


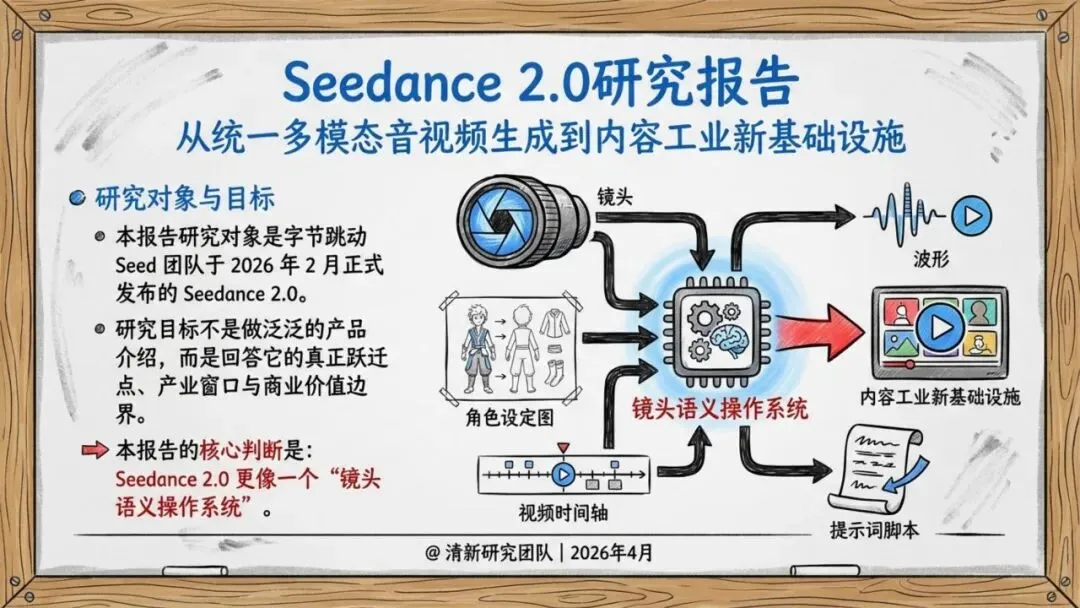
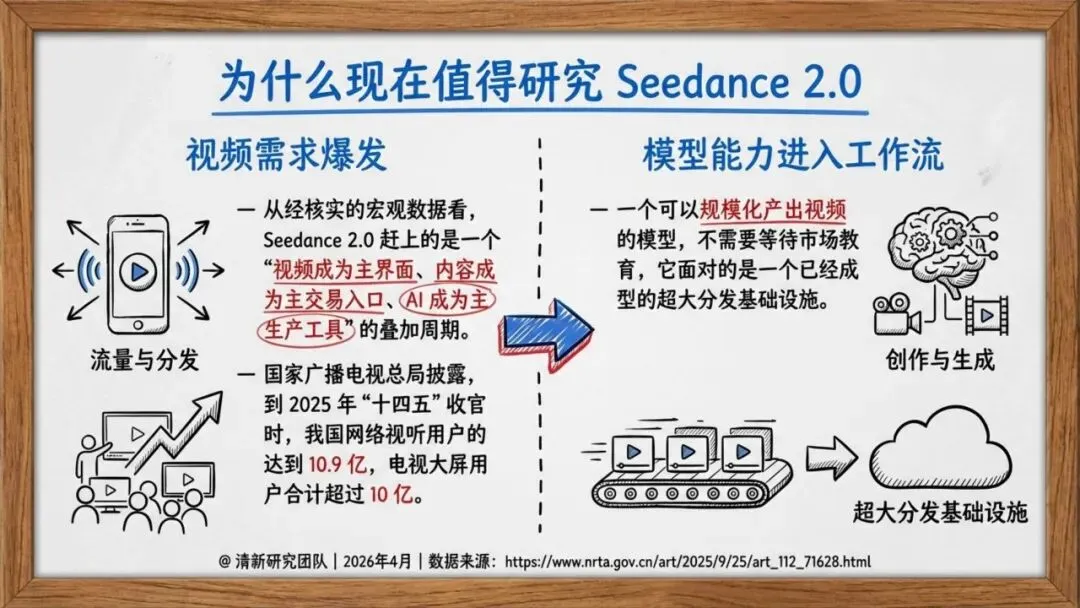
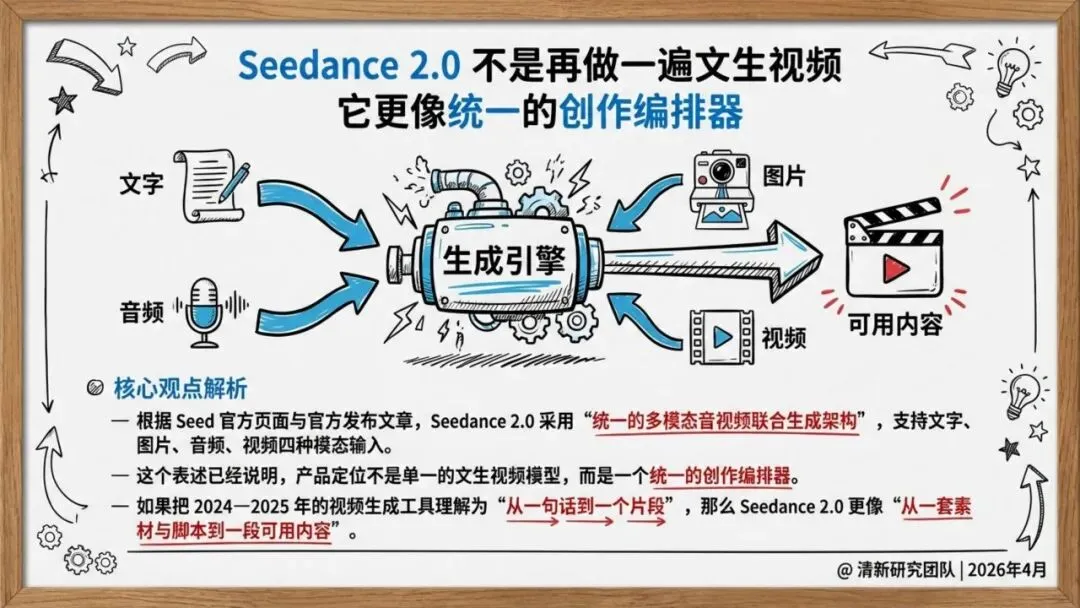
2026年2月,字节跳动Seed团队正式推出Seedance 2.0。它不是又一个“文生视频”工具,而是一个统一多模态音视频联合生成模型。
