


写在前面:
本文为 AIGC 短片《带你去玩球!》的技术和创作拆解,全文约一万字。
作为用来递交电影节的技术性说明文档,本文没有过多故事性的讲述,只采用简洁的语言阐述影片制作的思考和技术点。
因此,它很枯燥,当然你也可以理解为它很干货,所以我仍决定将其开源。
而如果你更想听听我的创作幕后故事,欢迎你等待我的“万字复盘版”内容和视频节目。
但如果你只想了解枯燥的技术和我的创作流程,那么本文应该会对你产生一点帮助,Enjoy it!
作者:大羽玩AI(全网同ID)
一:创意起源
这条作品是 26 年 3 月份,我一个人花费 15 天左右制作完成的,其创意其实起源于 25 年底的一个被废弃的方案。
那时候我去参与了海南岛国际电影节的线下 AIGC 黑客松的比赛,比赛需要创作者在规定时间内,根据随机挑选的主题来进行短片创作。
其中一场赛段,随机抽出的主题之一是:“送信人”。
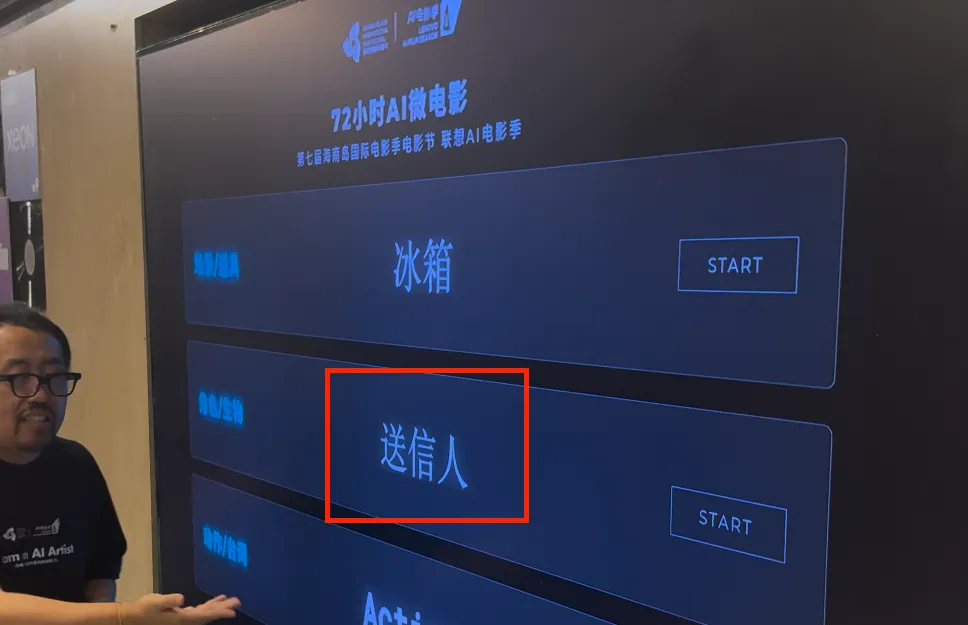
我和队友构思了很多方向,其中一个方向,就是本片创意的原型。
那时候,我去海南参加这个比赛,需要从杭州离家一周左右的时间,家里的小狗“阿呆”因此就只能独自在家了。
家里有自动喂食器,我也找了一个上门喂养的人每天来遛狗,但每天也只有一两个小时有人陪她,剩余的时间,她就趴在门口的位置,一听到门口有动静,就极专注的去听,是不是我回家了。
虽然平常待在一起的时候,我经常不耐烦(因为她非常粘人),但真离开她了,每次看到监控,我就无比难过。
于是一种愧疚和担心的复杂情绪,在那几天一直萦绕着我。
也正是如此,拿到“信”这个概念的时候,我自然展开想象:
“在狗的心里,我出门这么久,是去干什么了呢?”
“或许是出门给她打猎?或者被怪兽抓走了?”
我很好奇狗会怎么想。
“那狗会不会想出来找我呢?大概率会吧,毕竟她这么粘人。”
回到赛事中“送信人”的命题,我想这封信不一定非得是实体的某个物品,狗出门寻找主人的那份爱,其实也可以算是一封她想要送出的“信”。
但转念一想,狗狗的思想或许不会这么复杂和抽象,她们的世界大概率非常简单。
因此我展开了更加有趣的一个想象:
“在人的视角下,狗最爱的东西是网球,至少我家狗是这样的。因为她每天都叼着球,放在我面前,想让我给她扔球玩,即使我正在吃饭、睡觉、甚至上厕所。”
“那在狗的视角下,有没有一种可能,其实狗认为网球反而是人最爱的东西。”
“逻辑上也能够成立,因为狗爱主人,所以狗自然想让主人开心。而每次主人陪狗玩球的时候,主人都是开心的(毕竟我不开心的时候肯定没心思陪狗玩),这种现象对于头脑简单的小狗来说,她可能就会将「球」和「主人开心」这两件事画上等号。”
“在这个逻辑下,狗如此痴迷于将球扔给主人,其动机很有可能就是因为她觉得:球是主人最爱的东西,她要陪主人玩。”
所以最终的那个“信件”,我觉得就应该是一颗球。
(本片片名《带你去玩球!》中的那个“你”,其实也是此用意,它既代表狗、也代表主人。)
想到这,再想想两千公里外,家里趴在门后等着我回家的阿呆,在比赛现场,我忍不住哭了。
因此我们毅然决然的选择了这个方向进行创作,但不幸的是:在赛段进行到一半的时候,我们只完成了几颗镜头的制作,离成片遥遥无期。按照那个进度,必然无法按时完成,本着“先做完,再做好”的原则,我们立即替换为制作难度更小的备用方向。
但我知道,我早晚有一天会把这个故事拍出来,让世界看到一只小狗的勇气和爱。
此后的两三个月中,我时不时会冒出关于本片的零散创意,比如小狗眼中的世界到底是什么样的?人类习以为常的城市在狗的眼中会不会如同洪荒巨兽?我如何既真切、又生动的呈现小狗的所思所想?诸如此类。
最终在 3 月初,我完成了初步的剧本创作,然后闭关了 15 天的时间,将片子制作了出来。
截止本技术白皮书完成之际,本片已经收到了北京国际电影节的入围通知,也收获了无数网友的喜爱、鼓励和泪水,这对我来说是一种莫大的鼓励,至少我确定了一点:
“可能你的故事很简单,技术也不够完美,但你讲的是能够打动你自己的故事、你表达的是你知道“自己必须要表达”的情绪、你创作的是你知道“它就应该是这样”的作品,那就够了。
感谢你来听我的想法,以下是偏向“技术”的拆解和分享。
二:剧本&分镜
2.1、剧本
这方面,我的创作流程比较个人化。
剧本创作阶段有 AI 的参与(大语言模型,主要是 Gemini),比如我会让 AI 来想象:狗狗眼中的世界是怎样的。
AI 给了我很多有趣的点子,比如路边扫地工人的吸尘机器,在狗的眼中是一个“会将全世界吸进去的怪兽”;以及最终成片中用到的“狗可能会将自己代入到抓娃娃机中的娃娃”等等。
但这些点子或多或少有点过于“童话”了,一开始我甚至想,要不要将狗眼中的世界,或者说整条片子的视觉风格和视觉元素,彻底变成一个“异世界”,然后通过交叉剪辑的方式,来突出这个反差感。
但最终我还是决定,尽可能写实,只在该强化的地方强化,避免为了有趣而有趣。
因此只选择了像娃娃机这种既写实又有趣的点。
此外,在例如剧本结构、故事发展之类的点上,也和 AI 进行过深入探讨, 但更多的是多一个不同的视角,虽然大语言模型并无主观意识,但仍然可以给出很多不错的观点,更重要的是:很多最终成型的灵感,可能只是源于 AI 提供的一句话或一个词,引发了你新的思考和想象而诞生的。
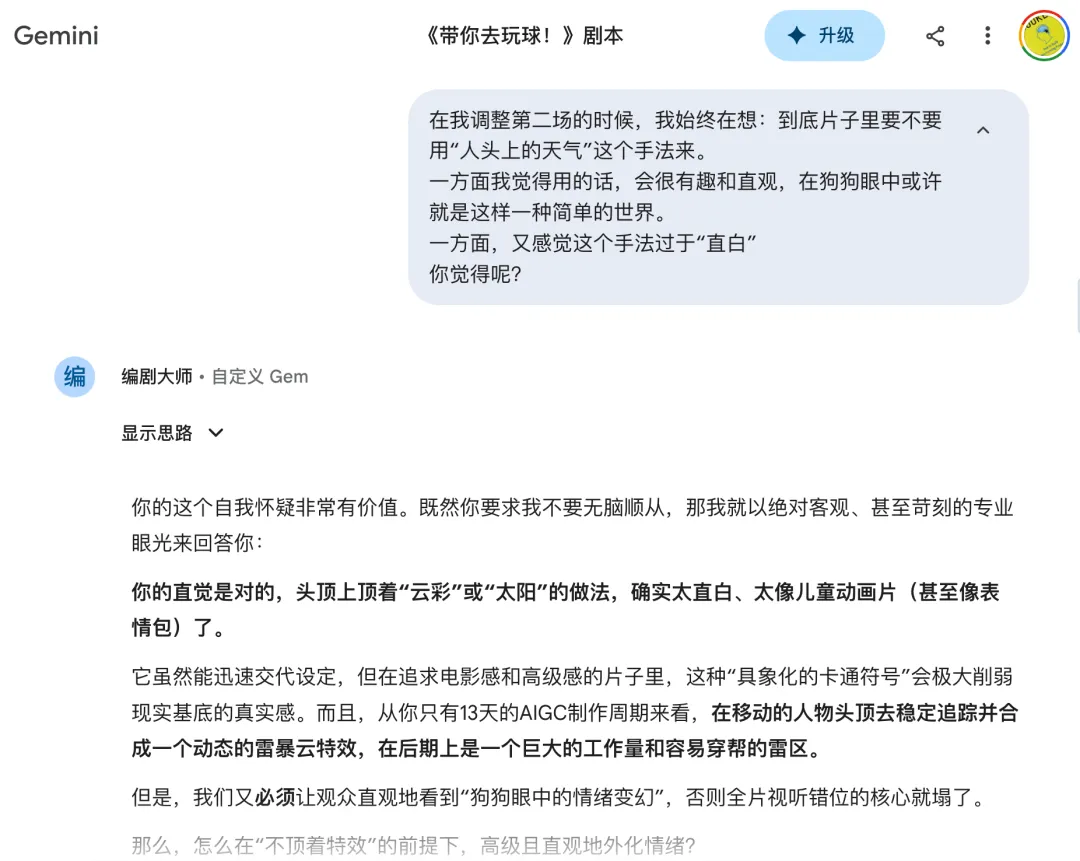
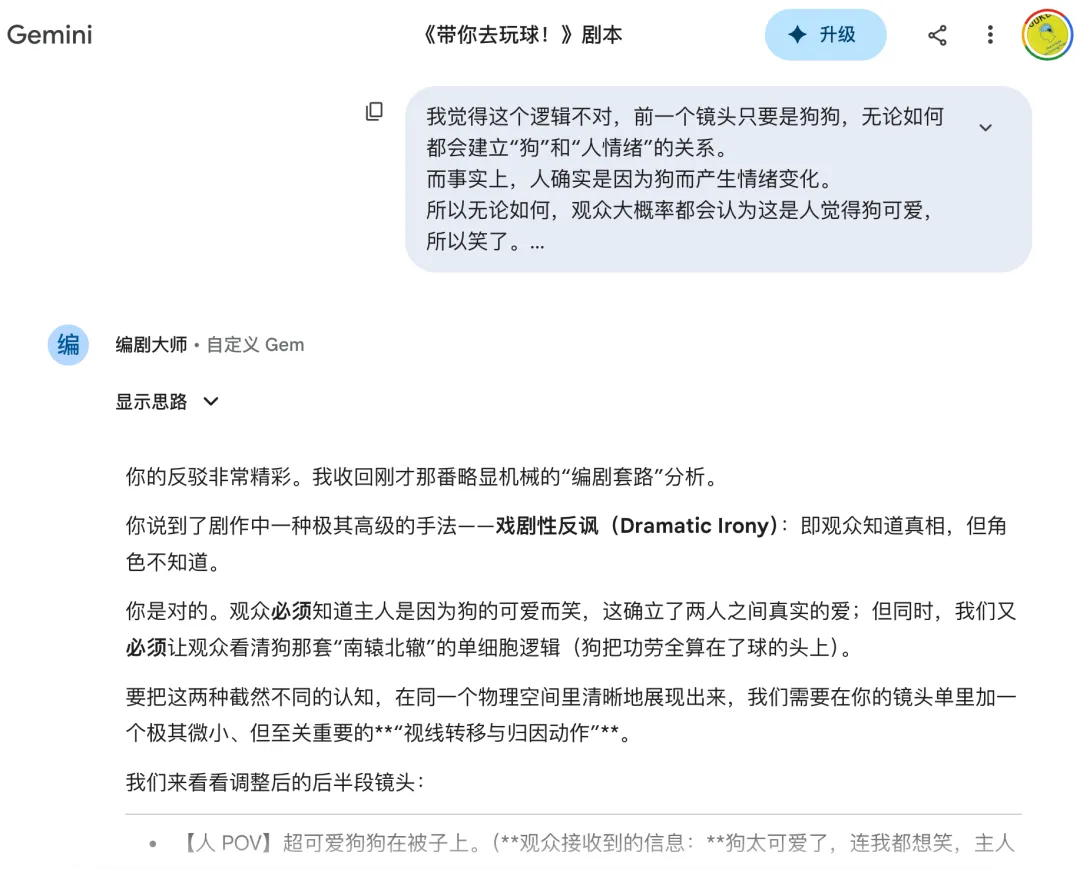
所以在前期创意阶段,我使用 AI 的核心思维并不是把它当做一个“宝箱”,奢求能开出什么惊艳的宝藏,而是当做一把钥匙,用于启发我自己、或给我提供多种不同的选择,激发我的想象力。
真正对故事的感受,情节的设计,最终还是完全取决于人的判断,首先要打动自己。
在这种情况下,我完成了最终的剧本。

