斯坦福2026年AI指数发展报告(一):研究和发展
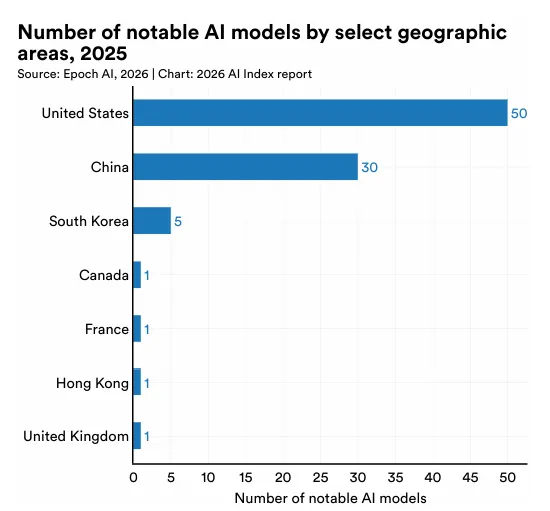
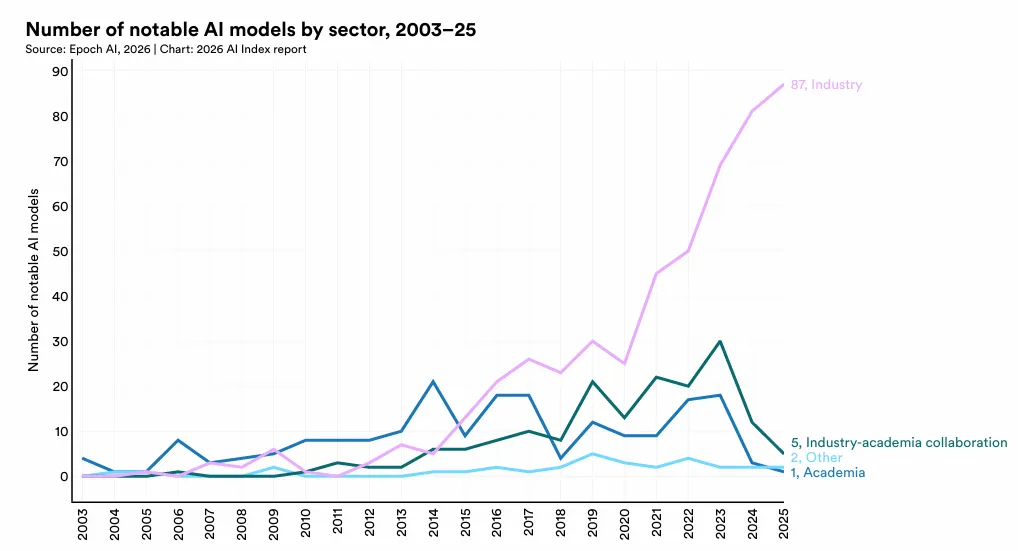
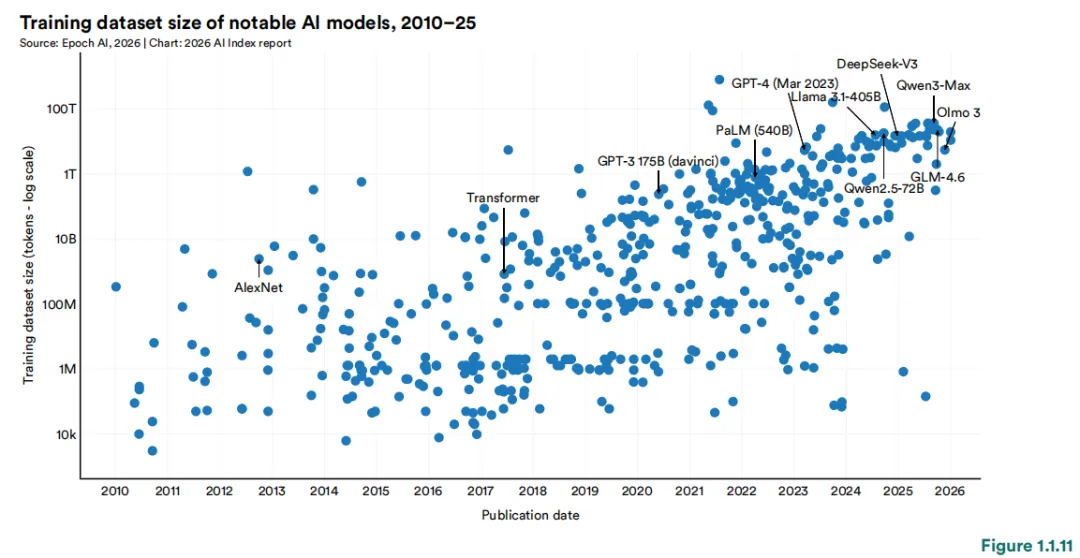
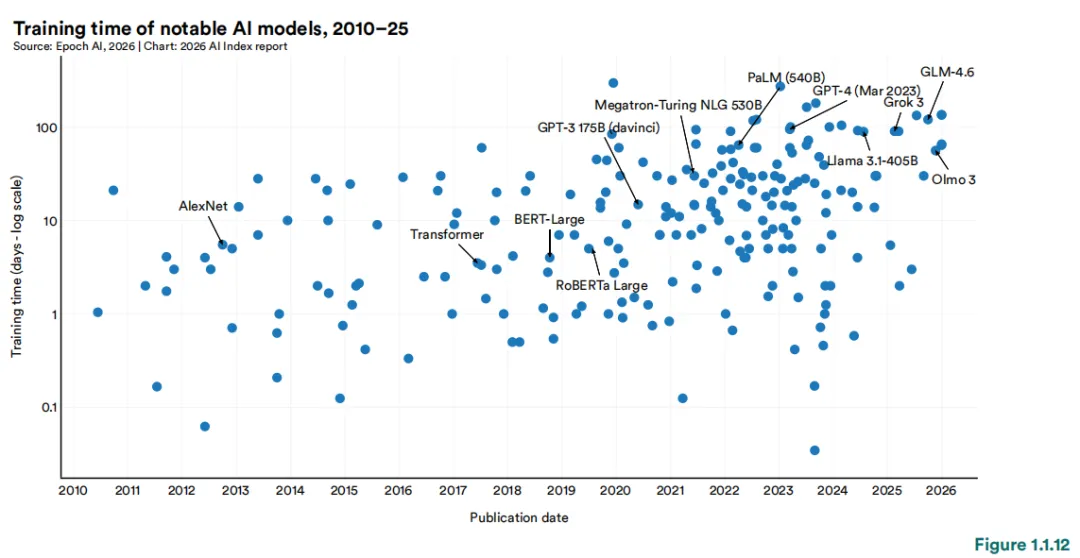
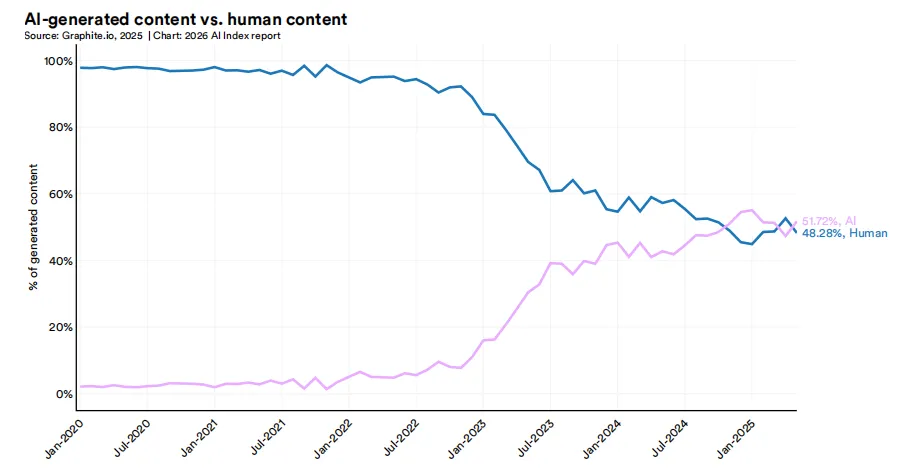
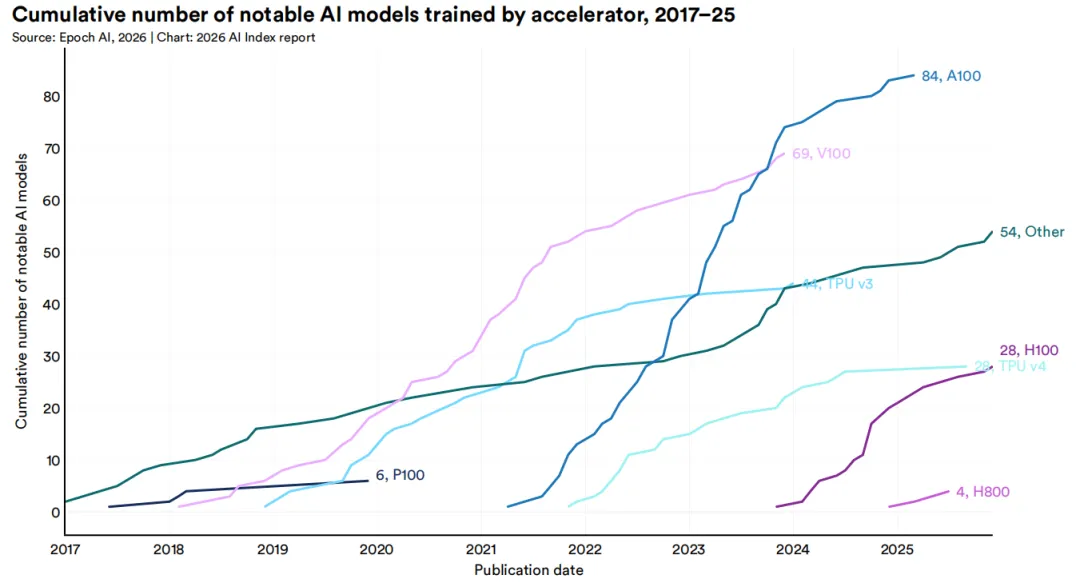
1 中美AI模型性能差距已基本消除。自2025年初以来,中美两国模型多次交替领先。2025年2月,DeepSeek-R1曾短暂追平美国顶级模型;截至2026年3月,Anthropic的顶级模型仅领先2.7%。美国仍在顶级AI模型数量和高影响力专利方面保持优势,而中国在论文发表量、引用量、专利产出和工业机器人安装量方面领先。韩国凭借其创新密度脱颖而出,在人均AI专利数量上位居全球第一。2 美国拥有5,427个数据中心,超过任何其他国家的十倍以上,其能耗也几乎超过所有其他国家。3 美国在AI投资方面领先,但其吸引全球人才的能力正在下降。 2025年,美国私人AI投资达到2,859亿美元,是中国124亿美元投资的23倍以上——不过仅看私人投资数据可能低估了中国的AI总支出,因为中国还有政府引导基金。美国在创业活动方面同样领先,2025年有1,953家新获融资的AI公司,超过第二名国家的十倍以上。