



一、为什么存算一体如此重要?
传统计算架构以“冯·诺伊曼架构”为核心:存储单元与计算单元相互分离,数据在两者之间频繁搬运。英伟达CEO黄仁勋曾指出,“GPU有七成时间在等待数据”,这形象地描绘了“内存墙”(Memory Wall)问题——数据搬移的能耗和时间,严重制约了芯片算力的进一步提升。
存算一体(Compute-in-Memory, CIM)的核心理念,是将计算直接嵌入存储单元内部或附近,从根本上减少甚至消除数据搬移。根据存储与计算融合程度的不同,业界通常将其分为三大技术流派:
1. 近存计算(Near-Memory Computing)
仓库(存储)与车间(计算)同园区——物理距离大幅缩短,数据搬运功耗和延迟显著降低,但计算仍在独立单元完成。典型方案包括HBM(高带宽内存)+ GPU Chiplet协同封装,以及美光、三星推动的HMC(混合存储立方体)路线。
2. 存内处理(In-Memory Processing)
在存储内部嵌入初加工能力,对数据进行局部预处理或过滤,减少传向计算单元的数据量。典型的“存算近邻”设计,已在部分AI推理芯片中实现商用。
3. 存内计算(In-Memory Computing / Compute-in-Memory)
将整条计算流水线搬入存储阵列,数据在同一位置完成乘加运算,无需搬移。这是融合程度最高、技术难度最大、但能效提升潜力也最大的方案,被认为是AI芯片的“终极形态”之一。
据市场研究机构预测,2025年全球存算一体芯片市场规模已突破120亿美元,其中中国占比约30%。随着大模型推理需求的爆发,存算一体正从学术前沿快速走向产业落地。
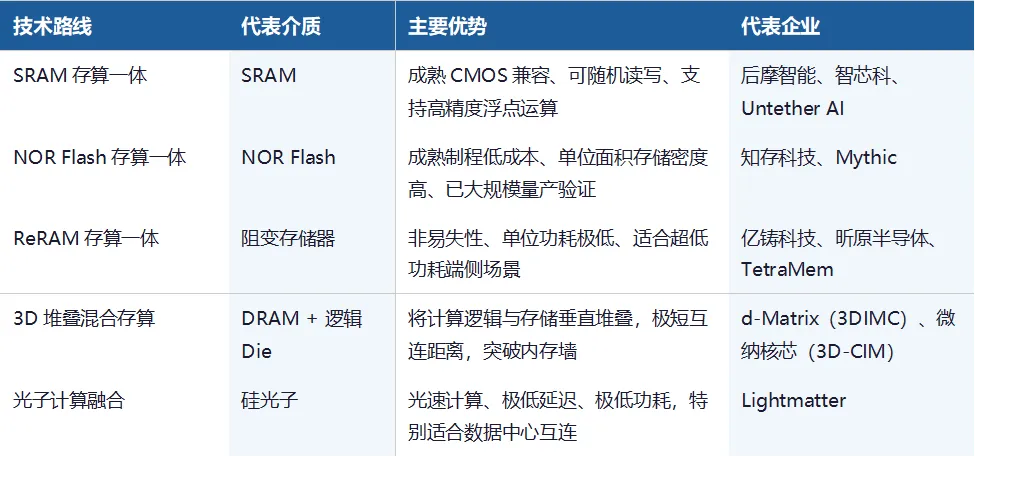
二、技术路线全景:五大技术派系
根据底层存储介质和电路实现方式的不同,存算一体芯片可分为以下五条主要技术路线:
三、国际存算一体公司巡礼
全球存算一体芯片创业生态以美国最为活跃,集中在硅谷周边。以下是按技术路线分类的主要国际玩家:
3.1 数据中心与大算力阵营
d-Matrix(美国·加州)
d-Matrix是目前最受关注的存算一体创业公司之一,采用“数字存算一体”(DIMC)路线,专注AI推理加速。
•融资规模:2025年11月完成2.75亿美元融资,估值20亿美元。
•核心产品:Corsair芯片(数字存算一体,2024年11月开始出货);Raptor推理平台(2025年)。
•技术亮点:2025年9月在Hot Chips大会上发布3D堆叠数字存内计算(3DIMC)技术,与Alchip合作实现商业化,宣称比HBM4方案徫10倍。每台服务器可运行高达1000亿参数模型。
