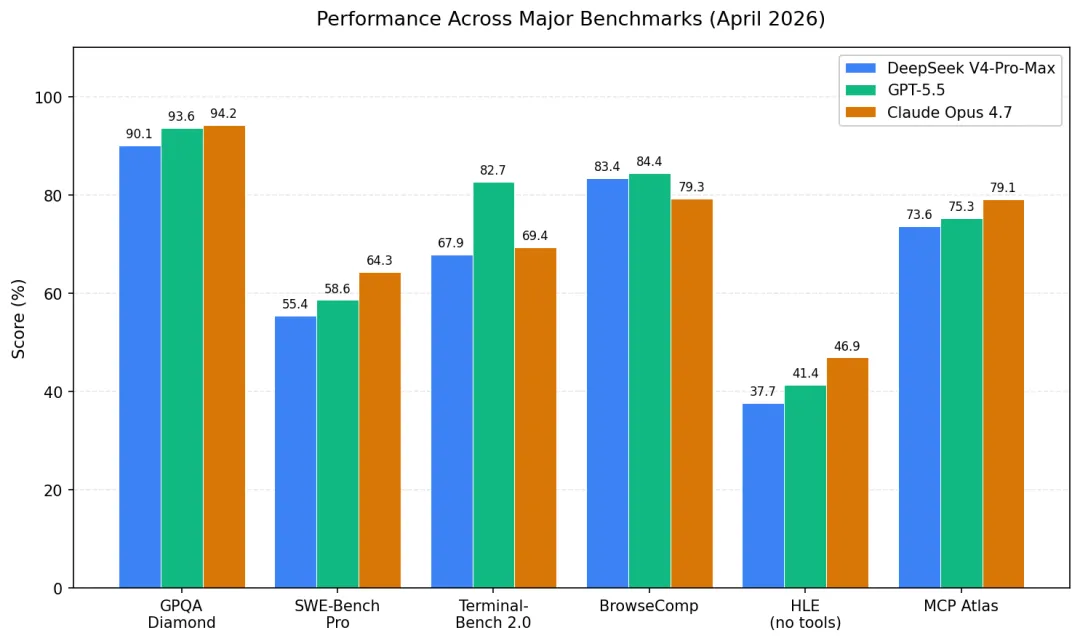
图 1:三款旗舰模型在主要基准测试上的得分对比
从图 1 可以观察到几个清晰的格局: 在 GPQA Diamond 这类研究生级学科推理上,Claude Opus 4.7(94.2%)与 GPT-5.5(93.6%)以微弱差距领先,DeepSeek V4-Pro-Max(90.1%)处于追赶阵营; 在 SWE-Bench Pro 这一更接近真实工程场景的代码智能体基准上,Claude Opus 4.7 以 64.3% 显著领先,体现 Anthropic 在编程智能体领域的传统优势; 在 Terminal-Bench 2.0(终端命令行任务)上,GPT-5.5 以 82.7% 大幅领先 Opus 4.7(69.4%)与 V4-Pro(67.9%),OpenAI 在通用计算机操作智能体方向的布局优势明显; 而 BrowseComp(网页浏览智能体)上三家差距很小,V4-Pro-Max 的 83.4% 反超 Claude Opus 4.7 的 79.3%,接近 GPT-5.5 的 84.4%。
3.3 编程能力专题对比
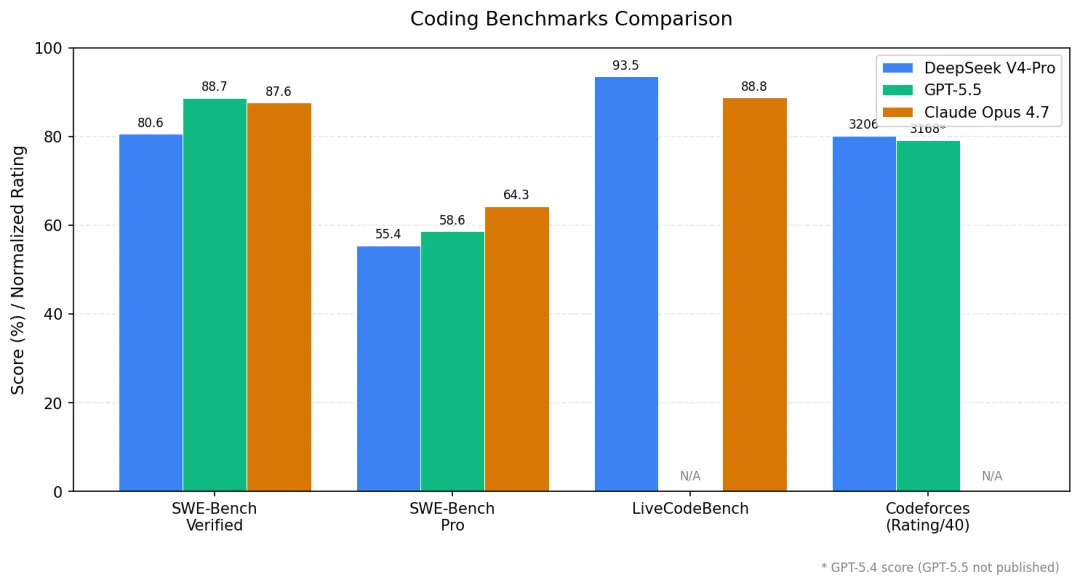
图 2:编程相关基准测试对比 (* GPT-5.5 在 Codeforces 上未公布独立成绩,使用 GPT-5.4 数据)
编程能力的对比呈现“分工明确”的特点:Claude Opus 4.7 在更贴近真实工程任务的 SWE-Bench Verified(87.6%)和 SWE-Bench Pro(64.3%)上保持领先;DeepSeek V4-Pro 则在代表算法竞赛和单文件代码生成能力的 LiveCodeBench(93.5)和 Codeforces(Elo 3206)上反超闭源模型;GPT-5.5 凭借在 SWE-Bench Verified 上据称的 88.7% 与 Terminal-Bench 上 82.7% 的成绩,在偏向自动化软件工程的领域占据顶端。
Anthropic 官方数据显示 Opus 4.7 相比 4.6 在 SWE-Bench Pro 上由 53.4% 提升到 64.3%,在 CursorBench 上由 58% 提升到 70%, 单代提升幅度近 10 个百分点,是其继 4.5 → 4.6 5 个百分点之后的进一步加速。
3.4 价格与性价比
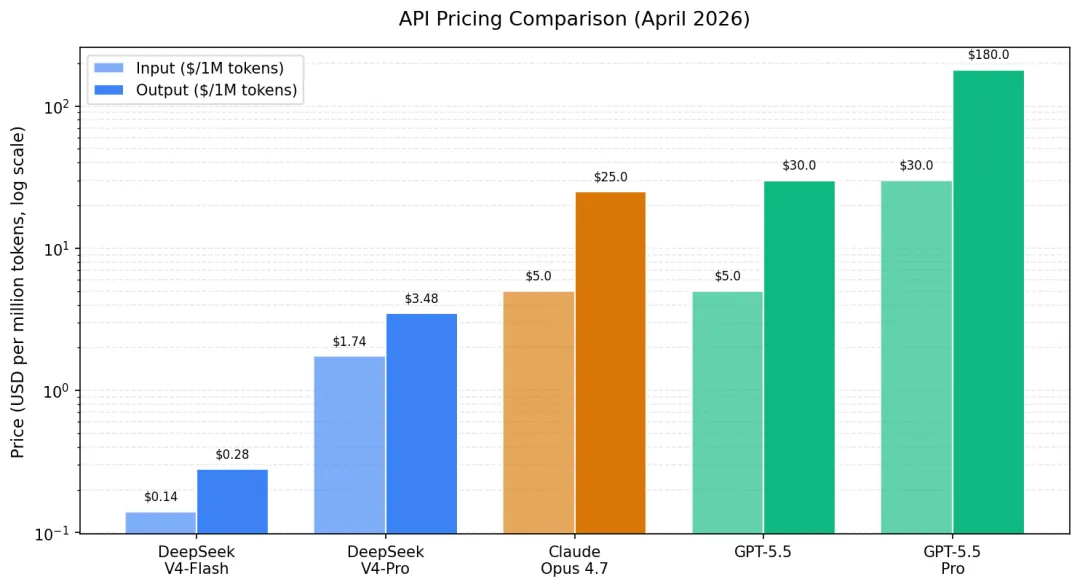
图 3:API 价格对比 (对数尺度,USD per 1M tokens)