然而,移居美国的AI研究人员和开发人员数量自2017年以来下降了89%,仅在过去一年就下降了80%。4 AI带来的生产力提升正出现在许多入门级就业开始下降的领域。 研究显示,在客户服务和软件开发领域,生产力提升了14%至26%,而在需要更多判断力的任务中,效果较弱甚至为负。AI智能体正在为几乎所有业务功能开发面向消费者的AI工具。在软件开发领域——AI可衡量的生产力提升最为显著——美国22至25岁的开发人员就业人数从2024年起下降了近20%,而年长开发人员的数量仍在增长。5 AI的环境足迹随着其能力的提升而不断扩大。 Grok的估算训练排放量达到728.16亿吨二氧化碳当量。AI数据中心电力容量上升至29.6吉瓦,相当于纽约州的峰值用电需求,仅GPT-4的年度推理用水量就可能超过1,200万人的饮用水需求。6 全球AI算力容量自2022年以来以每年3.3倍的速度增长,达到1,710万个H100等效单位。 英伟达占据了总算力的60%以上,Google和Amazon提供了其余大部分算力,华为占有较小但不断增长的份额。算力扩张由超大规模数据中心的扩展以及对前沿模型训练和推理的持续需求驱动。从历史上看,美国在总产出数量上一直位居首位,其次是中国。这一格局在2025年延续——美国以发布50个知名AI模型领先,中国为30个,韩国为5个。所有主要地理区域的新模型发布数量均出现了同比下降。知名AI模型的开发继续以产业界为主导,在过去十年中,产业界产出的占比稳步增长,目前已以较大优势占据最大份额(91.6%)。