


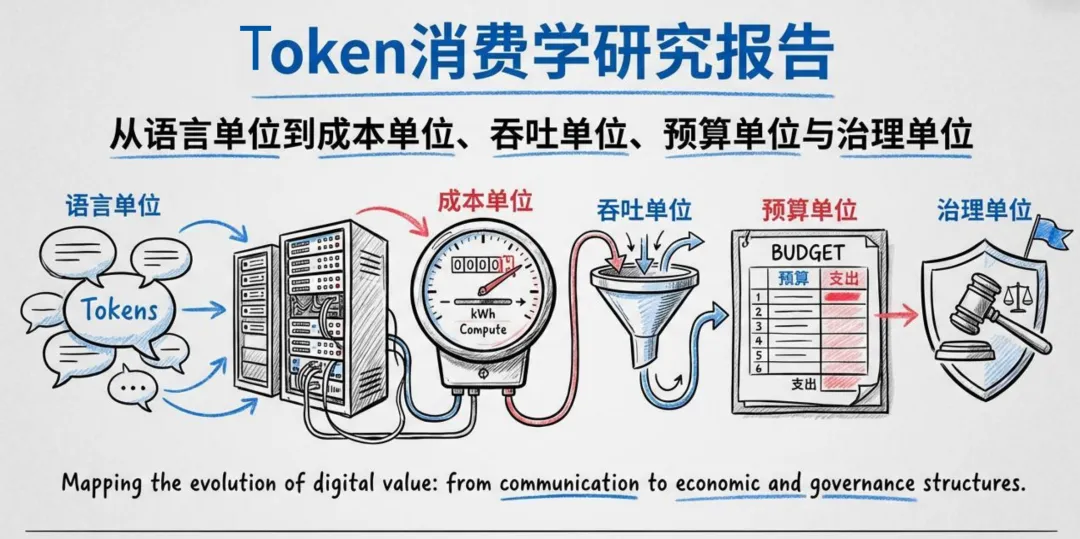
导读:当AI从"玩具"变成"工具",再从"工具"变成"基础设施",一个被长期忽视的经济学命题浮出水面——Token不再只是模型内部的计算痕迹,而是企业经营AI时最稳定、最可计量、最可治理的资源单位。清华大学最新研究报告揭示:2026年前后,Token消费将成为企业独立的经营议题。
一、一个被低估的"万亿级"命题:Token消费学到底是什么?
2024年,中国数字经济核心产业增加值达到140891亿元,占GDP比重10.5%。在这串数字背后,一个更细微但更具决定性的变化正在发生——数字技术应用业增加值占核心产业的44.0%,应用层已经成为数字经济最重要的支点。
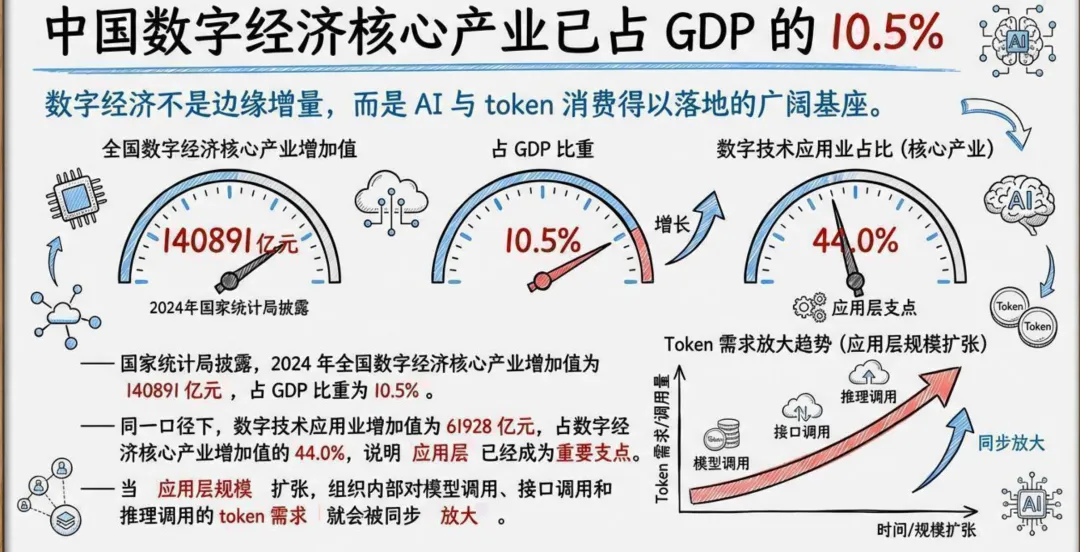
这意味着什么?意味着AI不再只是实验室里的技术突破,而是真正嵌入到了客服、研发、分析、内容和流程系统中。而一旦AI嵌入业务流程,Token就会像带宽、电力和云资源一样持续被消耗。