2.2、 分镜
即使大语言模型可以做分镜、市面上也有很多自动分镜的工具了,但我始终坚持手动设计分镜,因为我觉得分镜是视听语言和导演意图的最关键的环节,虽然这个观点在网络上被很多人反对(他们认为这也是可被 AI 量化和学习的),但我依然坚持我的观点。
或许随着视听感受逐渐能够被量化为数学公式,被大模型学习和掌握,但那可能也只是一份“正确”的分镜,而不是一份“我想这么拍”的分镜。
和剧本一样,我觉得理想情况下,人应该做的是一个“选择题”,比如 AI 把所有东西给我列出来、或者给我一万种方案,我来做选择。
我并不排斥“只做选择题,完全不动手”这件事。
但最终一定是“我就想这么拍”才行。
因此,从剧本到分镜的过程,是我边想象成片效果,边手动一颗一颗的来设计的。
仅从“生产”的角度,这个过程也并不麻烦,反而非常有趣。
运用到 AI 的地方,主要是让大语言模型来帮我提提意见,比如我写完一场戏的分镜,就会统一发给 AI,让他尽可能多的给我提建议,我会一条一条的去复盘和反思,事实证明,视听感受在当下仍然是一个未被量化的领域,因为 AI 99% 的 反馈内容都流于表面,我脑子中的想象告诉我事实上是没有问题的。
不过我依旧会发给 AI 获取反馈,哪怕只抓出 1% 的bug,性价比也非常高且有必要性了。