从绝对定价看,DeepSeek V4 系列的价格优势仍然显著: V4-Pro 输出 $3.48 / 1M tokens 约为 Claude Opus 4.7($25)的 1/7,为 GPT-5.5($30)的 1/8.6;V4-Flash 输出 $0.28 / 1M tokens 是同尺寸级别中价格最低的旗舰候选之一,甚至低于 OpenAI 的 GPT-5.4 Nano。 顶级精度档的 GPT-5.5 Pro 输出 $180 / 1M tokens,与 V4-Pro 之间存在约 50 倍的差距。
需要指出的是,Anthropic 在 Claude Opus 4.7 上引入了新分词器,同样的中文/英文文本可能多产生最多 35% 的 tokens,意味着在“账面价格不变”的情况下,实际单任务成本可能上升约 0–35%; 而 GPT-5.5 则在长上下文(>272K)时启用 2× 输入、1.5× 输出的加价机制。 因此真实的成本对比需要结合具体业务的输入/输出比例和上下文长度。
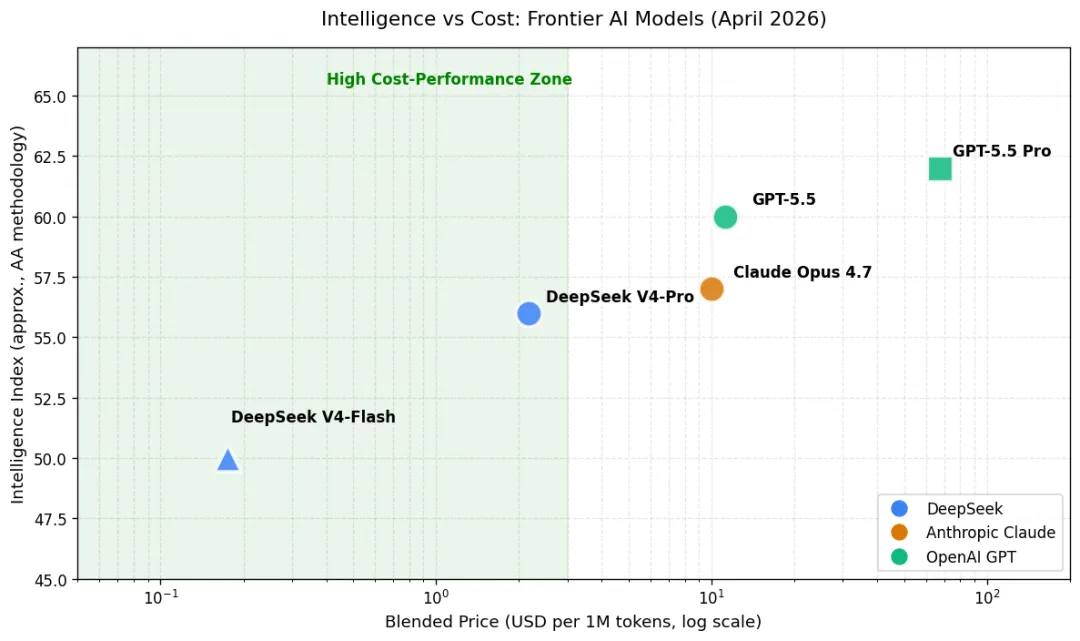
图 4:智能水平 vs API 成本(对数尺度,基于 AA Intelligence Index 与 3:1 加权混合价格)
如图 4 所示,以 Artificial Analysis 综合智能指数与混合价格(3:1 输入输出比)为坐标,DeepSeek V4-Pro 处于左上角的“高性价比区”——以接近 Claude Opus 4.7 的智能水平,获得仅约 1/4 的混合成本。 Artificial Analysis 公开发布的对比指出, GPT-5.5(medium)在该综合指数上达到与 Claude Opus 4.7(max)相当的得分,而前者跑完一次完整测试集的费用约为 1,200 美元,后者约为 4,800 美元(详见 Artificial Analysis 公开测评)。
四、纵向代际演进对比
4.1 DeepSeek 系列演进
DeepSeek 系列的代际演进路径可以归纳为“从稠密到稀疏 → 从中等上下文到百万级上下文 → 从通用专家到领域专家蒸馏”三步走。
| 版本 | 发布时间 | 架构 / 参数 | 上下文 | 训练数据 | 主要架构特征 |
|---|---|---|---|---|---|
表 3:DeepSeek 系列主要版本演进 (来源:DeepSeek 官方模型卡及技术报告汇总)
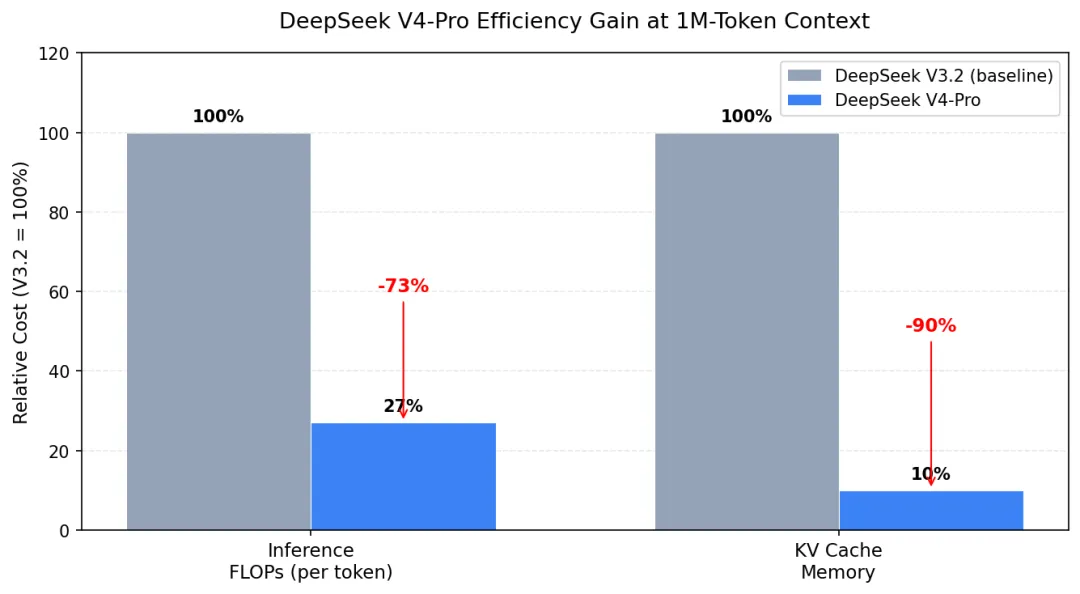
图 5:DeepSeek V4-Pro 在 1M 上下文下的相对推理成本(以 V3.2 为基准)
DeepSeek 在 V4-Pro 模型卡中明确指出:在 1M token 上下文设置下,V4-Pro 的单 token 推理 FLOPs 仅为 V3.2 的 27%,KV 缓存仅为 10%。 这意味着即便上下文窗口扩大近 8 倍,实际推理算力消耗反而降低了约 73%,显存占用降低了 90%。 这是 DeepSeek 能在保持 V3 时代价格水平的同时进一步压缩成本的根本原因,也是 V4 称为“突破超长上下文效率瓶颈”的核心依据。