在产业界内部,少数组织占据了大部分发布份额。2025年,贡献最多的机构为OpenAI(19个)、Google(12个)和阿里巴巴(11个)。自2014年以来,Google产出的知名模型数量最多,其次是Meta和OpenAI。在学术界内部,清华大学(26个)、斯坦福大学(26个)和卡内基梅隆大学(25个)是过去十年中产出最多的机构。回望2010年代初期至2022年,AI模型的参数数量经历了一段惊人的爆发期。驱动这一增长的因素是多方面的——模型架构不断推陈出新、训练数据日益丰富、算力硬件持续迭代,以及业界一次次验证了"规模即能力"的规律。但2022年之后,情况悄然发生了变化。从公开数据来看,参数增长的曲线似乎趋于平缓。不过,这一"平缓"很可能只是表象。近年来,OpenAI、Anthropic、Google等前沿实验室密集发布了多个资源密集型模型,却几乎不再披露参数规模、训练数据集大小或训练时长等关键信息。数据的缺失,让我们难以窥见这场竞赛的真实全貌。训练数据集和训练周期的故事也类似。进入2020年代,领先模型的训练词元数已达数万亿量级,训练周期动辄超过100天。但同样由于前沿实验室的披露日益保守,我们能掌握的近期数据并不完整。性能提升日益依赖现有数据集的质量优化,而非单纯获取更多数据。研究人员不再不加区分地扩展数据规模,而是投入更多精力对训练输入进行筛选、整理与精炼。数据中心化方法强调通过清洗标签、去重样本、构建高质量数据集等方式提升模型表现。