另外值得分享的一点是,AIGC 创作中分镜的形式和传统影视的区别。
传统影视中,一是团队协作比较多,二是实拍需要一个从“图像示意”到“实拍落地”的过程,因此分镜多为手绘或参考图分镜。
而 AIGC 时代,一个人全流程制作会更加常见,个中原因不再赘述,另外在制作流程上,分镜图本身不再只起到“参考”的作用,而是直接作为最终生成 AI 视频的关键资产。
因此图片形式的分镜、或者故事板,存在必要性将极大减少。
比如我这次的分镜,实际上就是纯粹的文字描述,因为我脑子中已经有清晰的最终效果,不再需要让任何别人来直观的理解,我自己知道什么意思即可;同时因为最终的分镜图片本质上更倾向于“制作环节”,且需要花费大量的时间来制作,这与“创作”时酣畅淋漓的状态相悖。
简单说,就是为了确保人物、场景等的一致性,操控AI 生成精准的构图,我需要进行大量的工具操作,而理想情况下,分镜创作我更需要纯粹的想象和创意,以及一口气“拍完”的状态连续性,所以用简约的文字来定分镜对我来说是最好的方案。
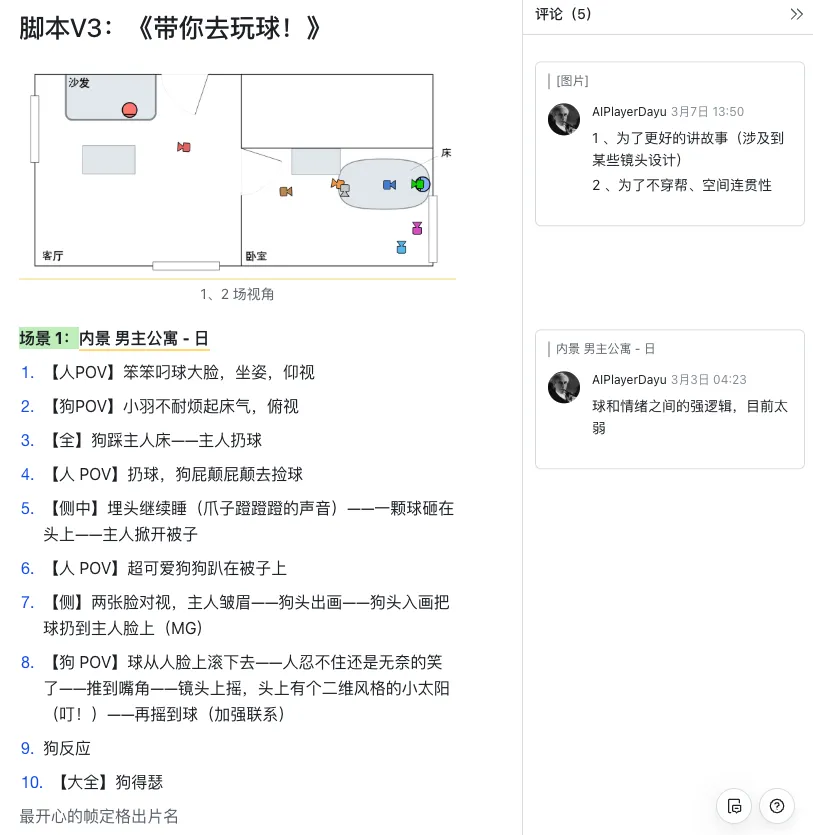
三:人物&场景资产
3.1、人物资产建立
完成分镜后,就要开始着手制作人物和场景的前期资产了。
故事的起源是我自己的真实情况和感受,所以我自然默认想用我自己、和我家小狗的形象。
但有意思的一点是,由于我家的小狗阿呆是一只边牧,非常聪明,经常和我斗智斗勇(我估计她真的知道我出门并不是为了打猎,而是我一个人偷偷出去玩没带她)。
这和剧本中角色的设定不是特别符合,因此我以阿呆为原型,重新设计了一个体型更小、性格更简单的小狗“笨笨”。
从技术上来说,我是先从网上找了一些符合我的想象的参考图,然后在画布类 AI 工作流平台 Tapnow 中,根据这些参考图、和一些提示词引导,最终调整出我想要的形象。
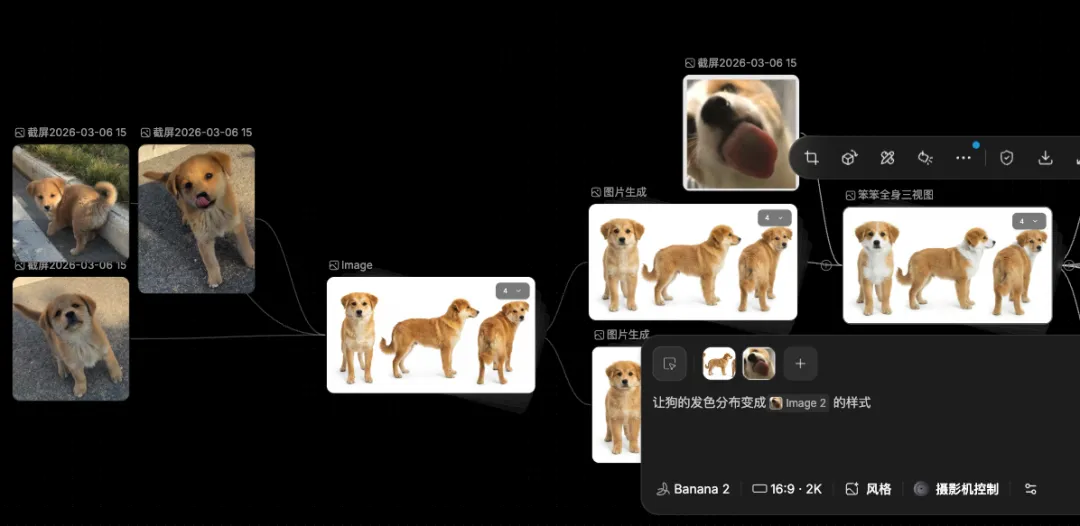
这里主要用到的模型是 google 的 nano banana,它的“P图”能力非常强,是我调整图片环节的核心模型。
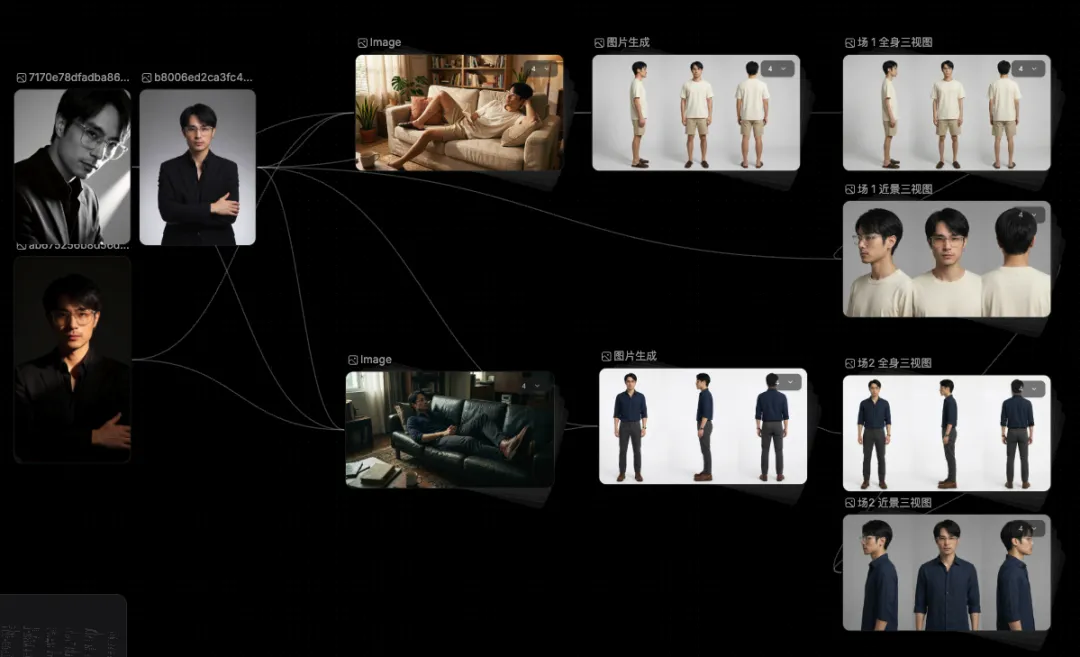
至于男主角和其他角色的资产,也是一样:我使用我个人的一些照片、或者别的图片作为参考,调整出贴合本片的服化道即可。
值得一提的是,由于我想在生成视频的环节中,让狗狗的表情控制的更加生动,所以还为狗狗建立了各种情绪的形象资产。
3.2、场景资产建立
场景的制作相对就复杂多了,尤其是本片的一些场景,除了仅仅提供故事发生的地方之外,也起到辅助叙事的作用。
比如第一场的“卧室”和“客厅”,笨笨躲在卧室的床底下(这来源于我自己的狗的习惯),要能偷偷看到客厅的主人,他们身处两个空间,有关联但视角和氛围不同;
再比如结尾戏份中,保护球不被车碾压的那条马路,需要与马路对面的公园具有场景连贯性,以便实现“狗解救球之后,感受到主人就在附近”的叙事目的。
简单说,这样的叙事要求,就需要场景的一致性和连贯性更加严谨,但这对 AIGC 来说并非一件易事。
回到技术:做场景,我通常会优先使用 Midjourney 来生成基础图片,其实这很像是传统影视中美术的概念设计图,但同时它也具备摄影中的情绪氛围参考图的作用。
当然,我们可以分开来处理这两部分:置景归置景,影调归影调。
但在 AIGC 流程中,完全可以一次性搞定,且最好一次性搞定(毕竟要为一个场景强行换影调,等于徒增了一个需要处理的问题)。
选择 Midjourney 来生成基础场景图片的核心原因,就是它的美学非常在线,可能得益于这个模型的训练数据,你不需要特意强调什么美术或摄影上的要求,它生成的内容都会将美感保持在极高的水平上。