•商业化状态:已开始向客户发货,与数据中心客户深度合作。2025年11月完成2.75亿美元C轮融资,估值达20亿美元,成为国际存算一体领域估值最高的公司。本轮由全球财团联合领投,此前已获微软投资。Corsair-X采用3D堆叠数字内存计算(3DIMC)技术,带宽达150TB/s,每台服务器可运行高达1000亿参数模型。与SK海力士合作高带宽内存方案。
Untether AI(加拿大·多伦多)
Untether AI成立于2018年,以"内存计算"架构闻名。专注于SRAM-based数字存算一体芯片,面向低功耗AI推理场景。团队工程化能力强,已有多代产品路线图推进中。2025年6月,AMD收购了Untether AI的AI硬件和软件工程师团队。
•技术路线:全数字SRAM存算一体,精度可编程。
•应用定位:边缘推理、终端设备,已与多家OEM展开合作。
•2025年6月5日,AMD宣布收购Untether AI的AI硬件和软件工程师团队(非整体收购)。公司核心产品speedAI240集成1400个RISC-V内核,推理性能达2 PFLOPS。
TetraMem(美国·加州)
由多位顶级学术和工业界专家创立,是模拟存算一体领域的技术先驱,核心技术基于ReRAM/忆阻器。
•技术亮点:能效比超过20 TOPS/W,已在28nm制程上验证。
•商业模式:IP授权为主,向大型芯片公司提供存算一体IP核。
•商业化状态:处于技术授权阶段,已与多家芯片厂商建立合作。
•2024年2月在《Science》杂志发表重大突破,实现忆阻器任意高精度模拟计算;2024年12月与Andes晶心科技合作,整合RISC-V向量处理器,支持5nm、3nm及更先进工艺。与台积电等代工厂合作,推进先进制程落地。
3.2 边缘AI与终端低功耗阵营
Mythic(美国·德克萨斯)
模拟存算一体的早期明星公司,采用基于Flash存储的模拟计算方案。技术成熟度较高,在边缘视觉AI领域积累深厚。
•核心产品:GEN 1 APU模拟存算一体芯片(2025年12月发布),已进入多家边缘视觉客户供应链。
•技术亮点:模拟计算在特定功耗预算下可提供极高的MAC(乘加运算)密度,适合always-on视觉场景。
•商业化状态:产品已出货。2025年12月完成1.25亿美元融资;2026年2月与本田(Honda)宣布联合开发车规级模拟AI SoC。
•GEN 1 APU采用SST SuperFlash memBrain技术,能效比达120 TOPS/W,模拟计算将AI参数直接存储在Flash单元中,无需权重数据搬移。2026年3月与Microchip/SST达成战略合作,将SuperFlash memBrain技术应用于AI计算。已进入多家边缘视觉客户供应链。
EnCharge AI(美国·新泽西)
采用电容式模拟存算一体方案,目标是PC端和移动端的AI加速。