大量研究证实,在低质量或污染数据上训练会严重损害性能;同时,筛选最具信息量的训练输入进行数据修剪,往往优于盲目使用全部数据的训练策略,最新研究表明,合成生成数据在包含微调、对齐、指令调优和强化学习的后训练场景中能有效提升模型性能。2025年发布的多项研究支持这一结论:合成后训练数据在少样本生成、长上下文能力优化、强化学习工作流增强及更广泛的推理能力提升等方面均显现实效。自2022年11月ChatGPT发布以来,互联网将被AI生成内容淹没的预测持续不断。Graphite近期研究显示,2025年1月起超50%的新增网络内容由AI生成。有预测认为2026年该比例可能进一步攀升。知名AI模型的硬件采用模式反映了性能与效率的提升。自2017年以来,使用A100级硬件训练的模型累计数量持续增长,2025年达84个模型。上一代硬件V100仍占据可观份额(69个模型)。新一代硬件如H100的早期采用速度迅猛(28个),而TPU v3和TPU v4等其他类别则呈现稳定增长曲线。
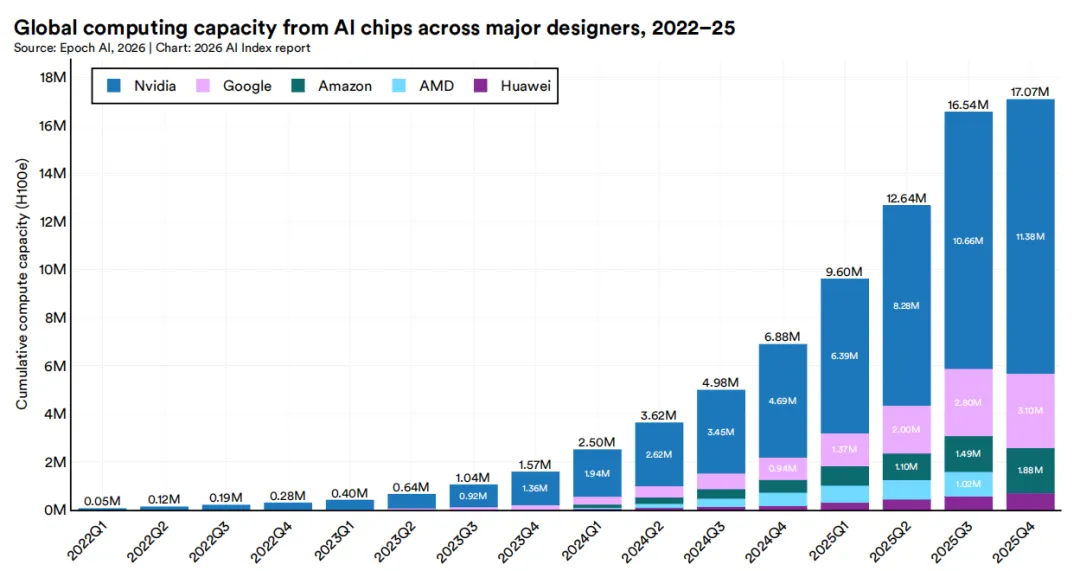
主要芯片设计商提供的AI计算能力持续增长。自2022年以来,总算力规模估计每年增长3.3倍,达到约1710万H100当量。英伟达AI芯片目前占总算力的60%以上,谷歌和亚马逊供应剩余大部分份额,华为则持有虽小但不断增长的份额。头部AI企业正大幅增加资本支出,基础设施已成为私人AI融资中增长最快的重点领域。