统一接口,四种输入
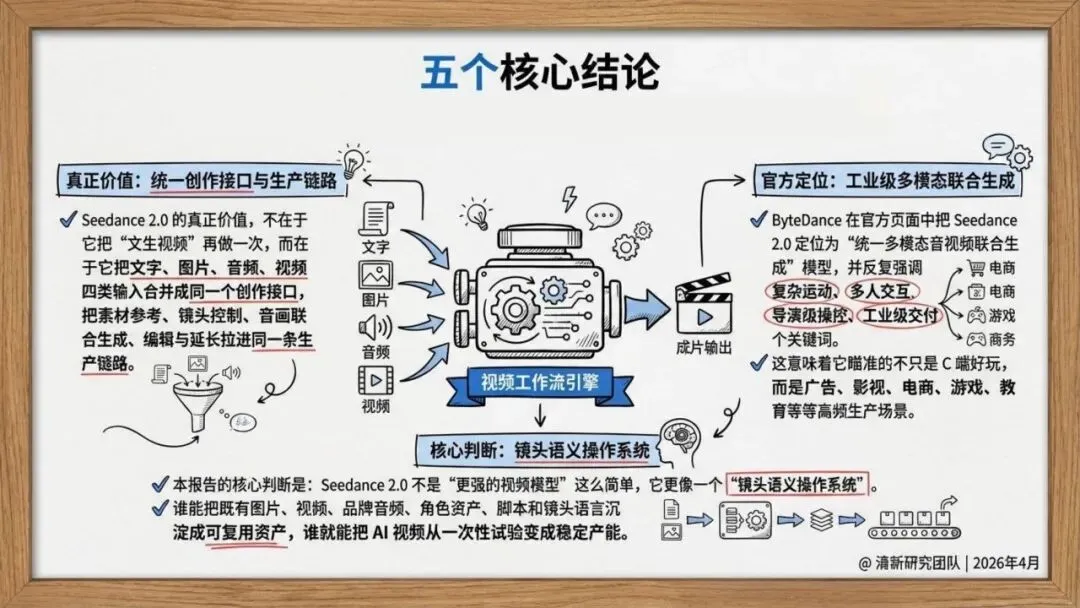
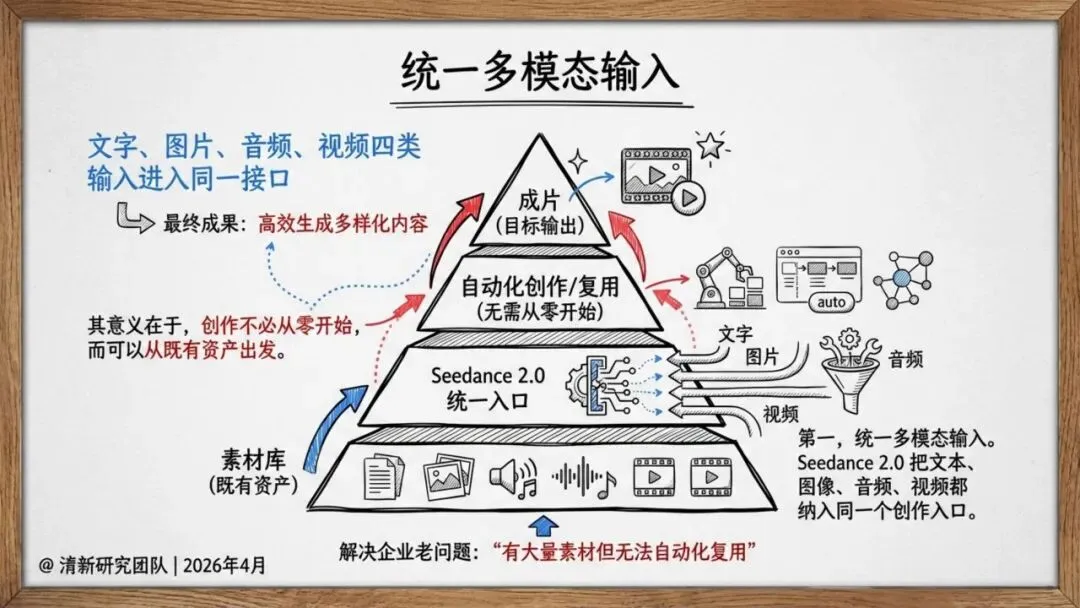
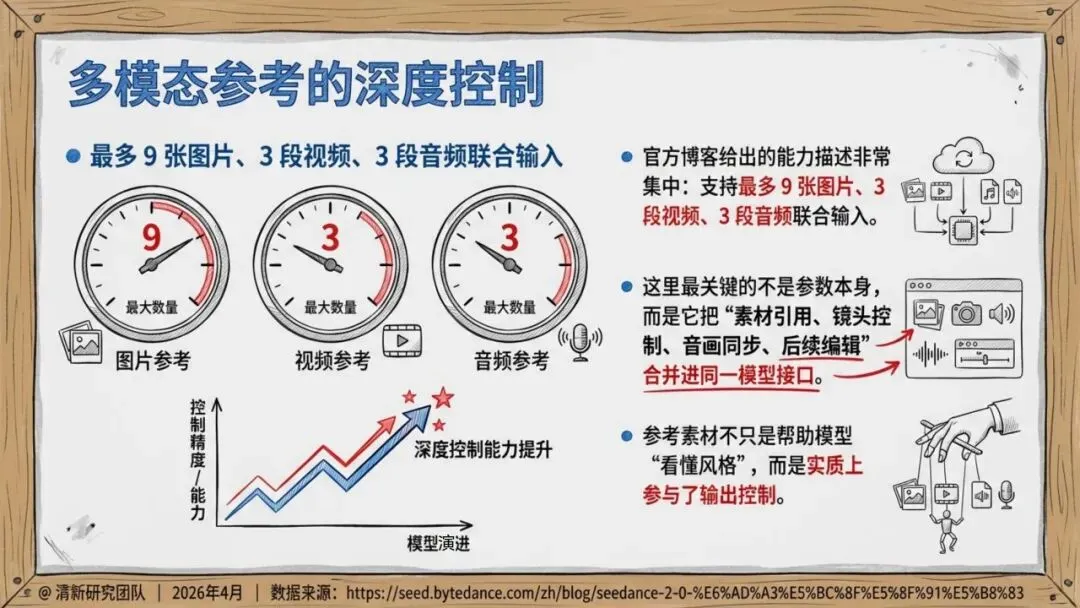
Seedance 2.0支持文字、图片、音频、视频四类输入进入同一创作接口。