4.2 Claude Opus 系列演进
| 版本 | 发布时间 | 代表分数 (SWE-Bench Verified) | 上下文 | 价格 (输入/输出 USD/1M) | 重点变化 |
|---|---|---|---|---|---|
表 4:Claude Opus 系列代际演进 (来源:Anthropic 官方文档与 SWE-Bench 公开排行)
Anthropic 自 Opus 4.5 起将旗舰输入/输出价格固定在 $5/$25,相对 Opus 4 时代($15/$75)降幅 67%。 Opus 4.7 在保持账面价格不变的同时,实现了 SWE-Bench Verified 由 80.8% 跃升至 87.6% 的代际跳跃, 并新增 xhigh 推理档作为 high 与 max 之间的折中选项,Claude Code 默认升级到使用 xhigh,显示该档位被 Anthropic 视为编程智能体的最佳折中点。
4.3 GPT-5 系列演进
OpenAI 在 GPT-5.5 的官方介绍中明确指出:GPT-5.1、5.2、5.3、5.4 都属于在同一基础模型之上的“后训练迭代”(post-training iteration), 而 GPT-5.5 则是“自 GPT-4.5 以来第一款从底层完全重训的基础模型”——其架构、预训练语料、智能体导向的目标函数都进行了重做。 这一“代际跳跃”体现在:综合智能指数从 5.4 阵营进入第一档(AA Intelligence Index v4.0 = 60), Terminal-Bench 2.0 取得 82.7%(领先 Opus 4.7 13 个百分点),GDPval 经济价值基准达到 84.9%。
代价是定价翻倍: GPT-5.4 输入/输出为 $2.5 / $15,GPT-5.5 翻倍至 $5 / $30; 对此 OpenAI 给出的官方解释是 GPT-5.5 在大多数任务上消耗的 token 数显著低于 GPT-5.4(Codex 任务上据称下降约 40%),最终单任务成本上升约 20%。 真实成本变化仍取决于具体业务场景,需要在迁移前进行小范围对比测试。
五、DeepSeek 与华为合作模式分析
5.1 合作事实概述
据 Reuters、CNBC、South China Morning Post(SCMP)、Fortune、Manila Times 等国际主流媒体在 2026 年 4 月 24–26 日的一致报道,DeepSeek V4 系列发布同日,华为通过 Bilibili 与微信进行了官方直播,披露了与 DeepSeek 的深度合作进展。
已公开的合作内容
- 训练阶段参与:
华为公开声明,其 Ascend 芯片被用于 V4 部分训练流程;DeepSeek 没有披露 V4 是否完全或部分使用 Nvidia 芯片(此前 V3 与 R1 主要在 Nvidia GPU 上训练)。 - 推理阶段全面适配:
“整个 Ascend SuperNode 产品线已全面支持 DeepSeek V4 系列模型”——华为在直播中宣布两家在模型发布前完成了软硬件协同优化,实现 day-zero 适配。 - 新一代芯片:
华为新一代 Ascend 950PR 与 950DT 芯片完成对 V4 的“day-zero”适配,这两款芯片预计 2026 年下半年规模出货。 - 软件栈:
华为自研的 CANN(Compute Architecture for Neural Networks)软件栈对 V4 进行了优化,扮演与 Nvidia CUDA 对位的角色。 - 价格联动:
DeepSeek 公开表示,V4-Pro 当前定价考虑了吞吐量限制,等到 2026 年下半年华为 Ascend 950PR SuperNode 量产,V4-Pro 的价格将进一步下调。
5.2 合作模式特征
综合上述信息,DeepSeek 与华为的合作模式可以概括为以下几个特征:
- “模型 ↔ 芯片”双向协同:
不同于过去模型公司单向适配既有硬件的模式,V4 在架构设计阶段就考虑了 Ascend 芯片的特性(例如 FP4/FP8 混合精度对 Ascend 计算单元的友好度),华为则在模型发布前完成 CANN 与 Ascend SuperNode 的优化。 - 训练 + 推理覆盖:
合作不止步于推理部署,还延伸到了训练阶段(华为披露 Ascend 参与 V4 训练),完整覆盖了 LLM 生命周期。 - 开源加速生态:
由于 V4 采用 MIT 开源协议,中文开发者可以直接下载权重在 Ascend 设备上部署,降低了从模型到硬件的整链国产化门槛。 - 市场反应客观存在:
消息发布当日,中芯国际(SMIC)香港股价上涨约 10%,华虹半导体上涨约 15%——市场普遍将这一合作视为国产 AI 算力供应链的实质性进展;同期 Nvidia 股价波动较小。
5.3 第三方评论
Omdia 半导体研究总监 He Hui 评论:“华为 Ascend 是中国本土对 Nvidia 最强的替代品,支持 DeepSeek V4 表明中国头部 AI 模型现在可以在中国硬件上运行,这对中国 AI 行业是一件大事”;Counterpoint Research 首席 AI 分析师 Wei Sun 则指出 V4 在国产芯片上的原生运行能力将“最终加速全球 AI 发展”。
另一方面,Omdia 首席分析师 Lian Jye Su 也指出,“华为在技术层面仍落后于 Nvidia,要让开发者从 Nvidia 生态迁移仍然困难”,但 DeepSeek 的此次转向显示出 “向 AI 基础设施自给自足迈进的实际进展”。这两种观点共同构成了对该合作的客观评价基线。