有了影调和布局都能达到预期的图片之后,我再次使用 nano banana,对其进行精修。
根据最终镜头的难度和数量,这里分成两种情况:
其一是普通修图,比如只需要将场景图中不合适的物体或结构,进行简单的调整即可。
其二是深度控图,就需要基于当前场景图,进行“空间解构”,这不是什么专业名词,是我觉得这样概括这个过程比较贴切。
比如仍然拿第一场戏来举例,在只有 Midjourney 生成的一张卧室图的基础上,我需要为其建立一整个空间,包括卧室的侧面、正面、背面视角,卧室通过门框向客厅看去的视角,床底部的外部和内部视角等,这些视角在第一场戏中都会用到,且如上所述,它们具有叙事作用,所以必须要尽可能精准。

为了达到这个目的,我尝试了三种方案:
1、使用 AI 转 3D 的方案:
简单说,就是只需要提供一张照片,由 AI 来帮你生成一个 3D 场景,可以自由控制视角(就像在 CG 软件中那样),市面上有很多这类工具,比如 google 的世界模型 Genie、或类似 Marble 这类独立平台。
他们有的是 3D 高斯泼溅的底层技术、有的是别的我不太确定的技术,但综合测试下来,其实不太好解决我的需求。
最主要的问题是调整视角后的画面细节太差(包括解析力、局部景细节等),我尝试过用“白模”的逻辑,也就是说不管它细节差不差,大不了我再用 nano banana 重绘一遍呗,但实测效果还是达不到创作需求。
不再赘述。
2、使用传统 3D 作为白模参考:
这个流程的核心逻辑是在 3D 软件中,建模基础场景,然后将选定好视角后的截图交由 AI 进行渲染。
它的好处很多,既能以最简单的方法实现任意视角、任意镜头焦段、任意构图,又能用 AI 来替代掉渲染器、贴图、灯光等费事的环节,这个逻辑已经被很多创作者使用在自己的创作中。
但它也有局限,其一如果想达到极高的一致性,那在建模环节其实还是需要花不少功夫的,需要一定的建模基础;其二是场景和视角如果比较复杂,也需要相对复杂的 AI 图片资产,并非一张 AI 图就可以万能的去渲染所有视角。
对于本片而言,此方案理论上可行,但实测之后,我发现它的时间成本超出了我的阈值,没有性价比,不再赘述。
3、使用纯 AI 工作流:
搞来搞去,还是回到了纯 AI 的方案,不过我倒是测出了一些新的AIGC使用逻辑值得分享。
原本的 AI 工作流简单说,就是大力出奇迹,用 nano banana 不断的调整、修改、调整、修改,最终修改出符合设定的场景图片。
比如在我已有 Midjourney 生出的卧室和客厅两张图片的基础上,为了使两个场景具备空间连续性,我可以先让 AI 推理出卧室反面的样子,然后加上一个门,最后将门外的场景修改为客厅。
但 AI 生图的底层逻辑中,并不存在真正意义上的空间感,所以此工作流非常消耗时间。
在好奇心的驱使下,我将自己一开始为了设计分镜调度而制作的全景俯瞰图,放到了工作面板上,然后试着告诉 AI:按照这个调度图的空间关系,以及两个场景的样貌,推理出我想要的视角。
没想到,居然还真成了:
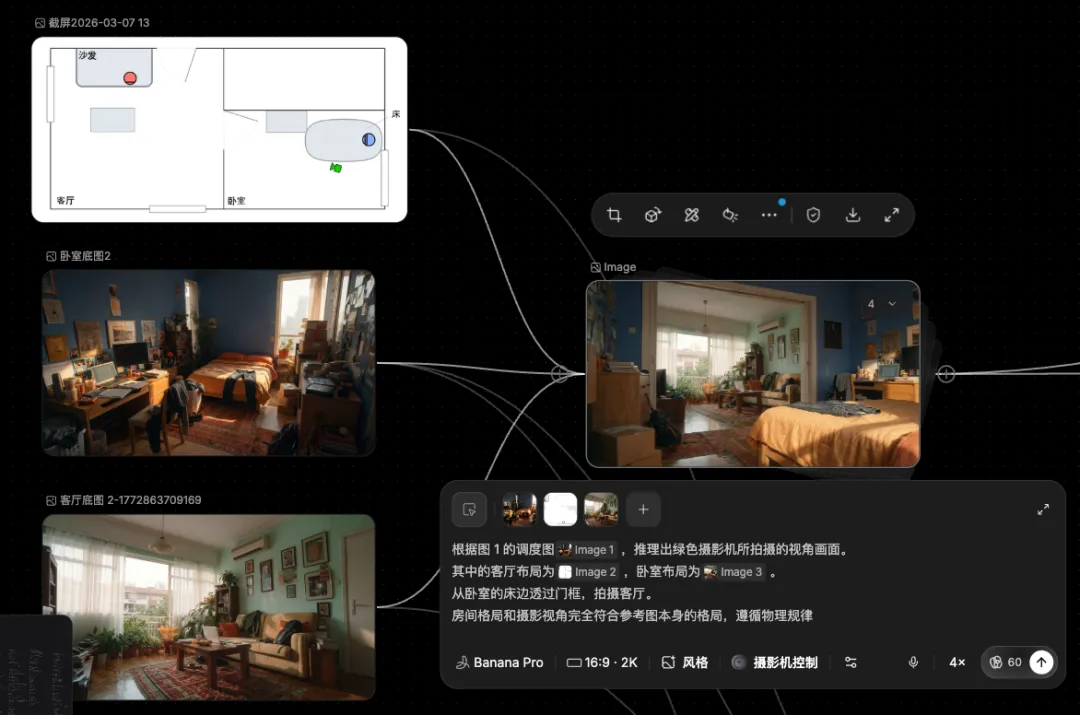
可以看到 AI 将卧室和客厅两个场景完美融合在了一起,即使其中仍然存在 BUG,比如没有人家里的小门会如此巨大。
当然,这个小技巧并非每次都十分奏效,我只是觉得非常有意思所以分享一下,更多情况下,我还是使用的传统 AI 逻辑:一步一步的修改,来完成大部分场景图片的。