你可以同时上传最多9张图片、3段视频、3段音频,让模型参考构图、动作、运镜、音效,生成真正可控的内容。
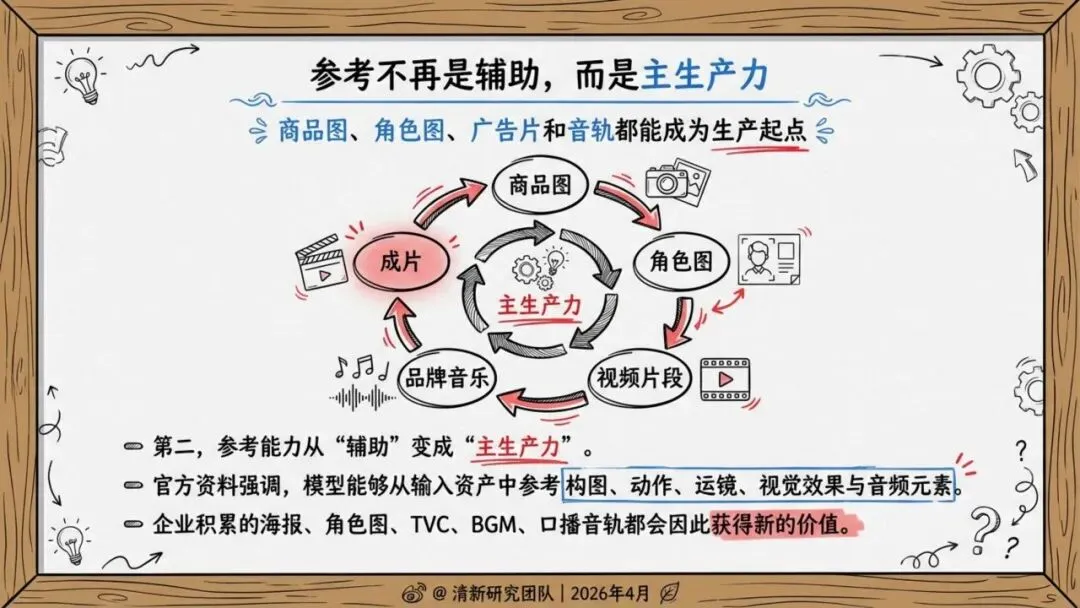
这意味着创作不必从零开始——企业积累的商品图、广告片、角色设定、品牌音乐,第一次可以直接成为生产力。
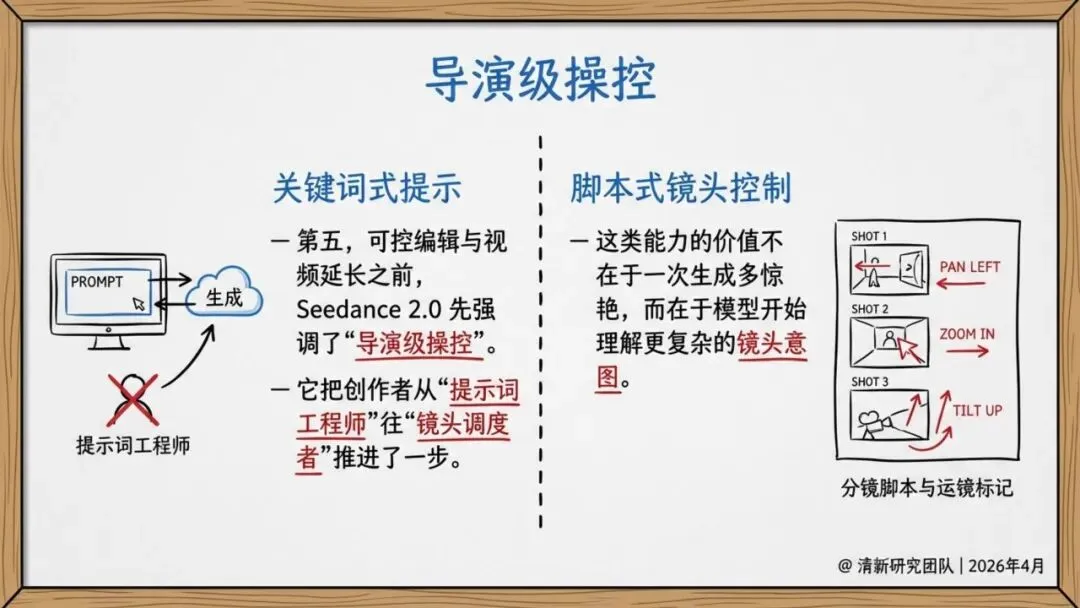