•核心产品:EN100芯片,面向轻薄本和AI PC。
•技术亮点:模拟计算在端侧能效方面优势显著。
•商业化状态:积极与PC OEM厂商接触,产品导入验证中。
Lightmatter(美国·加州)
将光子技术引入计算,采用硅光子进行矩阵运算,堪称存算一体领域的“另类玩家”。
•核心产品:Passage M1000光子超级芯片(2025年4月发布),可实现全球最快AI互连。
•技术亮点:光速矩阵运算,无电阻电容延迟,极低功耗,特别适合AI集群内部的高速互连。
•商业化状态:已与SK海力士等存储大厂合作推进商业化,估值达44亿美元。
3.3 欧洲与以色列阵营
Axelera AI(荷兰·埃因霍温)
欧洲最活跃的AI芯片创业公司之一,采用数字存算一体(Digital In-Memory Computing)+RISC-V架构的异构方案。
•核心产品:Metis AI平台,面向边缘AI推理。
•技术亮点:数字存算计算单元与RISC-V控制核心深度集成,提供完整的边缘AI解决方案。
•商业化状态:积极拓展欧洲及全球客户。
NeuroBlade(以色列·特拉维夫)
专注于近存计算(Near-Memory Computing)路线,主要面向数据中心和大型数据库分析场景。2025年10月,NeuroBlade被AWS(亚马逊云科技)收购。
•技术路线:近存计算,在存储控制器附近集成专用计算引擎。
•应用场景:大数据分析、数据库加速,已有多家合作伙伴。
Sagence AI(美国·加州)
模拟存算一体技术公司,专注于减少数据搬移以提升AI推理效率,已获数千万美元融资。
Rain Neuromorphics(美国·加州)
融合神经形态计算与忆阻器技术,探索类脑计算与存算融合的新路径,研究属性较强。
四、国内存算一体核心玩家
中国是全球存算一体技术最为活跃的市场之一。国内企业覆盖了从超低功耗端侧到大算力智驾的全场景,技术路线也极为多元。2026年ISSCC会议上,清华大学、华为与字节跳动联合发布了28nm混合存内计算芯片,推荐系统能效提升1-2个数量级,标志着国内学术与产业界的深度协同。
4.1 大算力阵营(智驾/数据中心)
后摩智能(上海)
后摩智能创立于2020年,是国内存算一体AI芯片领域的领军企业。基于先进的存算一体架构和存储工艺,致力于突破芯片性能与功耗瓶颈,加速AI技术普惠落地。

自研天枢架构,Int8精度下AI核心能效比达15 TOPS/W。鸿途H30芯片(256 TOPS算力,35W功耗)已完成车规认证并量产;后摩漫界M50(160 TOPS,10W)面向端侧AI。2025年实现量产,已与联想、科大讯飞、中国移动等建立合作。投资方包括中国移动产业链发展基金(中移数字新经济产业基金、上海中移数字转型产业基金)。
亿铸科技(苏州/上海)