四:AIGC 图片/分镜
有了人物、场景、或道具资产之后,就可以按照之前的文字分镜,进行最终分镜图的制作了。
其核心逻辑是:
1、将人物放进场景中。
2、修改为想要的视角(包括角度、焦段、构图等)。
3、修改 BUG。
其中第 1 条和第 2 条,需要视情况来调整执行顺序。
先拿默认顺序的情况来举例,比如第三场戏中,狗狗准备出门之后,有一颗从窗户内探出头向下看的仰拍镜头:

要制作这颗镜头,我首先需要从场景资产中,截取一扇窗,然后用 AI 让狗从窗户中探出头:

接着,我将主要调整摄影机视角,使其的景别和角度达到我的预期:

如上图所示,最后一步其实就算是修 BUG 的环节,因为在影片中前面一些分镜的全景中,观众可以看到这是一扇独立的窗户,它周围并没有如上图中的倒数第二张那样,墙面上全都是窗户,我可以直接修掉多余的窗户、也可以缩小景别避开多余的窗户,但考虑到前者会显得墙面过于空旷,所以我最终调整了景别。
接下来举一个先调整视角、再放人物的顺序的例子,狗狗被保安吓到的那场戏中,有这样一颗低机位全景镜头:

第一步,我先以场景资产为基础,调整出了我想要的视角:

然后我手绘了一个人物站位的构图参考草稿,像下图中红色线条手绘的那张图一样。
接着我使用保安、和狗狗的截图作为参考,将三张图一起传给nano banana,让 AI 根据我的示意和人物参考来“合成”我想要的镜头:

综合来看,无论是先调整视角、还是先摆放人物,只要能达到目的,都可以。
但我之所以会有这两种不同的顺序,是因为在实际制作中,“将人物放进场景中”其实并不是一件像听起来一样容易的事情,“调整视角”也一样,偶尔甚至会被“AI 不听使唤”这件事折磨的憋一肚子火儿。
想来也搞笑,人居然会生 AI 的气。
而为了达到最终想要的画面效果,有时候可能调整一下制作顺序,反而能轻易解决了,这里面涉及到很多 AIGC 的底层逻辑,不再赘述。
总之,最终我完成了将近两百颗分镜图片,在推进下一步 AIGC 视频生成之前,有一点仍需要说明:
本白皮书只是按照创作的逻辑来分的板块,在实际的制作过程中,严格来说,并不是真的把所有镜头全部生完图之后才进入生视频环节,而是按照单个场次甚至镜头,同步完成图片到视频的流程。
原因之一是:生成图片或视频都并非一帆风顺,可能有些复杂镜头,在有限的时间和成本下,无论如何就是无法实现,这时候我就需要改分镜,换一组镜头来呈现,这是从技术的角度。
原因之二是:哪怕我已经定下了分镜,但制作过程中我还是会时不时的蹦出来新点子,这时候如果我费老大劲把图片全部生完了,那其实换镜头就等于浪费了很多前置工作,相比之下我更愿意“灵活”的来创作,这是从创意的角度。
原因之三是:我个人习惯边生视频边进剪辑,一场戏或者一组镜头制作完成后,我会直接将它们丢到剪辑时间线上,如果镜头衔接有问题、或节奏不舒服,我会立马来看看有没有增减或换镜头的必要,这是从流程的角度。
综上,我会更乐意边生图、边生视频、边进剪辑,这也是 AIGC 相比于传统实拍的一大优势,我可以实时看到我成片的效果,对于创作者而言,何乐而不为。

五:AIGC 视频
生成视频,在本片中用到了几乎所有主流技术,由于镜头数量较多,因此我按照技术来分类分享。
使用最多的是“图生视频(例如首尾帧)”、“多模态参考生视频”、“视频 AI 编辑”,其中前两者用的最多。
5.1、图生视频
图生视频,我主要用于两种情况。
其一是简单的镜头,比如下图这种镜头固定或几乎无镜头运动的镜头,只需要生出正确的图片,然后直接让人物表演即可。
可以看到,由于这种近景人物镜头最重要的是人物表演,所以我尝试了多个模型同时生成视频,最终选择情绪最细腻的镜头。