导演级操控,音画原生同步
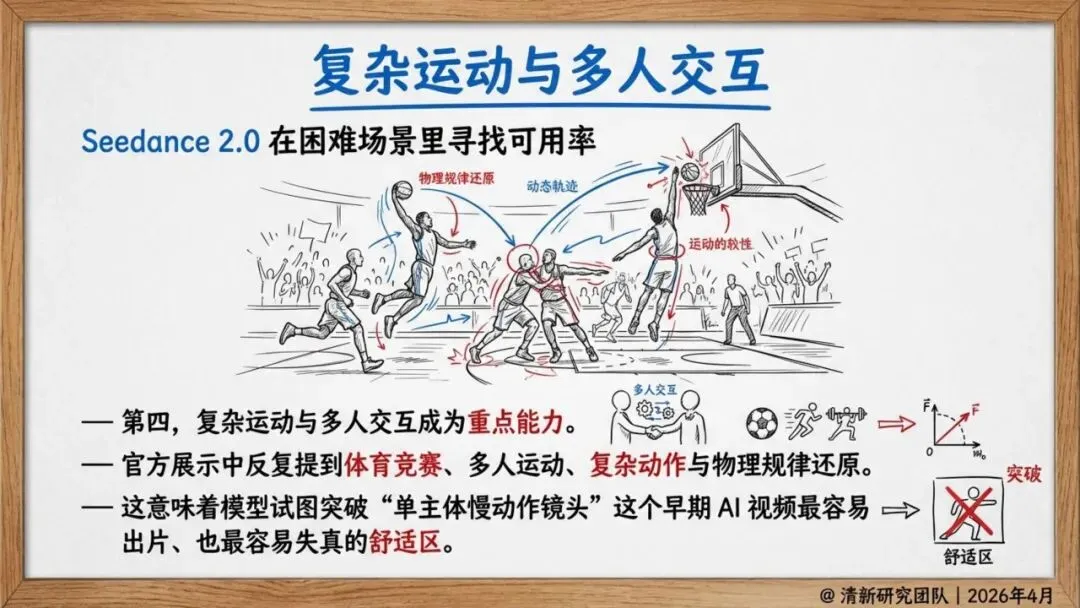
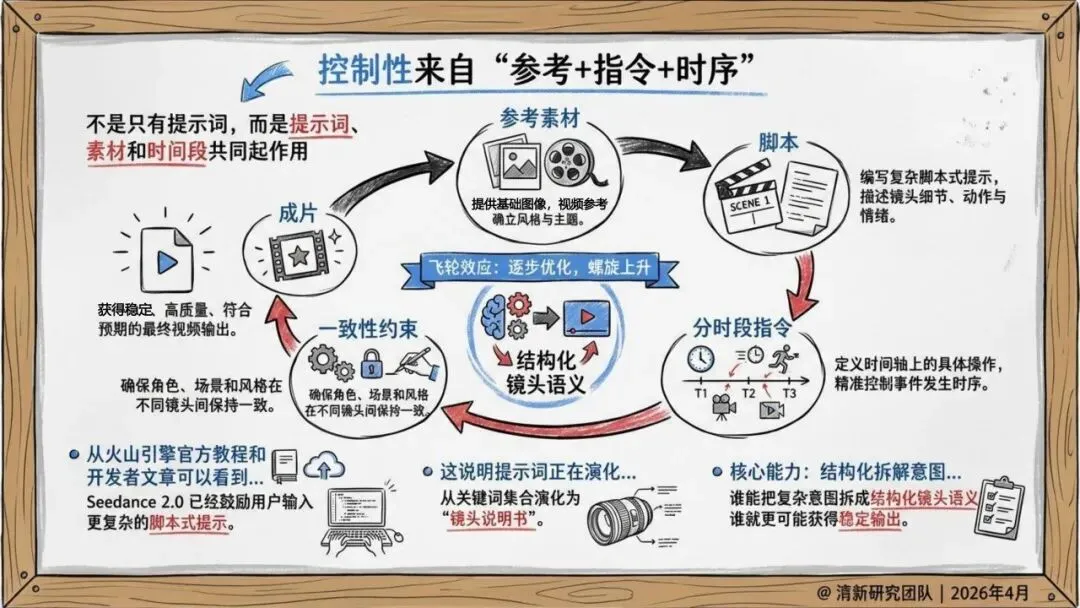
官方强调“导演级操控”,让创作者从“提示词工程师”变成镜头调度者。模型支持复杂运动、多人交互、体育竞赛等困难场景,不再局限于慢动作特写。
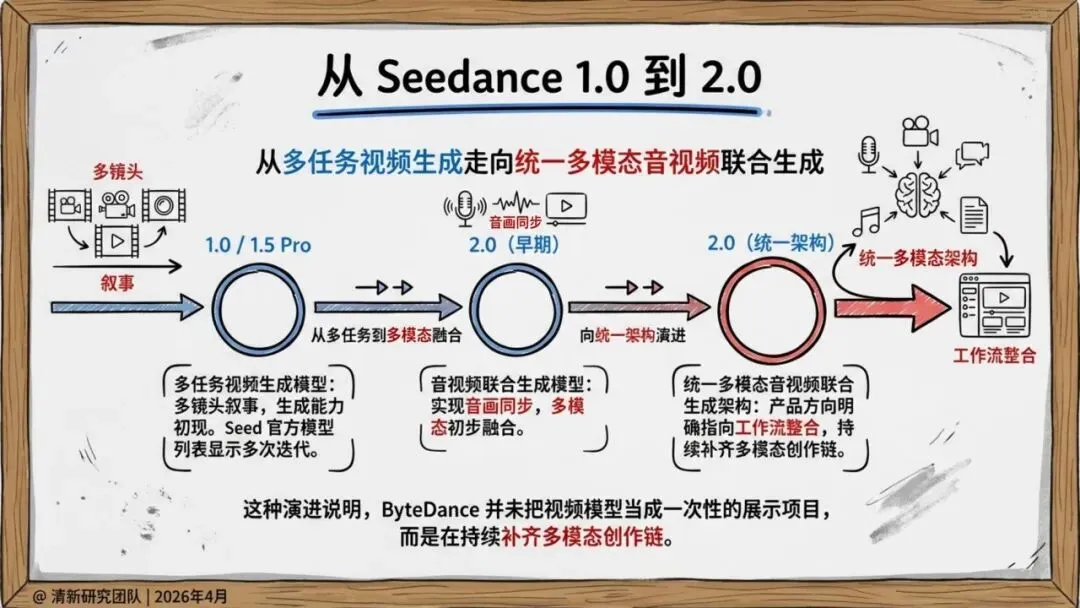
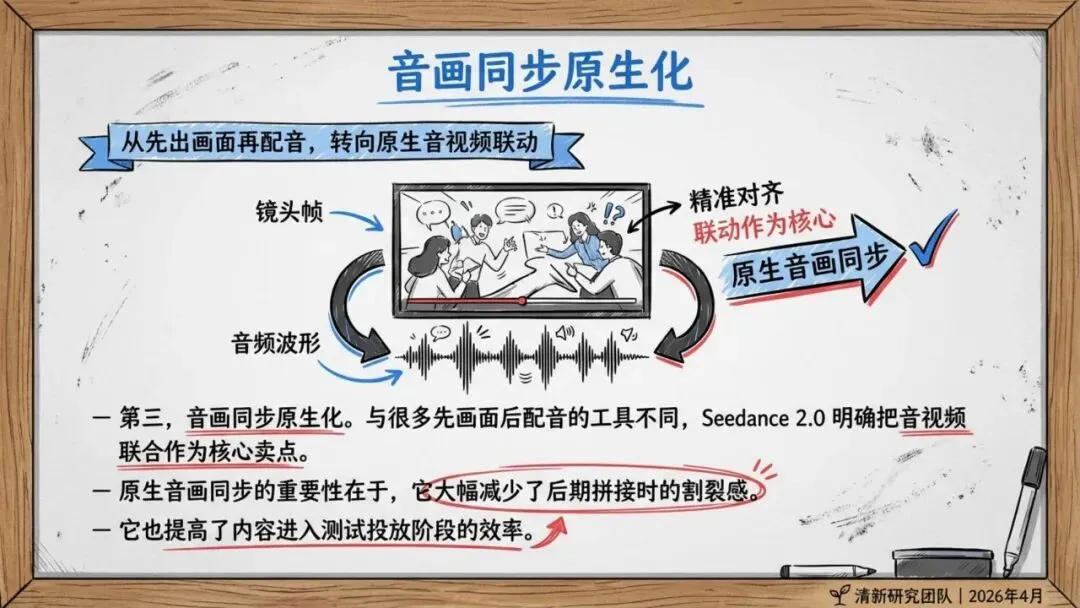
更重要的是,Seedance 2.0实现了原生音画联合生成,而非先出画面再配音。这大幅减少了后期拼接的割裂感,让输出更接近可交付片段。
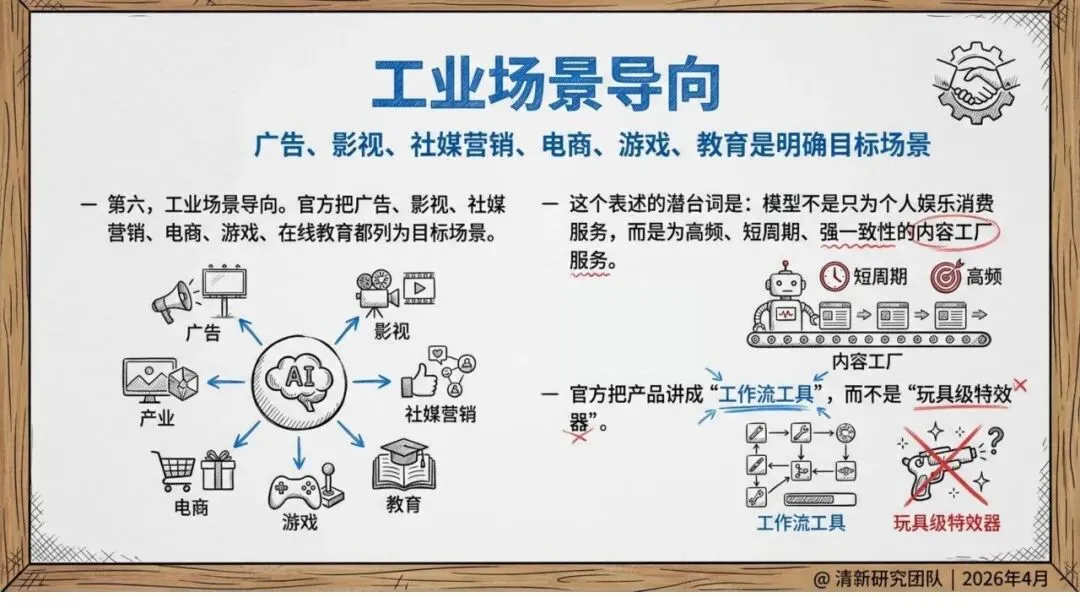
瞄准工业场景,而非玩具
官方明确将广告、影视、电商、游戏、在线教育列为目标场景。Seedance 2.0已上线即梦AI、豆包和火山方舟,同时布局C端创作入口与B端企业服务。
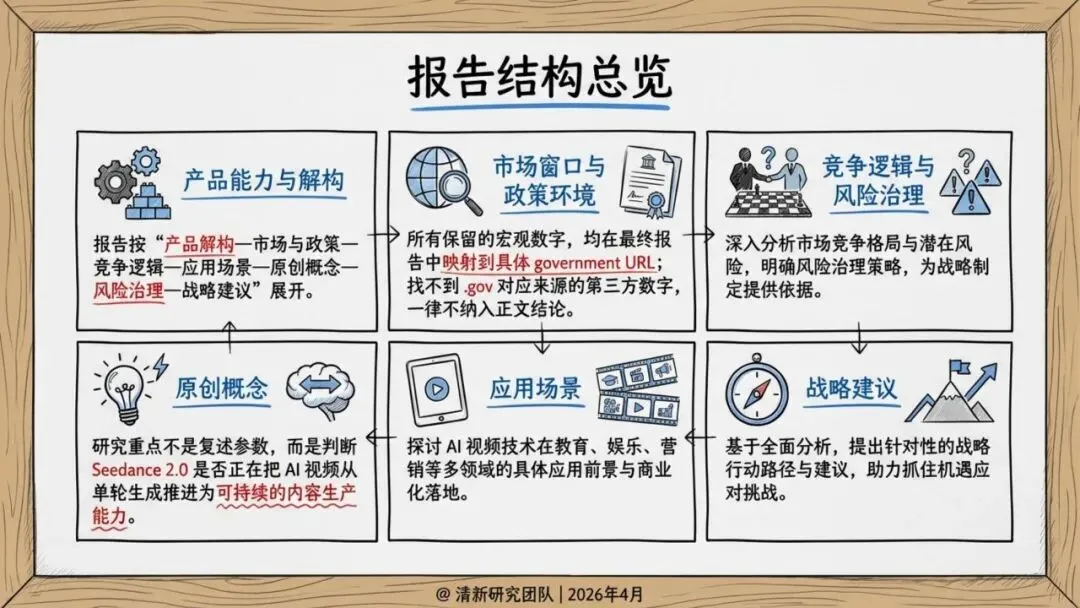
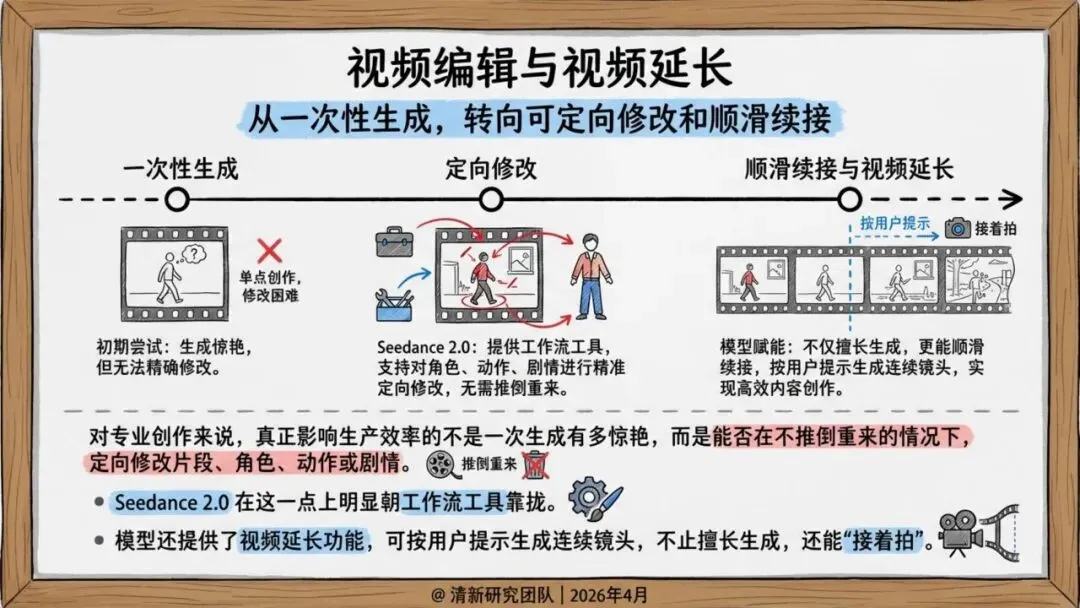
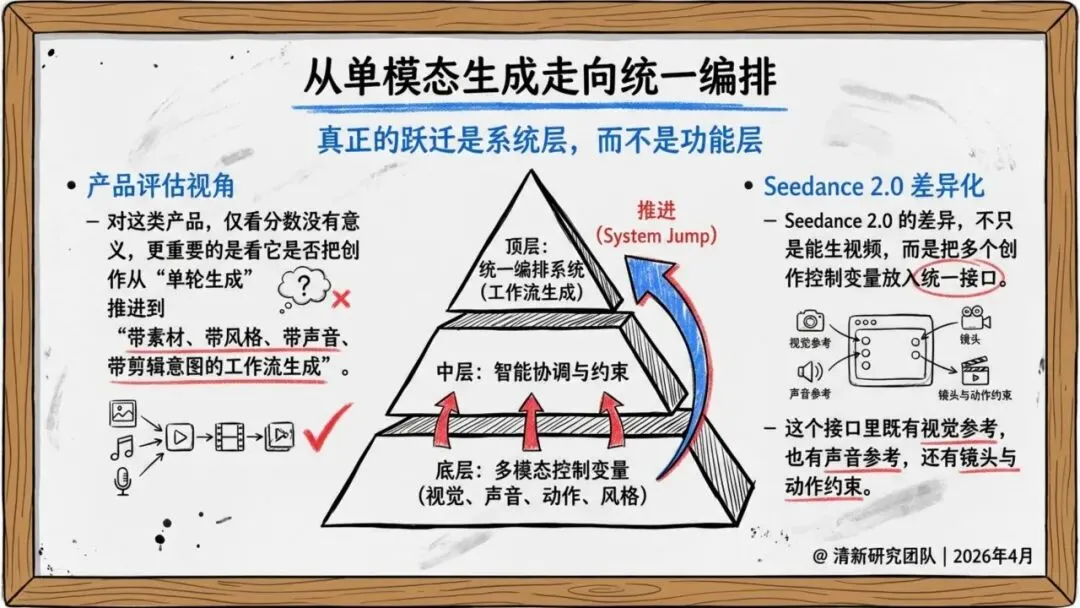
报告判断,它的真正价值在于把素材参考、镜头控制、音画生成、编辑与延长拉进同一条生产链路,从“单轮生成”推进到“工作流生成”。
从工具到系统
未来竞争焦点不再是模型单点能力,而是谁能把图片、视频、品牌音频、脚本沉淀成可复用资产。企业需要建设三类基础设施:参考素材库、镜头语义模板库、合规审核流程库。
Seedance 2.0的意义,在于把视频生成从工具变成系统。它不是更强的模型,而是一个正在成型的创作基础设施。



清华信息
清华:AI康养深度研究报告:从“辅助诊疗工具”走向“生命全周期照护操作系统”
清华大学2025人工智能治理年度报告迈向可衡量的AI治理19页.pdf
清华大学2025年AIGC发展研究报告4.0版152 页.pdf
清华大学&华为:AI终端白皮书-AI与人协作、服务于人.pdf