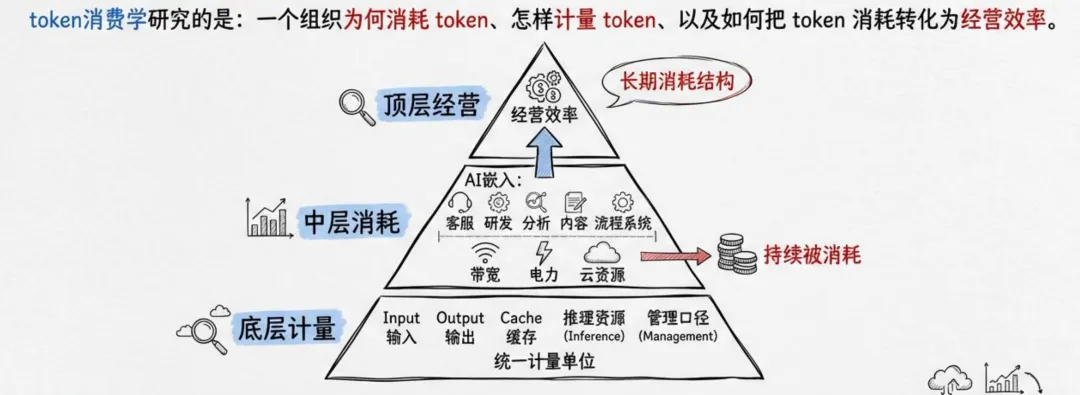
清华大学"清新研究团队"在2026年4月发布的《Token消费学研究报告》中,首次系统性地提出了"Token消费学"这一概念:研究一个组织为何消耗Token、怎样计量Token,以及如何把Token消耗转化为经营效率。
这不是一个技术问题,而是一个经营问题。
报告中的一个核心洞察令人警醒:在大模型场景里,Token是输入、输出、缓存和中间推理资源的统一计量单位,因此天然适合作为管理口径。但大多数企业目前对Token的认知,还停留在"单次问答贵不贵"的层面,而非全组织范围内的长期消耗结构。
二、宏观信号:为什么2026年是Token消费的"分水岭"?
1、供给侧:算力、电力与资本开支的三重扩张
Token消费的前提,是可被调度的供给能力持续扩张。国家数据局披露,截至2025年6月底,中国在用算力标准机架达到1085万架,智能算力规模达到788 EFLOPS(FP16),生成式AI备案数达到439款,较2024年4月增加2.8倍。
但供给扩张的边界在哪里?