六、未来发展前景分析
基于上述事实与公开数据,本节对未来 6–18 个月的发展进行情景化前景分析。 需要强调的是,以下分析均基于已公开信息的合理推演,不构成对任何具体厂商竞争胜负的预测,也不涉及政治判断。
6.1 性能维度: 开源-闭源差距将进一步收窄,但仍将在“最难任务”上保留差距
从 V3 到 V4,DeepSeek 在多数公开基准上与闭源前沿的差距已从 6–12 个月压缩到 3–6 个月(DataCamp 等媒体的评估)。考虑到:1) V4 仍是预览版,稳定版可能进一步提升;2) MIT 开源使全球研究社区可在此之上做后训练改进;3) Kimi K2.6、GLM-5.1 等其他开源前沿模型也在快速迭代。 预计在未来 6–12 个月内,开源阵营在通用基准上的中位数性能将进一步逼近闭源前沿。
但在最难的智能体任务(SWE-Bench Pro、Humanity's Last Exam、长时程多步代理)上,Claude Opus 与 GPT-5 系列在数据闭环、对齐与安全工程方面的多年积累仍将提供差距。 这一差距未必体现为基准分数,更可能体现在“可靠性”这一难以量化的维度上。
6.2 价格维度: 价格战可能进入新一轮,但顶级智能档可能反向上涨
DeepSeek 已表态在 Ascend 950PR 量产后会下调 V4-Pro 价格;Gemini 3.1 Pro 当前混合价格仅约为 GPT-5.5 的 1/3。 因此,中等智能档(混合智能指数 55–60 区间)的价格预期将持续下行,可能在 1–2 年内低于 $1 / 1M tokens 输出。
与之相对,顶级智能档反而出现了反向定价: GPT-5.5 相比 5.4 翻倍,GPT-5.5 Pro 输出 $180 / 1M tokens 与一年前相比上涨明显。 这反映出 “最前沿能力”的稀缺性溢价仍在;未来 “量大价低的中端开源模型 + 用于关键场景的高价闭源旗舰”可能成为企业 AI 部署的常见组合。
6.3 硬件维度: 国产芯片与开源模型的协同效应
DeepSeek + 华为模式如果证明可持续,可能引发以下连锁反应:
- 国产生态正反馈:
开发者一旦能在国产硬件上跑通主流开源模型,就会有更多的 ISV、云厂商基于这一组合构建产品,从而进一步反哺华为 CANN 等软件栈成熟。 SCMP 已经报道整条 Ascend SuperNode 产品线适配 V4 推理。 - 全球供应链多元化:
在 Nvidia 部分高端 GPU 受出口管制限制的客观背景下,Counterpoint 等机构观察认为,国产硬件 +开源模型的组合可能加速全球 AI 算力来源的多元化。 但这是“补充”而非“替代”——Omdia 等机构同时指出 Ascend 在工艺和绝对算力上仍落后于 Nvidia 最新一代。 - 价格→规模→成本下降循环:
如果国产硬件的规模化生产 + 开源模型的低边际成本部署能形成正循环,推理价格存在持续下行空间; 但这取决于工艺良率、能效等多重工程因素,无法仅凭模型层面的数据推断。
6.4 应用维度: 智能体(Agent)将成为下一个主战场
三家厂商在 2026 年 4 月的发布中,几乎不约而同地将 “智能体能力” 而非 “聊天助手能力”作为宣传重点: DeepSeek 强调 V4 与 Claude Code、OpenClaw、OpenCode 等智能体框架的兼容; Anthropic 强调 Opus 4.7 在长时程任务、自验证与文件系统记忆方面的提升; OpenAI 则直接将 GPT-5.5 描述为 “可执行一系列动作、调用工具、自我检查并持续推进的智能体模型”。
结合 Terminal-Bench、SWE-Bench Pro、BrowseComp、MCP Atlas 等智能体导向基准的快速迭代,可以预期未来 6–12 个月各家的差异化将更多体现在: 1) 工具使用与自我验证的可靠性;2) 长时程多步任务的稳健性;3) 与具体生产工具(IDE、终端、浏览器、文档)的深度集成。 价格、单点基准成绩仍重要,但权重将下降,智能体场景的端到端任务成功率(end-to-end task success rate)成为更具说服力的指标。
6.5 不确定性与风险因素
- DeepSeek V4 仍是预览版:
DeepSeek 已明确表示 V4 处于预览期,需要根据真实场景反馈进行调整,未给出稳定版时间表。报告中列出的 V4 数据(包括基准成绩与价格)在稳定版发布前可能继续变化。 - 基准数据存在脚手架与污染问题:
OpenAI 在 GPT-5.5 公告中已经标注 SWE-Bench 等评测可能存在记忆性证据(memorization),Anthropic 也指出 Opus 4.7 部分基准与 harness 强相关。 单一基准排名的解读应谨慎。 - Ascend 量产节奏:
DeepSeek 后续降价计划取决于华为 Ascend 950PR 在 2026 年下半年的实际量产进度,任何工艺瓶颈或交付延迟都会改变价格预期。 - 政策与监管环境:
多国监管部门对开源模型与跨境 API 调用的政策仍在演变(部分国家政府机构已限制本机构使用 DeepSeek),具体合规要求会显著影响企业部署的实际选择。
七、结论
2026 年 4 月的连续发布展示了大模型领域 “三足鼎立 + 多元生态” 的格局: Claude Opus 4.7 在编程、知识工作和企业级智能体领域保持高地,GPT-5.5 在通用智能体、多步推理和综合智能指数上夺取头名,DeepSeek V4 则以开源、超长上下文效率与极致性价比改变了行业的成本曲线。