亿铸科技是国内ReRAM(阻变存储器)存算一体路线的代表性企业,核心技术基于忆阻器介质,面向数据中心和云计算场景。
•技术路线:ReRAM存算一体,拥抱RISC-V生态。
•核心进展:2023年成功流片并点亮原型验证芯片,计划2026年推出国产AI算力卡。
•应用定位:数据中心大模型推理、云计算加速。
•2025年10月完成A轮融资。国内唯一能够自主设计并量产基于新型存储全数字存算一体大算力AI芯片的公司,破解"存储墙""能耗墙""编译墙"瓶颈。布局低空经济等新兴领域,拥抱RISC-V生态。
4.2 端侧AI与低功耗IoT阵营
知存科技(北京)
知存科技是国内存算一体商业化最成功的公司之一,采用NOR Flash路线,已实现百万颗级别的芯片出货。

WTM2101芯片(300词连续识别功耗小于1mA,含麦克风数据处理)已实现百万颗级别出货。WTM-8系列(至少24 TOPS算力,功耗仅为市场同类方案的10%,支持10ms超低延迟Video See Through)。WTM8600新一代视觉AI正在研发中。与科创板上市公司安凯微深度合作。2024年荣获财联社"最具投资价值奖"。
炬芯科技(珠海)
炬芯科技采用SRAM存内计算路线,构建CPU+DSP+NPU三核异构架构,率先实现了存内计算技术在品牌音频产品中的商业化落地。
•ATS323X芯片:已落地品牌客户旗舰无线麦克风和无线电竞耳机。
•ATS362X芯片:切入专业音频头部品牌供应链,已在品牌耳机和麦克风中跑量。
•年报披露:率先实现存内计算技术商业化应用,是目前存算一体商业化进展最快的细分场景之一。
•模数混合SRAM存内计算(MMSCIM),CPU+DSP+NPU三核异构架构,支持全链路48KHz@32bit高清音频通路,48K双麦AI ENC降噪算法,2.4G私有协议端到端延迟小于20ms。ATS323X系列已实现品牌客户量产(旗舰无线麦克风、无线电竞耳机);ATS362X切入专业音频头部品牌供应链。荣获"2025年度中国IC设计成就奖";入选"2025年度中国数智产业创新产品榜"。
智芯科(杭州/合肥)
智芯科(AISTARTEK)创立于2019年,是国内SRAM数字存算一体路线的重要代表。创始团队均来自UTSTARCOM、Adobe、Marvell、展讯等国内外知名半导体企业,平均行业经验30年。公司专注于基于SRAM的精度无损数字存内计算,产品线覆盖从超低功耗端侧到具身智能大算力的全场景。
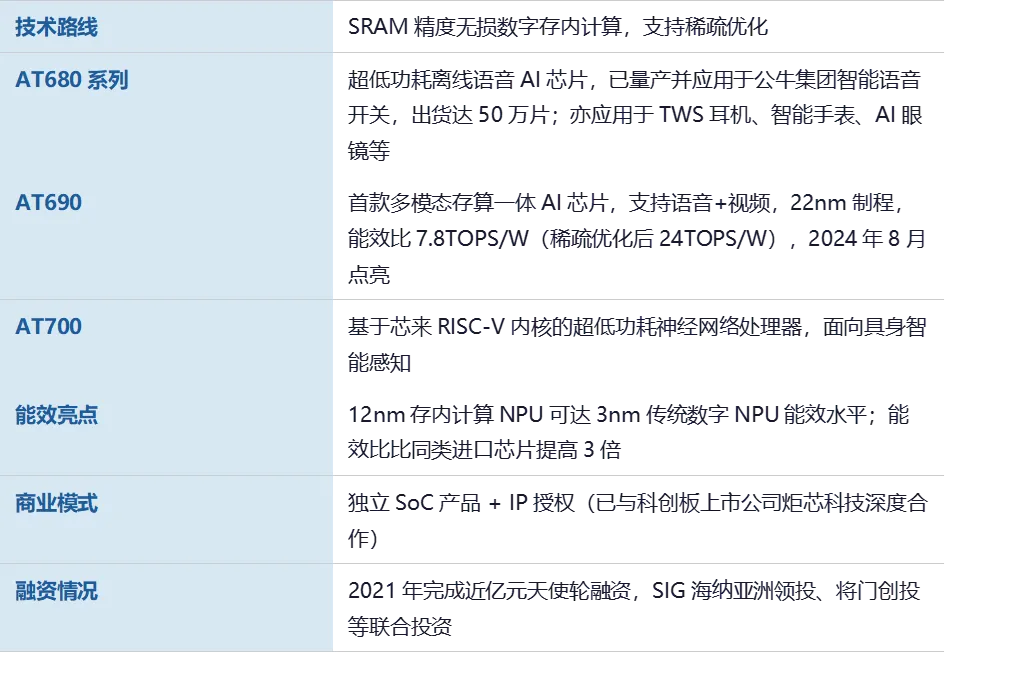
AT680(22nm,7.8 TOPS/W,多模态存算一体AI芯片,语音+视频,已量产50万片)。AT690(22nm,稀疏优化后24 TOPS/W,首款支持语音+视频的多模态芯片,2024年8月成功点亮并跑通端侧语音和图像模型)。AT8600(超大算力,面向大模型、低空飞行、自动驾驶SoC)。已与科创板上市公司炬芯科技深度合作(IP授权+独立SoC)。
