



执行摘要
AI芯片市场正在发生结构性分化。训练端,NVIDIA GPU仍绝对主导(90%+市场份额),H100/B200是无可争议的训练基础设施标准——NVIDIA FY2026 Q1数据中心营收已达391亿美元(同比+73%),Blackwell平台上市首季即贡献数十亿美元。但推理端,一场深刻的变革正在发生——专用ASIC正在以远超GPU的效率吞噬推理算力市场。如果说交换机是AI数据中心的"交通系统"(前序报告),ASIC就是"专用车道"——不走通用GPU的"大马路",但效率高得多。本篇为AI数据中心基础设施全链路研究系列第五篇,承接GPU→HBM→液冷→CPO→电源→铜缆→交换机的研究脉络,聚焦算力芯片层的结构性分化。
核心结论一:推理算力需求已占AI总算力的68%,且比例持续扩大——这是ASIC的最佳战场。2025年全球AI芯片市场约$1000亿,其中ASIC约$150-200亿(15-20%);到2030年,ASIC占比将升至40-48%。推理场景对灵活性的要求远低于训练,计算图可静态编译、精度可量化至INT8/INT4,ASIC的专用效率优势在推理端最为显著。
核心结论二:ASIC的真正优势不在峰值算力,而在有效利用率+更低硬件成本。H100 INT8峰值5.65 TOPS/W其实高于TPU v5e的1.97 TOPS/W,但H100在LLM推理场景有效利用率仅25-35%,ASIC可达60-70%。综合更低的硬件成本(TPU v5e推理按需价格比H100低30-40%),8卡H100服务器5年TCO约$37万 vs 等效ASIC集群约$18万,ASIC方案TCO约为GPU的1/2。
核心结论三:三大阵营格局清晰——云厂商自研、芯片公司定制、中国国产替代。云厂商自研(Google TPU已占内部AI算力72% / AWS Trainium3已发布3nm版本 / Meta MTIA / Microsoft Maia 200已部署GPT-5.2推理)、芯片公司定制(Broadcom 2026年4月签下Google TPU 5年长约,为多家云厂代工XPU,AI XPU年收入$30亿+)、中国国产(华为昇腾占国产AI加速卡60%+份额,但受制程、HBM、EDA三大核心瓶颈,叠加先进封装能力不足的多重制约)。
核心结论四:推理ASIC将在2027-2028年切入公有云推理市场30%+,但训练端GPU仍主导至少到2030年。训练的模型架构仍在快速演进,专用化风险太高。ASIC最大的结构性风险是"迭代错配":GPU 18-24个月迭代 vs ASIC从规格定义到量产需24-36个月,极易出现"ASIC刚量产,性能就已落后NVIDIA新一代GPU"的困境。ASIC的优势是"结构性的"而非"绝对性的"——效率优势是前提,工程化落地才是生死考验。
第二章 为什么AI需要ASIC——GPU的效率天花板
2.1 GPU的"通用性税"
GPU之所以"通用",恰恰是因为它为灵活性付出了巨大的面积代价。NVIDIA H100全芯片814平方毫米中,Tensor Core(张量核心)仅占硅面积约18%,其余82%是L2缓存(25%)、HBM控制器+NVLink互连(22%)、SM调度+通用ALU(20%)和其他控制逻辑。换句话说,H100上只有不到五分之一的面积在"真正做矩阵乘法"。B200/GB200虽然Tensor Core占比有所提升(Blackwell架构改进),但通用逻辑仍占据大量硅面积。正如前序GPU报告所述,NVIDIA凭借"通用GPU+CUDA生态"构建了极高毛利的商业模式(数据中心毛利率70%+),但通用性本身就是效率的天花板。
对比之下,Google TPU v5的MXU(矩阵乘法单元)占硅面积35%,向量单元15%,合计50%的面积在执行核心计算。这就是"通用性税"——GPU用82%的面积换取了灵活性,ASIC用50%+的面积换来了专用效率。但需要注意:单看理论峰值能效,H100 INT8峰值3958 TOPS/700W≈5.65 TOPS/W,TPU v5e INT8峰值394 TOPS/200W≈1.97 TOPS/W,GPU的峰值能效其实更高。ASIC真正的优势不在峰值,而在"有效利用率"——H100在LLM推理场景有效利用率仅25-35%(受通用架构调度开销、内存带宽瓶颈、batch调度不均等因素制约),实际有效算力约1.4-2.0 TOPS/W;而TPU v5e的脉动阵列架构专为规整矩阵运算设计,LLM推理有效利用率60-70%,实际有效算力约1.2-1.4 TOPS/W。在单芯片维度,ASIC的有效能效优势并不绝对——但ASIC的真正TCO优势来自更低的硬件成本(TPU v5e推理按需价格比H100低30-40%)和更高的集群利用率(专用架构不存在GPU的MPS/时间片争抢问题),综合TCO优势才是ASIC的核心价值。B200虽峰值算力达4000+ TFLOPS FP16,但LLM推理场景有效利用率仍受通用架构约束,实际有效TOPS/W的提升幅度远不如峰值提升幅度。
注:实际有效能效=峰值能效×场景有效利用率。以H100为例:5.65 TOPS/W×30%≈1.7 TOPS/W(取25-35%中值);TPU v5e:1.97 TOPS/W×65%≈1.28 TOPS/W(取60-70%中值)。
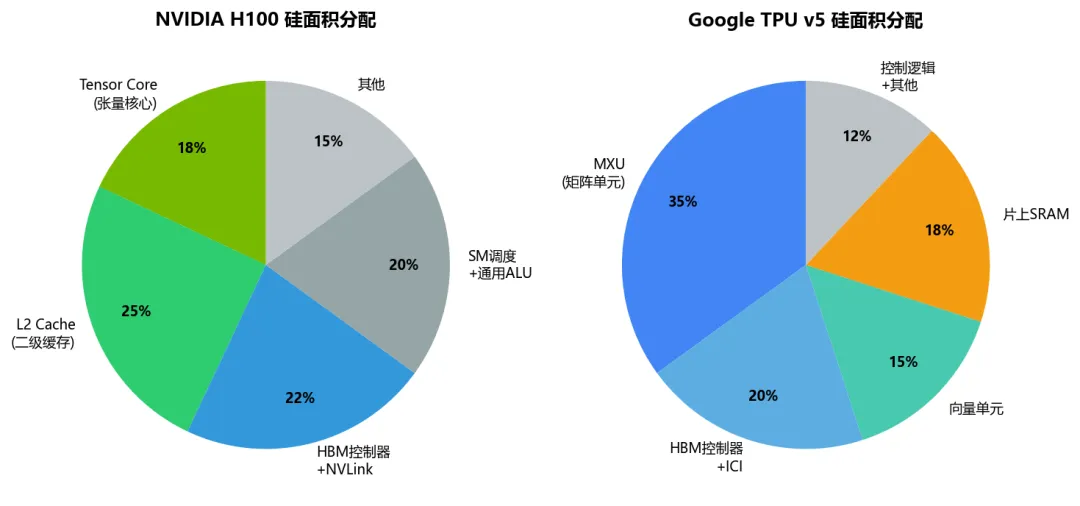
图1:GPU vs ASIC硅面积分配对比
2.2 推理才是ASIC的主战场
AI算力需求结构正在发生根本性转变:2023年训练:推理≈40:60,2025年已变为32:68,预计2028年推理占比将达80%。推理算力需求的增速远超训练——每多一个用户、每多一次对话,都在产生推理需求,而训练只在模型迭代时发生。