美国能源部的数据给出了一个震撼的参照:2023年美国数据中心用电量已达176 TWh(较2014年的58 TWh增长超3倍),占美国总用电量的4.4%。美国能源信息署预计,到2028年,这一数字可能达到325至580 TWh。
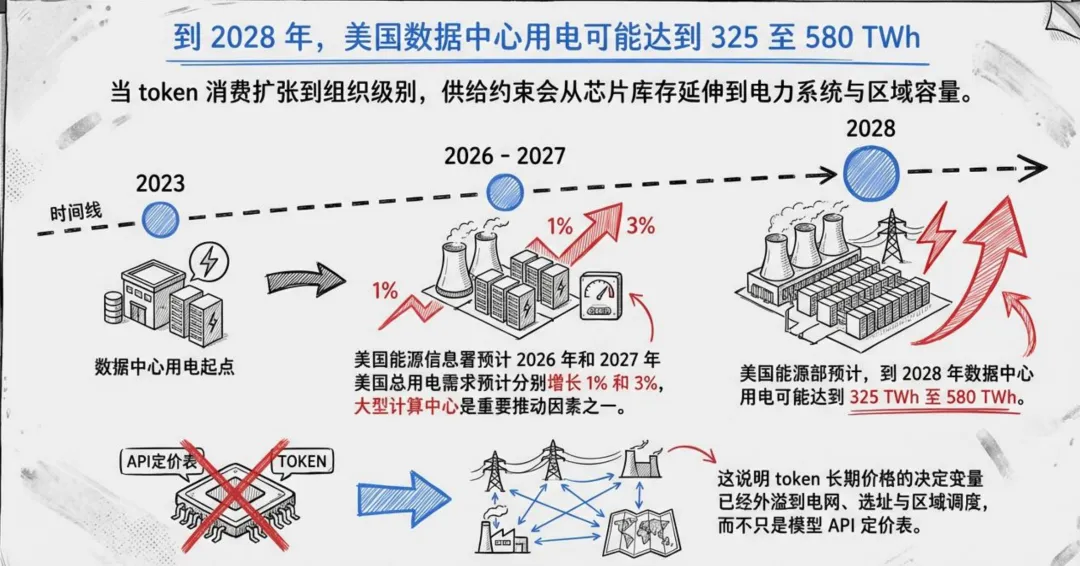
Token不是漂浮在云上的抽象符号,它背后是实打实的电力消耗。当Token消费扩张到组织级别,供给约束会从芯片库存延伸到电力系统与区域容量。这意味着,Token长期价格的决定变量已经外溢到电网、选址与区域调度,而不只是模型API定价表。
与此同时,全球云与平台巨头正在把AI基础设施资本开支抬到新台阶:
Amazon:2025年现金资本开支1283亿美元
Microsoft:2025财年新增物业和设备投入645.51亿美元
Alphabet(谷歌):2025年资本开支预期约850亿美元
Meta:2025年资本开支722.2亿美元,预计2026年将达到1150亿至1350亿美元
大厂资本开支并不等于Token价格立刻下跌,但它决定了未来几年的供给坡度。资本开支并不会直接形成低价Token,而是通过基础设施充足、竞争加剧和调度优化间接传导。
2、需求侧:从"有没有"到"用得好"
美国Census工作论文显示,企业报告"正在使用AI"的比例从2023年秋季的3.7%上升到2024年2月的5.4%,预期到2024年秋季将达到6.6%。按就业加权后的预期使用比例接近12%。
低渗透率与高关注度并存,说明Token消费更像长坡厚雪而非短期爆发。信息业的当前使用率达到18.1%,而建筑业仅为1.4%——行业差异意味着Token消费扩散具有明显的先后顺序。
更关键的是政策导向。2026年政府工作报告提出实施超大规模智算集群、算电协同等新基建工程;国家发改委提出,到2027年新一代智能终端、智能体等应用普及率要超过70%,到2030年相关应用普及率要超过90%。
Token消费并非只发生在工作台,也会扩散到更多终端和日常场景。当智能体成为大量终端的默认能力,Token消费将从集中式采购进一步转向分布式、常态化和后台化。
三、供给侧真相:决定Token价格的不仅是"有没有卡",更是"能不能调度"
报告提出了一个颠覆性观点:供给侧的核心不是"有没有卡",而是"能不能被高效调度"。
国家数据局把新型算力网概括为集算力统筹监测、统一调度、弹性供给与安全保障于一体,这其实是在为Token供给铺路。当前算力资源利用率和供需匹配效率仍有提升空间,说明便宜的Token不一定来自更便宜的芯片,而可能来自更好的调度。
报告构建了一个四要素循环模型:
电力系统决定上限
资本开支决定坡度
算力调度决定斜率
公共云与开源决定普及范围
因此,Token单价下降并不必然代表浪费减少,反而常常意味着需求端会被进一步激活。从经营角度看,最关键的是抓住供给改善窗口,在价格下行时完成口径、台账与路由能力建设。
四、需求侧裂变:为什么Token消耗总比预期增长更快?
1、从单轮问答到流程嵌入:Token消费的"性质变化"
真正拉高总消耗的,不是偶尔"聊一聊天",而是让AI接管更多环节。
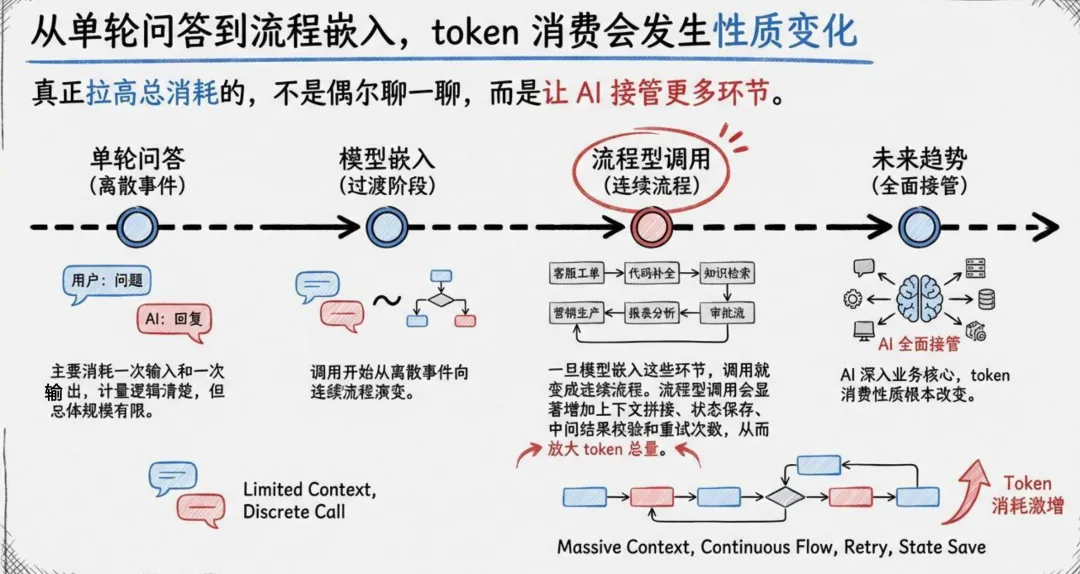
报告将Token消费划分为四个阶段:
单轮问答(离散事件):主要消耗一次输入和一次输出,计量逻辑清楚,但总体规模有限
模型嵌入(过渡阶段):调用开始从离散事件向连续流程演变
流程型调用(连续流程):一旦模型嵌入客服工单、代码补全、知识检索、营销生产等环节,调用就变成连续流程,显著增加上下文拼接、状态保存、中间结果校验和重试次数,从而放大Token总量
未来趋势(全面接管):AI深入业务核心,Token消费性质根本改变
2、长上下文:最容易被低估的Token"放大器"
模型越能看长文档,组织越容易把无差别信息一股脑塞进去。长上下文能力提升后,用户通常不会同步提升信息压缩能力,因此文档、附件、历史记录和制度文本会被整包注入。
这造成了"看起来很稳妥、实际上很浪费"的调用习惯——真正被模型利用的信息密度往往远低于注入总量。长上下文本身会把Token从变量成本推向结构性成本。
3、多轮工作流与Agent:一次任务拆成多次调用
在Agent或工作流系统中,一个看似单一的任务,往往会被拆成检索、规划、调用工具、生成、校验、重写和归档等多个环节。每多一个环节,就多一轮输入输出、多一份系统提示和多一次失败重试,这会形成阶梯式放大。
4、审慎型组织往往比激进型组织更"吃"Token
高风险行业和大型组织通常会要求更长的提示词、更厚的制度背景、更明确的输出格式,以及更多的人工或机器复核。这些做法的好处是降低错误率和责任暴露,代价则是Token消耗显著上升。
在组织内部,最贵的常常不是模型能力,而是为确定性付出的冗余Token。
五、Token的四重经济学角色:钱、速度、预算与盾牌
同一个Token,在企业内部同时扮演四种不同角色:
角色一:成本单位
只要API或推理平台按输入、输出或缓存计费,Token就首先表现为可被结算的成本单位。成本单位视角让组织能够比较不同模型、不同场景和不同团队的单位任务支出,但它只回答"花了多少钱"。
陷阱警示:如果只盯单价,不看任务成功率、延迟、复用和治理成本,就会把低价错认成低成本。
角色二:吞吐单位
系统能否稳定跑起来,常常受限于每秒可处理多少Token。并发量、响应速度和队列积压,本质上都与单位时间内能够处理的Token数量相关。
在生产环境里,很多团队先遇到的不是价格问题,而是高峰期吞吐不足导致的排队问题。