苹芯科技(北京)
苹芯科技专注于存算一体AI芯片设计与应用,2025年发布了两款重磅产品,在边缘AI领域取得显著突破。
•PiMCHIP-N300:存算一体NPU芯片,功耗低至毫瓦级,面向端侧AI推理。
•PiMCHIP-S300:多模态智能感知SoC芯片,深度融合存算一体技术与多处理器架构,适用于智能家居、智能穿戴等场景。
•制程进展:在28nm及22nm制程节点上首次实现存算一体技术产品化,已交付客户使用。
•获奖荣誉:2025年11月获AABI火炬技术转移奖。未来规划:联合代工厂推进eNVM工艺量产,构建“存算+”生态。
•PiMCHIP-N300(28nm/22nm存算一体NPU,毫瓦级功耗,面向端侧AI推理)。PiMCHIP-S300(28nm/22nm多模态智能感知SoC,深度融合存算一体与多处理器架构)。2024年8月发布国内首颗商用端侧28nm存算一体AI芯片;2025年5月推出N300存算一体NPU,突破传统MCU算力瓶颈。已交付客户使用,面向智能家居、智能穿戴等场景。
4.3 新型存储介质与标准阵营
微纳核芯(北京)
微纳核芯孵化于北大信研院,首创三维存算一体(3D-CIM)架构,技术路线独特,获得兆易创新战略入股。
•核心技术:3D-CIM(三维存算一体),将计算逻辑与存储垂直堆叠,实现极致融合。
•性能数据:相比传统架构,可实现4倍以上算力密度提升、10倍以上功耗降低。
•标准主导:牵头启动全球首个RISC-V存算一体标准研制,引领行业生态建设。
•商业进展:已与多家手机龙头厂商深度合作,推进存算一体芯片在移动端的落地。
•资本动态:2026年3月获兆易创新战略入股,强化存储-计算协同生态。
•3D-CIM(三维存算一体),在存内计算基础上创造性加入"近存计算"和"RISC-V存算",可扩展至先进制程(22nm及以下)。相比传统架构,可实现4倍以上算力密度提升、10倍以上功耗降低。受中国RISC-V工委会任命,牵头全球首个RISC-V存算一体标准研制。2025年10月完成超亿元B轮融资(蓝驰创投领投,中芯聚源、锦秋基金等)。已完成多个客户导入,与多家手机龙头厂商深度合作。
昕原半导体(上海)
昕原半导体是国内唯一实现28nm ReRAM存储芯片量产的企业,技术可用于VR/AR等新型终端设备。
•技术路线:阻变存储器(ReRAM),28nm制程已实现量产。
•资本背景:字节跳动曾战略入股,技术方向与元宇宙终端高度契合。
•应用方向:VR/AR、智能穿戴等新型终端,兼顾低功耗与高计算密度需求。
•国内唯一实现28nm/22nm ReRAM存储芯片量产的企业,Fab-lite模式,自建先进制程ReRAM中试后道生产线。覆盖器件材料、工艺制程、芯片设计及中试量产全链条,与CMOS工艺和常规Foundry兼容。2024年3月完成近亿美元Pre-A轮融资(上海联和投资领投);2025年9月获阿里巴巴(蚂蚁集团)、字节跳动战略投资;2026年3月完成C轮融资(蚂蚁集团等参与)。
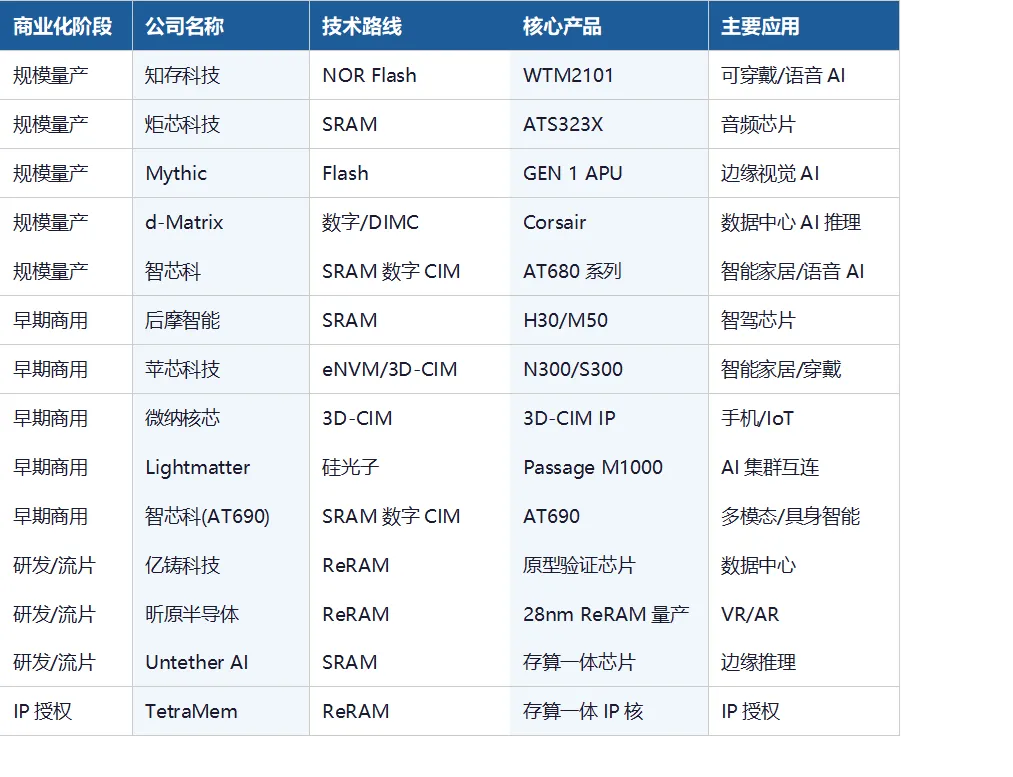
五、商业化全景:谁已跑通从0到1?
综合各公司公开信息,以下按商业化成熟度对主要存算一体公司进行分层梳理:
六、大模型时代的演进路径
存算一体技术并非一蹴而就,其在AI时代的价值将分阶段释放:
第一阶段:专用加速器(当下~2027年)
存算一体芯片作为GPU万卡集群的补充,处理推理任务中的特定计算密集型操作(如矩阵乘法)、数据预处理和推荐系统。与GPU协同而非替代,共同构成异构计算底座。
第二阶段:深度融合(2027~2030年)
随着Chiplet技术和3D堆叠封装工艺成熟,存算一体单元将与GPU/NPU通过先进封装深度融合,形成“近存+存内”的混合架构,整体系统能效再提升一个数量级。
第三阶段:主导万卡集群(2030年以后)
当ReRAM、MRAM等新型存储介质成熟量产,存算一体将从补充角色升级为主导角色,彻底重构AI计算集群的基础架构,颠覆延续七十年的冯·诺伊曼架构,推动AGI时代算力基础设施的范式转变。
七、总结与展望
存算一体正从学术前沿走向产业爆发的前夜。2025年全球120亿美元市场规模、中国约30%的占比背后,是国内外企业从不同技术路线切入、竞相推进商业化的生动局面。
在端侧,知存科技百万颗出货、炬芯科技品牌落地,证明存算一体已具备真实商业价值;在智驾领域,后摩智能完成车规认证并量产,标志着存算一体叩开万亿级汽车市场的大门;在数据中心,d-Matrix的Corsair芯片出货和Lightmatter的光子技术商业化,展示了存算一体在大模型推理时代的巨大潜力;在端侧多模态赛道,智芯科的AT680已量产出货50万片、AT690实现语音+视觉多模态融合,展现了SRAM数字存算一体的商业化活力;在前沿探索上,清华-华为-字节跳动联合发布的28nm混合存内计算芯片,则代表了中国力量在全球最高学术舞台上的亮相。
与此同时,挑战依然严峻:模拟计算的精度限制、存算一体EDA工具链的成熟度、大算力场景下的良率控制,以及与现有软件生态(CUDA等)的兼容性问题,都需要整个行业共同攻克。
但趋势已不可逆转。当摩尔定律逼近物理极限,当大模型对算力的需求永无止境,当能效比成为AI芯片最重要的竞争维度——存算一体,正在成为AI计算史上最重要的一次架构革命。
Edge AI Pulse·2026年4月
本报告综合公开资料整理,如有疏漏欢迎指正。不构成任何投资建议。