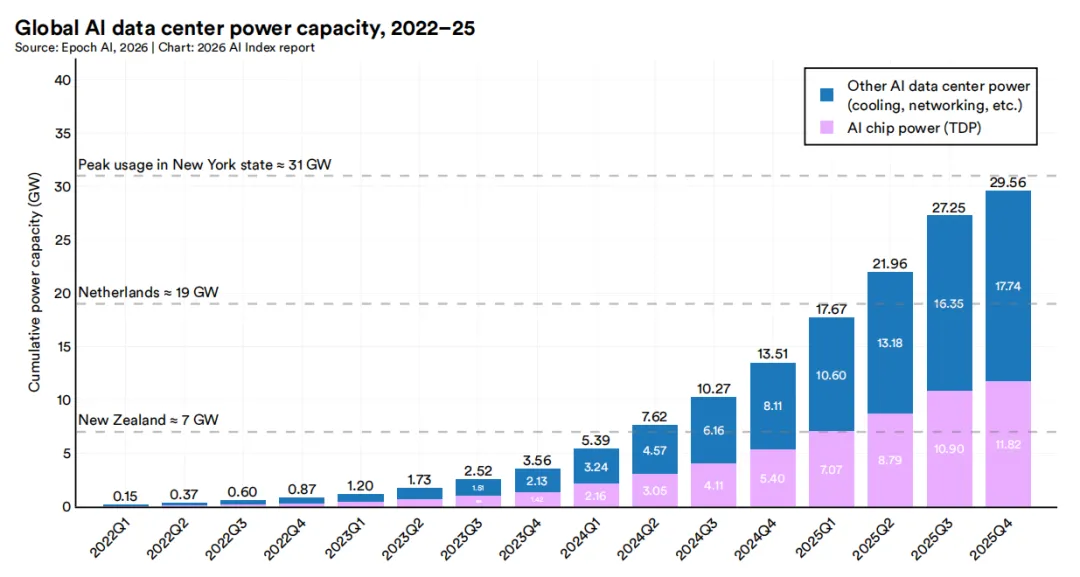
算力扩张伴随着直接的能源成本。截至2025年第四季度,AI数据中心总电力容量达约29.6吉瓦,足以满足纽约州峰值用电需求。其中AI芯片功耗(以热设计功耗计量)约占11.8吉瓦,其余部分归因于冷却、网络及其他数据中心基础设施。数据中心是算力的物理载体,其容量、地理分布及供应链构成直接影响AI系统的构建能力与布局。现代AI数据中心依赖算力、存储、通信及专用硬件的协同组合,以支持大规模AI系统运行。尽管GPU(图形处理器)和张量处理单元(TPU)等定制加速器最受关注,但它们仅为更广泛基础设施堆栈中的一层。这些芯片处理的所有数据均存储于高带宽内存(HBM)中,以实现海量数据的高效进出。训练过程中,GPU需持续相互共享数据,这要求通过光纤电缆运行InfiniBand等高带宽网络架构,实现高速、高吞吐量的网络连接。硬件背后的供应链构成另一维度。英伟达和SK海力士等企业仅负责芯片设计,而不参与制造;它们将设计交付给专业半导体代工厂,主要为台湾积体电路制造公司(台积电)和三星晶圆厂,由其以现代AI硬件所需的纳米级工艺制程芯片。制造完成的芯片随后由日月光集团(台湾)和安靠技术(美国)等封装测试企业进行封装与测试。台积电是全球AI供应链中的关键依赖点,几乎制造所有领先AI芯片,包括英伟达的Blackwell GPU和AMD的MI300X。各环节均存在极高准入壁垒,需要数十年积累的专业知识、专用设备及巨额资本投入。
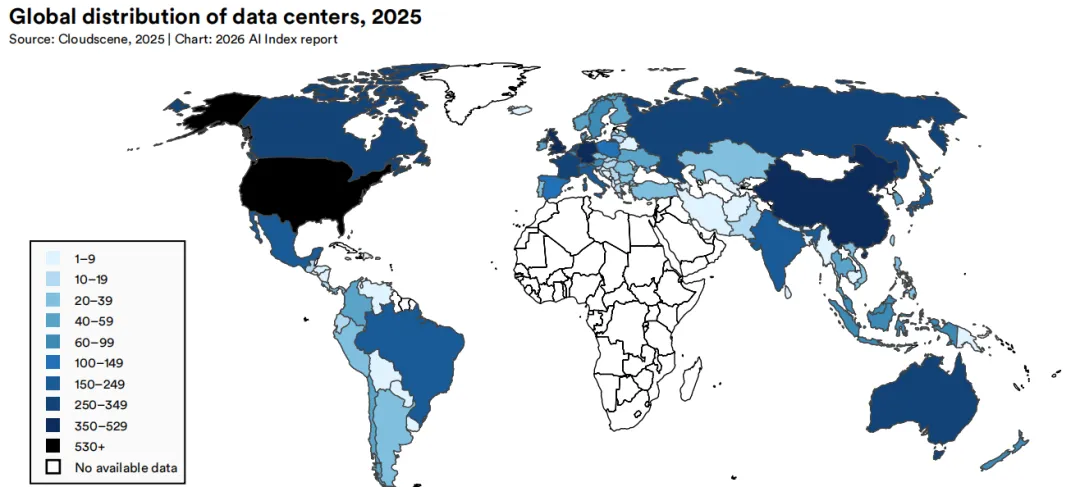
全球大部分数据中心基础设施集中分布在少数国家。2025年,美国以5,427座数据中心大幅领先,数量超过其他任何国家的10倍以上。德国(529座)、英国(523座)和中国(449座)紧随其后,而其余大多数国家各自拥有的数据中心设施均不足300座。尽管美国优势明显,但需注意的是,数据中心数量无法反映设施规模、计算能力或利用率等差异。
自2016年以来,领先机器学习硬件的能效显著提升,以每瓦特浮点运算次数(FLOP/s)衡量。当前顶尖芯片的能效约为十年前的10倍,其中英伟达B200和谷歌TPU v5e表现最为突出。然而,模型规模的增速超过了能效改进速度,导致训练前沿系统的总功耗持续攀升。自2010年代初以来,模型训练的总功耗已增长数个数量级。数据集中计算强度最高的模型(如Grok 3和Llama 4 Behemoth)训练期间功耗高达1亿瓦以上。由于开发者披露有限,许多最新模型的功耗数据尚未公开。
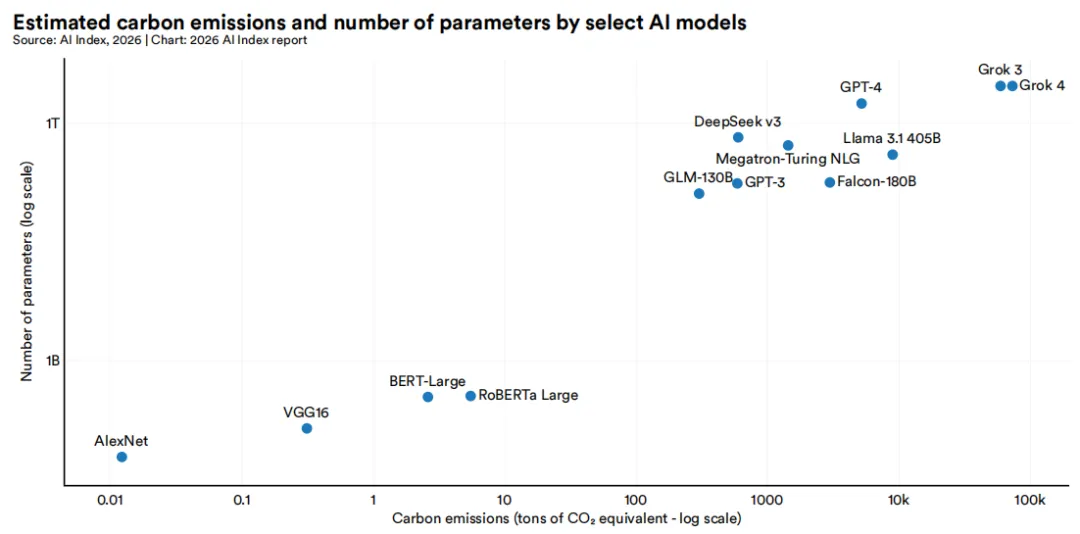
训练产生的碳排放增长更为迅猛。2012年训练AlexNet约产生0.01吨二氧化碳当量,而2025年训练Grok 4约产生72,816吨。作为参照,这超过了一辆普通汽车的全生命周期碳排放量(63吨)。大型模型通常排放更多碳,但并非绝对——硬件能效、训练时长及所用能源的碳强度均会影响结果。例如,DeepSeek v3的碳排放约为597吨,远低于同等规模模型。
训练成本历来最受关注,但推理正逐渐成为AI总能耗中占比更高的部分。模型大规模部署后,服务查询所需的累计能耗可能在数月内超过一次性训练成本。
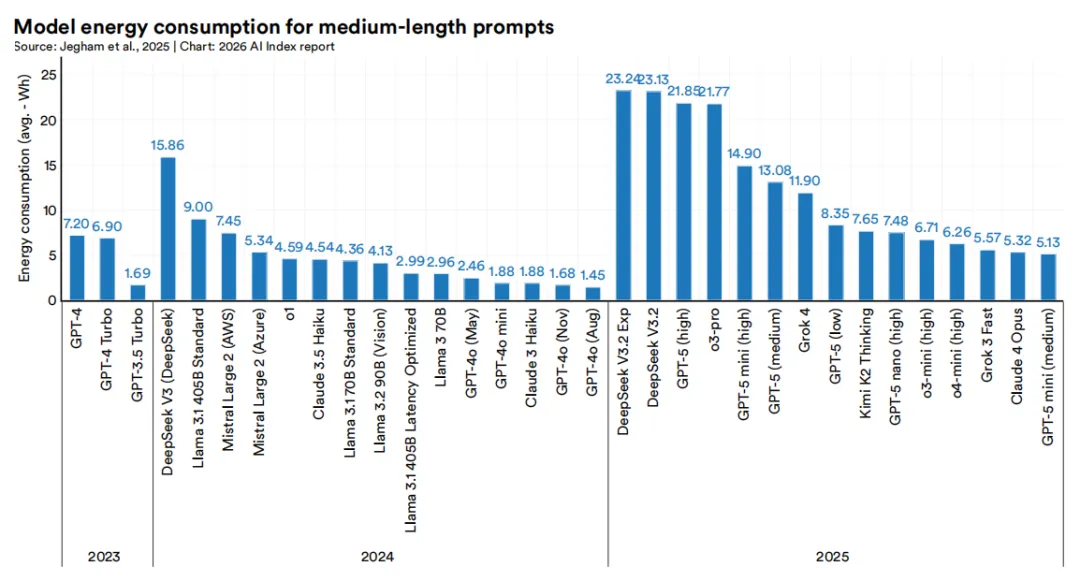
Jegham等人(2025)近期的基准研究针对中等长度提示词(约1,000个输入词元和1,000个输出词元)提供了各模型的推理能耗与碳排放估算。2025年能耗最高的15个模型中,DeepSeek V3.2 Exp和DeepSeek V3.2单次查询能耗最高(23 Wh),GPT-5(高算力版)以21.9 Wh紧随其后。Claude 4 Opus和GPT-5 min(中等算力版)等模型处于低功耗端,能耗为5-6 Wh。
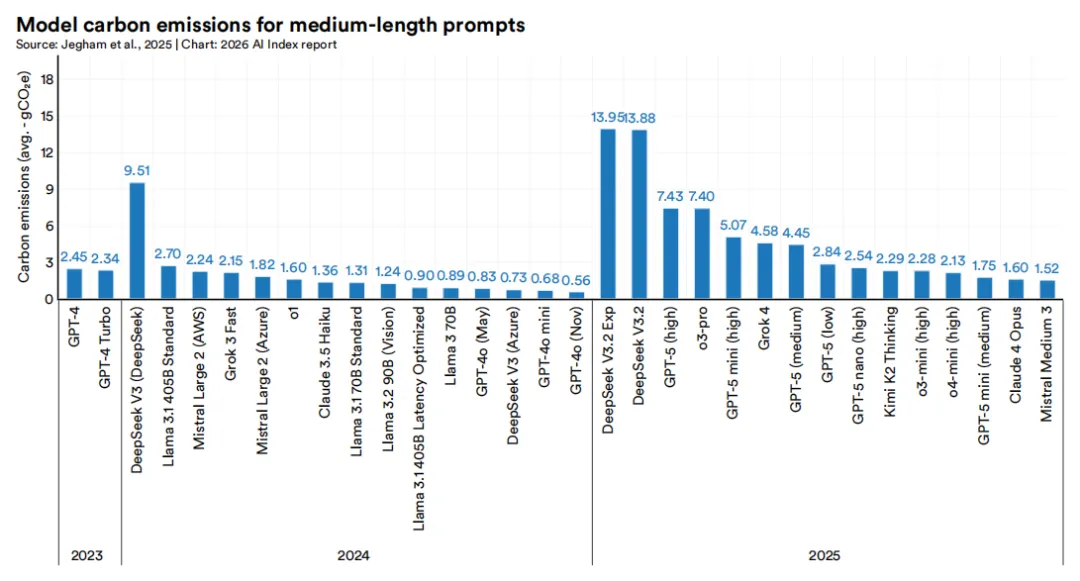
按碳排放排序也呈现相似规律。DeepSeek V3.2 Exp和DeepSeek V3.2每处理一个中等长度提示词产生的碳排放最高,各约14克二氧化碳当量。相比之下,Claude 4 Opus和Mistral Medium 3最低,分别为1.6克和1.5克。即便同年份发布的模型间也存在显著差异,不仅体现推理效率的分化,更说明更高能力未必与环境成本成正比。
单次查询的能耗数字看似温和:一次简短的GPT-4o查询约消耗0.42瓦时,比谷歌搜索(0.3瓦时)高出40%;每日进行八次中等长度查询的能耗(9.7瓦时)相当于给两部智能手机充电。但在数亿次日查询的规模下,总能耗将膨胀至惊人水平。水耗同样呈现规模放大效应:GPT-4o推理的年耗水量估计在1.3-1.6千升之间,仅上限值就超过1200万人一年的饮用水需求总量。
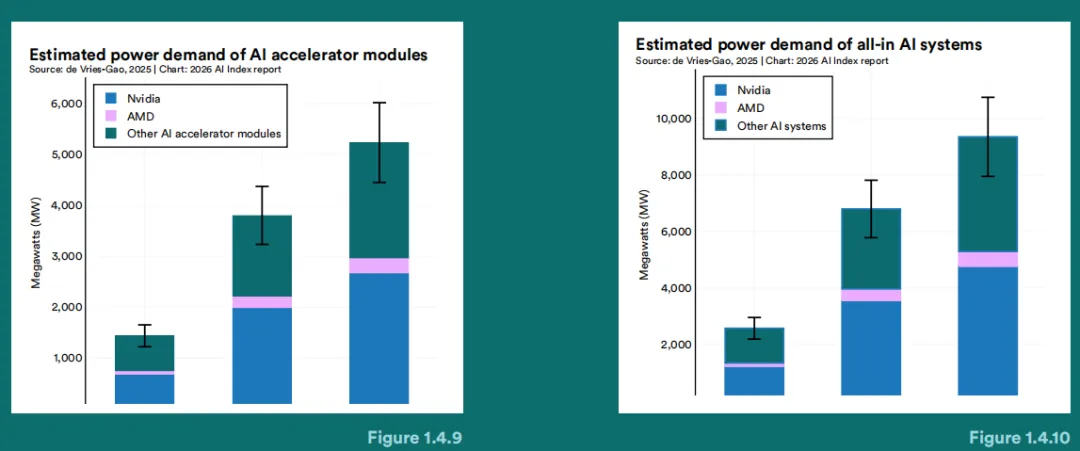
模型与查询的查询的功耗需求累积形成了更为庞大的基础设施足迹。截至2024年,AI加速模块的累计功耗需求估计达到约5,200兆瓦。英伟达占据了最大份额,这与其在全球AI芯片容量中的领先地位一致。当包含支持这些加速器的完整系统(服务器、冷却、网络)时,估计需求达到约9,400兆瓦。然而,de Vries和Gao(2025)的这些数据因利用率的差异和设施级效率的不同而存在不确定性。
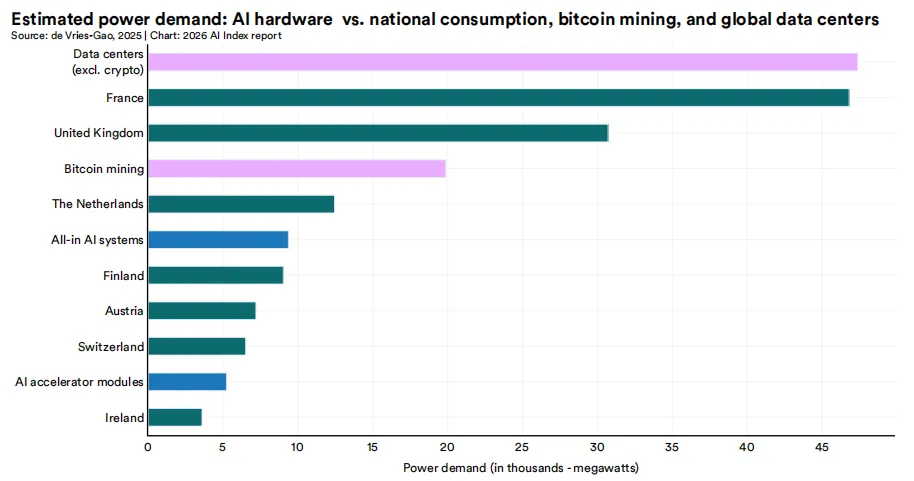
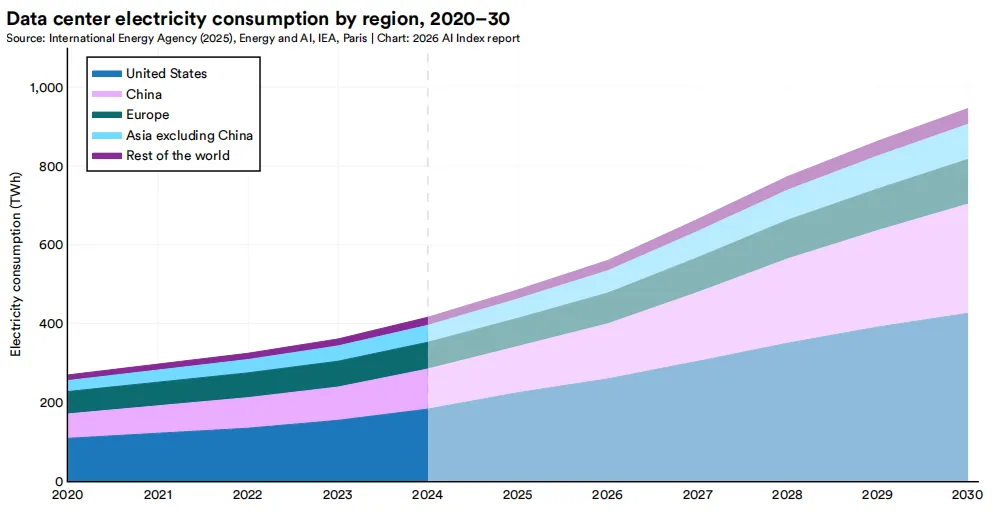
为了更直观地理解这一规模,全球AI系统的累计功耗需求可与瑞士或奥地利的全国用电量相类比,约为比特币挖矿功耗的一半。若排除加密货币领域,全球数据中心以约47,000兆瓦的功耗需求位居首位,而AI硬件在其中占比持续增长。然而,成本却呈相反趋势。自2006年以来,GPU计算成本下降了99%以上。这一下降是本章所述规模扩张趋势的关键支撑,使得在当前水平上训练和部署模型在经济上可行——若放在十年前,这种规模将因成本过高而不可行。在区域层面,所有主要地区的数据中心电力消耗均持续上升,预计到2030年仍将保持增长态势。美国占比最大,其次是中国、欧洲和亚洲其他地区。