角色三:预算单位
当AI从试验转向常态运行,Token就会进入预算表。在试验阶段,Token往往被记在研发费用、创新项目或部门杂项里,看起来不大,也难以持续管理。一旦业务开始稳定依赖AI,Token支出就会像云资源和SaaS一样进入预算编制、月度复盘和部门考核。
预算单位的意义在于把调用行为纳入经营纪律,使扩张有边界,优化有抓手。
角色四:治理单位
只有被记录、被归因、被审计的Token,才适合在组织里放大规模。治理单位视角关心的不只是成本,还包括权限、留痕、风控、隐私和责任追溯。
在高风险场景下,能被审计的Token往往比账面更便宜的Token更有价值。
这四种角色之间会不断相互转化:吞吐不足会抬高隐性成本,治理不足会让预算失真,预算约束又会反向推动模型路由与缓存策略。真正成熟的Token管理不会只优化某一项,而是同时兼顾效率、质量、成本与合规。
六、五大原创机制:Token消费的"经济学解剖"
报告提出了五个可观察、可讨论的消费驱动机制:
1. 上下文税
上下文税 = 无差别上下文注入 - 被真实使用的信息密度。
当输入总量持续增加,而真正影响生成结果的关键信息比例并没有同步上升时,额外消耗的那部分Token就形成了上下文税。这不是技术故障,而是一种组织性浪费——来自缺少信息压缩、模板治理和检索边界。
2. 输出通胀
输出通胀 = 安全冗余 + 模板冗余 + 组织审慎叠加。
很多组织为了降低风险,会要求模型写得更完整、更礼貌、更可追责,于是不断叠加免责声明、格式模板和解释性语言。输出通胀的本质,不是模型太啰嗦,而是组织把确定性需求转化成了输出冗余。
3. 调度折价
调度折价 = 统一监测调度 + 模型路由 + 缓存复用 + 任务分级带来的单位任务成本下降。
同样的底层算力,如果能够按任务难度、时效要求和可复用程度进行调度,组织就不必让所有请求都走最贵的路径。这种因为调度改进而获得的成本下降,不依赖更便宜的芯片,属于经营能力带来的折价。
4. 预算内生化
预算内生化 = Token从研发测试指标转变为组织内部常规预算科目。
预算内生化意味着Token不再只是技术团队的事,而会成为财务、采购和业务共同管理的经营变量。
5. 合规溢价
合规溢价 = 可审计Token的部署价值 - 不可追踪Token的名义低价。
能够被记录、审查和回溯的Token,虽然账面单价不一定最低,却更容易进入核心流程和高价值场景。合规能力会转化为真实部署价值。
七、四阶段演化:你的企业处于哪个阶段?
Token消费会经历从模型红利到经营内生的四段路径:
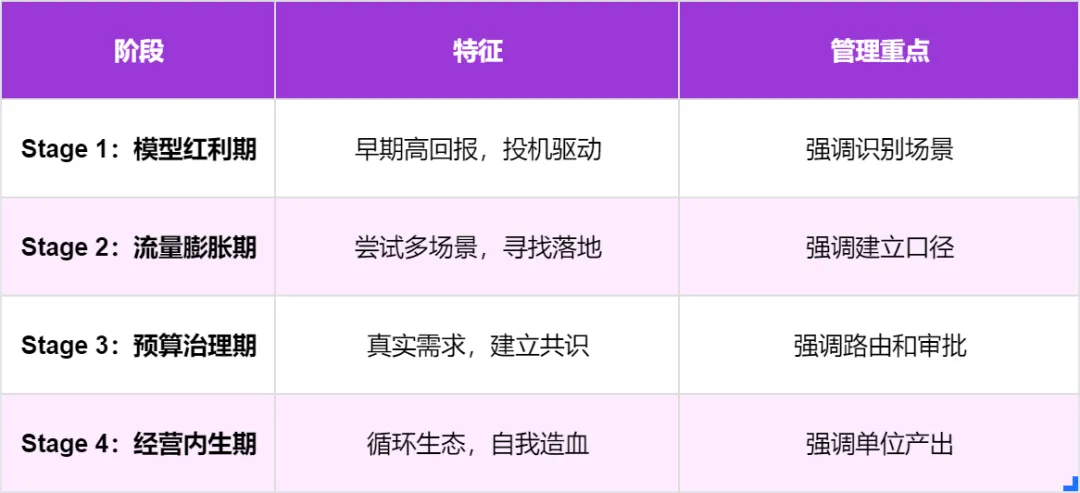
阶段错配会导致两种常见问题:一是过早管死创新,二是过晚补治理,最后双输。
进入经营内生期后,组织不再把AI调用看作单独实验,而把它视作流程、产品和服务的一部分。此时最重要的指标不再是Token总量本身,而是单位Token产出多少收入、多少效率和多少确定性。
八、企业如何建立Token经营体系?五步落地法
报告提出了建立Token经营体系的五个关键步骤:
第一步:建立统一口径与计量台账所有优化都建立在可比、可归集、可追踪的口径之上。台账不是为了追责,而是为了找到真实的消耗结构,从而识别哪些地方应该压缩、复用或分流。
第二步:把Token正式纳入预算制度建议按团队、场景和任务类型设置预算视图,而不是只看一个全公司总额。月度复盘应同时看Token消耗、任务完成量、单位任务成本和关键结果指标,避免把省钱误当成效率。
第三步:用模型路由和缓存复用,主动制造调度折价简单任务优先走轻模型,复杂任务再升级到强模型;高频重复问题应优先通过缓存、模板和结果复用解决。本质是让不同价格带的Token各自承担最适合的工作。
第四步:建立分级服务与审批闸门不是每个请求都值得走最昂贵、最完整的处理路径。高价值、高风险任务配置更强模型和更严格审计;低价值、低风险任务采用更轻模型和更宽松策略。
第五步:把日志、审计与风控接入日常管理能放量的前提,是出了问题之后知道发生了什么。只有治理链路完整,Token才能从实验室走向高价值核心流程。
九、中国组织的特别机会窗口
当算力网络、公共云、备案体系与终端普及率目标同时存在,中国组织有机会在价格下行期完成能力建设。
全国一体化算力调度、公共云支持、开源社区建设和算力券政策,构成了一个相对独特的普惠供给环境。这意味着中国组织未必需要等到最强模型稳定后再入场,而可以在供给改善过程中同步建设口径、预算、路由和治理能力。
越早把Token当成经营对象,越有机会在未来的普及阶段获得更高的单位产出。
十、Token消费学的三重结论
结论一:Token已经从技术指标变成经营指标判断AI落地深度,越来越要看一个组织如何采购、调度、归集和审计Token。组织管理Token的方式,本身就是其AI经营成熟度的体现。
结论二:未来的关键不是"省Token",而是"提高单位Token产出"只追低价,可能换来更差的质量、更慢的吞吐和更弱的治理,最后并不便宜。Token消费学的核心目标是经营最优,而不是局部最省。
结论三:先建立体系,再等待普及红利对多数组织来说,最好的时点不是"等一切确定后再做",而是在供给改善期先把体系建好。当行业进入更大规模普及时,已经准备好的组织会用更低摩擦把Token转成真实收益。
......
在水木人工智能学堂公众号对话框回复关键词ai12826,可获取《清华大学2026年Token消费学研究报告》的报告下载链接。