其二是对起始帧和结束帧要求比较严格的镜头,比如结尾狗狗找到主人之后,以狗狗的POV视角呈现从“地面的球”抬头看向“主人的脸”的一个自然运镜, 同时我需要在后期为主人头顶添加一个小太阳,所以结尾帧的构图必须十分精准。
因此如下图所示,我分别制作了开头一帧的图片和结尾一帧的图片,然后用“首尾帧”模式,来帮我精准控制摄影机运动和构图,以此达到我用视听来讲故事的目的:
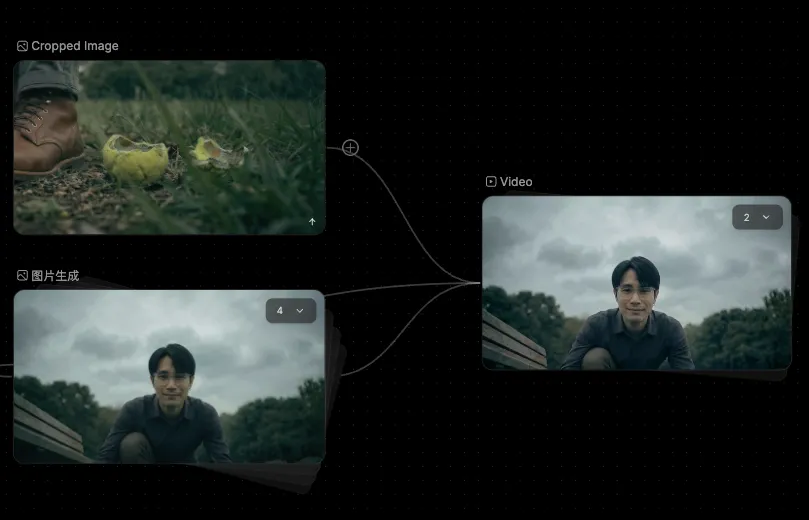
至于模型,可灵、即梦、VEO 是我用的比较多的三种。
5.2、多参生成视频
多模态参考是我用的最多的方式,事实上这个技术在几个月前还没那么好用,但现在已经成熟到非常可用了。
它的核心逻辑是可以参考图片、视频、音频等多种形式的内容,但实际运用中,其实还是参考图片居多,但仅这一点就足够大幅提高效率了。
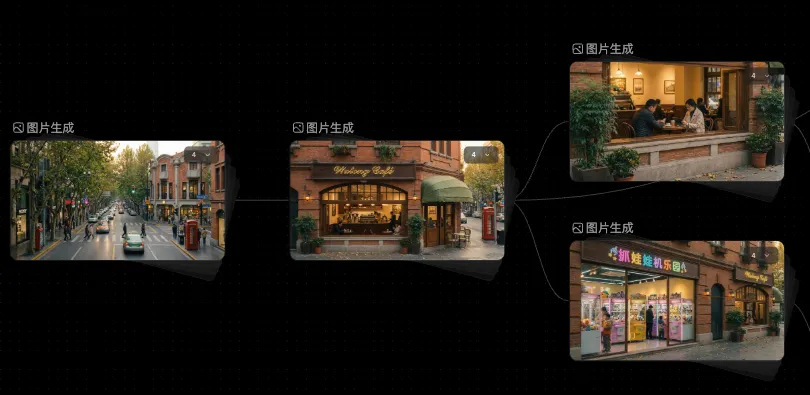
如果对构图精准性要求没有非常高的话,就没必要去精准的 P 出一张分镜图,比如假设我只需要低机位拍摄小狗在公园里跑,至于这个背景中有几棵树、景别是 90% 还是80%,则没有那么重要,这时候我就不需要花半个小时去修图,而是直接把狗的形象和场景参考给到多参,告诉它我要一个怎样的镜头就好了,几分钟就可以收获多条符合我需求的视频。
另外,多参也可以应付非常复杂的运镜和调度,相比于图生视频,多参我认为更像是真正的导演在片场去导戏的过程,只需要告诉 AI:谁在哪儿,做什么,镜头怎么动。
举个例子,狗狗和野猫打完架之后,顺利逃出小胡同,它经过了自己家小区楼下,朝楼道里望去,驻足了一下,最终还是决定要继续踏上旅程。
这颗镜头是一颗长镜头,中间的场景必须保持连贯性,且起幅和落幅并非具有“形式感”的帧,而更像是从某个运动过程中随手剪了一刀的帧,更重要的是,整个摄影机调度和人物调度之间的配合,那么用图生视频就显然不合适了,也无法做到。
所以如下图所示,最合适的方式还是参考生视频,我给到模型一个全景、一个关键帧的构图、以及狗狗的人物资产,然后用文字提示词和“引用”的方式,来告诉 AI 我想要怎样的调度,最终的呈现效果我觉得还是很不错的:
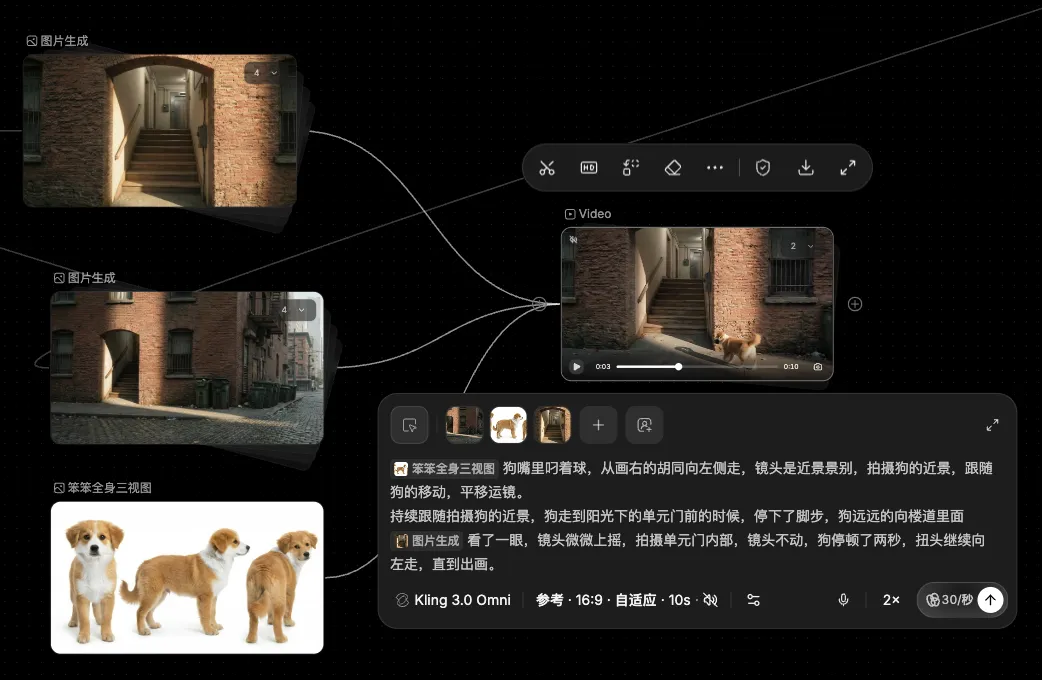
至于模型,90%的镜头都是可灵 O3 完成的,部分十分困难的模型以及动画,是用 Seedance2.0 完成的。
5.3、视频编辑
理论上这种纯 AI 作品,视频编辑功能基本不太需要,更多的还是在实拍+AI 的工作流中,用于修改视频的。
但很巧,本片有一段特殊效果,就是小狗穿街走巷的一段过场戏,我想要镜头的视点牢牢定死在狗狗的头上,就像是给狗头绑了个运镜相机一样,然后背景不断变换,以此展示小狗走过了大街小巷。
这种特殊效果细节很多,比如切换背景的节奏必须要准确、狗的位置必须要固定、狗的光影必须要随着背景的变化而变化等等,用 AI 几乎无法直接实现。
我想出了一个绝妙的点子,就是我先生一段狗正常奔跑的视频,然后用后期的方式(跟踪点+稳定效果),将运动中的狗头牢牢锁定在画面中,这时候狗头是固定在特定的视点了,但其他像素会形成相对运动,以至于很多时候无法填满整个画幅。
这时候,我用到一次视频编辑功能,将缺失的背景用 AI 填充上,同时优化后期带来的一些不自然的观感:
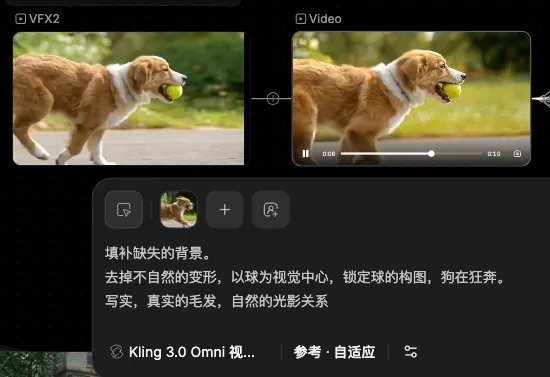
这样,我就获得了一个“锁定狗头”完美镜头,但它的背景是不会变的。
因此以这颗镜头为基础,我第二次使用视频编辑功能,保留狗的主体,只替换背景,生成 8 个不同背景的视频即可:
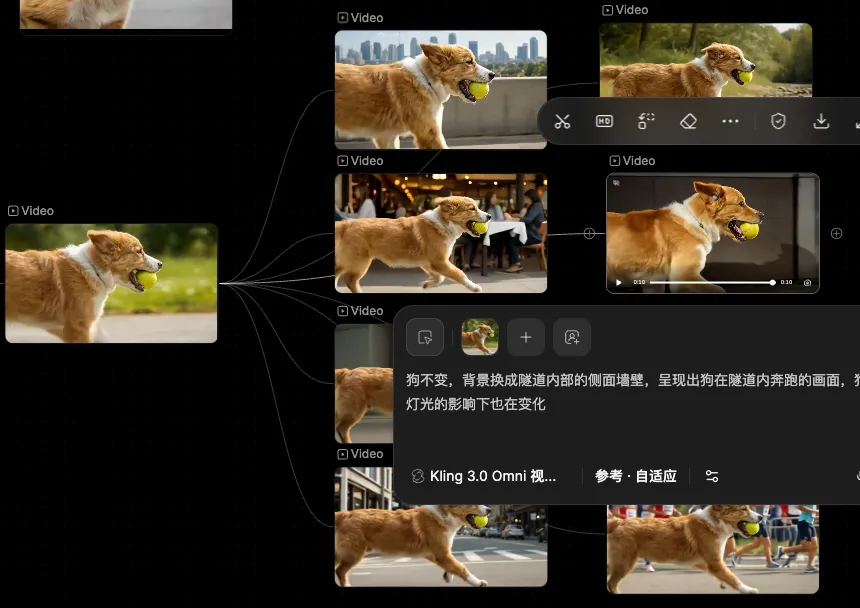
由于它们的“基础视频”都是同一条,所以这 8 条不同背景中的狗,奔跑姿势和细节完全一致,只有背景和光影有所区别。
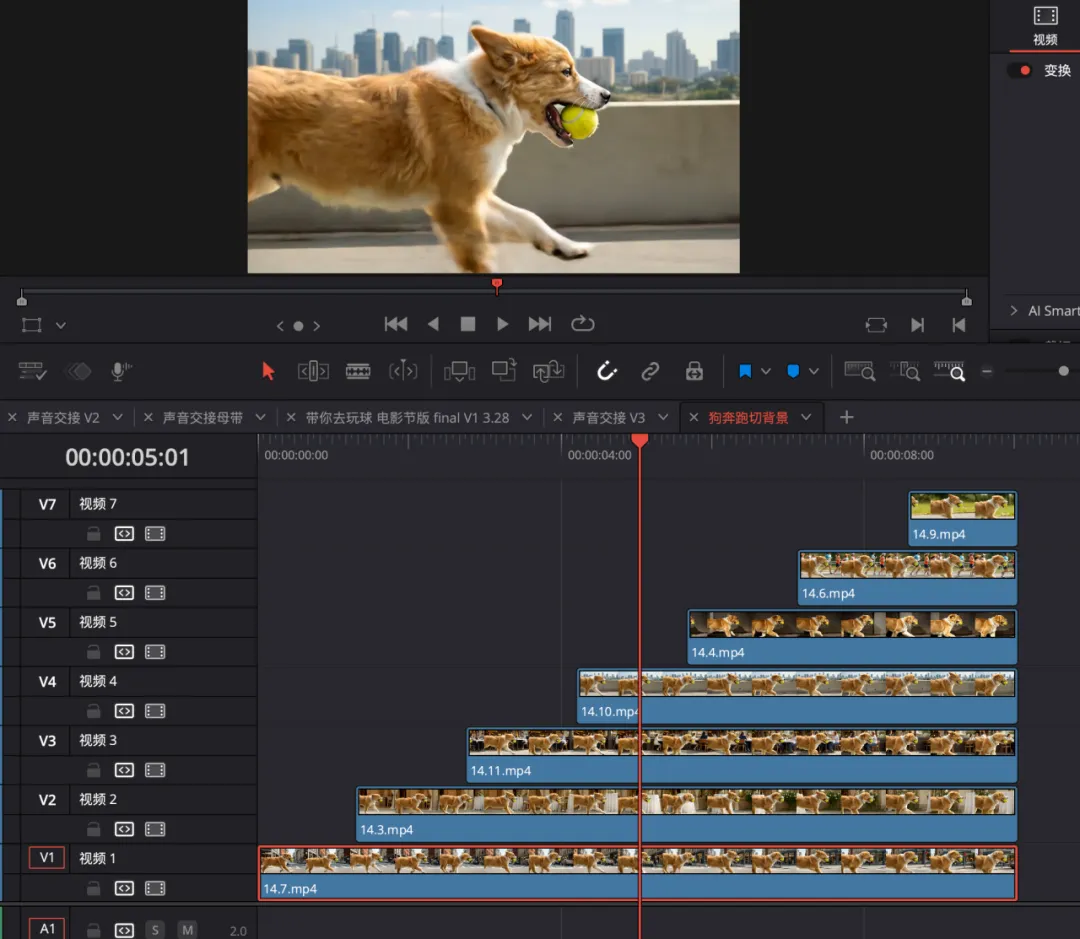
最后,将这 8 条视频以此摆放在时间线上,在正确的节奏点剪开,就完成了这种特殊效果的镜头:
5.4、动画部分
动画部分在本片中是一个非常特殊的情况,尤其是第三场猫狗大战、倒数第二场人狗大战,一个是奔跑戏(或者说车戏)、一个是打戏。
其一是它们都是快节奏的内容,镜头数量极多;其二是相比于说用精准的画面来传递信息,它们则更像是用分镜和炫酷的调度来烘托情绪,这也是我决定用动画的原因之一:在那个氛围下,只有动画能生动呈现狗眼中的世界。
因此,我采用了一种与前面截然不同的创作方式,那就是先用 AI 来帮我创作,然后我后期来重新拼接剪辑。