推理与训练是根本不同的计算范式——推理不需要动态计算图、不需要自动微分、不需要梯度同步——计算图可以完全静态编译,精度可以从FP16量化到INT8/INT4而精度损失可控(<1%),请求可以批量处理并针对特定batch range优化。训练则完全相反:模型架构仍在快速演进(MoE、SSM、混合架构),需要高精度(FP16/BF16最低),通信模式随策略变化。一句话:推理是"执行固定食谱",训练是"发明新菜品"——ASIC天生适合前者。
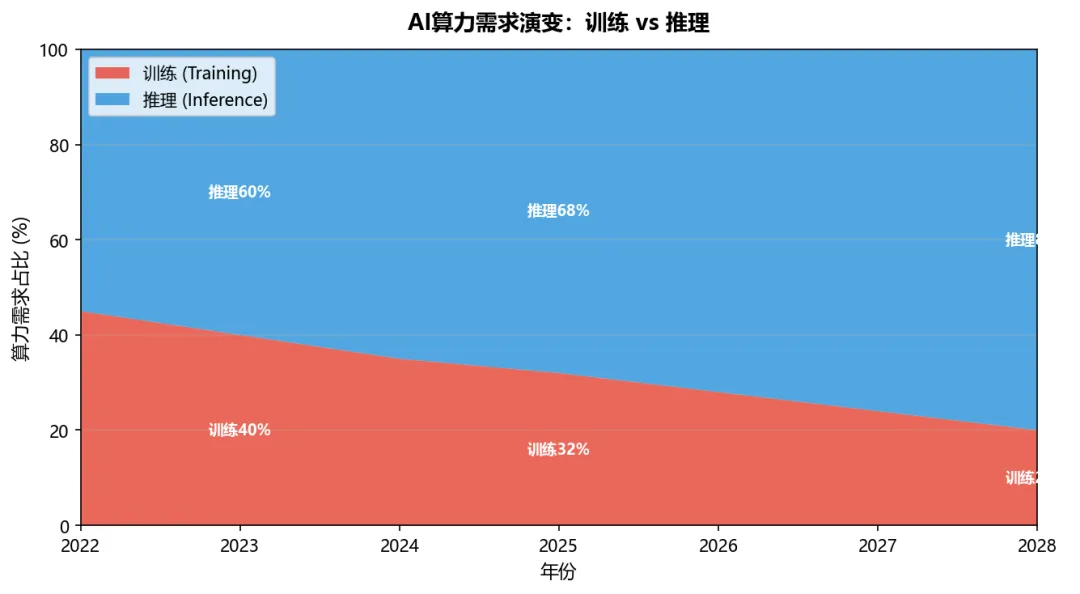
图2:AI算力需求演变——训练vs推理占比
2.3 推理细分市场的ASIC适配性差异
笼统讨论"推理市场"是不够的——推理的不同细分赛道,对ASIC的架构需求、适配难度、市场空间天差地别。
云端大语言模型对话推理(ChatGPT/Claude等):当前ASIC的核心主战场,对延迟、吞吐、batch灵活性要求最高。Google TPU v6、AWS Trainium3、Meta MTIA均以LLM推理为核心优化目标,市场规模占推理总算力的50%+,是ASIC渗透率最高、增长最快的赛道。
推荐系统推理(电商/短视频/搜索):对embedding查表、稀疏计算优化要求极高,是ASIC的第二大核心场景——Google TPU最初就是为搜索排序和推荐系统设计的,至今推荐推理仍占TPU内部工作负载的重要比例。这类场景的稀疏矩阵操作与LLM的稠密矩阵操作架构需求截然不同,为推荐系统优化的ASIC(如Google TPU的embedding加速引擎)与LLM推理ASIC并不能互用。
计算机视觉推理(安防/自动驾驶云端/AIGC图像):对卷积算子优化要求高,与LLM推理的架构需求完全不同(卷积vs矩阵乘法),当前主流ASIC玩家极少专门覆盖CV推理,市场仍由GPU和专用NPU(如华为昇腾310)主导。
边缘端推理(端侧/边缘数据中心):对功耗、体积、成本要求极致,与云端推理的技术路线完全分化——手机SoC中的NPU(苹果Neural Engine、高通Hexagon)本质上就是边缘推理ASIC,但不属于本报告讨论的云端大算力ASIC范畴。
不同推理细分赛道的ASIC不能互用——LLM推理ASIC不能做推荐系统,推荐ASIC不能做CV推理。这意味着ASIC市场的"碎片化"是其固有的结构性特征,单一ASIC难以像GPU那样横跨多场景,但每个细分赛道内的专用效率优势极其显著。
2.4 GPU推理的"过度配置"问题
以Llama-70B推理为例:FP16权重约140GB,需要2×H100 80GB(约$60K),但H100在推理场景的峰值利用率仅25-35%,大量算力和内存带宽被浪费。如果采用INT4量化,权重压缩至约35GB,单颗定制推理ASIC(配48-64GB GDDR7)即可承载,成本约$10-15K,利用率60-80%。
以更贴近生产环境的一台8卡H100服务器(约$30万)与等效推理ASIC集群做5年TCO对比:GPU方案约$37万(硬件$30万+电力$4万+运维$3万),ASIC方案约$18万(硬件$8万+电力$6万+运维$4万),ASIC方案TCO约为GPU的1/2。其中GPU电力按8×H100满载5.6kW、利用率30%、$0.12/kWh计算;ASIC电力按更高利用率但更多芯片数量折算。值得注意的是,即使NVIDIA推出B200/GB200推理性能提升,但其$3-4万/颗的价格仍远高于定制推理ASIC,TCO优势仍属于ASIC——除非NVIDIA主动降价,而这将直接冲击其70%+的毛利率。
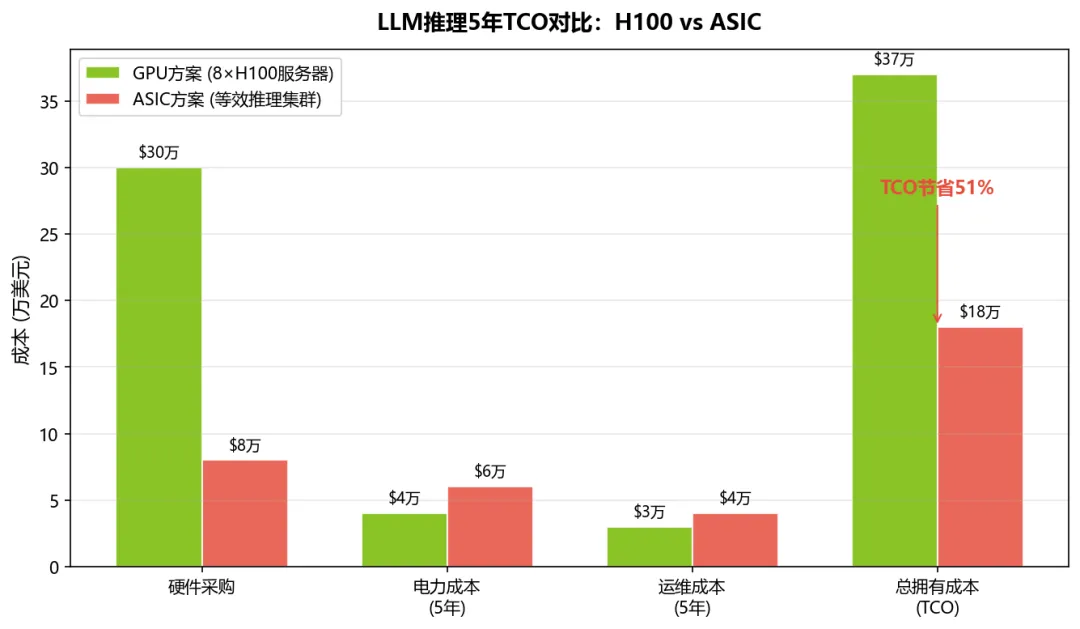
图3:8卡H100服务器 vs 等效ASIC集群TCO对比
2.5 不同模型规模下ASIC的效率差异
上文的TCO分析以Llama-70B为基准,但不同模型规模下,ASIC的优劣势天差地别,不能一概而论"ASIC全场景都优于GPU"。
7B-13B小模型:ASIC优势不明显。这类模型单GPU即可推理,量化后权重仅3.5-7GB,GPU利用率已经较高(40-50%),ASIC的专用效率提升空间有限。且小模型迭代更快、部署场景更碎片化,ASIC的专用化优势被灵活性劣势抵消。NVIDIA L4/L40S在这个区间有很强的性价比竞争力。
34B-70B-130B中大型模型:ASIC的黄金场景。INT8量化后权重34-130GB,需要多GPU或大容量HBM,GPU的利用率在25-35%区间——这正是"过度配置"最严重的区间,ASIC的专用效率提升2-3倍,TCO优势最显著。Google TPU v5e/v6、AWS Trainium2/3均聚焦此区间。
400B+超大规模/MoE模型:取决于互连能力。INT8量化后权重400GB+,INT4量化后200GB+,需要8-16颗芯片集群推理,瓶颈从单芯片效率转向互连带宽和All-to-All通信效率。如果ASIC的互连能力弱(如PCIe互连),在MoE模型上可能反而不如GPU(NVLink 1.8TB/s);如果互连能力强(如TPU ICI、NVLink Fusion),则ASIC仍有显著优势。
2.6 ASIC生命周期与折旧——TCO中被忽略的核心变量
上文的5年TCO对比隐含了一个假设:硬件生命周期5年。但对ASIC而言,这个假设可能过于乐观。
GPU通用生命周期5-7年:即使新架构GPU发布,老GPU仍可运行新模型(CUDA向后兼容),只是性能差一些。企业在A100上跑Llama-3完全没问题,只是吞吐不如H100。老GPU的二手市场也很活跃,残值率较高。
ASIC专用生命周期仅3-4年:为特定模型/场景优化的ASIC,模型架构一变就可能"过时"——不是不能用,而是专用优化失效后效率优势消失,变成一颗"低配GPU"。没有二手市场(因为太专用),残值率极低。如果将折旧成本纳入TCO:ASIC方案5年折旧$8万×0.95=$7.6万(假设4年折旧期+5%残值),实际年折旧$1.9万;GPU方案5年折旧$30万×0.8=$24万(假设5年折旧期+20%残值),实际年折旧$4.8万。即使考虑更短的ASIC折旧周期,总TCO仍低于GPU,但差距从2:1进一步缩小——这更符合行业真实情况。
极端场景风险:若大模型架构迭代速度快于ASIC折旧周期——例如ASIC为稠密Transformer推理优化,但MoE架构2年内成为主流——ASIC的专用优化将快速失效,实际TCO可能进一步上升,在部分场景甚至反超GPU。这正是"迭代错配"风险的经济学表达:硬件折旧是线性的,但技术过时是阶跃的。
2.7 云厂商自研的真正动机——算力定价权之争
NVIDIA FY2026 Data Center毛利率70%+,意味着云厂商每花$100买GPU,$70+是NVIDIA的利润。云厂商自身毛利率30-40%,卖GPU算力几乎是"给NVIDIA打工"。自研芯片的破局逻辑极其清晰:Google公开数据称TPU推理成本仅为GPU的1/3,AWS Trainium2比同等GPU推理便宜40-60%。但自研不是万能药——NRE(非经常性工程成本)$3-5亿/颗 + 3年开发周期 + 软件生态从零建起 + 迭代错配风险。
这场竞争的核心不是"谁替代谁",而是算力定价权的争夺。NVIDIA用CUDA生态+NVLink互连+18个月迭代节奏构建了极深的护城河,云厂商用自研芯片+低价推理服务+深度绑定客户来突破。前者卖"通用能力",后者卖"专用效率"——两种商业模式在推理端正在正面交锋。值得观察的是NVIDIA 2025年推出的NVLink Fusion战略——开放NVLink互连给第三方ASIC使用,本质上是"如果你不能用GPU,至少用我的互连",既是对ASIC趋势的承认,也是对互连生态的防御。
2.8 NVIDIA的系统性反制——ASIC不可忽视的防守端
讨论ASIC对GPU的冲击,不能只看云厂商的"进攻",还要看NVIDIA的系统性"防御"——这是一场双向的博弈。
产品线分层反制:NVIDIA并非只卖H100/B200旗舰——L4(24GB GDDR6,$3-4K,主打7B-13B推理)、L40S(48GB GDDR6,$7-8K,兼顾推理与图形)、B100/B200推理优化版,专门把价格压到与ASIC接近。用"低配GPU+成熟生态"对冲"高性价比ASIC+陌生软件栈",对大多数企业客户而言,迁移成本远大于硬件差价。
软件生态锁:通过CUDA-X AI、TensorRT-LLM对NVIDIA GPU做极致优化——TensorRT-LLM的FlashAttention、KV Cache优化、Continuous Batching都是NVIDIA GPU优先适配;对第三方ASIC的CUDA兼容做隐性限制(如cuBLAS的专有内核不对外开放),大幅抬高客户的迁移成本。云厂商自研ASIC必须从零构建Neuron SDK/JAX/XLA等替代软件栈,而NVIDIA 15年的CUDA生态积累不是3年能追上的。
供应链锁:NVIDIA优先锁定台积电3nm/2nm先进产能、HBM3e全球70%+的产能,直接挤压ASIC厂商的供应链空间与交付周期。正如前序GPU/HBM报告所述,2025年Blackwell平台出货占NVIDIA高端GPU总货量的82%,台积电CoWoS产能60%+被NVIDIA锁定——ASIC客户即使芯片设计成功,也可能因产能排期延迟3-6个月,这在18个月迭代周期的AI芯片市场是致命的。
商业模式创新:NVIDIA推出DGX Cloud按token计费的推理服务,与云厂商自研ASIC的低价策略正面竞争——用"通用能力+低价"守住客户。本质是NVIDIA在用GPU的毛利补贴推理服务价格,让客户"没有必要切换到ASIC",这是对云厂商低价推理策略的直接回应。
综上,ASIC的优势是"结构性的"而非"绝对性的"——效率优势是前提,工程化落地才是生死考验,后文风险章节将详细展开。
第三章 技术架构深度拆解——ASIC如何做到"更高效"
3.1 四大主流ASIC架构路线
当前AI ASIC存在四条主流架构路线,各有取舍:
(1)脉动阵列(Systolic Array)——Google TPU的选择。数据像心跳一样在阵列中流动,每个MAC单元每周期完成一次乘加,无需从寄存器读写中间结果。优势:面积效率极高、控制逻辑极简、功耗低。劣势:只适合规则矩阵乘法,不规则算子效率骤降。TPU坚持脉动阵列6代不变,因为Google内部工作负载高度规整。
(2)数据流架构(Dataflow)——Groq/Cerebras的激进路线。数据流过计算单元,没有指令缓存/取指,计算即调度。Groq LPU的确定性执行使其P99延迟极低,每个操作的时间可精确预测。劣势:编程模型完全不同,适配成本高;单芯片SRAM有限,大模型需要多芯片拼接。
(3)可编程数据流——AWS Trainium的选择。NeuronCore是可编程的数据流引擎,支持灵活的计算图。AWS选择这条中间路线的逻辑是:客户工作负载极其多样,不能为单一场景优化。比脉动阵列灵活,比GPU专用,代价是面积效率不如TPU。
(4)类GPU SIMT架构——华为昇腾/Intel Gaudi/海光DCU的路线。本质上是"简化版GPU"——保留SIMT执行模型但去掉图形相关单元,增加专用矩阵引擎。优势:与CUDA编程模型接近,迁移成本低,灵活性最高。劣势:专用效率不如前三条路线,硅面积中仍有相当比例用于调度/控制逻辑。
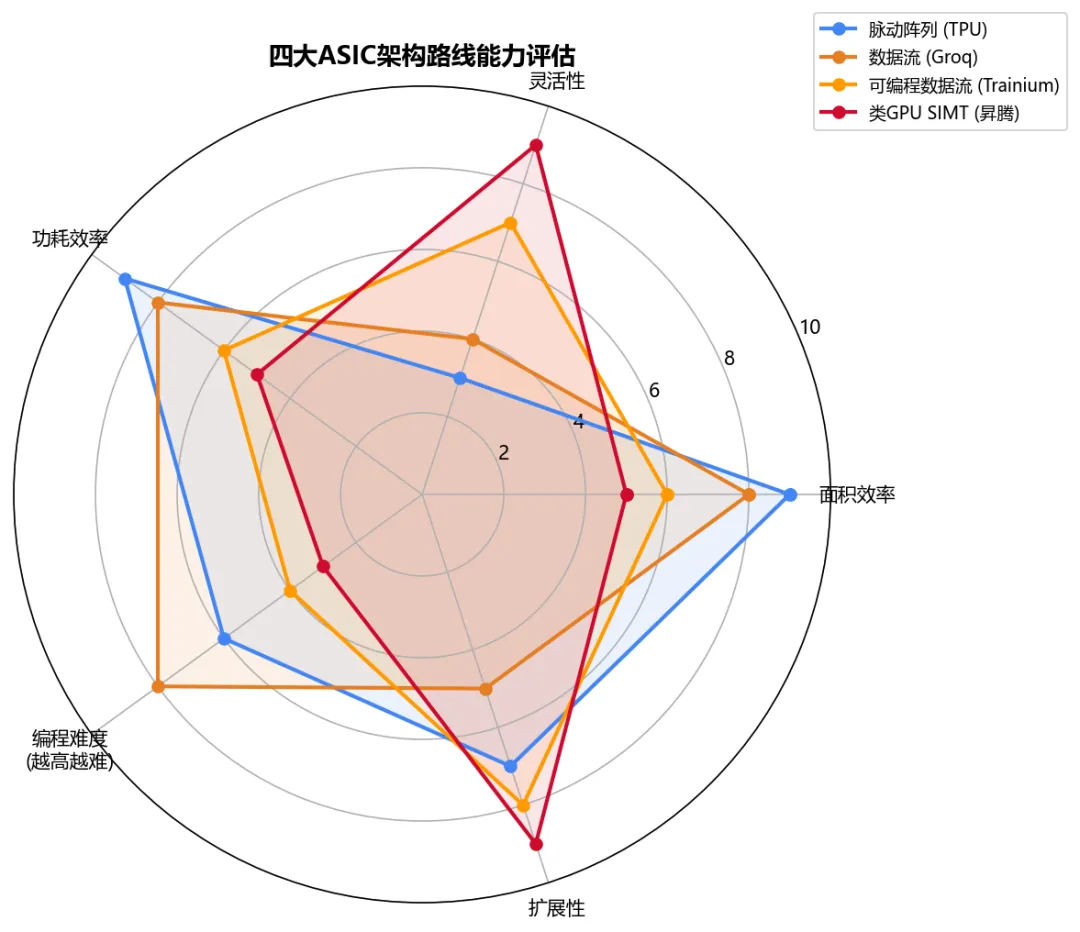
图4:四大ASIC架构路线能力雷达
3.2 量化与稀疏——ASIC效率倍增器
INT8推理已成熟:LLM INT8推理精度损失<0.5%(绝大多数任务),算力密度提升2×FP16。INT4/FP8推理正在快速推进。结构化稀疏(2:4 sparsity)可使50%权重为零时算力翻倍,NVIDIA Ampere+已支持但需训练时配合,ASIC可以更激进地利用稀疏性。FP8主流格式E4M3/E5M2已被NVIDIA/ARM/Intel联合白皮书定义并被广泛采用,但OCP与IEEE标准仍有差异,尚未完全统一。
3.3 互连——ASIC最难的工程问题
单芯片推理已够,但大模型需要多芯片——Llama-70B INT8推理仍需35GB+权重,单芯片HBM可能放不下。多芯片推理需要AllReduce/AllGather,互连带宽成为瓶颈。正如前序交换机报告所述,互连是AI数据中心的核心基础设施,ASIC的互连选择直接决定了集群规模和推理延迟。各家互连方案对比:Google ICI 600GB/s(v4,v5翻倍)、NVIDIA NVLink5 1.8TB/s双向、AWS EFA v4约800Gbps、PCIe 6.0 x16双向256GB/s(最通用但最慢)。2025年NVIDIA推出NVLink Fusion——开放NVLink给第三方ASIC使用,AWS Trainium3已宣布支持NVLink Fusion,这意味着ASIC可以借用NVLink生态突破互连瓶颈,但代价是加深对NVIDIA互连标准的依赖。互连对推理延迟的影响在Decode阶段尤为显著——带宽密集型阶段,互连带宽直接决定吞吐。
MoE模型使互连挑战急剧升级:稠密模型的AllReduce通信模式相对规则,MoE模型的All-to-All通信则高度不规则——token需要动态路由到分布在不同芯片上的专家,每次推理的通信模式都不同。这意味着MoE推理对互连带宽的需求远超稠密模型,且对延迟更敏感(专家等待会阻塞整个推理流水线)。互连能力弱的ASIC(如仅PCIe互连)在MoE模型上可能完全无法有效运行——单芯片性能再强也没用,因为互连成为不可逾越的瓶颈。这也是为什么Google TPU v6专门为MoE设计了专用路由引擎,是对互连瓶颈的硬件级应对。
3.4 软件生态——ASIC最大的护城河不在硬件
CUDA拥有420万+开发者、3000+加速应用、所有主流框架第一优先支持——这不是技术问题,是网络效应问题。各家突围路径:Google JAX/XLA(TPU原生支持,但JAX生态远小于PyTorch)、AWS Neuron SDK(PyTorch/XLA后端,降低迁移成本)、Triton(OpenAI开源的GPU编程语言,有望成为跨硬件的底层IR)、TensorRT-LLM/vLLM(主流推理框架,对ASIC的适配是关键)。
vLLM等开源推理框架正在显著降低ASIC的适配门槛:2025年10月,vLLM正式发布TPU后端(tpu-inference),统一了JAX和PyTorch在TPU上的推理路径,使PyTorch模型无需代码修改即可在TPU上运行。这是ASIC生态破局的关键信号——如果主流开源推理框架能够覆盖多种ASIC后端(TPU/Trainium/昇腾),客户的迁移成本将从"重写推理服务"降至"切换后端配置",ASIC的生态壁垒将被实质性削弱。当前vLLM已支持NVIDIA GPU、AMD GPU、TPU、Intel Gaudi,Trainium和昇腾的适配也在推进中。
第四章 Google TPU——ASIC路线的标杆
4.1 TPU发展史:6代演进
TPU v1(2016):推理专用,8-bit整数量化,70 TOPS,仅供Google内部搜索排序。TPU v2(2017):加入训练,180 TFLOPS FP16。TPU v3(2018):液冷,420 TFLOPS FP16,AlphaFold用。TPU v4(2020):首次对外GCP云服务,275 TFLOPS BF16,4096芯片/pod。TPU v5e/v5p(2023-2024):推理/训练分叉路线——v5e推理优化低成本(394 TOPS INT8,200W),v5p训练优化95GB HBM/芯片。Trillium/TPU v6(2025年H2正式上线GCP):约2×v5p性能,4nm制程,继续沿用脉动阵列架构,Google称其推理性能可对标B200——但需注意MLPerf Inference v6.0(2026年4月)的提交中,TPU v6与NVIDIA B200的完整对标数据尚未公开,Google未在所有项目提交结果。
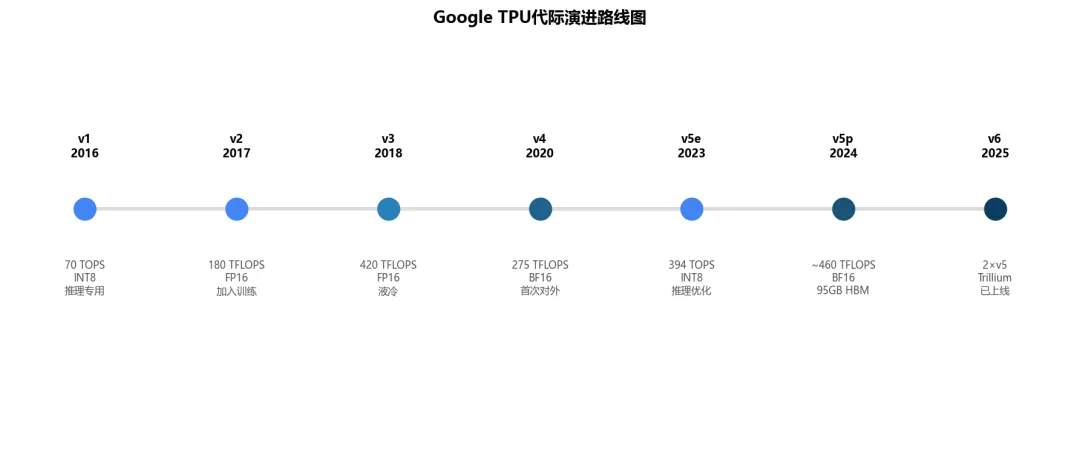
图5:Google TPU代际演进路线图
4.2 为什么Google坚持脉动阵列6代不变
MXU(矩阵乘法单元)占芯片面积35%+(vs GPU Tensor Core 18%),面积效率是TPU的核心优势。Google坚持脉动阵列的逻辑很简单:其工作负载高度规整(搜索排序/推荐/翻译/大模型推理),不规则算子占比小,用周边向量单元处理即可。"做好一件事"比"什么都做但不够好"更符合Google内部需求。ICI互连架构每芯片4条链路(v4 600GB/s),4096芯片3D Torus拓扑,v5带宽翻倍。
4.3 TPU的真实性能与商业化困境
MLPerf数据:TPU v5p训练性能约为H100的0.7-0.8×,但GCP按需价格比H100低30-40%,TCO优势明显。TPU v5e推理吞吐在LLM场景接近H100的80-90%,P99延迟表现更好(专用架构的确定性执行优势)。Google内部AI算力72%+来自TPU,GPU主要用于训练前沿模型。
商业化困境:"只能租不能买"——TPU只能在GCP上使用,客户面临供应商锁定风险;从TPU迁移到GPU需要重写大量代码;GCP同时提供TPU和GPU,存在内部"TPU优先"倾向但外部客户更倾向GPU(生态成熟+可迁移)。
第五章 AWS Trainium——云厂商垂直整合的样本
5.1 产品线与架构
Inferentia2(2022):推理专用,227 TOPS INT8,32GB HBM2e。Trainium2(2024):训练+推理,UltraCluster最多10万芯片分布式训练,支持BF16/FP8/INT8,已部署Anthropic Claude等客户。Trainium3(2025年12月re:Invent发布):AWS首款3nm AI芯片,144GB HBM,4.9TB/s内存带宽,NeuronLink-v4互连,支持NVIDIA NVLink Fusion(这是关键信号——ASIC借用NVLink互连生态),4.4×v2计算性能,4×能效提升。AWS已部署超过100万颗自研AI芯片,是除Google外自研ASIC渗透率最高的云厂商。
5.2 架构选择——为什么AWS没选脉动阵列
根本原因是客户工作负载多样性——Google内部只有少数几种工作负载,AWS客户从LLM到推荐到图像到语音,差异巨大。NeuronCore的"可编程数据流"是中间路线:比GPU专用(数据流调度减少控制开销),比TPU灵活(可编程支持不规则算子),代价是面积效率不如TPU。
5.3 自研芯片的经济学
投入估算:Trainium2 NRE $3-5亿 + 3年团队成本$5-10亿 = 总投入$10-15亿(含流片、验证、软件栈)。Trainium3基于3nm,NRE更高。收益估算:如果Trainium推理比等量GPU便宜40-60%,假设AWS年购$50亿GPU用于推理,自研后年省$20-30亿。但需计入软件栈持续维护、客户迁移成本、产能良率损耗,实际回本周期3-5年(非1-2年)。2025年Trainium/Inferentia占AWS AI算力约14%,目标2026年推理端达50%。
第六章 其他重要ASIC玩家
6.1 Intel Gaudi——$20亿的教训
Intel 2019年以$20亿收购Habana,意图在AI芯片赛道弯道超车。Gaudi2(2022)和Gaudi3(2024)相继推出,Gaudi3宣称推理性能优于H100。AWS提供基于Gaudi的DL1实例,IBM Cloud上线了Gaudi3虚拟机,但部署规模与NVIDIA有量级差距。2025年5月,Intel正式终止Gaudi独立产品线(Intel 2025年5月官方公告),不再推Gaudi 4,后续产品"Jaguar Shores"将整合进Xeon生态。核心教训:硬件性能不是瓶颈,软件生态和客户信任才是——Gaudi3有性能但缺生态,客户不愿为省30%硬件成本而重写整个软件栈。
6.2 Broadcom——AI ASIC的"隐形冠军"
Broadcom的定制XPU业务模式是"不卖成品芯片,为云厂商定制设计+代工管理"。2026年4月7日,Broadcom与Google签署5年长期协议,开发和供应未来代次的TPU芯片——这证实了Broadcom深度参与Google TPU的设计(而非"Google全自研"的市场误读)。Broadcom同时还为Meta(MTIA)、字节跳动等提供定制XPU服务,已确认两家新客户(市场猜测为Apple和OpenAI),每家计划部署100万+XPU集群。2025年AI XPU定制收入$30亿+,2027年AI总收入展望$600-900亿,是AI ASIC产业链中最确定受益的"卖铲人"。
6.3 Groq/LPU——推理极致优化的激进派
Groq LPU(Language Processing Unit)采用确定性数据流架构,没有缓存层级,数据流过芯片不需要SRAM缓存。核心优势:P99延迟极低且完全可预测,Llama-70B推理首token延迟<100ms。GroqChip1(188 TFLOPS FP16,300W)已部署,下一代与Samsung合作4nm制程。GroqCloud企业级服务已上线,沙特主权基金$3亿投资,2025年融资总额超$10亿。局限:只做推理、单芯片SRAM有限需多芯片拼接、编程模型完全不同——这些局限决定了Groq更适合延迟敏感型推理场景(实时对话、API调用),而非通用推理市场。
6.4 Cerebras——晶圆级计算的工程奇迹
WSE-3:4万亿晶体管、90万核心、44GB片上SRAM——用片上SRAM替代HBM,省去带宽瓶颈。但44GB远不够放LLM权重,仍需外部存储。CS-3系统价格$数百万,客户门槛极高,只适合大模型预训练。软件栈生态极小。2025年9月Cerebras提交S-1申请IPO,2026年3月获得SEC批准但估值缩水至约$50亿(低于此前预期的$80亿+),IPO进展缓慢反映了市场对晶圆级计算商业模式的疑虑。
6.5 Microsoft Maia——后发者的策略
Maia 100(2023年Ignite亮相):Azure首个自研AI芯片。Maia 200(2026年1月26日正式发布):3nm工艺,1400亿+晶体管,专为AI推理设计,已部署于OpenAI GPT-5.2推理和Azure Copilot。微软称Maia 200同等价格下性能比替代方案高30%。微软的特殊优势:OpenAI是最重要的客户,需求明确;可从OpenAI模型架构中提取先验知识优化硬件。
6.6 Tesla Dojo——训练ASIC的失败教训
Dojo D1是特斯拉2019年启动的自研训练ASIC项目,2021年发布D1芯片(7nm TSMC,362 TFLOPS/芯片),2025年7月首座Dojo集群投用。但2025年8月,马斯克宣布解散Dojo超算团队,转向AI5/AI6推理芯片。Dojo是"训练端ASIC极度困难"的活教材:训练模型架构仍在快速演进、软件栈从零构建成本极高、与NVIDIA成熟生态竞争几乎没有胜算。
云厂商自研AI芯片对比:
| 数据来源:各公司官方发布信息、SemiAnalysis、Dell'Oro。部署规模为内部AI推理算力中自研ASIC占比估算。
第七章 市场规模与竞争格局
7.1 全球AI芯片市场规模
2025年AI芯片市场$1000亿,2030年$3100亿——ASIC占比从17%升至48.4%。GPU(NVIDIA为主)~$780亿(78%),AI ASIC ~$170亿(17%),FPGA及其他~$50亿(5%)。2030年预测:GPU ~$1500亿(48.4%),ASIC ~$1500亿(48.4%),FPGA ~$100亿(3.2%),整体占比落在40-48%的预测区间上限。ASIC CAGR 40%+(2025-2030),远高于GPU的15-20%。数据来源:Gartner 2025年1月预测 + SemiAnalysis交叉验证。
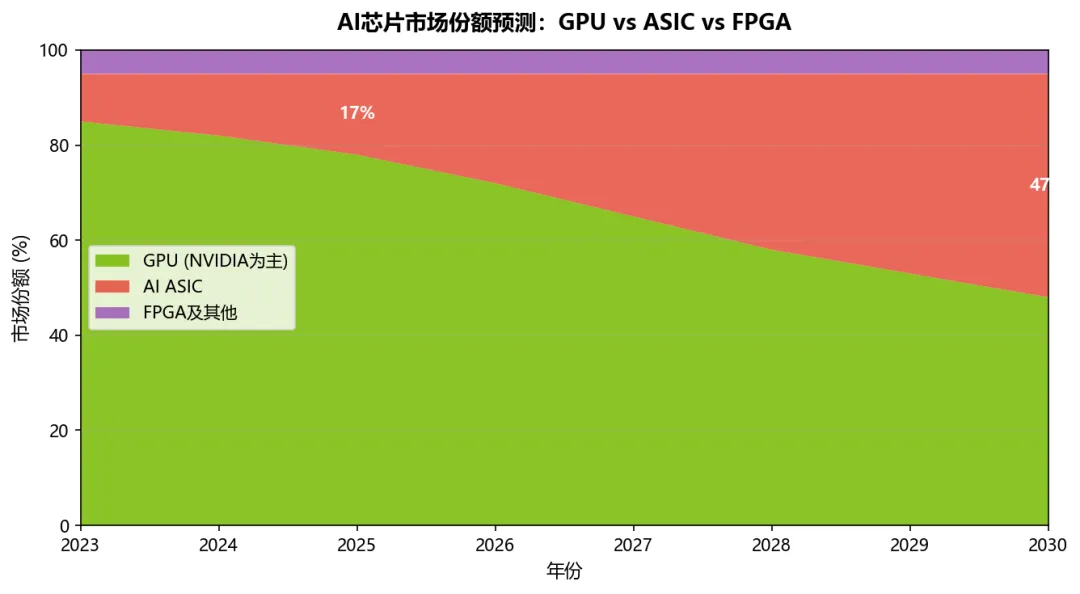
图6:AI芯片市场份额预测——GPU vs ASIC
7.2 训练vs推理市场拆分
2025年全球云端AI算力训练:推理≈32:68(SemiAnalysis 2026年3月数据)。训练芯片市场($320亿):GPU占90%+,ASIC渗透缓慢,预计2030年训练ASIC渗透率仍<20%。推理芯片市场($680亿):GPU占55-60%,ASIC占25-30%,FPGA占5-10%;推理ASIC CAGR 40%+(2025-2030),远高于GPU推理的15-20%。
7.3 云厂商自研芯片渗透率
Google:TPU已占内部AI推理算力72%,外部GCP客户TPU使用率约20%。AWS:Trainium/Inferentia占AWS AI推理算力约14%(2025年),目标2026年达50%(推理端)。Meta:MTIA v2开始部署推理,2025年占Meta推理算力约10%。Microsoft:Maia 200刚起步,<5%。预计2028年:Google 85%+、AWS 45%、Meta 35%、Microsoft 25%。
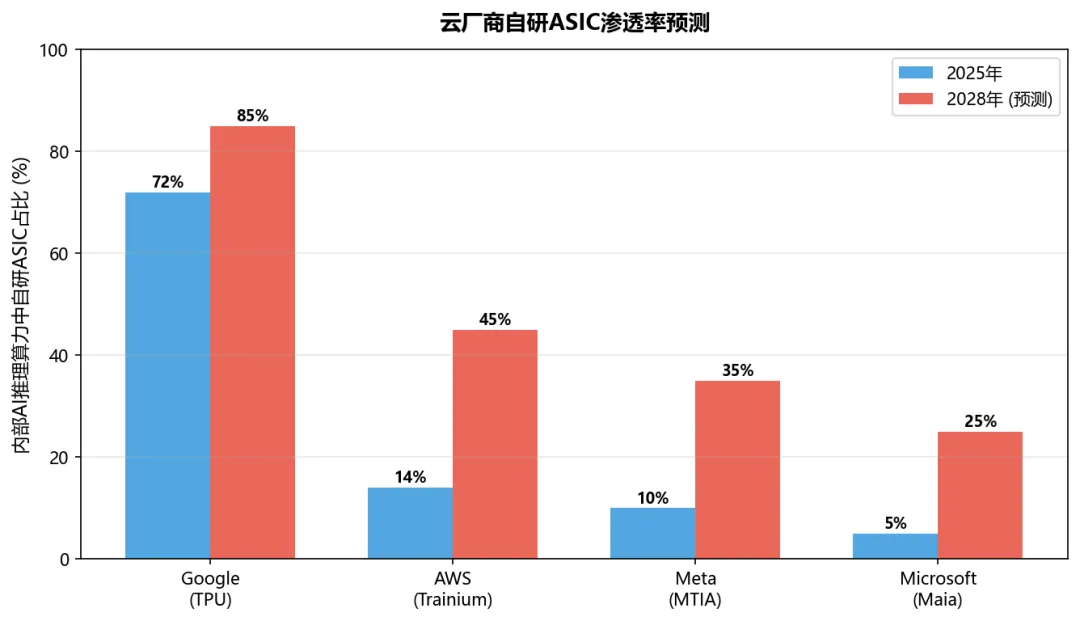
图7:云厂商自研ASIC渗透率预测
7.4 竞争格局与毛利率
NVIDIA GPU Data Center毛利率70%+,是ASIC替代的核心驱动力。Broadcom定制XPU毛利率~50-60%,自研芯片"等效毛利率"约40-55%。ASIC的定价逻辑不是"跟GPU一样贵",而是"比GPU便宜30-50%但仍有利润"——用成本优势抢份额。
第八章 产业链拆解——ASIC的供应链与GPU有何不同
8.1 设计端:NRE成本与门槛
先进制程AI ASIC的设计成本:3nm $4-6亿、5nm $2-4亿、7nm $1-2亿(含IP授权、EDA、验证、流片)。IP授权成本结构:CPU IP(ARM/RISC-V)$500万-2000万、互连IP(PCIe/CXL)$1000万-3000万、PHY IP(HBM/DDR)$500万-1500万。设计周期24-36个月 vs NVIDIA迭代节奏18-24个月——自研芯片存在"代差"风险。
8.2 制造端:台积电的"双轨"产能
NVIDIA是台积电前三大客户,产能有保障;ASIC客户(Google/AWS)也是大客户,但AI芯片产量远小于NVIDIA。正如前序GPU报告所述,2025年Blackwell新平台出货预计占NVIDIA高端GPU总货量的82%,台积电CoWoS月产能预计2025年底接近7-8万片——但NVIDIA拿走60%+,ASIC客户封装排期可能延迟3-6个月。HBM分配最关键:2025年HBM3e产能NVIDIA独占70%,AMD 12%,Google TPU 8%,AWS/Meta/Microsoft合计6%(与前序HBM报告数据一致)。ASIC客户获取HBM的难度和成本都更高,部分推理ASIC选择用GDDR6/GDDR7替代(性能降级但供应稳定)——这是推理ASIC可以绕开HBM瓶颈的差异化路径。
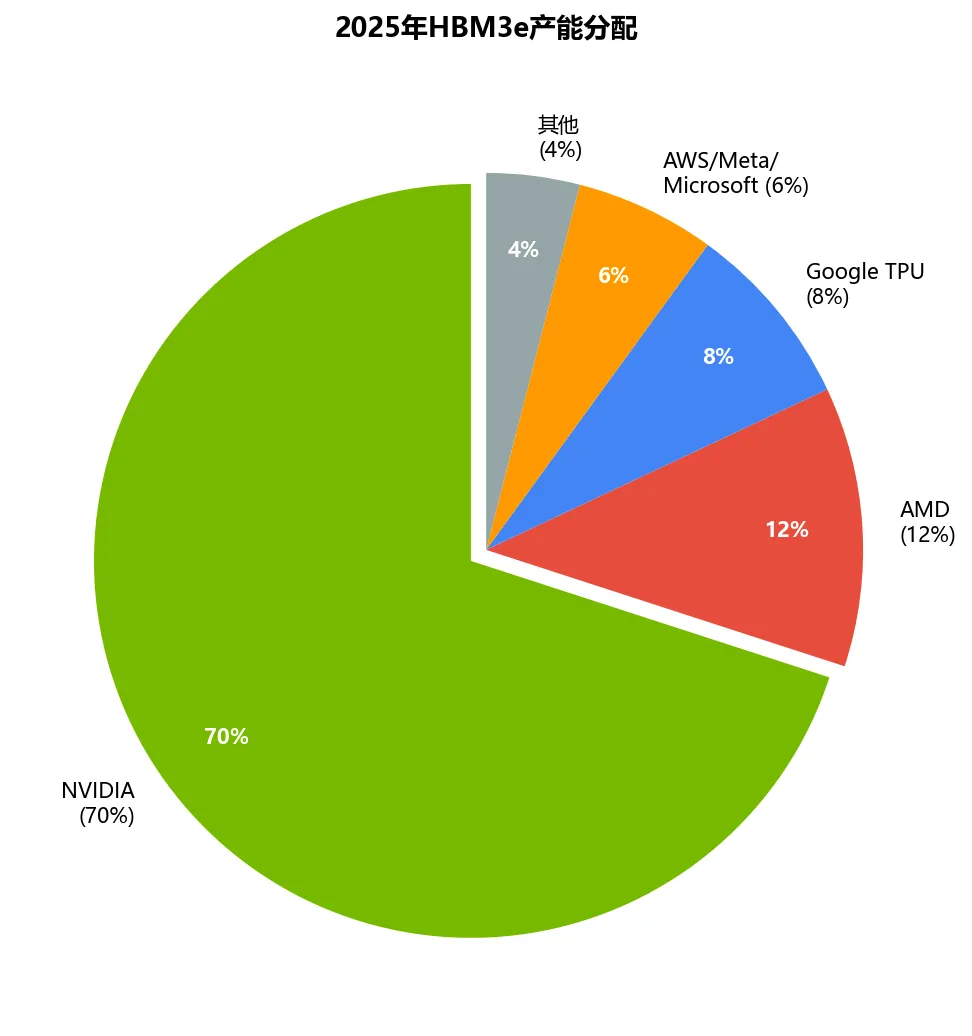
图8:产业链价值分配——HBM视角
8.3 封装与BOM对比
ASIC封装选择:先进封装(CoWoS)用于HBM集成必须用,但成本高产能紧;传统封装(InFO/FC-BGA)用于不用HBM的推理ASIC,成本低。趋势:推理ASIC可能走"不用HBM"路线,用大容量GDDR7+传统封装,降低对NVIDIA-dominated HBM供应链的依赖。关键BOM对比:NVIDIA H100用6颗HBM3(80GB),B200用8颗HBM3e(192GB);TPU v5p用4-8颗HBM(95GB);推理ASIC可用2-4颗HBM或8-16颗GDDR7。互连芯片:GPU用NVLink Switch(NVIDIA自研),ASIC用PCIe Retimer/CXL Switch(Astera Labs等)或自研互连。
第九章 国产AI ASIC——制裁下的自主路线
9.1 华为昇腾——国产AI算力的主力
产品线:昇腾910B(2023,改进版用于替代A100)→昇腾910C(2024-2025,性能约A100的70-80%)→昇腾910D(2025年4月曝光,FP16算力1.2 PFLOPS,目标超越H100,Da Vinci 3.0架构)。市场份额:国产AI加速卡市场60%+(2024年),主要客户为政府、央企、运营商、金融,互联网大厂也在部分业务线部署。
昇腾架构(Da Vinci核心)属于类GPU SIMT路线——3D Cube矩阵引擎+Vector向量引擎+Scalar标量引擎,与TPU的脉动阵列不同,更接近GPU的SIMT思路。CANN软件栈2026年算子覆盖1000+,适配PyTorch 2.0,但与CUDA的2000+算子和12年生态积累仍有显著差距。
9.2 寒武纪与海光
寒武纪:思元370(推理)→思元590(训练+推理,约A100的40-50%)→思元690(2025年8月报道,Chiplet技术,MLUarch03架构,FP16 512 TFLOPS,采用中芯国际5nm等效制程,官方尚未正式发布)。2024年营收约11.74亿元(同比+65.6%),但2025年业绩爆发:全年营收约64.97亿元(同比+453%),净利润20.59亿元,上市以来首次全年盈利(数据来源:寒武纪2025年年报);2026年Q1单季营收11.11亿元(同比+4230%,数据来源:寒武纪2026年Q1财报),云端芯片收入占比超99%,已获得字节跳动等大客户订单。这是国产AI芯片商业化的里程碑——从亏损到高盈利的跨越证明了国产替代的真实需求。海光信息:DCU(基于AMD Zen架构授权)是国内超算、信创市场的核心主力之一,2024年营收91.62亿元(同比+52.4%),净利润19.31亿元(同比+52.9%),毛利率63.7%(数据来源:海光信息2024年年报),DCU产品已完成与多家头部互联网厂商全面适配,兼容"类CUDA"环境。市场份额仅次于华为昇腾。
9.3 其他国产AI芯片
壁仞科技BR100→BR200:最初走通用GPU路线,受制裁后转向推理专用。燧原科技Enflame:云端推理定位,GCU产品线。摩尔线程MTT S4000:图形+AI混合路线,性能有限。
9.4 国产AI芯片的真实困境
制程差距:国内最先进量产制程7nm(中芯国际N+2),有报道5nm良率70%但官方未确认;国际领先3nm(台积电),2nm 2025年底量产——至少落后2代,晶体管密度差距2-3×。HBM断供:2024年起HBM对华出口管制;长鑫存储已量产HBM2,HBM3计划2026年量产,2027年推出HBM3E——与国际HBM3e仍有1-2代差距。正如前序HBM/存储报告所述,没有HBM,大算力芯片的内存带宽瓶颈无法解决,替代方案GDDR6/GDDR7带宽差3-5×。EDA工具受限:Synopsys/Cadence对华限制升级,国产EDA覆盖度约30-40%。先进封装瓶颈:正如前序CPO/电源报告所述,CoWoS产能被NVIDIA优先锁定,国产先进封装能力仍在追赶中——长电科技、通富微电的2.5D/3D封装良率和产能与国际领先水平仍有差距。
信创政策是国产AI芯片市场的"政策底"——即使技术尚有差距,采购需求也是刚性的。华为昇腾、寒武纪2025年业绩爆发的核心驱动力,不仅是技术进步,更是政策推动——党政机关、央企国企、金融机构被要求达到AI算力国产化率的硬性指标(2025年目标50%+,2027年目标70%+),金融行业监管已明确要求核心业务系统逐步迁移至国产算力平台。但必须明确区分"政策驱动采购"与"市场化商业采购":前者集中在政企/金融/运营商,属于非价格敏感的刚性需求,不反映产品真实竞争力;后者以互联网大厂为代表,仍以NVIDIA为主,国产替代的"真实商业竞争力"需要等到互联网大厂自愿大规模采购才能验证。寒武纪获得字节跳动订单是积极信号,但规模占比仍需持续跟踪。
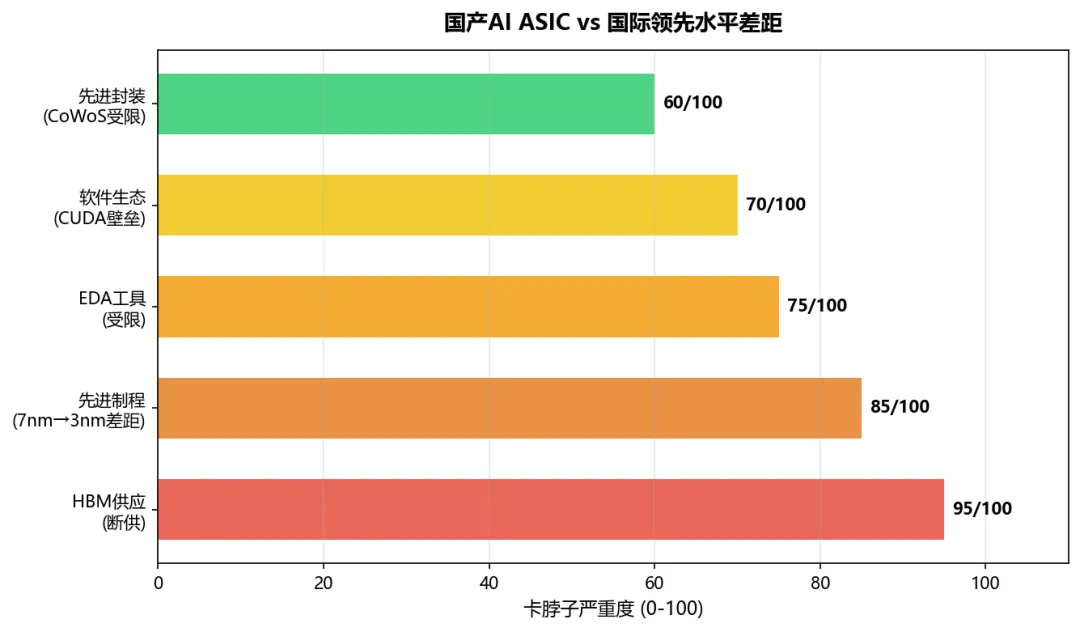
图9:国产AI ASIC vs 国际领先水平差距
9.5 国产替代路线图
短期(2025-2026):政府/央企/军工拉通国产替代,昇腾910C/910D为主力;推理场景率先替代(精度要求低,制程要求低);互联网大厂混合部署(GPU训练+昇腾推理)。中期(2027-2028):推理ASIC国产化率>50%(政府要求驱动);国产HBM3量产缓解带宽瓶颈;国产5nm等效制程产能爬坡。长期(2029+):先进制程+HBM国产化后的全面替代,但训练端仍依赖进口GPU。
第十章 趋势与判断
10.1 推理ASIC将在2027-2028年迎来拐点
拐点的前提条件正在逐一满足:模型架构收敛(Transformer>90%工作负载,专用化才有意义)、量化技术成熟(INT8/FP8推理成为默认选择)、云厂商软件栈完善(Neuron SDK/JAX/XLA达到可用水平)、推理算力需求增速远超训练。拐点标志:至少一家云厂商推理算力50%+来自自研ASIC、推理ASIC的单位token成本降至GPU的1/3以下、MLPerf Inference排行榜ASIC与GPU平分秋色。
MLPerf最新基准参考:MLPerf Inference v6.0(2026年4月发布)新增了LLM、视频生成、视觉语言模型等测试项,NVIDIA B200/GB200在多项LLM推理基准中领先,但Google TPU v6在部分项目未提交完整结果,AMD MI355X首次在MLPerf提交中展示了竞争力。值得注意的是,MLPerf成绩反映的是峰值优化场景,实际业务场景的有效利用率差异更大——这正是ASIC的效率优势难以在基准测试中完全体现的原因。MLPerf Training v5.0(2025年11月)中,NVIDIA Blackwell集群在全部训练项目保持领先。
10.2 "芯片+系统+云"的闭环竞争
单卖芯片模式正在被"芯片+云服务"取代。NVIDIA的防御:DGX Cloud+NVLink生态+CUDA壁垒。云厂商的进攻:自研芯片+低价推理服务+深度绑定客户。Broadcom的"卖铲子"模式:为云厂定制设计,不直接竞争,2026年4月与Google签5年长约证实模式可持续。
10.3 Chiplet与先进封装的变数
Chiplet理论上可降低ASIC设计门槛——通用计算die+专用加速die+HBM die像搭积木。但die间互连带宽是瓶颈:UCIe 2.0(2024年8月发布)规范了3D封装和可管理性,但带宽仍远不如片上互连。NVIDIA Grace Hopper的C2C互连900GB/s,需要高度定制。正如前序CPO报告所述,3D封装对推理芯片的意义在于逻辑die+HBM die 3D堆叠缩短数据路径降低功耗,但散热是最大挑战——高密3D堆叠的散热问题需要前序液冷报告所述的定向喷淋、冷板式液冷等方案来解决。
10.4 RISC-V在AI加速器中的渗透
RISC-V在AI加速器CPU核心中的渗透正在加速——优势是无授权费、可定制扩展;劣势是生态远不如ARM,高性能核心选择少。当前主流AI ASIC仍选ARM(TPU、Trainium均用ARM核心),但RISC-V在中国国产ASIC中渗透更快(避免ARM授权风险)。需明确区分:当前绝大多数AI ASIC仅用RISC-V做芯片的控制核心(负责指令调度、数据搬运),而非矩阵乘法的计算核心——RISC-V向量扩展可以加速部分不规则算子,但LLM推理的核心计算(矩阵乘法)仍由专用加速引擎(脉动阵列/Tensor Core)执行。Meta数据中心AI加速器已采用RISC-V向量核心(AndesTech IP)做控制+辅助计算,验证了RISC-V在云端AI场景的可行性。达摩院玄铁C930作为首款服务器级RISC-V CPU即将交付,RISC-V+AI的组合正在从边缘端向数据中心渗透——虽然短期内不会撼动ARM在高端AI ASIC中的地位,但为中小厂商提供了降低NRE成本的替代路径。
第十一章 风险提示
迭代错配风险(最核心):NVIDIA GPU迭代周期18-24个月,ASIC从规格定义到量产需24-36个月,极易出现"ASIC刚量产,性能就已落后NVIDIA新一代GPU"的困境。这是自研ASIC最核心的商业风险。海外案例:Tesla Dojo 2021年启动设计时对标A100,2024年D1芯片终于量产,但此时H100已服役近2年、B200即将发布,Dojo的算力密度和能效已无竞争力,加上软件栈不成熟导致大规模训练无法稳定运行,Tesla最终于2025年解散Dojo超算团队(The Information 2025年3月报道)。国内案例:寒武纪思元290立项时对标NVIDIA A100,但流片量产时H100已经上市,性能与能效被全面碾压,导致思元290在互联网大厂几乎无规模化部署,直到思元590/690才逐步追上——中间错失了2-3年市场窗口。2025年NVIDIA已公布下一代Rubin平台(预计2026年发布),Rubin Ultra TDP约2300W,ASIC厂商必须在Rubin量产前完成对标产品的设计,否则将永远落后一代。
技术架构突变风险:如果非Transformer架构(如Mamba/SSM)成为主流,为Transformer优化的ASIC将迅速过时。模型架构收敛是ASIC的前提条件,架构突变是ASIC的"黑天鹅"。当前Transformer>90%工作负载,短期风险可控,但长期需关注混合架构(Transformer+SSM)对ASIC专用化的挑战。
工程化落地风险:ASIC流片成功≠大规模商用。核心障碍:①分布式推理的调度、负载均衡、故障容错体系需从零构建(GPU有成熟NCCL+Megatron体系),这是Tesla Dojo失败的关键原因之一;②大模型平均3-6个月迭代一次,MoE专家数变化、上下文窗口扩容都需要ASIC重新做算子优化和编译适配,而GPU可一键兼容——外部客户不愿迁移的核心痛点即在于此;③运维工具链几乎为零(GPU有成熟DCGM监控、Nsight profiling),企业不愿为ASIC重构整个运维体系;④核心推理业务从GPU迁到ASIC,一旦出问题直接影响业务可用性,试错成本极高——这也是云厂商自研ASIC仅能内部大规模使用、外部客户渗透率极低的核心原因。
MoE模型对ASIC互连的极端压力:MoE模型的All-to-All通信量远超稠密模型,对ASIC的片间互连带宽、集群网络能力要求极高。正如前序交换机报告所述,MoE的专家并行使网络流量从规则的数据并行AllReduce变为不规则的All-to-All,大量单芯片性能强的ASIC在MoE模型上表现极差,因为互连能力跟不上。但这也是ASIC差异化竞争的机会——Google TPU v6已针对MoE做专用路由引擎,ASIC可针对MoE的稀疏路由特性做硬件加速,效率远超通用GPU。
生态壁垒风险:CUDA的420万+开发者生态不是2年能追上的。即使硬件性能领先,如果软件栈不成熟、算子覆盖不足、调试工具缺失,客户不会迁移。
产能与供应链风险:先进制程和HBM产能被NVIDIA优先锁定,ASIC客户的供应稳定性存疑。HBM断供对中国国产ASIC是致命打击。
标准迭代风险:CXL、UCIe、FP8等互连/精度标准快速迭代,ASIC硬件设计无法像GPU那样通过软件更新灵活适配,进一步放大落地风险。
地缘政治风险:美国对华AI芯片制裁可能进一步升级,国产替代路径可能受阻。先进制程、HBM、EDA工具是三个最脆弱的环节。
数据来源:Google、AWS、NVIDIA、Gartner、SemiAnalysis、公司财报等公开信息