三款模型均已迈入百万级 tokens 上下文时代,但在“能力侧重”、“定价结构”、“开源策略”和“硬件生态”上各有取舍。 对开发者与企业而言,“选择一款模型”的二元思路已经过时——基于业务需求(任务复杂度、延迟容忍度、合规要求、上下文长度)进行的多模型路由,正在成为生产部署的主流模式; Lushbinary 等媒体测算的“60–70% 流量给 V4-Flash + 编码任务给 Opus 4.7 + 通用智能体给 GPT-5.5”的混合架构,可在保持质量的前提下相比单模型方案降低 40–60% 成本。
DeepSeek 与华为的深度协同则提供了另一条独立的演进路径:开源模型 + 国产硬件 + 自研软件栈的全链条协同,如能持续推进,有望在中文及亚太市场形成可观规模; 而能否在更广泛的全球开发者中获得采用,则取决于 CANN 软件栈成熟度、Ascend 950 系列的量产节奏以及生态工具链的完善程度。
总体而言,2026 年大模型行业进入了一个 “能力快速逼近上限、价格剧烈分化、智能体场景重新定义竞争维度”的阶段。 接下来 6–12 个月的关键观察点包括:DeepSeek V4 稳定版与中文社区生态、Ascend 950 系列量产、Anthropic 与 OpenAI 在智能体可靠性上的进一步突破,以及全球监管对开源 AI 与跨境 AI 服务的政策走向。
附录:数据与参考资料
本报告所引用的数据均来自下列公开资料,数据基准日期为 2026 年 4 月 26 日。
一手来源(厂商官方文档)
DeepSeek-AI. DeepSeek-V4-Pro 模型卡. https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro DeepSeek API Docs. DeepSeek V4 Preview Release Notes. https://api-docs.deepseek.com/news/news260424 Anthropic. What's New in Claude Opus 4.7. https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 Anthropic. Claude API Pricing. https://platform.claude.com/docs/en/about-claude/pricing OpenAI. Introducing GPT-5.5 (2026-04-23). https://openai.com/index/introducing-gpt-5-5/ OpenAI. GPT-5.5 Model API 文档. https://developers.openai.com/api/docs/models/gpt-5.5 OpenAI. API Pricing. https://openai.com/api/pricing/
第三方评测与数据机构
Artificial Analysis. GPT-5.5 (xhigh) - Intelligence, Performance & Price Analysis. https://artificialanalysis.ai/models/gpt-5-5 Counterpoint Research(经 CNBC 引用). DeepSeek V4 Preview Analysis (2026-04-24). Omdia(经 Reuters / Manila Times 等引用). 关于 Ascend 与 DeepSeek 合作的分析(2026-04-24/25).
主流科技与财经媒体
Reuters / Bloomberg(BNN). DeepSeek previews new AI model adapted to run on Huawei chips (2026-04-24). CNBC. China's DeepSeek releases preview of long-awaited V4 model as AI race intensifies (2026-04-24). Fortune. DeepSeek unveils V4 model, with rock-bottom prices and close integration with Huawei's chips (2026-04-24). South China Morning Post. Huawei, DeepSeek strengthen China's AI self-reliance with collaboration on V4 model (2026-04-25). VentureBeat. DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th the cost of Opus 4.7, GPT-5.5 (2026-04-25). DataCamp. DeepSeek V4: Features, Benchmarks, and Comparisons (2026-04). Simon Willison. DeepSeek V4—almost on the frontier, a fraction of the price (2026-04-24).
免责说明
1. 本报告为基于公开资料的整合性研究,不代表任何机构或个人的官方立场; 2. 所有基准成绩、价格信息和技术参数均以本报告基准日期为准,后续可能因厂商更新而变化; 3. 报告中的“前景分析”章节为基于已公开信息的合理推演,不构成对任何具体厂商商业胜负或股票走势的预测; 4. 报告内容力求中立客观,如读者发现具体数据存在偏差,以原始一手来源为准。