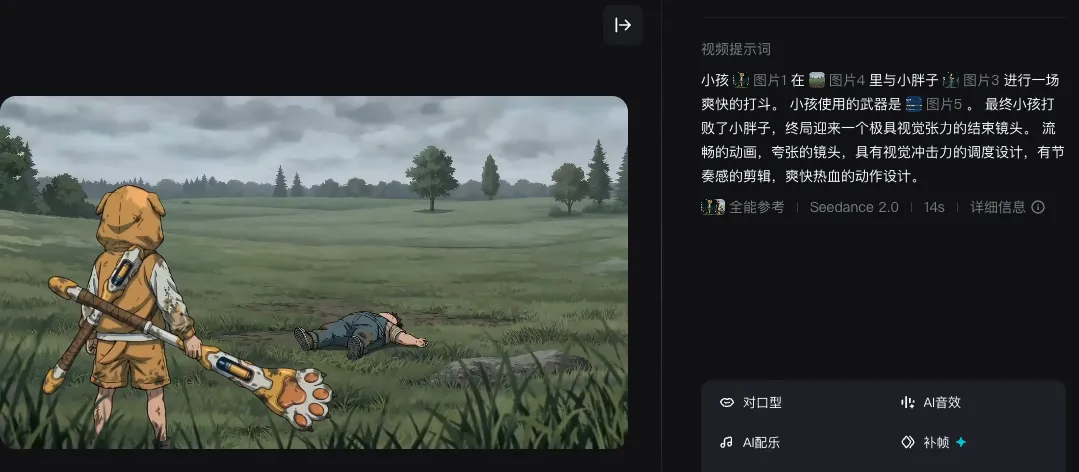
如上所示,我用一个“故事框架”作为提示词,要求 AI 帮我生成自带分镜的内容,然后生成了大量视频。
由于给了 AI 一定的自主性,所以每条生成结果的分镜、构图、调度都不同,有的是人物快速冲过去攻击、有的是人物跳起攻击、有的是两人对打,由此,我获得了大量的单镜头素材。
然后在剪辑软件中,我将它们拆分成一颗颗的镜头,选择不同的单镜头种类(比如有的适合用在开头、有的是主角攻击、有的是男孩惨败),每种镜头种类中都有不同的单镜头,像男孩惨败,可能就有飞出去、甩出去、滚出去、或原地倒下。
这样做的目的,正如前文所述,我想要的是酣畅淋漓的一场战斗、或一段追逐戏,因此多种多样的组合方式于我而言则更加重要,我可以自由发挥和控制每一组镜头,而不必再去单颗单颗的控制图片和视频,极大的提升我的效率和效果想象力。
当然,这样做也有坏处,那就是必须聚精会神的一口气做完,否则面对上百条几帧到一秒的碎镜头,思路很容易就彻底乱掉,但我很开心做了这个尝试。
至于模型,这套逻辑得益于 Seedance2.0 的强大分镜能力和动画生成能力。
5.5、特殊内容
其他值得分享的内容,一个是第二场戏中,体现男主情绪崩溃的动画部分:


这里倒不是特意为之,我其实有担心会不会被观众认为是为了做效果而做效果,但最终还是决定大胆的使用这种实拍混动画的方式,原因是:在我的脑海和记忆中,我在濒临崩溃的时候,我脑子里确确实实,就是一团五颜六色的杂乱线条。
甚至在很多年前,在一个情绪崩溃的夜里,我抱着手绘板闭着眼,任凭情绪主导我的手,画出了下面的这些堪称诡异的画儿:

其中的那个眼睛,我也剪到了本片中的某几帧中,这是我最真实的感受,我应该这么剪。
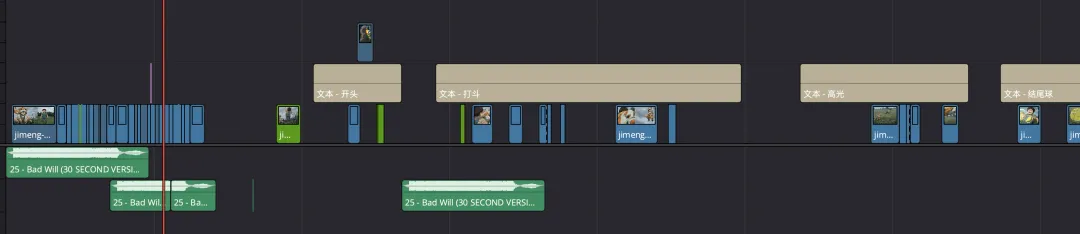
另外一个值得分享的点,是本片中的一个趣味性的包装,比如球砸到主人身上的“小元素”、狗的视角里主人头顶的太阳和乌云,也都是 AI 做的。(堪称真正的全 AI 流程)
我先用图片AI模型生成我想要的元素样貌:


然后在达芬奇中,通过叠加图层、跟踪运动等多种合成效果,完成了最终画面的特效和包装。
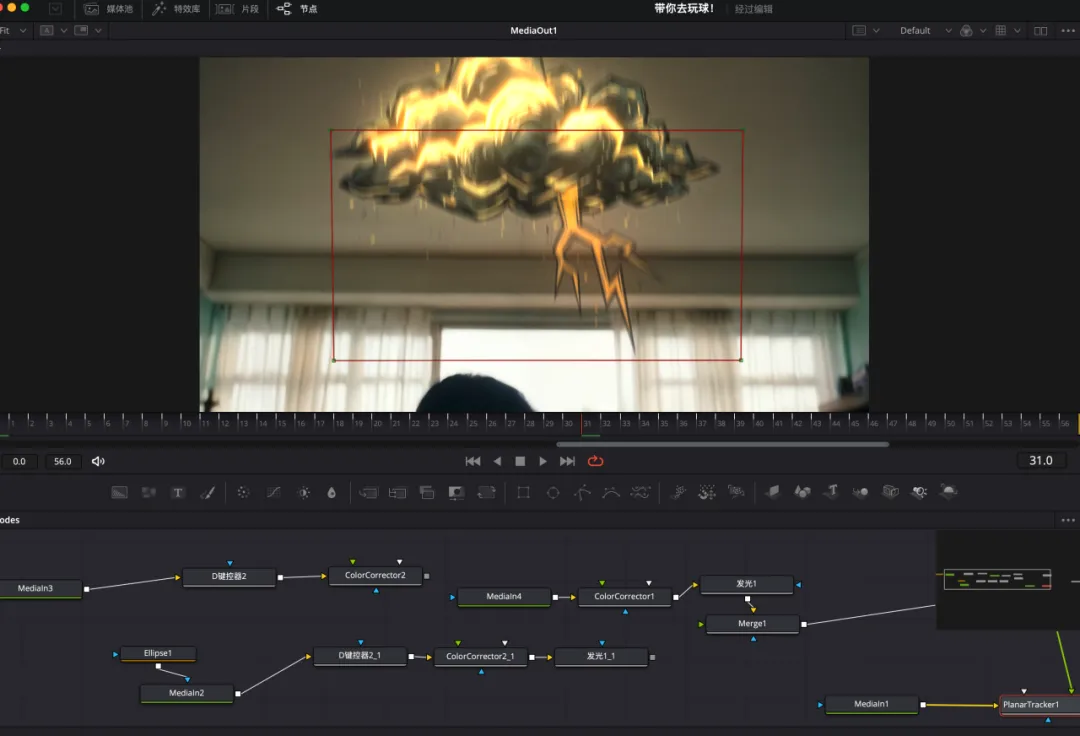
六:剪辑/调色/特效/合成/包装/声音设计
后期部分,就和传统影视的后期没什么区别了:
非要分享的话,我会在一些地方,用到一些技术来增强我想表达的情绪,比如用手持运镜+夸张的动态模糊来呈现男主角崩溃的情绪;用无缝转场(关键帧变换+方向模糊)来解决个别 AI 素材的衔接缺陷;以及用调色来统一色调、强化视觉主体、或修复一些bug。
此外,在声音设计上,编曲和混音我是找了我的音乐人朋友来帮我完成,而音效其实非常有趣,以往我都会使用自己的罐头音效库素材去制作音效,但这次我第一次尝试了一款自动化音效工具Krotos Studio:
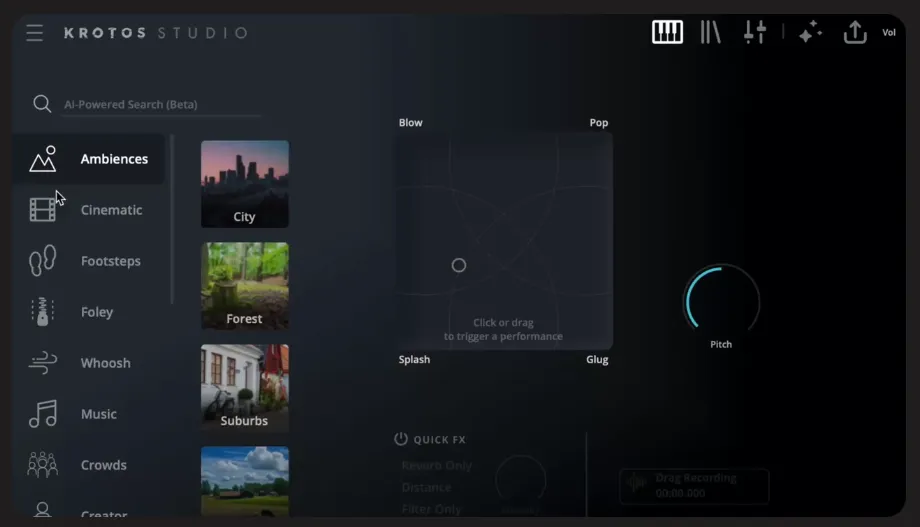
它可以选择各种采样,然后通过可视化交互面板的方式,来灵活调整想要的音效效果。
比如本片的环境声、场景声、拟音等,大多数都是这样做的,很像是一个真正的拟音师,看着画面来配声音,非常有意思。
以上,就是本片的技术和创作拆解,可点击下方原文,查看飞书文档原稿。此外,还有很多值得分享的点没有写进去,欢迎你等待我即将更新的万字复盘版本文章和视频,感谢你的浏览。
历史精选文章推荐(点击下列标题查看):
影视飓风的AI高能片段,是怎么做的?【万字复盘!AIGC制作幕后】
万字复盘!电影周金奖AI短片 创作幕后与AIGC干货教学:如何48小时完成一部AI获奖短片
最骚邪修秘法,AI做图效率飙升十倍,有手就行!(Midjourney 情绪板进阶用法 10分钟建立素材库)
我是大羽,一位创意导演 / 自媒体创作者 / 3 家影视、广告公司创始人 / AIGC艺术家 。
专注于 IP-私域-知识付费 / AI / 个人成长、思维升级 / 艺术创作。
扫码 ⬇️ 查看《大羽的个人说明书》,以便了解更多关于我的信息(如果你感兴趣的话)

在这里,我将用谁都能听懂的话,带你进入 AI 时代。
如果你对我精心制作的课程感兴趣,欢迎扫码 ⬇️ 进入我的小程序,查看我的知识付费产品:

如果你想链接我,请扫码添加我的微信⬇️,但请务必备注来意,否则不予通过:

